😘個人主頁:@Cx330?
👀個人簡介:一個正在努力奮斗逆天改命的二本覺悟生
📖個人專欄:《C語言》《LeetCode刷題集》《數據結構-初階》
前言:在上篇博客的學習中,我們掌握了直接選擇排序和堆排序,發現堆排序算法的優秀,那么今天我們就進入冒泡排序和快速排序的學習中
目錄
一、冒泡排序
代碼實現:
測試結果:
復雜度分析:
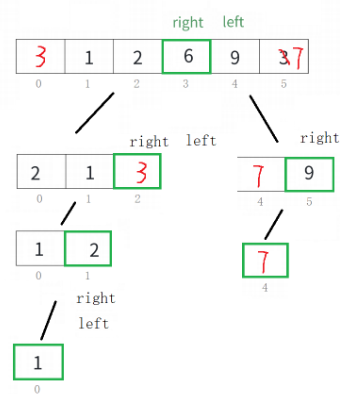
二.快速排序(遞歸實現)
代碼實現(框架):
找基準值劃分的三種實現方式:?
1.hoare版本
2.挖坑法
3.lomuto前后指針
4.基準值的重要性?
時間復雜度:
測試結果:
三.非遞歸實現快速排序
代碼實現:
測試結果:
四.冒泡排序和快速排序性能對比
代碼實現:
一、冒泡排序
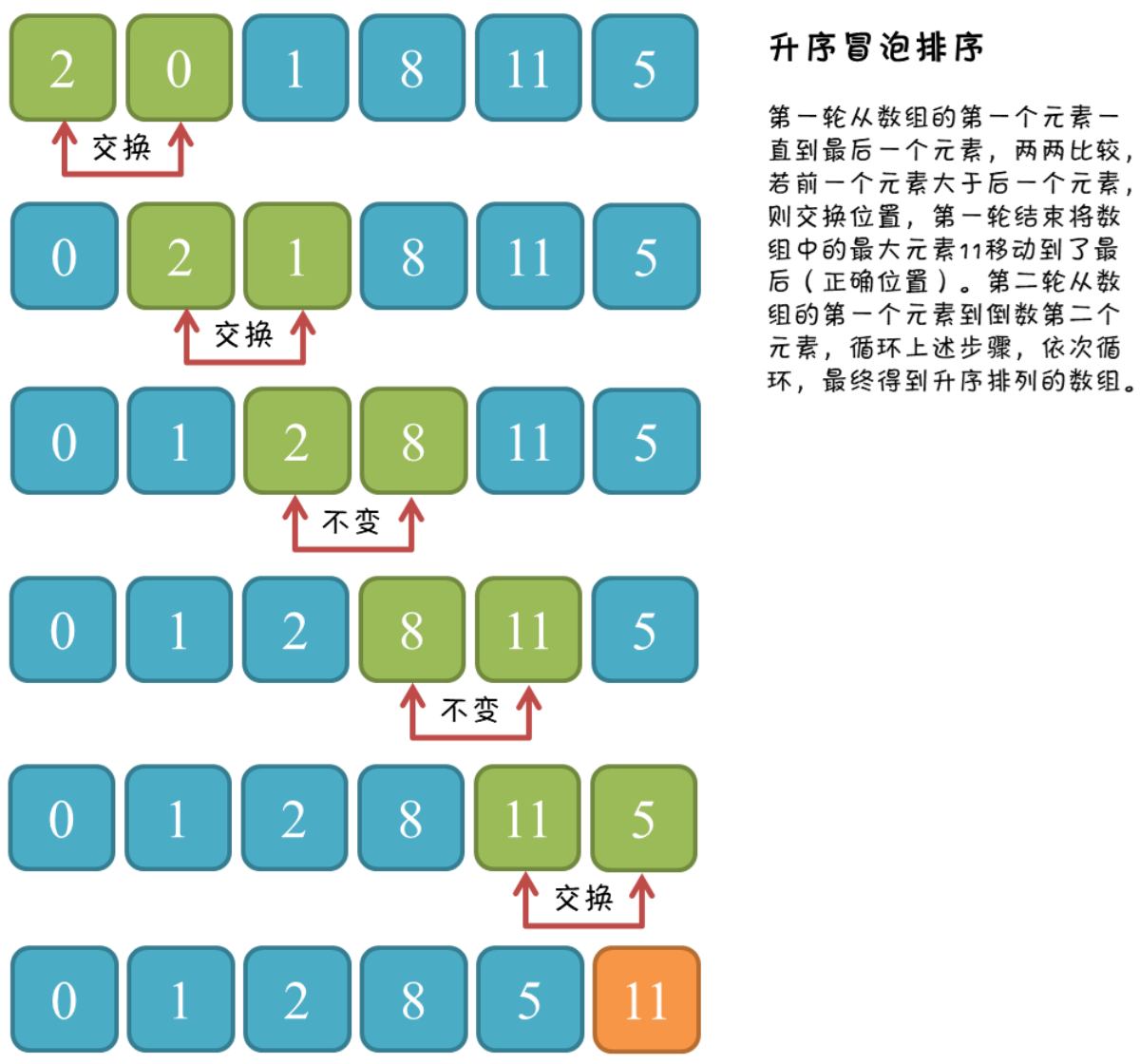
冒泡排序大家肯定都不陌生了,我們直接來看代碼吧
代碼實現:
//冒泡排序
void BubbleSort(int* arr, int n)
{int change = 1;for (int i = 0; i < n-1; i++){for (int j = 0; j < n - 1 - i; j++){if (arr[j] > arr[j + 1]){Swap(&arr[j], &arr[j + 1]);change = 0;}}if (change == 1){break;}}
}圖解:
test.c:
#include"Sort.h"
void printArr(int* arr, int n)
{for (int i = 0; i < n; i++){printf("%d ", arr[i]);}printf("\n");
}void test01()
