?
?
不多說,直接上干貨!
?
?
?
?
SparkSQL數據源:從各種數據源創建DataFrame
因為 spark sql,dataframe,datasets 都是共用 spark sql 這個庫的,三者共享同樣的代碼優化,生成以及執行流程,所以 sql,dataframe,datasets 的入口都是 sqlContext。
可用于創建 spark dataframe 的數據源有很多:

?
?
?
?
?
SparkSQL數據源:RDD
val sqlContext = new org.apache.spark.sql.SQLContext(sc)// this is used to implicitly convert an RDD to a DataFrame. import sqlContext.implicits._// Define the schema using a case class.case class Person(name: String, age: Int)// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)) sqlContext.createDataFrame(people)?
?
?
?
?
SparkSQL數據源:Hive
當從Hive 中讀取數據時,Spark SQL 支持任何Hive 支持的存儲格式(SerDe),包括文件、RCFiles、ORC、Parquet、Avro,以及Protocol Buffer(當然Spark SQL也可以直接讀取這些文件)。
要連接已部署好的Hive,需要拷貝hive-site.xml、core-site.xml、hdfs-site.xml到Spark 的./conf/ 目錄下即可
如果不想連接到已有的hive,可以什么都不做直接使用HiveContext:
Spark SQL 會在當前的工作目錄中創建出自己的Hive 元數據倉庫,叫作metastore_db
如果你嘗試使用HiveQL 中的CREATE TABLE(并非CREATE EXTERNAL TABLE)語句來創建表,這些表會被放在你默認的文件系統中的/user/hive/warehouse 目錄中(如果你的classpath 中有配好的hdfs-site.xml,默認的文件系統就是HDFS,否則就是本地文件系統)。
?
?
?
?
SparkSQL數據源:Hive讀寫
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// Queries are expressed in HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
?
?
?
?
SparkSQL數據源:訪問不同版本的metastore
從Spark1.4開始,Spark SQL可以通過修改配置去查詢不同版本的?Hive metastores(不用重新編譯)

?
?
?
?
?
?
?
?
SparkSQL數據源:Parquet
Parquet(http://parquet.apache.org/)是一種流行的列式存儲格式,可以高效地存儲具有嵌套字段的記錄。
Parquet 格式經常在Hadoop 生態圈中被使用,它也支持Spark SQL 的全部數據類型。Spark SQL 提供了直接讀取和存儲Parquet 格式文件的方法。
val sqlContext = new org.apache.spark.sql.SQLContext(sc)// this is used to implicitly convert an RDD to a DataFrame. import sqlContext.implicits._// Define the schema using a case class.case class Person(name: String, age: Int)// Create an RDD of Person objects and register it as a table.val people = sc.textFile("examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()people.write.parquet("xxxx")val parquetFile = sqlContext.read.parquet("people.parquet")//Parquet files can also be registered as tables and then used in SQL statements.parquetFile.registerTempTable("parquetFile")val teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
?
?
?
?
?
?
?
SparkSQL數據源:Parquet-- Partition Discovery
在Hive中通常會用分區表來優化性能,比如:
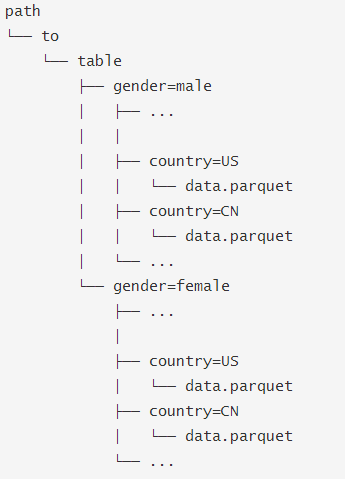
SQLContext.read.parquet或者SQLContext.read.load只需要指定path/to/table,SparkSQL會自動從路徑中提取分區信息,返回的DataFrame?的schema?將是:

?
當然你可以使用Hive讀取方式:
hiveContext.sql("FROM src SELECT key, value").
?
?
?
?
?
?
SparkSQL數據源:Json
SparkSQL支持從Json文件或者Json格式的RDD讀取數據
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 可以是目錄或者文件夾val path = "examples/src/main/resources/people.json"val people = sqlContext.read.json(path)// The inferred schema can be visualized using the printSchema() method. people.printSchema()// Register this DataFrame as a table.people.registerTempTable("people")// SQL statements can be run by using the sql methods provided by sqlContext.val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")// Alternatively, a DataFrame can be created for a JSON dataset represented by// an RDD[String] storing one JSON object per string.val anotherPeopleRDD = sc.parallelize("""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)val anotherPeople = sqlContext.read.json(anotherPeopleRDD)
?
?
?
?
?
?
?
SparkSQL數據源:JDBC
val jdbcDF = sqlContext.read.format("jdbc").options(Map("url" -> "jdbc:postgresql:dbserver","dbtable" -> "schema.tablename")).load()
?
?
支持的參數:

?
?
?





一致性哈希算法詳解 一點課堂(多岸教育))




【批量導入數據】)



(原理+代碼)——最全總結)




)