
從PDF文件獲取表格中的數據,也是日常辦公容易涉及到的一項工作。一個一個復制吧,效率確實太低了。用Python從PDF文檔中提取表格數據,并寫入Excel文件,灰常灰常高效
 。
。
上市公司的年報往往包含幾百張表格,用它作為例子再合適不過,搞定這個,其他含表格的PDF都是小兒科了。今天以"保利地產年報"為例,這個PDF文檔中有321頁含有表格,總表格數超過這個數了。?先導入PDF讀取模塊pdfplumber,隨便挑一頁看下表格數據的結構。如下,我們挑了第4頁pages[3]來讀取其中的表格,并顯示。這里讀取表格,用到了extract_tables(),即默認每頁有多個表格。它會將單個表格的數據按行讀取存入列表,再將每個表格的所有數據匯總存到一個上一級列表,最后將所有表格的數據匯總到一個大列表。而extract_table()方法則只能讀一張表,當一個頁面有多張表,就默認選第一個,因此會漏掉后面的。而且它們的數據結構也不同,差異如下。

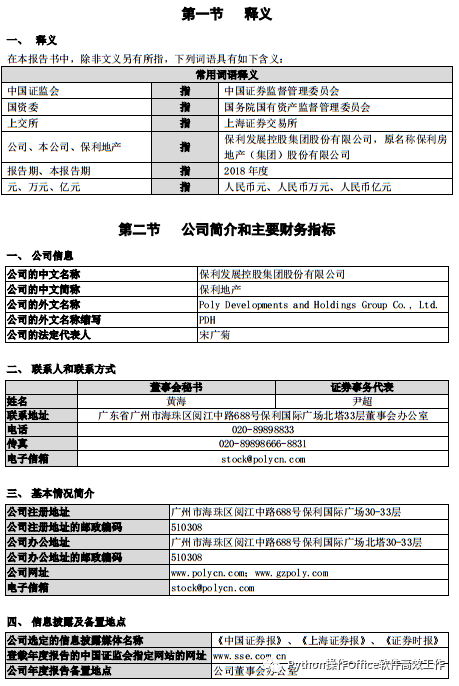
“保利地產年報”第四頁如圖所示,讀取的結果存到列表table,顯示如下。
#觀察讀取出來的表格的數據結構
import?pdfplumber
with?pdfplumber.open("保利地產年報.pdf")?as?p:
????page?=?p.pages[3]?#選取第4頁(起始頁為0)
????table?=?page.extract_tables()?#多表格讀取,存為嵌套列表
????print(table)
[[['',?'常用詞語釋義',?None,?None,?None,?None,?None,?''],?['中國證監會',?None,?'',?'指',?'',?'',?'中國證券監督管理委員會',?''],?['國資委',?None,?'',?'指',?'',?'',?'國務院國有資產監督管理委員會',?''],?['上交所',?None,?'',?'指',?'',?'上海證券交易所',?None,?None],?['公司、本公司、保利地產',?None,?'指',?None,?None,?'保利發展控股集團股份有限公司,原名稱保利房\n地產(集團)股份有限公司',?None,?None],?['報告期、本報告期',?None,?'',?'指',?'',?'2018年度',?None,?None],?['元、萬元、億元',?None,?'',?'指',?'',?'人民幣元、人民幣萬元、人民幣億元',?None,?None]],?[['公司的中文名稱',?'保利發展控股集團股份有限公司'],?['公司的中文簡稱',?'保利地產'],?['公司的外文名稱',?'Poly?Developments?and?Holdings?Group?Co.,?Ltd.'],?['公司的外文名稱縮寫',?'PDH'],?['公司的法定代表人',?'宋廣菊']],?[['',?'董事會秘書',?'證券事務代表'],?['姓名',?'黃海',?'尹超'],?['聯系地址',?'廣東省廣州市海珠區閱江中路688號保利國際廣場北塔33層董事會辦公室',?None],?['電話',?'020-89898833',?None],?['傳真',?'020-89898666-8831',?None],?['電子信箱',?'stock@polycn.com',?None]],?[['公司注冊地址',?'廣州市海珠區閱江中路688號保利國際廣場30-33層'],?['公司注冊地址的郵政編碼',?'510308'],?['公司辦公地址',?'廣州市海珠區閱江中路688號保利國際廣場北塔30-33層'],?['公司辦公地址的郵政編碼',?'510308'],?['公司網址',?'www.polycn.com;www.gzpoly.com'],?['電子信箱',?'stock@polycn.com']],?[['公司選定的信息披露媒體名稱',?'《中國證券報》、《上海證券報》、《證券時報》'],?['登載年度報告的中國證監會指定網站的網址',?'www.sse.com.cn'],?['公司年度報告備置地點',?'公司董事會辦公室']]]