{int a[] = { 5,3,9,6,2,4,7,1,8 };//int a[] = { 6,1,2,7,9,3 };int n = sizeof(a) / sizeof(a[0]);printf("排序之前:");printArr(a, n);//InsertSort(a, n);//ShellSort(a, n);//SelectSort(a, n);//HeapSort(a, n);BubbleSort(a, n);//QuickSort(a, 0, n - 1);//QuickSortNorR(a, 0, n - 1);//MergeSort(a, n);//CountSort(a, n);//MergeSortNonR(a, n);printf("排序之后:");printArr(a, n);
}
int main()
{test01();return 0;
}測試結果:

測試完成,打印沒有問題,升序排列正確,退出碼為0
復雜度分析:
時間復雜度:O(N^2)
冒泡排序比較簡單,博主這里的冒泡排序是優化過的,當某一次已經有序了就會直接結束
二.快速排序(遞歸實現)
快速排序是Hoare于1962年提出的?種二叉樹結構的交換排序方法,其基本思想為:任取待排序元素序列中的某元素作為基準值,按照該排序碼將待排序集合分割成兩個子序列,左子序列中所有元素均小于基準值,右子序列中所有元素均大于基準值,然后最左右子序列重復該過程,直到所有元素都排列在相應位置上為止。
代碼實現(框架):
void QuickSort(int* arr, int left, int right)
{if (left >= right){return ;}//左【left, keyi - 1】 右【keyi+1,right】int keyi = _QuickSort(arr, left, right);QuickSort(arr, left, keyi - 1);QuickSort(arr,keyi+1,right);
}圖解:
采用遞歸的思想,有些類似二叉樹的前序遍歷,分組進行劃分。
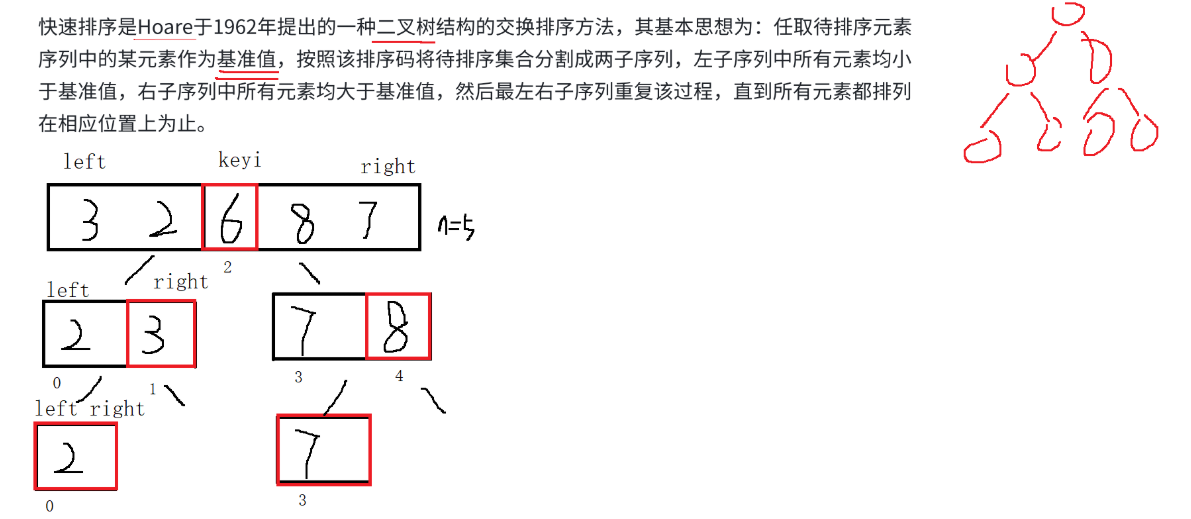
找基準值劃分的三種實現方式:?
