Alink漫談(十二) :在線學習算法FTRL 之 整體設計
[Toc]
0x00 摘要
Alink 是阿里巴巴基于實時計算引擎 Flink 研發的新一代機器學習算法平臺,是業界首個同時支持批式算法、流式算法的機器學習平臺。本文和下文將介紹在線學習算法FTRL在Alink中是如何實現的,希望對大家有所幫助。
0x01概念
因為 Alink 實現的是 LR + FTRL,所以我們需要從邏輯回歸 LR 開始介紹。
1.1 邏輯回歸
Logistic Regression 雖然被稱為回歸,但其實際上是分類模型,并常用于二分類。Logistic 回歸的本質是:假設數據服從這個分布,然后使用極大似然估計做參數的估計。
邏輯回歸的思路是,先擬合決策邊界(不局限于線性,還可以是多項式),再建立這個邊界與分類的概率聯系,從而得到了二分類情況下的概率。
1.1.1 推導過程
我們從線性回歸開始說起。某些情況下,使用線性的函數來擬合規律后取閾值的辦法是行不通的。行不通的原因在于擬合的函數太直,離群值(也叫異常值)對結果的影響過大。但是我們的整體思路是沒有錯的,錯的是用太"直"的擬合函數,如果我們用來擬合的函數是非線性的,不這么直,是不是就好一些呢?
所以我們下面來做兩件事:
找到一個辦法解決掉回歸的函數嚴重受離群值影響的辦法.
選定一個閾值.
對于第一件事,我們用sigmod函數把回歸函數掰彎。
對于二分類問題,1表示正例,0表示負例。邏輯回歸是在線性函數輸出預測實際值的基礎上,尋找一個假設函數函數h_θ(x) = g(θ,x),將實際值映射到到0,1之間。邏輯回歸中選擇對數幾率函數(logistic function)作為激活函數,對數幾率函數是Sigmoid函數(形狀為S的函數)的重要代表。
對于第二件事,我們選定閾值是0.5。
意思就是,當我選閾值為0.5,那么小于0.5的一定是負例,哪怕他是0.49。此時我們判斷一個樣本為負例一定是準確的嗎?其實不一定,因為它還是有49%的概率為正例的。但是,即便它是正例的概率為0.1,則我們隨機選擇1w個樣本來做預測,還是會有接近100個預測它是負例結果它實際是正例的誤差。無論怎么選,誤差都是存在的,所以我們選定閾值就是在選擇可以接受誤差的程度。
1.1.2 求解
到這里,邏輯回歸的由來我們就基本理清楚了,我們知道邏輯回歸的判別函數就是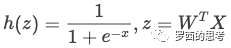
如何求解邏輯回歸?也就是如何找到一組可以讓 h(z) 全都預測正確概率最大的W。
求解邏輯回歸的方法有非常多,我們這里主要聊下梯度下降和牛頓法。優化的主要目標是找到一個方向,參數朝這個方向移動之后使得損失函數的值能夠減小,這個方向往往由一階偏導或者二階偏導各種組合求得。
梯度下降是通過 J(w) 對 w 的一階導數來找下降方向,并且以迭代的方式來更新參數。
牛頓法的基本思路是,在現有極小點估計值的附近對 J(w) 做二階泰勒展開,進而找到極小點的下一個估計值。
1.1.3 隨機梯度下降
當樣本數據里N很大的時候,通常采用的是隨機梯度下降法,算法如下所示:
while?{
????for?i?in?range(0,m):
????????w_j?=?w_j?+?a?*?g_j
}
隨機梯度下降的好處是可以實現分布式并行化,具體計算流程是:
在每次迭代的時候,隨機抽樣一定比例的樣本作為當前迭代的計算樣本。
對計算樣本中的每一個樣本,分別計算不同特征的計算梯度。
通過聚合函數,對所有計算樣本的特征的梯度進行累加,得到每一個特征的累積梯度以及損失。
最后根據最新的梯度以及之前的參數,對參數進行更新。
根據更新的參數計算損失函數誤差值,如果損失函數誤差值達到允許的范圍,那么停止迭代,否則重復步驟1
1.2 LR的并行計算
