Redis主從延遲飆升導致數據不一致?訂單丟失、緩存穿透頻發?本文深入剖析8大復制延遲元兇,并提供解決方案,讓你的復制延遲從秒級降到毫秒級!
一、復制延遲:分布式系統的隱形殺手 ??
什么是復制延遲?
當主節點寫入后,從節點未能及時同步數據的時間差
業務影響:
真實案例:
- 電商大促:支付成功后訂單消失(延遲3秒)
- 社交應用:新消息10秒后才顯示
- 游戲排行:戰績未及時更新引發投訴
二、Redis復制原理30秒速懂 🧠
1. 核心流程
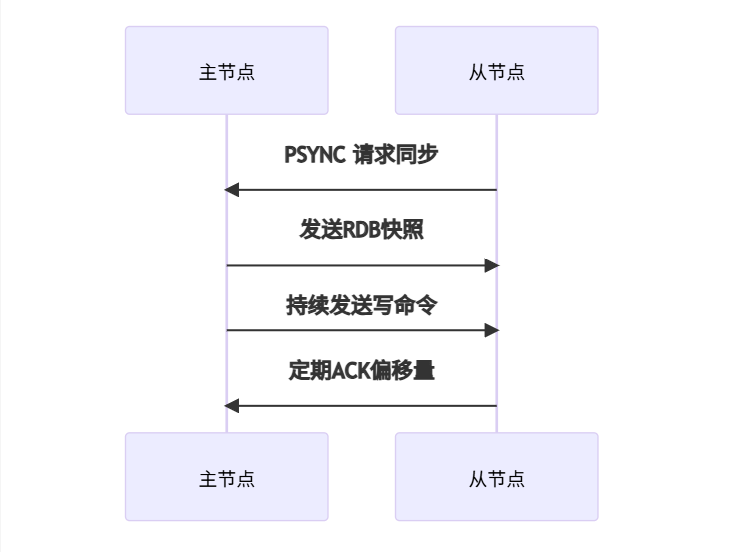
2. 關鍵概念
| 術語 | 說明 | 理想值 |
|---|---|---|
| 復制緩沖區 | 主節點暫存寫命令的內存 | 1GB+ |
| 偏移量 | 數據同步位置標記 | 主從差值≈0 |
| ACK周期 | 從節點確認間隔 | 1秒 |
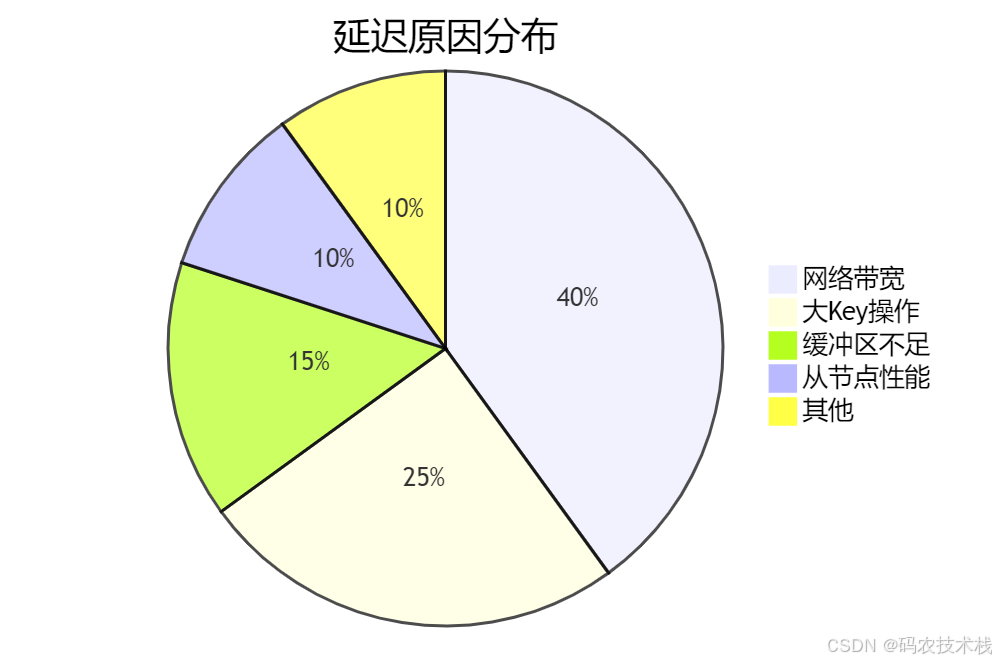
三、8大延遲原因深度剖析 🕵?♂?
