
目錄
翻譯環境和運行環境
翻譯環境
預處理(預編譯)
編譯
詞法分析
語法分析
?語義分析
匯編
鏈接
運行環境

?翻譯環境和運行環境
在ANSI C的任何?種實現中,存在兩個不同的環境。
- 第1種是翻譯環境,在這個環境中源代碼被轉換為可執行的機器指令。
- 第2種是運行環境,它用于實際執行代碼。

可執行程序中存儲的是二進制指令(機器指令)
?翻譯環境
那翻譯環境是怎么將源代碼轉換為可執行的機器指令的呢?這里我們就得展開開講解?下翻譯環境所做的事情。
其實翻譯環境是由編譯和鏈接兩個大的過程組成的,而編譯?可以分解成:預處理(有些書也叫預編譯)、編譯、匯編三個過程。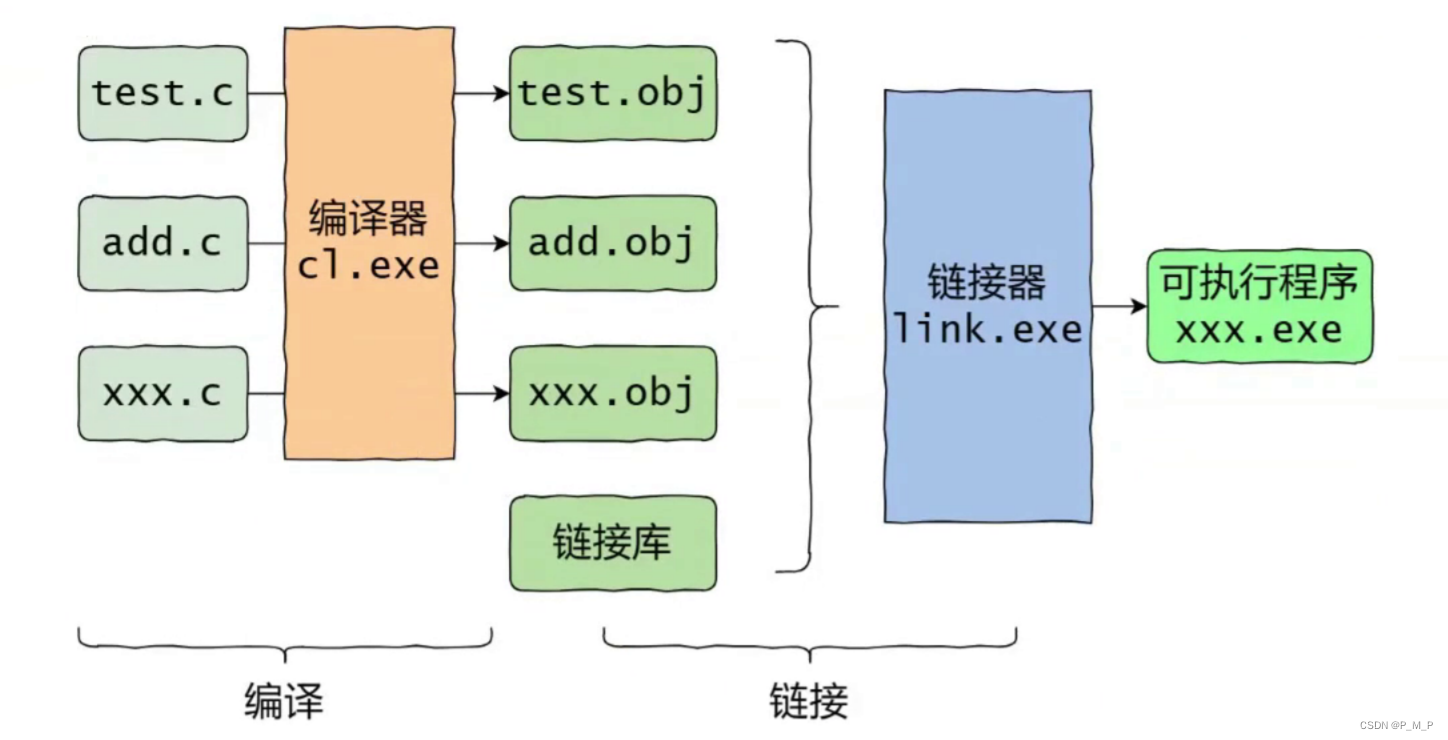
?個C語言的項目中可能有多個.c文件?起構建,那多個.c文件如何生成可執行程序呢?