將區間元素進行劃分的_QuickSort方法主要有以下幾種實現方法:
1.hoare版本
思路:
- 創建left和right指針
- (升序)從右向左找出比基準值小的數據,從左向右找出比基準值大的數據,左右指針數據交換。進入下次循環-------我們默認left初始位置的值為基準值,特別注意一下確定基準之后left要先++一次。
- 循環結束后,交換keyi和right位置的值,然后返回right下標
代碼實現:
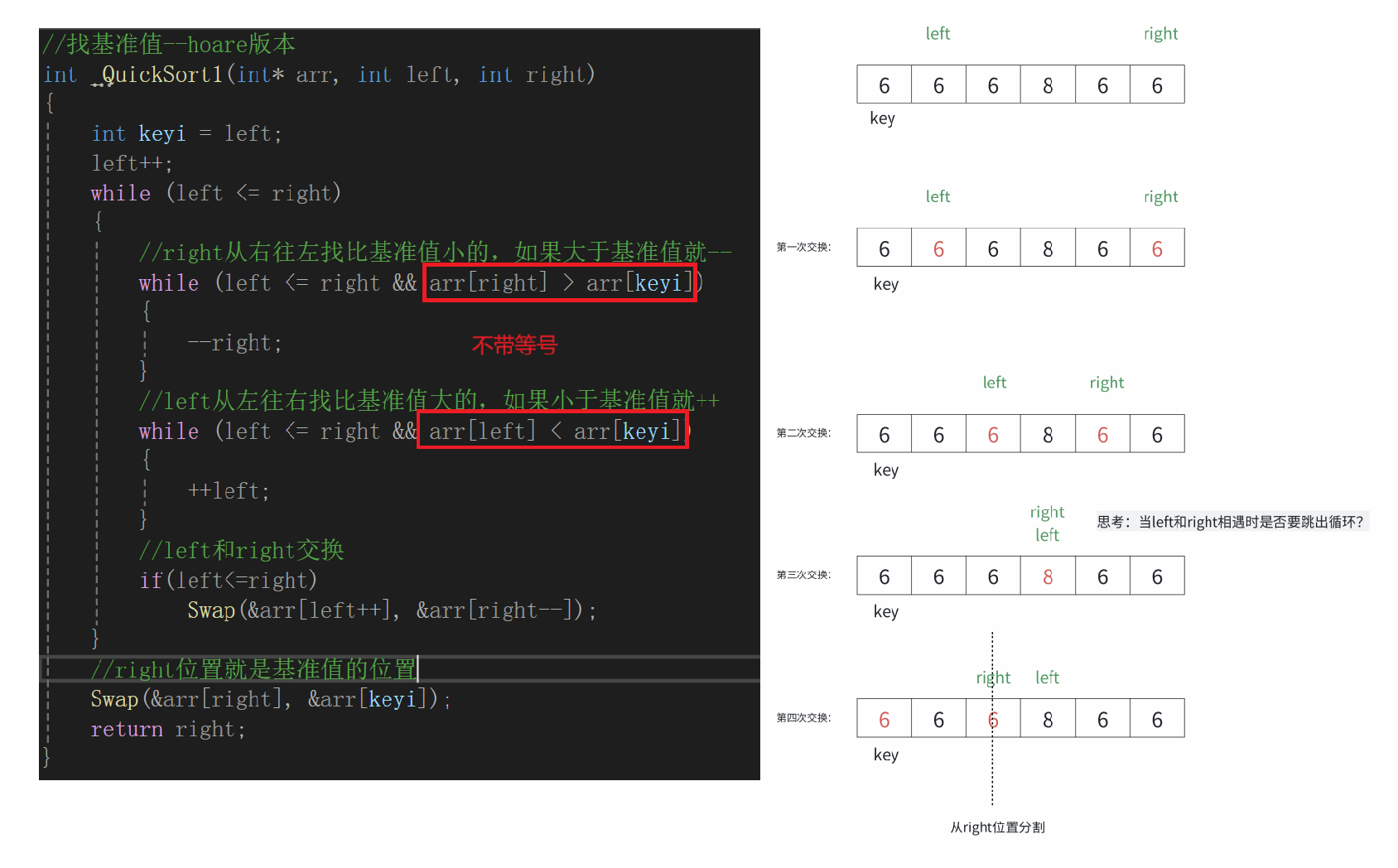
//找基準值--hoare版本
int _QuickSort1(int* arr, int left, int right)
{int keyi = left;left++;while (left <= right){//right從右往左找比基準值小的,如果大于基準值就--while (left <= right && arr[right] > arr[keyi]){--right;}//left從左往右找比基準值大的,如果小于基準值就++while (left <= right && arr[left] < arr[keyi]){++left;}//left和right交換if(left<=right)Swap(&arr[left++], &arr[right--]);}//right位置就是基準值的位置Swap(&arr[right], &arr[keyi]);return right;
