一、文件讀取
- Client向NameNode發起RPC請求,來確定請求文件block所在的位置;
- NameNode會視情況返回文件的部分或者全部block列表,對于每個block,NameNode 都會返回含有該 block
副本的 DataNode 地址; 這些返回的 DN 地址,會按照集群拓撲結構得出 DataNode
與客戶端的距離,然后進行排序,排序兩個規則:網絡拓撲結構中距離 Client 近的排靠前;心跳機制中超時匯報的 DN 狀態為
STALE,這樣的排靠后; - Client 選取排序靠前的 DataNode 來讀取
block,如果客戶端本身就是DataNode,那么將從本地直接獲取數據(短路讀取特性); - 底層上本質是建立 Socket Stream(FSDataInputStream),重復的調用父類 DataInputStream
的 read 方法,直到這個塊上的數據讀取完畢; - 當讀完列表的 block 后,若文件讀取還沒有結束,客戶端會繼續向NameNode 獲取下一批的 block 列表;
- 讀取完一個 block 都會進行 checksum 驗證,如果讀取 DataNode 時出現錯誤,客戶端會通知
NameNode,然后再從下一個擁有該 block 副本的DataNode 繼續讀。 - read 方法是并行的讀取 block 信息,不是一塊一塊的讀取;NameNode
只是返回Client請求包含塊的DataNode地址,并不是返回請求塊的數據; - 最終讀取來所有的 block 會合并成一個完整的最終文件。
二、文件寫入

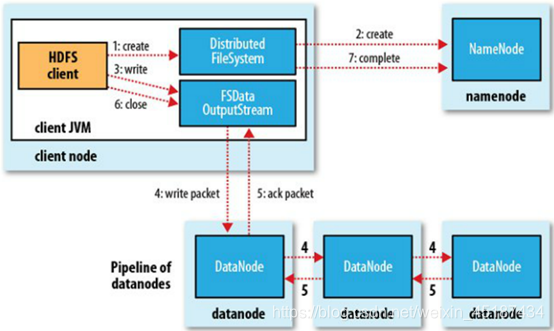
1.client發起文件上傳請求,通過RPC與NameNode建立通訊,NameNode檢查目標文件是否已存在,父目錄是否存在,返回是否可以上傳;
2. client請求第一個block該傳輸到哪些DataNode服務器上;
3. NameNode根據配置文件中指定的備份數量及機架感知原理進行文件分配,返回可用的DataNode的地址如:A,B,C;
注:Hadoop在設計時考慮到數據的安全與高效,數據文件默認在HDFS上存放三份,存儲策略為本地一份,同機架內其它某一節點上一份,不同機架的某一節點上一份。
4. client請求3臺DataNode中的一臺A上傳數據(本質上是一個RPC調用,建立pipeline),A收到請求會繼續調用B,然后B調用C,將整個pipeline建立完成,后逐級返回client;
5. client開始往A上傳第一個block(先從磁盤讀取數據放到一個本地內存緩存),以packet為單位(默認64K),A收到一個packet就會傳給B,B傳給C;A每傳一個packet會放入一個應答隊列等待應答。
6. 數據被分割成一個個packet數據包在pipeline上依次傳輸,在pipeline反方向上,逐個發送ack(命令正確應答),最終由pipeline中第一個DataNode節點A將pipelineack發送給client;
7. 當一個block傳輸完成之后,client再次請求NameNode上傳第二個block到服務器。



















