MySQL 索引
A database index is a data structure that improves the speed of operations in a table. Indexes can be created using one or more columns, providing the basis for both rapid random lookups and efficient ordering of access to records.
為什么需要索引
根據上面索引的定義,可以知道索引其實是一種數據結構,主要用于提高表中的查詢效率,除此之外,索引還是數據庫隨機高速讀取和對記錄進行有效排序的基礎。
不使用索引情況下數據的讀取
除了像 Redis 這樣的內存型數據庫外,大部分的關系型數據庫如 MySQL 等的數據都是直接存儲在磁盤上的,而對于從磁盤查找數據來說,需要經歷尋道, 尋址, 數據傳輸三個階段。
- 尋道:驅動器驅動磁頭前后移動到對應的磁道,一般為 5 ~ 14 ms
- 尋址:磁盤旋轉到指定扇區的過程,尋址時間與磁盤轉速有關,對于一個 7200 轉的磁盤來說,意味著一分鐘轉 7200 圈,每秒可以轉 120 圈,在尋址時,最好情況下磁頭正好在正確扇區不需要再次尋址,最差情況下需要轉一圈才能到正確扇區,所以尋址的平均時間為 1/120/2=4.17ms1/120/2 = 4.17ms1/120/2=4.17ms
- 數據傳輸:數據傳輸階段的耗時主要包括兩部分,一是磁頭從磁盤讀取到數據并存儲到磁盤緩存所需要的時間,二是從磁盤緩存中讀取數據到對應控制器所需的時間;數據傳輸耗時主要與硬件性能有關,但一般為零點幾毫秒。
所以直接從磁盤讀取數據的 IO 耗時一般在 10ms 左右,為了避免頻繁的磁盤 IO,所以操作系統在讀取數據時會以頁為單位,一次讀取目標數據以及和目標數據相鄰的一頁大小(4K或8K)的數據并放在緩存中,這樣下次再讀取相鄰的數據時就可以直接從緩存中返回了。
MySQL 一次會讀四頁也就是 16 K
在不使用索引的情況下,如果要查詢最后一條數據,就需要從頭遍歷到尾,
這種情況下,數據庫需要讀取所有的片才能得到目標數據,大量時間會浪費在磁盤 IO 上,為此,我們需要一種數據結構去記錄數據項和磁盤中頁的關系,這樣在查詢某條記錄時就可以直接定位到某一頁,這樣只需要進行一次磁盤IO便可以得到目標數據,可以大大優化查詢效率,這種數據結構便是索引。
為什么是 B+ 樹
要實現上面的功能,首先可以采用 Hash Table 的方式,將索引鍵 Hash 之后存儲哈希值和鍵對應的行指針,這樣一來,在使用哈希索引查詢的時候就可以直接計算出要查詢記錄的哈希值,然后查詢此哈希值對應的行指針,由于每一行所需要的存儲空間是固定的,所以得到行指針就相當于定位到了記錄對應的頁,這時每次查詢只需要進行一次磁盤 IO, 可以大大優化查詢效率,但哈希索引存在一些問題:
- 哈希沖突: 只要使用 Hash Table 的數據結構,哈希沖突就是不可避免的,MySQL 中解決沖突的方式是拉鏈法,即一旦發生沖突就把新的記錄以鏈表的方式鏈接到原來的記錄之后,這樣每次查詢都需要先遍歷這個鏈表得到一個行指針,再根據行指針查詢記錄,得到記錄后再與要查詢的記錄作比較,如果得到的不是要查詢的記錄,要回去取鏈表中的下一個行指針,再去查詢比較,直到得到期望的數據,因此使用哈希索引后的磁盤IO次數取決于沖突的發生率,在存在大量沖突時,哈希索引的查詢效率會急速下降。
- 哈希索引只支持等值查詢:由于哈希索引是根據哈希鍵計算出哈希值,所以它只能在進行等值查詢(如
IN,=,<=>)時才能起到優化效率的效果,在進行非等值操作(如!=,>,<,<>)時起不到任何作用。 - 組合索引:在使用組合索引時,哈希索引的做法是將所有索引鍵合并后再做哈希,這就導致對多個字段做組合索引后,再查詢其中某一個字段時無法利用索引。
- 無法根據索引進行有效排序,哈希之后的的值已經丟失了原來的索引鍵的大小信息,所以無法根據索引進行高效排序
除了使用 Hash Table, 另一個思路是使用排序樹,以排序樹的結構組織頁后,可以將原來查詢 O(n)O(n)O(n)的復雜度降低到 lg?n\lg nlgn 而 o(n)o(n)o(n)的復雜度就意味著每次查詢需要進行 nnn 次磁盤IO,使用排序樹后雖然不能像哈希表一樣達到 O(1)O(1)O(1) 的復雜度,但相比不使用索引可以大大減少磁盤 IO 的次數 。
