- Mongodb的更新方式有?
- db.集合名.update() 函數:用于更新已存在的文檔。
語法格式:db.COLLECTION_NAME.update({查詢條件},{更新內容},{更新參數(可選)})
注:這種方式會覆蓋原有的文檔。
- 使用更新操作符
- 使用 save()函數更新文檔
- Mongodb的update更新?
db.集合名.update({key:“value”},{key:“value”})
- Mongodb的更新操作符有哪些 都是什么意思?
$set:更新文檔(只更新指定鍵,不會覆蓋整個文檔),若該鍵不存在,會自動創建,并插入數據
$unset:刪除指定鍵
$push:向文檔的某個數組類型的鍵添加一個數組元素,不過濾重復的數據。添 加時鍵存在,要求鍵值類型必須是數組;鍵不存在,則創建數組類型的鍵
$inc:對文檔的某個值為數字型(只能為滿足要求的數字)的鍵進行增減的操作。
$pop 操作符:刪除數據元素,給定值1表示從數組尾部刪除,-1表示從數組頭部刪除。
$pull 操作符:從數組中刪除滿足條件的元素
$pullAll 操作符:從數組中刪除滿足條件的多個元素
$rename 操作符:對鍵進行重新命名。
- Mongodb的save()更新?
save() 方法通過傳入的文檔來替換已有文檔。
語法格式:db.集合名.save({文檔})
- Mongodb刪除文檔的三種方式?
- remove()函數
使用 remove()函數可刪除集合中的指定文檔。
語法格式:remove({指定刪除條件},刪除參數(可選參數))
如果使用的條件在集合中可以匹配多條數據,那么 remove()函數會刪除所有滿足條件的 數據。我們可以在 remove 函數中給定 justOne,表示只刪除第一條,在 remove 函數中給定
注意:remove() 方法 并不會真正釋放空間。需要繼續執行 db.repairDatabase() 來回收 磁盤空間 參數 1 即可。
2. deleteOne()函數
deleteOne()函數是官方推薦刪除文檔的方法。該方法只刪除滿足條件的第一條文檔。
3.deleteMany()函數
deleteMany 函數是官方推薦的刪除方法。該方法刪除滿足條件的所有數據。 再次插入兩條測試數據
刪除集合中的所有文檔 1.remove({}) 、2.deleteMany({})
- Mongodb如何實對文檔的查詢,請舉例說明?
1 find()函數
在 MongoDB 中可以使用 find()函數查詢文檔。
語法格式為:find({查詢條件(可選)},{指定投影的鍵(可選)}) 如果未給定參數則表示查詢所有數據。
pretty()函數可以使用格式化的方式來顯示所有文檔。
2 findOne()函數
findOne()函數只返回滿足條件的第一條數據。如果未做投影操作該方法則自帶格式化功 能。
語法格式:findOne({查詢條件(可選)},{投影操作(可選)})
3 模糊查詢
在 MongoDB 中可以通過//與^ 、$實現模糊查詢,注意使用模糊查詢時查詢條件不能放到 雙引號或單引號中。使用^表示起始位置,使用$表示結尾位置。
- Mongodb中的投影操作指的是?
在 find 函數中我們可以指定投影鍵。
語法格式為:find({查詢條件},{投影鍵名:1(顯示該列)|0(不顯示該列),投影鍵名:1|0,......})
_id 列默認為顯示列。如果不顯示_id 可在投影中通過 0 過濾
- 條件運算符有哪些 分別什么意思?
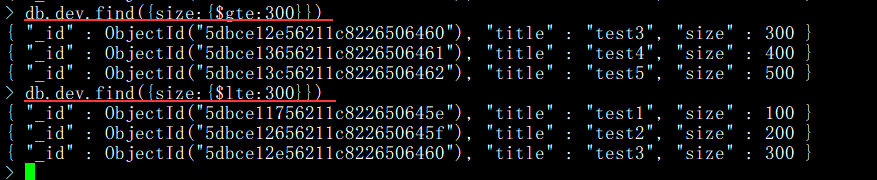
$gt:大于指定條件,用于數字或日期運算
$lt:小于指定條件,用于數字或日期運算

