使用Beat收集nginx日志和指標數據
項目需求
Nginx是一款非常優秀的web服務器,往往nginx服務會作為項目的訪問入口,那么,nginx的性能保障就變得非常重要了,如果nginx的運行出現了問題就會對項目有較大的影響,所以,我們需要對nginx的運行有監控措施,實時掌握nginx的運行情況,那就需要收集nginx的運行指標和分析nginx的運行日志了。
業務流程
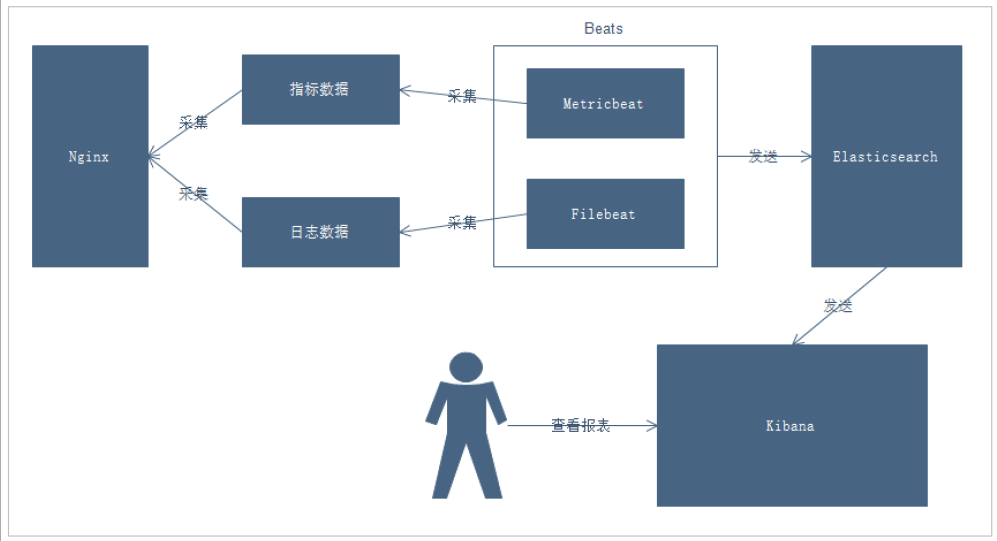
說明:
- 通過Beats采集Nginx的指標數據和日志數據
- Beats采集到數據后發送到Elasticsearch中
- Kibana讀取數據進行分析
- 用戶通過Kibana進行查看分析報表
部署Nginx
部署教程可以參考這篇博客:CentOS下如何安裝Nginx?
部署完成后,我們就可以啟動nginx了
啟動完成后,我們通過下面命令,就可以獲取到nginx中的內容了
tail -f /var/log/nginx/access.log
Beats簡介
通過查看ElasticStack可以發現,Beats主要用于采集數據
官網地址:https://www.elastic.co/cn/beats/
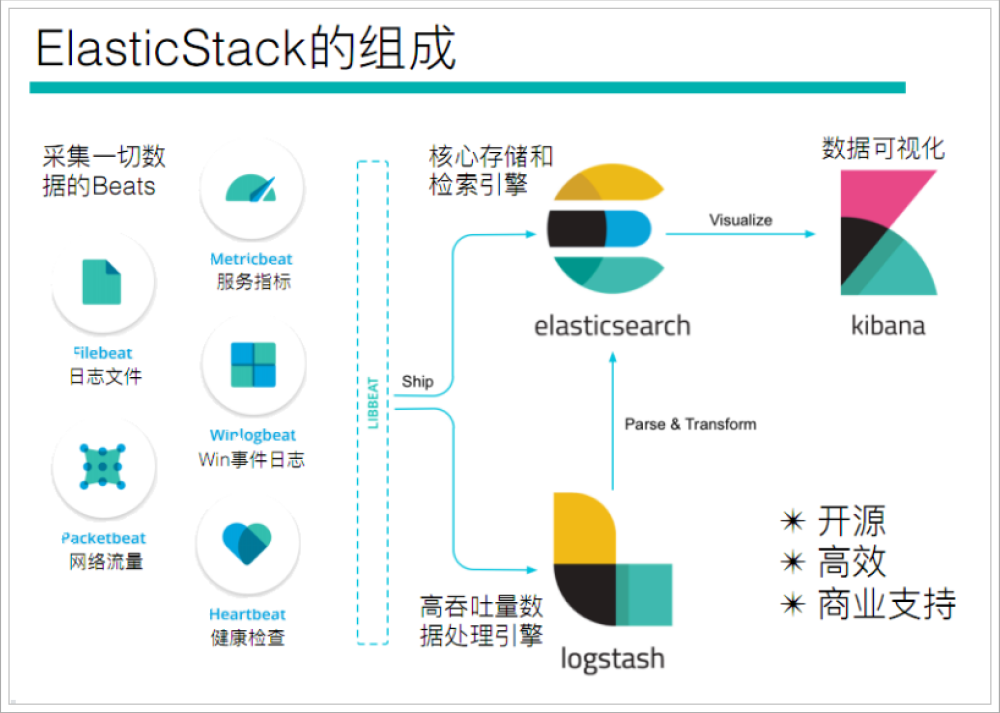
Beats平臺其實是一個輕量性數據采集器,通過集合多種單一用途的采集器,從成百上千臺機器中向Logstash或ElasticSearch中發送數據。

通過Beats包含以下的數據采集功能
- Filebeat:采集日志文件
- Metricbeat:采集指標
- Packetbeat:采集網絡數據
如果我們的數據不需要任何處理,那么就可以直接發送到ElasticSearch中
如果們的數據需要經過一些處理的話,那么就可以發送到Logstash中,然后處理完成后,在發送到ElasticSearch
最后在通過Kibana對我們的數據進行一系列的可視化展示
Filebeat
介紹
Filebeat是一個輕量級的日志采集器
為什么要用Filebeat?
當你面對成百上千、甚至成千上萬的服務器、虛擬機和溶氣氣生成的日志時,請告別SSH吧!Filebeat將為你提供一種輕量型方法,用于轉發和匯總日志與文件,讓簡單的事情不再繁華,關于Filebeat的記住以下兩點:
- 輕量級日志采集器
- 輸送至ElasticSearch或者Logstash,在Kibana中實現可視化
架構
用于監控、收集服務器日志文件.