確保可正常讀取表格,以及了解讀取出來的表格的數據結構,下面就可以一次性讀取出所有表格,并存入Excel文件中了。導入相應模塊,然后使用pdfplumber打開PDF文件。使用Workbook()新建Excel工作簿,然后使用remove()將其自帶的工作表刪除。因為我們想用PDF文件中表格所在的頁碼給相應的Excel工作表命名,以便二者的編號一致,方便后續查詢。所以需要使用enumerate()給PDF的頁從1開始編號。然后使用extract_tables()獲取表格數據。?當然,如果當頁沒有表格,則extract_tables()獲得的是空值None。在后續的操作中,空值會報錯,所以加入if語句來做個判斷。只有當列表tables不為空,即里面有貨的時候,才建新的Excel表格,并執行后續的寫入操作。列表tables若為空(即當頁沒有表格),則直接跳到下一頁。?當發現當頁有表格后,新建一個Excel表,以“Sheet”加上此時PDF的頁碼(比如“Sheet3”)命名。在寫入數據時,先用一個for循環獲得單個表格的數據,再用第二個for循環獲得表格中一行的數據,然后寫入Excel表。最后保存數據。由于表格太多,程序運行時間較長,大約需要3分鐘。
import?pdfplumber
from?openpyxl?import?Workbook????
with?pdfplumber.open("保利地產年報.pdf")?as?p:
????wb?=?Workbook()?#新建excel工作簿
????wb.remove(wb.worksheets[0])#刪除工作簿自帶的工作表
????for?index,page?in?enumerate(p.pages,start?=?1):?#從1開始給所有頁編號
????????tables?=?page.extract_tables()?#讀取表格
????????if?tables:?#判斷是否存在表格,若不存在,則不執行下面的語句
????????????ws?=?wb.create_sheet(f"Sheet{index}")?#新建工作表,表名的編號與表在PDF中的頁碼一致
????????????for?table?in?tables:?#遍歷所有列表
????????????????for?row?in?table:?#遍歷列表中的所有子列表,里面保存著行數據
????????????????????ws.append(row)?#寫入excel表
????wb.save("保利地產年報表格.xlsx")
數百個表格就這樣瀟灑地復制到Excel表格中了 。
。
如果想要指定某個表格,在提取數據的時候指定頁碼即可。但如果想批量導出大量不同公司的年報的指定表格,則需要使用關鍵詞定位了。還好,無論深圳市場還是上海市場,公司的年報中的標題基本都是唯一的,這給我們用標題做關鍵詞提供了方便。假設我們需要提取公司“主要會計數據”下面的表格,則用關鍵詞“主要會計數據”定位即可。如下以此為例進行操作。
import?os
import?pdfplumber
from?openpyxl?import?Workbook????
path='PDF'??#文件所在文件夾
files?=?[path+"\\"+i?for?i?in?os.listdir(path)]?#獲取文件夾下的文件名,并拼接完整路徑
key_words?=?"主要會計數據"
for?file?in?files:
????with?pdfplumber.open(file)?as?p:
????????wb?=?Workbook()?#新建excel工作簿
????????wb.remove(wb.worksheets[0])#刪除工作簿自帶的工作表
????????#獲取關鍵詞所在頁及下一頁的頁碼
????????pages_wanted?=?[]
????????for?index,page?in?enumerate(p.pages):?#從0開始給所有頁編號
????????????if?key_words?in?page.extract_text():
????????????????pages_wanted.append(index)
????????????????pages_wanted.append(index+1)
????????????????break
????????#提取指定頁碼里的表格
????????for?i?in?pages_wanted:?????
????????????page?=?p.pages[i]
????????????tables?=?page.extract_tables()?#讀取表格
????????????if?tables:?#判斷是否存在表格,若不存在,則不執行下面的語句
????????????????ws?=?wb.create_sheet(f"Sheet{i+1}")?#新建工作表,表名的編號與表在PDF中的頁碼一致
????????????????for?table?in?tables:?#遍歷所有列表
????????????????????for?row?in?table:?#遍歷列表中的所有子列表,里面保存著行數據
????????????????????????ws.append(row)?#寫入excel表
????????wb.save("Excel\\{}.xlsx".format(file.split("\\")[1].split(".")[0]))
以上,增加了一段獲取關鍵詞所在頁碼及下一頁的頁碼的程序。之所以要獲取關鍵詞下一頁頁碼,是因為有些表格會跨頁,為了不遺漏數據,寧愿多獲取一點。一旦找到關鍵詞所在頁,馬上用break停止for循環。后面再遍歷pages_wanted里面儲存的頁碼,提取表格并寫入Excel文件,并保存即可。批量獲取的指定內容保存在Excel文件夾下。

如果您有需要處理的問題,可發郵件到我郵箱:donyo@qq.com,一起探討解決方案。微信公眾號輸入“源文件”提取所有源文件及資料。

最好的贊賞就是點亮下方“在看”,多給PythonOffice積攢一點人氣哈!

、最大后驗概率估計(MAP),以及貝葉斯公式的理解)



)

生成模型簡介)




設置)






