Cron 源碼閱讀
robfig/cron/v3 是一個 Golang 的定時任務庫,支持 cron 表達式。Cron 的源碼真實教科書級別的存在(可能是我菜 …),真的把低耦合高內聚體現地淋漓盡致,另外其中涉及的裝飾器模式,并發處理等都很值得學習。
使用 cron 可以很方便的實現一個定時任務,如下:
go get github.com/robfig/cron/v3@v3.0.0
package mainimport "github.com/robfig/cron/v3"c := cron.New()
// 添加一個任務,每 30 分鐘 執行一次
c.AddFunc("30 * * * *", func() { fmt.Println("Every hour on the half hour") })
// 開始執行(每個任務會在自己的 goroutine 中執行)
c.Start()// 允許往正在執行的 cron 中添加任務
c.AddFunc("@daily", func() { fmt.Println("Every day") })// 檢查上一個和下一個任務執行的時間
inspect(c.Entries())
..
c.Stop() // 停止調度,但正在運行的作業不會被停止
通過上面的示例,可以發現, cron 最常用的幾個函數:
New(): 實例化一個 cron 對象Cron.AddFunc(): 向 Cron 對象中添加一個作業,接受兩個參數,第一個是cron表達式,第二個是一個無參無返回值的函數(作業)Cron.Stop(): 停止調度,Stop 之后不會再有未執行的作業被喚醒,但已經開始執行的作業不會受影響。
關于 cron 表達式可以先看看 cron表達式的介紹與使用 這篇文章,一個 cron 表達式是一個由 5 個空格分隔的字符串,每一部分從左到右分別表示 秒,分, 時, 天,月, 星期,每個部分由數字和一些特殊字符表示一個約定的時間項,在 robfig/cron 中,每一部分允許的特殊字符如下:
| Field name | 是否強制 ? | 允許的值 | 允許的特殊字符 |
|---|---|---|---|
| Seconds | Yes | 0-59 | * / , - |
| Minutes | Yes | 0-59 | * / , - |
| Hours | Yes | 0-23 | * / , - |
| Day of month | Yes | 1-31 | * / , - ? |
| Month | Yes | 1-12 or JAN-DEC | * / , - |
| Day of week | Yes | 0-6 or SUN-SAT | * / , - ? |
這些特殊字符的含義如下:
*: 匹配該字段所有值,如0 0 * 1 1 *, 第三個字段為*表示(1 月 1 日)每小時。/: 表示范圍增量,如*/12 * * * * *表示每 12 秒執行一次,: 用來分隔同一組中的項目,如* * 5,10,15 3,4 * *表示每個三月或四月的 5, 10, 15 號(3.05, 3.10, 3.15, 4.05, 4.10,4.15)-: 表示范圍,如*/5 * 10-12 * * *表示每天十點到十二點每五秒執行一次?: 同*
cron 表達式雖然簡單,但他卻能滿足定時任務復雜的使用場景,比如每周一到周五早上十點就可以表示為 0 0 10 * * 1-5,除此之外,cron 還有幾個預定義的時間表:
| Entry | Description | Equivalent To |
|---|---|---|
| @yearly (or @annually) | Run once a year, midnight, Jan. 1st | 0 0 1 1 * |
