來源:B站
目錄
- Kafka生產者
- 生產經驗——生產者如何提高吞吐量
- 生產經驗——數據可靠性
- 生產經驗——數據去重
- 數據傳遞語義
- 冪等性
- 生產者事務
- 生產經驗——數據有序
- 生產經驗——數據亂序
- Kafka Broker
- Kafka Broker 工作流程
- Zookeeper 存儲的 Kafka 信息
- Kafka Broker 總體工作流程
- Broker 重要參數
- Kafka 副本
- 副本基本信息
- Leader 選舉流程
- Leader 和 Follower 故障處理細節
- 生產經驗——Leader Partition 負載平衡
- 生產經驗——增加副本因子
- 文件存儲
- 文件存儲機制
- 文件清理策略
- 高效讀寫數據
- Kafka 消費者
- Kafka 消費方式
- Kafka 消費者工作流程
- 消費者總體工作流程
- 消費者組原理
- 消費者重要參數
- 消費者 API
- 獨立消費者案例(訂閱主題)
- 生產經驗——分區的分配以及再平衡
- Range 以及再平衡
- RoundRobin 以及再平衡
- Sticky 以及再平衡
- offset 位移
- offset 的默認維護位置
- 自動提交 offset
- 手動提交 offset
- 指定 Offset 消費
- 指定時間消費
- 漏消費和重復消費
- 生產經驗——消費者事務
- 生產經驗——數據積壓(消費者如何提高吞吐量)
Kafka生產者
生產經驗——生產者如何提高吞吐量
package com.jjm.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerParameters {public static void main(String[] args) throws InterruptedException {// 1. 創建 kafka 生產者的配置對象Properties properties = new Properties();// 2. 給 kafka 配置對象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value 序列化(必須):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// batch.size:批次大小,默認 16Kproperties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);// linger.ms:等待時間,默認 0properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);// RecordAccumulator:緩沖區大小,默認 32M:buffer.memoryproperties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);// compression.type:壓縮,默認 none,可配置值 gzip、snappy、lz4 和 zstdproperties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");// 3. 創建 kafka 生產者對象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 4. 調用 send 方法,發送消息for (int i = 0; i < 5; i++) {kafkaProducer.send(new ProducerRecord<>("first","atguigu " + i));}// 5. 關閉資源kafkaProducer.close();}
}
測試:
①在 hadoop102 上開啟 Kafka 消費者。
[jjm@hadoop103 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
②在 IDEA 中執行代碼,觀察 hadoop102 控制臺中是否接收到消息。
[jjm@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
atguigu 0
atguigu 1
atguigu 2
atguigu 3
atguigu 4
生產經驗——數據可靠性
0)回顧發送流程
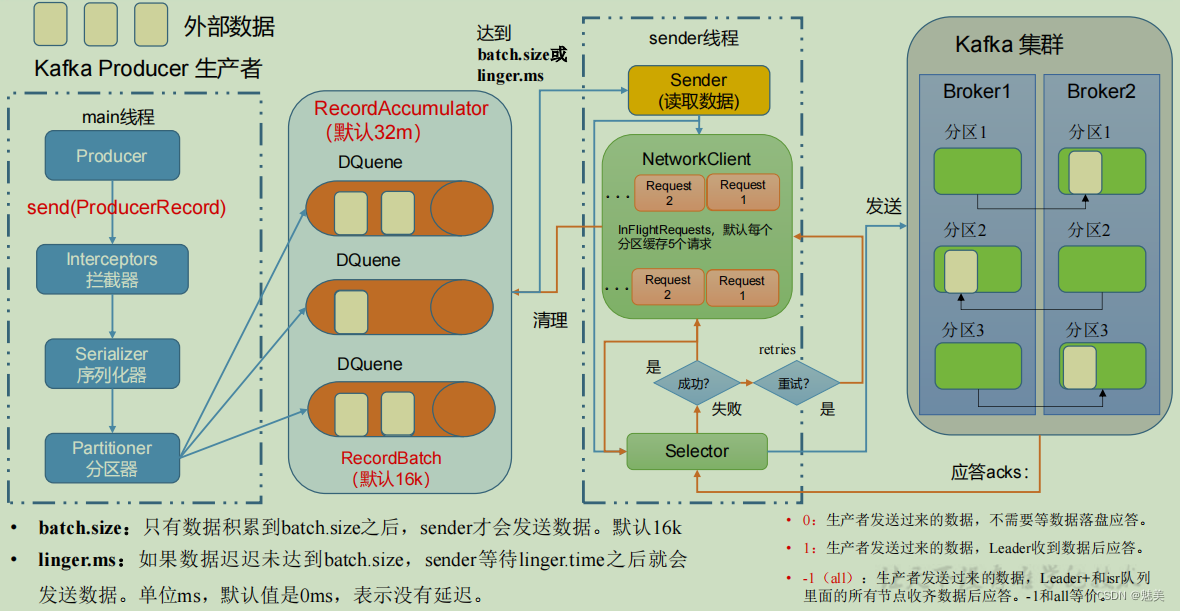
1)ack 應答原理
ACK應答級別
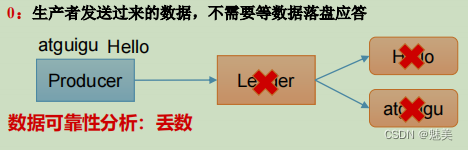
當acks=0時
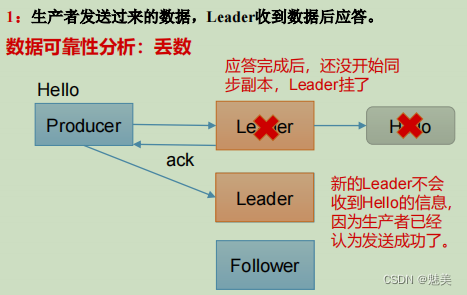
當acks=1時
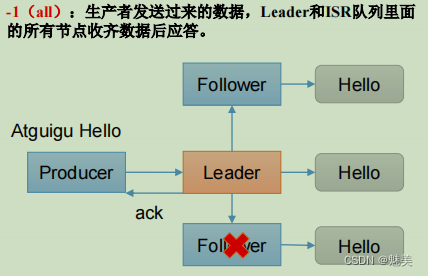
當acks=-1時
思考:Leader收到數據,所有Follower都開始同步數據,但有一個Follower,因為某種故障,遲遲不能與Leader進行同步,那這個問題怎么解決呢?
