
原創聲明:本文為 SIGAI 原創文章,僅供個人學習使用,未經允許,不能用于商業目的。
其它機器學習、深度學習算法的全面系統講解可以閱讀《機器學習-原理、算法與應用》,清華大學出版社,雷明著,由SIGAI公眾號作者傾力打造。
- 書的購買鏈接
- 書的勘誤,優化,源代碼資源
PDF 全文下載:論文解讀 Receptive Field Block Net for Accurate and Fast Object Detection
解讀論文:Receptive Field Block Net for Accurate and Fast Object Detection
ECCV 2018
隨著深度神經網絡的發展,目前性能最佳的目標檢測模型都依賴于深度的CNN主干網,如ResNet-101和Inception,雖然強大的特征表示有利于性能的提升,但卻帶來高額的計算成本。相反的,一些輕量級的檢測模型可以實時的處理檢測問題,但隨之帶來的是精度的犧牲。在這篇論文文中,作者探索了一種替代方案,通過使用人工設計的網絡模塊(hand-crafted mechanism)強化輕量級特征來構建快速準確的檢測模型。受人類視覺系統中感受野(RF)結構的啟發,作者提出了一種新穎的RF模塊(RFB),它通過模擬RF的大小和偏心率之間的關系增強了特征的可辨性和模型的魯棒性。作者進一步將RFB組裝到SSD的頂部,構建RFB檢測模型。為了評估其有效性,作者在兩個主要基準數據集上進行了實驗,結果表明RFB Net能夠在保持實時速度的同時達到與擁有較深主干網的檢測模型同級別的性能。
一. 概述
近年來,基于區域(Region-baesd)的卷積神經網絡(R-CNN)及其衍生網絡(如Fast R-CNN和Faster R-CN等)在Pascal VOC,MS COCO和ILSVRC等主要的比賽和基準測試中不斷提升著目標檢測的最高性能。這一類檢測模型將整個網絡劃分為兩個階段并構建了一種特有的流水線(pipeline)結構,其中第一階段是對圖像內各類別目標的所有可能位置進行候選框粗略估計(region proposal),第二階段使用基于CNN的特征提取器及分類器對每個估計進行分類和校準。通常認為在這些方法中,CNN構建的特征表示起著至關重要的作用.通過CNN學習的特征是一種對于目標的編碼,這種編碼通常擁有較高的區分度和良好的魯棒性。很多最新的研究都證實了CNN在目標檢測中的重要作用, 例如,ResNet和DenseNet使用越來越深的網絡提取圖像特征; FPN引入了一種自上而下的架構來構建特征金字塔, 從而集成了淺層和高層語義信息; 最新的Mask R-CNN使用RoIAlign層以產生更精確的區域特征。所有的這些網絡都通過改進特征提取的方法來獲得更優的結果. 但是由于它們都沒有跳出使用更深層神經網絡的定勢思維,因而結論便是計算成本的不斷累加和檢測速率的減低。
為了加快檢測速度,單階段(one-stage)檢測框架被提出并廣泛使用. 其與two-stage檢測模型的不同點在于one-stage模型舍棄候選區域生成(Region proposal)的階段。雖然YOLO和SSD的實驗結果證明了one-stage模型可以做到實時的目標檢測,但它們與最新的two-stage檢測模型相比精度卻有著10%到40%的下降。盡管最新的Deconvolutional SSD(DSSD)和RetinaNet大大改善了one-stage模型的精度,使其幾乎可以和two-stage檢測模型媲美,但不幸的是它們性能的提升也來源于對更深層神經網絡的利用, 這也同樣影響著檢測速度。
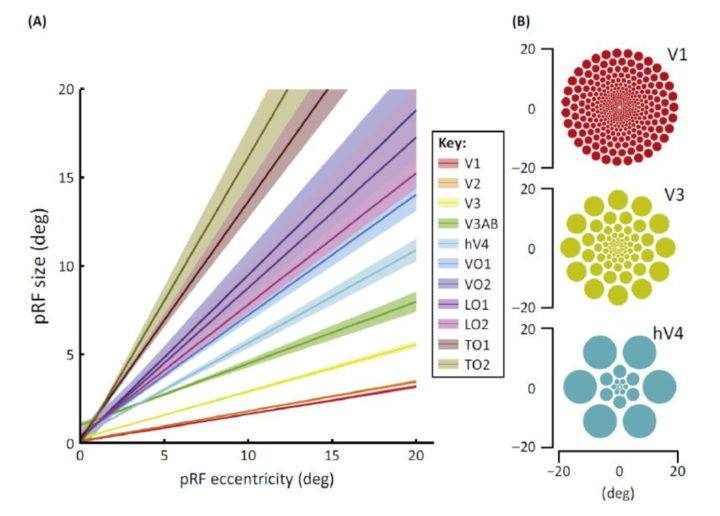