從邏輯回歸的求解方法中我們可以發現這些算法都是需要計算梯度的,因此邏輯回歸的并行化最主要的就是對目標函數梯度計算的并行化。
我們看到目標函數的梯度向量計算中只需要進行向量間的點乘和相加,可以很容易將每個迭代過程拆分成相互獨立的計算步驟,由不同的節點進行獨立計算,然后歸并計算結果。
所以并行 LR 實際上就是在求解損失函數最優解的過程中,針對尋找損失函數下降方向中的梯度方向計算作了并行化處理,而在利用梯度確定下降方向的過程中也可以采用并行化。
如果將樣本矩陣按行劃分,將樣本特征向量分布到不同的計算節點,由各計算節點完成自己所負責樣本的點乘與求和計算,然后將計算結果進行歸并,則實現了“ 按行 并行的LR”。
按行并行的LR解決了樣本數量的問題,但是實際情況中會存在針對高維特征向量進行邏輯回歸的場景(如廣告系統中的特征維度高達上億),僅僅按行進行并行處理,無法滿足這類場景的需求,因此還需要 按列 將高維的特征向量拆分成若干小的向量進行求解。
1.3 傳統機器學習
傳統的機器學習開發流程基本是以下步驟:
數據融合,獲取訓練以及評估數據集。
特征工程。
構建模型,比如LR,FM等。
訓練模型,獲得最優解。
評估模型效果。
保存模型,并在線上使用訓練的有效模型進行訓練。
這種方式主要存在兩個瓶頸:
模型更新周期慢,不能有效反映線上的變化,最快小時級別,一般是天級別甚至周級別。
模型參數少,預測的效果差;模型參數多線上predict的時候需要內存大,QPS無法保證。
比如,傳統Batch算法中每次迭代對全體訓練數據集進行計算(例如計算全局梯度),優點是精度和收斂還可以,缺點是無法有效處理大數據集(此時全局梯度計算代價太大),且沒法應用于數據流做在線學習。
針對這些問題,一般而言有兩種解決方式:
對1采用On-line-learning的算法。
對2采用一些優化的方法,在保證精度的前提下,盡量獲取稀疏解,從而降低模型參數的數量。
1.4 在線學習
在線學習 ( OnlineLearningOnlineLearning ) 代表了一系列機器學習算法,特點是每來一個樣本就能訓練,能夠根據線上反饋數據,實時快速地進行模型調整,使得模型及時反映線上的變化,提高線上預測的準確率。
傳統的訓練方法在模型訓練上線后,一般是靜態的,不會與線上的狀況有任何的互動,加入預測錯誤,只能在下一次更新的時候完成修正,但是這個更新的時間一般比較長。
Online Learning訓練方法不同,會根據線上的預測結果動態調整模型,加入模型預測錯誤,從而及時做出修正,因此Online Learning能夠更加及時地反應線上變化。
Online Learning的優化目標是使得整體的損失函數最小化,它需要快速求解目標函數的最優解。
在線學習算法的特點是:每來一個訓練樣本,就用該樣本產生的loss和梯度對模型迭代一次,一個一個數據地進行訓練,因此可以處理大數據量訓練和在線訓練。常用的有在線梯度下降(OGD)和隨機梯度下降(SGD)等,本質思想是對上面【問題描述】中的未加和的單個數據的loss函數 L(w,zi)做梯度下降,因為每一步的方向并不是全局最優的,所以整體呈現出來的會是一個看似隨機的下降路線。
1.5 FTRL
FTR是FTRL的前身,思想是每次找到讓之前所有樣本的損失函數之和最小的參數。
FTRL,即 Follow The Regularized Leader,是在之前的幾個工作上產生的,主要出發點就是為了提高稀疏度且滿足精度要求。FTRL 在FTL的優化目標的基礎上,加入了正則化,防止過擬合。
FTRL的損失函數一般也不容易求解,這種情況下,一般需要找一個代理的損失函數。
代理損失函數需要滿足以下條件:
代理損失函數比較容易求解,最好是有解析解。
代理損失函數求得的解,和原函數的解的差距越小越好
為了衡量條件2中的兩個解的差距,引入regret的概念。