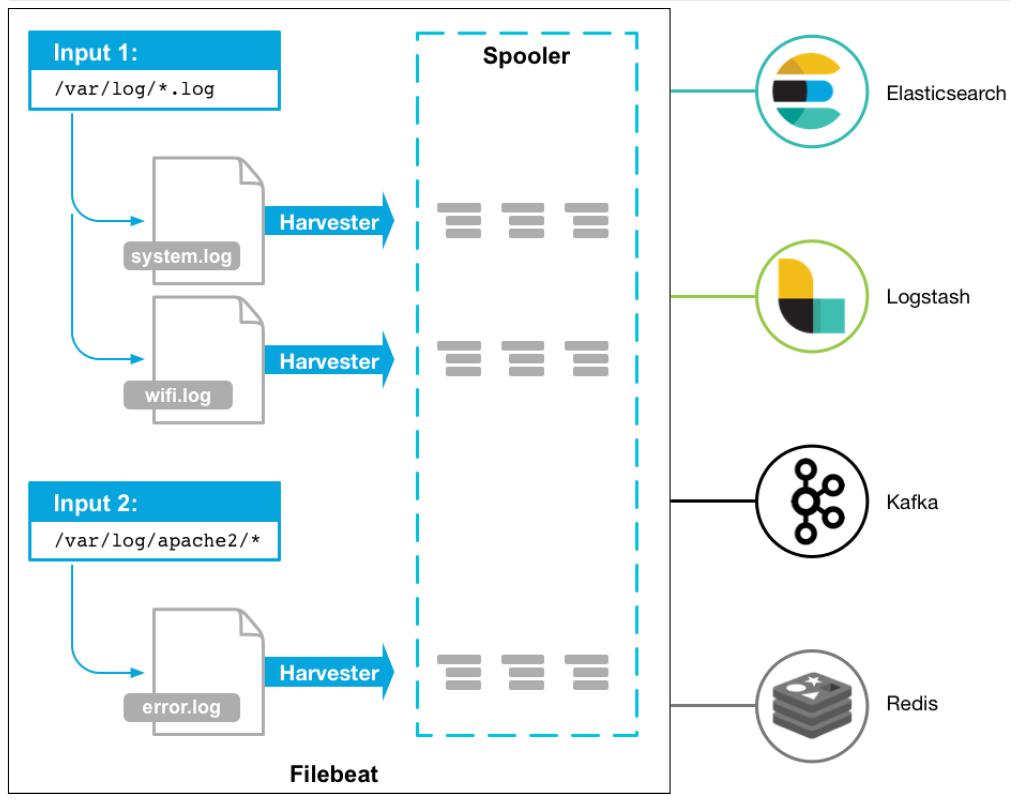
流程如下:
- 首先是input輸入,我們可以指定多個數據輸入源,然后通過通配符進行日志文件的匹配
- 匹配到日志后,就會使用Harvester(收割機),將日志源源不斷的讀取到來
- 然后收割機收割到的日志,就傳遞到Spooler(卷軸),然后卷軸就在將他們傳到對應的地方
下載
官網地址:https://www.elastic.co/cn/downloads/beats/filebeat
選中對應版本的Filebeat,我這里是Centos部署的,所以下載Linux版本
下載后,我們上傳到服務器上,然后創建一個文件夾
# 創建文件夾
mkdir -p /soft/beats
# 解壓文件
tar -zxvf filebeat-7.9.1-linux-x86_64.tar.gz
# 重命名
mv filebeat-7.9.1-linux-x86_64/ filebeat
然后我們進入到filebeat目錄下,創建對應的配置文件
# 進入文件夾
cd filebeats
# 創建配置文件
vim mogublog.yml
添加如下內容
filebeat.inputs: # filebeat input輸入
- type: stdin # 標準輸入enabled: true # 啟用標準輸入
setup.template.settings: index.number_of_shards: 3 # 指定下載數
output.console: # 控制臺輸出pretty: true # 啟用美化功能enable: true
啟動
在我們添加完配置文件后,我們就可以對filebeat進行啟動了
./filebeat -e -c mogublog.yml
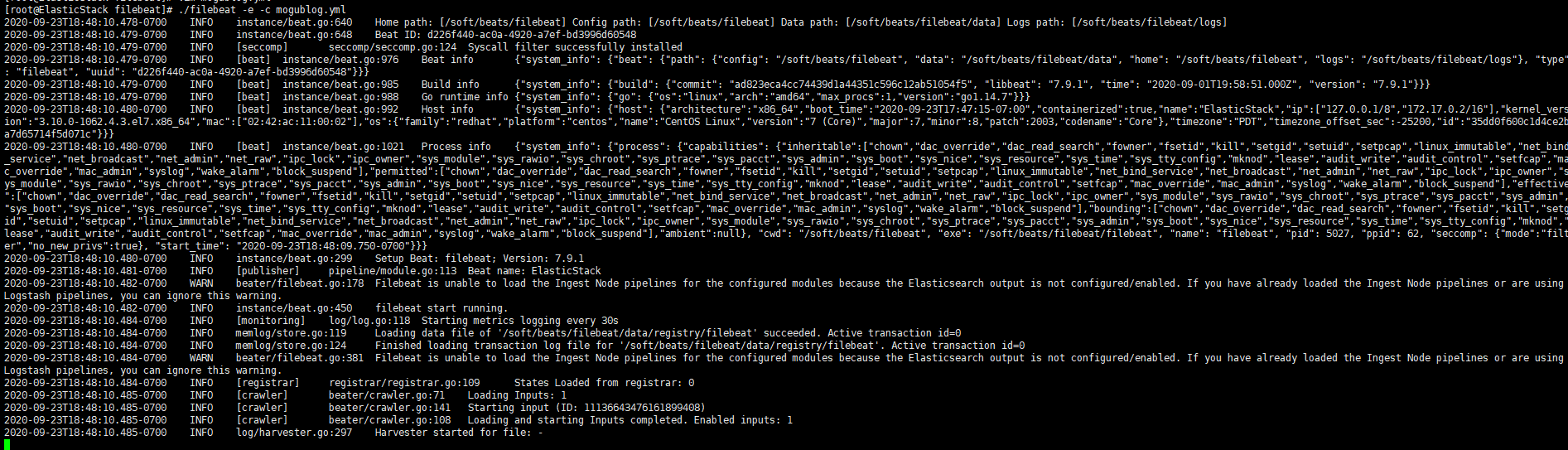
然后我們在控制臺輸入hello,就能看到我們會有一個json的輸出,是通過讀取到我們控制臺的內容后輸出的
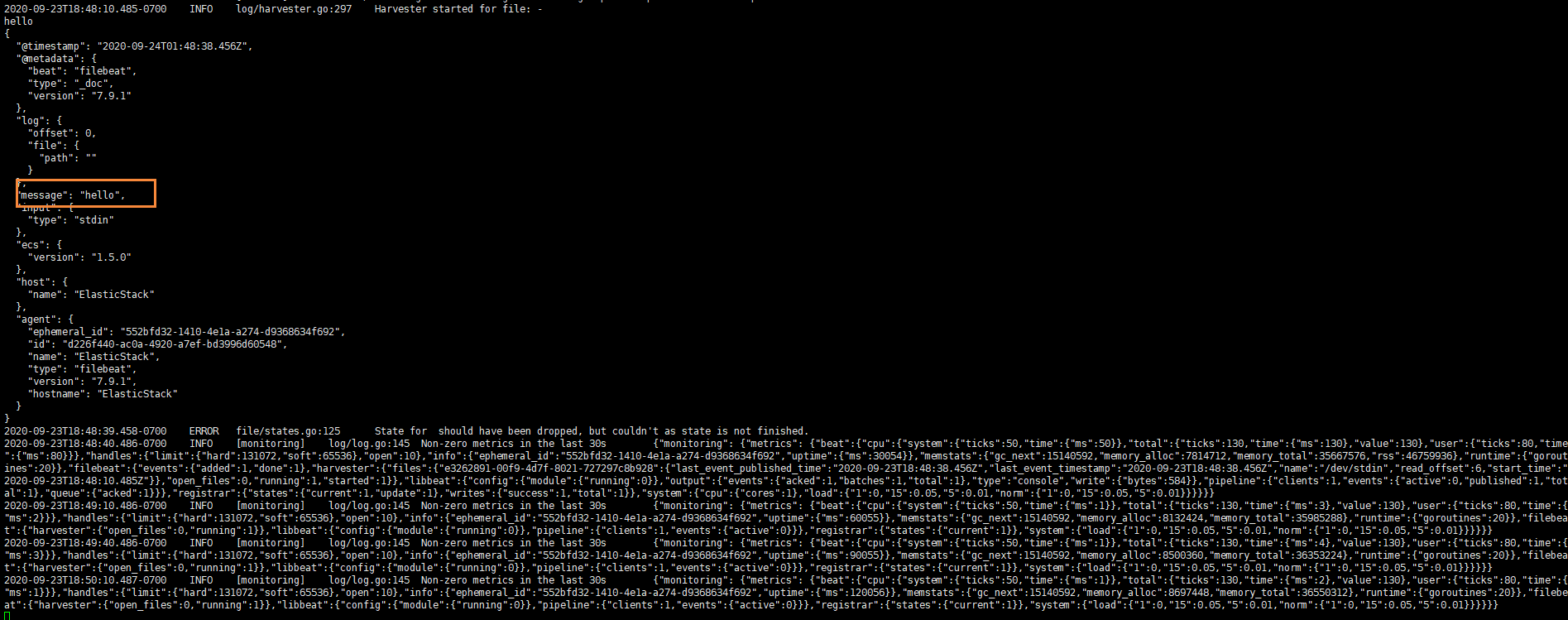
內容如下
{"@timestamp":"2019-01-12T12:50:03.585Z","@metadata":{ #元數據信息"beat":"filebeat","type":"doc","version":"6.5.4"},"source":"","offset":0,"message":"hello", #元數據信息"prospector":{"type":"stdin" #元數據信息},"input":{ #控制臺標準輸入"type":"stdin"},"beat":{ #beat版本以及主機信息"name":"itcast01","hostname":"ElasticStack","version":"6.5.4"},"host":{"name":"ElasticStack"}
