目錄
礦物數據項目介紹:
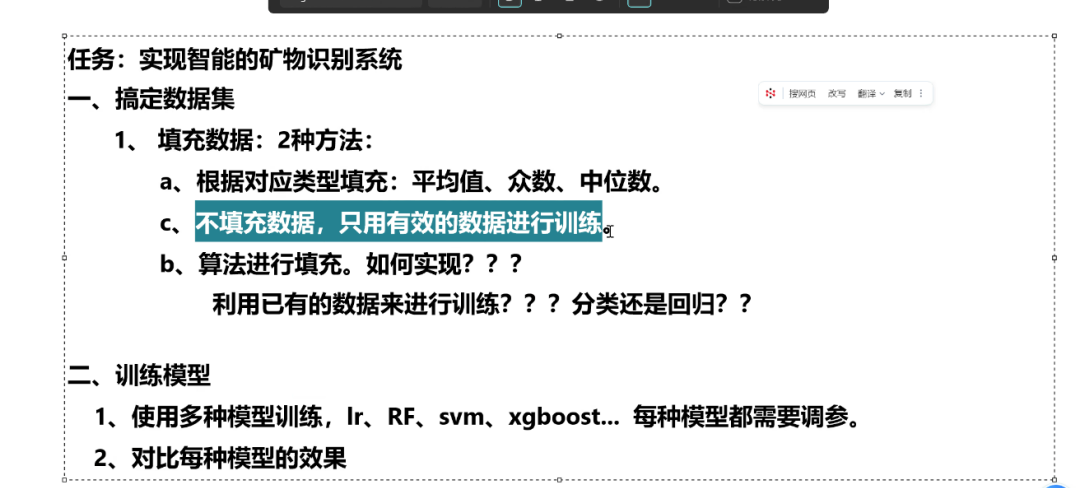
數據問題與處理方案:
數據填充策略討論:
模型選擇與任務類型:
模型訓練計劃:
一.數據集填充
1.讀取數據
2.把標簽轉化為數值
3.把異常數據轉化為nan
4.數據Z標準化
5.劃分訓練集測試集
6.創建一個新的fill_data.py文件,用來存放填充訓練數據和填充測試數據的方法
方法①:刪除有缺失值的行
方法②:平均值填充處理(測試集用訓練集對應的平均值來填充)
方法③:中位數填充處理(測試集用訓練集對應的中位數來填充)
方法④:眾數填充處理(測試集用訓練集對應的眾數來填充)
7.調用填充方法,生成各自方法填充后的數據,并保存到各自的excel文件中
礦物數據項目介紹:
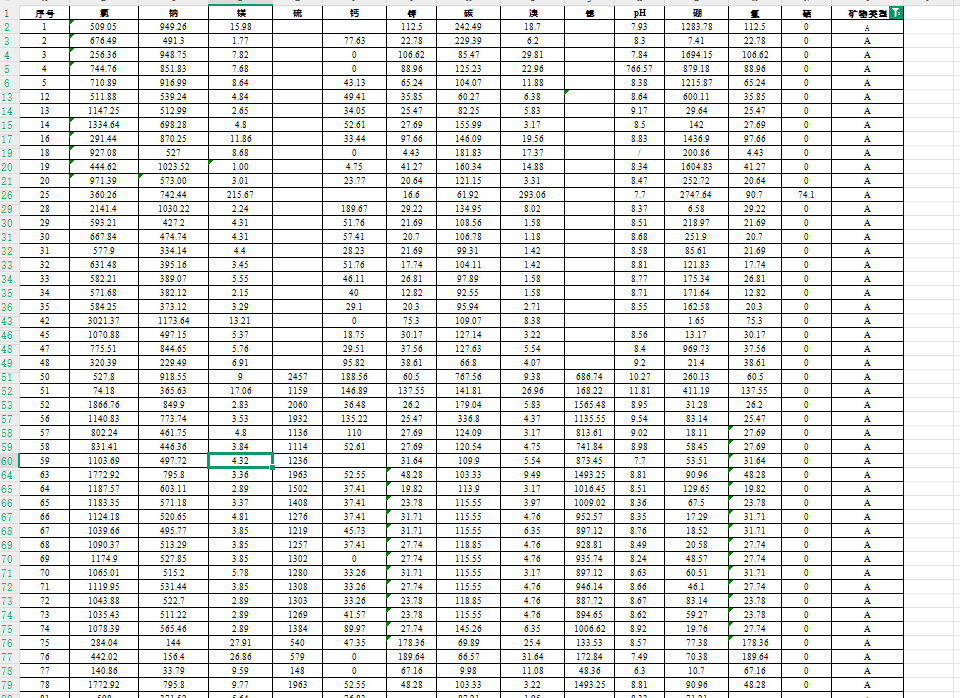
數據類型:每行記錄礦物微量元素(氯、鈉、鎂等)及類別(A/B/C/D/E)(注意:發現類別 E 僅有一條數據,無法用于模型訓練,所以我們應該刪除該數據)
任務目標:構建分類模型,通過微量元素自動識別礦物類型(A/B/C/D)
數據問題與處理方案:
異常值:如“7.97”(應為7.97)、“41.12”(應為41.12)等輸入錯誤,需手動修正。
缺失值填充:
方法A:按類別分組填充(如A類用A類均值/眾數/中位數)。
方法B:智能填充(如邏輯回歸、隨機森林等算法預測缺失值)。
特征工程:特征數量較少(約10個),無需降維。
發現數據中存在隱藏空格(如“思”列),導致NaN檢測失敗,需手動清理空格干擾。
其他問題:斜杠(如PH值列)、單一類別數據列(如“異”列)需刪除或特殊處理。
數據填充策略討論:
優先填充缺失值最少的列(如F列僅缺3個值),以增加完整數據量,便于后續預測其他列(如K列)。
填充順序:從缺失少的列到缺失多的列,以提高填充準確性。
強調利用已有數據(包括部分缺失的數據)進行訓練,而非僅依賴完全完整的數據。
模型選擇與任務類型:
確定當前任務為回歸問題(因預測目標Y為連續型數據)。
可用回歸模型包括:SVR(SVM變體)、KNN、隨機森林、線性回歸等。
模型訓練計劃:
多模型對比:嘗試邏輯回歸、隨機森林、支持向量機、XGBoost等,調參后評估效果(準確率、召回率等)。
步驟:
數據預處理(清洗、填充缺失值)。
分模型訓練與調參(交叉驗證)。
生成對比表格,選擇最優模型。
=========================================================================
下面我們先用四種方法來填充數據分別是刪除空白數據行處理,平均值填充處理,中位數填充處理,眾數填充處理
一.數據集填充
部分數據如下
1.讀取數據
刪除僅有一行數據的‘E’類數據,并刪除無關列‘序號’
import pandas as pd
data=pd.read_excel('礦物數據.xlsx')
data=data[data['礦物類型']!='E']
data=data.drop('序號',axis=1)
x_whole=data.iloc[:,:-1]
y_whole=data.iloc[:,-1]2.把標簽轉化為數值
把礦物類型A,B,C,D類轉化成機器可讀的數字1,2,3,4
labels_dict={'A':1,'B':2,'C':3,'D':4}
en_labels=[labels_dict[label] for label in data['礦物類型']]
y_whole=pd.Series(en_labels,name='礦物類型')3.把異常數據轉化為nan
用pandas庫將可以轉化為數字類型的數據轉化為數字,不能轉化的數據寫為nan
# 異常數據轉化為nan
for column_name in x_whole.columns:x_whole[column_name]=pd.to_numeric(x_whole[column_name],errors='coerce')4.數據Z標準化
#對數據Z標準化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
X_whole_Z=scaler.fit_transform(x_whole)
X_whole_Z=pd.DataFrame(X_whole_Z,columns=x_whole.columns)5.劃分訓練集測試集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(X_whole_Z,y_whole)6.創建一個新的fill_data.py文件,用來存放填充訓練數據和填充測試數據的方法
方法①:刪除有缺失值的行
import pandas as pd