根據上面的討論作者認為, 為了構建快速而強大的檢測模型,合理的替代方案是通過引入某些人工設計的機制來增強輕量級網絡的特征表示,而不是頑固地加深模型。 另一方面,神經科學中的一些發現表明,在人類視覺皮層中,群智感受野(pRF)的大小是其視網膜圖中偏心率的函數,且如圖一所示隨著偏心率而增加. 這個結論同樣證明了更靠近中心的區域在識別物體時擁有更高的比重或作用,并且大腦在對于小的空間變化時具有不敏感性。 一些現有的網絡機制其實碰巧也在使用這一假設, 如pooling機制等等, 且這些機制或多或少的都在圖像領域展現出了各自的能力和效果。
目前現有的深度學習模型通常在特征圖上使用常規采樣網格將RF設置為相同尺寸,但是這可能會導致特征可辨性和魯棒性的一些損失。Inception考慮了多種尺寸的RF,它通過使用具有不同卷積核的多分支CNN來實現這一功能,雖然Inception的一系列變體在目標檢測(基于區域的框架中)和分類任務中實現了較為可觀的結果,但是Inception的問題在于所有卷積核都在同一中心進行采樣。類似的想法也出現在膨脹卷積網絡中,膨脹卷積網絡利用Atrous空間金字塔池(ASPP)來獲取多尺度信息,在頂部特征圖上應用了幾個具有不同比率的并行卷積以改變與中心的采樣距離,結果顯示這一模塊在語義分割中發揮著重要作用。但是上述特征針對先前的卷積層均具有相同的分辨率,并且與傳統卷積層相比,其所產生的特征往往不那么獨特。可變形CNN試圖根據物體的尺度和形狀自適應地調整RF的空間分布。盡管其采樣網格是靈活的,但沒有考慮RF的偏心率的影響: RF中的所有像素對輸出響應貢獻相同并且不重視最重要的信息。
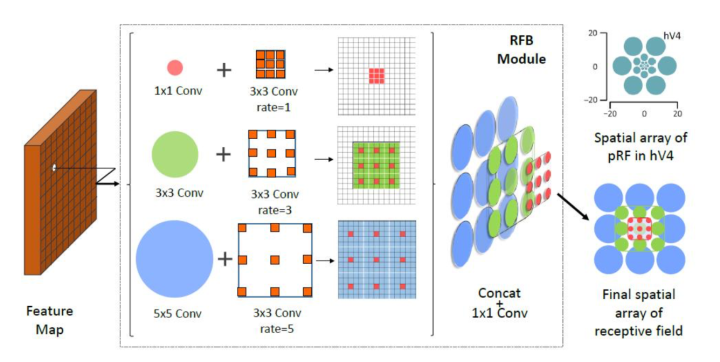
受人類視覺系統中RF結構的啟發,本文提出了一個新穎的模塊: 感受野模塊(RFB),加強了從輕量級CNN模型中學到的深層特征,使檢測模型更加快速且準確。如圖2所示: 具體來說,RFB利用具有與不同尺寸的RF相對應的不同卷積核的多分支池,應用膨脹卷積層來控制它們的偏心率,并將它們重新整合以生成最終表示。作者將RFB模塊組裝在SSD 上, 構建了一個新的one-stage檢測模型(RFB Net)。得益于這樣一個簡單的模塊,RFB Net展現出了相當不錯的結果: 在精度可以與最新的基于更深層神經網絡的檢測模型相媲美的同時, 保持了原始輕量級檢測模型的高速度。此外,由于對網絡架構施加的限制很少, RFB可以作為一種通用模塊嵌入到絕大多數網路當中。
本文的貢獻可以歸納如下:
- 作者提出了RFB模塊模擬人類視覺系統中pRF的大小和偏心度的函數關系,旨在增強輕量級CNN網絡的深層特征。
- 作者通過簡單地用RFB替換SSD的頂部卷積層, 提出了基于RFB Net的檢測模型. 它顯示出顯著的性能增益,同時仍然保持計算成本的可控性。
- RFB Net在保證實時處理速度的同時, 在Pascal VOC和MS COCO上實現了state-of-the-art的結果,作者最終將RFB鏈接到MobileNet來表明RFB的泛化能力。
二. 相關工作
Two-stage detector:
?R-CNN直接結合了選擇性搜索等提取候選框的步驟,并通過CNN模型對它們進行分類,與傳統方法相比在準確度上做到了顯著的提升,這開啟了目標檢測的深度學習時代。 它的一些變體(如fast R-CNN,faster R-CNN)更新了two-stage的模型結構并不斷的實現著更高的檢測性能。除此之外,為了進一步提高檢測精度, 更多領域的有效拓展也被不斷的提出: 如R-FCN,FPN,Mask R-CNN等。
One-stage detector:
最具代表性的one-stage檢測模型是YOLO和SSD, 它們基于整個特征圖預測多個對象的屬性和位置, 由于它們均采用輕量級的backbone進行加速,因而精度往往明顯落后于two-stage的檢測方法。
