基于AdaBoost算法的情感分析研究
摘 要
- 隨著互聯網的快速發展,各類社交媒體平臺如微信、QQ等也與日俱增,而微博更是集成了傳統網站、論壇、博客等的優點,并加上了人與人之間的互動性、關系親密程度等多種智能算法,并以簡練的形式讓數據爆發性的傳播,促進了人與人之間的交流。網民可以通過微博來分享自己的生活,同時抒發自己的喜怒哀樂。因此對微博每天產生的信息量的分析和利用的需求顯得更為迫切。
- 情感分析,也稱傾向性分析、意見抽取和意見挖掘。主要是通過對帶有情感色彩的主觀性文本進行分析、處理、歸納然后進行推理的過程。而微博,人口基數大,涉及的話題廣泛,對人們的日常生活產生了不可估量的影響,而對微博的情感分析,更是有著十分重要的意義。為此,本文針對了微博文本的情感分析進行了如下幾個工作。
- 首先,使用微博官方的API對微博進行抓取,進行分類標注。然后,對微博文本進行預處理,主要包括去掉無意義,對微博文本沒有影響的詞語。其次,使用SVM算法對文本進行初步的篩選,主要是去除特別明顯的廣告等無關性的微博。最后使用樸素貝葉斯對微博進行情感分析,將微博分為積極、消極、客觀三類,同時使用AdaBoost算法對樸素貝葉斯算法進行加強。
這些帶有情感信息的微博是非常寶貴的資源,通過情感分析可以獲取網民的此時的心情,對某個事件或事物的看法,可以挖掘其潛在的商業價值,還能對社會的穩定做出一定的貢獻。
關鍵詞:情感分析 AdaBoost 樸素貝葉斯 文本分類 數據挖掘
大致流程和原理。
一、獲取微博文本:
該部分主要使用微博應用獲取微博文本,獲取到的文本可以用于后續的分類和情感分析等。
2.3.2 模擬登錄
由于微博中的接口需要獲取權限,所以需要手動截取token,比如鏈接中:https://api.weibo.com/oauth2/authorize?code=7dded6d1b81bdc341cc75d585b566492
鏈接的token就是code=7dded6d1b81bdc341cc75d585b566492。本文將采用模擬登陸微博并獲取token后直接調用接口的方法,省去了手動輸入的麻煩。
2.3.3 微博抓取與存儲
使用官方的python sdk,然后使用statuses/public_timeline的接口一次性獲取200條微博。其連接代碼如下:
json_str = client.get(‘statuses/public_timeline’, uid=uuid, separators=(‘,’, ‘:’), count=200)
由于服務器返回的格式是json的,所以將json中所需要的key和value存儲入數據庫即可。
二、SVM初步分類:
該部分使用支持向量機(SVM)模型對微博文本進行初步分類,將文本分為積極、消極和中立三類,以便進行后續的情感分析。
三、使用樸素貝葉斯分類:
該部分使用樸素貝葉斯分類器對微博文本進行情感分析,將文本劃分為積極或消極兩類,并得出相應的概率值。
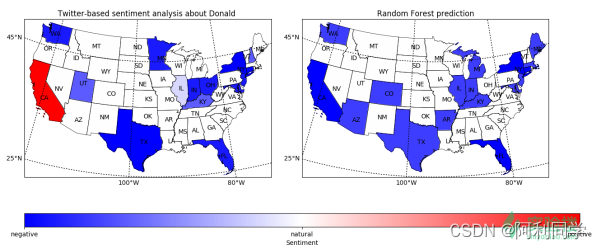
圖1.3 每個州對川普的情感
四、AdaBoost:
該部分是一種集成學習方法,將多個弱分類器組合成一個強分類器。主要包括二分類AdaBoost和多分類AdaBoost兩種方法:
4.1 二分類AdaBoost:
該方法主要用于解決二分類問題,通過多次迭代訓練多個弱分類器,每次迭代都會調整數據權重,使得之前分類錯誤的數據更容易被正確分類。最終將多個弱分類器加權組合成一個強分類器來進行分類預測。
4.2 多分類AdaBoost:
該方法主要用于解決多分類問題,包括AdaBoost.SAMME和AdaBoost.SAMME.R兩種方法。
import re
word="jofwjoifA級哦啊接我金佛安fewfae慰劑serge"
p = re.compile(r'\w', re.L)
result = p.sub("", word)
print(result)
4.2.1 AdaBoost.SAMME:
該方法基于AdaBoost算法,通過多次迭代訓練多個弱分類器,并根據錯誤率對每個分類器進行加權。最終將多個弱分類器加權組合成一個強分類器,用于多分類預測。
4.2.2 AdaBoost.SAMME.R:
該方法與AdaBoost.SAMME類似,但是在每次迭代中會更新數據的權重,同時還會更新每個分類器的輸出權重。最終將多個弱分類器加權組合成一個強分類器,用于多分類預測。
圖2.1 申請微博應用
運行
運行環境
[anaconda: 3.5+]https://www.anaconda.com/
本文項目流程
一、 使用微博應用獲取微博文本
二、 SVM初步分類(svm_temp.py)
三、 利用貝葉斯定理進行情感分析
四、 利用AdaBoost加強分類器





編程——逆向分析向)



)

)