1.5.1 regret & sparsity
一般對于在線學習來說,我們致力于解決兩個問題:降低 regret 和提高 sparsity。其中 regret 的定義為: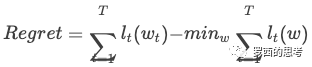
其中 t 表示總共 T 輪中的第 t 輪迭代,?t 表示損失函數,w 表示要學習的參數。Regret 表示 "代理函數求出來的解" 離 "真正損失函數求出來的解" 的損失差距。
第二項 表示得到了所有樣本后損失函數的最優解,因為在線學習一次只能根據少數幾個樣本更新參數,隨機性較大,所以需要一種穩健的優化方式,而 regret 字面意思是 “后悔度”,意即更新完不后悔。
在理論上可以證明,如果一個在線學習算法可以保證其 regret 是 t 的次線性函數,則: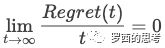
那么隨著訓練樣本的增多,在線學習出來的模型無限接近于最優模型。即隨著訓練樣本的增加,代理損失函數和原損失函數求出來的參數的實際損失值差距越來越小。而毫不意外的,FTRL 正是滿足這一特性。
另一方面,現實中對于 sparsity,也就是模型的稀疏性也很看重。上億的特征并不鮮見,模型越復雜,需要的存儲、時間資源也隨之升高,而稀疏的模型會大大減少預測時的內存和復雜度。另外稀疏的模型相對可解釋性也較好,這也正是通常所說的 L1 正則化的優點。
1.5.2 FTRL的偽代碼

Per-Coordinate 意思是FTRL是對w每一維分開訓練更新的,每一維使用的是不同的學習速率,也是上面代碼中lamda2之前的那一項。與w所有特征維度使用統一的學習速率相比,這種方法考慮了訓練樣本本身在不同特征上分布的不均勻性,如果包含w某一個維度特征的訓練樣本很少,每一個樣本都很珍貴,那么該特征維度對應的訓練速率可以獨自保持比較大的值,每來一個包含該特征的樣本,就可以在該樣本的梯度上前進一大步,而不需要與其他特征維度的前進步調強行保持一致。
1.5.3 簡要理解
我們再看看下一時刻的特征權重的更新公式,增加理解(我個人覺得找到的這個解釋相對易于理解):
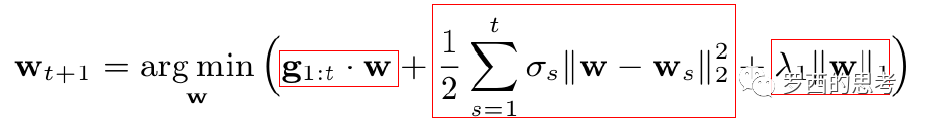
式中第一項是對損失函數的貢獻的一個估計,第二項是控制w(也就是model)在每次迭代中變化不要太大,第三項代表L1正則(獲得稀疏解)。
0x02 示例代碼
我們采用的就是Alink官方示例代碼。我們可以看到大致分為幾部分:
建立特征處理管道,其包括StandardScaler和FeatureHasher,進行標準化縮放和特征哈希,最后得到了特征向量,這部分可以參見 ?Alink漫談(九) :特征工程 之 特征哈希/標準化縮放;
對于流數據源進行實時切分得到原始訓練數據和原始預測數據,這部分可以參見 ?Alink漫談(七) : 如何劃分訓練數據集和測試數據集;
訓練出一個邏輯回歸模型作為FTRL算法的初始模型,這是為了系統冷啟動的需要。邏輯回歸和線性回歸類似,所以大家可以參見這兩篇文章:Alink漫談(十) :線性回歸實現 之 數據預處理 和 ?Alink漫談(十一) :線性回歸 之 L-BFGS優化;
在初始模型基礎上進行FTRL在線訓練;
在FTRL在線模型的基礎上,連接預測數據進行預測;
對預測結果流進行評估,具體可以參見 Alink漫談(八) : 二分類評估 AUC、K-S、PRC、Precision、Recall、LiftChart 如何實現;
你大概已經看出來了,為了剖析FTRL,我前面做了很多工作……
public?class?FTRLExample?{
????public?static?void?main(String[]?args)?throws?Exception?{
????????......