- 多個.c文件單獨經過編譯器,編譯處理生成對應的目標文件(后綴為.obj)。
- 注:在Windows環境下的目標文件的后綴是.obj,Linux環境下目標文件的后綴是.o
- 多個目標文件和鏈接庫?起經過鏈接器處理生成最終的可執行程序。
- 鏈接庫是指運行時庫(它是支持程序運行的基本函數集合)或者第三方庫。
?
如果再把編譯器展開成3個過程,那就變成了下面的過程:
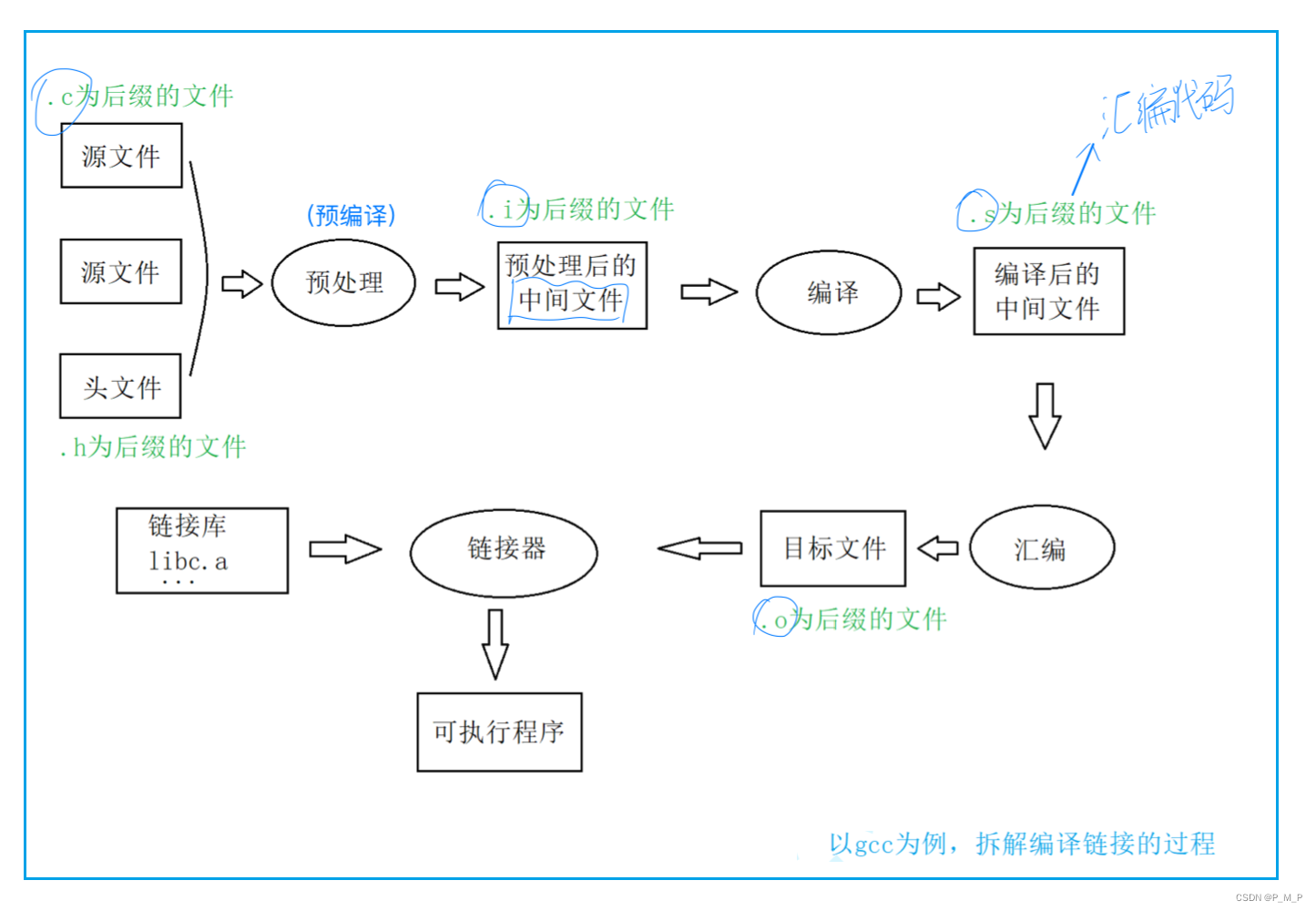
🏲預處理(預編譯)
在預處理階段,源文件和頭文件會被處理成為.i為后綴的文件。
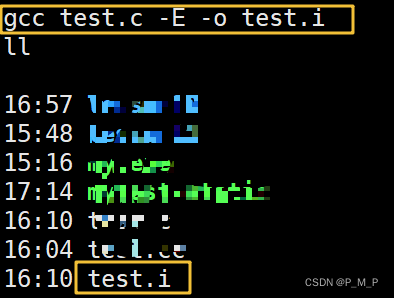
在(Linux) gcc 環境下想觀察一下,對 test.c 文件預處理后的.i 文件,命令如下:
- gcc -E test.c -o test.i

預處理階段主要處理那些源文件中#開始的預編譯指令。比如:#include,#define,處理的規則如下:
- 將所有的#define刪除,并展開所有的宏定義。
- 處理所有的條件編譯指令,如: #if、#ifdef、#elif、#else、#endif 。