}
讀取文件
我們需要再次創建一個文件,叫 mogublog-log.yml,然后在文件里添加如下內容
filebeat.inputs:
- type: logenabled: truepaths:- /soft/beats/logs/*.log
setup.template.settings:index.number_of_shards: 3
output.console:pretty: trueenable: true
添加完成后,我們在到下面目錄創建一個日志文件
# 創建文件夾
mkdir -p /soft/beats/logs# 進入文件夾
cd /soft/beats/logs# 追加內容
echo "hello" >> a.log
然后我們再次啟動filebeat
./filebeat -e -c mogublog-log.yml
能夠發現,它已經成功加載到了我們的日志文件 a.log
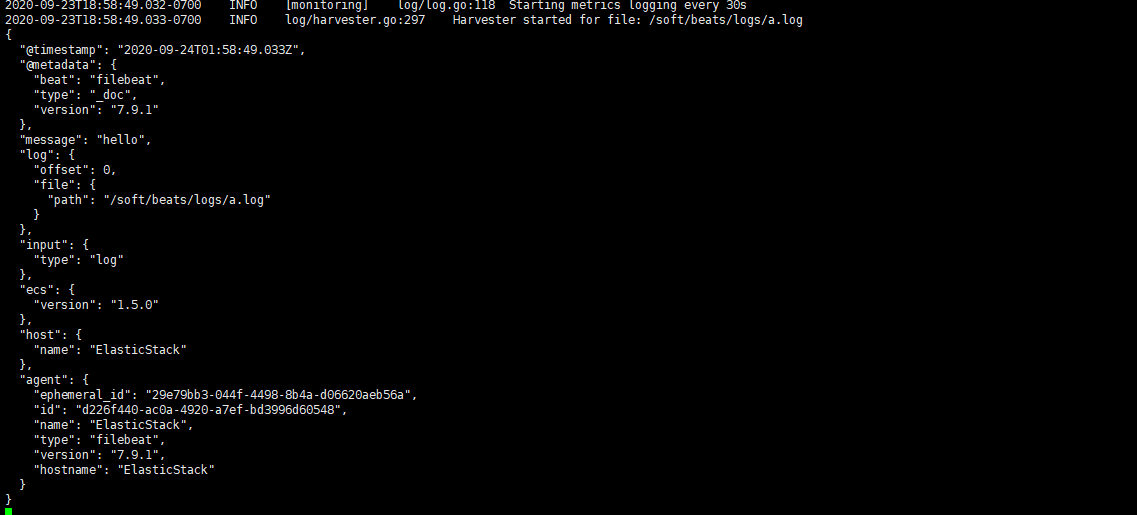
同時我們還可以繼續往文件中追加內容
echo "are you ok ?" >> a.log
追加后,我們再次查看filebeat,也能看到剛剛我們追加的內容
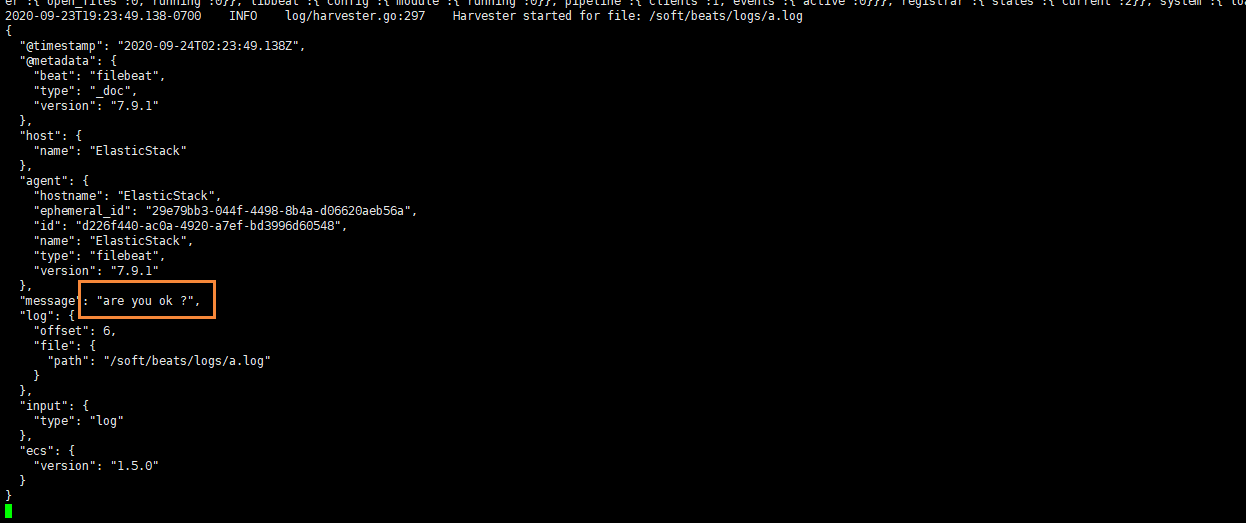
可以看出,已經檢測到日志文件有更新,立刻就會讀取到更新的內容,并且輸出到控制臺。
自定義字段
但我們的元數據沒辦法支撐我們的業務時,我們還可以自定義添加一些字段
filebeat.inputs:
- type: logenabled: truepaths:- /soft/beats/logs/*.logtags: ["web", "test"] #添加自定義tag,便于后續的處理fields: #添加自定義字段from: test-webfields_under_root: true #true為添加到根節點,false為添加到子節點中
setup.template.settings:index.number_of_shards: 3
output.console:pretty: trueenable: true
添加完成后,我們重啟 filebeat
./filebeat -e -c mogublog-log.yml
