
來自:z小趙
前言
經過前幾篇文章的介紹,大致了解了生產者背后的運行原理。消息有生產就得有人去消費,今天我們就來介紹下消費端消費消息背后發生的那點事兒。
文章概覽
- 消費者與消費組的“父子關系”。
- Repartition 觸發時機。
- 消費者與 ZK 的關系。
- 消費端工作流程。
- 消費者的三種消費情況。
消費者與消費組的“父子關系”
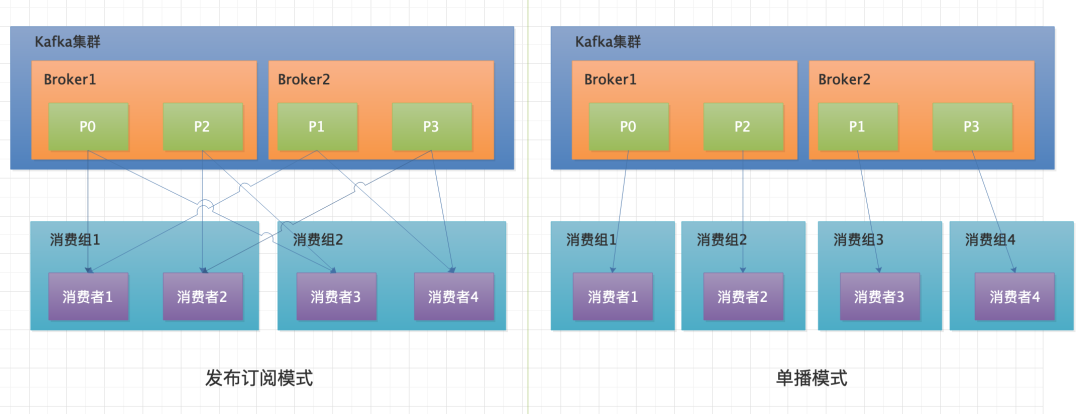
Kafka 消費端確保一個 Partition 在一個消費者組內只能被一個消費者消費。這句話改怎么理解呢?
- 在同一個消費者組內,一個 Partition 只能被一個消費者消費。
- 在同一個消費者組內,所有消費者組合起來必定可以消費一個 Topic 下的所有 Partition。
- 在同一個消費組內,一個消費者可以消費多個 Partition 的信息。
- 在不同消費者組內,同一個分區可以被多個消費者消費。
- 每個消費者組一定會完整消費一個 Topic 下的所有 Partition。
消費組存在的意義
了解了消費者與消費組的關系后,有朋友會比較疑惑消費者組有啥實際存在的意義呢?或者說消費組的作用是什么?
作者對消費組的作用歸結了如下兩點。
- 在實際生產中,對于同一個 Topic,可能有 A、B、C 等 N 個消費方想要消費。比如一份用戶點擊日志,A 消費方想用來做一個用戶近 N 天點擊過哪些商品;B 消費方想用來做一個用戶近 N 天點擊過前 TopN 個相似的商品;C 消費方想用來做一個根據用戶點擊過的商品推薦相關周邊的商品需求。對于多應用場景,就可以使用消費組來隔離不同的業務使用場景,從而達到一個 Topic 可以被多個消費組重復消費的目的。