Leader維護了一個動態的in-sync replica set(ISR),意為和Leader保持同步的Follower+Leader集合(leader:0,isr:0,1,2)。
如果Follower長時間未向Leader發送通信請求或同步數據,則該Follower將被踢出ISR。該時間閾值由replica.lag.time.max.ms參數設定,默認30s。例如2超時,(leader:0, isr:0,1)。這樣就不用等長期聯系不上或者已經故障的節點。
數據可靠性分析:
如果分區副本設置為1個,或 者ISR里應答的最小副本數量( min.insync.replicas 默認為1)設置為1,和ack=1的效果是一樣的,仍然有丟數的風險(leader:0,isr:0)。
數據完全可靠條件 = ACK級別設置為-1 + 分區副本大于等于2 + ISR里應答的最小副本數量大于等于2
可靠性總結:
acks=0,生產者發送過來數據就不管了,可靠性差,效率高;
acks=1,生產者發送過來數據Leader應答,可靠性中等,效率中等;
acks=-1,生產者發送過來數據Leader和ISR隊列里面所有Follwer應答,可靠性高,效率低;
在生產環境中,acks=0很少使用;acks=1,一般用于傳輸普通日志,允許丟個別數據;acks=-1,一般用于傳輸和錢相關的數據,對可靠性要求比較高的場景。
生產經驗——數據去重
數據傳遞語義
- 至少一次(At Least Once)= ACK級別設置為-1 + 分區副本大于等于2 + ISR里應答的最小副本數量大于等于2
- 最多一次(At Most Once)= ACK級別設置為0
- 總結:
At Least Once可以保證數據不丟失,但是不能保證數據不重復;
At Most Once可以保證數據不重復,但是不能保證數據不丟失。
精確一次(Exactly Once):對于一些非常重要的信息,比如和錢相關的數據,要求數據既不能重復也不丟失。Kafka 0.11版本以后,引入了一項重大特性:冪等性和事務。
冪等性
- 1)冪等性原理
冪等性就是指Producer不論向Broker發送多少次重復數據,Broker端都只會持久化一條,保證了不重復。
精確一次(Exactly Once) = 冪等性 + 至少一次( ack=-1 + 分區副本數>=2 + ISR最小副本數量>=2) 。
重復數據的判斷標準:具有<PID, Partition, SeqNumber>相同主鍵的消息提交時,Broker只會持久化一條。其中PID是Kafka每次重啟都會分配一個新的;Partition 表示分區號;Sequence Number是單調自增的。
所以冪等性只能保證的是在單分區單會話內不重復。 - 2)如何使用冪等性
開啟參數 enable.idempotence 默認為 true,false 關閉。
生產者事務
1)Kafka 事務原理
說明:開啟事務,必須開啟冪等性。

2)Kafka 的事務一共有如下 5 個 API
// 1 初始化事務
void initTransactions();
// 2 開啟事務
void beginTransaction() throws ProducerFencedException;
// 3 在事務內提交已經消費的偏移量(主要用于消費者)
void sendOffsetsToTransaction(Map<TopicPartition,OffsetAndMetadata> offsets, String consumerGroupId) throws ProducerFencedException;
// 4 提交事務
void commitTransaction() throws ProducerFencedException;
// 5 放棄事務(類似于回滾事務的操作)
void abortTransaction() throws ProducerFencedException;
3)單個 Producer,使用事務保證消息的僅一次發送
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class CustomProducerTransactions {public static void main(String[] args) throws InterruptedException {// 1. 創建 kafka 生產者的配置對象Properties properties = new Properties();// 2. 給 kafka 配置對象添加配置信息properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key,value 序列化properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 設置事務 id(必須),事務 id 任意起名properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transaction_id_0");// 3. 創建 kafka 生產者對象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 初始化事務kafkaProducer.initTransactions();// 開啟事務kafkaProducer.beginTransaction();try {// 4. 調用 send 方法,發送消息for (int i = 0; i < 5; i++) {// 發送消息kafkaProducer.send(new ProducerRecord<>("first", "jjm" + i));}// int i = 1 / 0;// 提交事務kafkaProducer.commitTransaction();} catch (Exception e) {// 終止事務kafkaProducer.abortTransaction();} finally {// 5. 關閉資源kafkaProducer.close();}}
}
生產經驗——數據有序
單分區內,有序(有條件的,詳見下節);
多分區,分區與分區間無序;
生產經驗——數據亂序
- 1)kafka在1.x版本之前保證數據單分區有序,條件如下:
max.in.flight.requests.per.connection=1(不需要考慮是否開啟冪等性)。 - 2)kafka在1.x及以后版本保證數據單分區有序,條件如下:
(2)開啟冪等性
max.in.flight.requests.per.connection需要設置小于等于5。
(1)未開啟冪等性
max.in.flight.requests.per.connection需要設置為1。
原因說明:因為在kafka1.x以后,啟用冪等后,kafka服務端會緩producer發來的最近5個request的元數據,故無論如何,都可以保證最近5個request的數據都是有序的。
Kafka Broker
Kafka Broker 工作流程
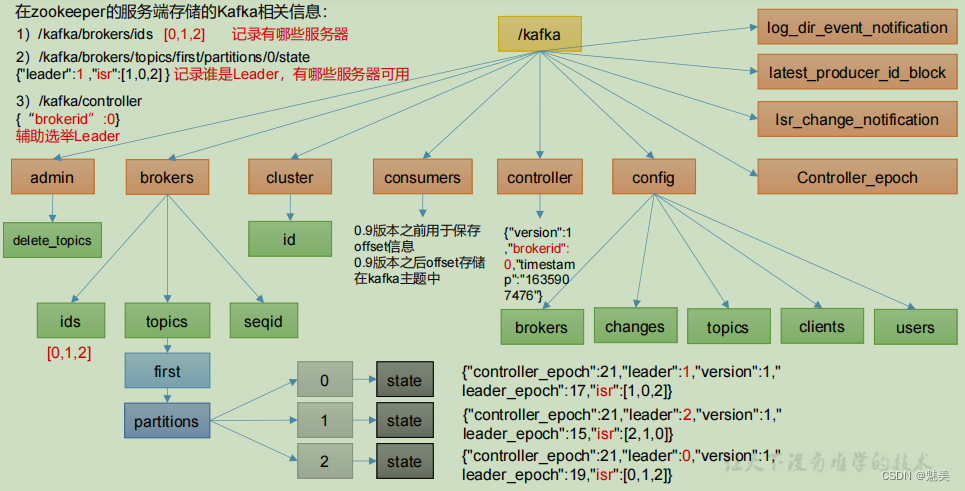
Zookeeper 存儲的 Kafka 信息
(1)啟動 Zookeeper 客戶端。
[jjm@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh
(2)通過 ls 命令可以查看 kafka 相關信息。
[zk: localhost:2181(CONNECTED) 2] ls /kafka
Zookeeper中存儲的Kafka 信息