$gte:大于等于指定條件,用于數字或日期運算
$lte:小于等于指定條件,用于數字或日期運算
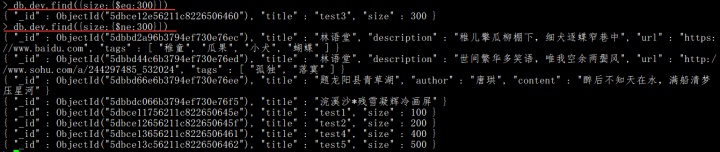
$eq:等于指定條件,用于數字或日期運算
$ne:不等于指定條件,用于數字或日期運算
$and:表示多條件間的并且關系
語法格式為:find({$and:[{條件一},{,條件二},.......]})

注意:這種方式只能當參與判斷的條件key相同時使用

$or:表示多條件間的或者關系。
語法格式為:find({$or:[{條件一},{條件二},.....]})

8.1and和or如何聯合使用?
查詢 title 為 test5 并且 size 等于 500,或者 size 小于 400 的文檔。

$type:根據value的類型查詢

- 每頁顯示5條查看第5頁的數據如何實現?
limit函數:使用 MongoDB 的 Limit 函數, limit()函數接受一個數字參數,該參數指定從 MongoDB 中讀取的記錄條數。
語法格式:db.COLLECTION_NAME.find().limit(NUMBER)

skip函數:使用 skip()函數來跳過 指定數量的數據,skip 函數同樣接受一個數字參數作為跳過的記錄條數。
語法格式:db.COLLECTION_NAME.find().limit(NUMBER).skip(NUMBER)

實現分頁顯示第五頁數據,每頁五條:
db.dev.find({},{title:1,_id:0}).skip(25).limit(5)
注意:我們可以使用 skip 函數與 limit 函數實現 MongoDB 的分頁查詢,但是官方并不推薦這 樣做,因為會掃描全部文檔然后在返回結果,效率過低。
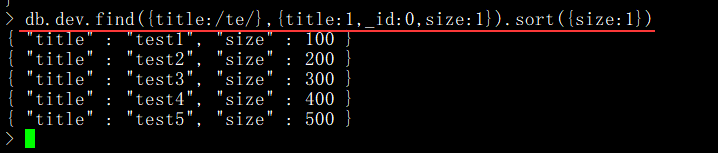
- 如何實現排序,兩個條件如何排序 如年齡一致按照分數排序?
在 MongoDB 中使用 sort() 函數對查詢到的文檔進行排序,sort() 函數可以通過參數 指定排序的字段,并使用 1 和 -1 來指定排序的方式,其中 1 為升序排列,而 -1 是用于 降序排列。
語法格式:db.COLLECTION_NAME.find().sort({排序鍵:1})
- 如何創建索引?
在 MongoDB 中會自動為文檔中的_Id(文檔的主鍵)鍵創建索引,與關系型數據的主鍵索 引類似。 我們可以使用 createIndex()函數來為其他的鍵創建索引。在創建索引時需要指定排序規 則。1 按照升序規則創建索引,-1 按照降序規則創建索引。 在創建索引時,需要使用具有 dbAdmin 或者 dbAdminAnyDatabase 角色的用戶。
語法格式:db.COLLECTION_NAME.createIndex({創建索引的鍵:排序規則,......},{創建索 引的參數(可選參數)})