}注意事項:
1.為什么跳出循環后right位置的值一定不大于key?
答:當left>right時,即right走到left的左側,而left掃過的數據均不大于key,所有right此時所指向的數據一定不大于key
三種情況都在圖中有所講解,大家可以仔細的看一下
2.內層循環不能等于,數據重復的情況下會造成時間復雜度變為O(n^2)

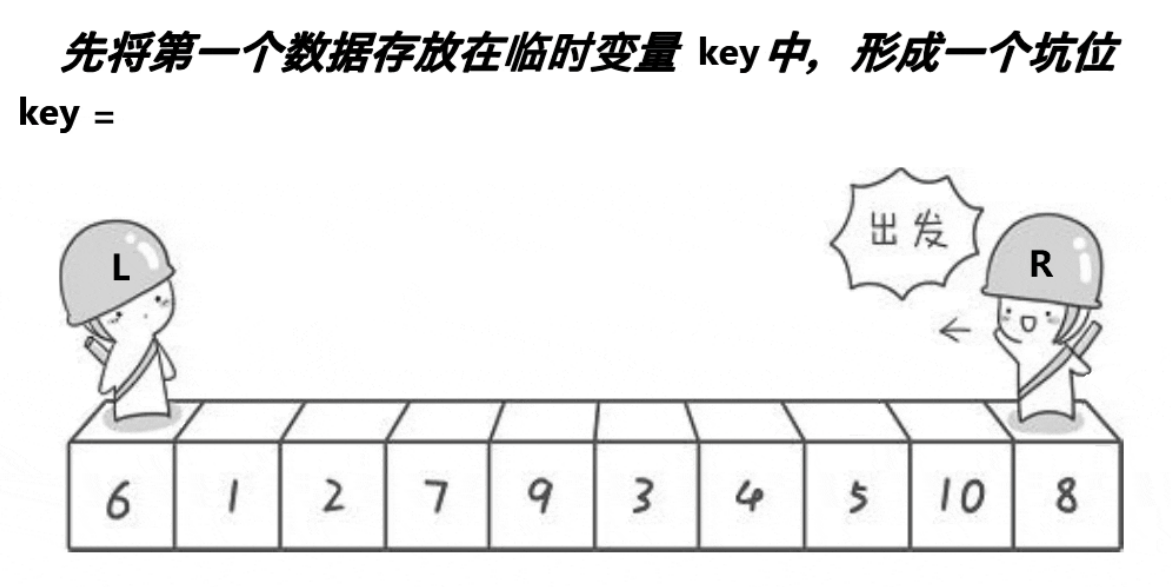
2.挖坑法
思路:
- 創建右指針,(這個思路left不用先++)首先從右向左找出比基準小的,找到后立即放入坑中,當前位置變為新的坑。
- 然后從左到右找出比基準大的數據,找到后立即放到右邊坑中,當前位置變為新的坑
- 結束循環后將最開始存儲的分界值放入當前的坑中,返回當前坑的下標
代碼實現:
//找基準值--挖坑法
int _QuickSort(int* arr, int left, int right)
{int hole = left;int key = arr[hole];while (left < right){while (left<right && arr[right] > key){right--;}arr[hole] = arr[right];hole = right;while (left < right && arr[left] < key){++left;}arr[hole] = arr[left];hole = left;}arr[hole] = key;return hole;
}圖解:

3.lomuto前后指針
思路:
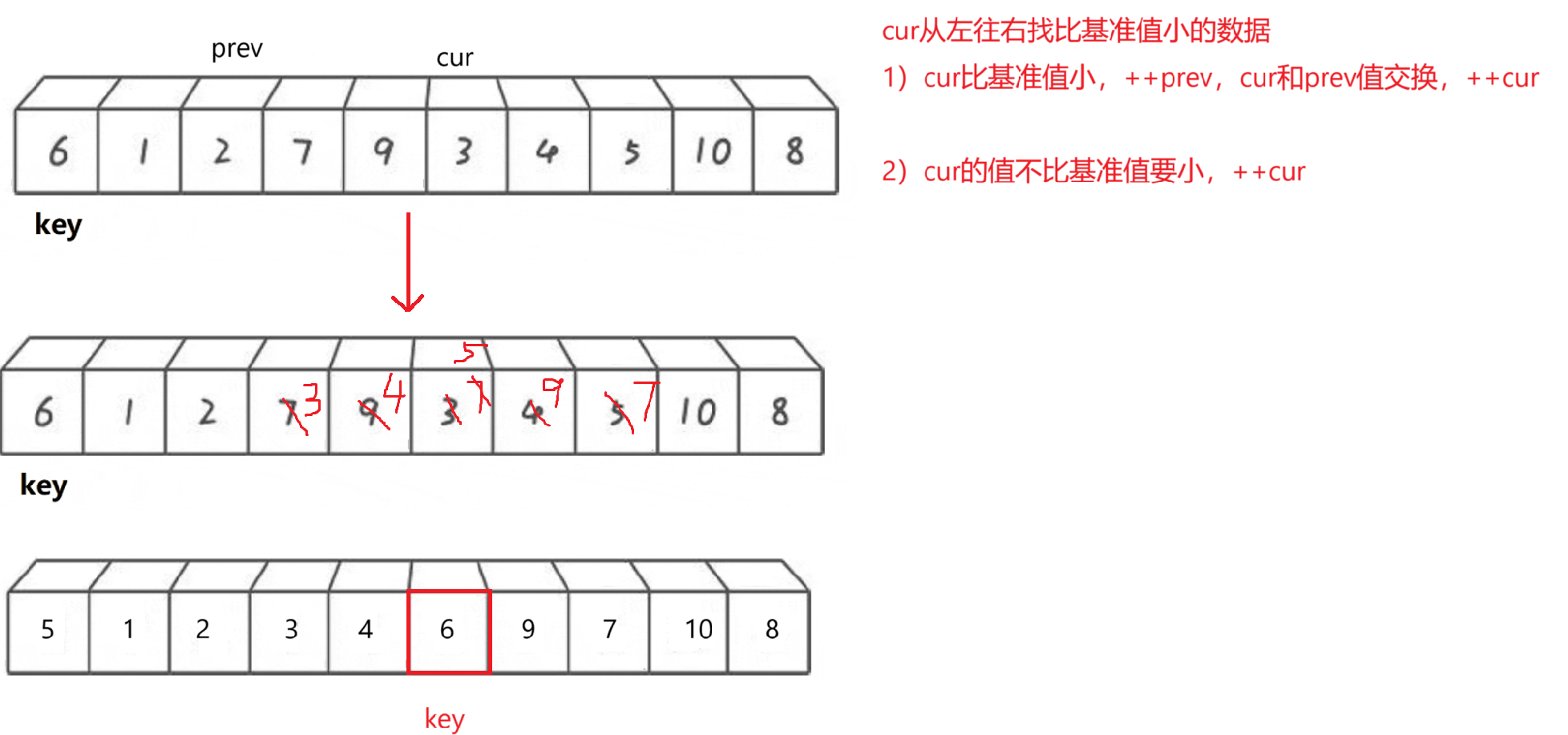
- 創建左右指針prev和cur,cur從左往右找比基準值要小的數據
- cur指向的數據比基準值要小的話,++prev,(且++prev!=cur),交換cur和prev位置的值。再++cur
- cur指向的數據不比基準值小的話,直接++cur
- 循環結束后,交換keyi位置和prev位置的值,返回prev下標

代碼實現:
//找基準值--lumoto雙指針法
int _QuickSort2(int* arr, int left, int right)
{int prev = left, cur = prev + 1;int keyi = left;while (cur < right){if (arr[cur] < arr[keyi] && ++prev != cur){Swap(&arr[cur], &arr[prev]);}++cur;}Swap(&arr[prev], &arr[keyi]);return prev;
}圖解:
4.基準值的重要性?