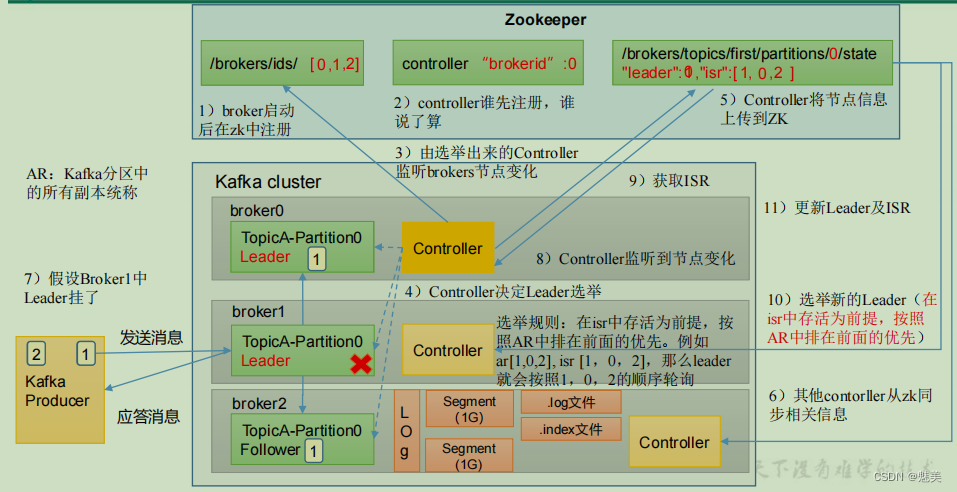
Kafka Broker 總體工作流程
- 1)模擬 Kafka 上下線,Zookeeper 中數據變化
(1)查看/kafka/brokers/ids 路徑上的節點。
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids
[0, 1, 2]
(2)查看/kafka/controller 路徑上的數據。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}
(3)查看/kafka/brokers/topics/first/partitions/0/state 路徑上的數據。
[zk: localhost:2181(CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18,"isr":[0,1,2]}
(4)停止 hadoop104 上的 kafka。
[jjm@hadoop104 kafka]$ bin/kafka-server-stop.sh
(5)再次查看/kafka/brokers/ids 路徑上的節點。
[zk: localhost:2181(CONNECTED) 3] ls /kafka/brokers/ids
[0, 1]
(6)再次查看/kafka/controller 路徑上的數據。
[zk: localhost:2181(CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}
(7)再次查看/kafka/brokers/topics/first/partitions/0/state 路徑上的數據。
[zk: localhost:2181(CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18,"isr":[0,1]}
(8)啟動 hadoop104 上的 kafka。
[atguigu@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon ./config/server.properties
(9)再次觀察(1)、(2)、(3)步驟中的內容。
Broker 重要參數
| 參數名稱 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR 中,如果 Follower 長時間未向 Leader 發送通信請求或同步數據,則該 Follower 將被踢出 ISR。該時間閾值,默認 30s。 |
| auto.leader.rebalance.enable | 默認是 true。 自動 Leader Partition 平衡。 |
| leader.imbalance.per.broker.percentage | 默認是 10%。每個 broker 允許的不平衡的 leader的比率。如果每個 broker 超過了這個值,控制器會觸發 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默認值 300 秒。檢查 leader 負載是否平衡的間隔時間。 |
| log.segment.bytes | Kafka 中 log 日志是分成一塊塊存儲的,此配置是指 log 日志劃分 成塊的大小,默認值 1G。 |
| log.index.interval.bytes | 默認 4kb,kafka 里面每當寫入了 4kb 大小的日志(.log),然后就往 index 文件里面記錄一個索引。 |
| log.retention.hours | Kafka 中數據保存的時間,默認 7 天。 |
| log.retention.minutes | Kafka 中數據保存的時間,分鐘級別,默認關閉。 |
| log.retention.ms | Kafka 中數據保存的時間,毫秒級別,默認關閉。 |
| log.retention.check.interval.ms | 檢查數據是否保存超時的間隔,默認是 5 分鐘。 |
| log.retention.bytes | 默認等于-1,表示無窮大。超過設置的所有日志總大小,刪除最早的 segment。 |
| log.cleanup.policy | 默認是 delete,表示所有數據啟用刪除策略;如果設置值為 compact,表示所有數據啟用壓縮策略。 |
| num.io.threads | 默認是 8。負責寫磁盤的線程數。整個參數值要占總核數的 50%。 |
| num.replica.fetchers | 副本拉取線程數,這個參數占總核數的 50%的 1/3 |
| num.network.threads | 默認是 3。數據傳輸線程數,這個參數占總核數的50%的 2/3 。 |
| log.flush.interval.messages | 強制頁緩存刷寫到磁盤的條數,默認是 long 的最大值,9223372036854775807。一般不建議修改,交給系統自己管理。 |
| log.flush.interval.ms | 每隔多久,刷數據到磁盤,默認是 null。一般不建議修改,交給系統自己管理。 |
Kafka 副本
副本基本信息
(1)Kafka 副本作用:提高數據可靠性。
(2)Kafka 默認副本 1 個,生產環境一般配置為 2 個,保證數據可靠性;太多副本會增加磁盤存儲空間,增加網絡上數據傳輸,降低效率。
(3)Kafka 中副本分為:Leader 和 Follower。Kafka 生產者只會把數據發往 Leader,然后 Follower 找 Leader 進行同步數據。
(4)Kafka 分區中的所有副本統稱為 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 長時間未向 Leader 發送通信請求或同步數據,則該 Follower 將被踢出 ISR。該時間閾值由 replica.lag.time.max.ms參數設定,默認 30s。Leader 發生故障之后,就會從 ISR 中選舉新的 Leader。
OSR,表示 Follower 與 Leader 副本同步時,延遲過多的副本。
Leader 選舉流程
Kafka 集群中有一個 broker 的 Controller 會被選舉為 Controller Leader,負責管理集群broker 的上下線,所有 topic 的分區副本分配和 Leader 選舉等工作。
Controller 的信息同步工作是依賴于 Zookeeper 的。
Leader選舉流程
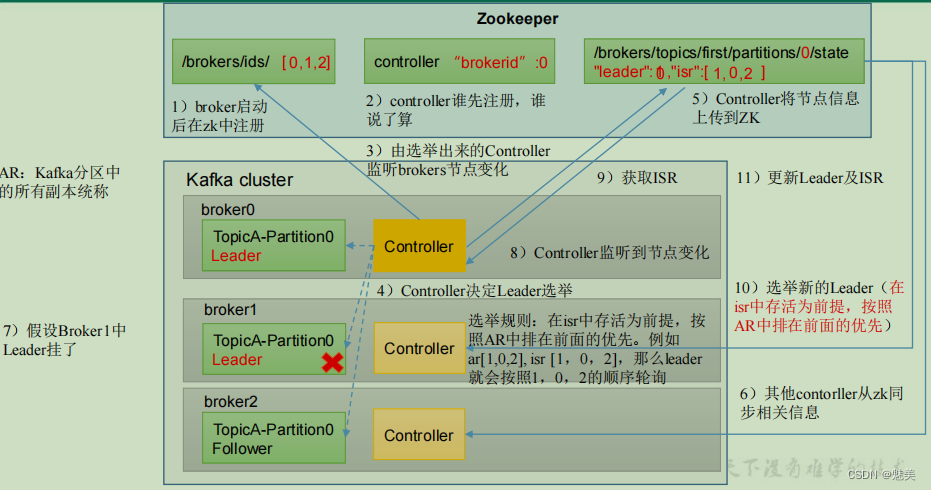
Leader 和 Follower 故障處理細節
- Follower故障處理細節
LEO(Log End Offset):每個副本的最后一個offset,LEO其實就是最新的offset + 1。
HW(High Watermark):所有副本中最小的LEO 。
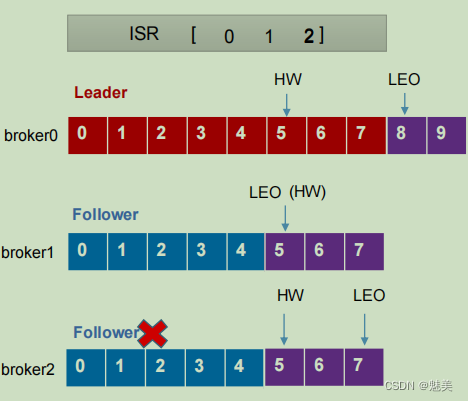
1)Follower故障
(1) Follower發生故障后會被臨時踢出ISR
(2) 這個期間Leader和Follower繼續接收數據
(3)待該Follower恢復后,Follower會讀取本地磁盤記錄的上次的HW,并將log文件高于HW的部分截取掉,從HW開始向Leader進行同步。
(4)等該Follower的LEO大于等于該Partition的HW,即Follower追上Leader之后,就可以重新加入ISR了。 - Leader故障處理細節