????????//?setup?feature?engineering?pipeline
????????Pipeline?featurePipeline?=?new?Pipeline()
????????????????.add(
????????????????????????new?StandardScaler()?//?標準縮放
????????????????????????????????.setSelectedCols(numericalColNames)
????????????????)
????????????????.add(
????????????????????????new?FeatureHasher()?//?特征哈希
????????????????????????????????.setSelectedCols(selectedColNames)
????????????????????????????????.setCategoricalCols(categoryColNames)
????????????????????????????????.setOutputCol(vecColName)
????????????????????????????????.setNumFeatures(numHashFeatures)
????????????????);
????????//?構建特征工程流水線
????????//?fit?feature?pipeline?model
????????PipelineModel?featurePipelineModel?=?featurePipeline.fit(trainBatchData);
????????//?prepare?stream?train?data
????????CsvSourceStreamOp?data?=?new?CsvSourceStreamOp()
????????????????.setFilePath("http://alink-release.oss-cn-beijing.aliyuncs.com/data-files/avazu-ctr-train-8M.csv")
????????????????.setSchemaStr(schemaStr)
????????????????.setIgnoreFirstLine(true);
????????//?對于流數據源進行實時切分得到原始訓練數據和原始預測數據
????????//?split?stream?to?train?and?eval?data
????????SplitStreamOp?splitter?=?new?SplitStreamOp().setFraction(0.5).linkFrom(data);
????????//?訓練出一個邏輯回歸模型作為FTRL算法的初始模型,這是為了系統冷啟動的需要。
????????//?train?initial?batch?model
????????LogisticRegressionTrainBatchOp?lr?=?new?LogisticRegressionTrainBatchOp()
????????????????.setVectorCol(vecColName)
????????????????.setLabelCol(labelColName)
????????????????.setWithIntercept(true)
????????????????.setMaxIter(10);
????????BatchOperator>?initModel?=?featurePipelineModel.transform(trainBatchData).link(lr);
????????//?在初始模型基礎上進行FTRL在線訓練
????????//?ftrl?train
????????FtrlTrainStreamOp?model?=?new?FtrlTrainStreamOp(initModel)
????????????????.setVectorCol(vecColName)
????????????????.setLabelCol(labelColName)
????????????????.setWithIntercept(true)
????????????????.setAlpha(0.1)
????????????????.setBeta(0.1)
????????????????.setL1(0.01)
????????????????.setL2(0.01)
????????????????.setTimeInterval(10)
????????????????.setVectorSize(numHashFeatures)
????????????????.linkFrom(featurePipelineModel.transform(splitter));
????????//?在FTRL在線模型的基礎上,連接預測數據進行預測
????????//?ftrl?predict
????????FtrlPredictStreamOp?predictResult?=?new?FtrlPredictStreamOp(initModel)
????????????????.setVectorCol(vecColName)
????????????????.setPredictionCol("pred")
????????????????.setReservedCols(new?String[]{labelColName})
????????????????.setPredictionDetailCol("details")
????????????????.linkFrom(model,?featurePipelineModel.transform(splitter.getSideOutput(0)));
????????//?對預測結果流進行評估
????????//?ftrl?eval
????????predictResult
????????????????.link(
????????????????????????new?EvalBinaryClassStreamOp()
????????????????????????????????.setLabelCol(labelColName)
????????????????????????????????.setPredictionCol("pred")
????????????????????????????????.setPredictionDetailCol("details")
????????????????????????????????.setTimeInterval(10)
????????????????)
????????????????.link(
????????????????????????new?JsonValueStreamOp()
????????????????????????????????.setSelectedCol("Data")
????????????????????????????????.setReservedCols(new?String[]{"Statistics"})
????????????????????????????????.setOutputCols(new?String[]{"Accuracy",?"AUC",?"ConfusionMatrix"})
????????????????????????????????.setJsonPath(new?String[]{"$.Accuracy",?"$.AUC",?"$.ConfusionMatrix"})
????????????????)
