當需要處理的數據量超過了單機尺度(比如我們的計算機有4GB的內存,而我們需要處理100GB以上的數據)這時我們可以選擇spark集群進行計算,有時我們可能需要處理的數據量并不大,但是計算很復雜,需要大量的時間,這時我們也可以選擇利用spark集群強大的計算資源,并行化地計算
一、架構及生態
架構示意圖如下:
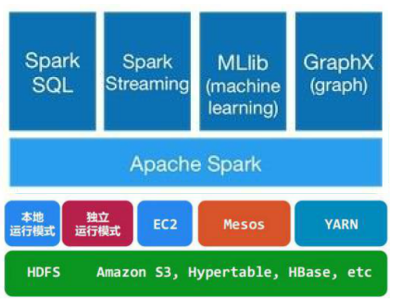
- Spark Core:實現了 Spark 的基本功能,包含任務調度、內存管理、錯誤恢復、與存儲系統交互等模塊。SparkCore 中還包含了對彈性分布式數據集(Resilient Distributed DataSet,簡稱RDD)的API定義。
- Spark SQL:是 Spark 用來操作結構化數據的程序包。通過SparkSql,我們可以使用 SQL或者Apache Hive 版本的 SQL 方言(HQL)來查詢數據。Spark SQL 支持多種數據源,比如 Hive 表、Parquet 以及 JSON 等。
- Spark Streaming:是 Spark 提供的對實時數據進行流式計算的組件。提供了用來操作數據流的 API,并且與 Spark Core 中的 RDD API 高度對應。
- Spark MLlib:提供常見的機器學習 (ML) 功能的程序庫。包括分類、回歸、聚類、協同過濾等,還提供了模型評估、數據導入等額外的支持功能。
- GraphX:控制圖、并行圖操作和計算的一組算法和工具的集合。GraphX擴展了RDD API,包含控制圖、創建子圖、訪問路徑上所有頂點的操作。
Spark架構的組成圖如下:
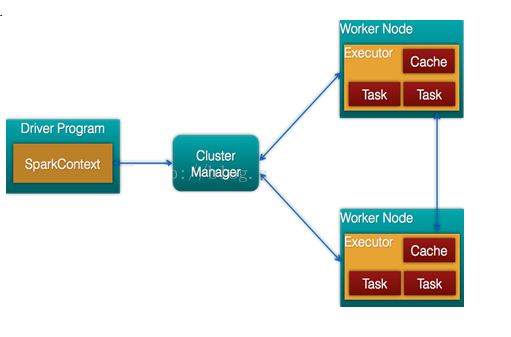
- Cluster Manager:Spark 設計為可以高效地在一個計算節點到數千個計算節點之間伸縮計算,為了實現這樣的要求,同時獲得最大靈活性,Spark 支持在各種集群管理器(Cluster Manager)上運行,目前 Spark 支持 3 種集群管理器:
- Hadoop YARN(在國內使用最廣泛)
- Apache Mesos(國內使用較少, 國外使用較多)
- Standalone(Spark 自帶的資源調度器, 需要在集群中的每臺節點上配置 Spark)
- Worker節點:從節點,負責控制計算節點,啟動Executor或者Driver。
- Driver: 運行Application 的main()函數
- Executor:執行器,是為某個Application運行在worker node上的一個進程
二、Spark運行架構
基本概念:RDD、DAG、Executor、Application、Task、Job、Stage
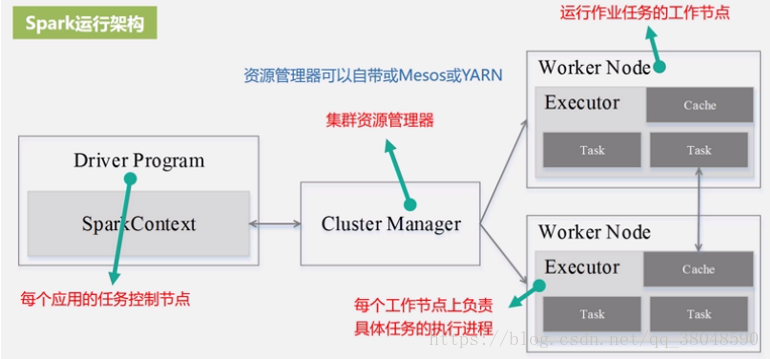
-
RDD:彈性分布式數據集的簡稱,是分布式內存的一個抽象概念 ,提供了一個高度共享的內存模型。
-
Worker Node:物理節點,上面執行executor進程
-
Executor:Worker Node為某應用啟動的一個進程,執行多個tasks
-
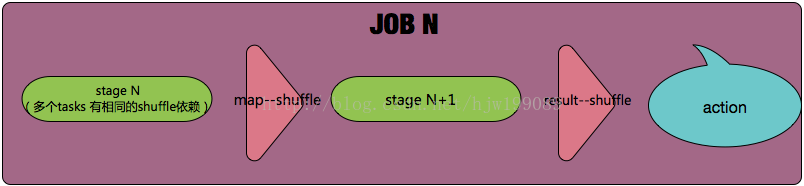
Jobs:action 的觸發會生成一個job, Job會提交給DAGScheduler,分解成Stage,
-
Stage:DAGScheduler 根據shuffle將job劃分為不同的stage,同一個stage中包含多個task,這些tasks有相同的 shuffle dependencies。
? 有兩類shuffle map stage和result stage:
? shuffle map stage:case its tasks’ results are input for other stage(s)
? result stage:case its tasks directly compute a Spark action (e.g. count(), save(), etc) by running a function on an RDD,輸入與結果間劃分stage
- Task:被送到executor上的工作單元,task簡單的說就是在一個數據partition上的單個數據處理流程。
action觸發一個job (task對應在一個partition上的數據處理流程)
------stage1(多個tasks 有相同的shuffle依賴)------【map–shuffle】------- stage2---- 【result–shuffle】-----