文章目錄
- 說明
- 一 GraphRAG查詢(Query)流程
- 二 Local Search 實現原理
- 三 Global Search 實現原理
- 四 GraphRAG Python API使用
說明
- 本文學自賦范社區公開課,僅供學習和交流使用!
- 本文重在介紹GraphRAG查詢流程,有關索引構建的詳細內容參看GraphRAG快速入門和原理理解
一 GraphRAG查詢(Query)流程
- 完成
Microsoft GraphRAG的索引構建后,Microsoft GraphRAG提供一種更為直觀、易用的查詢方式,只需要輸入自然語言查詢,即可獲得結構化的查詢結果。 - 索引階段利用大語言模型結合提示工程,從非結構化文本(
.txt、.csv、Json)中提取出實體(Entities)與關系(Relationships),構建出了基礎的Knowledge Graph,并且通過建立層次化的community結構,community以及community_report的豐富語義。 - 相較于傳統基于
Cypher的查詢方式可以提供更多靈活性的Query操作,Microsoft GraphRAG提供local和global兩種查詢方式,分別對應local search和global search,而后在不斷的迭代更新過程中,除了優化了local search和global search的效果,還新增了DRIFT Search和Multi Index Search作為擴展優化的可選項,以進一步豐富Query操作的多樣性。
| 模式 | 核心思路 | 場景舉例 |
|---|---|---|
| local | 只查詢與“當前節點”鄰居相關的子圖 | “圍繞某個主題節點的局部信息” |
| global | 全局搜索,忽略當前節點,直接在所有節點里找 | “在整個圖中檢索最相關的節點” |
| hybrid | 先局部查詢,再全局補充 | “先看局部,再回溯全局補充背景” |
| contextual | 根據當前上下文,動態選擇檢索區域 | “根據問題類型或語境決定局部/全局混合策略” |
- Microsoft GraphRAG
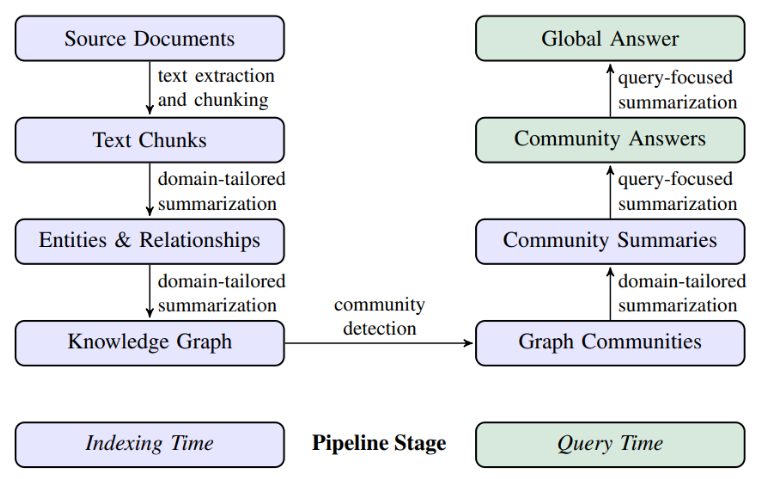
Microsoft GraphRAG在查詢階段構建的流程,相較于構建索引階段會更為直觀。核心的具體步驟包括:- 接收用戶的查詢請求。
- 根據查詢所需的詳細程度,選擇合適的社區級別進行分析。
- 在選定的社區級別進行信息檢索。
- 依據社區摘要生成初步的響應。
- 將多個相關社區的初步響應進行整合,形成一個全面的最終答案。
-
Indexing過程中并不是在創建完第一層社區后就停止,而是分層的。當創建第一層社區(即基礎社區)后,會將這些社區視為節點,進一步構建更高層級的社區。這種方法可以實現在知識圖譜中以不同的粒度級別上組織和表示數據。比如第一層社區可以包含具體的實體或數據,而更高層級的社區則可以聚合這些基礎社區,形成更廣泛的概覽。 -