- 消費組與 Partition 的消費進度綁定。當有新的消費者加入或者有消費者從消費組退出時,會觸發消費組的 Repartition 操作(后面會詳細介紹 Repartition);在 Repartition 前,Partition1 被消費組的消費者 A 進行消費,Repartition 后,Partition1 消費組的消費者 B 進行消費,為了避免消息被重復消費,需要從消費組記錄的 Partition 消費進度讀取當前消費到的位置(即 OffSet 位置),然后在繼續消費,從而達到消費者的平滑遷移,同時也提高了系統的可用性。
Repartition 觸發時機
使用過 Kafka 消費者客戶端的同學肯定知道,消費者組內偶爾會觸發 Repartition 操作,所謂 Repartition 即 Partition 在某些情況下重新被分配給參與消費的消費者。基本可以分為如下幾種情況。
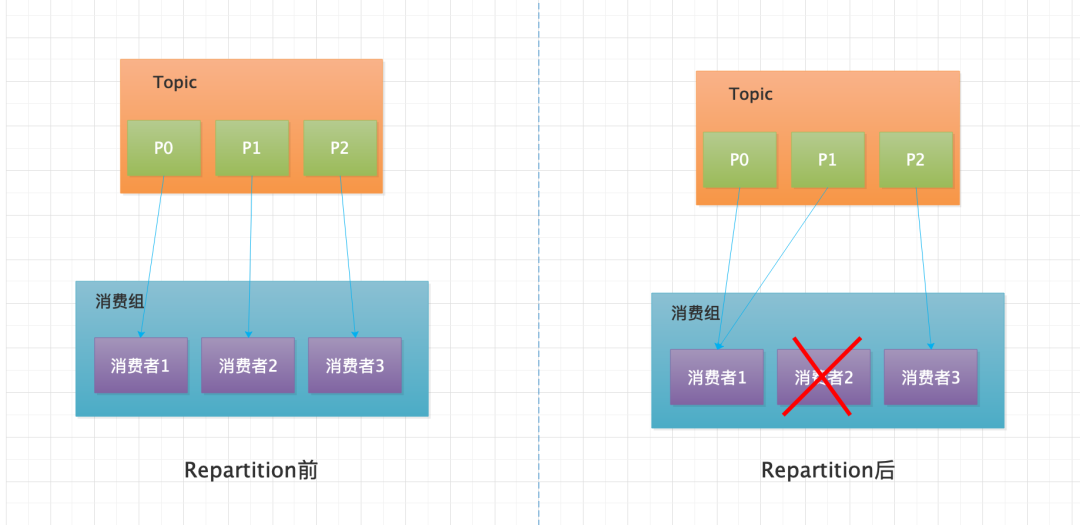
- 消費組內某消費者宕機,觸發 Repartition 操作,如下圖所示。
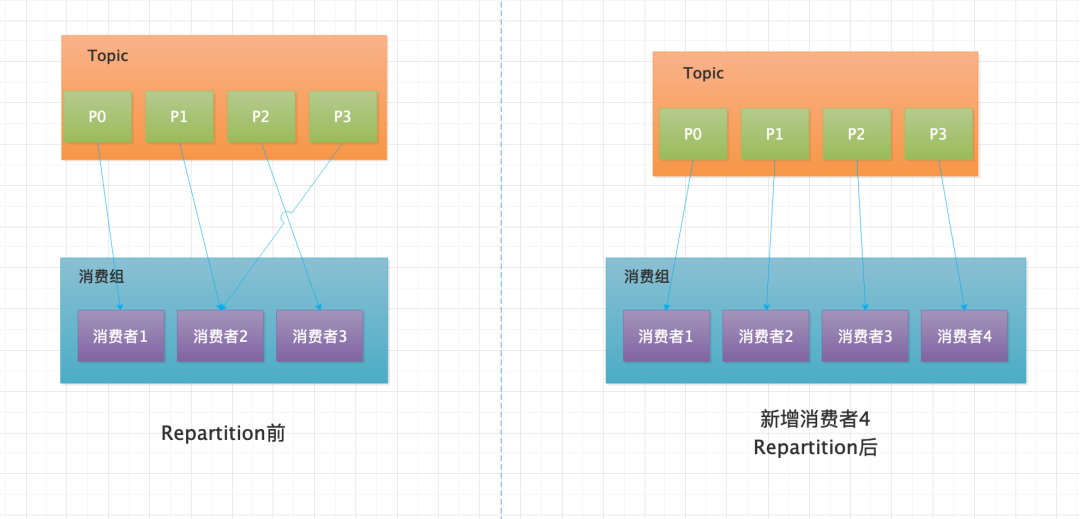
- 消費組內新增消費者,觸發 Repartition 操作,如下圖所示。一般這種情況是為了提高消費端的消費能力,從而加快消費進度。
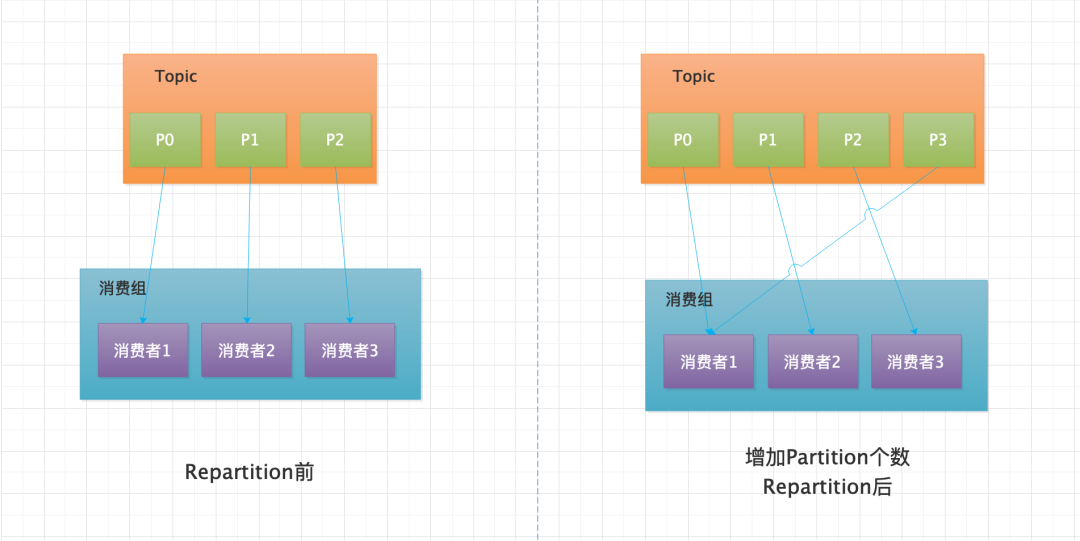