| @monthly | Run once a month, midnight, first of month | 0 0 1 * * |
| @weekly | Run once a week, midnight between Sat/Sun | 0 0 * * 0 |
| @daily (or @midnight) | Run once a day, midnight | 0 0 * * * |
| @hourly | Run once an hour, beginning of hour | 0 * * * * |
表示每隔多長時間時,你還可以使用預定義的 @every <duration> 如每隔十分鐘就可以表示為 @every 10m
…
源碼概覽
cron 并不是一個很大的庫,核心文件與作用如下:
chain.go: 裝飾器模式,使用 Chain 可以給一個作業添加多個裝飾器,以實現日志記錄等功能constantdelay.go:顧名思義,提供了一個簡單的常量延遲,如 每5分鐘,最小粒度支持到秒cron.go:提供核心功能logger.go: 定義了一個 Logger 接口,使之能插入到結構化日志系統中option.go:對默認行為的修改相關parser.go:解析 cron 表達式spec.go:
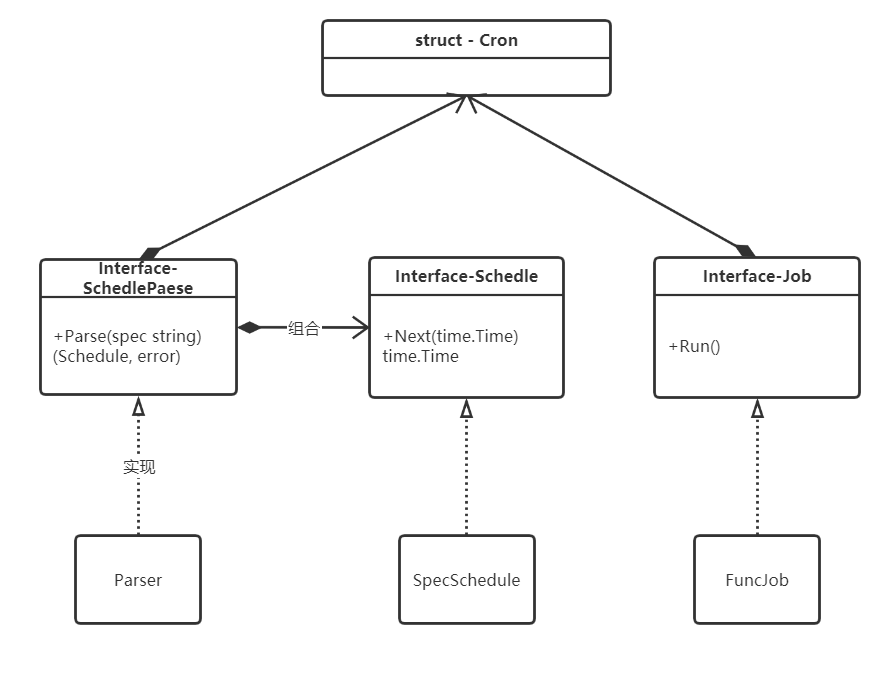
核心數據結構和接口
type Entry truct
Entry 是對添加到 Cron 中的作業的封裝,每個 Entry 有一個 ID,除此之外,Entry 里保存了這個作業上次運行的時間和下次運行的時間。
type EntryID inttype Entry struct {ID EntryIDSchedule ScheduleNext time.TimePrev time.TimeWrappedJob JobJob Job
}
type Cron struct
type Cron struct {entries []*Entry // 保存了所有加入到 Cron 的作業chain Chainstop chan struct{} // 接收 Stop() 信號的 chanadd chan *Entry // Cron 運行過程中接收 AddJob() 信號的 chan remove chan EntryID // 接收移除 Job 信號的 chansnapshot chan chan []Entry // 快照信號running bool // 標志 Cron 是否在運行中logger LoggerrunningMu sync.Mutex // Cron 運行前需要搶占該鎖,保證并發安全location *time.Locationparser ScheduleParser // cron 表達式的解析器nextID EntryID // 即將加入的 Job 對應的 Entry 的 IDjobWaiter sync.WaitGroup
}
interface
// Cron 表達式解析器接口,Parse 方法接收一個 Cron 表達式 spec,
// 返回一個解析出的 Schedule 類型對象
type ScheduleParser interface {Parse(spec string) (Schedule, error)
}// Schedule 類型的對象用來表輸 Job 的工作周期,它包含一個 Next() 方法,
// 用來返回 Job 下一次執行的時間
type Schedule interface {Next(time.Time) time.Time
}// Job is an interface for submitted cron jobs.
