Elastic Stack簡介
如果你沒有聽說過Elastic Stack,那你一定聽說過ELK,實際上ELK是三款軟件的簡稱,分別是Elasticsearch、 Logstash、Kibana組成,在發展的過程中,又有新成員Beats的加入,所以就形成了Elastic Stack。所以說,ELK是舊的稱呼,Elastic Stack是新的名字。

全系的Elastic Stack技術棧包括:
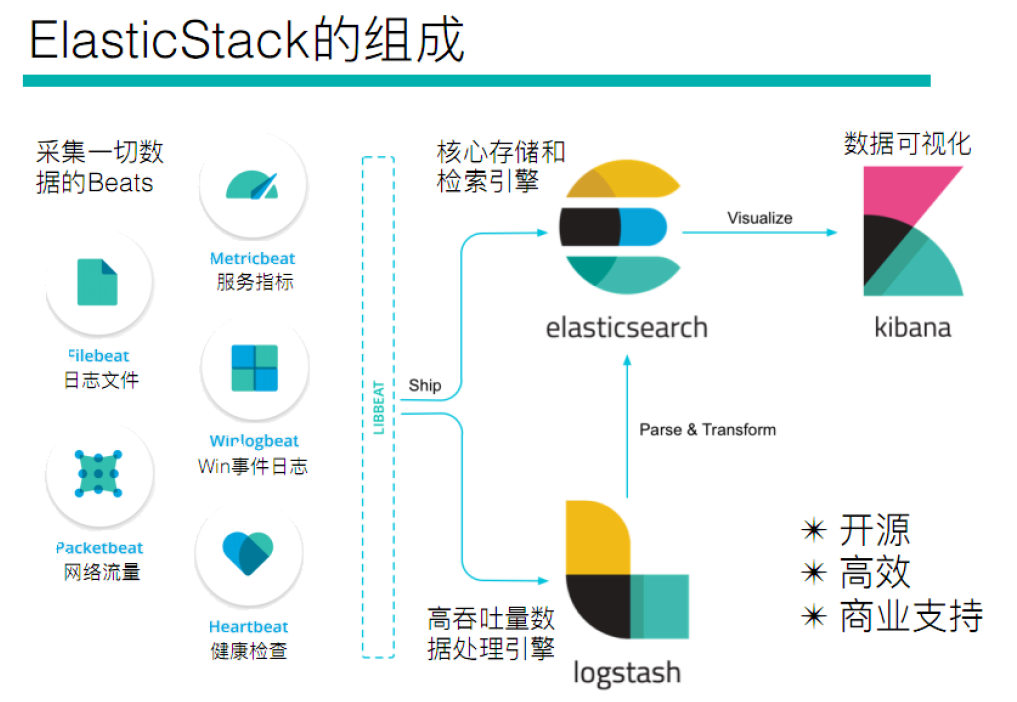
Elasticsearch
Elasticsearch 基于java,是個開源分布式搜索引擎,它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格接口,多數據源,自動搜索負載等。
Logstash
Logstash 基于java,是一個開源的用于收集,分析和存儲日志的工具。
Kibana
Kibana 基于nodejs,也是一個開源和免費的工具,Kibana可以為 Logstash 和 ElasticSearch 提供的日志分析友好的Web 界面,可以匯總、分析和搜索重要數據日志。
Beats
Beats是elastic公司開源的一款采集系統監控數據的代理agent,是在被監控服務器上以客戶端形式運行的數據收集器的統稱,可以直接把數據發送給Elasticsearch或者通過Logstash發送給Elasticsearch,然后進行后續的數據分析活動。Beats由如下組成:
- Packetbeat:是一個網絡數據包分析器,用于監控、收集網絡流量信息,Packetbeat嗅探服務器之間的流量,解析應用層協議,并關聯到消息的處理,其支 持ICMP (v4 and v6)、DNS、HTTP、Mysql、PostgreSQL、Redis、MongoDB、Memcache等協議;
- Filebeat:用于監控、收集服務器日志文件,其已取代 logstash forwarder;
- Metricbeat:可定期獲取外部系統的監控指標信息,其可以監控、收集 Apache、HAProxy、MongoDB MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper等服務;
Beats和Logstash其實都可以進行數據的采集,但是目前主流的是使用Beats進行數據采集,然后使用 Logstash進行數據的分割處理等,早期沒有Beats的時候,使用的就是Logstash進行數據的采集。
ElasticSearch快速入門
簡介
官網:https://www.elastic.co/
ElasticSearch是一個基于Lucene的搜索服務器。它提供了一個分布式多用戶能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java開發的,并作為Apache許可條款下的開放源碼發布,是當前流行的企業級搜索引擎。設計用于云計算中,能夠達到實時搜索,穩定,可靠,快速,安裝使用方便。
我們建立一個網站或應用程序,并要添加搜索功能,但是想要完成搜索工作的創建是非常困難的。我們希望搜索解決方案要運行速度快,我們希望能有一個零配置和一個完全免費的搜索模式,我們希望能夠簡單地使用JSON通過HTTP來索引數據,我們希望我們的搜索服務器始終可用,我們希望能夠從一臺開始并擴展到數百臺,我們要實時搜索,我們要簡單的多租戶,我們希望建立一個云的解決方案。因此我們利用Elasticsearch來解決所有這些問題及可能出現的更多其它問題。
ElasticSearch是Elastic Stack的核心,同時Elasticsearch 是一個分布式、RESTful風格的搜索和數據分析引擎,能夠解決不斷涌現出的各種用例。作為Elastic Stack的核心,它集中存儲您的數據,幫助您發現意料之中以及意料之外的情況。
前言
Elasticsearch的發展是非常快速的,所以在ES5.0之前,ELK的各個版本都不統一,出現了版本號混亂的狀態,所以從5.0開始,所有Elastic Stack中的項目全部統一版本號。目前最新版本是6.5.4,我們將基于這一版本進行學習。
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-ydFMcnus-1614908740678)(http://victorfengming.gitee.io/elk/1_ElasticSearch%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%89%E8%A3%85/images/image-20200922093432839.png)]
下載
到官網下載:https://www.elastic.co/cn/downloads/
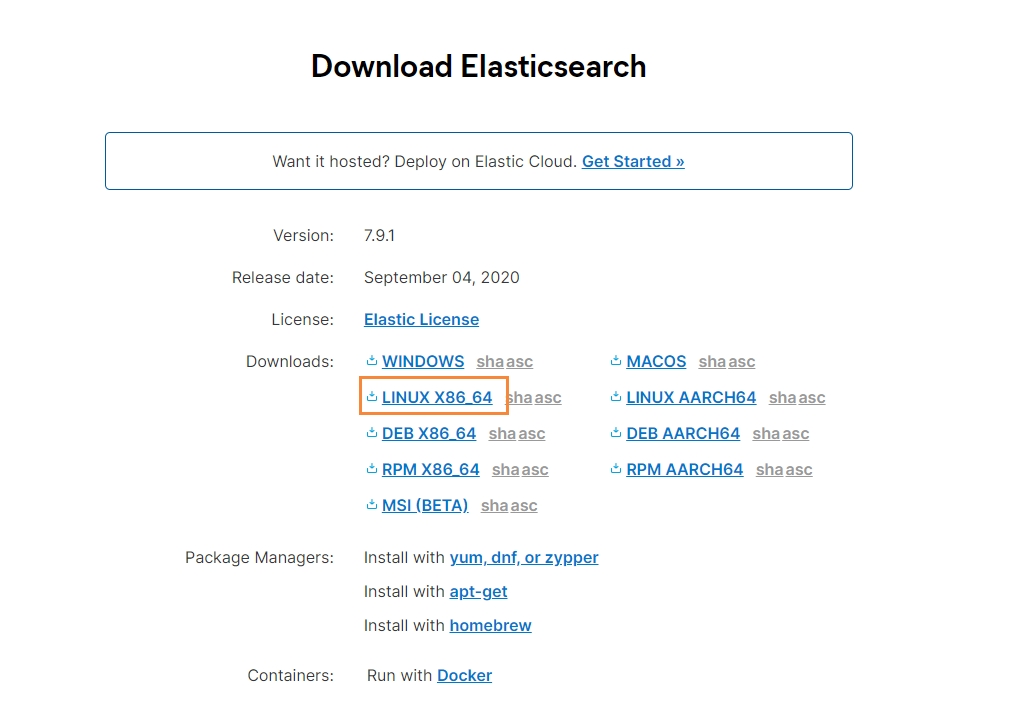
選擇對應版本的數據,這里我使用的是Linux來進行安裝,所以就先下載好ElasticSearch的Linux安裝包
拉取Docker容器
因為我們需要部署在Linux下,為了以后遷移ElasticStack環境方便,我們就使用Docker來進行部署,首先我們拉取一個帶有ssh的centos docker鏡像
# 拉取鏡像
docker pull moxi/centos_ssh
# 制作容器
docker run --privileged -d -it -h ElasticStack --name ElasticStack -p 11122:22 -p 9200:9200 -p 5601:5601 -p 9300:9300 -v /etc/localtime:/etc/localtime:ro moxi/centos_ssh /usr/sbin/init