- Topic 下的 Partition 增多,觸發 Repartition 操作,如下圖所示。一般這種調整 Partition 個數的情況也是為了提高消費端消費速度的,因為當消費者個數大于等于 Partition 個數時,在增加消費者個數是沒有用的(原因是:在一個消費組內,消費者:Partition = 1:N,當 N 小于 1 時,相當于消費者過剩了),所以一方面增加 Partition 個數同時增加消費者個數可以提高消費端的消費速度。
消費者與 ZK 的關系
眾所周知,ZK 不僅保存了消費者消費 partition 的進度,同時也保存了消費組的成員列表、partition 的所有者。消費者想要消費 Partition,需要從 ZK 中獲取該消費者對應的分區信息及當前分區對應的消費進度,即 OffSert 信息。那么 Partition 應該由那個消費者進行消費,決定因素有哪些呢?從之前的圖中不難得出,兩個重要因素分別是:消費組中存活的消費者列表和 Topic 對應的 Partition 列表。通過這兩個因素結合 Partition 分配算法,即可得出消費者與 Partition 的對應關系,然后將信息存儲到 ZK 中。Kafka 有高級 API 和低級 API,如果不需要操作 OffSet 偏移量的提交,可通過高級 API 直接使用,從而降低使用者的難度。對于一些比較特殊的使用場景,比如想要消費特定 Partition 的信息,Kafka 也提供了低級 API 可進行手動操作。
消費端工作流程
在介紹消費端工作流程前,先來熟悉一下用到的一些組件。
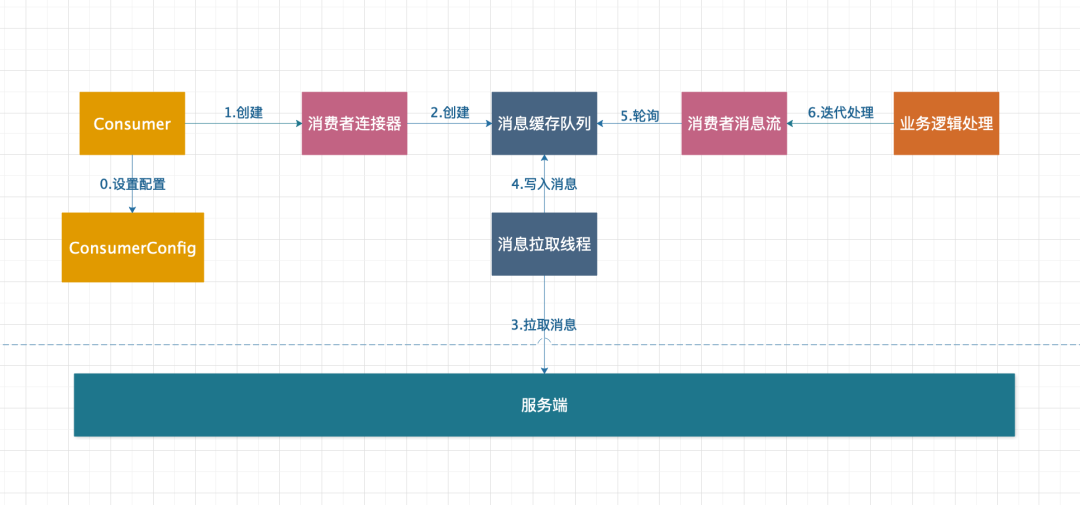