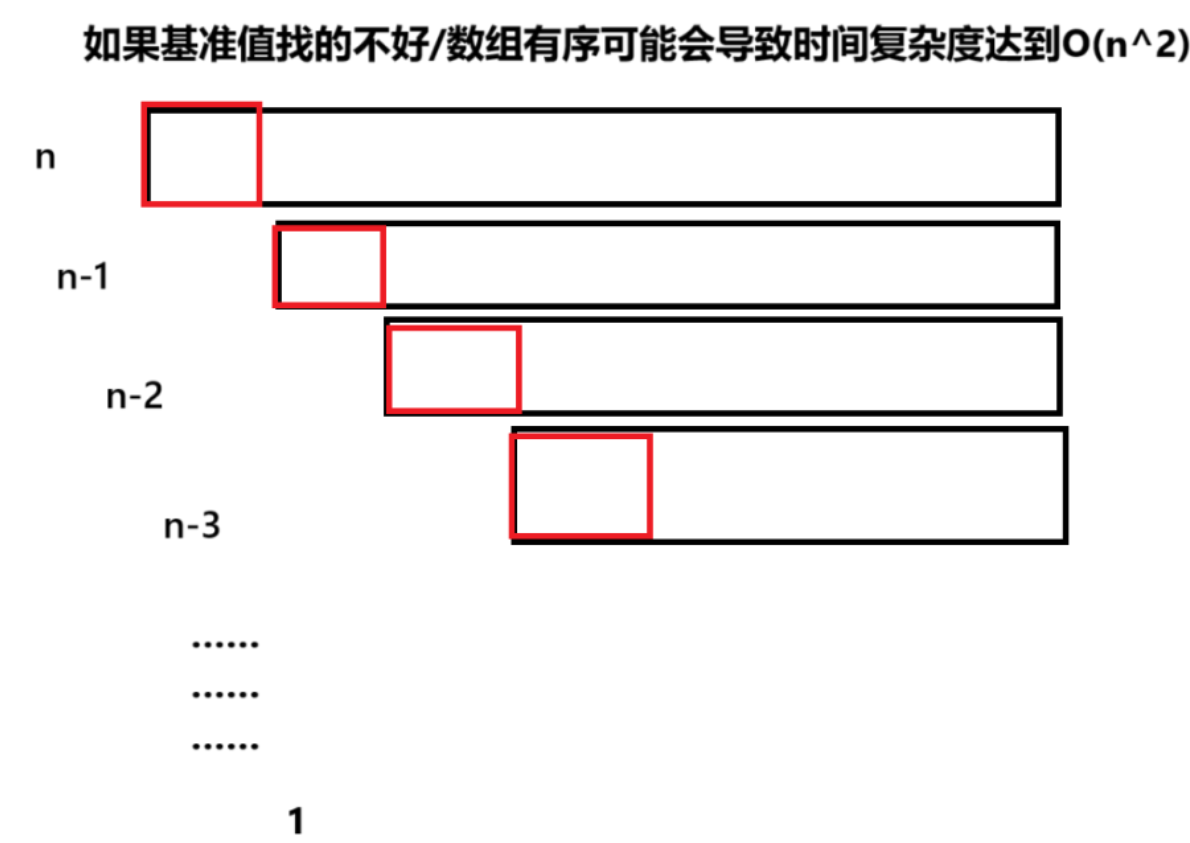
我們一般默認最左邊就是我們要找的基準值,但其實我們是有特定方法求出比較好的基準值的,這個在后續的提升篇中會有講解?