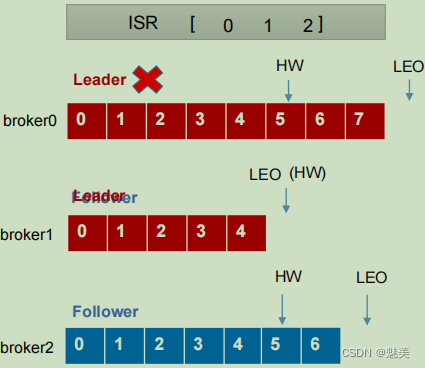
2)Leader故障
(1) Leader發生故障之后,會從ISR中選出一個新的Leader
(2)為保證多個副本之間的數據一致性,其余的Follower會先將各自的log文件高于HW的部分截掉,然后從新的Leader同步數據。
注意:這只能保證副本之間的數據一致性,并不能保證數據不丟失或者不重復。
生產經驗——Leader Partition 負載平衡
Leader Partition自動平衡
正常情況下,Kafka本身會自動把Leader Partition均勻分散在各個機器上,來保證每臺機器的讀寫吞吐量都是均勻的。但是如果某些broker宕機,會導致Leader Partition過于集中在其他少部分幾臺broker上,這會導致少數幾臺broker的讀寫請求壓力過高,其他宕機的broker重啟之后都是follower partition,讀寫請求很低,造成集群負載不均衡。
- auto.leader.rebalance.enable,默認是true。自動Leader Partition 平衡
- leader.imbalance.per.broker.percentage,默認是10%。每個broker允許的不平衡的leader的比率。如果每個broker超過了這個值,控制器會觸發leader的平衡。
- leader.imbalance.check.interval.seconds,默認值300秒。檢查leader負載是否平衡的間隔時間。
下面拿一個主題舉例說明,假設集群只有一個主題如下圖所示:

針對broker0節點,分區2的AR優先副本是0節點,但是0節點卻不是Leader節點,所以不平衡數加1,AR副本總數是4
所以broker0節點不平衡率為1/4>10%,需要再平衡。
broker2和broker3節點和broker0不平衡率一樣,需要再平衡。
Broker1的不平衡數為0,不需要再平衡
| 參數名稱 | 描述 |
|---|---|
| auto.leader.rebalance.enable | 默認是 true。 自動 Leader Partition 平衡。生產環境中,leader 重選舉的代價比較大,可能會帶來性能影響,建議設置為 false 關閉。 |
| leader.imbalance.per.broker.percentage | 默認是 10%。每個 broker 允許的不平衡的 leader的比率。如果每個 broker 超過了這個值,控制器會觸發 leader 的平衡。 |
| leader.imbalance.check.interval.seconds | 默認值 300 秒。檢查 leader 負載是否平衡的間隔時間。 |
生產經驗——增加副本因子
在生產環境當中,由于某個主題的重要等級需要提升,我們考慮增加副本。副本數的增加需要先制定計劃,然后根據計劃執行。
1)創建 topic
[jjm@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server
hadoop102:9092 --create --partitions 3 --replication-factor 1 --topic four
2)手動增加副本存儲
(1)創建副本存儲計劃(所有副本都指定存儲在 broker0、broker1、broker2 中)。
[jjm@hadoop102 kafka]$ vim increase-replication-factor.json
輸入如下內容:
{"version":1,"partitions":[{"topic":"four","partition":0,"replicas":[0,1,2]},{"topic":"four","partition":1,"replicas":[0,1,2]},{"topic":"four","partition":2,"replicas":[0,1,2]}]}
(2)執行副本存儲計劃。
[jjm@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
文件存儲
文件存儲機制
- 1)Topic 數據的存儲機制
Topic是邏輯上的概念,而partition是物理上的概念,每個partition對應于一個log文件,該log文件中存儲的就是Producer生產的數據。Producer生產的數據會被不斷追加到該log文件末端,為防止log文件過大導致數據定位效率低下,Kafka采取了分片和索引機制,將每個partition分為多個segment。每個segment包括:“.index”文件、“.log”文件和.timeindex等文件。這些文件位于一個文件夾下,該文件夾的命名規則為:topic名稱+分區序號,例如:first-0。 - 2)思考:Topic 數據到底存儲在什么位置?
(1)啟動生產者,并發送消息。
[jjm@hadoop102 kafka]$ bin/kafka-console-producer.sh --
bootstrap-server hadoop102:9092 --topic first
>hello world
(2)查看 hadoop102(或者 hadoop103、hadoop104)的/opt/module/kafka/datas/first-1(first-0、first-2)路徑上的文件。
[jjm@hadoop104 first-1]$ ls
00000000000000000092.index
00000000000000000092.log
00000000000000000092.snapshot
00000000000000000092.timeindex
leader-epoch-checkpoint
partition.metadata
- 3)index 文件和 log 文件詳解
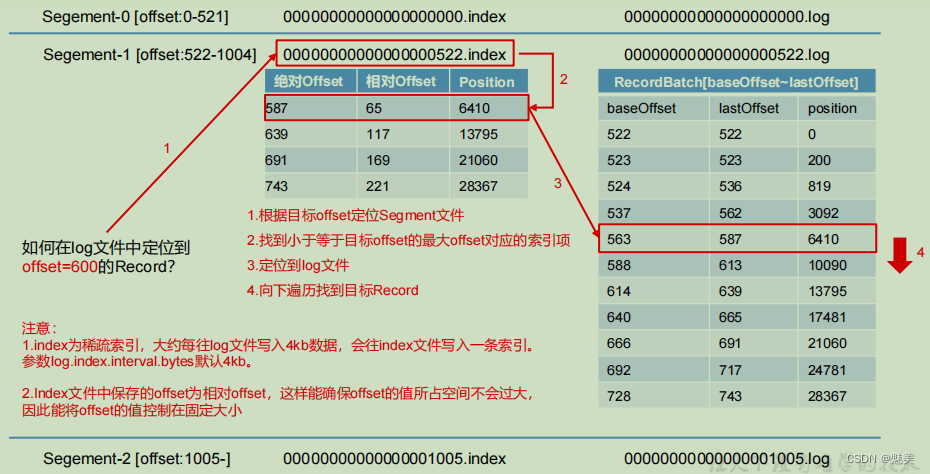
說明:日志存儲參數配置
| 參數 | 描述 |
|---|---|
| log.segment.bytes | Kafka 中 log 日志是分成一塊塊存儲的,此配置是指 log 日志劃分成塊的大小,默認值 1G。 |
| log.index.interval.bytes | 默認 4kb,kafka 里面每當寫入了 4kb 大小的日志(.log),然后就往 index 文件里面記錄一個索引。 稀疏索引。 |
文件清理策略
Kafka 中默認的日志保存時間為 7 天,可以通過調整如下參數修改保存時間。
- log.retention.hours,最低優先級小時,默認 7 天。
- log.retention.minutes,分鐘。
- log.retention.ms,最高優先級毫秒。
- log.retention.check.interval.ms,負責設置檢查周期,默認 5 分鐘。
那么日志一旦超過了設置的時間,怎么處理呢?
Kafka 中提供的日志清理策略有 delete 和 compact 兩種
1)delete 日志刪除:將過期數據刪除
log.cleanup.policy = delete 所有數據啟用刪除策略
(1)基于時間:默認打開。以 segment 中所有記錄中的最大時間戳作為該文件時間戳。
(2)基于大小:默認關閉。超過設置的所有日志總大小,刪除最早的 segment。
log.retention.bytes,默認等于-1,表示無窮大。
思考:如果一個 segment 中有一部分數據過期,一部分沒有過期,怎么處理?