type Job interface {Run()
}
對接口的實現
ScheduleParser 的實現
在 parser.go 中,我們可以找到對 ScheduleParser 接口的實現 Parser:
type Parser struct {options ParseOption
}func (p Parser) Parse(spec string) (Schedule, error) {...}
Parser 通過 NewParser() 方法創建:
func NewParser(options ParseOption) Parser {optionals := 0if options&DowOptional > 0 {optionals++}if options&SecondOptional > 0 {optionals++}if optionals > 1 {panic("multiple optionals may not be configured")}return Parser{options}
}
除此之外,parser.go 中,創建了一個私有的全局變量 standardParser:
var standardParser = NewParser(Minute | Hour | Dom | Month | Dow | Descriptor,
)
后續 Cron 所使用的就是這個解析器。
Schedule 的實現
Schedule 的實現位于 spec.go 中,定義了一個 SpecSchedule 結構體,實現了 Schedule 接口:
type SpecSchedule struct {Second, Minute, Hour, Dom, Month, Dow uint64Location *time.Location
}func (s *SpecSchedule) Next(t time.Time) time.Time {...}
Job 的實現
Job 其實就是用戶傳入的一個函數,對其的實現位于 cron.go 中:
type FuncJob func()func (f FuncJob) Run() { f() }
總結
Cron 中核心數據結構的類圖如下:
New()
cron.go 中的 New() 方法用來創建并返回一個 Corn 對象指針,其實現如下:
func New(opts ...Option) *Cron {c := &Cron{entries: nil,chain: NewChain(),add: make(chan *Entry),stop: make(chan struct{}),snapshot: make(chan chan []Entry),remove: make(chan EntryID),running: false,runningMu: sync.Mutex{},logger: DefaultLogger,location: time.Local,parser: standardParser,}for _, opt := range opts {opt(c)}return c
}
這個函數接收一組可變的 Option 類型的參數,該類型實際上是一類函數:
type Option func(*Cron)
Corn 內置了一些 Option 類型的函數,都在 option.go 中,以 With 開頭,用來改變 Cron 的默認行為,在 New() 中創建完 Cron 之后,會依次執行這些函數。
另外,注意 c.parser 的值是 standardParser, 這個變量在上一節介紹過,位于 parser.go 中,是一個 Parse 類型的變量, Parse 是對 SchedleParse 的一個默認實現。
AddFunc()
AddFunc() 用于向 Corn 中添加一個作業:
func (c *Cron) AddFunc(spec string, cmd func()) (EntryID, error) {// 包裝return c.AddJob(spec, FuncJob(cmd))
}func (c *Cron) AddJob(spec string, cmd Job) (EntryID, error) {schedule, err := c.parser.Parse(spec)if err != nil {return 0, err}return c.Schedule(schedule, cmd), nil
}
AddFunc() 相較于 AddJob() 幫用戶省去了包裝成 Job 類型的一步,在 AddJob() 中,調用了 standardParser.Parse() 將 cron 表達式解釋成了 schedule 類型,最終,他們調用了 Schedule() 方法:
func (c *Cron) Schedule(schedule Schedule, cmd Job) EntryID {c.runningMu.Lock()defer c.runningMu.Unlock()c.nextID++entry := &Entry{ID: c.nextID,Schedule: schedule,WrappedJob: c.chain.Then(cmd),Job: cmd,}if !c.running {c.entries = append(c.entries, entry)} else {c.add <- entry}return entry.ID