最核心的
Local Search和Global Search的實現,是源于不同的粒度級別而構建出來用于處理不同類型問題的Pipeline, 其中:Local Search是基于實體的檢索。Global Search則是基于社區的檢索。
二 Local Search 實現原理
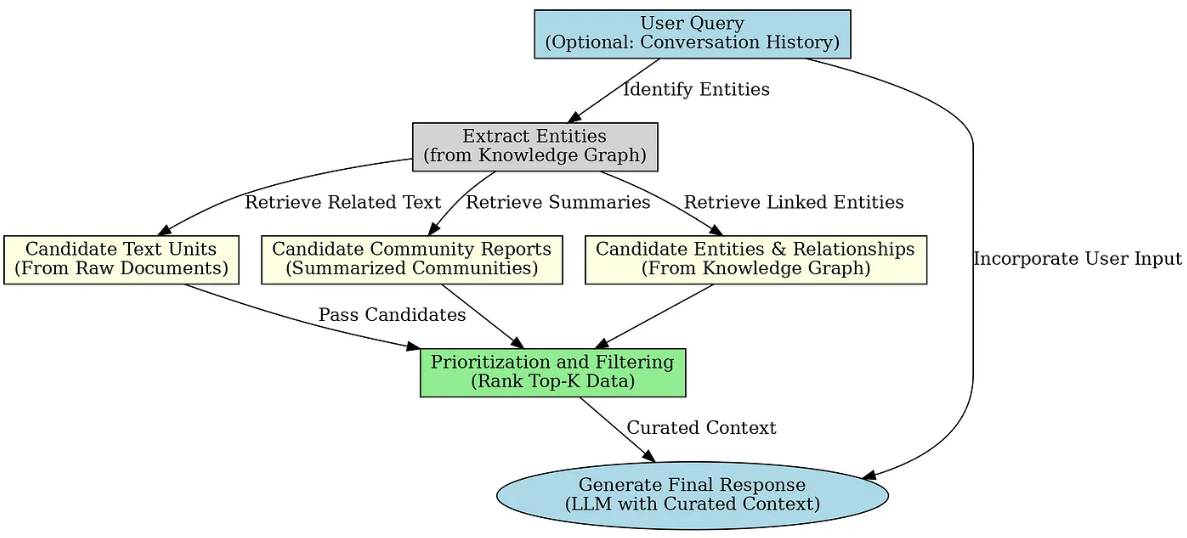
Local Search即本地檢索,是基于實體的檢索。本地搜索從相關實體開始,使用知識圖譜來查找最相關的信息。例如,給定查詢中的實體,使用的是連接節點的信息,通過辨識與查詢相關的實體與關系,檢索特定文本片段、摘要和關聯性資料。所以Local Search本質上是基于實體的推理。特別適合回答“who”、“what”、“when” 類型的問題。Microsoft GraphRAG源碼中實現的內部原理如下:
graphrag query 命令參數說明
| 參數名稱 | 類型 | 描述 | 默認值 | 是否必需 |
|---|---|---|---|---|
--method | Tpye | 可以選擇local、global、drift或basic算法。 | None | 是 |
--query | TEXT | 要執行的查詢,即提出的問題。 | None | 是 |
--config | PATH | 要使用的配置文件路徑。 | None | 否 |
--data | PATH | 索引管道輸出目錄(即包含 parquet 文件的目錄)。 | None | 否 |
--root | PATH | 項目根目錄的路徑。 | . | 否 |
--community-level | INTEGER | 從中加載社區報告的 Leiden 社區層級。較高的值表示來自較小社區的報告。 | 2 | 否 |
--dynamic-community-selection | 使用動態社區選擇的全局搜索。 | no-dynamic-community-selection | 否 | |
--response-type | TEXT | 描述響應類型和格式的自由文本,可以是任何內容,例如多個段落、單個段落、單句、3-7點列表、單頁、多頁報告。 | Multiple Paragraphs | 否 |
--streaming | 以流式方式打印響應。 | no-streaming | 否 | |
--help | 顯示幫助信息并退出。 | 否 |
- 其中,在執行查詢時必須指定的參數是
--method和--query,其他參數為可選參數。其中:--method參數可以選擇local、global、drift或basic算法。(接下來我們會依次介紹這幾種算法)--query參數是要執行的查詢,即提出的問題。
- 通過命令行快速啟動問答檢索。
local本地搜索命令:
graphrag query --root ./ --method local --query "蘋果公司都有哪些產品?"
