
前言
本文講解了從零開始學習Python數據科學的全過程,涵蓋各種工具和方法
你將會學習到如何使用python做基本的數據分析
你還可以了解機器學習算法的原理和使用
說明
先說一段題外話。我是一名數據科學家,在用SAS做分析超過5年后,我決定走出舒適區,尋找其它有效的數據分析工具,很快我發現了Python!
我非常喜歡編程,這是我真正喜歡做的事情。事實證明,編程并沒有想象中的那么難。
我在一周之內學習了Python的基本語法,接著我一方面繼續深入探索Python,另一方面我幫助其他人學習這門語言。Python最初是一門簡單的腳本語言,但隨著Python社區的不斷發展壯大,越來越多的開發者參與到Python工具庫開發中來,所以Python擁有了極其豐富的數據分析和挖掘第三方庫。
內容目錄
1、Python數據分析的基本概況
為何使用Python做數據分析?
Python2.7還是Python3.7?
如何安裝Python?
使用Python運行一段簡單的代碼
如何使用Jupyter notebook
2、Python數據結構和庫
Python數據結構
Python循環結構和判斷語句
Python庫
3、使用Pandas做探索性分析
Series和DataFrame數據結構介紹
具體數據集案例分析
4、Numpy基本概念
Numpy常見函數使用
5、使用Pandas和numpy做數據清洗
處理數據集中的空值
如何使用apply方法?
6、使用Matplotlib繪制圖表
Matplotlib介紹
使用Matplotlib繪制簡單的柱狀圖
7、使用Scikit-learn建立預測模型
邏輯回歸算法
決策樹算法
隨機森林算法
1、Python數據分析的基本概況
為何使用Python做數據分析?
最近幾年,Python用作數據分析語言引起了非常多的關注,一度超越R成為最受歡迎的數據科學工具。作為Python的使用者,我支持Python作為數據分析工具有以下理由:
開源-免費安裝使用
語言簡潔,是一門真正的強大的編程語言
非常強大的在線社區
學習門檻低
極其豐富的第三方數據科學庫
但它也有一些缺點:
Python是一種解釋性語言而非編譯性,速度相對比較慢。但是考慮到在學習和代碼上節省的時間,Python依然是不二的選擇。
Python 2.7還是Python 3.7?
很多初學者還在糾結選擇Python 2.7還是Python 3.7?這兩個版本有非常大的差異,簡直就是兩種語言。它們各有各的優缺點,取決于你使用的需求。
為什么Python 2.7
絕對優勢的社區支持!Python 2.x誕生于2000年,已經被使用快20年,許多公司依然在使用Python 2.7
豐富的第三方庫!目前絕大部分第三方庫都是建立在Python 2.x基礎上的,很多庫并不支持Python 3.x版本。如果你將Python用于特定的應用程序,如高度依賴外部模塊的web開發,那么建議使用Python 2.7
為什么Python 3.7
語法更加簡潔和快速。Python開發人員改進了Python 2.x的缺點,Python 3.x代表了Python未來發展的方向
Python 2.7 只維護到2020年
Python官方建議直接學習Python 3.x
如果將Python作為數據科學工具,我建議使用Python 3.x,因為基本上所有的數據科學第三方庫都已經支持Python 3.x。當然選擇哪一個版本不是目的,應當專注的是如何使用Python更好地服務于數據科學。
如何安裝Python?