時間復雜度:
O(n*logn)
遞歸時間復雜度=單次遞歸時間復雜度(n)*遞歸次數(樹的最大高度,logn)=n*logn
test.c:
#include"Sort.h"void PrintArr(int* arr, int n)
{for (int i = 0; i < n; i++){printf("%d ", arr[i]);}printf("\n");
}void test1()
{int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };int size = sizeof(a) / sizeof(a[0]);printf("排序前:");PrintArr(a, size);//快速排序QuickSort(a, 0, size - 1);printf("排序后:");PrintArr(a, size);
}int main()
{test1();return 0;
}測試結果:

三種找基準的方法結合快速排序主體最后測試都沒有問題,這里就放一個圖了,升序排列正確,退出碼為0
三.非遞歸實現快速排序
我們非遞歸實現快速排序需要借助數據結構棧,直接使用我們之前自己實現過的就行了,然后在.c文件里面引入一下棧的.h文件。具體操作和之前我們借助隊列實現二叉樹的層序遍歷和判斷二叉樹是否為完全二叉樹差不多,但是不用修改數據類型
思路:
1.初始化棧:首先將整個數組的起始索引(如 0)和結束索引(如 n-1)作為初始區間推入棧中,先推結束的再推起始的。
2.循環處理棧中區間:當棧不為空時,執行以下操作:
- 彈出區間:從棧頂取出一個待排序區間的起始索引 begin?和結束索引 end。
- 劃分區間:調用劃分函數(與遞歸版相同),選擇基準元素,將區間 [begin, end] 劃分為左子區間 [begin, keyi-1](元素均小于基準)和右子區間 [keyi+1, end](元素均大于基準),返回基準元素的最終位置 keyi。
- 推入子區間:若左子區間存在(即 begin?< keyi-1),將其邊界 (begin, keyi-1) 推入棧;若右子區間存在(即 keyi+1 < end),將其邊界 (keyi+1, end) 推入棧。
3.結束條件:當棧為空時,所有子區間均已排序完成,整個數組排序結束。
需要注意的時棧先進后出,所以我們一般都是先推右再推左,不管是左子區間右子區間還是左邊范圍右邊范圍都是這樣的
代碼實現:
//找基準值非遞歸版--棧
int QuickSortNorR(int* arr, int left, int right)
{ST st;STInit(&st);STPush(&st, right);STPush(&st, left);while (!STEmpty(&st)){//取棧頂兩次int begin = STTop(&st);STPop(&st);int end = STTop(&st);STPop(&st);//[begin,end]--找基準值int keyi = begin;int prev = begin, cur = prev + 1;while (cur <= end){if (arr[cur] < arr[keyi] && ++prev != cur){Swap(&arr[cur], &arr[prev]);}++cur;}Swap(&arr[prev], &arr[keyi]);keyi = prev;if (keyi + 1 < end){STPush(&st, end);STPush(&st, keyi+1);}if (begin < keyi - 1){STPush(&st, keyi - 1);STPush(&st, begin);}}STDesTroy(&st);
}圖解:

test.c:
#include"Sort.h"void PrintArr(int* arr, int n)
{for (int i = 0; i < n; i++){printf("%d ", arr[i]);}printf("\n");
}void test1()
{int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };int size = sizeof(a) / sizeof(a[0]);printf("排序前:");PrintArr(a, size);//非遞歸快速排序QuickSortNoare(a, 0, size - 1);printf("排序后:");PrintArr(a, size);
}
int main()
{test1();return 0;
}測試結果:

測試完成,打印沒有問題,非遞歸版本升序排序正確,退出碼為0
四.冒泡排序和快速排序性能對比
我們還是通過測試來對比一下這兩種排序的性能,大家也可以看看和之前實現過的排序的對比
代碼實現:
#include"Sort.h"void PrintArr(int* arr, int n)
{for (int i = 0; i < n; i++){printf("%d ", arr[i]);}printf("\n");
}void test1()
{int a[] = { 5, 3, 9, 6, 2, 4, 7, 1, 8 };int size = sizeof(a) / sizeof(a[0]);printf("排序前:");PrintArr(a, size);//直接插入排序//InsertSort(a, size);//希爾排序//ShellSort(a, size);//直接選擇排序//SelectSort(a, size);//堆排序//HeapSort(a, size);//冒泡排序//BubbleSort(a, size);//快速排序//QuickSort(a, 0, size - 1);//非遞歸快速排序QuickSortNoare(a, 0, size - 1);printf("排序后:");PrintArr(a, size);
}// 測試排序的性能對比
void TestOP()
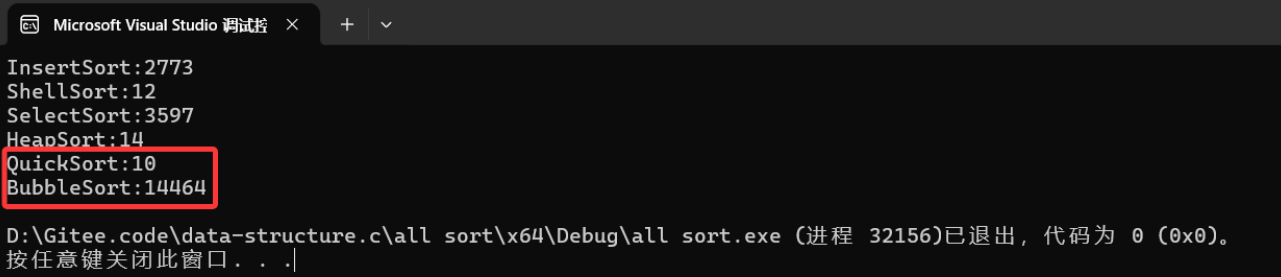
{srand(time(0));const int N = 100000;int* a1 = (int*)malloc(sizeof(int) * N);int* a2 = (int*)malloc(sizeof(int) * N);int* a3 = (int*)malloc(sizeof(int) * N);int* a4 = (int*)malloc(sizeof(int) * N);int* a5 = (int*)malloc(sizeof(int) * N);int* a6 = (int*)malloc(sizeof(int) * N);int* a7 = (int*)malloc(sizeof(int) * N);for (int i = 0; i < N; ++i){a1[i] = rand();a2[i] = a1[i];a3[i] = a1[i];a4[i] = a1[i];a5[i] = a1[i];a6[i] = a1[i];a7[i] = a1[i];}int begin1 = clock();InsertSort(a1, N);int end1 = clock();int begin2 = clock();ShellSort(a2, N);int end2 = clock();int begin3 = clock();SelectSort(a3, N);int end3 = clock();int begin4 = clock();HeapSort(a4, N);int end4 = clock();int begin5 = clock();QuickSort(a5, 0, N - 1);int end5 = clock();int begin6 = clock();//MergeSort(a6, N);int end6 = clock();int begin7 = clock();BubbleSort(a7, N);int end7 = clock();printf("InsertSort:%d\n", end1 - begin1);printf("ShellSort:%d\n", end2 - begin2);printf("SelectSort:%d\n", end3 - begin3);printf("HeapSort:%d\n", end4 - begin4);printf("QuickSort:%d\n", end5 - begin5);//printf("MergeSort:%d\n", end6 - begin6);printf("BubbleSort:%d\n", end7 - begin7);free(a1);free(a2);free(a3);free(a4);free(a5);//free(a6);free(a7);
}int main()
{TestOP();//test1();return 0;
}我們可以看出快速排序要比冒泡快很多,和其它排序相比的情況下,快速排序也是很快的
往期回顧:
【數據結構初階】--排序(一):直接插入排序,希爾排序
【數據結構初階】--排序(二):直接選擇排序,堆排序
總結:本篇博客就到此結束了,主要實現了一下兩種交換排序,一個冒泡排序,一個快速排序。我們通過對比可知快速排序優于冒泡排序。其中快速排序找基準值我們提供了三種方法,如果文章對你有幫助的話,歡迎評論,點贊,收藏加關注,感謝大家的支持。







 加權稀疏迭代最近點算法(matlab版))


)


|所有權機制 Ownership)


 關鍵字搜索 API 實戰:從認證到商品列表獲取全流程解析)