然后直接遠程連接11122端口即可
單機版安裝
因為ElasticSearch不支持Root用戶直接操作,因此我們需要創建一個elsearch用戶
# 添加新用戶
useradd elsearch# 創建一個soft目錄,存放下載的軟件
mkdir /soft# 進入,然后通過xftp工具,將剛剛下載的文件拖動到該目錄下
cd /soft# 解壓縮
tar -zxvf elasticsearch-7.9.1-linux-x86_64.tar.gz#重命名
mv elasticsearch-7.9.1/ elsearch
因為剛剛我們是使用root用戶操作的,所以我們還需要更改一下/soft文件夾的所屬,改為elsearch用戶
chown elsearch:elsearch /soft/ -R
然后在切換成elsearch用戶進行操作
# 切換用戶
su - elsearch
然后我們就可以對我們的配置文件進行修改了
# 進入到 elsearch下的config目錄
cd /soft/elsearch/config
然后找到下面的配置
#打開配置文件
vim elasticsearch.yml #設置ip地址,任意網絡均可訪問
network.host: 0.0.0.0
在Elasticsearch中如果,network.host不是localhost或者127.0.0.1的話,就會認為是生產環境,會對環境的要求比較高,我們的測試環境不一定能夠滿足,一般情況下需要修改2處配置,如下:
# 修改jvm啟動參數
vim conf/jvm.options#根據自己機器情況修改
-Xms128m
-Xmx128m
然后在修改第二處的配置,這個配置要求我們到宿主機器上來進行配置
# 到宿主機上打開文件
vim /etc/sysctl.conf
# 增加這樣一條配置,一個進程在VMAs(虛擬內存區域)創建內存映射最大數量
vm.max_map_count=655360
# 讓配置生效
sysctl -p
啟動ElasticSearch
首先我們需要切換到 elsearch用戶
su - elsearch
然后在到bin目錄下,執行下面
# 進入bin目錄
cd /soft/elsearch/bin
# 后臺啟動
./elasticsearch -d
啟動成功后,訪問下面的URL
http://202.193.56.222:9200/
如果出現了下面的信息,就表示已經成功啟動了
如果你在啟動的時候,遇到過問題,那么請參考下面的錯誤分析~
錯誤分析
錯誤情況1
如果出現下面的錯誤信息
java.lang.RuntimeException: can not run elasticsearch as rootat org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:111)at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:178)at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:393)at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:170)at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:161)at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:127)at org.elasticsearch.cli.Command.main(Command.java:90)at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:126)at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92)
For complete error details, refer to the log at /soft/elsearch/logs/elasticsearch.log
[root@e588039bc613 bin]# 2020-09-22 02:59:39,537121 UTC [536] ERROR CLogger.cc@310 Cannot log to named pipe /tmp/elasticsearch-5834501324803693929/controller_log_381 as it could not be opened for writing
2020-09-22 02:59:39,537263 UTC [536] INFO Main.cc@103 Parent process died - ML controller exiting
就說明你沒有切換成 elsearch用戶,因為不能使用root操作es
su - elsearch
錯誤情況2
[1]:max file descriptors [4096] for elasticsearch process is too low, increase to at least[65536]
解決方法:切換到root用戶,編輯limits.conf添加如下內容
vi /etc/security/limits.conf# ElasticSearch添加如下內容:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
錯誤情況3
[2]: max number of threads [1024] for user [elsearch] is too low, increase to at least
[4096]
也就是最大線程數設置的太低了,需要改成4096