2)compact 日志壓縮
compact日志壓縮:對于相同key的不同value值,只保留最后一個版本。
log.cleanup.policy = compact 所有數據啟用壓縮策略
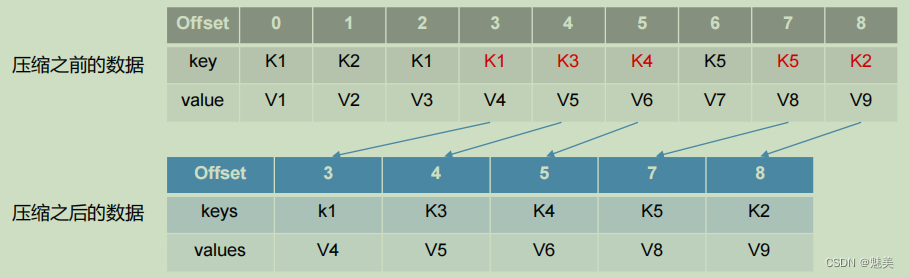
壓縮后的offset可能是不連續的,比如上圖中沒有6,當從這些offset消費消息時,將會拿到比這個offset大的offset對應的消息,實際上會拿到offset為7的消息,并從這個位置開始消費。
這種策略只適合特殊場景,比如消息的key是用戶ID,value是用戶的資料,通過這種壓縮策略,整個消息集里就保存了所有用戶最新的資料。
高效讀寫數據
1)Kafka 本身是分布式集群,可以采用分區技術,并行度高
2)讀數據采用稀疏索引,可以快速定位要消費的數據
3)順序寫磁盤
Kafka 的 producer 生產數據,要寫入到 log 文件中,寫的過程是一直追加到文件末端,為順序寫。官網有數據表明,同樣的磁盤,順序寫能到 600M/s,而隨機寫只有 100K/s。這與磁盤的機械機構有關,順序寫之所以快,是因為其省去了大量磁頭尋址的時間。
4)頁緩存 + 零拷貝技術
零拷貝:Kafka的數據加工處理操作交由Kafka生產者和Kafka消費者處理。Kafka Broker應用層不關心存儲的數據,所以就不用走應用層,傳輸效率高。
PageCache頁緩存:Kafka重度依賴底層操作系統提供的PageCache功 能。當上層有寫操作時,操作系統只是將數據寫入PageCache。當讀操作發生時,先從PageCache中查找,如果找不到,再去磁盤中讀取。實際上PageCache是把盡可能多的空閑內存都當做了磁盤緩存來使用。
| 參數 | 描述 |
|---|---|
| log.flush.interval.messages | 強制頁緩存刷寫到磁盤的條數,默認是 long 的最大值,9223372036854775807。一般不建議修改,交給系統自己管理。 |
| log.flush.interval.ms | 每隔多久,刷數據到磁盤,默認是 null。一般不建議修改,交給系統自己管理。 |
Kafka 消費者
Kafka 消費方式
- pull(拉)模 式:
consumer采用從broker中主動拉取數據。Kafka采用這種方式。 - push(推)模式:
Kafka沒有采用這種方式,因為由broker決定消息發送速率,很難適應所有消費者的消費速率。例如推送的速度是50m/s,Consumer1、Consumer2就來不及處理消息。
pull模式不足之處是,如果Kafka沒有數據,消費者可能會陷入循環中,一直返回空數據。
Kafka 消費者工作流程
消費者總體工作流程
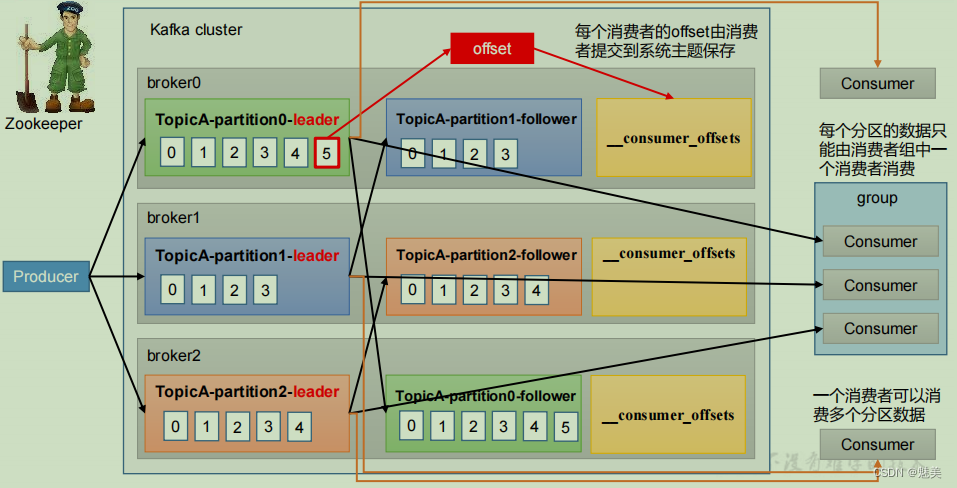
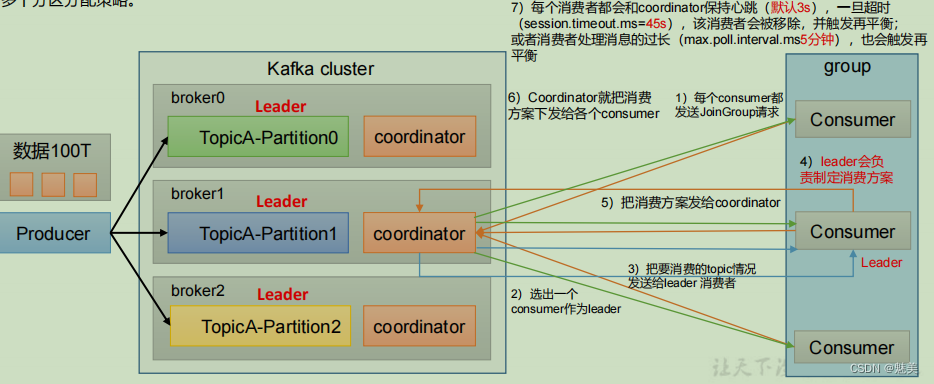
消費者組原理
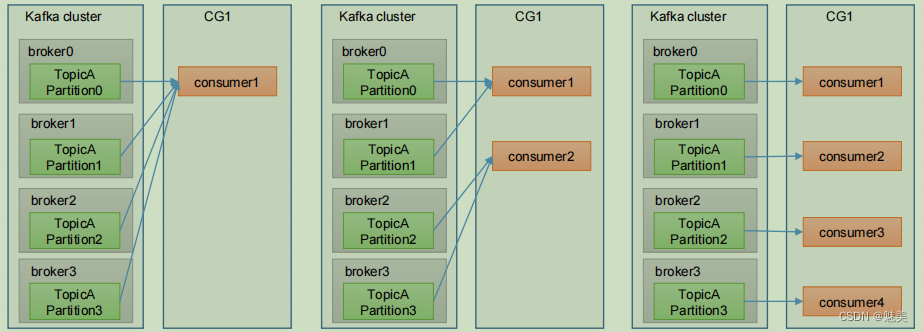
Consumer Group(CG):消費者組,由多個consumer組成。形成一個消費者組的條件,是所有消費者的groupid相同。
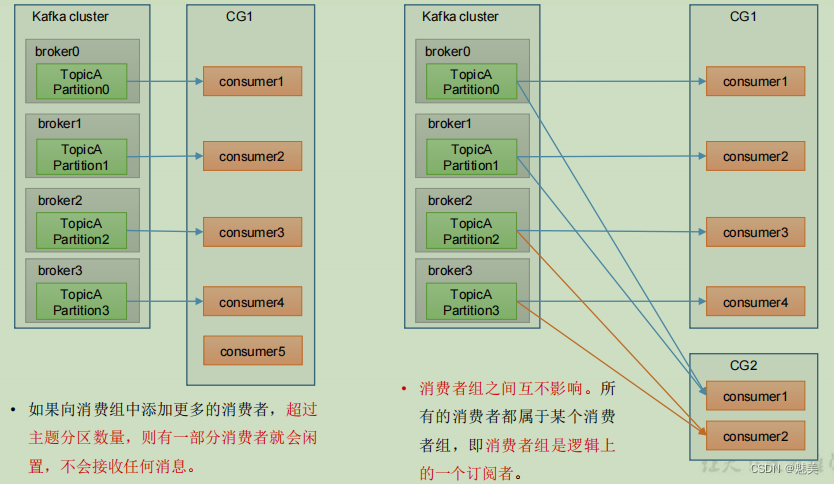
- 消費者組內每個消費者負責消費不同分區的數據,一個分區只能由一個組內消費者消費。
- 消費者組之間互不影響。所有的消費者都屬于某個消費者組,即消費者組是邏輯上的一個訂閱者。
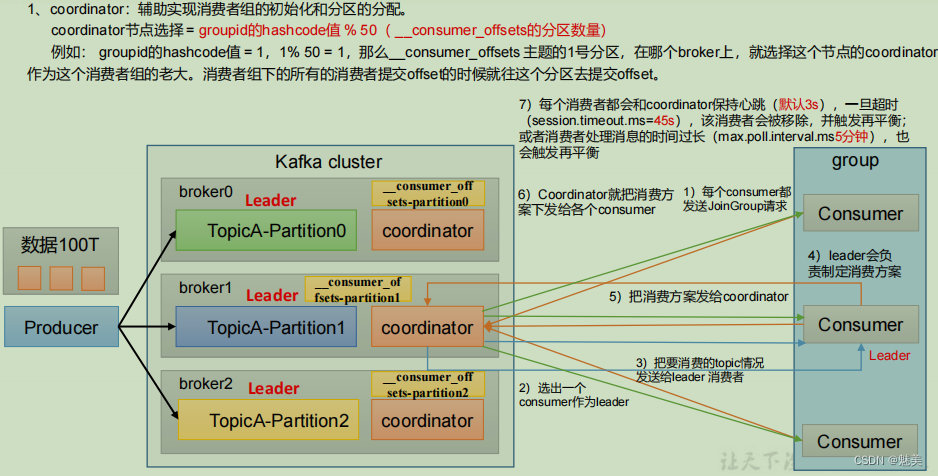
消費者組初始化流程
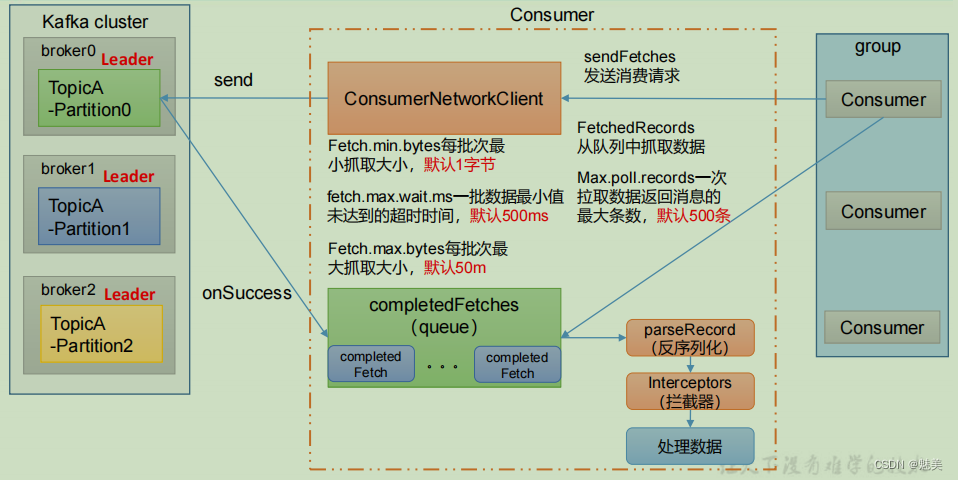
消費者組詳細消費流程
消費者重要參數
| 參數名稱 | 描述 |
|---|---|
| bootstrap.servers | 向 Kafka 集群建立初始連接用到的 host/port 列表。 |
| key.deserializer 和value.deserializer | 指定接收消息的 key 和 value 的反序列化類型。一定要寫全類名。 |
| group.id | 標記消費者所屬的消費者組。 |
| enable.auto.commit | 默認值為 true,消費者會自動周期性地向服務器提交偏移量。 |
| auto.commit.interval.ms | 如果設置了 enable.auto.commit 的值為 true, 則該值定義了消費者偏移量向 Kafka 提交的頻率,默認 5s。 |
| auto.offset.reset | 當 Kafka 中沒有初始偏移量或當前偏移量在服務器中不存在(如,數據被刪除了),該如何處理? earliest:自動重置偏移量到最早的偏移量。 latest:默認,自動重置偏移量為最新的偏移量。 none:如果消費組原來的(previous)偏移量不存在,則向消費者拋異常。 anything:向消費者拋異常。 |
| offsets.topic.num.partitions | __consumer_offsets 的分區數,默認是 50 個分區。 |
| heartbeat.interval.ms | Kafka 消費者和 coordinator 之間的心跳時間,默認 3s。該條目的值必須小于 session.timeout.ms ,也不應該高于session.timeout.ms 的 1/3。 |
| session.timeout.ms | Kafka 消費者和 coordinator 之間連接超時時間,默認 45s。超過該值,該消費者被移除,消費者組執行再平衡。 |