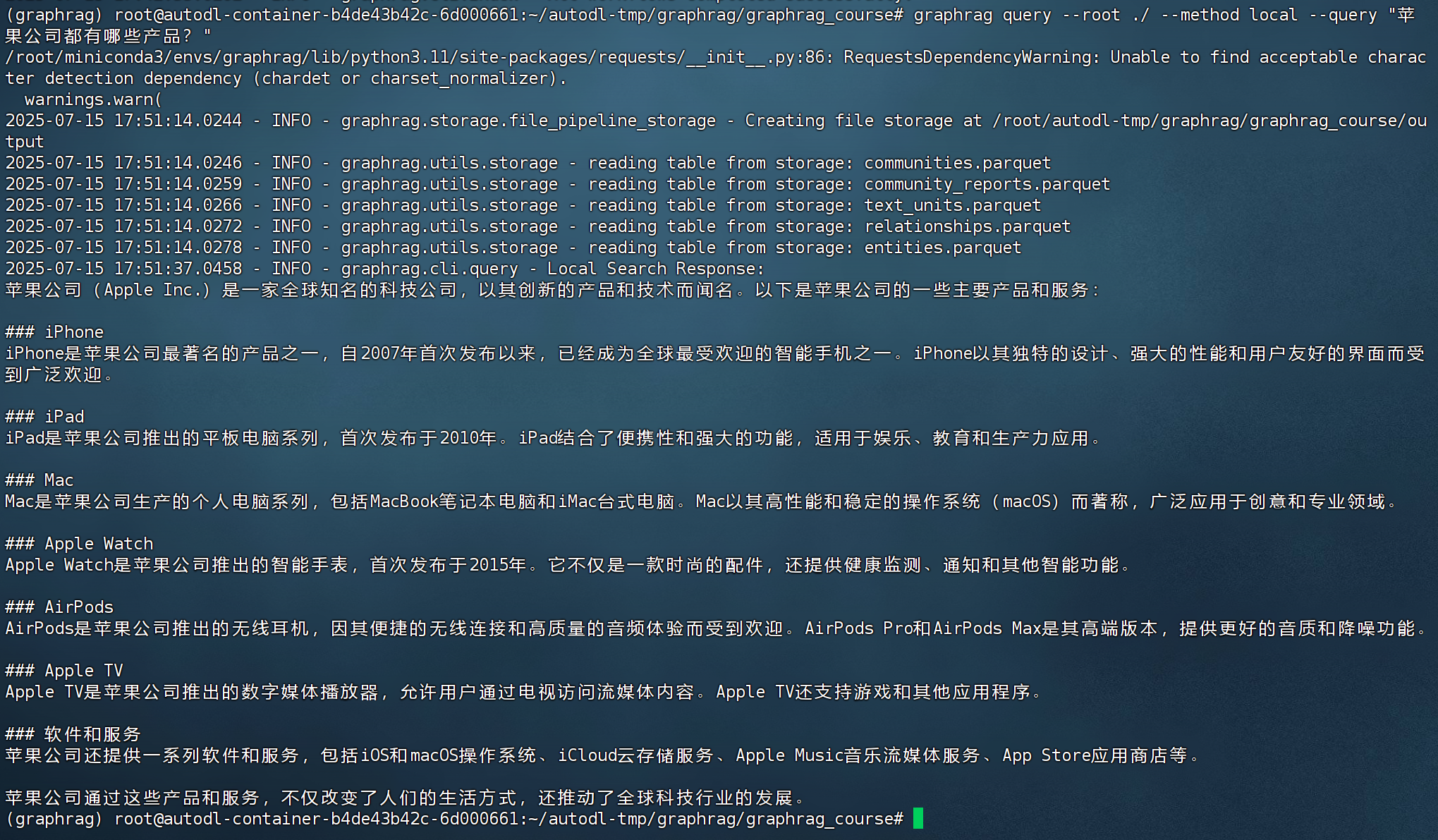
- 整個本地查詢過程使用起來非常簡單,但是大多數情況下基于通用流程的問答檢索,并不能滿足實際業務需求。比如檢索的效果不準確,效率不高,檢索結果不全面等,因此,需要進一步掌握
Microsoft GraphRAG的檢索原理,并根據實際業務需求,進行針對性的優化和調整。
Local Search的完整實現過程:
- 依次讀取
text_units.parent、entities.parent、relationships.parentcommunities.parent和community_reports.parent的索引文件,并將其加載到內存中。 - 加載
Lancedb中的詞向量,準備用于后續的相似度計算。 - 根據社區的
community_level參數的值,對實體進行第一輪的過濾,過濾的規則是:如果實體的community_level小于等于community_level參數的值,則保留該實體,否則丟棄。 - 基于輸入的問題,進行實體的匹配,并構建完整的上下文。
- 處理輸入問題,如果存在對話歷史記錄,則將之前的用戶問題附加到當前查詢。
- 將輸入的問題轉化為詞向量,然后和lancedb中的實體詞向量進行相似度計算,得到與查詢最相關的實體,這個過程中會采用兩個策略:
- 過采樣 (Oversampling) 策略,即最終檢索的實體數量是 k * oversample_scaler。
- 如果提供了exclude_entity_names列表,則過濾掉這些實體。
- 根據匹配到的實體,讀取該實體所屬的社區報告,這個過程會采用的策略是:
- 統計每個社區被多少個選中實體引用(一個實體可能屬于多個社區),做基于實體歸屬的社區投票排序
- 按匹配度和社區自身排名雙重排序
- 主要排序標準:被實體引用的頻次(匹配度)
- 次要排序標準:社區自身的重要性排名
- 在 2,3 的基礎上,提取出文本單元、關系的附件屬性
- 生成完整的數據表格