MySQL 中默認使用 B+ 樹構建索引,之所以使用 B+ 樹而不是 B 樹或二叉排序樹的原因在于:
- 要選取的樹結構必須是穩定的,如果采用二叉排序樹,在插入有序序列后,二叉樹就會退化為鏈表,起不到好的優化效果
- 根據排序樹查詢其實是在進行樹的深度遍歷,而每遍歷一個樹節點都是一次磁盤IO,所以具體的IO次數取決于樹的高度,這就要求樹要盡可能矮,也就要求能一個根節點能持有多個子節點。
B+ 樹就滿足上面兩點要求,首先 B+ 樹是一棵多路平衡二叉樹,其次由于磁盤IO以固定大小的頁為單位,所以每次進行磁盤IO能夠查詢出的數據量是有限制的,這同樣意味著樹的一個父節點能夠持有的子節點數量是有限的,而 B+ 樹的數據只存儲在葉子節點,中間節點只存儲指針,這使得每個中間節點能持有更多的子節點,相比 B 樹,B+ 樹的高度更低,且每次查詢都必須遍歷到葉子節點,使得 B+ 樹的查詢穩定性更高。
雖然上面說 B+ 樹的葉子節點存儲數據,但具體到 MySQL 對索引的實現上,葉子節點存儲的依然不是真正的數據,存儲的只是指向真實數據的指針,當然聚簇索引除外,聚簇索引存儲數據的順序和索引順序是一致的,一張表也只能建立一個聚簇索引,一般用于主鍵索引。
索引類型
MySQL 索引根據用途不同可以分為以下幾種類型:
-
普通索引(INDEX)
-
唯一索引(UNIQUE INDEX)
-
主鍵索引(PRIMARY KEY)
-
組合索引(UNION INDEX)
-
全文索引(FULLTEXT ):這是針對大量文本數據的一種特殊所索引,其組織形式也與一般索引不盡相同,主要用于查找文本中的關鍵字,只能建立在
char、varchar,text列上, 需要注意的是,直到 MySQL 5.6 InnoDB 引擎才支持了全文索引,在這之前只有 MyISAM 支持, 同時,全文索引一般配合match against使用,而不是where, 關于全文索引的用法,可以參考知乎這篇文章值得一提的是,在數據量較大時候,現將數據放入一個沒有全局索引的表中,然后再用CREATE index創建fulltext索引,要比先為一張表建立fulltext然后再將數據寫入的速度快很多。
創建索引
創建索引有三種方式;
-
創建表時直接定義
-
使用
ALTER語句修改表結構創建 -
直接使用
CREATE TABLE命令創建:CREATE TABLE table_name[col_name data type] [unique|fulltext][index|key][index_name](col_name[length])[asc|desc]-
unique|fulltext為可選參數,分別表示唯一索引、全文索引 -
index和key為同義詞,兩者作用相同,用來指定創建索引 -
col_name為需要創建索引的字段列,該列必須從數據表中該定義的多個列中選擇 -
index_name指定索引的名稱,為可選參數,如果不指定,默認col_name為索引值 -
length為可選參數,表示索引的長度,只有字符串類型的字段才能指定索引長度 -
asc或desc指定升序或降序的索引值存儲
-
刪除索引:
-
直接刪除:
DROP index_name ON table_name; -
通過修改表結構刪除
ALTER TABLE table_name DROP index_name;
索引建立的原則
天下沒有免費的午餐,索引也并不是萬能的,它帶來高查詢效率的同時也會帶來一些問題:
- 占用更多的磁盤空間(一般不考慮)
- 導致較低的寫效率:由于索引需要維持一個龐大的樹結構,加上這是一棵排序樹,這就會導致某些插入和修改操作會造成樹的重建,因此索引帶來高查詢效率的同時會導致較低的寫效率。
所以對一些不應該建立索引的列建立索引后可能導致更差的性能,在考量某一列是否應該建立索引時需要參考一個重要的法則:最左前綴法則,不滿足該法則可能導致索引失效進而退化成全表掃描。
最左前綴法則
最左前綴法則是建立聯合索引時最重要的法則。
mysql會一直向右匹配直到遇到范圍查詢(>、<、between、like)就停止匹配.