| max.poll.interval.ms | 消費者處理消息的最大時長,默認是 5 分鐘。超過該值,該消費者被移除,消費者組執行再平衡。 |
| fetch.min.bytes | 默認 1 個字節。消費者獲取服務器端一批消息最小的字節數。 |
| fetch.max.wait.ms | 默認 500ms。如果沒有從服務器端獲取到一批數據的最小字節數。該時間到,仍然會返回數據。 |
| fetch.max.bytes | 默認 Default: 52428800(50 m)。消費者獲取服務器端一批消息最大的字節數。如果服務器端一批次的數據大于該值(50m)仍然可以拉取回來這批數據,因此,這不是一個絕對最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影響。 |
| max.poll.records | 一次 poll 拉取數據返回消息的最大條數,默認是 500 條。 |
消費者 API
獨立消費者案例(訂閱主題)
- 1)需求:
創建一個獨立消費者,消費 first 主題中數據。
注意:在消費者 API 代碼中必須配置消費者組 id。命令行啟動消費者不填寫消費者組id 會被自動填寫隨機的消費者組 id。 - 2)實現步驟
(1)創建包名:com.jjm.kafka.consumer
(2)編寫代碼
package com.jjm.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Properties;
public class CustomConsumer {public static void main(String[] args) {// 1.創建消費者的配置對象Properties properties = new Properties();// 2.給消費者配置對象添加參數properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// 配置序列化 必須properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消費者組(組名任意起名) 必須properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test");// 創建消費者對象KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);// 注冊要消費的主題(可以消費多個主題)ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);// 拉取數據打印while (true) {// 設置 1s 中消費一批數據ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));// 打印消費到的數據for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}
}
- 3)測試
(1)在 IDEA 中執行消費者程序。
(2)在 Kafka 集群控制臺,創建 Kafka 生產者,并輸入數據。
[jjm@hadoop102 kafka]$ bin/kafka-console-producer.sh --bootstrap-server hadoop102:9092 --topic first
>hello
(3)在 IDEA 控制臺觀察接收到的數據。
ConsumerRecord(topic = first, partition = 1, leaderEpoch = 3, offset = 0, CreateTime = 1629160841112, serialized key size = -1, serialized value size = 5, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = hello)
生產經驗——分區的分配以及再平衡
1、一個consumer group中有多個consumer組成,一個 topic有多個partition組成,現在的問題是,到底由哪個consumer來消費哪個partition的數據。
2、Kafka有四種主流的分區分配策略: Range、RoundRobin、Sticky、CooperativeSticky。可以通過配置參數partition.assignment.strategy,修改分區的分配策略。默認策略是Range + CooperativeSticky。Kafka可以同時使用多個分區分配策略。
Range 以及再平衡
- 1)Range 分區策略原理
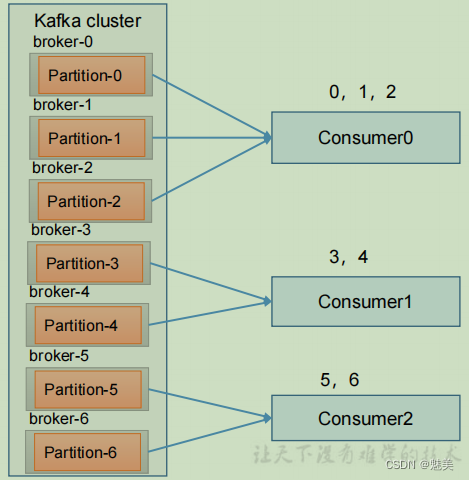
Range 是對每個 topic 而言的。首先對同一個 topic 里面的分區按照序號進行排序,并
對消費者按照字母順序進行排序。
假如現在有 7 個分區,3 個消費者,排序后的分區將會是0,1,2,3,4,5,6;消費者排序完之后將會是C0,C1,C2。
通過 partitions數/consumer數 來決定每個消費者應該消費幾個分區。如果除不盡,那么前面幾個消費者將會多消費 1 個分區。
例如,7/3 = 2 余 1 ,除不盡,那么 消費者 C0 便會多消費 1 個分區。 8/3=2余2,除不盡,那么C0和C1分別多消費一個。
注意:如果只是針對 1 個 topic 而言,C0消費者多消費1個分區影響不是很大。但是如果有 N 多個 topic,那么針對每個 topic,消費者 C0都將多消費 1 個分區,topic越多,C0消費的分區會比其他消費者明顯多消費 N 個分區。