KakfaConsumer:消費端,用于啟動消費者進程來消費消息。ConsumerConfig:消費端配置管理,用于給消費端配置相關參數,比如指定 Kafka 集群,設置自動提交和自動提交時間間隔等等參數,都由其來管理。ConsumerConnector:消費者連接器,通過消費者連接器可以獲得 Kafka 消息流,然后通過消息流就能獲得消息從而使得客戶端開始消費消息。
以上三者之間的關系可以概括為:消費端使用消費者配置管理創建出了消費者連接器,通過消費者連接器創建隊列(這個隊列的作用也是為了緩存數據),其中隊列中的消息由專門的拉取線程從服務端拉取然后寫入,最后由消費者客戶端輪詢隊列中的消息進行消費。具體操作流程如下圖所示。
我們在從消費者與 ZK 的角度來看看其工作流程是什么樣的?
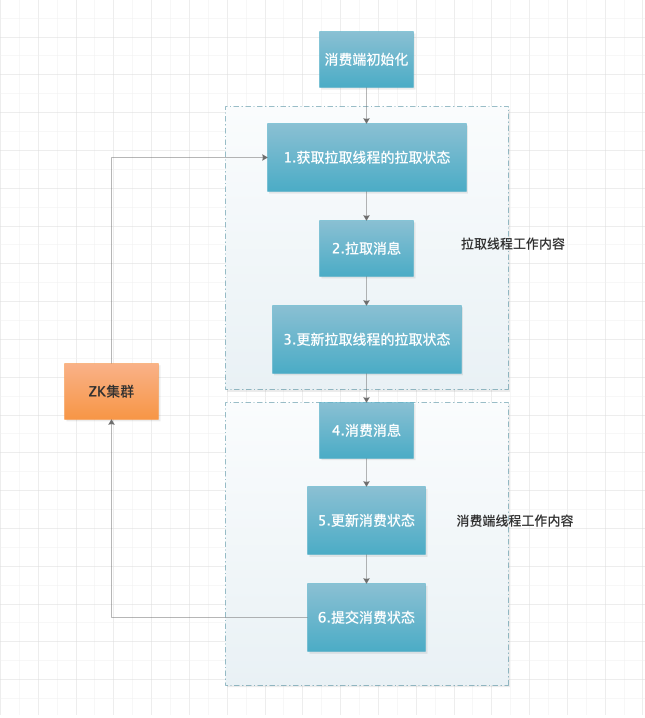
從上圖可以看出,首先拉取線程每拉取一次消息,同步更新一次拉取狀態,其作用是為了下一次拉取消息時能夠拉取到最新產生的消息;拉取線程將拉取到的消息寫入到隊列中等待消費消費線程去真正讀取處理。消費線程以輪詢的方式持續讀取隊列中的消息,只要發現隊列中有消息就開始消費,消費完消息后更新消費進度,此處需要注意的是,消費線程不是每次都和 ZK 同步消費進度,而是將消費進度暫時寫入本地。這樣做的目的是為了減少消費者與 ZK 的頻繁同步消息,從而降低 ZK 的壓力。
消費者的三種消費情況
消費者從服務端的 Partition 上拉取到消息,消費消息有三種情況,分別如下:
- 至少一次。即一條消息至少被消費一次,消息不可能丟失,但是可能會被重復消費。