- 處理#include預編譯指令,將包含的頭文件的內容插入到該預編譯指令的位置。這個過程是遞歸進行的,也就是說被包含的頭文也可能包含其他文件。
- 刪除所有的注釋
- 添加行號和文件名標識,方便后續編譯器生成調試信息等。
- 或保留所有的#pragma的編譯器指令,編譯器后續會使用。
經過預處理后的 .i 文件中不再包含宏定義,因為宏已經被展開(替換)。并且包含的頭文件都被插入到 .i 文件中。所以當我們無法知道宏定義或者頭文件是否包含正確的時候,可以查看預處理后的 .i 文件來確認。
🏲編譯
編譯過程就是將預處理后的文件進行?系列的:詞法分析、語法分析、語義分析及優化,生成相應的匯編代碼文件。
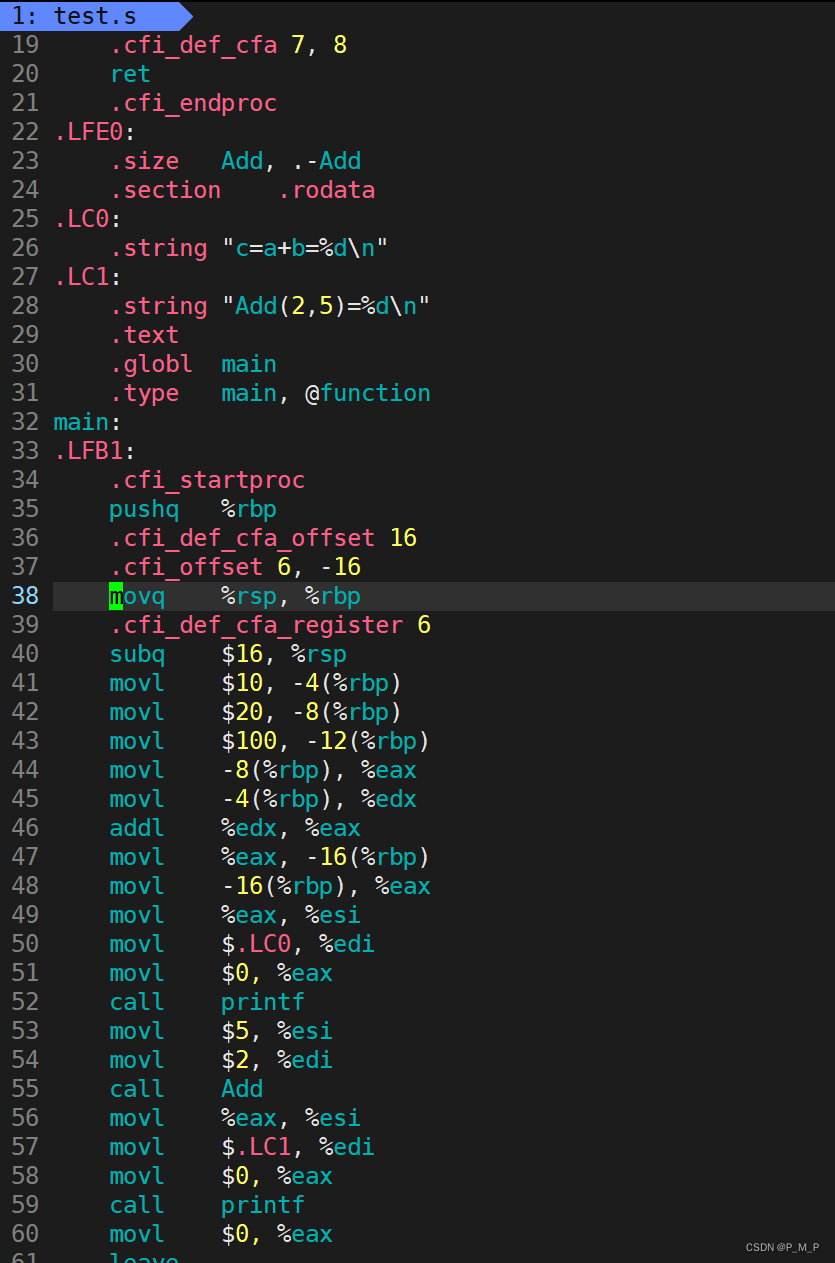
編譯過程的命令如下:
gcc -S test.i -o test.s
對下面代碼進行編譯的時候,會怎么做呢?假設有下面的代碼
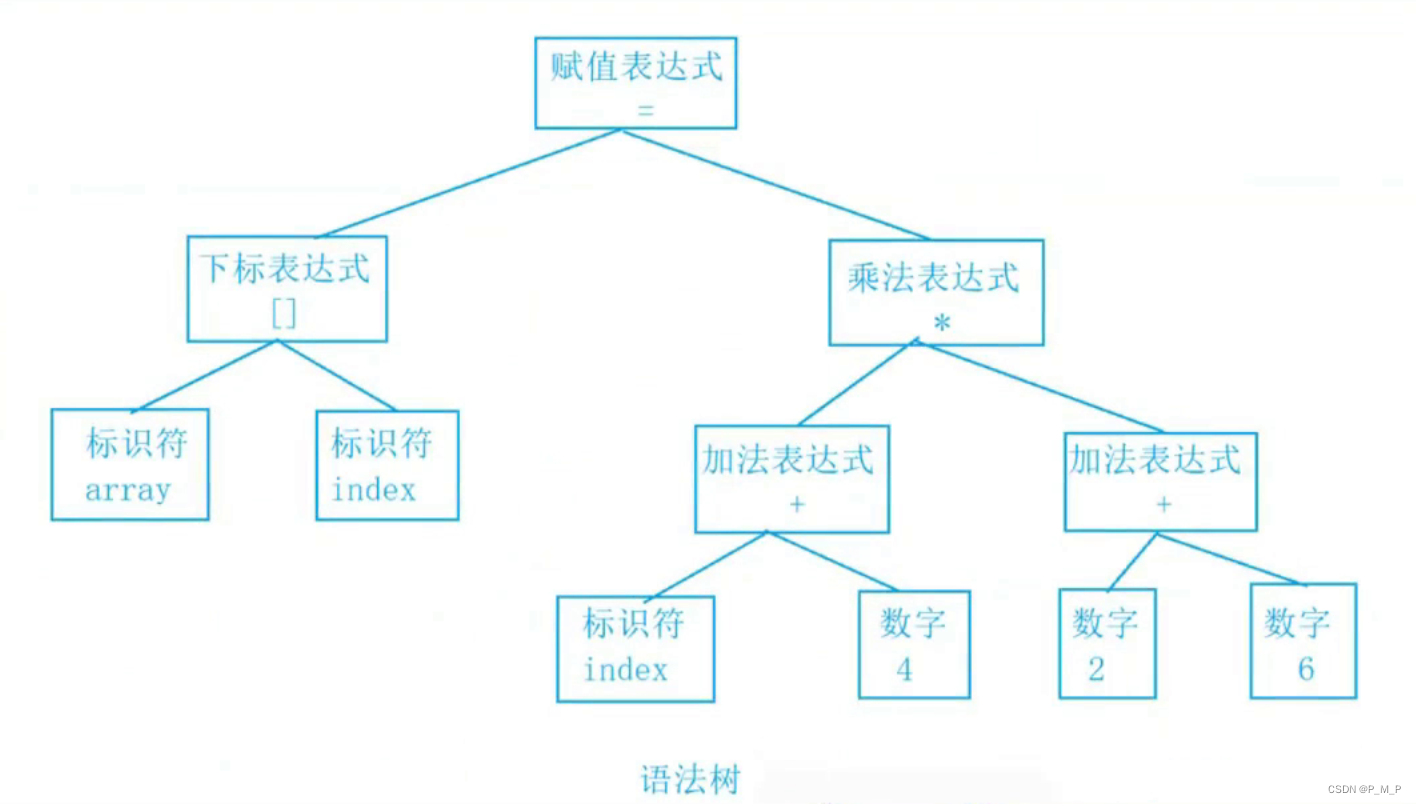
array[index] = (index+4)*(2+6);?詞法分析
將源代碼程序被輸入掃描器,掃描器的任務就是簡單的進行詞法分析,把代碼中的字符分割成?系列的記號(關鍵字、標識符、字?量、特殊字符等)。
array[index] = (index+4)*(2+6);上面程序進行詞法分析后得到了16個記號:
| 記號 | 類型 |
| array | 標識符 |
| [ | 左方括號 |
| index | 標識符 |
| ] | 右方括號 |
| = | 賦值 |
| ( | 左圓括號 |
| index | 標識符 |
| + | 加號 |
| 4 | 數字 |
| ) | 右圓括號 |
| * | 乘號 |
| ( | 左圓括號 |
| 2 | 數字 |
| + | 加號 |
| 6 | 數字 |
| ) | 右圓括號 |
?語法分析
接下來語法分析器,將對掃描產生的記號進行語法分析,從而產生語法樹。這些語法樹是以表達式為節點的樹。
??語義分析
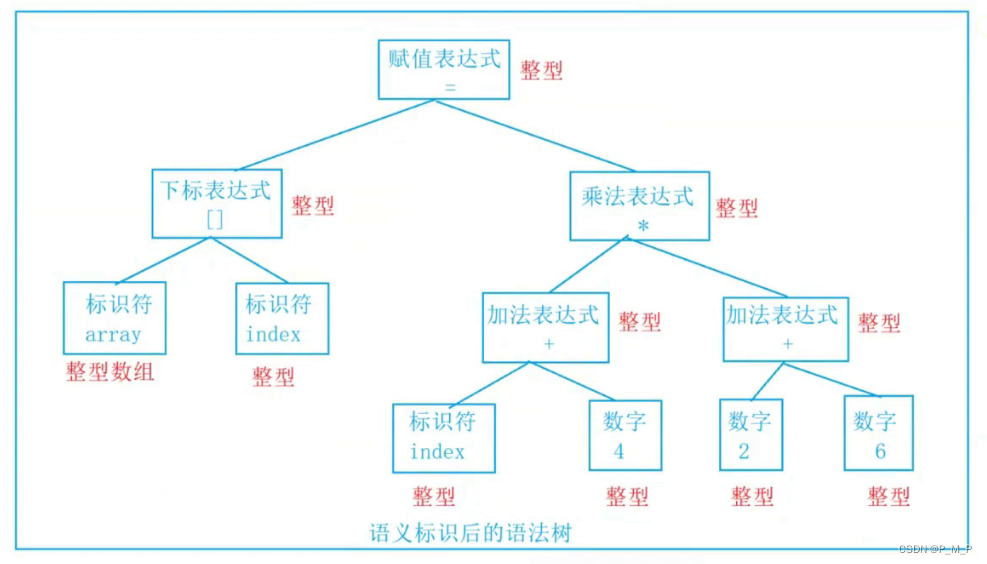
由語義分析器來完成語義分析,即對表達式的語法層?分析。編譯器所能做的分析是語義的靜態分
析。靜態語義分析通常包括聲明和類型的匹配,類型的轉換等。這個階段會報告錯誤的語法信息。
🏲匯編
匯編器是將匯編代碼轉轉變成機器可執行的指令,每?個匯編語句幾乎都對應?條機器指令。就是根據匯編指令和機器指令的對照表??地進行翻譯,翻譯成機器語言(二進制指令),也不做指令優化。
匯編的命令如下:
gcc -c test.s -o test.o