- 構建本地搜索的系統提示詞,將數據表格填充到系統提示詞中,引導大模型生成最終的回答。其提示詞設置在
settings.yaml文件的local_search中。
- 再理解
Microsoft GraphRAG給出的Local Search原理圖。
三 Global Search 實現原理
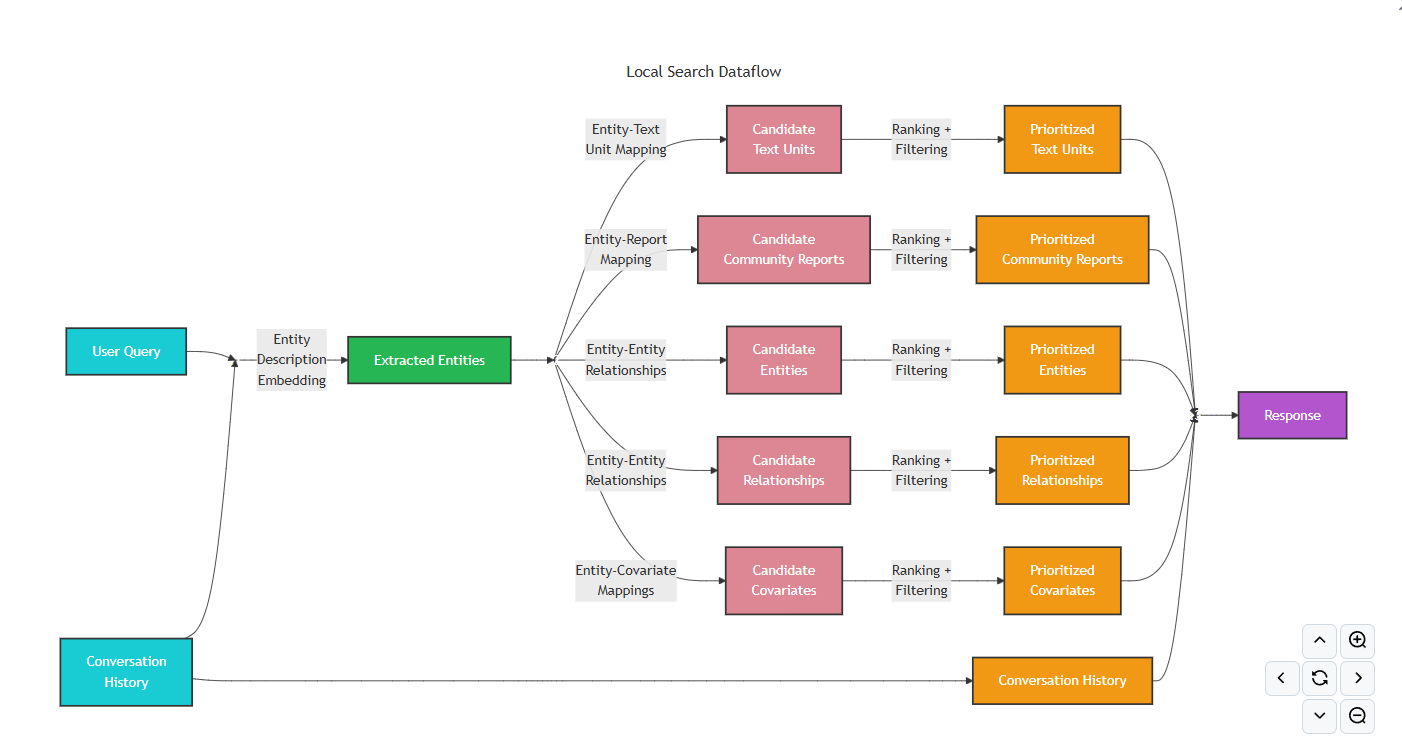
-
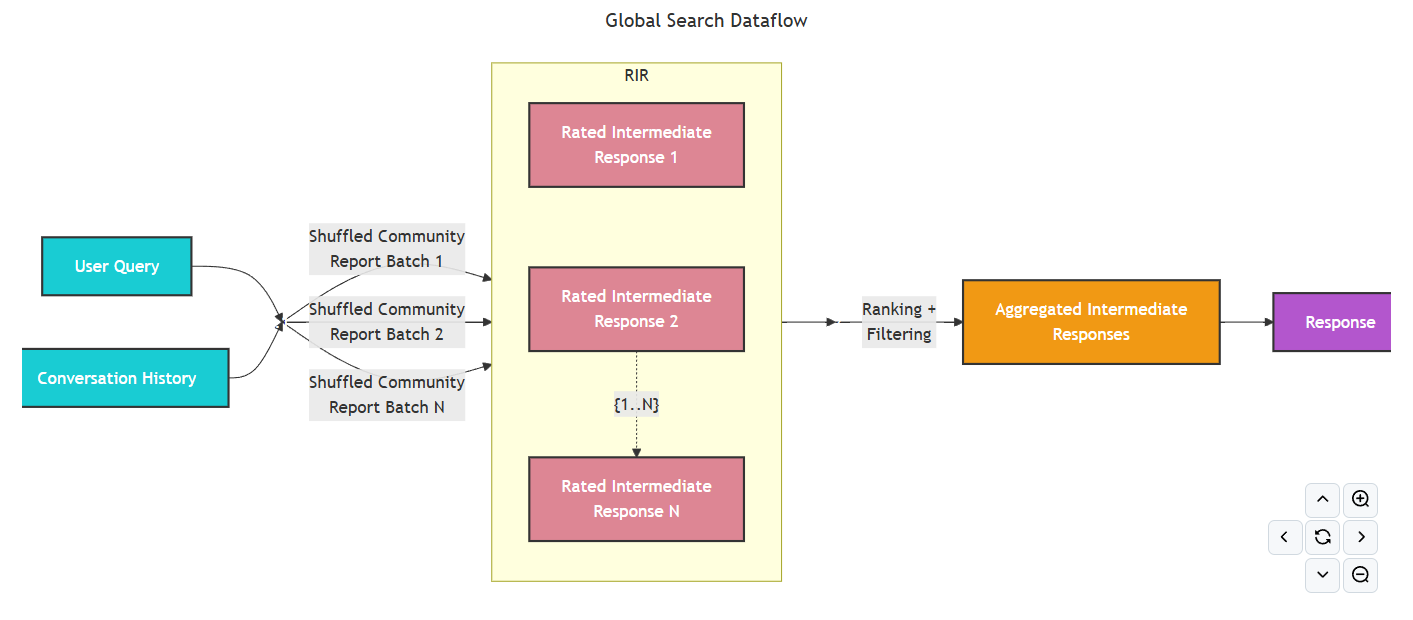
Microsoft GraphRAG中的全局搜索算法旨在回答需要了解整個數據集的抽象問題,即借助社區摘要來獲取全局的答案。實現思路是通過map-reduce流程總結知識圖譜中的社群摘要,匯總社區摘要中的見解,嘗試生成文檔中元素的概述,聚合相關資料并生成針對整體數據集的高層次回答。因此全局搜索更側重于為需要更高層次理解的問題提供答案。比如數據中的前5個主題是什么?這類問題。 -
在
Microsoft GraphRAG中,Map階段會使用大模型對多個文檔或信息片段并行處理,從每個片段中提取相關信息,然后Reduce階段會匯總所有映射操作的結果,生成最終輸出。 -
Global Search在Microsoft GraphRAG源碼中的實現原理圖如下:

-
當使用
Global Search時,需要指定--method global參數:graphrag query --root ./ --method global --query "文本庫的內容可以分為哪幾個主題?" -
Global Search的實現過程:- 依次讀取
entities.parent、communities.parent和community_reports.parent的索引文件,并將其加載到內存中。 - 依次創建
entities.parent、communities.parent和community_reports.parent的實體對象,并進行格式化處理。 - 進入到構建上下文階段。在這個階段,最關鍵的一個核心概念是:靜態與動態全局搜索策略的選擇。