這里兩種安裝方法可供參考:
直接去Python官網下載Python3.7安裝包,再選擇安裝自己需要的第三方庫和編輯器
或者,你不想這么麻煩,你可以選擇安裝Anaconda,這是一個開源的Python發行版本,其預裝了180多個第三方庫和依賴包
第二種方法包含了數據科學用到的大部分工具包,為你省去很多安裝時間。這也是本教程建議初學者使用的安裝方法 。
選擇Python開發環境
一旦你安裝好了python,就需要選擇開發環境用于Python編程,這里有四個常用選擇:
終端交互模式
IDLE(默認環境)
其它IDE,如pycharm
Jupyter notebook(ipython)
這里不對它們作具體比較,讀者可自行上網查詢,選擇什么樣的開發環境取決于你的需求。
我建議初學者使用Jupyter notebook(ipython)作為Python數據分析的開發環境。Jupyter Notebook 是一個交互式筆記本,本質是一個 Web 應用程序,便于創建和共享程序文檔,支持實時代碼,數學方程,可視化和markdown。用途包括:數據清理和轉換,數值模擬,統計建模,機器學習等等。數據挖掘領域中最熱門的比賽 Kaggle 里的資料都是Jupyter 格式。
本教程也是使用Jupyter Notebook 作為代碼環境。
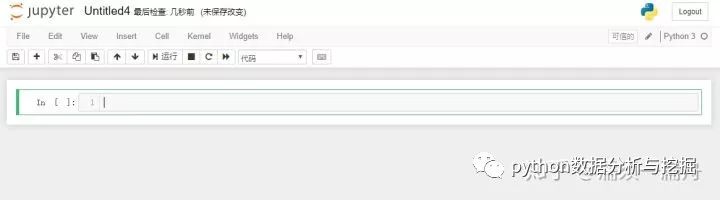
使用Python運行一段簡單的代碼
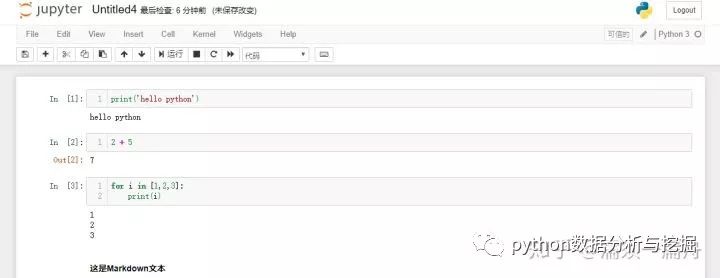
如何使用Jupyter Notebook
Anaconda預裝了Jupyter Notebook庫,所以安裝Anaconda后就可以直接使用Jupyter Notebook。
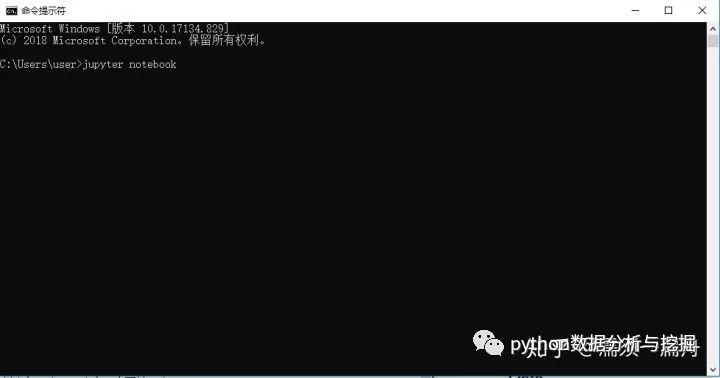
啟動Jupyter Notebook有兩種方法,你可以在命令行中鍵入jupyter notebook再按enter鍵,便可以進入Jupyter Notebook環境,記住不要關閉命令行窗口,否則Jupyter環境會失效。
還可以在開始菜單Anaconda文件夾中直接雙擊Jupyter Notebook
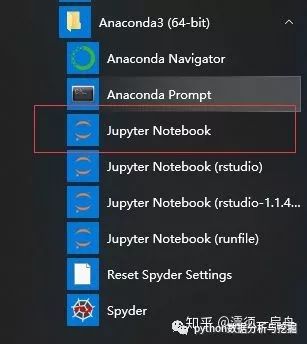