????????????????.print();
????????StreamOperator.execute();
????}
}
0x03 問題
用問題來引導剖析比較好,以下是我們容易想到的一些問題。
訓練階段和預測階段都有預制模型以應對"冷啟動"嘛?
訓練階段和預測階段是如何關聯起來的?
如何把訓練出來的模型傳給預測階段?
輸出模型時候,模型過大怎么處理?
在線訓練的模型通過什么機制實現更新?是定時驅動更新嘛?
預測階段加載模型過程中,還可以預測嘛?有沒有機制保證這段時間內也能預測?
訓練和預測中,有哪些階段用到了并行處理?
遇到高維向量如何處理?切分開嘛?
后續我們會一一探究這些問題。
0x04 總體邏輯
在線訓練是在 FtrlTrainStreamOp 類中實現的,其 linkFrom 函數實現了基本邏輯。
主要邏輯是:
1)加載初始化模型到 dataBridge;dataBridge = DirectReader.collect(model);
2)獲取相關參數。比如vectorSize默認是30000,是否有hasInterceptItem;
3)獲取切分信息。splitInfo = getSplitInfo(featureSize, hasInterceptItem, parallelism); 下面馬上會用到。
4)切分高維向量。初始化數據做了特征哈希,會產生高維向量,這里需要進行切割。initData.flatMap(new SplitVector(splitInfo, hasInterceptItem, vectorSize,vectorTrainIdx, featureIdx, labelIdx));
5)構建一個 IterativeStream.ConnectedIterativeStreams iteration,這樣會構建(或者說連接)兩個數據流:反饋流和訓練流;
6)用iteration來構建迭代體 iterativeBody,其包括兩部分:CalcTask,ReduceTask;
CalcTask分成兩個部分。flatMap1 是分布計算FTRL迭代需要的predict,flatMap2 是FTRL的更新參數部分;
ReduceTask分為兩個功能:歸并這些predict計算結果 / 如果滿足條件則歸并模型并 & 向下游算子輸出模型;
7)result = iterativeBody.filter;基本是以時間間隔為標準來判斷(也可以認為是時間驅動),"時間未過期&向量有意義" 的數據將被發送回反饋數據流,繼續迭代,回到步驟 6),進入flatMap2;
8)output = iterativeBody.filter;符合標準(時間過期了)的數據將跳出迭代,然后算法會調用WriteModel將LineModelData轉換為多條Row,轉發給下游operator(也就是在線預測階段);即定時把模型更新給在線預測階段。
代碼摘要是:
@Override
public?FtrlTrainStreamOp?linkFrom(StreamOperator>...?inputs)?{
????......
????//?3)獲取切分信息
????final?int[]?splitInfo?=?getSplitInfo(featureSize,?hasInterceptItem,?parallelism);
????DataStream?initData?=?inputs[0].getDataStream();// 4)切分高維向量。//?Tuple5
????DataStream>?input
????????=?initData.flatMap(new?SplitVector(splitInfo,?hasInterceptItem,?vectorSize,
????????vectorTrainIdx,?featureIdx,?labelIdx))
????????.partitionCustom(new?CustomBlockPartitioner(),?1);//?train?data?format?=?//?feedback?format?=?Tuple7// 5)構建一個 IterativeStream.ConnectedIterativeStreams iteration,這樣會構建(或者說連接)兩個數據流:反饋流和訓練流;
????IterativeStream.ConnectedIterativeStreams,
????????Tuple7>
????????iteration?=?input.iterate(Long.MAX_VALUE)
????????.withFeedbackType(TypeInformation
????????????.of(new?TypeHint>()?{}));// 6)用iteration來構建迭代體 iterativeBody,其包括兩部分:CalcTask,ReduceTask;
????DataStream?iterativeBody?=?iteration.flatMap(new?CalcTask(dataBridge,?splitInfo,?getParams()))
????????.keyBy(0)
????????.flatMap(new?ReduceTask(parallelism,?splitInfo))
????????.partitionCustom(new?CustomBlockPartitioner(),?1);// 7)result = iterativeBody.filter;基本是以時間間隔為標準來判斷(也可以認為是時間驅動),"時間未過期&向量有意義"?的數據將被發送回反饋數據流,繼續迭代,回到步驟 6),進入flatMap2;
????DataStream>
????????result?=?iterativeBody.filter(new?FilterFunction>()?{@Overridepublic?boolean?filter(Tuple7?t3)throws?Exception?{//?if?t3.f0?>?0?&&?t3.f2?>?0?then?feedbackreturn?(t3.f0?>?0?&&?t3.f2?>?0);
????????????}
????????});// 8)output = iterativeBody.filter;符合標準(時間過期了)的數據將跳出迭代,然后算法會調用WriteModel將LineModelData轉換為多條Row,轉發給下游operator(也就是在線預測階段);即定時把模型更新給在線預測階段。
????DataStream?output?=?iterativeBody.filter(new?FilterFunction>()?{@Overridepublic?boolean?filter(Tuple7?value)throws?Exception?{/*?if?value.f0?small?than?0,?then?output?*/return?value.f0?0;