- 靜態策略方法指的是知識圖譜中預定級別的社區中進行搜索來生成答案。然后,大模型合并并總結此抽象級別的所有社區報告。最后,摘要用作 大模型的附加上下文,以生成對用戶問題的響應。此為靜態方法。它存在的問題是既昂貴又低效,因為包含許多對用戶查詢沒有幫助的低級報告。
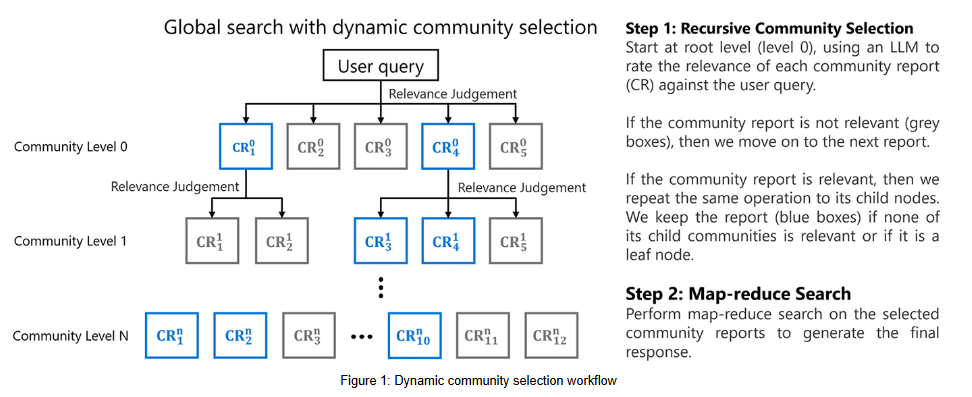
- 動態社區選擇算法
dynamic_community_selection利用索引數據集的知識圖譜結構。從知識圖譜的根開始,使用提示工程 + 大模型來評估社區報告在回答用戶問題方面的相關性。如果報告被視為不相關,則將其及其節點(或子社區)從搜索過程中刪除。另一方面,如果報告被視為相關,將遍歷其子節點并重復該操作。最后,只有相關的報告才會傳遞給map-reduce操作以生成對用戶的響應。
- 依次讀取
-
該算法類實現的核心機制并不是簡單地評估所有社區,而是采用啟發式遍歷,具體體現在:
- 選擇性探索: 并不是簡單地評估所有社區,而是根據當前社區的相關性決定是否探索其子社區。只有當一個社區的評分大于或等于閾值時,才會將其子社區添加到下一輪評估中。
- 動態隊列構建:
queue = communities_to_rate表明下一輪要評估的社區完全取決于當前輪次中哪些社區被認為是相關的。這不是一個固定的或預先確定的遍歷順序。 - 剪枝機制: 如果一個社區的評分低于閾值,其所有子社區都會被"剪枝",不會被進一步探索。這是啟發式算法的典型特征。
- 自適應性: 算法的路徑會根據不同的查詢而變化,因為相關性評分依賴于具體的查詢內容。
- 回退策略: 如果在當前路徑上找不到相關社區,算法會嘗試探索下一個層級的所有社區,這也是一種啟發式決策。
-
其中,用于評估社區相關性的提示詞是這樣的,其對應的中文提示如下所示:
Rate_query = "“”——角色你是一個樂于助人的助手,負責決定所提供的信息是否有助于回答給定的問題,即使它只是部分相關。——目標在0到5的范圍內,請對回答問題所提供的信息的相關性或幫助程度進行評分。——信息{描述}——問題{問題}——目標回復長度和格式——請以以下JSON格式回復,包含兩個條目:-“原因”:評分的原因,請包括你考慮過的信息。-“評級”:相關度從0到5,其中0是最不相關的,5是最相關的。{{“理由”:str,“等級”:int。}}
- 然后,該輸出的結果會作為變量
context_data傳遞給global_search_reduce_system_prompt.txt中定義的提示,并調用大模型生成最終的Reduce響應,同時,Reduce響應的結果會作為變量context_text傳遞給global_search_knowledge_system_prompt.txt中定義的提示,引導大模型生成最終的Knowledge響應。
四 GraphRAG Python API使用
- 構建索引過程
from pathlib import Path
from pprint import pprintimport pandas as pdimport graphrag.api as api
from graphrag.config.load_config import load_config
from graphrag.index.typing.pipeline_run_result import PipelineRunResultPROJECT_DIRECTORY = "./graphrag_test"
graphrag_config = load_config(Path(PROJECT_DIRECTORY))index_result: list[PipelineRunResult] = await api.build_index(config=graphrag_config)# index_result is a list of workflows that make up the indexing pipeline that was run