最近更先進的one-stage檢測模型(如DSSD和RetinaNet)通過更深層的ResNet-101替代其原始輕量級backbone,并應用某些技術(如反卷積或Focal loss), 取得了可以媲美甚至優于two-stage檢測方法的精度, 但是這種性能提升的代價是: 從一定程度上放棄了one-stage方法最為引以為傲的檢測速度。
Receptive Field:
在本文的研究中,作者的目標是在提高one-stage檢測模型性能的同時不產生太多的計算負擔。因而與應用非常深的backbone不同, RFB通過模仿人類視覺系統中RF的作用機制,增強了基于輕量級模型的特征表示。實際上對于CNN中RF的研究已經廣泛存在于深度學習領域,其中最相關的研究是便Inception家族,ASPP和可變形CNN。
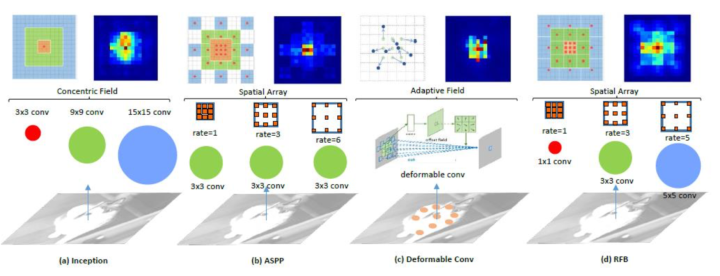
Inception塊采用具有不同卷積核大小的多個分支來捕獲多尺度信息, 但是所有卷積核都在同一個中心進行采樣,這需要更大的卷積核才能達到相同的采樣覆蓋率,因而會丟失一些關鍵細節。對于ASPP,擴張卷積改變了與中心的采樣距離,但是這些特征具有來自相同卷積核大小的先前卷積層的相同分辨率,且在所有位置上平等地處理特征,這可能導致目標和上下文之間的混淆。可變形的CNN針對不同對象學習到了完全不同的分辨率位置分布,遺憾的是它與ASPP具有相同的缺點。RFB與它們的不同點在于: RFB突出了感受野大小和偏心率之間的關系,其中較大的權重分配給較小卷積核靠近中心的位置,表明它們比周圍的特征點更為重要(圖3列舉了四種典型空間RF結構的差異)。另一方面,采用Inception和ASPP來改進one-stage檢測模型的研究尚未出現成果,而RFB則展示了在這個問題上獨特的優勢。
三. 方法
在本節中,作者重新探究人類視覺大腦皮層,介紹RFB組件以及模擬這種機制的方法,并描述RFB網絡檢測模型的架構及其訓練/測試數據表。
Visual Cortex Revisit:
在過去的幾十年中,通過使用功能性磁共振成像(fMRI), 人類從技術上使測量人類大腦活動成為可能,RF模型已成為用于預測反應和闡明大腦計算的重要感官科學工具。由于人類神經科學儀器經常觀察到許多神經元的匯集反應,因此這些模型通常被稱為pRF模型。 基于fMRI和pRF建模,可以研究皮質中許多視覺感應圖的關系。 在每個皮質圖上,研究人員發現pRF大小與離心率之間存在正相關,而相關系數在視覺圖中有所不同(如圖1所示)。
Receptive Field Block:
本文所提出的RFB是一種多分支的卷積模塊,它的內部結構可以分為兩個部分:具有不同卷積核的多分支卷積層后接膨脹池化或膨脹卷積。前者的部分與原始網絡相同,負責模擬多種尺寸的pRF,后者的部分再現了人類視覺系統中pRF尺寸與偏心率之間的關系,圖2展示了RFB及其對應的空間池區域圖。我們將在下面詳細闡述這兩部分及其功能。
Multi-branch convolution layer:
根據CNN中RF的定義,相比于共享相同尺度的RF, 應用不同的卷積核來實現多尺寸RF是一種更自然和簡單的方式。
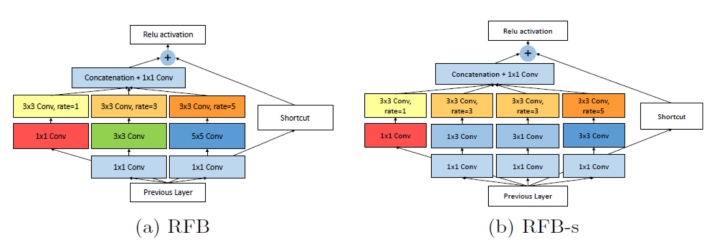
作者選擇最新的Inception版本進行模塊化修改(即Inception系列中的Inception V4和Inception-ResNet V2)。具體來說,首先作者在每個分支中采用瓶頸結構,包括一個用以減少特征圖中通道數量的1*1卷積層和一個n*n卷積層。 第二,為了減少參數和構建更深層的非線性映射, 作者使用兩個堆疊的3*3個卷積層代替5*5卷積層。出于同樣的原因,作者使用1*n加n*1卷積層來代替原始n*n卷積層。最后,作者結合使用了ResNet和Inception-ResNet V2 中的支路模塊(shortcut)。