#只保留完整數據集
def cca_train_fill(x_train,y_train):data=pd.concat([x_train,y_train],axis=1)data=data.reset_index(drop=True)data=data.dropna()return data.iloc[:,:-1],data.iloc[:,-1]
def cca_test_fill(x_test,y_test):data=pd.concat([x_test,y_test],axis=1)data=data.reset_index(drop=True)data=data.dropna()return data.iloc[:,:-1],data.iloc[:,-1]方法②:平均值填充處理(測試集用訓練集對應的平均值來填充)
由于每一類的平均值都要分開處理所以我們先將每一類分別提取出來
def mean_train_fill(x_train,y_train):data=pd.concat([x_train,y_train],axis=1)data=data.reset_index(drop=True)A=data[data['礦物類型']==1]B=data[data['礦物類型']==2]C=data[data['礦物類型']==3]D=data[data['礦物類型']==4]A=mean_method_train(A)B=mean_method_train(B)C=mean_method_train(C)D=mean_method_train(D)data=pd.concat([A,B,C,D])return data.drop('礦物類型',axis=1),data['礦物類型']
def mean_test_fill(x_train,y_train,x_test,y_test):data_train = pd.concat([x_train, y_train], axis=1)data_train = data_train.reset_index(drop=True)A_train = data_train[data_train['礦物類型'] == 1]B_train = data_train[data_train['礦物類型'] == 2]C_train = data_train[data_train['礦物類型'] == 3]D_train = data_train[data_train['礦物類型'] == 4]data_test = pd.concat([x_test, y_test], axis=1)data_test = data_test.reset_index(drop=True)A_test = data_test[data_test['礦物類型'] == 1]B_test = data_test[data_test['礦物類型'] == 2]C_test = data_test[data_test['礦物類型'] == 3]D_test = data_test[data_test['礦物類型'] == 4]A_test=mean_method_test(A_train,A_test)B_test = mean_method_test(B_train, B_test)C_test = mean_method_test(C_train,C_test)D_test = mean_method_test(D_train, D_test)data = pd.concat([A_test, B_test, C_test, D_test])return data.drop('礦物類型', axis=1), data['礦物類型']def mean_method_train(data):fill_values=data.mean()data=data.fillna(fill_values)return data
def mean_method_test(train_data,test_data):fill_values=train_data.mean()test_data=test_data.fillna(fill_values)return test_data方法③:中位數填充處理(測試集用訓練集對應的中位數來填充)