然后進入Jupyter Notebook主界面,點擊New新建,點擊Python 3,就可以開始愉快的編程了。

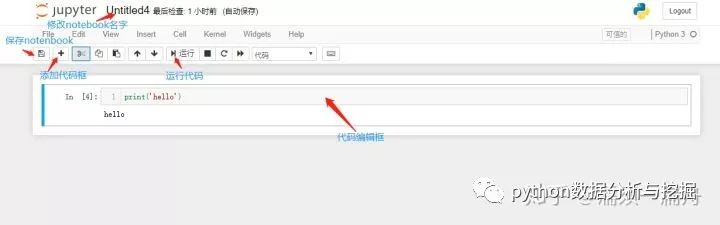
你可以修改該notebook的名字,添加或刪除代碼編輯框,使用“Shift + Enter” 或者“Ctrl + Enter”快捷鍵運行代碼。具體功能快捷鍵這里不做贅述,可以去Jupyter Notebook 快捷鍵?查看。
2、Python數據結構和庫
Python數據結構
接下來要講到Python的數據結構,你應該盡可能熟悉它,因為在接下來的數據分析代碼中會經常用到這些數據結構。
字符串
Python 可以操作字符串。字符串有多種形式,可以使用單引號('……'),雙引號("……")都可以獲得同樣的結果2。反斜杠\可以用來轉義:

列表
Python 中可以通過組合一些值得到多種復合數據類型。其中最常用的列表,可以通過方括號括起、逗號分隔的一組值得到。一個列表可以包含不同類型的元素,但通常使用時各個元素類型相同:
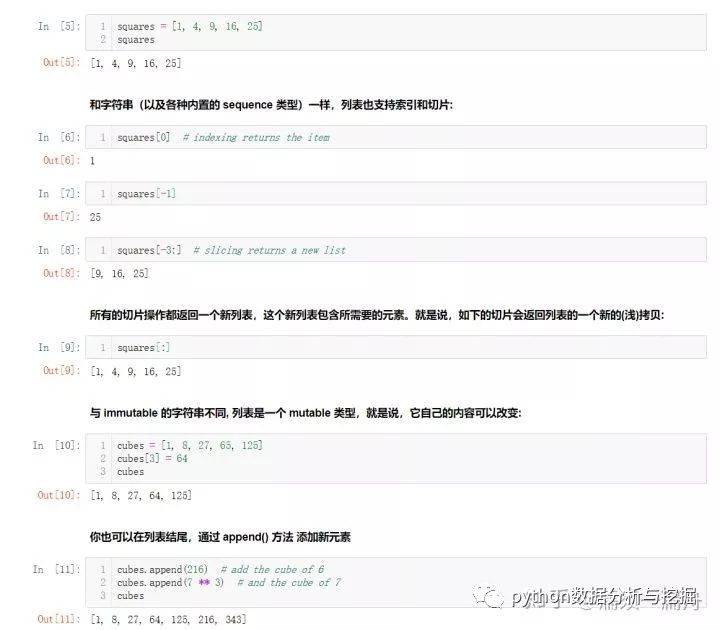
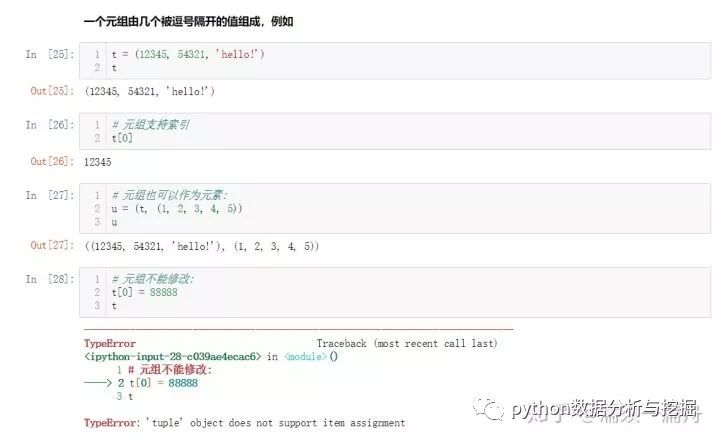
元組
可以看到列表和字符串有很多共同特性,例如索引和切片操作。Python的元組與列表類似,不同之處在于元組的元素不能修改。元組使用小括號,列表使用方括號。元組創建很簡單,只需要在括號中添加元素,并使用逗號隔開即可。
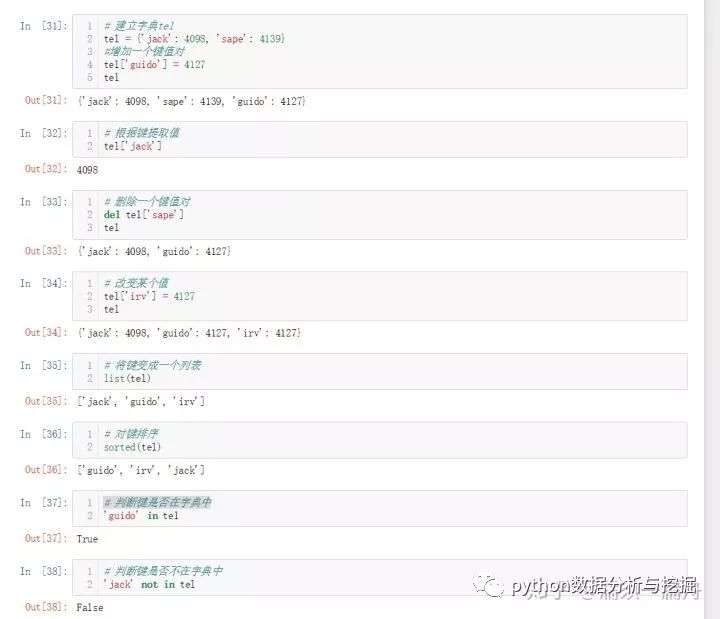
字典
另一個非常有用的 Python 內置數據類型是字典。字典在其他語言里可能會被叫做?聯合內存?或?聯合數組。與以連續整數為索引的序列不同,字典是以?關鍵字?為索引的,關鍵字可以是任意不可變類型,通常是字符串或數字。如果一個元組只包含字符串、數字或元組,那么這個元組也可以用作關鍵字。但如果元組直接或間接地包含了可變對象,那么它就不能用作關鍵字。列表不能用作關鍵字,因為列表可以通過索引、切片或?append()?和?extend()?之類的方法來改變。