然后添加新的數據到 a.log中
echo "test-web" >> a.log
我們就可以看到字段在原來的基礎上,增加了兩個
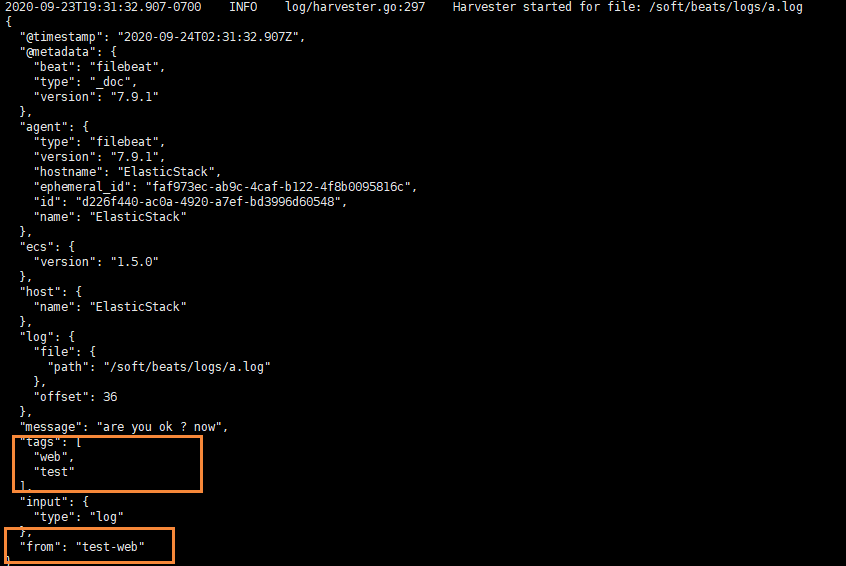
輸出到ElasticSearch
我們可以通過配置,將修改成如下所示
filebeat.inputs:
- type: logenabled: truepaths:- /soft/beats/logs/*.logtags: ["web", "test"]fields:from: test-webfields_under_root: false
setup.template.settings:index.number_of_shards: 1
output.elasticsearch:hosts: ["127.0.0.1:9200"]
啟動成功后,我們就能看到它已經成功連接到了es了
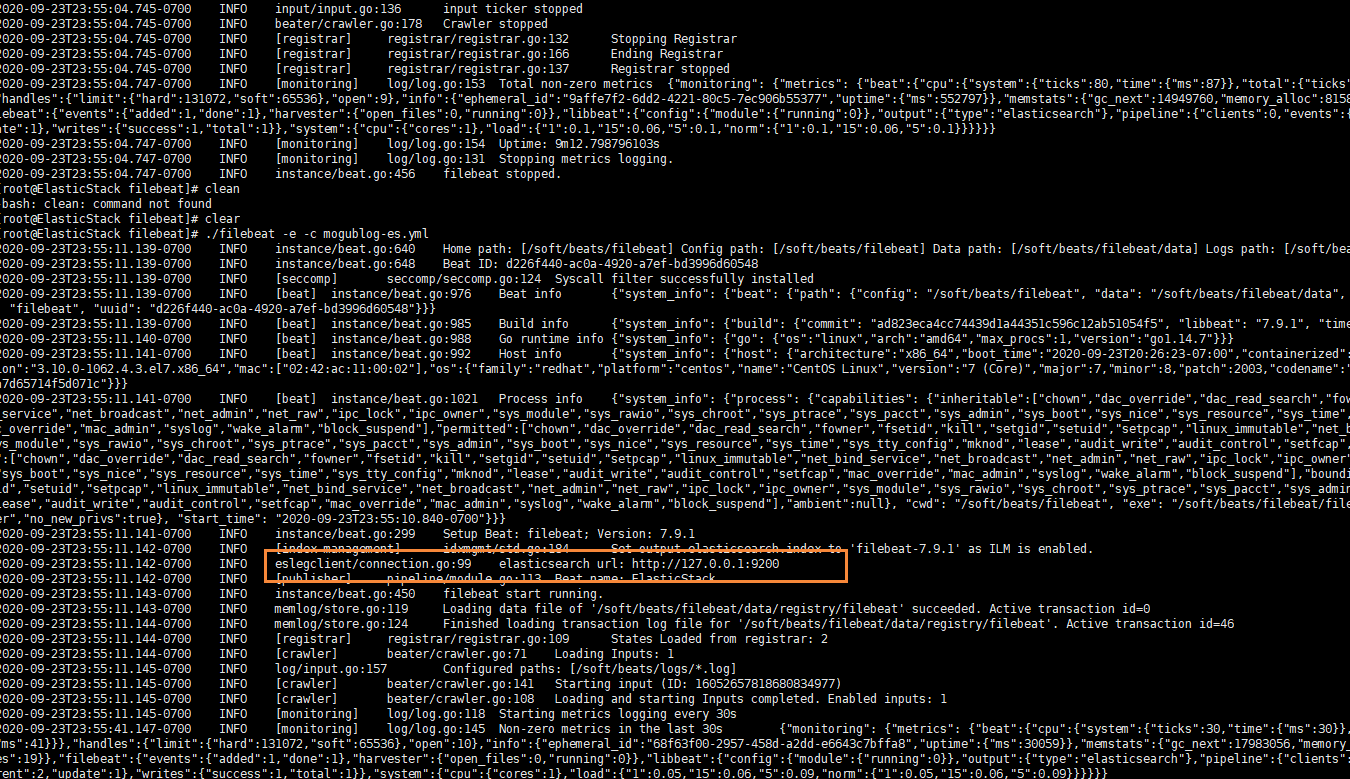
然后我們到剛剛的 logs文件夾向 a.log文件中添加內容
echo "hello mogublog" >> a.log
在ES中,我們可以看到,多出了一個 filebeat的索引庫
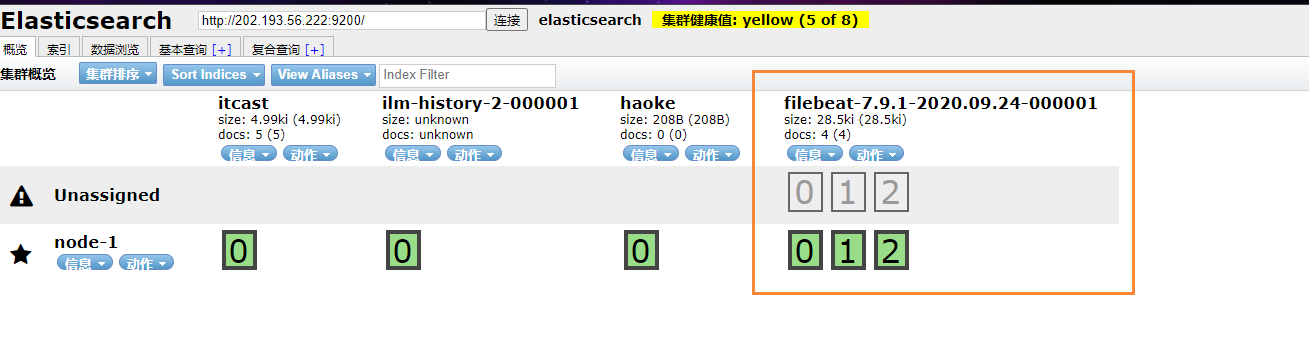
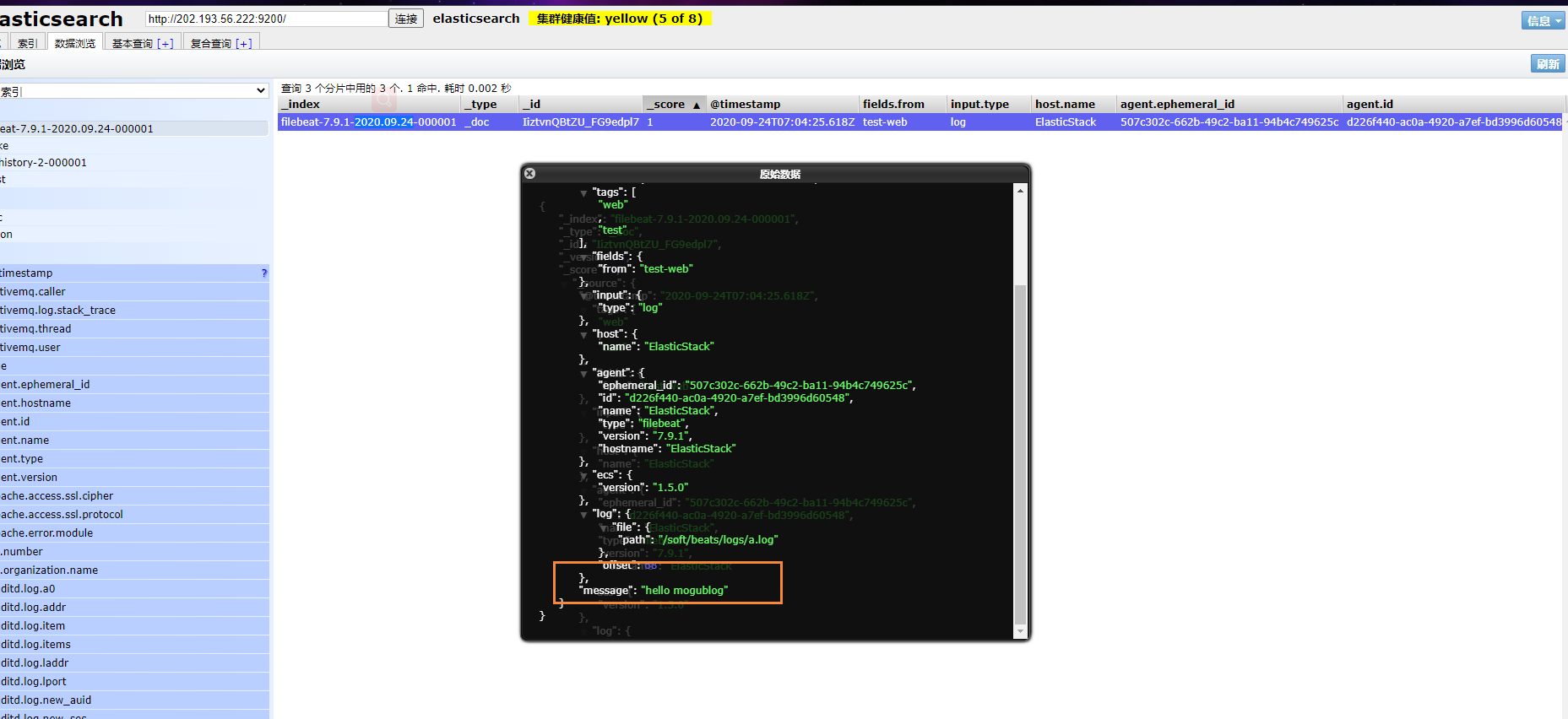
然后我們瀏覽對應的數據,看看是否有插入的數據內容
Filebeat工作原理
Filebeat主要由下面幾個組件組成: harvester、prospector 、input
harvester
- 負責讀取單個文件的內容
- harvester逐行讀取每個文件(一行一行讀取),并把這些內容發送到輸出
- 每個文件啟動一個harvester,并且harvester負責打開和關閉這些文件,這就意味著harvester運行時文件描述符保持著打開的狀態。
- 在harvester正在讀取文件內容的時候,文件被刪除或者重命名了,那么Filebeat就會續讀這個文件,這就會造成一個問題,就是只要負責這個文件的harvester沒用關閉,那么磁盤空間就不會被釋放,默認情況下,Filebeat保存問價你打開直到close_inactive到達
prospector
- prospector負責管理harvester并找到所有要讀取的文件來源
- 如果輸入類型為日志,則查找器將查找路徑匹配的所有文件,并為每個文件啟動一個harvester
- Filebeat目前支持兩種prospector類型:log和stdin