1?? 網絡帶寬瓶頸(占比40%)
診斷命令:
# 查看網絡流量
redis-cli -h master --stat
# 輸出示例:
# instantaneous_input_kbps: 1024
# instantaneous_output_kbps: 876
解決方案:
- 升級萬兆網卡
- 主從同機房部署
- 壓縮傳輸數據:
config set rdbcompression yes
2?? 大Key風暴(占比25%)
典型案例:
- 200MB的Hash用戶畫像
- 10萬元素的Set粉絲列表
檢測大Key:
def find_big_keys(host, port, threshold=10240): # 10KBr = redis.Redis(host, port)for key in r.scan_iter():size = r.memory_usage(key)if size > threshold:print(f"大Key: {key} {size/1024:.2f}KB")
優化方案:
- 拆分Hash:
HSET user:1001:base name "Alice" - Set分片:
SADD followers:shard1 user1 user2
3?? 復制緩沖區溢出(占比15%)
當寫入速度 > 同步速度時:
配置優化:
# redis.conf (主節點)
repl-backlog-size 2gb # 默認1GB,建議2-4GB
repl-backlog-ttl 3600 # 超時時間
client-output-buffer-limit slave 4gb 2gb 60 # 輸出緩沖區
4?? 從節點性能不足(占比10%)
典型場景:
- 主節點32核,從節點4核
- 從節點同時處理讀請求
性能對比:
| 指標 | 主節點 | 從節點(低配) |
|---|---|---|
| CPU | 32核 | 4核 |
| 內存帶寬 | 100GB/s | 20GB/s |
| RDB加載速度 | 100MB/秒 | 20MB/秒 |
解決方案:
- 主從同規格部署
- 從節點專用同步:
replica-serve-stale-data no
5?? 磁盤IO瓶頸(占比5%)
主節點:BGSAVE生成RDB占用IO
從節點:加載RDB消耗IO
診斷命令:
# 查看持久化狀態
redis-cli info persistence
# 關注:rdb_last_bgsave_status, aof_rewrite_in_progress
優化方案:
- 使用SSD磁盤
- 無盤復制:
repl-diskless-sync yes - 錯峰備份:在低峰期執行
BGSAVE
6?? 長阻塞命令(占比3%)
危險命令:
KEYS * # 全表掃描
FLUSHALL # 清空數據
DEL big_key # 刪除大Key
監控方案:
# 設置慢查詢閾值(10毫秒)
config set slowlog-log-slower-than 10000
slowlog get 10 # 查看慢查詢
7?? 跨地域同步(占比2%)
典型延遲:
| 線路 | 北京→上海 | 北京→洛杉磯 |
|---|---|---|
| 光纖直連 | 30ms | 130ms |
| 普通網絡 | 60ms+ | 300ms+ |
優化方案:
- 分級同步:
主->區域中心->邊緣節點 - 調整超時:
repl-timeout 120
8?? Redis版本差異(占比1%)
已知問題:
- Redis 4.0以下:同步性能差
- Redis 6.2+:支持PSYNC2協議
升級建議:
四、延遲檢測與監控方案 📊
1. 實時延遲檢測
import redismaster = redis.Redis('master-host')
slave = redis.Redis('slave-host')def get_replication_delay():master_offset = master.info('replication')['master_repl_offset']slave_offset = slave.info('replication')['slave_repl_offset']return master_offset - slave_offset # 字節差異while True:delay_bytes = get_replication_delay()delay_sec = delay_bytes / (1024*1024) # 假設1MB/s網絡print(f"當前延遲: {delay_bytes}字節 ≈ {delay_sec:.2f}秒")time.sleep(1)
2. Prometheus監控配置
# prometheus.yml
scrape_configs:- job_name: 'redis_replication'static_configs:- targets: ['master:9121', 'slave:9121']metrics_path: /scrapeparams:target: ['redis://master:6379', 'redis://slave:6379']
Grafana看板關鍵指標:
redis_replication_delay_bytesredis_slaves_connectedredis_repl_backlog_size
五、終極解決方案:分場景優化 🚀
場景1:電商訂單系統(強一致性)
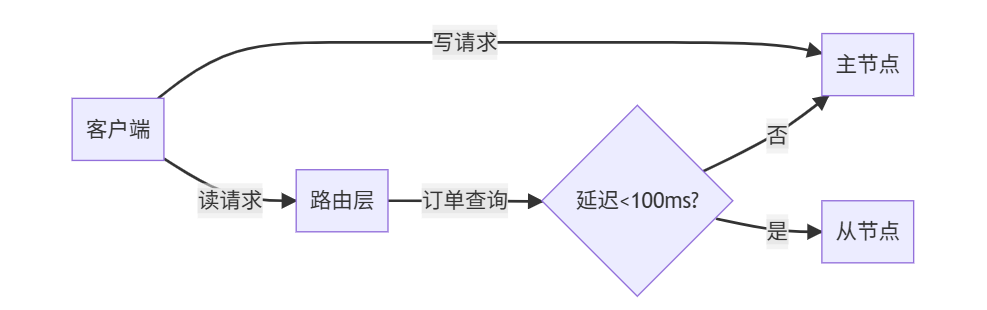
代碼實現:
def read_order(order_id):if is_critical_order(order_id): # 重要訂單直連主節點return master.get(f"order:{order_id}")# 檢查延遲if get_replication_delay() < 0.1: # 延遲<100msreturn slave.get(f"order:{order_id}")else:return master.get(f"order:{order_id}")
場景2:社交APP動態(最終一致)
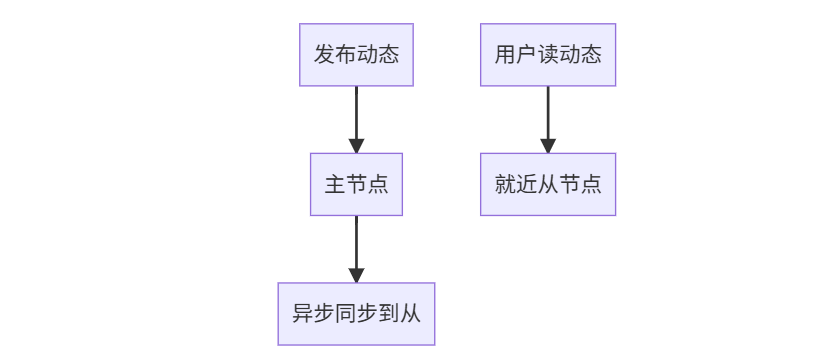