理解字典的最好方式,就是將它看做是一個?鍵: 值?對的集合,鍵必須是唯一的(在一個字典中)。一對花括號可以創建一個空字典:{}?。另一種初始化字典的方式是在一對花括號里放置一些以逗號分隔的鍵值對,而這也是字典輸出的方式。
以下是使用字典的一些簡單示例:
Python循環結構和判斷語句
for循環
和大多數編程語言一樣,Python也有for循環結構,其被廣泛使用在迭代方法中。
Python 中的for語句與你在 C 或 Pascal 中可能用到的有所不同。Python 中的for語句并不總是對算術遞增的數值進行迭代(如同 Pascal),或是給予用戶定義迭代步驟和暫停條件的能力(如同 C),而是對任意序列進行迭代(例如列表或字符串),條目的迭代順序與它們在序列中出現的順序一致。

如果在循環內需要修改序列中的值(比如重復某些選中的元素),推薦你先拷貝一份副本。對序列進行循環不代表制作了一個副本進行操作。切片操作使這件事非常簡單:

如果寫成for w in words:,這個示例就會創建無限長的列表,一次又一次重復地插入defenestrate。
range函數
如果你確實需要遍歷一個數字序列,內置函數range()會派上用場。它生成算術級數:

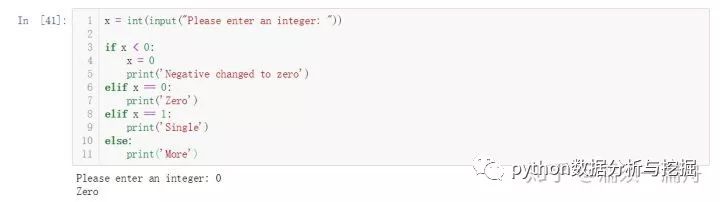
if判斷語句
可能最為人所熟知的編程語句就是if語句了,這是python中的判斷語句。
使用形式為if ... elif ... else ...
可以有零個或多個elif部分,以及一個可選的else部分。關鍵字 'elif' 是 'else if' 的縮寫,適合用于避免過多的縮進。一個if...elif...elif... 序列可以看作是其他語言中的switch或case語句的替代。
現在你熟悉了Python中的循環結構和判斷語句,可以更進一步去學習更多的語法知識。
如果每做一件事都需要從頭開始寫代碼,那么這將是一場噩夢,比如你想要對一個列表里數字進行加法運算,難道還要一個一個數字加起來嗎?這樣的話,你肯定不想學習python了。慶幸的是,python有很多工具庫,可以幫助我們更加直接有效地解決問題。
例如,求數學中的階乘,你可以很簡單的導入math模塊,使用已經編譯好的階乘函數:

當然在使用函數之前,你必須要導入庫和函數。話不多說,一起來探索更多的Python庫吧!