- Filebeat如何保持文件的狀態
- Filebeat保存每個文件的狀態并經常將狀態刷新到磁盤上的注冊文件中
- 該狀態用于記住harvester正在讀取的最后偏移量,并確保發送所有日志行。
- 如果輸出(例如ElasticSearch或Logstash)無法訪問,Filebeat會跟蹤最后發送的行,并在輸出再次可以用時繼續讀取文件。
- 在Filebeat運行時,每個prospector內存中也會保存的文件狀態信息,當重新啟動Filebat時,將使用注冊文件的數量來重建文件狀態,Filebeat將每個harvester在從保存的最后偏移量繼續讀取
- 文件狀態記錄在data/registry文件中
input
- 一個input負責管理harvester,并找到所有要讀取的源
- 如果input類型是log,則input查找驅動器上與已定義的glob路徑匹配的所有文件,并為每個文件啟動一個harvester
- 每個input都在自己的Go例程中運行
- 下面的例子配置Filebeat從所有匹配指定的glob模式的文件中讀取行
filebeat.inputs:
- type: logpaths:- /var/log/*.log- /var/path2/*.log
啟動命令
./filebeat -e -c mogublog-es.yml
./filebeat -e -c mogublog-es.yml -d "publish"
參數說明
- **-e:**輸出到標準輸出,默認輸出到syslog和logs下
- **-c:**指定配置文件
- **-d:**輸出debug信息
讀取Nginx中的配置文件
我們需要創建一個 mogublog-nginx.yml配置文件
filebeat.inputs:
- type: logenabled: truepaths:- /soft/nginx/*.logtags: ["nginx"]fields_under_root: false
setup.template.settings:index.number_of_shards: 1
output.elasticsearch:hosts: ["127.0.0.1:9200"]
啟動后,可以在Elasticsearch中看到索引以及查看數據
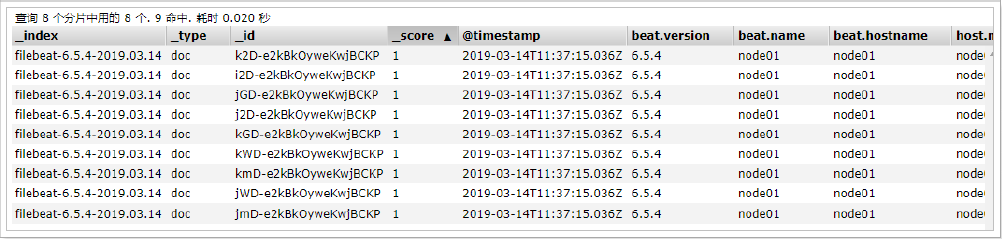
可以看到,在message中已經獲取到了nginx的日志,但是,內容并沒有經過處理,只是讀取到原數據,那么對于我們后期的操作是不利的,有辦法解決嗎?