}
這個方法負責創建 Entry 結構體,并把它追加到 Cron 的 entries 列表中,如果 Cron 已經處于運行狀態,會將這個創建好的 entry 發送到 Cron 的 add chan 中,在 run() 中會處理這種情況。
Entries() 和 Entry()
這兩個方法被用來返回 Cron entries 的一組快照,Entries() 返回所有作業的快照,Entry(id EntryID) 根據 ID 返回特定作業的快照,其實就是遍歷了一遍 Entries() 的返回值:
func (c *Cron) Entry(id EntryID) Entry {for _, entry := range c.Entries() {if id == entry.ID {return entry}}return Entry{}
}
關鍵在于 Entries() 的實現上:
func (c *Cron) Entries() []Entry {c.runningMu.Lock()defer c.runningMu.Unlock()if c.running {replyChan := make(chan []Entry, 1)c.snapshot <- replyChanreturn <-replyChan}return c.entrySnapshot()
}
獲取快照時,根據 Cron 是否在運行有不同的處理邏輯,為了避免獲取快照過程中 Cron 開始運行,需要競爭 runningMutex;
如果 Cron 沒在運行,直接調用 entrySnapshot() 返回快照:
func (c *Cron) entrySnapshot() []Entry {var entries = make([]Entry, len(c.entries))for i, e := range c.entries {entries[i] = *e}return entries
}
這種情況很簡單,如果 Cron 已經在運行中了,會向 c.snapshot 發送一個信號,在 cron.run() 中會處理這個信號:
case replyChan := <-c.snapshot:replyChan <- c.entrySnapshot()continue
這有點向一個鉤子,Entries() 中創建了一個新的 chan replyChan, 并將其發送給了 c.snapshot, run() 中通過多路復用監聽到這個信號后,調用了 c.entrySnapshot() ,并將結果發送到了 replyChan 中,Entries() 阻塞等待結果并返回。
既然最終調用的都是 c.entrySnapshot() 為什么要分兩種情況呢?后面再說。
Remove()
Remove() 用于刪除一個作業,實現邏輯和 Entries() 類似:
func (c *Cron) Remove(id EntryID) {c.runningMu.Lock()defer c.runningMu.Unlock()if c.running {c.remove <- id} else {c.removeEntry(id)}
}func (c *Cron) removeEntry(id EntryID) {var entries []*Entryfor _, e := range c.entries {if e.ID != id {entries = append(entries, e)}}c.entries = entries
}
run() 中處理 c.remove 信號:
case id := <-c.remove:timer.Stop()now = c.now()c.removeEntry(id)c.logger.Info("removed", "entry", id)
Stop()
Stop() 用來停止 Cron 的運行,但已經在執行中的作業是不會被打斷的,也就是從執行 Stop() 之后,不會再有新的作業被調度:
func (c *Cron) Stop() context.Context {c.runningMu.Lock()defer c.runningMu.Unlock()if c.running {c.stop <- struct{}{}c.running = false}ctx, cancel := context.WithCancel(context.Background())go func() {// 等待所有已經在執行的作業執行完畢c.jobWaiter.Wait()// 會發出一個 cancelCtx.Done() 信號cancel()}()return ctx
}
大體邏輯和上面的一樣,比較巧妙地是 Stop() 返回了一個 Context, 具體來說是一個 cancelCtx, 用戶可以監聽 cancelCtx.Done() 得知什么時候 Cron 真的停止了.