def median_train_fill(x_train,y_train):data = pd.concat([x_train, y_train], axis=1)data = data.reset_index(drop=True)A = data[data['礦物類型'] == 1]B = data[data['礦物類型'] == 2]C = data[data['礦物類型'] == 3]D = data[data['礦物類型'] == 4]A = median_method_train(A)B = median_method_train(B)C = median_method_train(C)D = median_method_train(D)data = pd.concat([A, B, C, D])return data.drop('礦物類型', axis=1), data['礦物類型']
def median_test_fill(x_train,y_train,x_test,y_test):data_train = pd.concat([x_train, y_train], axis=1)data_train = data_train.reset_index(drop=True)A_train = data_train[data_train['礦物類型'] == 1]B_train = data_train[data_train['礦物類型'] == 2]C_train = data_train[data_train['礦物類型'] == 3]D_train = data_train[data_train['礦物類型'] == 4]data_test = pd.concat([x_test, y_test], axis=1)data_test = data_test.reset_index(drop=True)A_test = data_test[data_test['礦物類型'] == 1]B_test = data_test[data_test['礦物類型'] == 2]C_test = data_test[data_test['礦物類型'] == 3]D_test = data_test[data_test['礦物類型'] == 4]A_test=median_method_test(A_train,A_test)B_test = median_method_test(B_train, B_test)C_test = median_method_test(C_train,C_test)D_test = median_method_test(D_train, D_test)data = pd.concat([A_test, B_test, C_test, D_test])return data.drop('礦物類型', axis=1), data['礦物類型']
def median_method_train(data):fill_values = data.median()data = data.fillna(fill_values)return data
def median_method_test(train_data,test_data):fill_values=train_data.median()test_data=test_data.fillna(fill_values)return test_data方法④:眾數填充處理(測試集用訓練集對應的眾數來填充)
def mode_train_fill(x_train,y_train): data = pd.concat([x_train, y_train], axis=1)data = data.reset_index(drop=True)A = data[data['礦物類型'] == 1]B = data[data['礦物類型'] == 2]C = data[data['礦物類型'] == 3]D = data[data['礦物類型'] == 4]A = mode_method_train(A)B = mode_method_train(B)C = mode_method_train(C)D = mode_method_train(D)data = pd.concat([A, B, C, D])return data.drop('礦物類型', axis=1), data['礦物類型']
def mode_test_fill(x_train,y_train,x_test,y_test):data_train = pd.concat([x_train, y_train], axis=1)data_train = data_train.reset_index(drop=True)A_train = data_train[data_train['礦物類型'] == 1]B_train = data_train[data_train['礦物類型'] == 2]C_train = data_train[data_train['礦物類型'] == 3]D_train = data_train[data_train['礦物類型'] == 