Module
前面要想實現日志數據的讀取以及處理都是自己手動配置的,其實,在Filebeat中,有大量的Module,可以簡化我們的配置,直接就可以使用,如下:
./filebeat modules list
得到的列表如下所示
Disabled:
activemq
apache
auditd
aws
azure
barracuda
bluecoat
cef
checkpoint
cisco
coredns
crowdstrike
cylance
elasticsearch
envoyproxy
f5
fortinet
googlecloud
gsuite
haproxy
ibmmq
icinga
iis
imperva
infoblox
iptables
juniper
kafka
kibana
logstash
microsoft
misp
mongodb
mssql
mysql
nats
netflow
netscout
nginx
o365
okta
osquery
panw
postgresql
rabbitmq
radware
redis
santa
sonicwall
sophos
squid
suricata
system
tomcat
traefik
zeek
zscaler
可以看到,內置了很多的module,但是都沒有啟用,如果需要啟用需要進行enable操作:
#啟動
./filebeat modules enable nginx
#禁用
./filebeat modules disable nginx
可以發現,nginx的module已經被啟用。
nginx module 配置
我們到下面的目錄,就能看到module的配置了
# 進入到module目錄
cd modules.d/
#查看文件
vim nginx.yml.disabled
得到的文件內容如下所示
# Module: nginx
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.9/filebeat-module-nginx.html- module: nginx# Access logsaccess:enabled: true# 添加日志文件var.paths: ["/var/log/nginx/access.log*"]# Set custom paths for the log files. If left empty,# Filebeat will choose the paths depending on your OS.#var.paths:# Error logserror:enabled: truevar.paths: ["/var/log/nginx/error.log*"]
配置filebeat
我們需要修改剛剛的mogublog-nginx.yml文件,然后添加到我們的module
filebeat.inputs:
setup.template.settings:index.number_of_shards: 1
output.elasticsearch:hosts: ["127.0.0.1:9200"]
filebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: false
測試
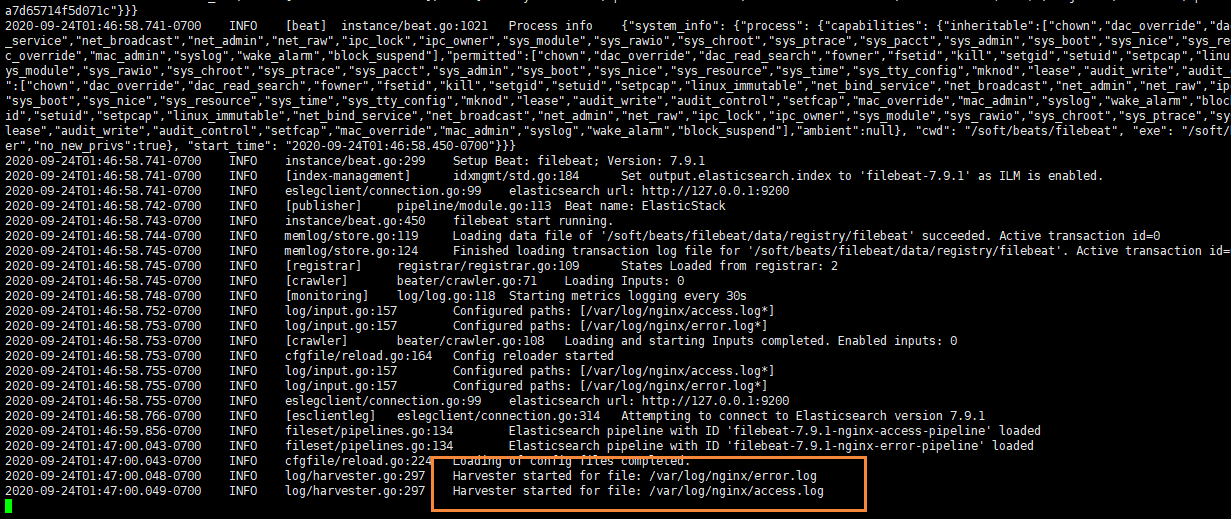
我們啟動我們的filebeat
./filebeat -e -c itcast-nginx.yml
如果啟動的時候發現出錯了,錯誤如下所示,執行如圖所示的腳本即可 【新版本的ES好像不會出現這個錯誤】
#啟動會出錯,如下
ERROR fileset/factory.go:142 Error loading pipeline: Error loading pipeline for
fileset nginx/access: This module requires the following Elasticsearch plugins:
ingest-user-agent, ingest-geoip. You can install them by running the following
commands on all the Elasticsearch nodes:sudo bin/elasticsearch-plugin install ingest-user-agentsudo bin/elasticsearch-plugin install ingest-geoip
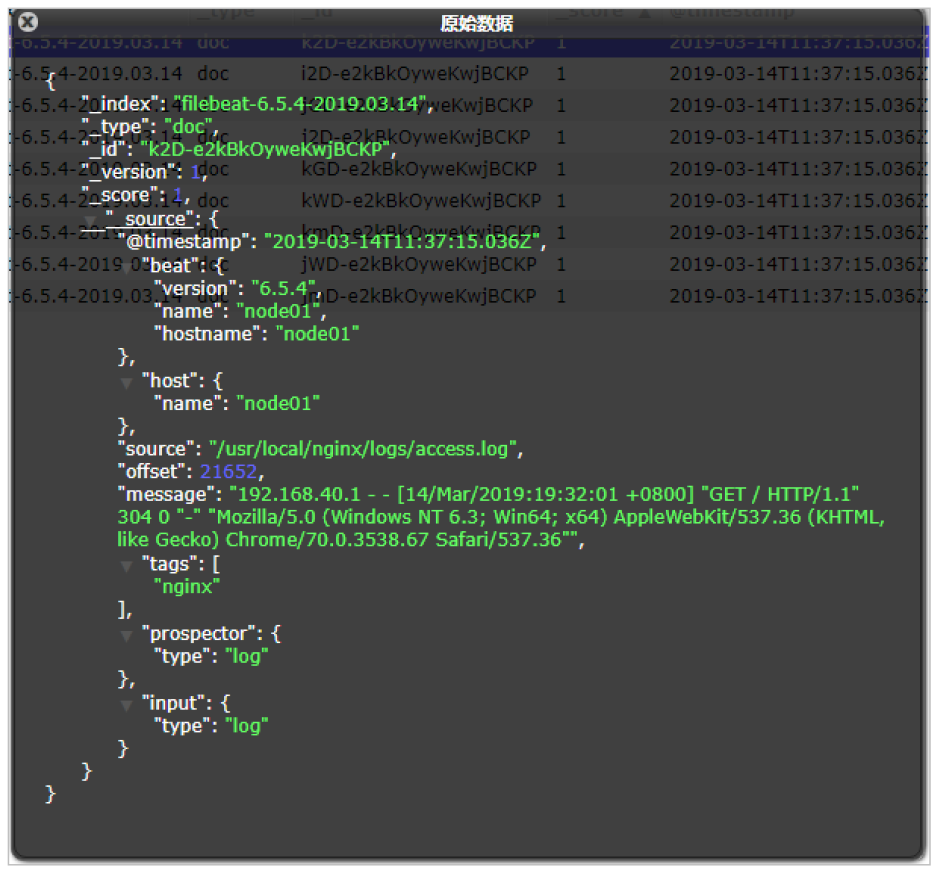
啟動成功后,能看到日志記錄已經成功刷新進去了
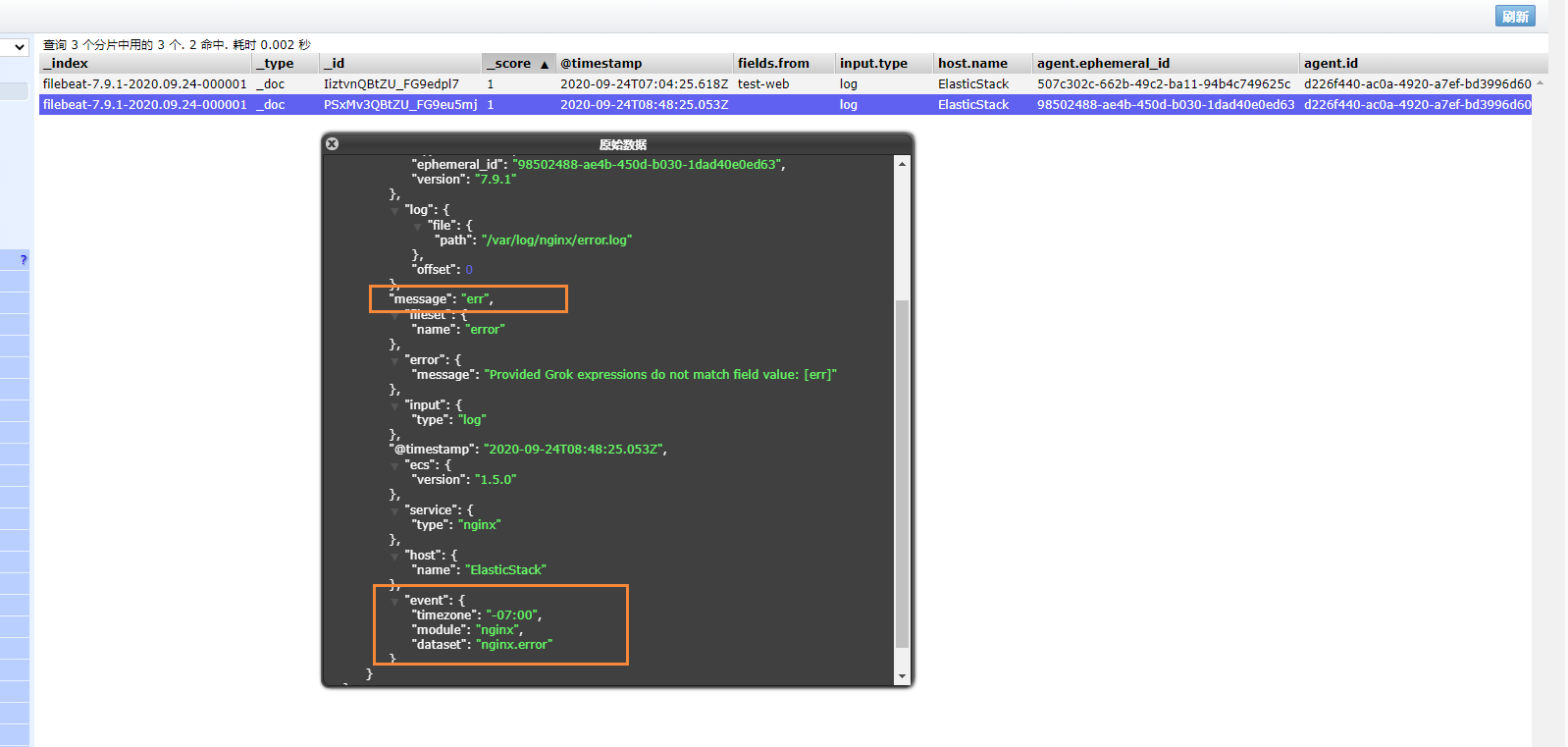
我們可以測試一下,刷新nginx頁面,或者向錯誤日志中,插入數據
echo "err" >> error.log
能夠看到,剛剛的記錄已經成功插入了
關于module的其它使用,可以參考文檔:
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-modules.html
Metricbeat
- 定期收集操作系統或應用服務的指標數據
- 存儲到Elasticsearch中,進行實時分析
Metricbeat組成
Metricbeat有2部分組成,一部分是Module,另一個部分為Metricset
- Module
- 收集的對象:如 MySQL、Redis、Nginx、操作系統等
- Metricset
- 收集指標的集合:如 cpu、memory,network等
以Redis Module為例:

下載
首先我們到官網,找到Metricbeat進行下載
下載完成后,我們通過xftp工具,移動到指定的目錄下
# 移動到該目錄下
cd /soft/beats
# 解壓文件
tar -zxvf
# 修改文件名
mv metricbeat
然后修改配置文件
vim metricbeat.yml
添加如下內容
metricbeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: false
setup.template.settings:index.number_of_shards: 1index.codec: best_compression
setup.kibana:
output.elasticsearch:hosts: [""127.0.0.1:9200"]
processors:- add_host_metadata: ~- add_cloud_metadata: ~
默認會指定的配置文件,就是在
${path.config}/modules.d/*.yml
也就是 system.yml文件,我們也可以自行開啟其它的收集
啟動
在配置完成后,我們通過如下命令啟動即可
./metricbeat -e
在ELasticsearch中可以看到,系統的一些指標數據已經寫入進去了:
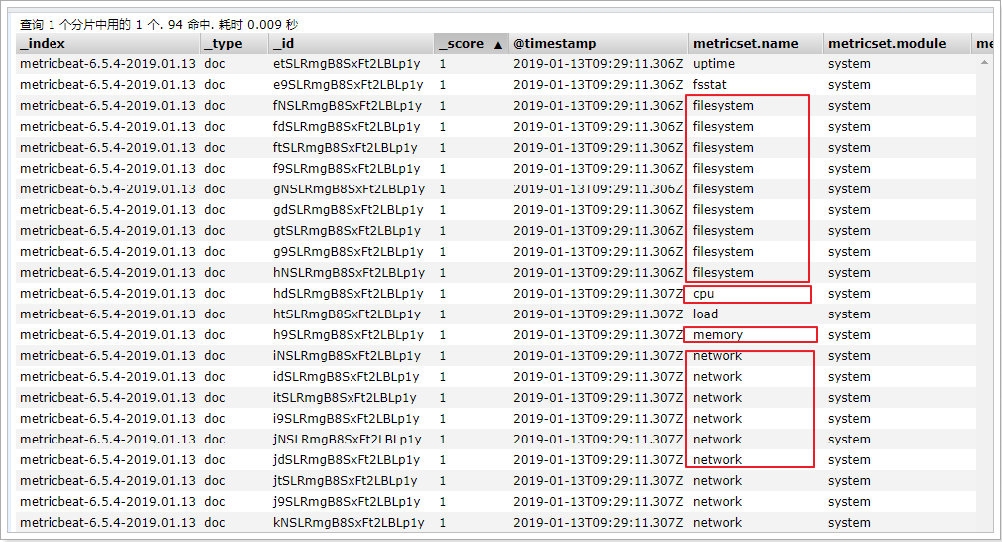
system module配置
- module: systemperiod: 10s # 采集的頻率,每10秒采集一次metricsets: # 采集的內容- cpu- load- memory- network- process- process_summary
Metricbeat Module
Metricbeat Module的用法和我們之前學的filebeat的用法差不多
#查看列表
./metricbeat modules list
能夠看到對應的列表
Enabled:
system #默認啟用Disabled:
aerospike
apache
ceph
couchbase
docker
dropwizard
elasticsearch
envoyproxy
etcd
golang
graphite
haproxy
http
jolokia
kafka
kibana
kubernetes
kvm
logstash