Start()
Start() 用于開始執行 Cron:
func (c *Cron) Start() {c.runningMu.Lock()defer c.runningMu.Unlock()if c.running {return}c.running = truego c.run()
}
這個函數干了三件事:
- 獲取鎖
- 將
c.running置為true表示 cron 已經在運行中了 - 開啟一個 goroutine 執行
c.run(),run中會一直輪循c.entries中的 entry, 如果一個 entry 允許執行了,就會開啟單獨的 goroutine 去執行這個作業
run是整個 cron 的一個核心,它負責處理 cron 開始執行后的大部分事情,包括添加作業,刪除作業,執行作業等,這是一個近一百行的大函數,其結構如下:
func (c *Cron) run() {c.logger.Info("start")// 第一部分now := c.now()for _, entry := range c.entries {entry.Next = entry.Schedule.Next(now)c.logger.Info("schedule", "now", now, "entry", entry.ID, "next", entry.Next)}// 第二部分for {// 2.1sort.Sort(byTime(c.entries))// 2.2var timer *time.Timerif len(c.entries) == 0 || c.entries[0].Next.IsZero() {timer = time.NewTimer(100000 * time.Hour)} else {timer = time.NewTimer(c.entries[0].Next.Sub(now))}// 2.3for {select {}break}}
}
大概包含下面這幾部分:
-
第一部分:遍歷了
c.entries列表,通過schedule.Next()計算出這個作業下一次執行的時間,并賦值給了entry.Next字段。 -
第二部分是一個死循環,這一部分又可以分為三個部分:
-
2.1:調用了 sort 的快排,其實是對 entries 中的元素按
Next字段的時間線后順序排序。 -
2.2:這一部分是對定時器的一個初始化操作:如果沒有可以執行的作業,定時器被設置為十萬小時后觸發(其實就是休眠),否則定時器會在第一個作業允許被執行時觸發,定時器觸發后, 2.3 部分會去做剩下的事。
-
2.3:這又是整個
run的核心,其主體是一個死循環(其實它會退出,不算是死循環),這個循環里面的核心又是一個select多路復用,這個多路復用里監聽了五種信號,這五種信號是怎樣發出的我們在上面其實已經說過了,他們分別是定時器觸發信號timer.C, 運行過程中添加作業的信號c.add, 快照信號c.snapshot, cron 停止的信號c.stop, 移除作業的信號c.remove。for {select {case now = <-timer.C:// ...case newEntry := <-c.add:// ...case replyChan := <-c.snapshot:// ...continuecase <-c.stop:// ...returncase id := <-c.remove:// ...}break }下面我們分開看對每一種信號的處理:
-
對 timer.C 的處理
case now = <-timer.C:now = now.In(c.location)c.logger.Info("wake", "now", now)// Run every entry whose next time was less than nowfor _, e := range c.entries {if e.Next.After(now) || e.Next.IsZero() {break}c.startJob(e.WrappedJob)e.Prev = e.Nexte.Next = e.Schedule.Next(now)c.logger.Info("run", "now", now, "entry", e.ID, "next", e.Next)}
這個信號被觸發有兩種情況:
- 排序后 entries 中第 0 位的作業可以被執行了。
- 休眠了十萬小時后,定時器被觸發…
在處理這類信號時,run 會遍歷所有的 entries, 因為這些作業都是按下一次執行時間排過序的,所以如果因為第一種情況出發了信號,說明至少有一個作業是可以執行的,我們遍歷整個 entries,直到遇到一個作業可執行時間大于當前時間,說明前面遍歷到的都是可以執行的,后面的都是不可以執行的;如果因為第二種情況發出來這個信號,則在第一次判斷時就會 break
執行作業調用了 cron.startJob() 方法,這個方法會為每個作業開啟一個 goroutine 去執行用戶函數:
func (c *Cron) startJob(j Job) {c.jobWaiter.Add(1)go func() {defer c.jobWaiter.Done()j.Run()}()
}
這里的操作簡單粗暴,直接開 goroutine 去執行,在使用時要注意定時任務一定要能結束,定時任務執行時間過長且執行速率很高時,可能造成 goroutine 泄露,進而可能導致內存溢出。
還有關于 jobWaiter,他是為了通知用戶程序 Cron 什么時候真的結束了,結合 Stop() 可以理解。
對 c.add 的處理