如以下的表結構:
CREATE TABLE `left` (`id` int(11) NOT NULL AUTO_INCREMENT,`a` varchar(255) NOT NULL,`b` varchar(255) NOT NULL,`c` varchar(255) NOT NULL,`d` varchar(255) NOT NULL,PRIMARY KEY (`id`),KEY `index1` (`a`,`b`,`c`)
) ENGINE=InnoDB AUTO_INCREMENT=86139 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
我們建立了 a, b, c 的組合索引后:
-
在進行等值查詢如
=或IN時, 可以不考慮順序,SQL 查詢優化器會自動調整語句順序,如執行下面兩條語句的效果是一樣的(根據索引長度我們可以推斷出對哪幾個列使用了索引):
-
可以查詢建立了聚合索引的某幾列,DBS會根據建立索引時的順序從左開始匹配能夠使用索引的列,如執行
a = “” AND b = “”時會對 a 和 b 使用索引,而在執行a = “” AND c = “"時則只會對 a 使用索引,而如果只執行b = “”時,由于第一個索引 a 就無法匹配到,所以不會使用索引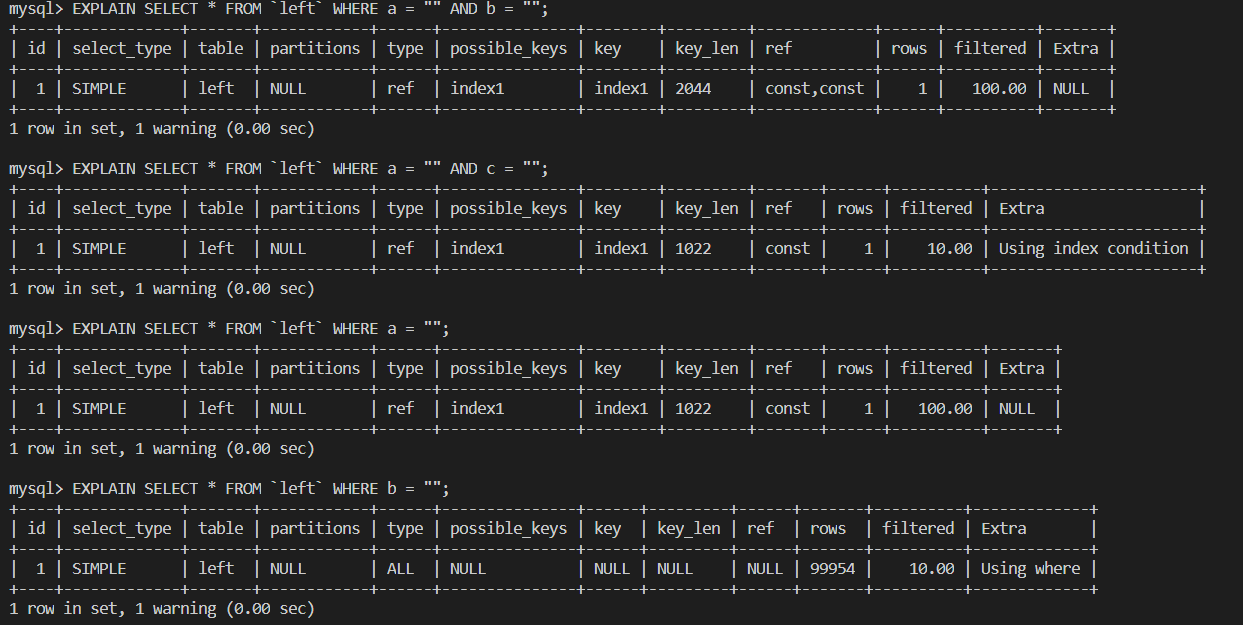
-
最左匹配原則在遇到范圍查詢:>、<、between、like 時會停止匹配,如執行
a = “” AND b > 10 AND c = “”時只會對 a 使用索引。
-
關于 like: like 相比于其他幾個要稍微復雜一點,并不是一旦遇見like就會停止匹配,而是通配符如果出現在首位才會停止匹配,如下面的情況:
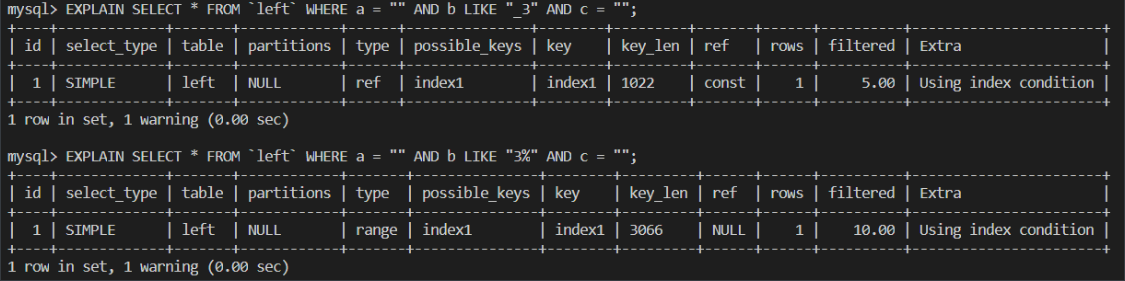
-
-
對索引列進行運算操作會導致索引失效,原因與 like 的通配符一樣,還有需要注意一點,如果索引字段是字符類型,查詢時不加引號也會導致索引失效,原因在于MySQL會自動為我們的查詢語句轉化成字符,這就相當于引入了運算操作:
SELECT * FROM `left` WHERE a = "" AND b = 1 -- 將 1 轉化為 '1' 的過程引入了運算操作導致索引失效 -
如果
OR之后的字段沒有使用索引,那么整個索引都將失效。 -
NOT IN可能導致的索引失效

為什么要最左匹配
首先要明確的是最左匹配原則適用于聯合索引,對于普通索引,不存在匹配的問題,而之所以要嚴格進行最左匹配,也是由聯合索引的數據結構形式決定的:
我們知道 MySQL 默認情況下使用 B+ 樹組織索引的數據結構,對于像上文中的聯合索引,它的結構是這樣的:
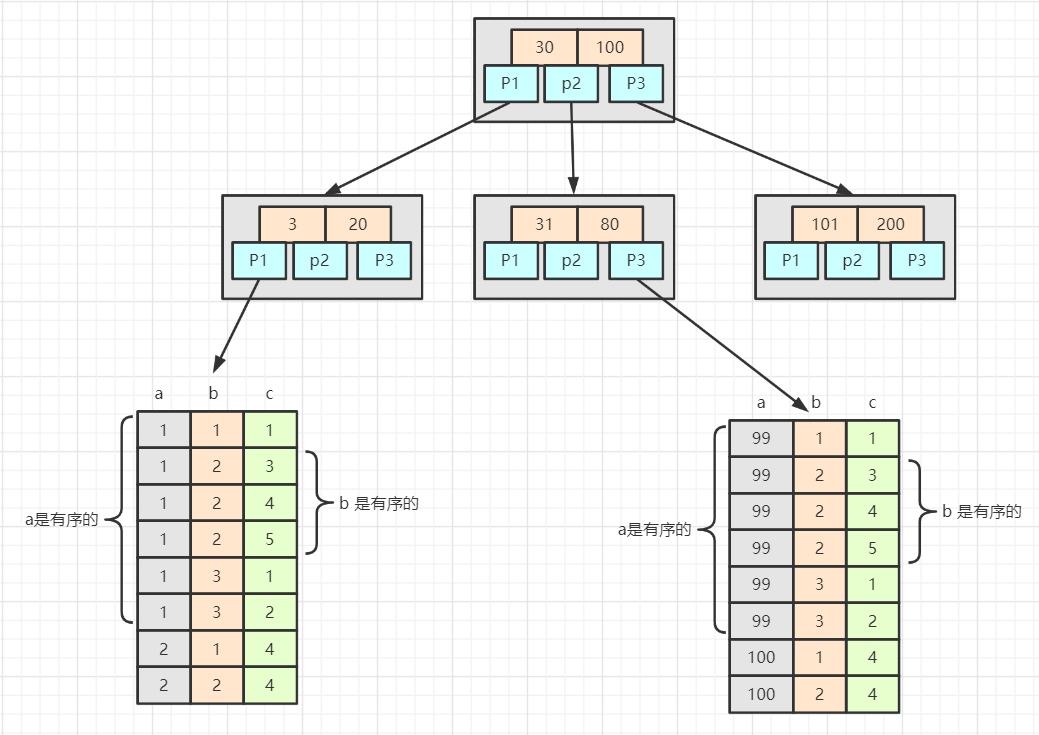
相比普通索引的葉子節點,聯合索引的葉子節點存儲所有關鍵字的數據,比如建立了a, b, c的索引,那么如上圖,每個葉子節點都會存儲a, b, c 三個關鍵字的數據信息,并且會按照建立索引時的順序排序,但中間節點只會存儲第一個關鍵字的位置指針,當我們執行類似
