點擊上方“AI派”,關注公眾號,選擇加“星標“或“置頂”
導讀只需要添加幾行代碼,就可以得到更快速,更省顯存的PyTorch模型。

你知道嗎,在1986年Geoffrey Hinton就在Nature論文中給出了反向傳播算法?
此外,卷積網絡最早是由Yann le cun在1998年提出的,用于數字分類,他使用了一個卷積層。但是直到2012年晚些時候,Alexnet才通過使用多個卷積層來實現最先進的imagenet。
那么,是什么讓他們現在如此出名,而不是之前呢?
只有在我們擁有大量計算資源的情況下,我們才能夠在最近的過去試驗和充分利用深度學習的潛力。
但是,我們是否已經足夠好地使用了我們的計算資源呢?我們能做得更好嗎?
這篇文章的主要內容是關于如何利用Tensor Cores和自動混合精度更快地訓練深度學習網絡。
什么是Tensor Cores?
根據NVIDIA的網站:
NVIDIA Turing和Volta GPUs都是由Tensor Cores驅動的,這是一項革命性的技術,提供了突破性的AI性能。Tensor Cores可以加速AI核心的大矩陣運算,在一次運算中就可以完成混合精度的矩陣乘法和累加運算。在一個NVIDIA GPU上有數百個Tensor Cores并行運行,這大大提高了吞吐量和效率。
簡單地說,它們是專門的cores,非常適合特定類型的矩陣操作。
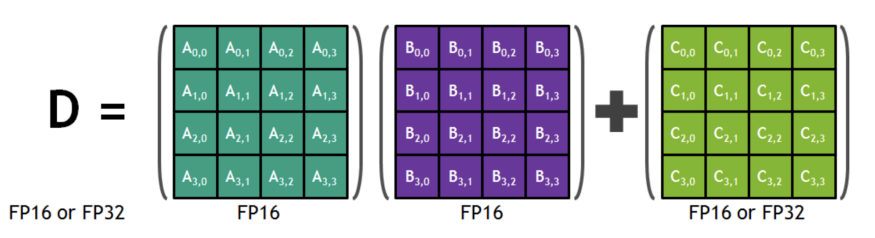
我們可以將兩個FP16矩陣相乘,并將其添加到一個FP16/FP32矩陣中,從而得到一個FP16/FP32矩陣。Tensor cores支持混合精度數學,即以半精度(FP16)進行輸入,以全精度(FP32)進行輸出。上述類型的操作對許多深度學習任務具有內在價值,而Tensor cores為這種操作提供了專門的硬件。
現在,使用FP16和FP32主要有兩個好處。
- FP16需要更少的內存,因此更容易訓練和部署大型神經網絡。它還只需要較少的數據移動。
- 數學運算在降低精度的Tensor cores運行得更快。NVIDIA給出的Volta GPU的確切數字是:FP16的125 TFlops vs FP32的15.7 TFlops(8倍加速)。
但也有缺點。當我們從FP32轉到FP16時,我們需要降低精度。

但是FP32真的有必要嗎?
實際上,FP16可以很好地表示大多數權重和梯度。所以存儲和使用FP32是很浪費的。
那么,我們如何使用Tensor Cores?
我檢查了一下我的Titan RTX GPU有576個tensor cores和4608個NVIDIA CUDA核心。但是我如何使用這些tensor cores呢?
坦白地說,NVIDIA用幾行代碼就能提供自動混合精度,因此使用tensor cores很簡單。我們需要在代碼中做兩件事:
- 需要用到FP32的運算比如Softmax之類的就分配用FP32,而Conv之類的操作可以用FP16的則被自動分配用FP16。