Dilated pooling or convolution layer:
這個概念最初被Deeplab提出并被命名為astrous卷積, 該結構的基本目的是生成更高分辨率的特征圖,在保持相同數量參數的情況下做到在更大的區域提取特征。這種設計已迅速被證明能夠勝任語義分割任務,并且以提高速度或精度的目的逐漸被應用到一些檢測模型當中,如SSD和R-FCN。
在本文中,作者利用了膨脹卷積來模擬pRF在人類視覺皮層中的離心率的影響。從圖4中我們可以看到應用多分支卷積層和膨脹卷積層的兩個組合。每個分支有兩個組成部分,分別是具有特定核大小的卷積層和擁有相應膨脹率的池化或卷積層。卷積核大小和膨脹率與視覺皮層中pRF的大小和離心率具有相似的正比例函數關系。最后所有分支的特征圖被拼接合并到相同的特征空間(如圖1所示)。
RFB的特定參數(例如內核大小、每個分支的膨脹率和分支數量)在檢測模型的每個位置都有一定程度上的差異,這些差異將在下一節中詳細介紹。
RFB Net Detection Architecture:
作者所提出的RFB網絡檢測模型重用了SSD的多尺度和one-stage框架,其中嵌入了RFB模塊以改善從輕量級主干網中提取的特征,使得檢測模型可以更準確和高速。由于RFB的特性可以輕松集成到CNN中,所以SSD的架構可以被最大限度的保留, 僅僅用RFB代替頂部卷積層便可實現網絡結構的升級,圖5給出了網絡中更多的細節。
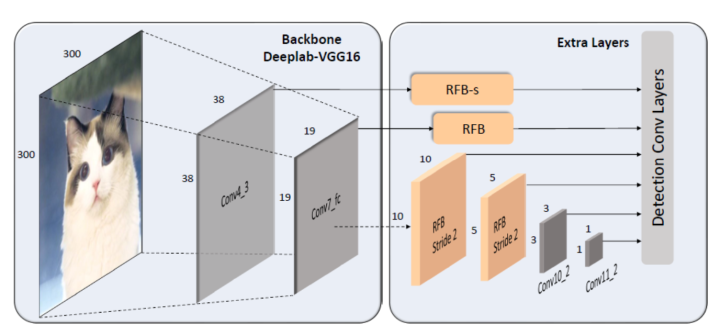
Lightweight backbone:
作者使用與SSD完全相同的主干網, 該網絡是在ILSVRC CLS-LOC數據集上預先訓練的VGG16架構,其中fc6和fc7層被轉換為具有次級采樣參數的卷積層, pool5層從2*2-stride2變為3*3- stride 1,并且去除所有pooling層和fc8層。 盡管最近提出了許多成熟的輕量級網絡(例如DarkNet,MobileNet和ShuffleNet),但作者為了與原始SSD進行直接對比,仍然使用上述的backbone。
Lightweight backbone:
在原始的SSD中,主干網由一系列卷積層組成,在各個網絡深度中形成一系列特征圖,這些特征圖具有連續遞減的空間分辨率和遞增的感受野。在本文的實現中,作者保持了相同的SSD級聯結構,將一些分辨率較大特征圖所在的卷積層替換為RFB模塊。 在RFB的一些主要版本中,作者使用單一的結構設置來模仿偏心率的影響。 根據特征圖之間pRF大小和偏心率的不同,我們相應地調整RFB的參數以形成RFB-s模塊并將其置于conv4_3層之后, 如圖4和圖5所示, 這個模塊實際上是模擬了人類淺層視網膜圖中較小的pRF。而網絡中的最后幾個卷積層被保留,原因是這些網絡層的輸出特征圖分辨率太小所以無法應用像5*5這樣大尺度的卷積核。
Training Settings:
作者基于Pytorch設計實現了RFB Net檢測模型,主要是利用了ssd.pytorch repository提供的開源基礎架構。作者為了盡可能跟SSD保持相同的訓練策略,使用了包括數據增強,hard negtive挖掘,相同默認框設置,以及相同的損失函數定義(如:使用用于定位的平滑L1損失和用于分類的softmax損失函數),但為了適應RFB的訓練,作者在學習率策略上略有調整, 另外所有新添加的卷積層均使用MSRA方法進行初始化.更多的訓練細節在之后的實驗部分會給出。
四.實驗
作者對與20個類別的Pascal VOC 2007和80個類別的MS COCO數據集分別進行了實驗. 在VOC 2007中,作者設置交并比(IoU)閾值為0.5,而在COCO中,作者使用多種閾值對數據集和結果進行更全面的分析。實驗結果的評估指標使用平均精度(mAP)。
?