????????????}
????????}).flatMap(new?WriteModel(labelType,?getVectorCol(),?featureCols,?hasInterceptItem));//?指定了某個流將成為迭代程序的結束,并且這個流將作為輸入的第二部分(second?input)被反饋回迭代
????iteration.closeWith(result);
????TableSchema?schema?=?new?LinearModelDataConverter(labelType).getModelSchema();
????......this.setOutput(output,?names,?types);return?this;
}為了方便閱讀,我們給出 訓練/預測 整體流程圖如下(這里省略了split 訓練數據集/測試數據集):
原諒我用這種辦法畫圖,因為我最討厭看到一篇好文,結果發現圖沒了…
--------------------------------------------------------------------------------------------
???????│??????????初始模型訓練階段??????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│
┌─────────────────┐??????????????????????????????┌─────────────────┐?
│?trainBatchData?????????????│??????????????????????????????│?trainStreamData?????????????│
└─────────────────┘??????????????????????????????└─────────────────┘?
???????│?????????????????????????????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│?
┌──────────────────┐????????????????????????????????????│?
│?featurePipeline??????????????│????????????????????????????????????│??
└──────────────────┘????????????????????????????????????│???
???????│?????????????????????????????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│
┌─────────────┐????????????????????????????????????????????│
│?線性回歸模型???????????│????????????????????????????????????????????│?
└─────────────┘?????????????????????????????????????????????│?
???????│?????????????????????????????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│
--------------------------------------------------------------------------------------------
???????│??????????在線訓練階段?????????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│
┌─────────────┐?????????????????????????????????┌──────────────────┐
│?dataBridge???????????│??加載初始化模型???????????????????│?featurePipeline??????????????│?
└─────────────┘?????????????????????????????????└──────────────────┘
???????│?????????????????????????????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│
┌─────────────┐??????????????????????????????┌──────────────────────────┐?
│?獲取切分信息???????????│?getSplitInfo?????????????????│?inputs[0].getDataStream()?????????????????│
└─────────────┘??????????????????????????????└──────────────────────────┘
???????│?????????????????????????????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│
???????│?????????????????????????????????????????????????????????????│
???????│??SplitInfo??????????????????????????????????????????????????│??
???????│?????????????????????????????????????????????????????????????│?
???????│?????????????????????????????????????????????????????????????│?
┌──────────────────────────┐??????特征向量??????????│?
│?SplitVector???????????????????????????????│?└──────────────────────────┘?
???????│?
???????│?解析輸入,得到DataStream>?input
???????│
???????│
┌───────────────────────────┐?
│??iteration???????????????????│?迭代構建,兩個輸入train?data:?Tuple5<>,feedback?data:?Tuple7<>
└───────────────────────────┘?
???????│?
???????│ CalcTask從邏輯上分成兩個模塊:flatMap1, flatMap2
???????│??
???????│????