case newEntry := <-c.add:timer.Stop()now = c.now()newEntry.Next = newEntry.Schedule.Next(now)c.entries = append(c.entries, newEntry)c.logger.Info("added", "now", now, "entry", newEntry.ID, "next", newEntry.Next)
如果 cron 在運行的過程中有作業被加入,會停止定時器(新加入的作業需要重新進行排序),然后計算新作業的下一次執行時間(cron 未運行時添加作業沒有這一步,是因為在 Start 的第一步會集中計算,集中計算結束后,進入第二步的死循環,就不會再次集中計算了),最后把新作業加入到 entries 列表中。
對 c.snapshot 的處理
case replyChan := <-c.snapshot:replyChan <- c.entrySnapshot()continue
上面已經說過這個信號,如果 Cron 在運行過程中,用戶請求獲取作業快照會觸發這個信號,之所以不在 Entries() 中直接返回,是因為一旦 Cron 被啟動,entries 列表中的元素就會被不斷排序,而這個操作是在另一個 goroutine 中進行的,這就可能導致直接返回的數據是臟數據。
另外,請注意這個 continue, 如果沒有 continue, 這個 case 執行完后,select 會退出,接著執行 break, 這可能導致與 c.snapshot 同時滿足的其他事件不被執行;可以說,select 外層的那個 for 就是未這種情況存在的。
那為什么只有 c.snapshot 需要 continue 呢?其實這個 select 最終的目的是讓 run 重新阻塞等待下一個事件信號,其他幾個不重新阻塞,原因在于他們執行完后需要對 entries 重新排序,而快照不需要,仔細對比 c.add 和 c.snapshot, 就會恍然大悟。
對 c.stop 的處理
case <-c.stop:timer.Stop()c.logger.Info("stop")return
這就很簡單了,停止定時器,結束 run goroutine, 因為作業的執行在自己單獨的 goroutine 中,所以 run() goroutine 的返回不會影響他們。
對 c.remove 的處理
case id := <-c.remove:timer.Stop()now = c.now()c.removeEntry(id)c.logger.Info("removed", "entry", id)
邏輯和 c,add 是一樣的。
Option
開頭說過,New() 時可以接收一組 option 參數,用以改變 Cron 的默認行為,這些參數其實是一些函數,他們會在 Cron 初始化后被依次執行,Cron 內置了一些函數, 他們會返回 Option 類型的函數,下面簡單了解一些這些函數的作用:
WithLocation
用于改變時區,默認情況下通過 time.Local 獲取
func WithLocation(loc *time.Location) Option {return func(c *Cron) {c.location = loc}
}
可以這樣使用:
c := cron.New(cron.WithLocation(nyc))
WithSeconds
用于覆蓋默認的 Cron 解析格式,默認的格式是 分鐘 小時 日 月 星期,也就是 Minute | Hour | Dom | Month | Dow
func WithSeconds() Option {return WithParser(NewParser(Second | Minute | Hour | Dom | Month | Dow | Descriptor,))
}
允許的字段如下:
const (Second ParseOption = 1 << iota // Seconds field, default 0SecondOptional // Optional seconds field, default 0Minute // Minutes field, default 0Hour // Hours field, default 0Dom // Day of month field, default *Month // Month field, default *Dow // Day of week field, default *DowOptional // Optional day of week field, default *Descriptor // Allow descriptors such as @monthly, @weekly, etc.
)
WithParser
如果你覺得 Cron 表達式是在難以理解,也記不住,可以寫一個自己的解析器,用這個函數替代原來的解析器。
func WithParser(p ScheduleParser) Option {return func(c *Cron) {c.parser = p}
}
WithChain
修改默認修飾器
func WithChain(wrappers ...JobWrapper) Option {return func(c *Cron) {c.chain = NewChain(wrappers...)}
}
WihLogger
使用自定義的 logger
func WithLogger(logger Logger) Option {return func(c *Cron) {c.logger = logger}
}
Chain
這是一個很值得學習的裝飾器模式,我們先看一下默認情況下,裝飾器是怎么工作的:
Cron 結構體只有一個 Chain 類型的 chain 字段,該字段在執行 New() 時會通過 NewChain() 初始化:
c := &Cron{entries: nil,chain: NewChain(),// ...