容易產生數據傾斜! - 2)Range 分區分配再平衡案例
(1)停止掉 0 號消費者,快速重新發送消息觀看結果(45s 以內,越快越好)。
1 號消費者:消費到 3、4 號分區數據。
2 號消費者:消費到 5、6 號分區數據。
0 號消費者的任務會整體被分配到 1 號消費者或者 2 號消費者。
說明:0 號消費者掛掉后,消費者組需要按照超時時間 45s 來判斷它是否退出,所以需要等待,時間到了 45s 后,判斷它真的退出就會把任務分配給其他 broker 執行。
(2)再次重新發送消息觀看結果(45s 以后)。
1 號消費者:消費到 0、1、2、3 號分區數據。
2 號消費者:消費到 4、5、6 號分區數據。
說明:消費者 0 已經被踢出消費者組,所以重新按照 range 方式分配。
RoundRobin 以及再平衡
- 1)RoundRobin 分區策略原理
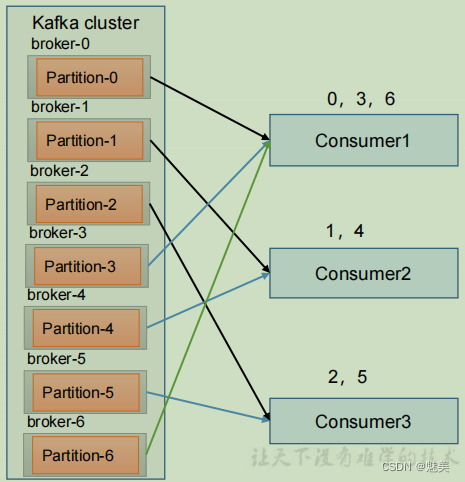
RoundRobin 針對集群中所有Topic而言。
RoundRobin 輪詢分區策略,是把所有的 partition 和所有的consumer 都列出來,然后按照 hashcode 進行排序,最后通過輪詢算法來分配 partition 給到各個消費者。 - 2)RoundRobin 分區分配再平衡案例
(1)停止掉 0 號消費者,快速重新發送消息觀看結果(45s 以內,越快越好)。
1 號消費者:消費到 2、5 號分區數據
2 號消費者:消費到 4、1 號分區數據
0 號消費者的任務會按照 RoundRobin 的方式,把數據輪詢分成 0 、6 和 3 號分區數據,分別由 1 號消費者或者 2 號消費者消費。
說明:0 號消費者掛掉后,消費者組需要按照超時時間 45s 來判斷它是否退出,所以需要等待,時間到了 45s 后,判斷它真的退出就會把任務分配給其他 broker 執行。
(2)再次重新發送消息觀看結果(45s 以后)。
1 號消費者:消費到 0、2、4、6 號分區數據
2 號消費者:消費到 1、3、5 號分區數據
說明:消費者 0 已經被踢出消費者組,所以重新按照 RoundRobin 方式分配。
Sticky 以及再平衡
粘性分區定義:可以理解為分配的結果帶有“粘性的”。即在執行一次新的分配之前,考慮上一次分配的結果,盡量少的調整分配的變動,可以節省大量的開銷。
粘性分區是 Kafka 從 0.11.x 版本開始引入這種分配策略,首先會盡量均衡的放置分區
到消費者上面,在出現同一消費者組內消費者出現問題的時候,會盡量保持原有分配的分區不變化。
1)Sticky 分區分配再平衡案例
(1)停止掉 0 號消費者,快速重新發送消息觀看結果(45s 以內,越快越好)。
1 號消費者:消費到 2、5、3 號分區數據。
2 號消費者:消費到 4、6 號分區數據。
0 號消費者的任務會按照粘性規則,盡可能均衡的隨機分成 0 和 1 號分區數據,分別
由 1 號消費者或者 2 號消費者消費。
說明:0 號消費者掛掉后,消費者組需要按照超時時間 45s 來判斷它是否退出,所以需要等待,時間到了 45s 后,判斷它真的退出就會把任務分配給其他 broker 執行。
(2)再次重新發送消息觀看結果(45s 以后)。
1 號消費者:消費到 2、3、5 號分區數據。
2 號消費者:消費到 0、1、4、6 號分區數據。
說明:消費者 0 已經被踢出消費者組,所以重新按照粘性方式分配。
offset 位移
offset 的默認維護位置
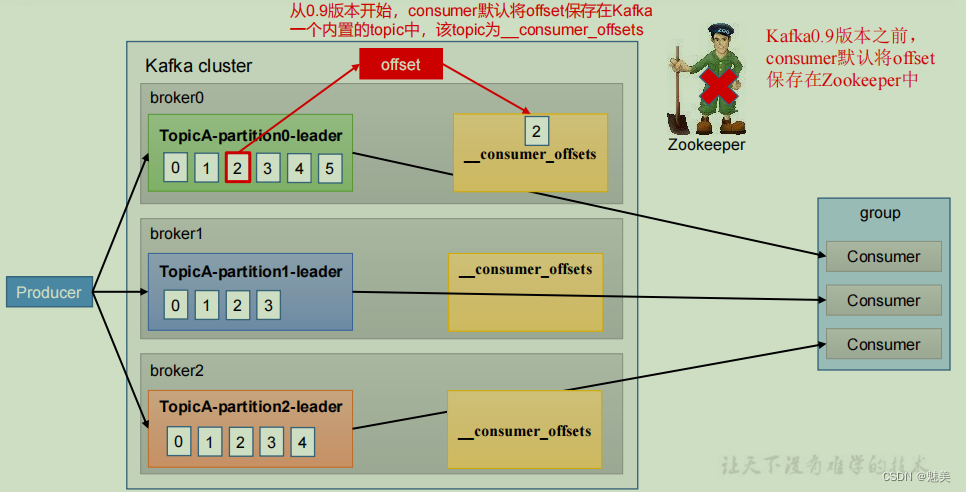
__consumer_offsets 主題里面采用 key 和 value 的方式存儲數據。key 是 group.id+topic+分區號,value 就是當前 offset 的值。每隔一段時間,kafka 內部會對這個 topic 進行compact,也就是每個 group.id+topic+分區號就保留最新數據。
自動提交 offset
為了使我們能夠專注于自己的業務邏輯,Kafka提供了自動提交offset的功能。
自動提交offset的相關參數:
- enable.auto.commit:是否開啟自動提交offset功能,默認是true
- auto.commit.interval.ms:自動提交offset的時間間隔,默認是5s
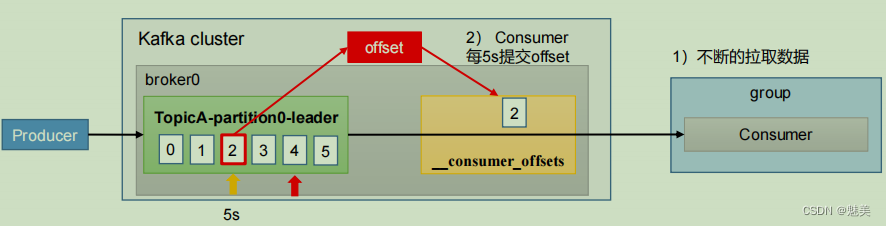
手動提交 offset
雖然自動提交offset十分簡單便利,但由于其是基于時間提交的,開發人員難以把握offset提交的時機。因此Kafka還提供了手動提交offset的API。
手動提交offset的方法有兩種:分別是commitSync(同步提交)和commitAsync(異步提交)。兩者的相同點是,都會將本次提交的一批數據最高的偏移量提交;不同點是,同步提交阻塞當前線程,一直到提交成功,并且會自動失敗重試(由不可控因素導致,也會出現提交失敗);而異步提交則沒有失敗重試機制,故有可能提交失敗。
- commitSync(同步提交):必須等待offset提交完畢,再去消費下一批數據。
- commitAsync(異步提交) :發送完提交offset請求后,就開始消費下一批數據了。
指定 Offset 消費
auto.offset.reset = earliest | latest | none
默認是 latest。
當 Kafka 中沒有初始偏移量(消費者組第一次消費)或服務器上不再存在當前偏移量
時(例如該數據已被刪除),該怎么辦?