4]data_test = pd.concat([x_test, y_test], axis=1)data_test = data_test.reset_index(drop=True)A_test = data_test[data_test['礦物類型'] == 1]B_test = data_test[data_test['礦物類型'] == 2]C_test = data_test[data_test['礦物類型'] == 3]D_test = data_test[data_test['礦物類型'] == 4]A_test=mode_method_test(A_train,A_test)B_test = mode_method_test(B_train, B_test)C_test = mode_method_test(C_train,C_test)D_test = mode_method_test(D_train, D_test)data = pd.concat([A_test, B_test, C_test, D_test])return data.drop('礦物類型', axis=1), data['礦物類型']
def mode_method_train(data):fill_values = data.apply(lambda x: x.mode().iloc[0] if len(x.mode())>0 else None)data = data.fillna(fill_values)return data
def mode_method_test(train_data,test_data):fill_values=train_data.apply(lambda x: x.mode().iloc[0] if len(x.mode())>0 else None)test_data=test_data.fillna(fill_values)return test_data
7.調用填充方法,生成各自方法填充后的數據,并保存到各自的excel文件中
由于訓練集樣本不平衡,我們采用smote過采樣來平衡數據
import fill_data
#1.刪除空白數據行處理
# x_train_fill,y_train_fill=fill_data.cca_train_fill(x_train,y_train)
# x_test_fill,y_test_fill=fill_data.cca_train_fill(x_test,y_test)
#2.平均值填充處理
# x_train_fill,y_train_fill=fill_data.mean_train_fill(x_train,y_train)
# x_test_fill,y_test_fill=fill_data.mean_test_fill(x_train_fill,y_train_fill,x_test,y_test)
#中位數填充處理
# x_train_fill,y_train_fill=fill_data.median_train_fill(x_train,y_train)
# x_test_fill,y_test_fill=fill_data.median_test_fill(x_train_fill,y_train_fill,x_test,y_test)
# 眾數填充處理
x_train_fill,y_train_fill=fill_data.mode_train_fill(x_train,y_train)
x_test_fill,y_test_fill=fill_data.mode_test_fill(x_train_fill,y_train_fill,x_test,y_test)
#smote擬合數據
from imblearn.over_sampling import SMOTE
oversample=SMOTE(k_neighbors=1,random_state=42)#保證數據擬合效果,隨機種子
x_train_fill,y_train_fill=oversample.fit_resample(x_train_fill,y_train_fill)#數據存入excel
train_data=pd.concat([y_train_fill,x_train_fill],axis=1)
train_data.to_excel('訓練集[眾數填充].xlsx',index=False)
test_data=pd.concat([y_test_fill,x_test_fill],axis=1)





)
--可編輯數據)


)




)
 配置為公網訪問(監聽 0.0.0.0))

實戰二——圖像邊界擴展cv2.copyMakeBorder())