#解決:切換到root用戶,進入limits.d目錄下修改配置文件。
vi /etc/security/limits.d/90-nproc.conf
#修改如下內容:
* soft nproc 1024
#修改為
* soft nproc 4096
錯誤情況4
[3]: system call filters failed to install; check the logs and fix your configuration
or disable system call filters at your own risk
解決:Centos6不支持SecComp,而ES5.2.0默認bootstrap.system_call_filter為true
vim config/elasticsearch.yml
# 添加
bootstrap.system_call_filter: false
bootstrap.memory_lock: false
錯誤情況5
[elsearch@e588039bc613 bin]$ Exception in thread "main" org.elasticsearch.bootstrap.BootstrapException: java.nio.file.AccessDeniedException: /soft/elsearch/config/elasticsearch.keystore
Likely root cause: java.nio.file.AccessDeniedException: /soft/elsearch/config/elasticsearch.keystoreat java.base/sun.nio.fs.UnixException.translateToIOException(UnixException.java:90)at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:111)at java.base/sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:116)at java.base/sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:219)at java.base/java.nio.file.Files.newByteChannel(Files.java:375)at java.base/java.nio.file.Files.newByteChannel(Files.java:426)at org.apache.lucene.store.SimpleFSDirectory.openInput(SimpleFSDirectory.java:79)at org.elasticsearch.common.settings.KeyStoreWrapper.load(KeyStoreWrapper.java:220)at org.elasticsearch.bootstrap.Bootstrap.loadSecureSettings(Bootstrap.java:240)at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:349)at org.elasticsearch.bootstrap.Elasticsearch.init(Elasticsearch.java:170)at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:161)at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:86)at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:127)at org.elasticsearch.cli.Command.main(Command.java:90)at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:126)at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92)
我們通過排查,發現是因為 /soft/elsearch/config/elasticsearch.keystore 存在問題
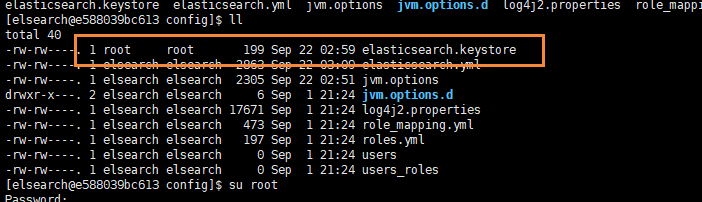
也就是說該文件還是所屬于root用戶,而我們使用elsearch用戶無法操作,所以需要把它變成elsearch
chown elsearch:elsearch elasticsearch.keystore
錯誤情況6
[1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
ERROR: Elasticsearch did not exit normally - check the logs at /soft/elsearch/logs/elasticsearch.log
繼續修改配置 elasticsearch.yaml
# 取消注釋,并保留一個節點
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
ElasticSearchHead可視化工具
由于ES官方沒有給ES提供可視化管理工具,僅僅是提供了后臺的服務,elasticsearch-head是一個為ES開發的一個頁面客戶端工具,其源碼托管于Github,地址為 傳送門
head提供了以下安裝方式
- 源碼安裝,通過npm run start啟動(不推薦)
- 通過docker安裝(推薦)