}
這個 NewChain() 接收一組裝飾器函數,并且會用這些函數初始化一個 Chain 對象返回:
type Chain struct {wrappers []JobWrapper
}func NewChain(c ...JobWrapper) Chain {return Chain{c}
}
每個 Entry 結構體持有一個 WrappedJob Job 屬性,在 Schedule() 中初始化時,會調用 chain 的 Than() 方法初始化:
entry := &Entry{ID: c.nextID,Schedule: schedule,WrappedJob: c.chain.Then(cmd),// ...
}
在 Then() 中,這些裝飾器會被執行:
func (c Chain) Then(j Job) Job {for i := range c.wrappers {j = c.wrappers[len(c.wrappers)-i-1](j)}return j
}
Then() 返回的是執行完裝飾器之后的 Job(被裝飾后的 Job), 這也解釋了為什么在 run() 中,傳遞給 startJob() 的是 e.WrappedJob 而不是 e.job.
了解了裝飾器是如何工作的,我們再來看 chain.go 中提供的三個內置裝飾器
Recover
類似于內置的 recover(),它會捕捉運行過程中的 panic,并使用提供的 logger 記錄下來,其實做的事情就是往用戶的 Job 里插入了一個 defer func(){}()
func Recover(logger Logger) JobWrapper {return func(j Job) Job {return FuncJob(func() {defer func() {if r := recover(); r != nil {const size = 64 << 10buf := make([]byte, size)buf = buf[:runtime.Stack(buf, false)]err, ok := r.(error)if !ok {err = fmt.Errorf("%v", r)}logger.Error(err, "panic", "stack", "...\n"+string(buf))}}()j.Run()})}
}
DelayIfStillRunning
這個裝飾器的作用是保證一個 Job 的前一次執行完,后一次才執行,比如有一個 Job 需要執行 10s, 但執行頻率是一秒一次,如果我們想要保證同時只有一個相同的 Job 被執行,就可以使用這個裝飾器,在實現上,他是為每個 Job 添加了一個排它鎖實現的,Job 執行前獲取該鎖,退出時釋放鎖,當一個 Job 等待該鎖的時間大于一分鐘,會記錄在日志中,設計很巧妙。
func DelayIfStillRunning(logger Logger) JobWrapper {return func(j Job) Job {var mu sync.Mutexreturn FuncJob(func() {start := time.Now()mu.Lock()defer mu.Unlock()if dur := time.Since(start); dur > time.Minute {logger.Info("delay", "duration", dur)}j.Run()})}
}
SkipIfStillRunning
上面那個是等待執行完,這個是如果上一個還在執行,就直接跳過,在實現上,這個裝飾器使用了一個容量為 1 的 chan, 在執行 Job 前,會消費 chan 里的數據,執行完后,再往 chan 里填一個數據,通過 select 監聽 chan, 如果里面有數據,則執行,否則說明上一個還在執行,只打印一個日志就好了。
func SkipIfStillRunning(logger Logger) JobWrapper {return func(j Job) Job {var ch = make(chan struct{}, 1)ch <- struct{}{}return FuncJob(func() {select {case v := <-ch:defer func() { ch <- v }()j.Run()default:logger.Info("skip")}})}
}
總結
Cron 的幾個特點:
- 允許在允許中添加或刪除 Job:通過 chan 發送信號,select 監聽,重新排序。
- 裝飾器機制:允許給 Job 添加裝飾器,裝飾器會在 Entry 初始化時執行。
- 低耦合:
New()時可以傳遞Option, 以此可以改變一些默認行為,如可以實現自己的 cron 解釋器。 - 每個 Job 使用單獨的 goroutine 執行。
- Stop Cron 不會停止已經開始執行但為執行完的 Job, 可以通過
Context得知什么時候執行完了。



)






![[轉]關于凸優化的一些簡單概念](http://pic.xiahunao.cn/[轉]關于凸優化的一些簡單概念)






的關系)
![[譯] Bounds Check Elimination 邊界檢查消除](http://pic.xiahunao.cn/[譯] Bounds Check Elimination 邊界檢查消除)