Pascal VOC 2007:
在本文的實驗中,作者將2007 trainval set和2012 trainval set合并, 作為一個完整數據集對RFB Net進行訓練。網絡最初設置batchsize為32, 初始學習率為1e-3,雖然這些參數的默認設置與原始的SSD一樣,但結果卻顯示損失函數存在較大的震蕩, 訓練過程很不穩定。于是作者使用“預熱(warmup)”策略,在前5個epoch逐漸將學習率從1e-6提高到4e-3, 之后回歸原本的學習策略, 在上述策略的基礎上, 作者選擇0.0005的權重衰減和0.9的動量參數總共訓練了250個epoch。
表1顯示了本文的結果與一些state of the art模型在VOC2007測試集上的對比。 表中SSD300 *和SSD512 *是與RFB Net使用了相同數據集拓展與數據增強技術(如縮小圖像以創建更多小例子)后SSD的訓練結果。為了做到公平的比較,作者使用與RFB Net完全相同的環境(Pytorch-0.3.0和CUDNN V6)復現了SSD。通過集成RFB層作者發現,即使是最原始的RFB Net(即RFB Net300),也有著優于SSD和YOLO的實驗結果(mAP為80.5%),與此同時也保持了SSD300的實時速度。通過表格我們也可以看到, RFB Net甚至可以達到與最新的two-stage檢測模型(R-FCN)相同的精度。 RFB Net512是在放大了輸入尺寸的情況下的實驗結果,最終實現了82.2%的mAP,優于大多數one-stage和two-stage檢測模型.雖然它擁有較深的backbone, 但仍然保持著很高的速度。
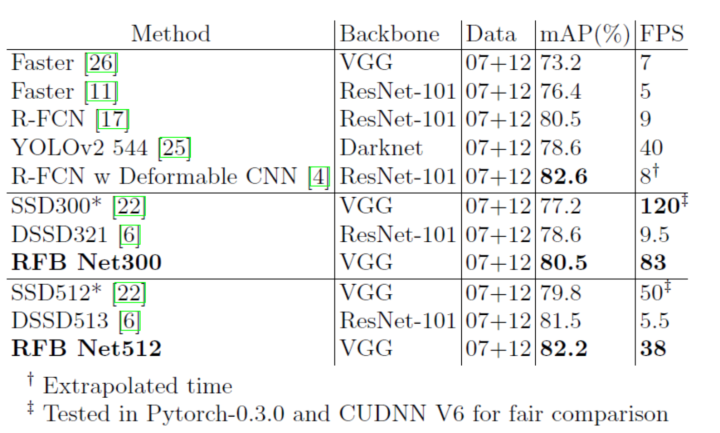
表1. PASCAL VOC 2007測試集上檢測方法的比較。所有數據信息都是在Geforce GTX Titan X(Maxwell架構)的GPU上計算得到。
Ablation Study:
RFB module:
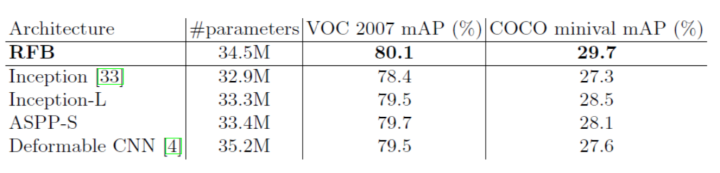
為了更好地理解RFB,我們研究了每個組件在網絡設計中的意義,并將RFB與一些類似的結構進行了比較,結果總結在表2和表3中。如表2所示,應用了新的數據增強方法的原始SSD300達到了77.2%mAP, 但通過簡單地使用RFB-max池化替換最后一個卷積層,我們便可以把結果提升至79.1%(1.9%的增益),這表明RFB模塊在檢測中是有效的。

Cortex map simulation:
正如上一節提到的,我們調整RFB參數以模擬大腦皮層圖中pRF的大小和偏心率之間的比率, 這種調整使RFB最大池化性能提高0.5%(從79.1%提高到79.6%),RFB膨脹卷積性能提高0.4%(從80.1%提高到80.5%),這同樣證實了本文所依據的人類視覺系統的機制(表2)。
More prior anchors:
原始SSD僅在conv4_3,conv10_2和conv11_2位置處的特征圖關聯4個默認框,并為所有其他層關聯6個默認anchor。 但是最近的研究表明:淺層特征對于檢測小物體起著至關重要的作用, 因此作者假設如果在淺層特征圖(如conv4_3)中添加更多anchor,那么檢測模型的性能(特別是小物體檢測的性能)往往會由一定程度的增加。在實驗中,作者在conv4_3處放置了6個默認框,實驗表明這對于原始SSD模型的性能沒有任何影響,但對于RFB模型卻有0.2%的提升(從79.6%到79.8%)(表2)。
Dilated convolutional layer:
在最早的實驗中,為了避免產生額外的參數, 作者選擇膨脹池化作為RFB的下采樣方式,但是這些固定的池化策略限制了多尺度RF特征的融合。而后的實驗選擇膨脹卷積替代池化,作者發現它在不降低預測速度的情況下將準確度提高了0.7%(從79.8%提高到80.5%)(表2)。
Microsoft COCO:
為了進一步驗證所提出的RFB模塊,本文在MS COCO數據集上也進行了實驗。作者使用trainval35k set(train set + val 35k set)進行訓練,并將batchsize設置為32. 作者在保留原始SSD策略的情況下,減小了默認框的大小, 原因是COCO數據集中相比PASCAL VOC包含更多小尺度的物體。在訓練開始時,作者同樣使用了“預熱(warmup)”技術,在前5個epoch逐漸將學習率從1e-6提高到2e-3,然后在80和100個epoch之后將其降低10倍,在120個epoch的時候結束訓練。
從表4中可以看出,RFB Net300在test-dev set上達到了30.3%/ 49.3%的精度,大幅度超過了SSD300 *的baseline,甚至和采用ResNet-101作為基礎網絡的R-FCN(輸入為600*1000)擁有相同的預測結果。
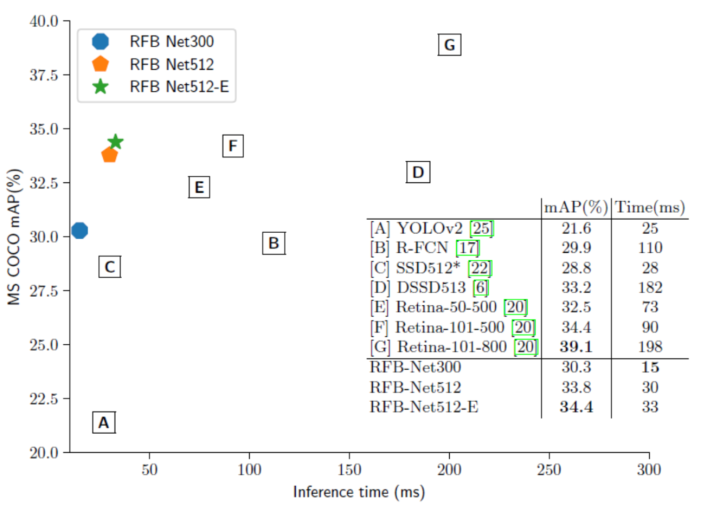