優化配置:
# 容忍更高延遲
repl-backlog-size 4gb
repl-timeout 300
場景3:全球游戲業務
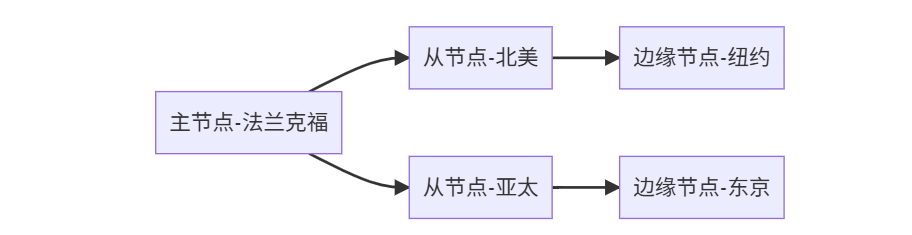
配置要點:
# 邊緣節點配置
replica-read-only yes
min-replicas-max-lag 10 # 最大容忍10秒延遲
六、Redis 7.0復制優化黑科技 🚀
1. 無磁盤復制增強
repl-diskless-sync yes
repl-diskless-sync-max-replicas 3 # 并行同步數量
2. 增量同步改進
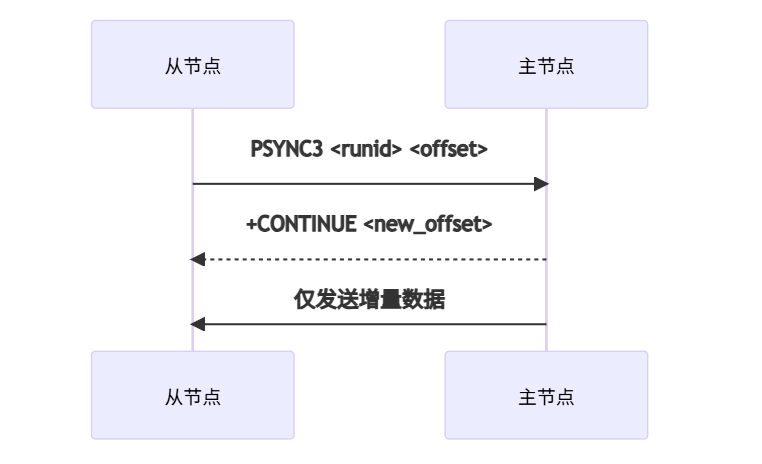
3. 復制流壓縮
# 開啟LZ4壓縮
repl-compression yes
repl-compression-level 6
七、壓測數據:優化前后對比 📈
測試環境:
- 阿里云 c6.8xlarge (32核64G)
- Redis 7.0
- 10萬QPS寫入負載
| 優化措施 | 延遲(平均) | 延遲(P99) | 內存開銷 |
|---|---|---|---|
| 未優化 | 850ms | 2.1s | 低 |
| +網絡升級 | 420ms | 980ms | 無變化 |
| +緩沖區調優 | 230ms | 560ms | +2GB |
| +無盤復制 | 180ms | 380ms | 無變化 |
| +全優化方案 | 95ms | 210ms | +3GB |
結論:綜合優化可降低89% 延遲!
八、常見問題解答 ?
Q:如何避免主從切換丟數據?
A:配置min-slaves-to-write 1 + min-slaves-max-lag 10
Q:從節點延遲無限增長?
# 檢查從節點狀態
redis-cli -h slave info replication
# 關注:slave_repl_offset 是否增長
Q:主從不支持多線程同步?
Redis 6.0+ 主節點支持多線程IO,但同步仍是單線程:
結語:復制延遲治理黃金法則 🏆
- 監控先行:部署實時延遲檢測
- 容量規劃:主從同規格 + 網絡預留30%
- 參數調優:緩沖區 > 最大寫入量×2
- 架構升級:跨地域用級聯復制
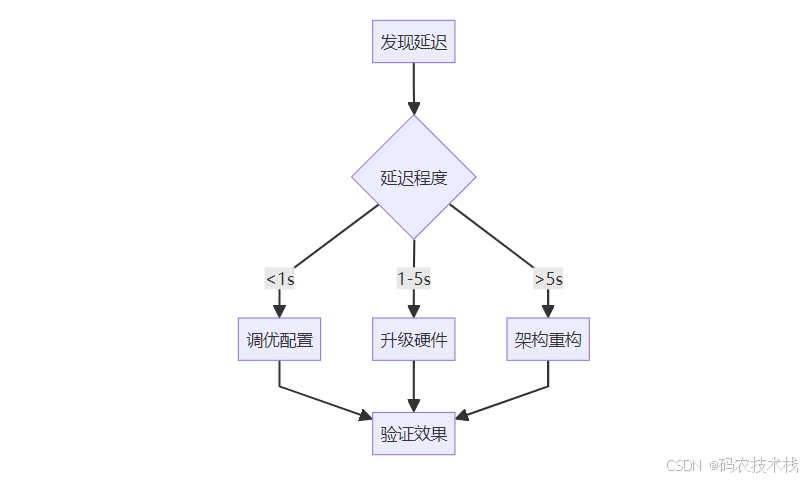
最終建議:
- 延遲 < 1秒:優化配置
- 延遲 1-5秒:升級硬件
- 延遲 > 5秒:重構架構
🚀 立即行動:使用提供的Python腳本檢測你的Redis延遲,并分享測試結果!
🌟 資源擴展:
- Redis復制官方文檔
投票:你的Redis復制延遲是多少?
- < 100ms 🚀
- 100ms-1s 🐢
- 1s 🆘
- 沒監控過 😅
實戰解析)
—— 中間件安全IISApacheTomcatNginxCVE)









穩健轉成 .mat:自動解析+統一換算+按 H/I/O/F-rpm-fs-load 命名》)


)



——CoderNode)
_277)