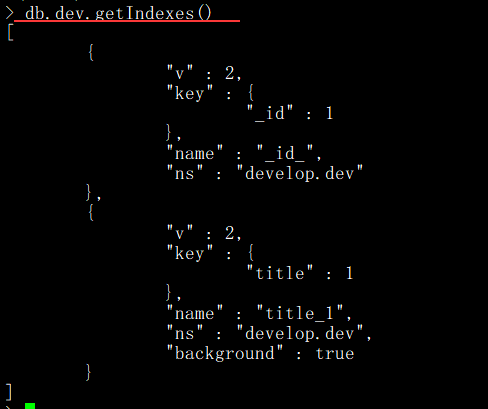
- 如何查看索引?
通過 getIndexes()或者 getIndexSpecs()函數查看集合中的所有索引信息。
語法格式:db.COLLECTION_NAME.getIndexes()
語法格式:db.COLLECTION_NAME.getIndexSpecs()
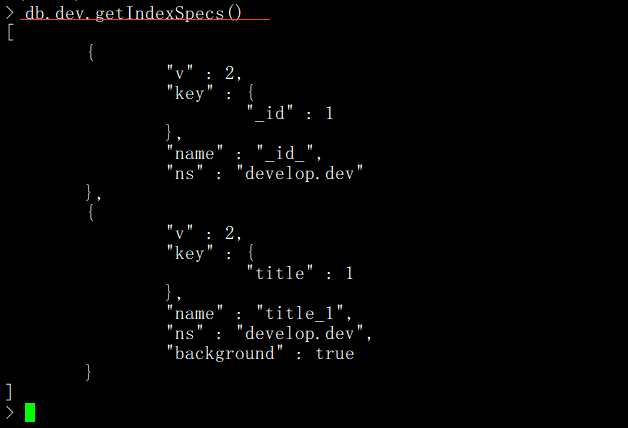
使用db.集合名.getIndexKeys()查看集合中的索引鍵

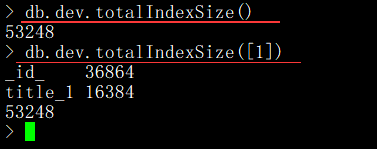
查看索引大小:
我們可以通過 totalIndexSize()函數來查看當前集合中索引的大小,單位為字節。
語法格式:db.COLLECTION_NAME.totalIndexSize([detail](可選參數)) 參數解釋:detail 可選參數,傳入除 0 或 false 外的任意數據,那么會顯示該集合中每個 索引的大小及集合中索引的總大小。如果傳入 0 或 false 則只顯示該集合中所有索引的總大 小。默認值為 false。
- 刪除索引有幾種方式,分別舉例說明?
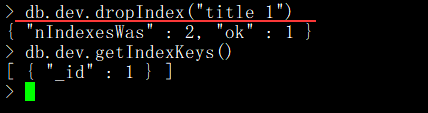
1. 刪除集合中的指定索引
通過 dropIndex()函數來刪除指定索引。
語法格式:db.COLLECTION_NAME.dropIndex("索引名稱")。
2. 刪除集合中的全部索引
使用 dropIndexes()函數刪除集合中的全部索引,_id 鍵的索引除外。
語法格式:db.COLLECTION_NAME.dropIndexes()