- 通過chrome插件安裝(推薦)
- 通過ES的plugin方式安裝(不推薦)
通過Docker方式安裝
#拉取鏡像
docker pull mobz/elasticsearch-head:5
#創建容器
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
#啟動容器
docker start elasticsearch-head
通過瀏覽器進行訪問:
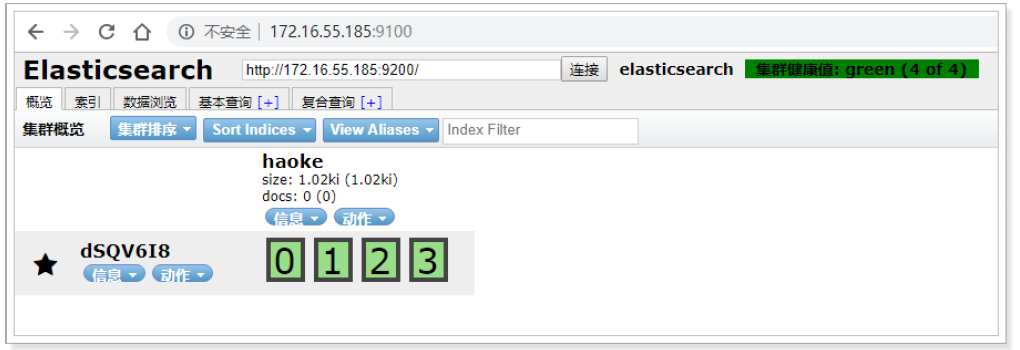
注意: 由于前后端分離開發,所以會存在跨域問題,需要在服務端做CORS的配置,如下:
vim elasticsearch.ymlhttp.cors.enabled: true http.cors.allow-origin: "*"
通過chrome插件的方式安裝不存在該問題
通過Chrome插件安裝
打開chrome的應用商店,即可安裝 https://chrome.google.com/webstore/detail/elasticsearch-head/ffmkiejjmecolpfloofpjologoblkegm
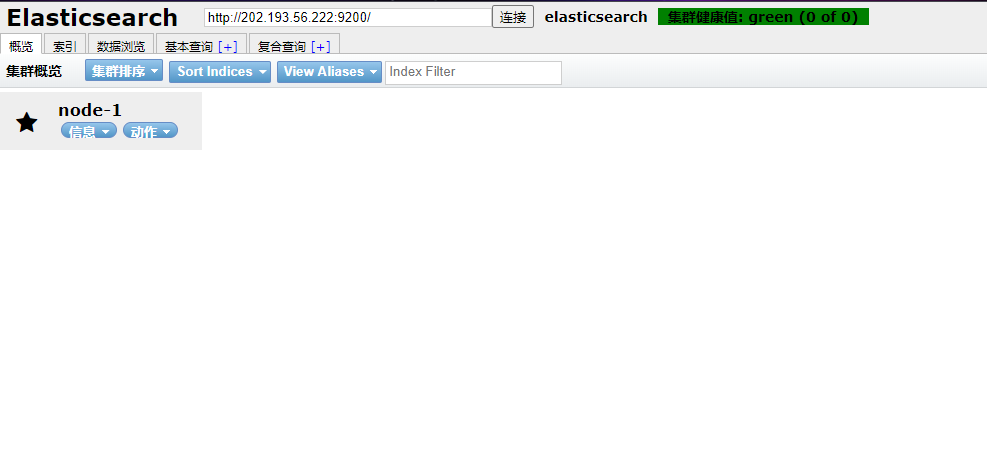
我們也可以新建索引
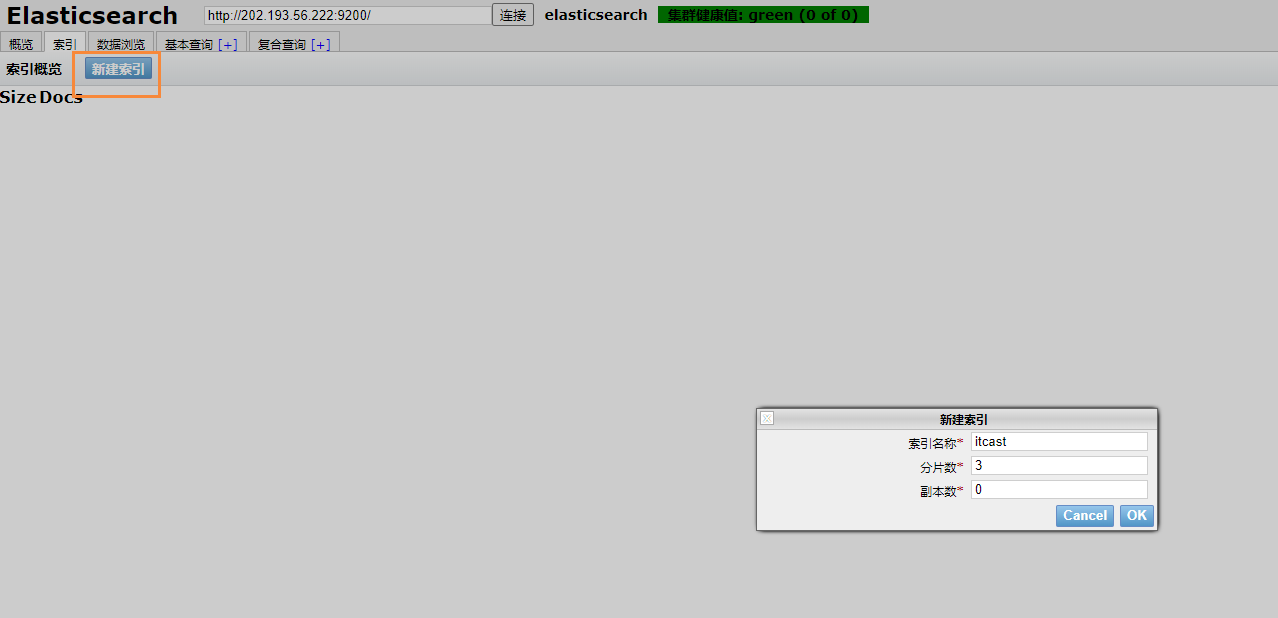
建議:推薦使用chrome插件的方式安裝,如果網絡環境不允許,就采用其它方式安裝。
ElasticSearch中的基本概念
索引
- 索引(index)是Elasticsearch對邏輯數據的邏輯存儲,所以它可以分為更小的部分。
- 可以把索引看成關系型數據庫的表,索引的結構是為快速有效的全文索引準備的,特別是它不存儲原始值。
- Elasticsearch可以把索引存放在一臺機器或者分散在多臺服務器上,每個索引有一或多個分片(shard),每個分片可以有多個副本(replica)。
文檔
- 存儲在Elasticsearch中的主要實體叫文檔(document)。用關系型數據庫來類比的話,一個文檔相當于數據庫表中的一行記錄。
- Elasticsearch和MongoDB中的文檔類似,都可以有不同的結構,但Elasticsearch的文檔中,相同字段必須有相同類型。
- 文檔由多個字段組成,每個字段可能多次出現在一個文檔里,這樣的字段叫多值字段(multivalued)。 每個字段的類型,可以是文本、數值、日期等。字段類型也可以是復雜類型,一個字段包含其他子文檔或者數 組。
映射
所有文檔寫進索引之前都會先進行分析,如何將輸入的文本分割為詞條、哪些詞條又會被過濾,這種行為叫做 映射(mapping)。一般由用戶自己定義規則。
文檔類型
- 在Elasticsearch中,一個索引對象可以存儲很多不同用途的對象。例如,一個博客應用程序可以保存文章和評 論。
- 每個文檔可以有不同的結構。
- 不同的文檔類型不能為相同的屬性設置不同的類型。例如,在同一索引中的所有文檔類型中,一個叫title的字段必須具有相同的類型。
RESTful API
在Elasticsearch中,提供了功能豐富的RESTful API的操作,包括基本的CRUD、創建索引、刪除索引等操作。
創建非結構化索引
在Lucene中,創建索引是需要定義字段名稱以及字段的類型的,在Elasticsearch中提供了非結構化的索引,就是不需要創建索引結構,即可寫入數據到索引中,實際上在Elasticsearch底層會進行結構化操作,此操作對用戶是透明的。
創建空索引
PUT /haoke
{"settings": {"index": {"number_of_shards": "2", #分片數"number_of_replicas": "0" #副本數}}
}
刪除索引
#刪除索引
DELETE /haoke
{"acknowledged": true
}
插入數據
URL規則: POST /{索引}/{類型}/{id}
POST /haoke/user/1001
#數據
{
"id":1001,
"name":"張三",
"age":20,
"sex":"男"
}
使用postman操作成功后
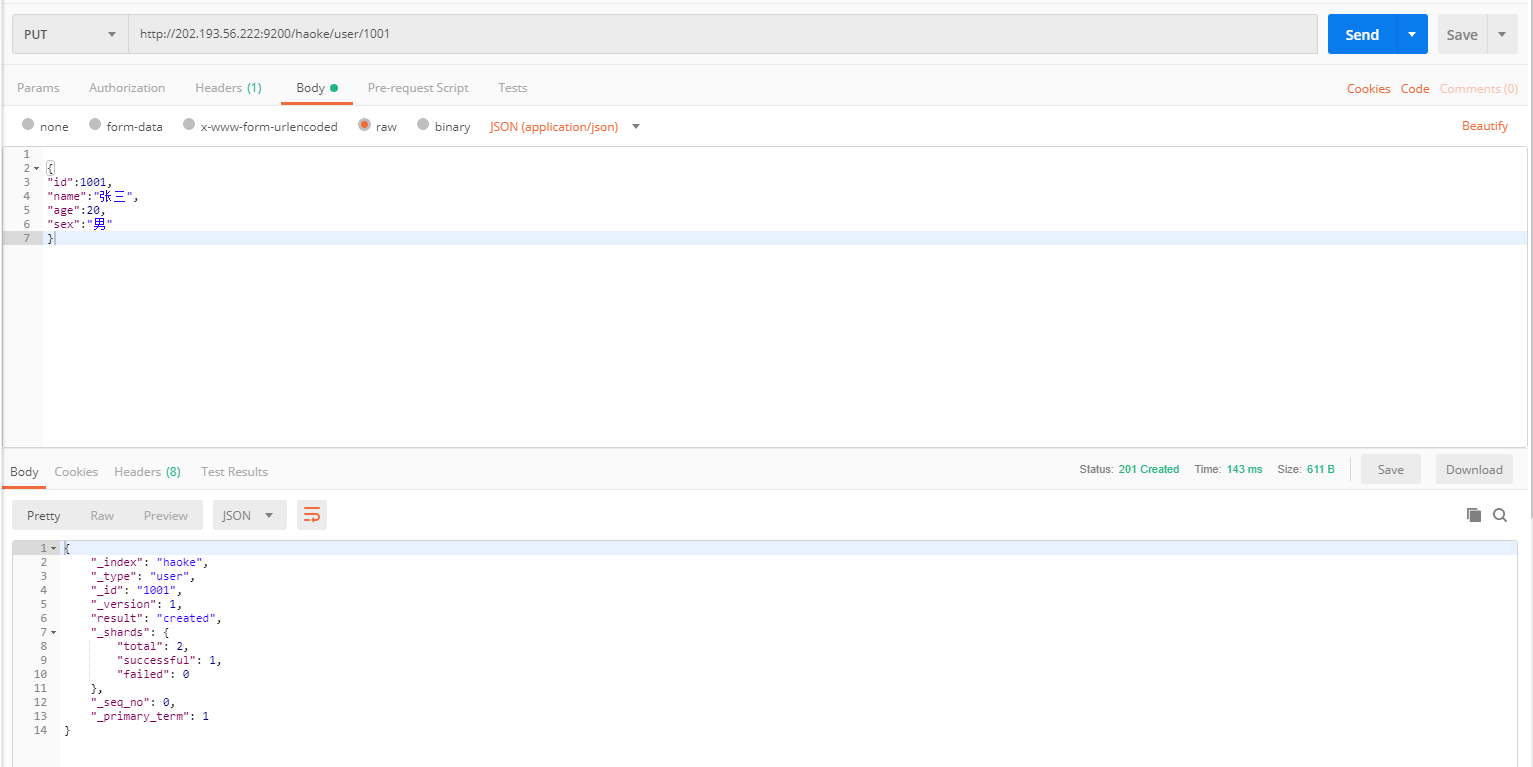
我們通過ElasticSearchHead進行數據預覽就能夠看到我們剛剛插入的數據了
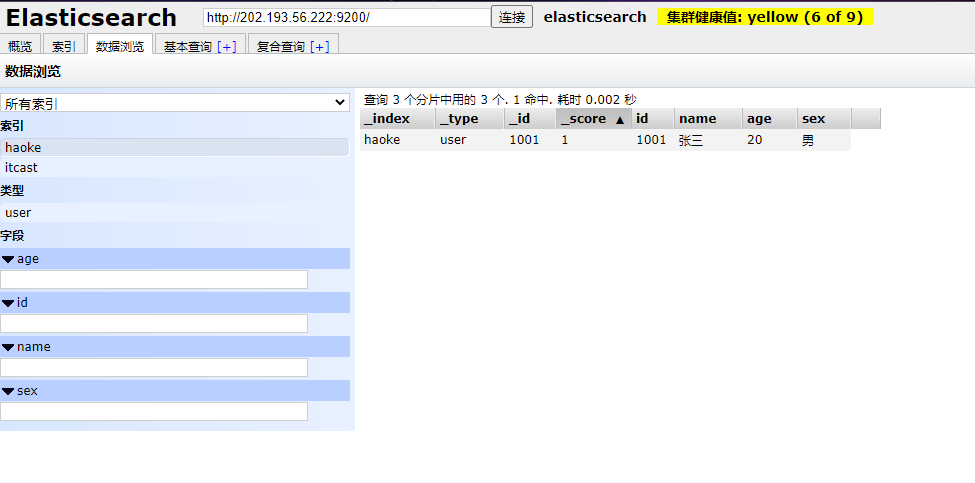
說明:非結構化的索引,不需要事先創建,直接插入數據默認創建索引。不指定id插入數據:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-ivzt81zo-1614908740705)(http://victorfengming.gitee.io/elk/1_ElasticSearch%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%89%E8%A3%85/images/image-20200922155935366.png)]
更新數據
在Elasticsearch中,文檔數據是不為修改的,但是可以通過覆蓋的方式進行更新。
PUT /haoke/user/1001
{
"id":1001,
"name":"張三",
"age":21,
"sex":"女"
}
更新結果如下:
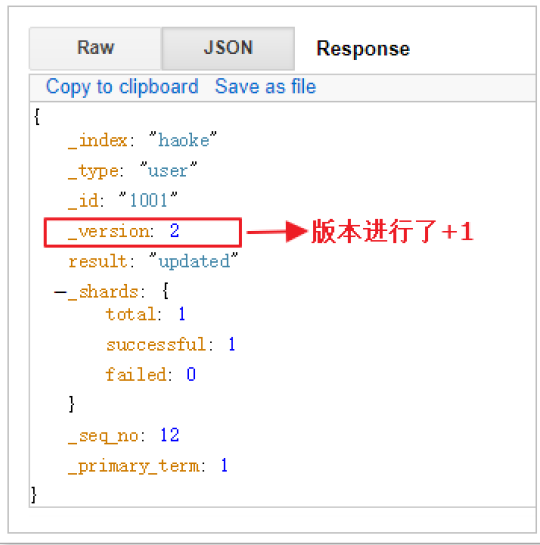
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-S0LhK1DA-1614908740708)(http://victorfengming.gitee.io/elk/1_ElasticSearch%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%89%E8%A3%85/images/image-20200922160201130.png)]
