大家都知道在對索引執行查詢的時候,需要在所有的分片上執行查詢,因為無法知道被查詢的關鍵詞位于哪個分片,對于全文查詢來說誠然如此,然而對于時序型的索引,當你從 my_index-* 中執行 now-3d 的范圍查詢時,可能很多分片上都不存在被查詢的數據范圍,因此 es 從 v5.6 開始引入了 pre-filter 機制:對于 Date 類型的 Range 查詢,在對分片執行搜索之前,先檢查一下分片是否包括被查詢的數據范圍,如果查詢的范圍與分片持有的數據沒有交集,就跳過該分片。
分布式搜索過程原先由兩個階段執行:查詢階段和取回階段,在引入了 pre-filter 之后,分布式搜索過程變成了三個階段:預過濾階段(pre-filter)、查詢階段和取回階段。pre-filter 在查詢階段之前執行。
協調節點收到客戶端的查詢請求后,向本次搜索涉及到的全部分片發送RPC 請求:
indices:data/read/search[can_match]
這次 RPC 請求以 shard 為單位并行發送,沒有并發限制。待查詢的 shard 有多少個,就并發發送多少個 RPC。然后等待全部 RPC 返回響應。
tips
此時發送的 RPC 請求沒有超時限制。事實上,_search 請求的 timeout參數僅在整個分布式搜索的 query 階段進行檢查,并且不包括 PRC 層面,他只在數據節點收到協調節點發來的 RPC 后開始計時,檢查 query 過程是否超時。fetch 階段的 RPC,以及數據節點對 fetch 請求的處理均沒有超時檢查。
節點收到請求后,判斷請求的范圍和待查詢的分片是否存在交集,返回是或否,然后協調節點跳過不存在交集的分片,向其他分片發送下一階段(查詢階段)的請求。
本次查詢跳過了多少分片可以通過查詢結果中的?skipped?字段看到,如:
"_shards":{
"total": 130,
"successful": 130,
"skipped": 129,
"failed": 0
}
同時也來看一下手冊對 skipped 字段的解釋:
skipped
(Integer) Number of shards that skipped the request because a lightweight check helped realize that no documents could possibly match on this shard. This typically happens when a search request includes a range filter and the shard only has values that fall outside of that range.
什么情況下會執行 pre-filter
pre-filter 并不會在所有查詢過程中執行,在 v7.4中,需要同時滿足以下條件,才會執行 pre-filter :
待查詢的分片數大于 128(pre_filter_shard_size指定)
聚合請求不要求訪問所有 doc。即非 Global Aggregation 或?"min_doc_count" 不為0
另外,非 Date 類型的數值查詢雖然也會走 pre-filter流程,但內部不會去判斷范圍,雖然協調節點也會發送 can_match 的 RPC,但數據節點的響應會在 MappedFieldType#isFieldWithinQuery 中直接返回相交,所以沒有分片會被 skip,未來這方面可能會有擴展。
pre-filter 實現原理
數據節點判斷某個 Range 查詢與分片是否存在交集,依賴于 Lucene 的一個重要特性:PointValues 。在早期的版本中,數值類型在 Lucene 中被轉換成字符串存入倒排索引,但是由于范圍查詢效率比較低,從 Lucene 6.0開始,對于數值類型使用 BKD-Tree 來建立索引,內部實現為 PointValues。PointValues原本用于地理位置場景,但它在多維、一維數值查詢上的表現也很出色,因此原先的數值字段(IntField,LongField,FloatField,DoubleField)被替換為(IntPoint,LongPoint,FloatPoint,DoublePoint)
關于 BKD-Tree 的性質請參閱其他資料,暫且只需要知道 Lucene為每個字段單獨建立索引,對于數值字段生成 BKD-Tree,一個新的 segment 生成時會產生一個新的.dim和.dii文件。最重要的,可以獲取到這個 segment 中數值字段的最大值和最小值,為 pre-filter 提供了基礎。當 segment 被 reader 打開的時候,Lucene 內部的 BKDReader 會將最大值和最小值讀取出來保存到類成員變量,因此每個 segment 中,每個數值字段的最大最小值都是常駐 JVM 內存的。
既然每個 segment 記錄了數值字段的取值范圍,獲取shard 級別的范圍就輕而易舉:PointValues.getMaxPackedValue(),PointValues.getMinPackedValue(),函數遍歷全部的 segment 分別計算最大值和最小值,然后根據查詢條件判斷是否存在交集,在 DateFieldMapper.DateFieldType#isFieldWithinQuery 函數中:
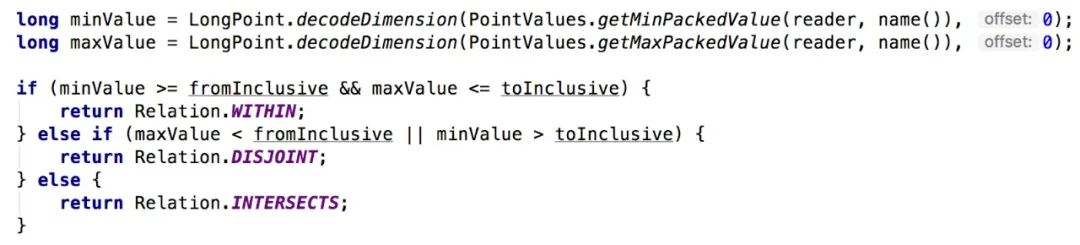
既然數值類型都可以獲取分片級別的范圍,為什么 pre-filter 只在 Date 類型的Range 查詢里實現了,而其他的數值類型的 Range 查詢不會走 pre-filter 流程?原因也非常簡單,只有 Date 類型的數值確定是遞增的,其他數值類型未必。對于非遞增的數值字段,其數據會散布到 my_index-* 的每個分片上,因此 pre-filter 也就沒有必要了。如果你有另外一個遞增的數值字段,目前也沒有配置的方式來使用 pre-filter。
題外話:BKD-Tree 的每個節點都記錄了節點自己的maxPackedValue、minPackedValue
Lucenene 內部查詢的也會按照 segment file 級別跳過
現在我們忘掉 es,討論數值類型查詢在 Lucene 內部的實現。
HBase 的寫入模型和 Lucene 類似,先寫內存,然后刷盤生成 HFile,HFile 合并成大文件。由于 HBase 使用時間戳作為數據版本號,因此每個 HFile 都記錄了時間范圍。因此查詢的時候如果指定時間范圍,就可以過濾掉大量的 HFile 不用查詢。這么優秀的操作在 Lucene 中也必不可少。
在一個 Lucene 索引中可能有很多 segment,Lucene遍歷所有的 segment 進行處理,在對每個 segment 的 weight.bulkScorer過程中,BKDReader.intersect函數根據相交情況決定收集符合條件的 docid,如果查詢條件和 segment 沒有交集,就什么都不做。