(1)earliest:自動將偏移量重置為最早的偏移量,–from-beginning。
(2)latest(默認值):自動將偏移量重置為最新偏移量。
(3)none:如果未找到消費者組的先前偏移量,則向消費者拋出異常。
指定時間消費
需求:在生產環境中,會遇到最近消費的幾個小時數據異常,想重新按照時間消費。
例如要求按照時間消費前一天的數據,怎么處理?
操作步驟:
package com.atguigu.kafka.consumer;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class CustomConsumerForTime {public static void main(String[] args) {// 0 配置信息Properties properties = new Properties();// 連接properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key value 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test2");// 1 創建一個消費者KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 訂閱一個主題ArrayList<String> topics = new ArrayList<>();topics.add("first");kafkaConsumer.subscribe(topics);Set<TopicPartition> assignment = new HashSet<>();while (assignment.size() == 0) {kafkaConsumer.poll(Duration.ofSeconds(1));// 獲取消費者分區分配信息(有了分區分配信息才能開始消費)assignment = kafkaConsumer.assignment();}HashMap<TopicPartition, Long> timestampToSearch = new HashMap<>();// 封裝集合存儲,每個分區對應一天前的數據for (TopicPartition topicPartition : assignment) {timestampToSearch.put(topicPartition, System.currentTimeMillis() - 1 * 24 * 3600 * 1000);}// 獲取從 1 天前開始消費的每個分區的 offsetMap<TopicPartition, OffsetAndTimestamp> offsets = kafkaConsumer.offsetsForTimes(timestampToSearch);// 遍歷每個分區,對每個分區設置消費時間。for (TopicPartition topicPartition : assignment) {OffsetAndTimestamp offsetAndTimestamp = offsets.get(topicPartition);// 根據時間指定開始消費的位置if (offsetAndTimestamp != null){kafkaConsumer.seek(topicPartition, offsetAndTimestamp.offset());}}// 3 消費該主題數據while (true) {ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}}
}
漏消費和重復消費
重復消費:已經消費了數據,但是 offset 沒提交。
漏消費:先提交 offset 后消費,有可能會造成數據的漏消費。
(1)場景1:重復消費。自動提交offset引起。

(2)場景1:漏消費。設置offset為手動提交,當offset被提交時,數據還在內存中未落盤,此時剛好消費者線程被kill掉,那么offset已經提交,但是數據未處理,導致這部分內存中的數據丟失。

思考:怎么能做到既不漏消費也不重復消費呢?詳看消費者事務。
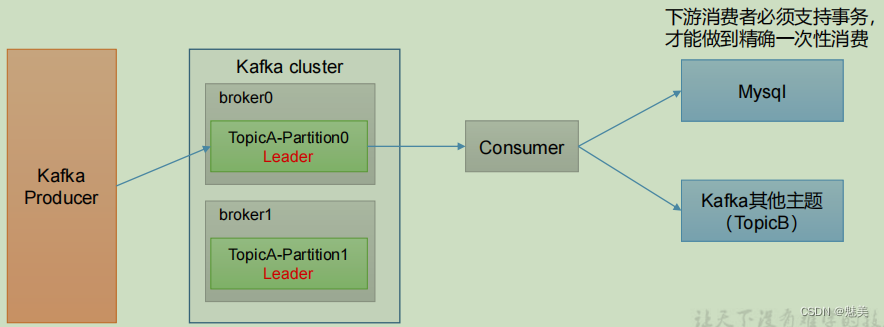
生產經驗——消費者事務
如果想完成Consumer端的精準一次性消費,那么需要Kafka消費端將消費過程和提交offset過程做原子綁定。此時我們需要將Kafka的offset保存到支持事務的自定義介質(比如MySQL)。
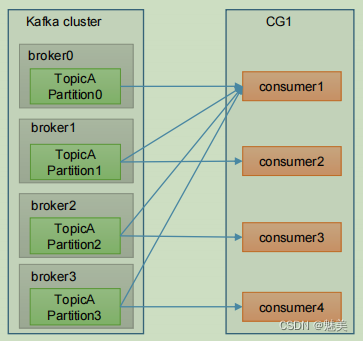
生產經驗——數據積壓(消費者如何提高吞吐量)
1)如果是Kafka消費能力不足,則可以考慮增加Topic的分區數,并且同時提升消費組的消費者數量,消費者數 = 分區數。(兩者缺一不可)
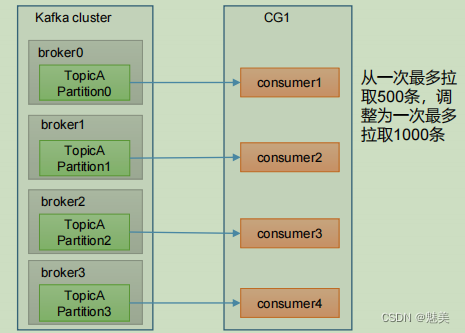
2)如果是下游的數據處理不及時:提高每批次拉取的數量。批次拉取數據過少(拉取數據/處理時間 < 生產速度),使處理的數據小于生產的數據,也會造成數據積壓。
| 參數名稱 | 描述 |
|---|---|
| fetch.max.bytes | 默認 Default: 52428800(50 m)。消費者獲取服務器端一批消息最大的字節數。如果服務器端一批次的數據大于該值(50m)仍然可以拉取回來這批數據,因此,這不是一個絕對最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影響。 |
| max.poll.records | 一次 poll 拉取數據返回消息的最大條數,默認是 500 條 |
)


