- 使用損失縮放 為了保留小的梯度值。梯度值可能落在FP16的范圍之外。在這種情況下,梯度值被縮放,使它們落在FP16范圍內。
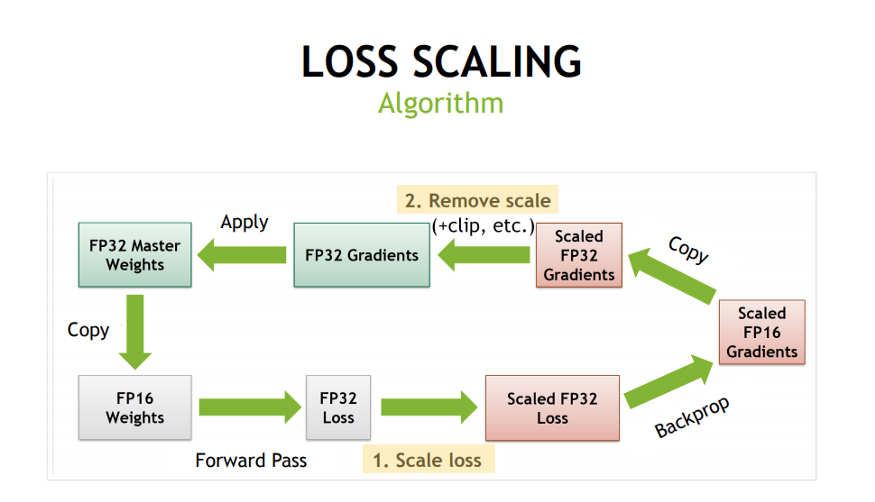
如果你還不了解背景細節也沒關系,代碼實現相對簡單。
使用PyTorch進行混合精度訓練:
讓我們從PyTorch中的一個基本網絡開始。
N,?D_in,?D_out?=?64,?1024,?512
x?=?torch.randn(N,?D_in,?device="cuda")
y?=?torch.randn(N,?D_out,?device="cuda")
model?=?torch.nn.Linear(D_in,?D_out).cuda()
optimizer?=?torch.optim.SGD(model.parameters(),?lr=1e-3)for?to?in?range(500):
???y_pred?=?model(x)
???loss?=?torch.nn.functional.mse_loss(y_pred,?y)
???optimizer.zero_grad()
???loss.backward()
???optimizer.step()為了充分利用自動混合精度訓練的優勢,我們首先需要安裝apex庫。只需在終端中運行以下命令。
$?git?clone?https://github.com/NVIDIA/apex$?cd?apex$?pip?install?-v?--no-cache-dir?--global-option="--cpp_ext"?--global-option="--cuda_ext"?./然后,我們只需向神經網絡代碼中添加幾行代碼,就可以利用自動混合精度(AMP)。
from?apex?import?amp
N,?D_in,?D_out?=?64,?1024,?512
x?=?torch.randn(N,?D_in,?device="cuda")
y?=?torch.randn(N,?D_out,?device="cuda")
model?=?torch.nn.Linear(D_in,?D_out).cuda()
optimizer?=?torch.optim.SGD(model.parameters(),?lr=1e-3)
model,?optimizer?=?amp.initialize(model,?optimizer,?opt_level="O1")for?to?in?range(500):
???y_pred?=?model(x)
???loss?=?torch.nn.functional.mse_loss(y_pred,?y)
???optimizer.zero_grad()
???with?amp.scale_loss(loss,?optimizer)?as?scaled_loss:
??????scaled_loss.backward()
???optimizer.step()在這里你可以看到我們用amp.initialize初始化了我們的模型。我們還使用amp.scale_loss來指定損失縮放。
基準測試
我們可以通過使用這個git倉庫:https://github.com/znxlwm/pytoring-apex-experiment來對amp的性能進行基準測試,它在CIFAR數據集上對VGG16模型進行基準測試。我只需要修改幾行代碼就可以了。你可以在這里找到修改后的版本:https://github.com/MLWhiz/data_science_blogs/tree/master/amp。要運行自己的基準代碼,你需要:
git?clone?https://github.com/MLWhiz/data_science_blogs
cd?data_science_blogs/amp/pytorch-apex-experiment/
python?run_benchmark.py
python?make_plot.py?--GPU?'RTX'?--method?'FP32'?'FP16'?'amp'?--batch?128?256?512?1024?2048這會在home目錄中生成下面的圖:
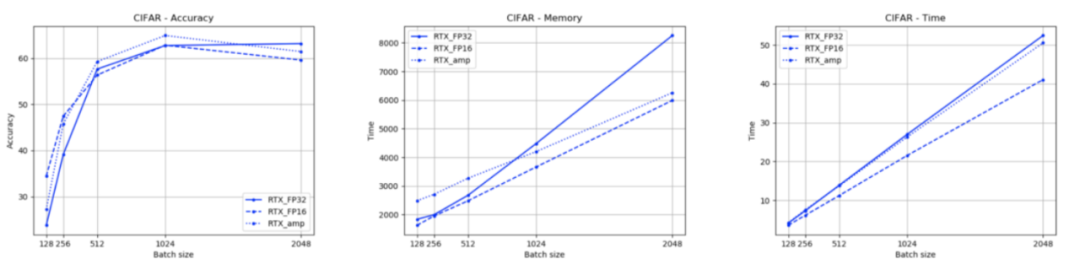
在這里,我使用不同的精度和批大小設置訓練了同一個模型的多個實例。我們可以看到,從FP32到amp,內存需求減少,而精度保持大致相同。時間也會減少,但不會減少那么多。這可能是由于數據集或模型太簡單。
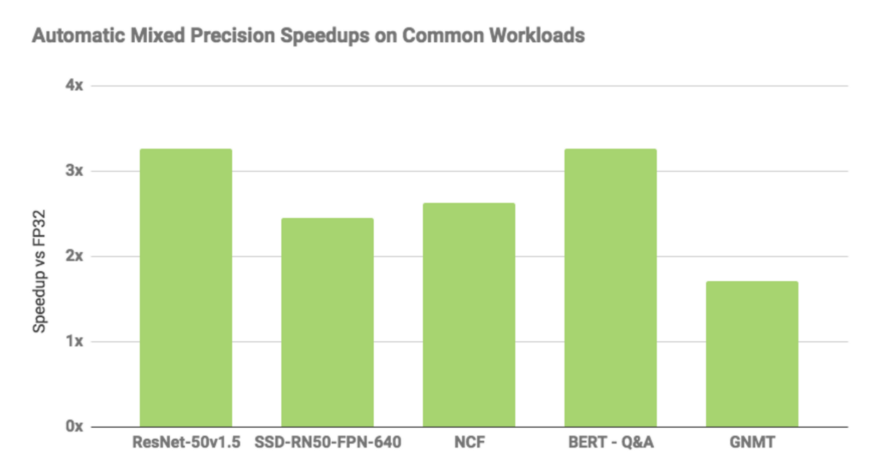
根據NVIDIA給出的基準測試,AMP比標準的FP32快3倍左右,如下圖所示。
 —END—文末福利各位猿們,還在為記不住API發愁嗎,哈哈哈,最近發現了國外大師整理了一份Python代碼速查表和Pycharm快捷鍵sheet,火爆國外,這里分享給大家。這個是一份Python代碼速查表
—END—文末福利各位猿們,還在為記不住API發愁嗎,哈哈哈,最近發現了國外大師整理了一份Python代碼速查表和Pycharm快捷鍵sheet,火爆國外,這里分享給大家。這個是一份Python代碼速查表
怎樣獲取呢?可以添加我們的AI派團隊的程序媛姐姐
一定要備注【高清圖】哦
?????

?我們的程序媛小姐姐微信要記得備注【高清圖】哦








——(基本材質))






...)