注意:_id索引不會被刪除掉
3.重建索引
我可以使用 reIndex()函數重建索引。重建索引可以減少索引存儲空間,減少索引碎片, 優化索引查詢效率。一般在數據大量變化后,會使用重建索引來提升索引性能。重建索引是 刪除原索引重新創建的過程,不建議反復使用。
語法格式:db.COLLECTION_NAME.reIndex()
- 索引類型有哪些,有何作用?
1.單字段索引(Single Field Index)
所謂單字段索引是指在索引中只包含了一個鍵。查詢時,可加速對該字段的各種查詢請 求,是最常見的索引形式。MongoDB 默認創建的_Id 索引也是這種類型。我們可以使用 createIndexes({索引鍵:排序規則})函數來創建單字段索引
語法格式:db.COLLECTION_NAME.createIndexes({索引鍵名:排序規則})
2 交叉索引
所謂交叉索引就是為一個集合的多個字段分別建立索引,在查詢的時候通過多個字段作 為查詢條件,這種情況稱為交叉索引。 在查詢文檔時,在查詢條件中包含一個交叉索引鍵或者在一次查詢中使用多個交叉索引 鍵作為查詢條件都會觸發交叉索引。
3 復合索引(Compound Index)
復合索引是 Single Field Index 的升級版本,它針對多個字段聯合創建索引,先按第一個 字段排序,第一個字段相同的文檔按第二個字段排序,依次類推。 語法格式:db.COLLECTION_NAME.createIndex({索引鍵名:排序規則, 索引鍵名:排序規 則,......}); 復合索引能滿足的查詢場景比單字段索引更豐富,不光能滿足多個字段組合起來的查 詢,也能滿足所以能匹配符合索引前綴的查詢。
4 多 key 索引 (Multikey Index)
當索引的字段為數組時,創建出的索引稱為多 key 索引,多 key 索引會為數組的每個元 素建立一條索引。
語法格式:db.COLLECTION_NAME.createIndex({數組鍵名:排序規則});
5. 唯一索引 (unique index)
唯一索引會保證索引對應的鍵不會出現相同的值,比如_id 索引就是唯一索引
語法格式:db.COLLECTION_NAME.createIndex({索引鍵名:排序規則},{unique:true}) 如果唯一索引所在字段有重復數據寫入時,拋出異常。
6.部分索引 (partial index):
部分索引是只針對符合某個特定條件的文檔建立索引,3.2 版本才支持該特性。 MongoDB 部分索引只為那些在一個集合中,滿足指定的篩選條件的文檔創建索引。由 于部分索引是一個集合文檔的一個子集,因此部分索引具有較低的存儲需求,并降低了索引 創建和維護的性能成本。部分索引通過指定過濾條件來創建,可以為 MongoDB 支持的所有 索引類型使用部分索引。 簡單點說:部分索引就是帶有過濾條件的索引,即索引只存在與某些文檔之上
語 法 格 式 : db.COLLECTION_NAME.createIndex({ 索引鍵名: 排 序 規 則},{partialFilterExpression:{鍵名:{匹配條件:條件值}}})
注意:部分索引只為集合中那些滿足指定的篩選條件的文檔創建索引。如果你指定的 partialFilterExpression 和唯一約束、那么唯一性約束只適用于滿足篩選條件的文檔。具有唯 一約束的部分索引不會阻止不符合唯一約束且不符合過濾條件的文檔的插入
- 使用索引需要注意什么?
1.建立合適的索引
為每一個常用查詢結構建立合適的索引。 復合索引是創建的索引由多個字段組成,例如: db.test.createIndex({"username":1, "age":-1}) 交叉索引是每個字段單獨建立索引,但是在查詢的時候組合查找,例如: db.test.createIndex({"username":1}) db.test.createIndex({"age":-1}) db.test.find({"username":"kaka", "age": 30}) 交叉索引的查詢效率較低,在使用時,當查詢使用到多個字段的時候,盡量使用復合索 引,而不是交叉索引
2 復合索引的字段排列順序
當我們的組合索引內容包含匹配條件以及范圍條件的時候,比如包含用戶名(匹配條件)
以及年齡(范圍條件),那么匹配條件應該放在范圍條件之前。
3.查詢時盡可能僅查詢出索引字段
有時候僅需要查詢少部分的字段內容,而且這部分內容剛好都建立了索引,那么盡可能 只查詢出這些索引內容,需要用到的字段顯式聲明(_id 字段需要顯式忽略!)。因為這些 數據需要把原始數據文檔從磁盤讀入內存,造成一定的損耗
4.對現有的數據大表建立索引的時候,采用后臺運行方式
在對數據集合建立索引的過程中,數據庫會停止該集合的所有讀寫操作,因此如果建立 索引的數據量大,建立過程慢的情況下,建議采用后臺運行的方式,避免影響正常業務流程。
- 索引限制指的是?
1.額外開銷
每個索引占據一定的存儲空間,在進行插入,更新和刪除操作時也需要對索引進行操作。 所以,如果你很少對集合進行讀取操作,建議不使用索引。
2 內存使用
由于索引是存儲在內存(RAM)中,你應該確保該索引的大小不超過內存的限制。 如果索引的大小大于內存的限制,MongoDB 會刪除一些索引,這將導致性能下降。
3 查詢限制
索引不能被以下的查詢使用: 正則表達式(最左匹配除外)及非操作符,如 $nin, $not, 等。 算術運算符,如 $mod, 等。 所以,檢測你的語句是否使用索引是一個好的習慣,可以用 explain 來查看。
4 最大范圍
集合中索引不能超過 64 個 索引名的長度不能超過 128 個字符 一個復合索引最多可以有 31 個字段
linux啟動jmeter,執行./jmeter.sh報錯解決方法)






)