SELECT * FROM `table` WHERE a = "1" AND b = "2" AND c = "4"
時,數據庫會根據第一個關鍵字 a 的值 1 定位到某個葉子(圖中左邊的葉子節點),然后從所有葉子節點的數據里檢索出符合第一條規則a = "1" 的數據(圖中前六行),然后再從這些數據里檢索出符合第二條規則的數據(圖中2, 3, 4)行,依次類推直到找到或確認找不到期望數據為止。
而之所以遵循最左匹配原則,也是因為葉子節點的排序方式是按照索引建立時的順序排序的,也就是 b 只有在 a 相等的情況下才是有序的(如圖中第二列整體并不是有序的,但只看 a = 1 前提下的 b 就是有序的了),所以如果跳過 a 去查詢 b, 因為無法保證 b 的有序性,只能進行全表掃描。
like 之所以遇到以通配符開頭的情況才停止匹配也是由葉子節點的這種數據排序方式決定的,因為 like 字句如果不以通配符開頭那他開頭的部分是可以利用到排序信息的,如執行:
SELECT * FROM `left` WHERE a = "1" AND b LIKE "2%"
雖然 b 的檢索不是等值檢索,但我們任然可以根據 like 子句開頭的 “2” 快速定位到 2 ~ 4 行,但如果以通配符開頭,顯然就定位不到了。
索引建立原則
-
對經常需要修改的數據不要建立索引,一般數據的讀寫比為 10:1, 如果低于此,索引可能造成寫數據效率低下
-
對于重復讀高的數據不建議建立索引,如性別,區分度公式為:
count(distinctcol)count(?)\frac{count(distinct col)}{count(*)} count(?)count(distinctcol)?最好的區分度為 111 ,即所有數據不重復,一般要求區分度高于 0.1
-
不建議對不經常查詢的列或 “大數據” 建立索引,如 TXT, 二進制信息等。
-
建議給主鍵和外鍵建立索引,一來主鍵是唯一的,通過索引檢索可以大大提高定位速度,其次為外鍵建立索引也可以提高表之間連接的速度
-
對于經常出現在 WHERE 子句中的或經常按范圍查詢的列,建議建立索引,由于 MySQL 中使用指針連接了葉子節點,所以對于按范圍查詢的列,建立索引后可以進一步降低磁盤 IO。
-
索引列不能參與計算,保持列“干凈”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很簡單,b+樹中存的都是數據表中的字段值,但進行檢索時,需要把所有元素都應用函數才能比較,顯然成本太大。所以語句應該寫成create_time = unix_timestamp(’2014-05-29’)。
-
盡量的擴展索引,不要新建索引。比如表中已經有a的索引,現在要加(a,b)的索引,那么只需要修改原來的索引即可。
索引跳躍式掃描(INDEX SKIP SCAN)