- 至多一次。即一條消息最多可以被消費一次,消息不可能被重復消費,但是消息有可能丟失。
- 正好一次。即一條消息正好被消費一次,消息不可能丟失也不可能被重復消費。
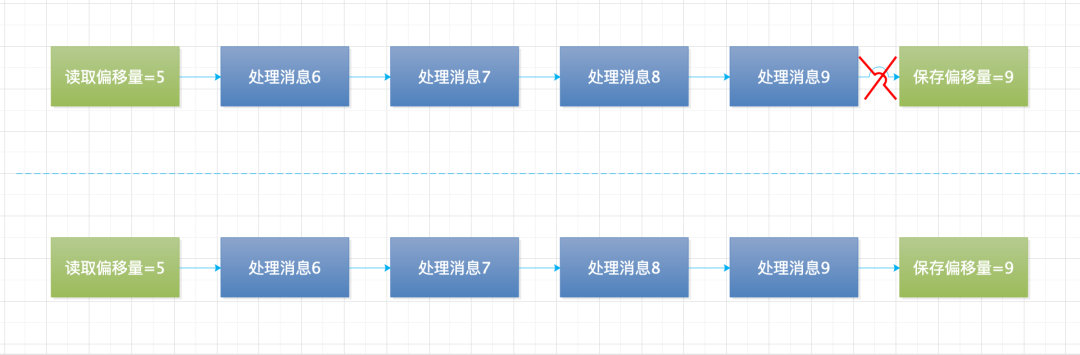
1.至少一次
消費者讀取消息,先處理消息,在保存消費進度。消費者拉取到消息,先消費消息,然后在保存偏移量,當消費者消費消息后還沒來得及保存偏移量,則會造成消息被重復消費。如下圖所示:
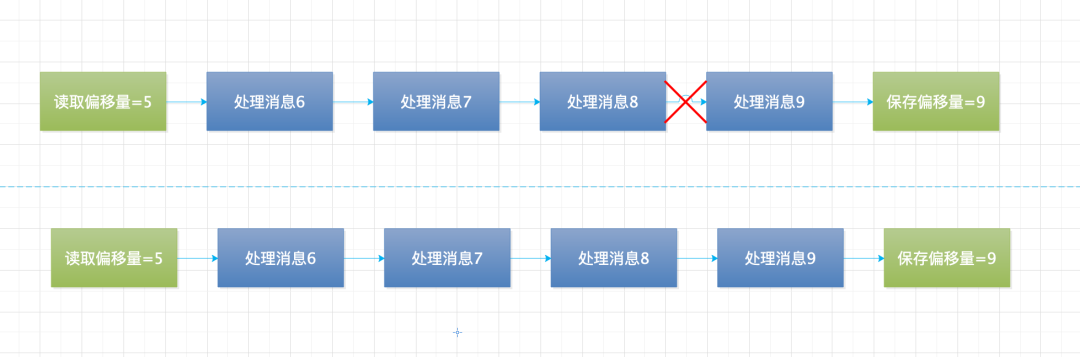
2.至多一次
消費者讀取消息,先保存消費進度,在處理消息。消費者拉取到消息,先保存了偏移量,當保存了偏移量后還沒消費完消息,消費者掛了,則會造成未消費的消息丟失。如下圖所示:
3.正好一次
正好消費一次的辦法可以通過將消費者的消費進度和消息處理結果保存在一起。只要能保證兩個操作是一個原子操作,就能達到正好消費一次的目的。通常可以將兩個操作保存在一起,比如 HDFS 中。正好消費一次流程如下圖所示。

總結
本文講解了消費組與消費者之間的關系,及 Repartition 的觸發時機,然后講述了消費端的基本工作流程,最后提出了一條消息被重復消費的幾種情況。下篇文章我們來講講消息在服務端是怎么存儲的,敬請期待。
特別推薦一個分享架構+算法的優質內容,還沒關注的小伙伴,可以長按關注一下:

長按訂閱更多精彩▼

如有收獲,點個在看,誠摯感謝












:如何識別 DDoS 攻擊?DDoS 防護 ADS 服務有哪些?)



...)