?因為編輯器格式不匹配,所以這些二進制指令展示出來的是亂碼。
🏲鏈接
鏈接是?個復雜的過程,鏈接的時候需要把?堆文件鏈接在?起才生成可執行程序。
鏈接過程主要包括:地址和空間分配,符號決議和重定位等這些步驟。
鏈接解決的是?個項目中多文件、多模塊之間互相調用的問題。
比如:
在?個C的項目中有2個.c文件( test.c 和?add.c ),代碼如下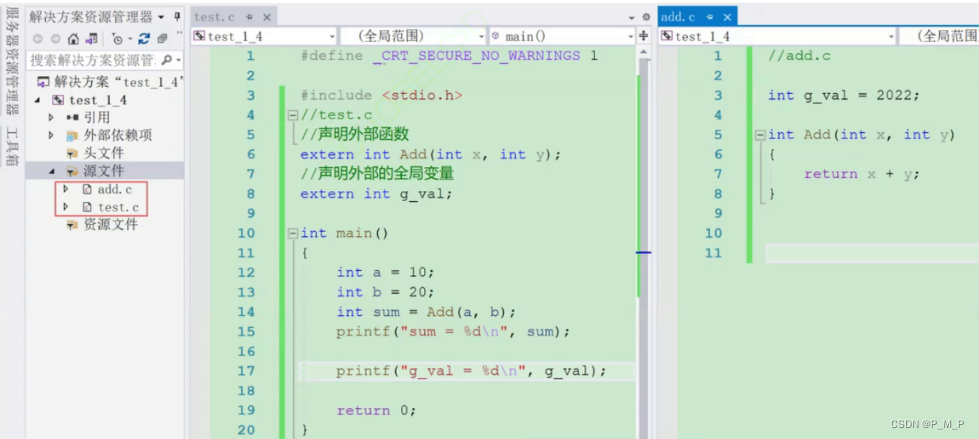
test.c 經過編譯器處理生成 test.o?
add.c 經過編譯器處理生成?add.o?
我們在 test.c 的文件中使用了 add.c 文件中的 Add 函數和 g_val 變量。
我們在 test.c 文件中每一次使用?Add 函數和 g_val變量?的時候必須確切的知道 Add 和 g_val 的地址,但是由于每個文件是單獨編譯的,在編譯器編譯 test.c 的時候并不知道 Add 函數和 g_val變量的地址,所以暫時把調用?Add 的指令的目標地址和 g_val 的地址擱置。等待最后鏈接的時候由鏈接器根據引用的符號 Add 在其他模塊中查找 Add 函數的地址,然后將 test.c 中所有引用到Add 的指令重新修正,讓他們的目標地址為真正的 Add 函數的地址,對于全局變量 g_val 也是類似的方法來修正地址。這個地址修正的過程也被叫做:重定位
在編譯階段,每個.c文件都會生成一個符號表,然后在鏈接的時候進行匯總。

?運行環境
- 程序必須載入內存中。在有操作系統的環境中:?般這個由操作系統完成。在獨立的環境中,程序的載入必須由手動安排,也可能是通過可執行代碼置入只讀內存來完成。
- 程序的執行便開始。接著便調用main函數。
- 開始執行程序代碼。這個時候程序將使用?個運行時堆棧(stack),存儲函數的局部變量和返回地址。程序同時也可以使用靜態(static)內存,存儲于靜態內存中的變量在程序的整個執行過程?直保留他們的值。
- 終止程序。正常終止main函數;也有可能是意外終止。
?
____________________
?感謝你的閱讀,希望本文能夠對你有所幫助。如果你喜歡我的內容,記得點贊關注收藏我的博客,我會繼續分享更多的內容。?
)











![[每周一更]-(第88期):Nginx 之 proxy_pass使用詳解](http://pic.xiahunao.cn/[每周一更]-(第88期):Nginx 之 proxy_pass使用詳解)