加入我們建立了 a, b, c 順序的組合索引,但 a 的區分度不高,然后執行了 WHERE b = "" AND ... 就會出現 INDEX SKIP SCAN 的情況, 也就是說 SQL 查詢優化器跳過了 a 對后面的列使用了索引,如下面這種情況:

上圖中 songs 表結構如下:
+--------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+--------------+------+-----+---------+-------+
| id | bigint(25) | NO | PRI | NULL | |
| name | varchar(255) | NO | | NULL | |
| link | varchar(200) | NO | | NULL | |
| singer | int(11) | YES | | NULL | |
+--------+--------------+------+-----+---------+-------+
并且為該表建立了 singer, name, link 順序的組合索引, 但 singer 的區分度約為 0.04, 很低:
mysql> select COUNT(DISTINCT left(singer,110))/COUNT(*) AS singer, COUNT(DISTINCT left(name,255))/COUNT(*) AS name, COUNT(DISTINCT left(link,200))/COUNT(*) AS link FROM songs ;
+--------+--------+--------+
| singer | name | link |
+--------+--------+--------+
| 0.0390 | 0.7715 | 1.0000 |
+--------+--------+--------+
1 row in set (25.82 sec)
在這種情況下,由于 singer 的區分度很低,所以全表掃描查詢 singer 字段的代價并不是很高,同樣對于 singer 來說,使用索引的效果并不明顯,但相比之下,后面的 name 和 link 字段的區分度很高,使用索引的效果會非常明顯,這時如果由于 “無關緊要” 的 singer 導致后面真正需要索引的 name 和 link 無法使用索引顯然得不償失,因此在 MySQL 8.0 之后加入了 ISS 機制,它允許組合索引在左邊的列唯一值較少的情況下跳過左邊列對右邊列使用索引。
成本優先
索引的出現本就是為了降低查詢成本的,但若在某些情況下使用索引反而增加了查詢成本,那就不應該使用索引,MySQL 在執行查詢前會預估查詢成本,然后根據成本決定是否使用索引或使用哪個索引,不使用索引時的查詢成本包括兩部分:
-
IO 成本:指的是把數據從磁盤讀到內存的成本,前面說到磁盤IO以頁為單位,如果每次磁盤IO的成本記為 1, 那么讀取一條數據的 IO成本就是:
Cost(IO)=Data_lengthpage_sizeCost(IO) = \frac{Data\_length}{page\_size} Cost(IO)=page_sizeData_length? -