for workflow_result in index_result:status = f"error\n{workflow_result.errors}" if workflow_result.errors else "success"print(f"Workflow Name: {workflow_result.workflow}\tStatus: {status}")
- Query過程
entities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/entities.parquet")
communities = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/communities.parquet")
community_reports = pd.read_parquet(f"{PROJECT_DIRECTORY}/output/community_reports.parquet"
)response, context = await api.global_search(config=graphrag_config,entities=entities,communities=communities,community_reports=community_reports,community_level=1,dynamic_community_selection=False,response_type="Multiple Paragraphs",query="請幫我介紹下亞馬遜公司?",
)print(response)
- 測試結果
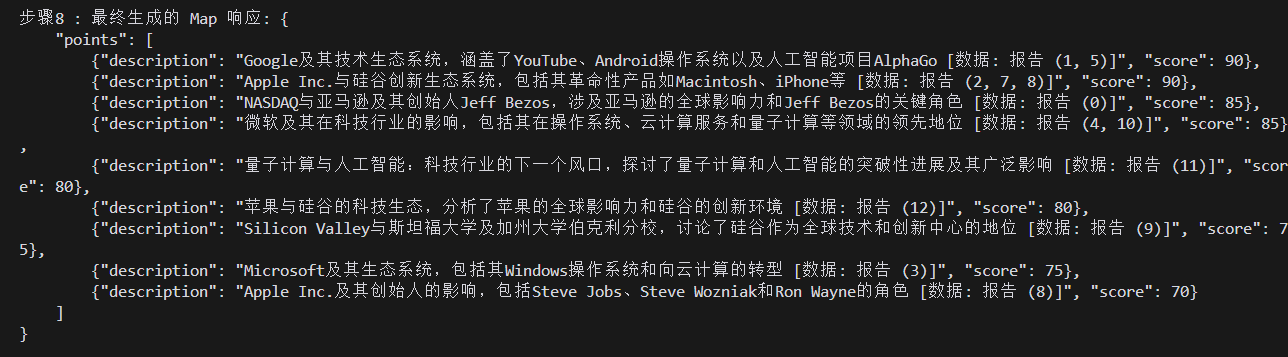
## 亞馬遜公司簡介
亞馬遜(Amazon),在中文中被稱為“亞馬遜”,是一家全球公認的電子商務和云計算領域的領導者。公司成立于1994年,最初是一個在線書店,但隨著時間的推移,亞馬遜已經發展成為一個綜合性的在線市場,提供廣泛的產品和服務 [Data: Reports (0)]。