┌─────────────┐??????????????????┌───────────┐?
│?CalcTask.flatMap1????│?輸入Tuple5<>?????│CalcTask.flatMap2??│?輸入Tuple7?└─────────────┘??????????????????└───────────┘??????????????????????????│
???????│?分布計算FTRL算法中的predict部分????????????│?分布處理反饋數據/更新參數/累積參數到期后發出??│
???????│?????????????????????????????????????????│???????????????????????????????????????│
???????│?????????????????????????????????????????│???????????????????????????????????????│
???????│???????│?以上兩個flatmap都輸出到下面ReduceTask???????????????????????????????????????????????│
???????│??????????????????????????????????????????????????????????????????????????????????│?
???????│??????????????????????????????????????????????????????????????????????????????????│?
┌─────────────┐??????????????????????????????????????????????????????????????????│
│?ReduceTask.flatMap???│?1.?如果時間過期&全部收集完成,歸并/輸出模型(value.f0?0)??????????????│
└─────────────┘?2.?未過期,歸并每個CalcTask計算的predict,形成一個?lable?y????????????│?
???????│??????????????????????????????????????????????????????????????????????????????????│?
???????│??????????????????????????????????????????????????????????????????????????????????│?
┌────────────┐???????????????????????????????????????????????????????????????????│?
│?result?=?filter????│??if?t3.f0?>?0?&&?t3.f2?>?0?or?not?????????????????????????????????│
└────────────┘???????????????????????????????????????????????????????????????????│
??????│???????????????????????????????????????????????????????????????????????????????????│?
??????│???????????????????????????????????????????????????????????????????????????????????│?
??????│???????????????????????????????????????????????????????????????????????????????????│
??????│?????if?t3.f0?>?0?&&?t3.f2?>?0?then???┌───────────┐???????????????????????│
??????│------------------------------------->│CalcTask.flatMap2??│輸出Tuple7?-------------
??????│"時間未過期&向量有意義"?將送回反饋,繼續迭代?└───────────┘
??????│?????
??????│??
??????│?如果未形成反饋數據流,則繼續過濾??
??????│??
??????│??
┌────────────┐?
│?output?=?filter????│?if?value.f0?small?than?0?or?not??
└────────────┘?
??????│?
??????│???????
??????│????if?value.f0?small?than?0,?then?output??
??????│????符合標準(時間過期了)的數據將跳出迭代,輸出模型
??????│?
??????│????????
┌────────┐?
│?WriteModel??│?因為filter?out,所以定期輸出模型
└────────┘?
??????│?
??????│???
--------------------------------------------------------------------------------------------
??????│???????????在線預測階段
??????│????????
??????│??????????????????????????????????????┌──────────┐?
??????│??????????????????????????????????????│?testStreamData??│
??????│??????????????????????????????????????└──────────┘
??????│?????????????????????????????????????????????│???????
??????│?????????????????????????????????????????????│??
??????│?????????????????????????????????????????????│???????????
┌──────────────┐??????????????????????┌───────────┐?
│?FTRL?Predict??????????│?└──────────────┘??????????????????????└───────────┘?????0xFF 參考
【機器學習】邏輯回歸(非常詳細)
邏輯回歸(logistics regression)
【機器學習】LR的分布式(并行化)實現
并行邏輯回歸
機器學習算法及其并行化討論
Online LR—— FTRL 算法理解
在線優化算法 FTRL 的原理與實現
LR+FTRL算法原理以及工程化實現
Flink流處理之迭代API分析
FTRL公式推導
FTRL論文筆記
在線機器學習FTRL(Follow-the-regularized-Leader)算法介紹
FTRL代碼實現
FTRL實戰之LR+FTRL(代碼采用的稠密數據)
在線學習算法FTRL-Proximal原理
基于FTRL的在線CTR預測算法
CTR預測算法之FTRL-Proximal
各大公司廣泛使用的在線學習算法FTRL詳解
在線最優化求解(Online Optimization)之五:FTRL
FOLLOW THE REGULARIZED LEADER (FTRL) 算法總結
)

