CPU 成本:是指將數據讀入內存后,還要檢測數據是否滿足條件和排序等 CPU 操作的成本,一般默認情況下每行的 CPU 成本約為 0.2
而如果表中有索引,在執行查詢前,數據庫引擎會估算使用索引所需要的成本,具體估算方法參考:xx , 估算出的值可以通過 optimizer_trace 工具查看,如果索引的成本高于全表掃描的成本,那就會放棄索引。
如執行 :
SET optimizer_trace="enabled=on";
SELECT * FROM `left` WHERE a > "1";
SELECT * FROM information_schema.OPTIMIZER_TRACE;
SET optimizer_trace="enabled=off";
后得到使用 index1 索引的成本為 54705
"analyzing_range_alternatives": {"range_scan_alternatives": [{"index": "index1","ranges": ["1 < a"],"index_dives_for_eq_ranges": true,"rowid_ordered": false,"using_mrr": false,"index_only": false,"rows": 49977,"cost": 54705,"chosen": false,"cause": "cost"}],"analyzing_roworder_intersect": {"usable": false,"cause": "too_few_roworder_scans"}
}
但全表掃描成本為:

0.2?Rows+Data_lengthpage_size=0.2?99954+473497616?1024=19990.80.2 * Rows + \frac{Data\_length}{page\_size} = 0.2 * 99954 + \frac{4734976}{16 * 1024} = 19990.8 0.2?Rows+page_sizeData_length?=0.2?99954+16?10244734976?=19990.8
顯然全表掃描的效率要高于使用索引的效率。
需要注意的是數據庫引擎只是只是在估算成本,這個值不一定準確,上面的例子從最左前綴的角度也不應該使用索引,只是為了說明并不是在任何時候數據庫引擎都會去使用索引的在涉及到低區分度,Null 值等的時候,引擎會選取一個相對最優的方案。
索引的使用建議
一. 避免索引失效
- 謹慎選擇組合索引的建立順序
- 涉及非等值操作查詢時,謹慎安排查詢語句的順序,避免范圍查詢導致索引失效
- 不要在索引字段上執行計算操作
- 匹配字符串時不要依賴 MySQL 的類型轉換
- 謹慎使用
OR - 謹慎選擇
IN,NOT IN,EXISTS
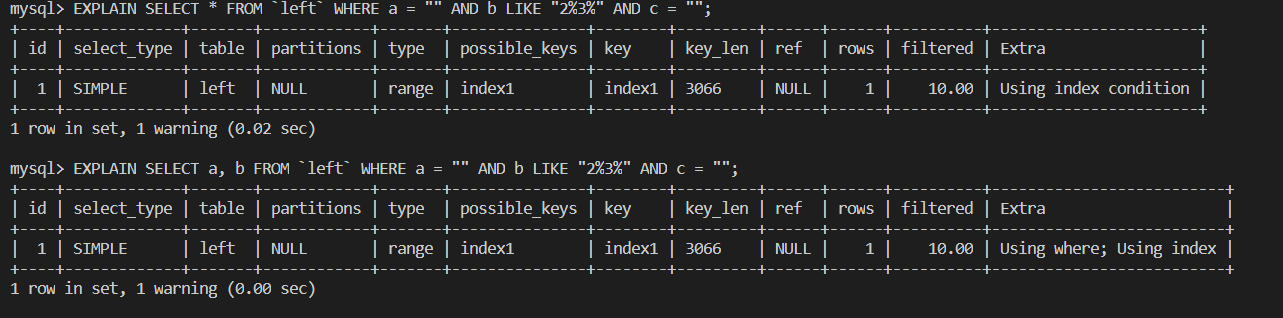