memcached
mongodb
munin
mysql
nginx
php_fpm
postgresql
prometheus
rabbitmq
redis
traefik
uwsgi
vsphere
windows
Nginx Module
開啟Nginx Module
在nginx中,需要開啟狀態查詢,才能查詢到指標數據。
#重新編譯nginx
./configure --prefix=/usr/local/nginx --with-http_stub_status_module
make
make install./nginx -V #查詢版本信息
nginx version: nginx/1.11.6
built by gcc 4.4.7 20120313 (Red Hat 4.4.7-23) (GCC)
configure arguments: --prefix=/usr/local/nginx --with-http_stub_status_module#配置nginx
vim nginx.conf
location /nginx-status {stub_status on;access_log off;
}# 重啟nginx
./nginx -s reload
測試
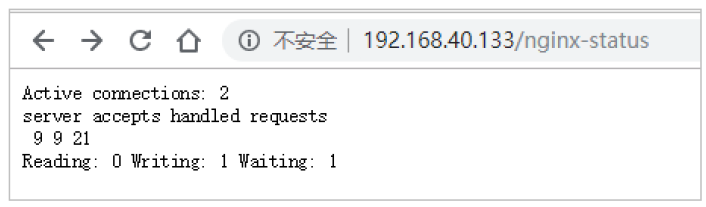
結果說明:
- Active connections:正在處理的活動連接數
- server accepts handled requests
- 第一個 server 表示Nginx啟動到現在共處理了9個連接
- 第二個 accepts 表示Nginx啟動到現在共成功創建 9 次握手
- 第三個 handled requests 表示總共處理了 21 次請求
- 請求丟失數 = 握手數 - 連接數 ,可以看出目前為止沒有丟失請求
- Reading: 0 Writing: 1 Waiting: 1
- Reading:Nginx 讀取到客戶端的 Header 信息數
- Writing:Nginx 返回給客戶端 Header 信息數
- Waiting:Nginx 已經處理完正在等候下一次請求指令的駐留鏈接(開啟keep-alive的情況下,這個值等于 Active - (Reading+Writing))
配置nginx module
#啟用redis module
./metricbeat modules enable nginx#修改redis module配置
vim modules.d/nginx.yml
然后修改下面的信息
# Module: nginx
# Docs: https://www.elastic.co/guide/en/beats/metricbeat/6.5/metricbeat-modulenginx.
html- module: nginx
#metricsets:
# - stubstatusperiod: 10s
# Nginx hostshosts: ["http://127.0.0.1"]
# Path to server status. Default server-statusserver_status_path: "nginx-status"
#username: "user"
#password: "secret"
修改完成后,啟動nginx
#啟動
./metricbeat -e
測試
我們能看到,我們的nginx數據已經成功的采集到我們的系統中了
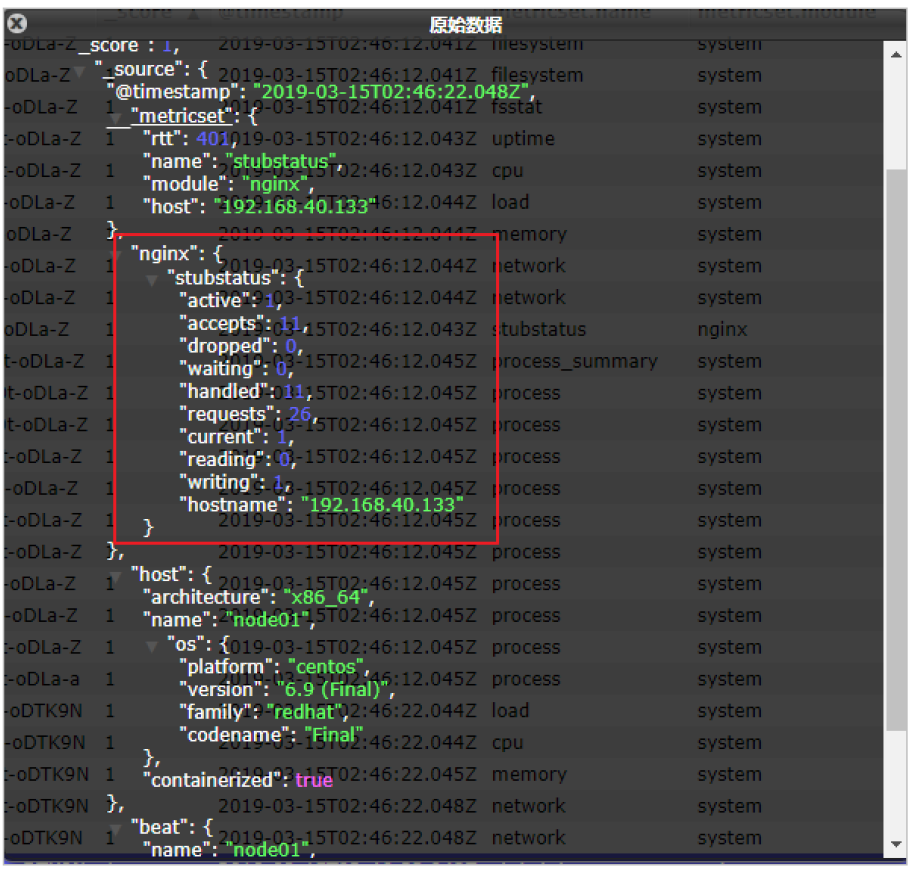
可以看到,nginx的指標數據已經寫入到了Elasticsearch。
更多的Module使用參見官方文檔:
https://www.elastic.co/guide/en/beats/metricbeat/current/metricbeat-modules.html
參考
Filebeat 模塊與配置
Elastic Stack(ELK)從入門到實踐
















)

)