可以看到數據已經被覆蓋了。問題來了,可以局部更新嗎? – 可以的。前面不是說,文檔數據不能更新嗎? 其實是這樣的:在內部,依然會查詢到這個文檔數據,然后進行覆蓋操作,步驟如下:
- 從舊文檔中檢索JSON
- 修改它
- 刪除舊文檔
- 索引新文檔
#注意:這里多了_update標識
POST /haoke/user/1001/_update
{
"doc":{
"age":23
}
}
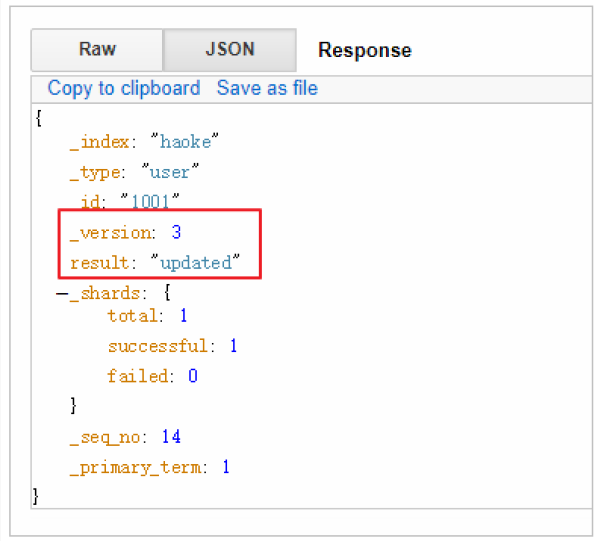
可以看到,數據已經是局部更新了
刪除索引
在Elasticsearch中,刪除文檔數據,只需要發起DELETE請求即可,不用額外的參數
DELETE 1 /haoke/user/1001
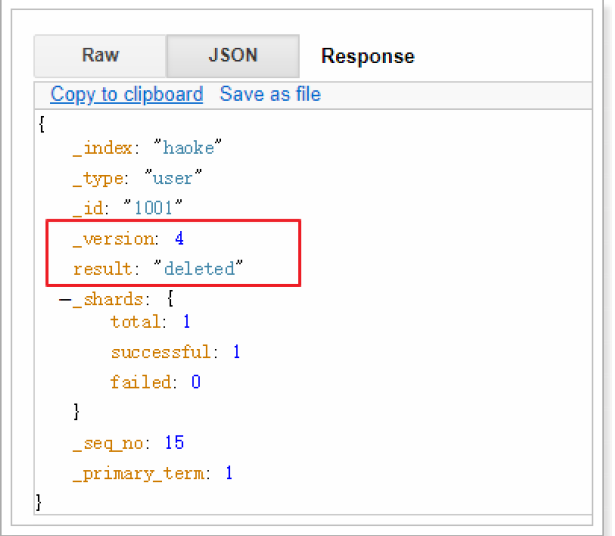
需要注意的是,result表示已經刪除,version也增加了。
如果刪除一條不存在的數據,會響應404
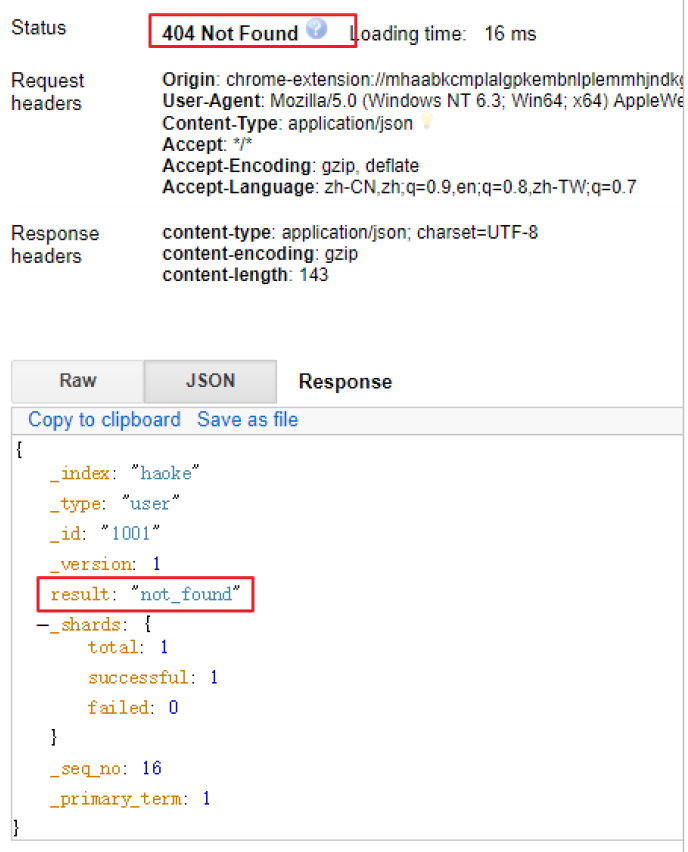
刪除一個文檔也不會立即從磁盤上移除,它只是被標記成已刪除。Elasticsearch將會在你之后添加更多索引的時候才會在后臺進行刪除內容的清理。【相當于批量操作】
搜索數據
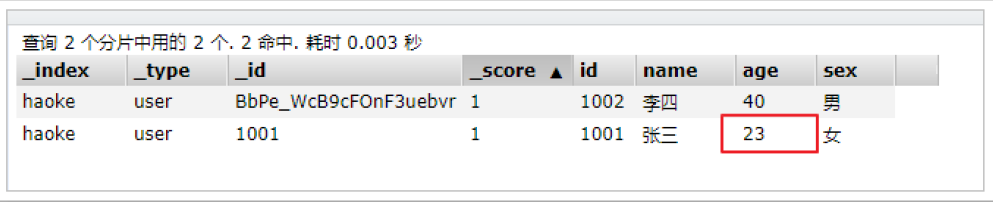
根據id搜索數據
GET /haoke/user/BbPe_WcB9cFOnF3uebvr
#返回的數據如下
{"_index": "haoke","_type": "user","_id": "BbPe_WcB9cFOnF3uebvr","_version": 8,"found": true,"_source": { #原始數據在這里"id": 1002,"name": "李四","age": 40,"sex": "男"}
}
搜索全部數據
GET 1 /haoke/user/_search
注意,使用查詢全部數據的時候,默認只會返回10條
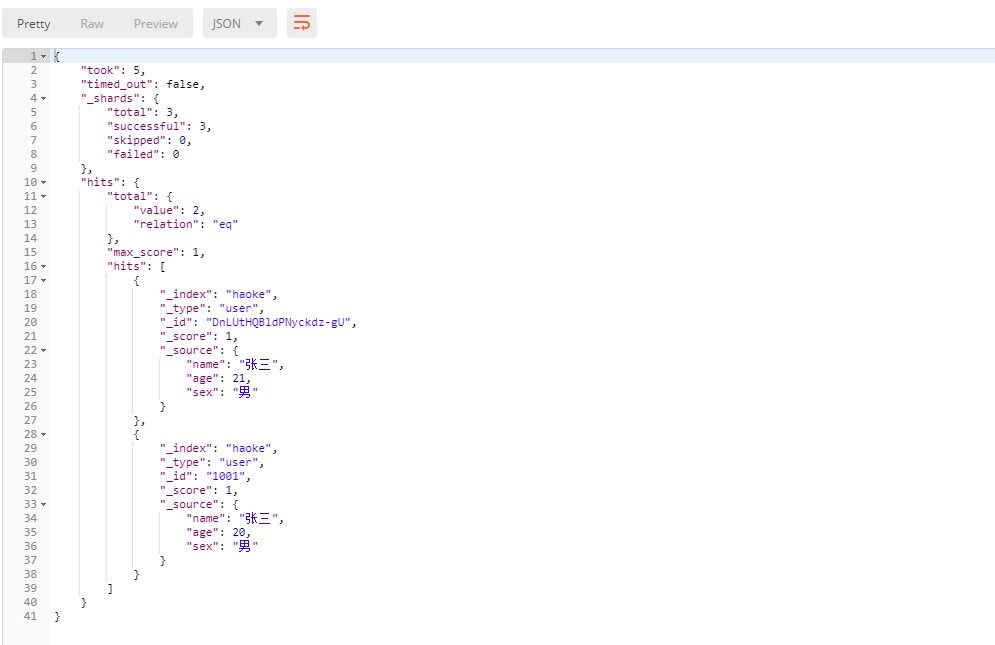
關鍵字搜索數據
#查詢年齡等于20的用戶
GET /haoke/user/_search?q=age:20
結果如下:
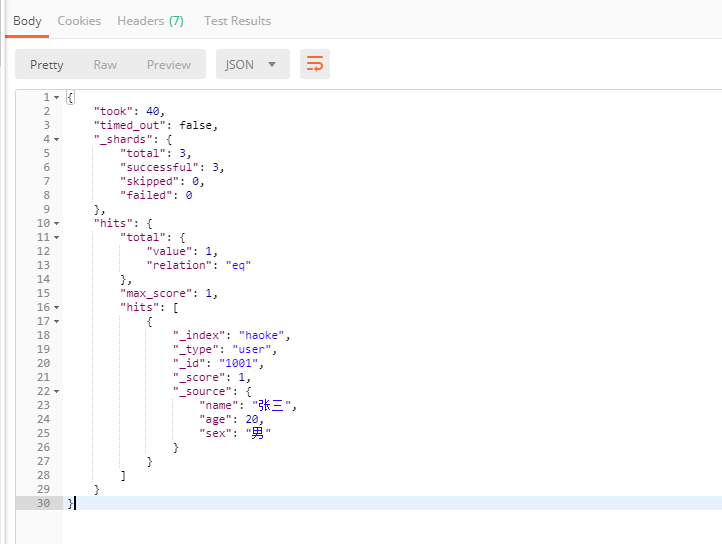
DSL搜索
Elasticsearch提供豐富且靈活的查詢語言叫做DSL查詢(Query DSL),它允許你構建更加復雜、強大的查詢。 DSL(Domain Specific Language特定領域語言)以JSON請求體的形式出現。
POST /haoke/user/_search
#請求體
{"query" : {"match" : { #match只是查詢的一種"age" : 20}}
}
實現:查詢年齡大于30歲的男性用戶。
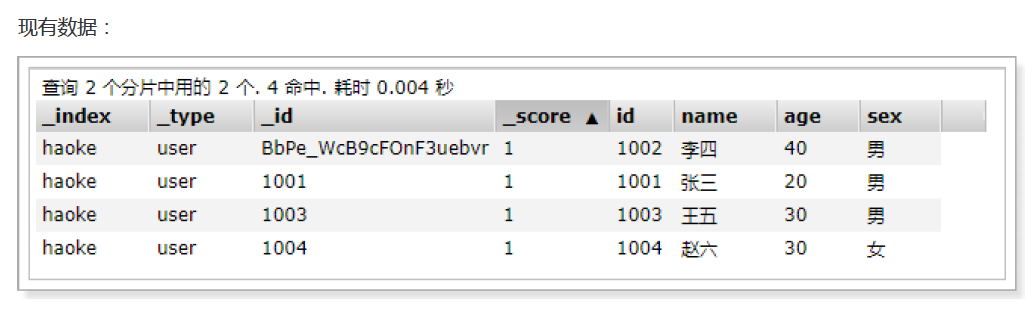
POST /haoke/user/_search
#請求數據
{"query": {"bool": {"filter": {"range": {"age": {"gt": 30}}},"must": {"match": {"sex": "男"}}}}
}
查詢出來的結果
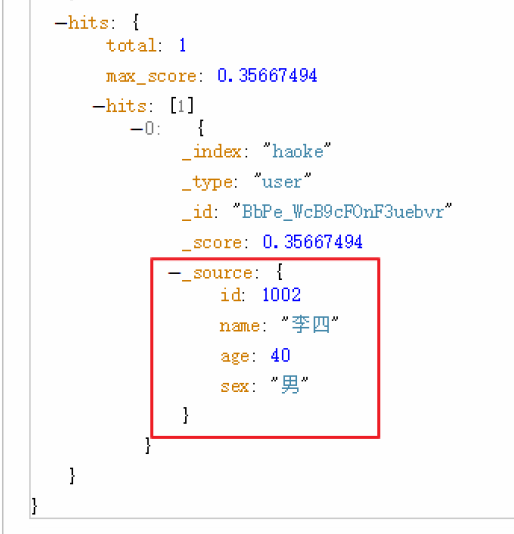
全文搜索
POST /haoke/user/_search
#請求數據
{"query": {"match": {"name": "張三 李四"}}
}
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-LfZ724mz-1614908740730)(http://victorfengming.gitee.io/elk/1_ElasticSearch%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%89%E8%A3%85/images/image-20200922163315285.png)]
高亮顯示,只需要在添加一個 highlight即可
POST /haoke/user/_search
#請求數據
{"query": {"match": {"name": "張三 李四"}}"highlight": {"fields": {"name": {}}}
}

聚合
在Elasticsearch中,支持聚合操作,類似SQL中的group by操作。
POST /haoke/user/_search
{"aggs": {"all_interests": {"terms": {"field": "age"}}}
}
結果如下,我們通過年齡進行聚合

從結果可以看出,年齡30的有2條數據,20的有一條,40的一條。
ElasticSearch核心詳解
文檔
在Elasticsearch中,文檔以JSON格式進行存儲,可以是復雜的結構,如:
{"_index": "haoke","_type": "user","_id": "1005","_version": 1,"_score": 1,"_source": {"id": 1005,"name": "孫七","age": 37,"sex": "女","card": {"card_number": "123456789"}}
}
其中,card是一個復雜對象,嵌套的Card對象
元數據(metadata)
一個文檔不只有數據。它還包含了元數據(metadata)——關于文檔的信息。三個必須的元數據節點是:
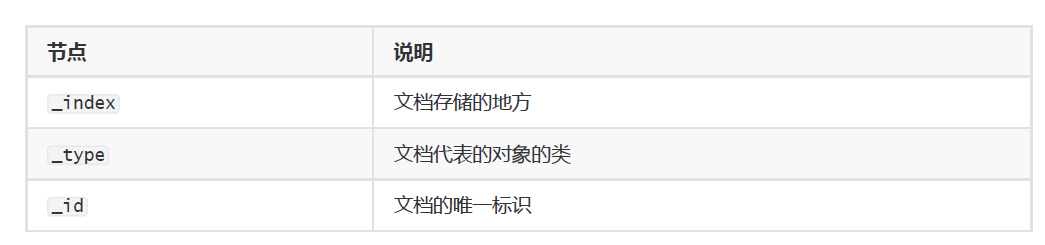
index
索引(index)類似于關系型數據庫里的“數據庫”——它是我們存儲和索引關聯數據的地方。
提示:事實上,我們的數據被存儲和索引在分片(shards)中,索引只是一個把一個或多個分片分組在一起的邏輯空間。然而,這只是一些內部細節——我們的程序完全不用關心分片。對于我們的程序而言,文檔存儲在索引(index)中。剩下的細節由Elasticsearch關心既可。
_type
在應用中,我們使用對象表示一些“事物”,例如一個用戶、一篇博客、一個評論,或者一封郵件。每個對象都屬于一個類(class),這個類定義了屬性或與對象關聯的數據。user 類的對象可能包含姓名、性別、年齡和Email地址。 在關系型數據庫中,我們經常將相同類的對象存儲在一個表里,因為它們有著相同的結構。同理,在Elasticsearch 中,我們使用相同類型(type)的文檔表示相同的“事物”,因為他們的數據結構也是相同的。
每個類型(type)都有自己的映射(mapping)或者結構定義,就像傳統數據庫表中的列一樣。所有類型下的文檔被存儲在同一個索引下,但是類型的映射(mapping)會告訴Elasticsearch不同的文檔如何被索引。
_type 的名字可以是大寫或小寫,不能包含下劃線或逗號。我們將使用blog 做為類型名。
_id
id僅僅是一個字符串,它與_index 和_type 組合時,就可以在Elasticsearch中唯一標識一個文檔。當創建一個文 檔,你可以自定義_id ,也可以讓Elasticsearch幫你自動生成(32位長度)
查詢響應
pretty
可以在查詢url后面添加pretty參數,使得返回的json更易查看。
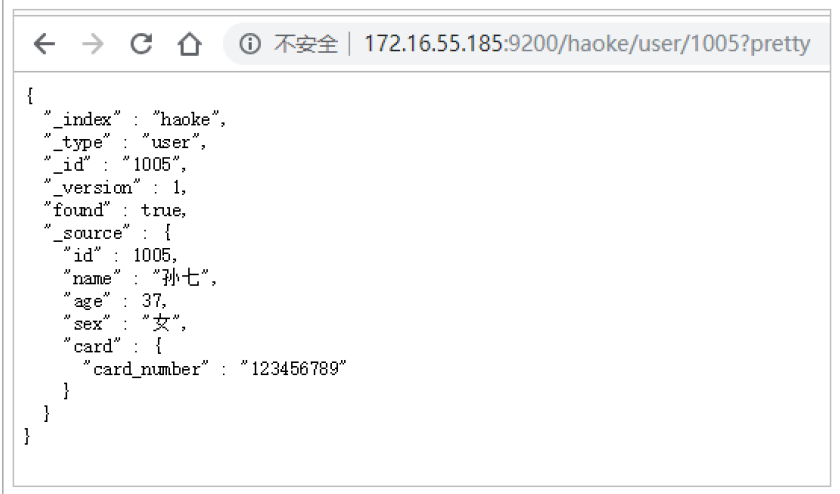
指定響應字段
在響應的數據中,如果我們不需要全部的字段,可以指定某些需要的字段進行返回。通過添加 _source
GET /haoke/user/1005?_source=id,name
#響應
{"_index": "haoke","_type": "user","_id": "1005","_version": 1,"found": true,"_source": {"name": "孫七","id": 1005}
}
如不需要返回元數據,僅僅返回原始數據,可以這樣:
GET /haoke/1 user/1005/_source
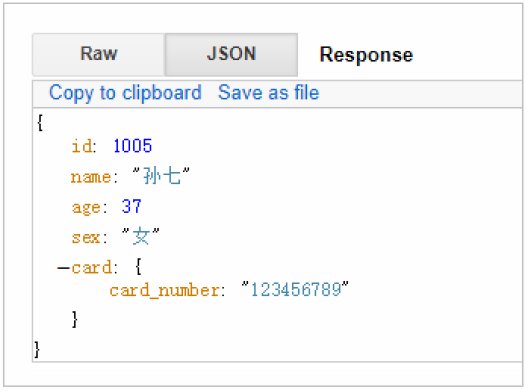
還可以這樣:
GET /haoke/user/1005/_source?_1 source=id,name
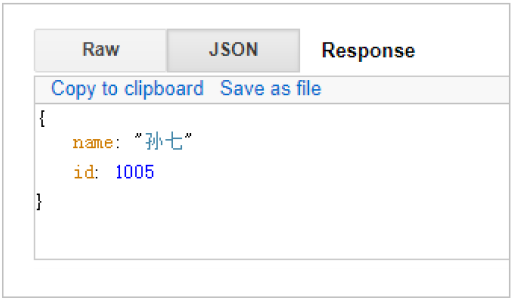
判斷文檔是否存在
如果我們只需要判斷文檔是否存在,而不是查詢文檔內容,那么可以這樣:
HEAD /haoke/user/1005
通過發送一個head請求,來判斷數據是否存在
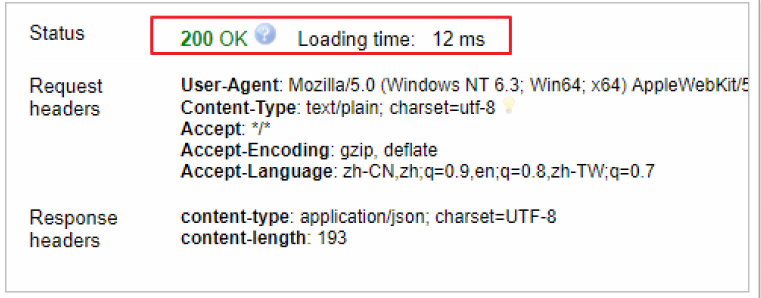
HEAD 1 /haoke/user/1006
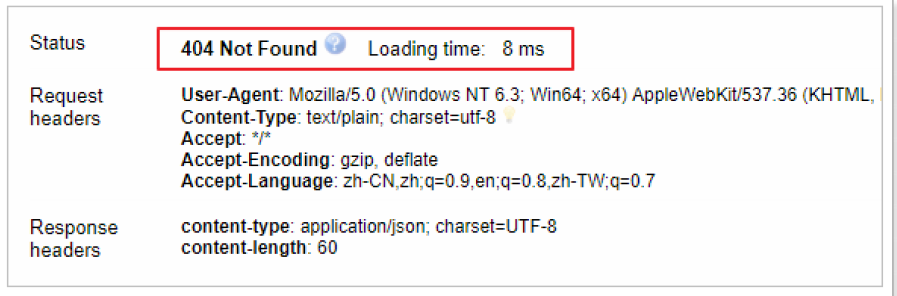
當然,這只表示你在查詢的那一刻文檔不存在,但并不表示幾毫秒后依舊不存在。另一個進程在這期間可能創建新文檔。
批量操作
有些情況下可以通過批量操作以減少網絡請求。如:批量查詢、批量插入數據。
批量查詢
POST /haoke/user/_mget
{"ids" : [ "1001", "1003" ]
}
結果:

如果,某一條數據不存在,不影響整體響應,需要通過found的值進行判斷是否查詢到數據。
POST /haoke/user/_mget
{"ids" : [ "1001", "1006" ]
}
結果:

也就是說,一個數據的存在不會影響其它數據的返回
_bulk操作
在Elasticsearch中,支持批量的插入、修改、刪除操作,都是通過_bulk的api完成的。
請求格式如下:(請求格式不同尋常)
{ action: { metadata }}
{ request body }
{ action: { metadata }}
{ request body }
...
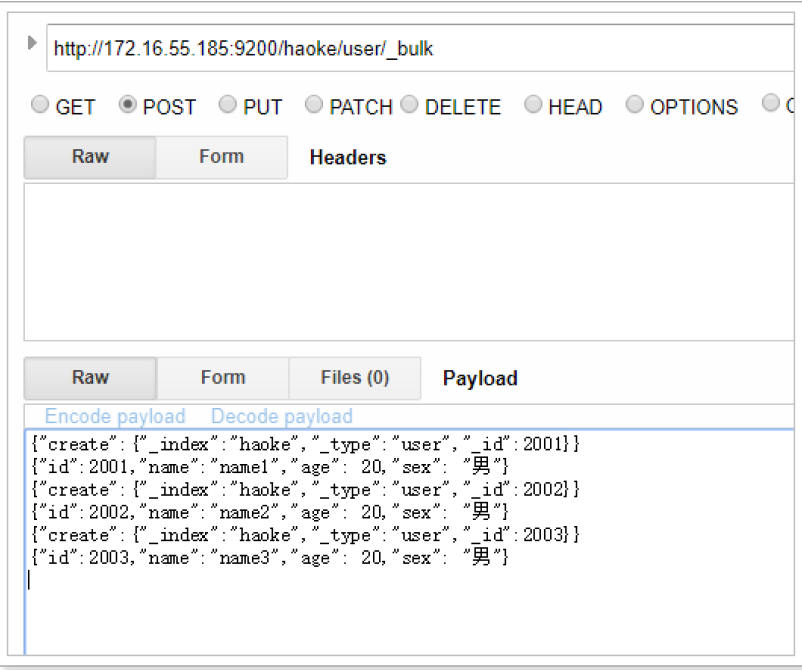
批量插入數據:
{"create":{"_index":"haoke","_type":"user","_id":2001}}
{"id":2001,"name":"name1","age": 20,"sex": "男"}
{"create":{"_index":"haoke","_type":"user","_id":2002}}
{"id":2002,"name":"name2","age": 20,"sex": "男"}
{"create":{"_index":"haoke","_type":"user","_id":2003}}
{"id":2003,"name":"name3","age": 20,"sex": "男"}
注意最后一行的回車。
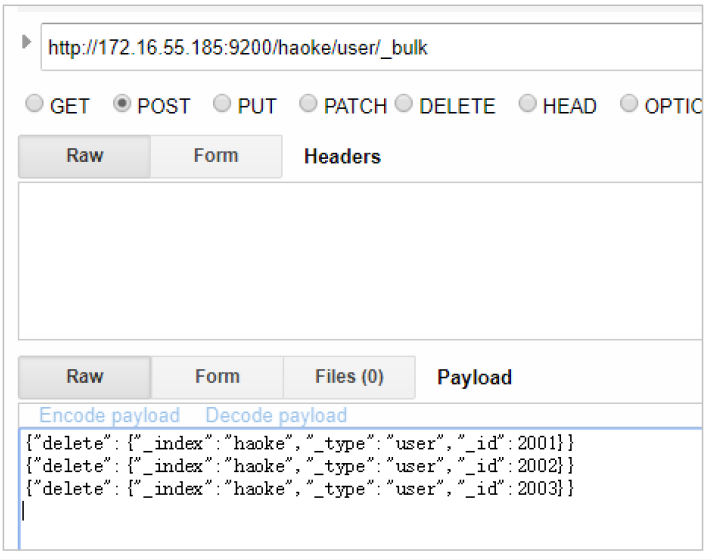
批量刪除:
{"delete":{"_index":"haoke","_type":"user","_id":2001}}
{"delete":{"_index":"haoke","_type":"user","_id":2002}}
{"delete":{"_index":"haoke","_type":"user","_id":2003}}
由于delete沒有請求體,所以,action的下一行直接就是下一個action。
其他操作就類似了。一次請求多少性能最高?