二. 使用索引覆蓋
覆蓋索引指的是索引字段覆蓋了需要查詢的所有字段,這時根據索引便可以拿到所有數據而不需要回表查詢,反之,如果使用類似 SELECT * 或 索引字段未覆蓋期望的所有字段時,未被覆蓋的字段就需要回表查詢,這便又增加了磁盤 IO 的次數,如果發生了回表查詢, EXPLAIN 的描述(Extra)字段會顯示 Using index condition 這時我們應該考慮是否需要優化。
三. 有時全表掃描更快
索引不一定能 100% 提高查詢效率,使用不當反而會使性能下降
四. 盡量使用復合索引
在每次查詢時,數據庫只會選擇一個最優的索引使用,所以使用復合索引往往優于使用多個單列索引。
總結
-
什么是索引:
- 索引是一種數據結構,用來提高在數據表中的數據查詢效率,同時也是隨機讀和有效排序的基礎。
-
為什么使用索引:
- 根本原因在于磁盤速度與內存速度差距甚大,所以我們希望能使用盡可能少的磁盤 IO 次數去拿到想要的數據,因此引入了索引,索引通過哈希表或 B+ 樹的方式存儲了索引值和數據塊的對應關系,使得能夠在較低的時間復雜度內拿到數據。
-
InnoDB 中為什么選擇 B+ 樹組織索引:
- 實現索引的數據結構必須能在較低的時間復雜度內找到索引鍵對應的數據,除了哈希表外,可以選擇排序樹,同時為了減少磁盤 IO 次數,要求這棵樹要盡可能低,要實現自平衡,不能在極端情況下退化為鏈表,再者,由于操作系統以頁為單位進行磁盤 IO,這就意味這不能為了降低樹高度無限增加一個樹節點的子節點,所以為了保證一個中間節點持有更多子節點而選擇 B+ 樹而不是 B 樹,另外,B+ 樹所有數據存儲在葉子節點,這樣每次查詢的時間復雜度都是一致的,可以獲得更高的穩定性。
-
聚簇索引和非聚簇索引的區別:
- 聚簇索引在一張表中只能有一個,一般是主鍵索引,聚簇索引的葉子節點存儲的是真實地數據。
- 非聚簇索引可以建立多個,其葉子節點存儲地并不是真實地數據,而是主鍵值,根據非聚簇索引只能拿到該行記錄地主鍵值,要拿到真實地數據還需要根據聚簇索引去查詢
-
在什么情況下使用索引:
- 讀操作比例大大高于寫操作比例時。
- 數據區分度高。
- 主鍵和外鍵建議使用。
- 經常出現在
WHERE子句中的列。
-
如何高效地使用索引:
- 建立索引時盡量使用組合索引。
- 不要對大量數據建立索引。
- 建立組合索引時認真考慮先后順序。
- 使用索引時嚴格遵循最左前綴原則,避免索引失效。
- 盡量使用索引覆蓋,避免
SELECT *
參考
【tutorialspoint】mysql-indexes
【美團技術文章】MySQL索引原理及慢查詢優化
【知乎】平衡二叉樹、B樹、B+樹、B*樹 理解其中一種你就都明白了
【CSDN】數據庫中的索引技術——哈希索引
【360doc】數據庫建立索引的原則
【博客園】sql 索引類型
索引跳躍式掃描(INDEX SKIP SCAN)
【騰訊云】 MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!







)








)
)