對于更’寬’的模型,RFB Net512的表現略差但仍然可以與最新的one-stage模型Reti- naNet500(33.8%對34.4%)相媲美。值得注意的是, RetinaNet利用了深度ResNet-101-FPN作為backbone, 且設計了全新的損失函數使學習重點放在困難的樣本上, 但RFB Net僅僅采用輕量級的VGG模型作為backbone. 從速度上比較我們也可以看到, RFB Net512預測一張圖片平均消耗30 ms,而RetinaNet卻需要90ms。
另外從表格中我們可以看出使用高達800像素尺度作為輸入的RetinaNet800獲得了最高精度(39.1%)。眾所周知,較大的輸入圖像尺寸通常會獲得更高的性能,但本文的研究重點在于高速度下的高精度實現,因而這項結果并不在本文的研究范圍。
本文還考慮另外的一些網絡構建策略:(1)在應用RFB-s模塊之前對conv7_fc特征圖進行上采樣并與conv4_3拼接,引入了類似于FPN的思想; (2)在所有RFB層中添加7*7卷積核的分支. 從表4中我們也可以看到,這兩個策略進一步的提高了性能,使得本文的實驗結果獲得了最高34.4%的精度(寫做RFB Net512-E),而計算成本僅略微的有所上升。
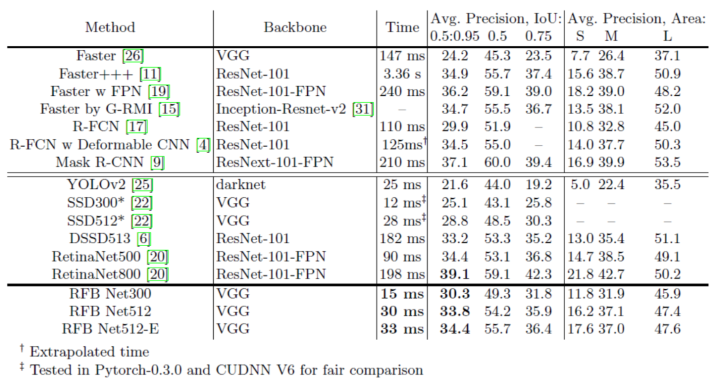
表4. COCO test-dev 2015數據集的檢測性能。 除了RetinaNet,Mask R-CNN和FPN實驗在Nvidia M40 GPU上,其余幾乎所有方法都是在Nvidia Titan X(Maxwell架構)GPU上測量的。
五.討論
Inference speed comparison:
在表1和圖6中列舉了RFB Net和一些state-of-the-art檢測模型的速度對比。在本文的實驗中,檢測模型在不同數據集上的預測速度有一定的差異,原因是MS COCO擁有80個類別,平均物體密集的增加使得模型在NMS步驟花費了更多的時間。從表1中可以看出, RFB Net300是擁有最高準確率的實時檢測模型(80.5%mAP),其在Pascal VOC上的運行速度為83 fps,并且RFB Net512仍可以以38 fps的速度為Pascal VOC提供更準確的結果。在圖6中,作者繪制RFB Net的速度/準確度trade-off曲線,并將其與RetinaNet等其他應用于MS COCO test-dev set上的檢測模型作比較。該圖表明本文提出的RFB網絡不僅在所有實時檢測模型中擁有最高的檢測精度,同時保持著優于所有單階段檢測模型的高速度(66 fps)。
Other lightweight backbone:
雖然我們使用的backbone是一個簡化的VGG16版本,但與最近的輕量級網絡(如MobileNet,DarkNet和ShuffleNet)相比仍然具有大量參數。 為了進一步測試RFB模塊的泛化能力,作者將RFB拼接到MobileNet-SSD上, 并使用相同的訓練策略在MS COCO數據集上進行訓練和評估。表5表明了:RFB在以MobileNet為backbone的模型上仍能通過增加少量參數而獲得準確度的提升, 這意味著RFB Net在低計算能力的設備上有著很大的應用前景。

Training from scratch:
作者還注意到RFB模塊的另一個有趣的特性: 即可以從頭開始有效地訓練物體檢測模型。最近的研究發現, 不使用預訓練backbone的檢測模型其訓練將會是一項艱巨的任務,在two-stage的檢測模型中, 所有的網絡結構均無法在脫離預訓練的條件下完成訓練任務, 在one-stage的檢測模型中, 雖然部分模型做到了收斂,但卻只能取得低于使用預訓練backbone的訓練結果。 深度監督物體檢測器(DSOD)提出了一種輕量級的結構,無需預先訓練即可在VOC 2007測試集上實現77.7%的mAP,但其在使用預訓練網絡時不會提升性能。作者從零開始在VOC 2007 + 2012訓練集上訓練了RFB Net300,并在相同的測試集上達到了與DSOD類似的77.6%的mAP. 但值得注意的是,如果在RFB Net上使用預訓練版本,性能將會提升至80.5%。
六.結論
在本文中,作者提出了一種快速而強大的目標檢測模型。與單純加深網絡深度不同,作者模仿人類視覺系統中的RF結構, 通過引入人工設計的機制,即感受野模塊(RFB)來增強輕量級網絡的特征表示. RFB模塊模擬了RF的大小和偏心率之間的關系,從而產生出更具辨別力和魯棒性的特征。RFB可以設置在基于輕量級CNN的SSD頂部,由此構建的RFB Net在Pascal VOC和MS COCO數據集上均取得了顯著的性能提升, 總的來說: RFB Net在保留了輕量級模型處理速度優勢的同時, 取得了可以與最新檢測框架相媲美的檢測精度。
1. Brown, M., Hua, G., Winder, S.: Discriminative learning of local image descriptors.TPAMI (2011)
2. Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv preprint arXiv:1606.00915 (2016)
