一、Hive 架構
下面是Hive的架構圖。
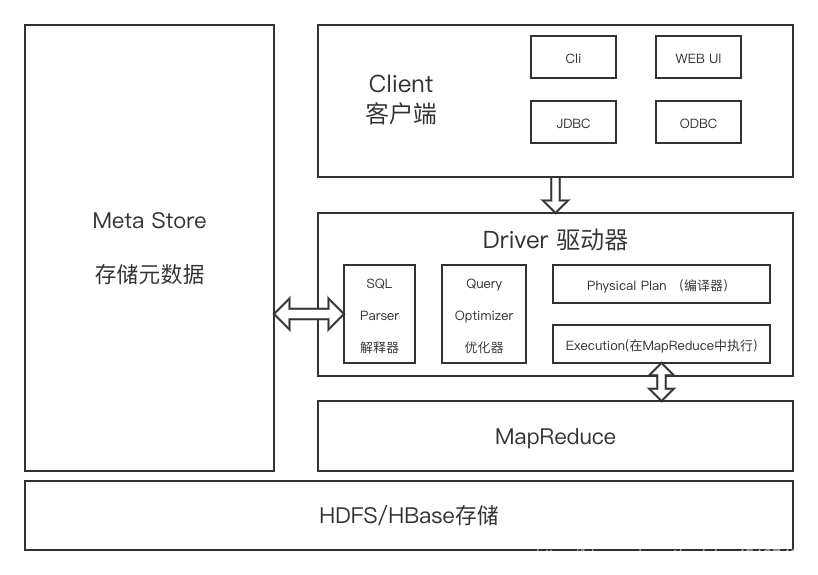
Hive的體系結構可以分為以下幾部分
1、用戶接口:CLI(hive shell);JDBC(java訪問Hive);WEBUI(瀏覽器訪問Hive)
2、元數據:MetaStore
元數據包括:表名、表所屬的數據庫(默認是default)、表的擁有者、列/分區字段,標的類型(表是否為外部表)、表的數據所在目錄。這是數據默認存儲在Hive自帶的derby數據庫中,推薦使用MySQL數據庫存儲MetaStore。
3、Hadoop集群:
使用HDFS進行存儲數據,使用MapReduce進行計算。
4、Driver:驅動器:
- 解析器(SQL Parser):將SQL字符串換成抽象語法樹AST,對AST進行語法分析,像是表是否存在、字段是否存在、SQL語義是否有誤。
- 編譯器(Physical Plan):將AST編譯成邏輯執行計劃。
- 優化器(Query Optimizer):將邏輯計劃進行優化。
- 執行器(Execution):把執行計劃轉換成可以運行的物理計劃。對于Hive來說默認就是Mapreduce任務。
二、Hive 工作原理
? Hive 工作原理如下圖所示。
1、ExecuteQuery:操作Hive接口,如命令行或Web UI發送查詢驅動程序(任何數據庫驅動程序,如JDBC,ODBC等)來執行。
2、Get Plan:在驅動程序幫助下查詢編譯器,分析查詢檢查語法和查詢計劃或查詢的要求。
3、Get Metadata:編譯器發送元數據請求到Metastore(任何數據庫)。
4、Send Metadata:Metastore發送元數據,以編譯器的響應。
5、Send Plan:編譯器檢查要求,并重新發送計劃給驅動程序。到此為止,查詢解析和編譯完成。
6、Execute Plan:驅動程序發送的執行計劃到執行引擎。
-
Execute Job:在內部,執行作業的過程是一個MapReduce工作。執行引擎發送作業給JobTracker,在名稱節點并把它分配作業到TaskTracker,這是在數據節點。在這里,查詢執行MapReduce工作。 -
Metadata Ops:與此同時,在執行時,執行引擎可以通過Metastore執行元數據操作。
7、Fetch Result:執行引擎接收來自數據節點的結果。
8、Send Results:執行引擎發送這些結果值給驅動程序。


















)