- 整個批量請求需要被加載到接受我們請求節點的內存里,所以請求越大,給其它請求可用的內存就越小。有一 個最佳的bulk請求大小。超過這個大小,性能不再提升而且可能降低。
- 最佳大小,當然并不是一個固定的數字。它完全取決于你的硬件、你文檔的大小和復雜度以及索引和搜索的負 載。
- 幸運的是,這個最佳點(sweetspot)還是容易找到的:試著批量索引標準的文檔,隨著大小的增長,當性能開始 降低,說明你每個批次的大小太大了。開始的數量可以在1000~5000個文檔之間,如果你的文檔非常大,可以使用較小的批次。
- 通常著眼于你請求批次的物理大小是非常有用的。一千個1kB的文檔和一千個1MB的文檔大不相同。一個好的 批次最好保持在5-15MB大小間。
分頁
和SQL使用LIMIT 關鍵字返回只有一頁的結果一樣,Elasticsearch接受from 和size 參數:
- size: 結果數,默認10
- from: 跳過開始的結果數,默認0
如果你想每頁顯示5個結果,頁碼從1到3,那請求如下:
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10
應該當心分頁太深或者一次請求太多的結果。結果在返回前會被排序。但是記住一個搜索請求常常涉及多個分 片。每個分片生成自己排好序的結果,它們接著需要集中起來排序以確保整體排序正確。
GET /haoke/user/_1 search?size=1&from=2
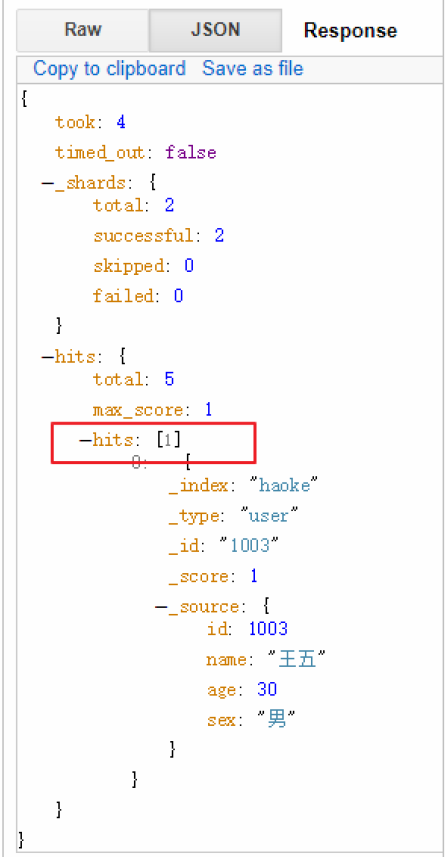
在集群系統中深度分頁
為了理解為什么深度分頁是有問題的,讓我們假設在一個有5個主分片的索引中搜索。當我們請求結果的第一 頁(結果1到10)時,每個分片產生自己最頂端10個結果然后返回它們給請求節點(requesting node),它再 排序這所有的50個結果以選出頂端的10個結果。
現在假設我們請求第1000頁——結果10001到10010。工作方式都相同,不同的是每個分片都必須產生頂端的 10010個結果。然后請求節點排序這50050個結果并丟棄50040個!
你可以看到在分布式系統中,排序結果的花費隨著分頁的深入而成倍增長。這也是為什么網絡搜索引擎中任何 語句不能返回多于1000個結果的原因。
映射
前面我們創建的索引以及插入數據,都是由Elasticsearch進行自動判斷類型,有些時候我們是需要進行明確字段類型的,否則,自動判斷的類型和實際需求是不相符的。
自動判斷的規則如下:
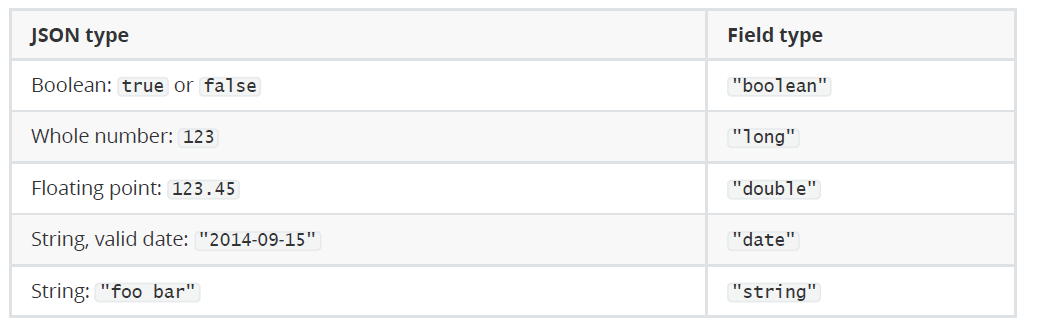
Elasticsearch中支持的類型如下:
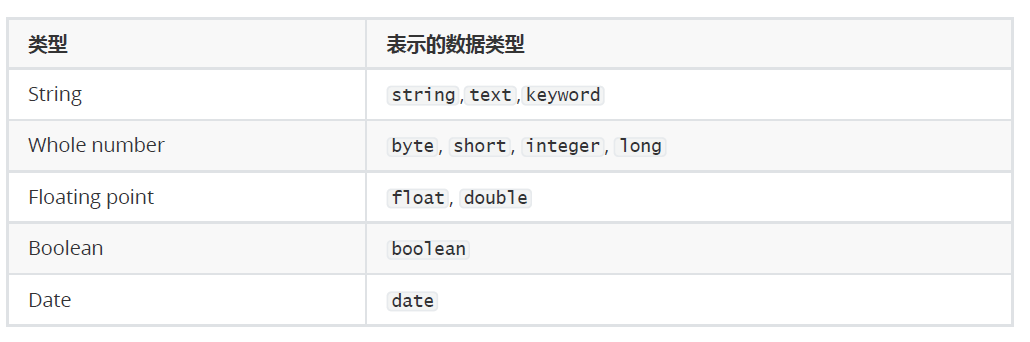
- string類型在ElasticSearch 舊版本中使用較多,從ElasticSearch 5.x開始不再支持string,由text和 keyword類型替代。
- text 類型,當一個字段是要被全文搜索的,比如Email內容、產品描述,應該使用text類型。設置text類型 以后,字段內容會被分析,在生成倒排索引以前,字符串會被分析器分成一個一個詞項。text類型的字段 不用于排序,很少用于聚合。
- keyword類型適用于索引結構化的字段,比如email地址、主機名、狀態碼和標簽。如果字段需要進行過 濾(比如查找已發布博客中status屬性為published的文章)、排序、聚合。keyword類型的字段只能通過精 確值搜索到。
創建明確類型的索引:
如果你要像之前舊版版本一樣兼容自定義 type ,需要將 include_type_name=true 攜帶
put http://202.193.56.222:9200/itcast?include_type_name=true
{"settings":{"index":{"number_of_shards":"2","number_of_replicas":"0"}},"mappings":{"person":{"properties":{"name":{"type":"text"},"age":{"type":"integer"},"mail":{"type":"keyword"},"hobby":{"type":"text"}}}}
}
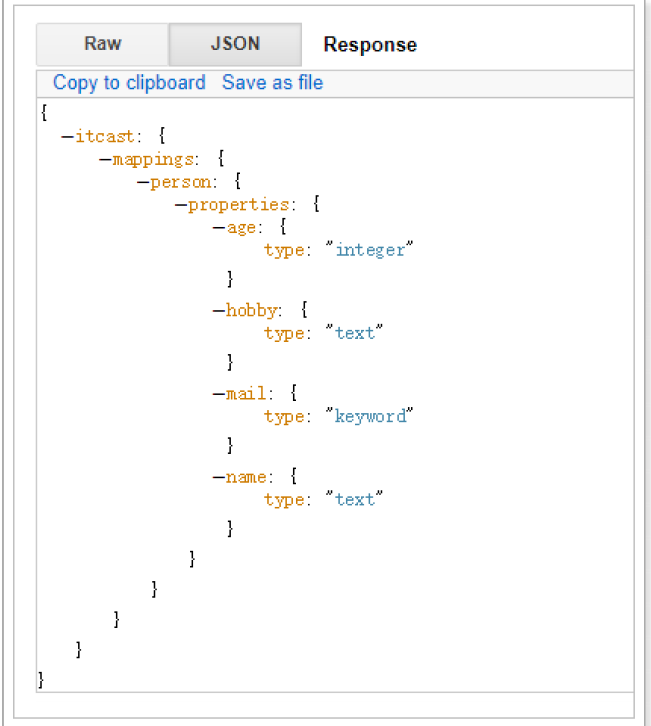
查看映射
GET /itcast/_mapping
插入數據
POST /itcast/_bulk
{"index":{"_index":"itcast","_type":"person"}}
{"name":"張三","age": 20,"mail": "111@qq.com","hobby":"羽毛球、乒乓球、足球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"李四","age": 21,"mail": "222@qq.com","hobby":"羽毛球、乒乓球、足球、籃球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"王五","age": 22,"mail": "333@qq.com","hobby":"羽毛球、籃球、游泳、聽音樂"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"趙六","age": 23,"mail": "444@qq.com","hobby":"跑步、游泳"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"孫七","age": 24,"mail": "555@qq.com","hobby":"聽音樂、看電影"}
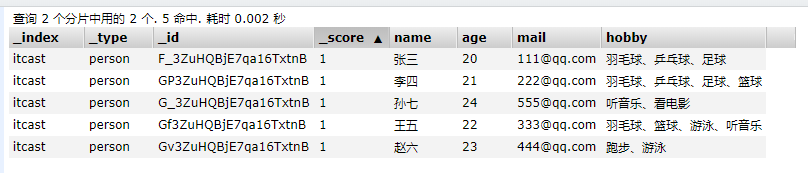
測試搜索
POST /itcast/person/_search
{"query":{"match":{"hobby":"音樂"}}
}
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-L5ioCs3J-1614908740773)(http://victorfengming.gitee.io/elk/1_ElasticSearch%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%89%E8%A3%85/images/image-20200923104653427.png)]
結構化查詢
term查詢
term 主要用于精確匹配哪些值,比如數字,日期,布爾值或 not_analyzed 的字符串(未經分析的文本數據類型):