3. Chen, L.C., Papandreou, G., Schro_, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587 (2017)
4. Dai, J., et al.: Deformable convolutional networks. In: ICCV (2017)
5. Everingham, M., Van Gool, L., Williams, C.K., Winn, J., Zisserman, A.: The pascal visual object classes (voc) challenge. IJCV (2010)
6. Fu, C.Y., et al.: Dssd: Deconvolutional single shot detector. arXiv preprint arXiv:1701.06659 (2017)
7. Girshick, R.: Fast r-cnn. In: ICCV (2015)
8. Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR (2014)
9. He, K., Gkioxari, G., Doll_ar, P., Girshick, R.: Mask r-cnn. In: ICCV (2017)
10. He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into recti_ers: Surpassing humanlevel performance on imagenet classi_cation. In: ICCV (2015)
11. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition.in - Domain Name For Sale | Undeveloped: CVPR (2016)
12. Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H.: Mobilenets: E_cient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
13. Hu, P., Ramanan, D.: Finding tiny faces. In: CVPR (2017)
14. Huang, D., Zhu, C., Wang, Y., Chen, L.: Hsog: a novel local image descriptor based on histograms of the second-order gradients. IEEE Transactions on Image Processing 23(11), 4680{4695 (2014)
15. Huang, J., et al.: Speed/accuracy trade-o_s for modern convolutional object detectors. In: CVPR (2017)
16. Kim, K.H., Hong, S., Roh, B., Cheon, Y., Park, M.: Pvanet: Deep but lightweight neural networks for real-time object detection. arXiv preprint arXiv:1608.08021 (2016)
17. Li, Y., He, K., Sun, J., et al.: R-fcn: Object detection via region-based fully convolutional networks. In: NIPS (2016)
18. Li, Y., Qi, H., Dai, J., Ji, X., Wei, Y.: Fully convolutional instance-aware semantic segmentation. In: CVPR (2017)
19. Lin, T.Y., Doll_ar, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: CVPR (2017)
20. Lin, T.Y., Goyal, P., Girshick, R., He, K., Doll_ar, P.: Focal loss for dense object detection. In: ICCV (2017)
21. Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll_ar, P.,Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV (2014)
22. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.Y., Berg, A.C.: Ssd:Single shot multibox detector. In: ECCV (2016)
23. Luo, W., et al.: Understanding the e_ective receptive _eld in deep convolutional neural networks. In: NIPS (2016)
24. Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Uni_ed, real-time object detection. In: CVPR (2016)
25. Redmon, J., Farhadi, A.: Yolo9000: Better, faster, stronger. In: CVPR (2017)
26. Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: Towards real-time object detection with region proposal networks. In: NIPS (2015)
27. Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z.,Karpathy, A., Khosla, A., Bernstein, M., et al.: Imagenet large scale visual recognition challenge. IJCV (2015)
28. Shen, Z., Liu, Z., Li, J., Jiang, Y.G., Chen, Y., Xue, X.: Dsod: Learning deeply supervised object detectors from scratch. In: ICCV (2017)
29. Simonyan, K., Vedaldi, A., Zisserman, A.: Learning local feature descriptors using convex optimisation. TPAMI (2014)
30. Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: NIPS (2014)
31. Szegedy, C., Io_e, S., Vanhoucke, V., Alemi, A.A.: Inception-v4, inception-resnet and the impact of residual connections on learning. In: AAAI (2017)
32. Szegedy, C., Vanhoucke, V., Io_e, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: CVPR (2016)
33. Szegedy, C., et al.: Going deeper with convolutions. In: CVPR (2015)
34. Tola, E., Lepetit, V., Fua, P.: A fast local descriptor for dense matching. In: CVPR
(2008)
35. Uijlings, J.R., Van De Sande, K.E., Gevers, T., Smeulders, A.W.: Selective search for object recognition. IJCV (2013)
36. Wandell, B.A., Winawer, J.: Computational neuroimaging and population receptive _elds. Trends in Cognitive Sciences (2015)
37. Weng, D., Wang, Y., Gong, M., Tao, D., Wei, H., Huang, D.: Derf: distinctivee_cient robust features from the biological modeling of the p ganglion cells. IEEE Transactions on Image Processing 24(8), 2287{2302 (2015)
38. Winder, S.A., Brown, M.: Learning local image descriptors. In: CVPR (2007)
39. Zhang, X., Zhou, X., Lin, M., Sun, J.: Shu_enet: An extremely e_cient convolutional neural network for mobile devices. arXiv preprint arXiv:1707.01083 (2017)




)
)
)

)

)


)

)


)
