spark的集群主要有三種運行模式standalone、yarn、mesos,其中常被使用的是standalone和yarn,本文了解一下什么是standalone運行模式,并嘗試搭建一個standalone集群

一、standalone模式
standalone模式,是spark自己實現的,它是一個資源調度框架。這里我們要關注這個框架的三個節點:
- client
- master
- worker
spark應用程序有一個Driver驅動,Driver可以運行在Client上也可以運行在master上。如果你使用spark-shell去提交job的話它會是運行在master上的,如果你使用spark-submit或者IDEA開發工具方式運行,那么它是運行在Client上的。這樣我們知道了,Client的主體作用就是運行Driver。而master除了資源調度的作用還可以運行Driver。
再關注master和worker節點,standalone是一個主從模式,master節點負責資源管理,worker節點負責任務的執行。
standalone的是spark默認的運行模式,它的運行流程主要就是把程序代碼解析成dag結構,并再細分到各個task提交給executor線程池去并行計算
二、運行流程
了解standalone主要節點之后,我們看一下它的運行流程,如圖:
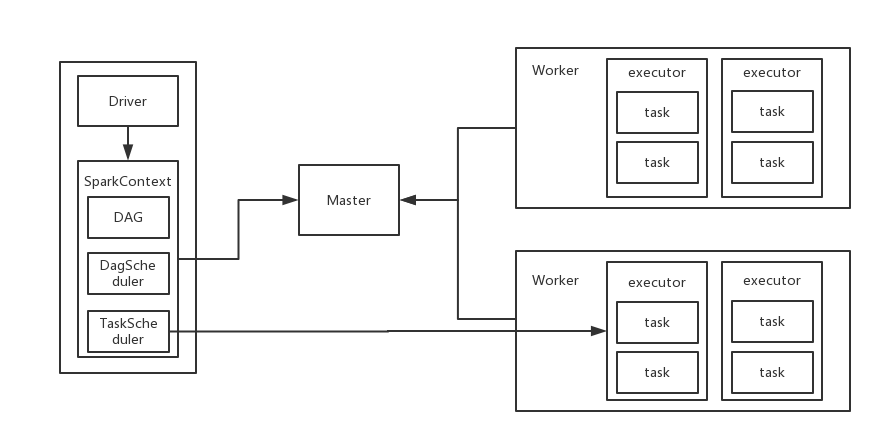
1)當spark集群啟動以后,worker節點會有一個心跳機制和master保持通信;
2)SparkContext連接到master以后會向master申請資源,而master會根據worker心跳來分配worker的資源,并啟動worker的executor進程;
3)SparkContext將程序代碼解析成dag結構,并提交給DagScheduler;
4)dag會在DagScheduler中分解成很多stage,每個stage包含著多個task;
5)stage會被提交給TaskScheduler,而TaskScheduler會將task分配到worker,提交給executor進程,executor進程會創建線程池去執行task,并且向SparkContext報告執行情況,直到task完成;
6)所有task完成以后,SparkContext向Master注銷并釋放資源;
三、standalone集群搭建
3.0、準備條件
機器(默認配置好了主機名、映射和免密登錄)
| hostname | 系統版本 |
|---|---|
| master | CentOS7.6 |
| slave1 | CentOS7.6 |
| slave2 | CentOS7.6 |
3.1、sbin/spark-config.sh
在spark-config.sh文件中配置JAVAHOME
vi spark-config.sh- 添加內容
export JAVA_HOME=/usr/local/apps/java/jdk1.8
3.2、conf/spark-env.sh
cp spark-env.sh.template spark-env.shvi spark-env.sh- 添加以下內容
export JAVA_HOME=/usr/local/apps/java/jdk1.8
export SCALA_HOME=/usr/local/apps/scala/scala-2.12.2
export SPARK_MASTER_HOST=master
export SPARK_WORKER_MEMORY=25g
export SPARK_WORKER_CORES=34
export SPARK_LOCAL_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_LOCAL_IP=master
其中SPARK_LOCAL_IP要配置為當前主機的hostname
3.3、conf/slaves
cp slaves.template slaves- 添加作為worker的機器地址
slave1
slave2
3.4、啟動 Spark 集群
$ sbin/start-all.sh
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-fmreEthG-1609913096682)(image/image3.png)]
3.5、jps查看
使用jps命令查看進程master下會有maser進程,slave下會有worker進程



