因此當對數值類型查詢的時候,不在范圍的 segment 會直接跳過,Lucene 內部稱為:CELL_OUTSIDE_QUERY
但是,段合并的時候目前還不會考慮按時間臨近的方式進行合并,因此借鑒 HBase 的思想按照時間臨近的段進行合并有助于降低數值類型的范圍查詢耗時。
思考
既然 Lucene 對數值類型有 segment 級別的skip,Elasticsearch 實現的分片層面的 pre-filter 還有必要存在嗎?他可以讓搜索延遲更低么?我們實際測試來說話。過程如下:
生產集群有 filebeat-* 索引,數據為 nginx 日志,大約8T,有180個shard,11227個 segment,分布在3個節點。
step1:我們對 date 字段執行一個不會命中的查詢,讓他走 pre-filter 流程:
POST filebeat-7.4.2-*/_search
{
"size":0,
"query": {
"range": {
"@timestamp": {
"gte": "2021-01-01",
"lte":"2022-01-01"
}
}
}
}
返回結果摘要如下,整個過程執行了31ms:
{
"took" : 31,
"timed_out" : false,
"_shards" : {
"total" : 180,
"successful" : 180,
"skipped" : 179,
"failed" : 0},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"}}step2:現在加上 ?pre_filter_shard_size=1000 參數重新查詢,其他條件不變,讓查詢過程不走 pre-filter,返回結果如下,整個過程執行了31ms,可見沒什么區別:
{
"took" : 23,
"timed_out" : false,
"_shards" : {
"total" : 180,
"successful" : 180,
"skipped" : 0,
"failed" : 0},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"}}}
step3:最后我們對 long 字段執行 range 查詢,這樣也不走 pre-filter 流程:
POST filebeat-7.4.2-*/_search?size=0
{
"query": {
"range": {
"nginx.bytes.body_sent": {
"gte": -2,
"lte":-1
}
}
}
}
這次查詢執行了50ms,還是在一個數據級。
{
"took" : 50,
"timed_out" : false,
"_shards" : {
"total" : 180,
"successful" : 180,
"skipped" : 0,
"failed" : 0},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"}}}
因此 pre-filter并不會降低查詢延遲,在和官方聊過之后,他們的想法是 pre-filter 最主要的作用不是降低查詢延遲,而是 pre-filter 階段可以不占用search theadpool,減少了這個線程池的占用情況。個人感覺這個收益并不大。不過未來會在這個階段做更多的查詢優化, 例如7.6中放出的 #49092,#48681
特別感謝:陸徐剛@螞蟻
基于:Elasticsearch 7.4 & 7.6
參考
https://github.com/elastic/elasticsearch/pull/25658
https://www.amazingkoala.com.cn/Lucene/Search/2020/0427/135.html
https://lucene.apache.org/core/6_2_1/core/org/apache/lucene/index/PointValues.html
http://www.nosqlnotes.com/technotes/searchengine/lucene-invertedindex-3/
https://www.jianshu.com/p/39eb0d66d082
https://cloud.tencent.com/developer/article/1366835
https://www.elastic.co/guide/en/elasticsearch/reference/current/release-notes-7.6.0.html#





![css滑動門的用處,CSS滑動門是什么?有什么用處?[web前端培訓]](http://pic.xiahunao.cn/css滑動門的用處,CSS滑動門是什么?有什么用處?[web前端培訓])













:scp命令)