### 電子商務與零售
亞馬遜在電子商務領域的成功不僅體現在其廣泛的產品種類和全球市場覆蓋,還通過戰略性收購進一步鞏固了其在零售行業的地位。亞馬遜收購全食超市(Whole Foods)就是一個重要的戰略舉措。這次收購不僅擴大了亞馬遜的市場影響力,還將其電子商務能力與實體零售相結合,為消費者提供無縫的購物體驗 [Data: Reports (0)]。
### 云計算與技術創新
亞馬遜網絡服務(AWS)是其云計算平臺,是公司利潤的主要驅動因素,也是其商業模式的關鍵組成部分。AWS為全球的企業提供計算能力和存儲服務,顯示了亞馬遜在技術領域的強大實力 [Data: Reports (0)]。
此外,亞馬遜在技術創新方面的投入也體現在其智能助手Alexa的推出。Alexa不僅增強了亞馬遜在技術領域的影響力,還展示了其利用人工智能改善用戶體驗的能力 [Data: Reports (0)]。亞馬遜積極投資于人工智能,以提升用戶體驗,這一戰略重點使其在技術創新的前沿占據一席之地 [Data: Reports (0)]。
### 領導力與企業文化
杰夫·貝索斯(Jeff Bezos),亞馬遜的創始人,在將公司轉變為全球電子商務巨頭的過程中發揮了關鍵作用。他的領導和遠見在亞馬遜的擴張和創新中起到了重要作用,特別是在AWS的發展和全食超市的收購中 [Data: Reports (0)]。
### 競爭與合作
亞馬遜與其他科技巨頭如蘋果和谷歌的互動,突顯了科技行業內的競爭與合作動態。這些公司在多個領域展開競爭,同時也在某些項目上進行合作 [Data: Reports (0)]。綜上所述,亞馬遜通過其在電子商務、云計算和技術創新方面的戰略舉措,鞏固了其在全球市場的領導地位。










![[QtADS]解析ads.pro](http://pic.xiahunao.cn/[QtADS]解析ads.pro)








)