Python庫
在學習更酷炫實用的Python庫之前,第一步要知道什么是Python庫。
Python庫是一個相關功能模塊的集合,里面包含各種函數方法,用來解決復雜的問題。
這些庫分為兩類:標準庫和第三方庫,標準庫是Python內置庫,無需再安裝,如math、range;第三方庫需要另外安裝,如jupyter、pandas、numpy
安裝第三方庫
安裝第三方庫有兩種方法,第一種是pip方法,pip是Python包管理工具,自帶無需安裝,提供了對Python 庫的查找、下載、安裝、卸載的功能。
如果想安裝pandas庫,你可以在命令行輸入:
pip install pandas接下來等待自行下載安裝。
第二種是手動安裝,在python庫集合里下載相關庫文件并安裝。
導入庫和庫函數
使用庫之前,需要將其導入Python環境。同樣有兩種方法可以做到(以math庫為例):
import math或者
from math import *第一種方法,導入整個庫,如果你需要使用庫中的某個函數,比如階乘函數factorial,那么,需要用math.factorial()形式。
第二種方法直接導入了math庫的所有方法和函數,直接factorial()就可以了。
建議使用第一種方法,用什么導入什么,不浪費。
最常用的數據科學庫列表
numpy:它是一個由多維數組對象和用于處理數組的例程集合組成的庫,里面包含了大量的計算函數,可以很輕松的進行科學計算。
scipy:科學計算的另一個核心庫是 SciPy。它基于 NumPy,其功能也因此得到了擴展。SciPy 主數據結構又是一個多維數組,由 Numpy 實現。這個軟件包包含了幫助解決線性代數、概率論、積分計算和許多其他任務的工具。此外,SciPy 還封裝了許多新的 BLAS 和 LAPACK 函數。
pandas:是基于NumPy 的一種工具,該工具是為了解決數據分析任務而創建的,具備強大的數據展示功能。Pandas 納入了大量庫和一些標準的數據模型,提供了高效地操作大型數據集所需的工具。pandas提供了大量能使我們快速便捷地處理數據的函數和方法。你很快就會發現,它是使Python成為強大而高效的數據分析環境的重要因素之一。
matplotlib:是一個Python 2D繪圖庫,可以生成各種硬拷貝格式和跨平臺交互式環境的出版物質量數據。Matplotlib可用于Python腳本,Python和IPython shell,Jupyter筆記本,Web應用程序服務器和四個圖形用戶界面工具包。只需幾行代碼即可生成繪圖,直方圖,功率譜,條形圖,誤差圖,散點圖等。
scikit-learn:是一個機器學習庫,可以對數據進行分類,回歸,無監督,數據降維,數據預處理等等,包含了常見的大部分機器學習方法。
StatsModels:Statsmodels 是一個 Python 模塊,它為統計數據分析提供了許多機會,例如統計模型估計、執行統計測試等。在它的幫助下,你可以實現許多機器學習方法并探索不同的繪圖可能性。
Seaborn:Seaborn 本質上是一個基于 matplotlib 庫的高級 API。它包含更適合處理圖表的默認設置。此外,還有豐富的可視化庫,包括一些復雜類型,如時間序列、聯合分布圖(jointplots)和小提琴圖(violin diagrams)。
Plotly:Plotly 是一個交互可視化庫,它可以讓你輕松構建復雜的圖形。該軟件包適用于交互式 Web 應用程,可實現輪廓圖、三元圖和三維圖等視覺效果。
Bokeh:Bokeh 庫使用 JavaScript 小部件在瀏覽器中創建交互式和可縮放的可視化。該庫提供了多種圖表集合,樣式可能性(styling possibilities),鏈接圖、添加小部件和定義回調等形式的交互能力,以及許多更有用的特性。
Scrapy:Scrapy 是一個用來創建網絡爬蟲,掃描網頁和收集結構化數據的庫。此外,Scrapy 可以從 API 中提取數據。由于該庫的可擴展性和可移植性,使得它用起來非常方便。
TensorFlow:TensorFlow 是一個流行的深度學習和機器學習框架,由 Google Brain 開發。它提供了使用具有多個數據集的人工神經網絡的能力。在最流行的 TensorFlow應用中有目標識別、語音識別等。在常規的 TensorFlow 上也有不同的 leyer-helper,如 tflearn、tf-slim、skflow 等。
Keras:Keras 是一個用于處理神經網絡的高級庫,運行在 TensorFlow、Theano 之上,現在由于新版本的發布,還可以使用 CNTK 和 MxNet 作為后端。它簡化了許多特定的任務,并且大大減少了單調代碼的數量。然而,它可能不適合某些復雜的任務。
requests:requests庫是一個常用的用于http請求的模塊,它使用python語言編寫,可以方便的對網頁進行爬取,是學習python爬蟲的較好的http請求模塊。
Blaze:Blaze生態系統為python用戶對大數據提供了高效計算的高層接口,Blaze整合了包括Python的Pandas、NumPy及SQL、Mongo、Spark在內的多種技術,使用Blaze能夠非常容易地與一個新技術進行交互。
現在你熟悉了Python了Python數據結構和庫的使用,接下來要用這些知識去解決一些簡單的問題。比如說利用pandas去做數據探索,用matplotlib可視化圖表等等。
未完待續!
本文部分翻譯自Kunal Jain博客



![angularjs 元素重復指定次數_[LeetCode] 442. 數組中重復的數據](http://pic.xiahunao.cn/angularjs 元素重復指定次數_[LeetCode] 442. 數組中重復的數據)








類的繼承示例)