{ "term": { "age": 26 }}
{ "term": { "date": "2014-09-01" }}
{ "term": { "public": true }}
{ "term": { "tag": "full_text" }}
示例
POST /itcast/person/_search
{"query":{"term":{"age":20}}
}

terms查詢
terms 跟 term 有點類似,但 terms 允許指定多個匹配條件。 如果某個字段指定了多個值,那么文檔需要一起去 做匹配:
{"terms":{"tag":["search","full_text","nosql"]}
}
示例:
POST /itcast/person/_search
{"query":{"terms":{"age":[20,21]}}
}

range查詢
range 過濾允許我們按照指定范圍查找一批數據:
{"range":{"age":{"gte":20,"lt":30}}
}
范圍操作符包含:
- gt : 大于
- gte:: 大于等于
- lt : 小于
- lte: 小于等于
示例:
POST /itcast/person/_search
{"query":{"range":{"age":{"gte":20,"lte":22}}}
}
exists 查詢
exists 查詢可以用于查找文檔中是否包含指定字段或沒有某個字段,類似于SQL語句中的IS_NULL 條件
{"exists": {"field": "title"}
}
這兩個查詢只是針對已經查出一批數據來,但是想區分出某個字段是否存在的時候使用。示例:
POST /haoke/user/_search
{"query": {"exists": { #必須包含"field": "card"}}
}

match查詢
match 查詢是一個標準查詢,不管你需要全文本查詢還是精確查詢基本上都要用到它。
如果你使用 match 查詢一個全文本字段,它會在真正查詢之前用分析器先分析match 一下查詢字符:
{"match": {"tweet": "About Search"}
}
如果用match 下指定了一個確切值,在遇到數字,日期,布爾值或者not_analyzed 的字符串時,它將為你搜索你 給定的值:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}
bool查詢
- bool 查詢可以用來合并多個條件查詢結果的布爾邏輯,它包含一下操作符:
- must :: 多個查詢條件的完全匹配,相當于 and 。
- must_not :: 多個查詢條件的相反匹配,相當于 not 。
- should :: 至少有一個查詢條件匹配, 相當于 or 。
這些參數可以分別繼承一個查詢條件或者一個查詢條件的數組:
{"bool":{"must":{"term":{"folder":"inbox"}},"must_not":{"term":{"tag":"spam"}},"should":[{"term":{"starred":true}},{"term":{"unread":true}}]}
}
過濾查詢
前面講過結構化查詢,Elasticsearch也支持過濾查詢,如term、range、match等。
示例:查詢年齡為20歲的用戶。
POST /itcast/person/_search
{"query":{"bool":{"filter":{"term":{"age":20}}}}
}
查詢和過濾的對比
- 一條過濾語句會詢問每個文檔的字段值是否包含著特定值。
- 查詢語句會詢問每個文檔的字段值與特定值的匹配程度如何。
- 一條查詢語句會計算每個文檔與查詢語句的相關性,會給出一個相關性評分 _score,并且 按照相關性對匹 配到的文檔進行排序。 這種評分方式非常適用于一個沒有完全配置結果的全文本搜索。
- 一個簡單的文檔列表,快速匹配運算并存入內存是十分方便的, 每個文檔僅需要1個字節。這些緩存的過濾結果集與后續請求的結合使用是非常高效的。
- 查詢語句不僅要查找相匹配的文檔,還需要計算每個文檔的相關性,所以一般來說查詢語句要比 過濾語句更耗時,并且查詢結果也不可緩存。
建議:
做精確匹配搜索時,最好用過濾語句,因為過濾語句可以緩存數據。
中文分詞
什么是分詞
分詞就是指將一個文本轉化成一系列單詞的過程,也叫文本分析,在Elasticsearch中稱之為Analysis。
舉例:我是中國人 --> 我/是/中國人
分詞api
指定分詞器進行分詞
POST /_analyze
{"analyzer":"standard","text":"hello world"
}
結果如下
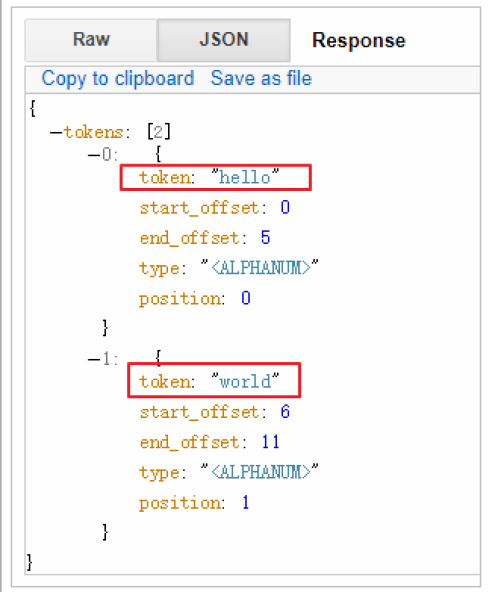
在結果中不僅可以看出分詞的結果,還返回了該詞在文本中的位置。
指定索引分詞
POST /itcast/_analyze
{"analyzer": "standard","field": "hobby","text": "聽音樂"
}

中文分詞難點
中文分詞的難點在于,在漢語中沒有明顯的詞匯分界點,如在英語中,空格可以作為分隔符,如果分隔不正確就會造成歧義。如:
- 我/愛/炒肉絲
- 我/愛/炒/肉絲
常用中文分詞器,IK、jieba、THULAC等,推薦使用IK分詞器。
IK Analyzer是一個開源的,基于java語言開發的輕量級的中文分詞工具包。從2006年12月推出1.0版開始,IKAnalyzer已經推出了3個大版本。最初,它是以開源項目Luence為應用主體的,結合詞典分詞和文法分析算法的中文分詞組件。新版本的IK Analyzer 3.0則發展為面向Java的公用分詞組件,獨立于Lucene項目,同時提供了對Lucene的默認優化實現。
采用了特有的“正向迭代最細粒度切分算法“,具有80萬字/秒的高速處理能力 采用了多子處理器分析模式,支持:英文字母(IP地址、Email、URL)、數字(日期,常用中文數量詞,羅馬數字,科學計數法),中文詞匯(姓名、地名處理)等分詞處理。 優化的詞典存儲,更小的內存占用。
IK分詞器 Elasticsearch插件地址:https://github.com/medcl/elasticsearch-analysis-ik
安裝分詞器
首先下載到最新的ik分詞器:下載地址
下載完成后,使用xftp工具,拷貝到服務器上
#安裝方法:將下載到的 es/plugins/ik 目錄下
mkdir es/plugins/ik#解壓
unzip elasticsearch-analysis-ik-7.9.1.zip#重啟
./bin/elasticsearch
我們通過日志,發現它已經成功加載了ik分詞器插件

測試
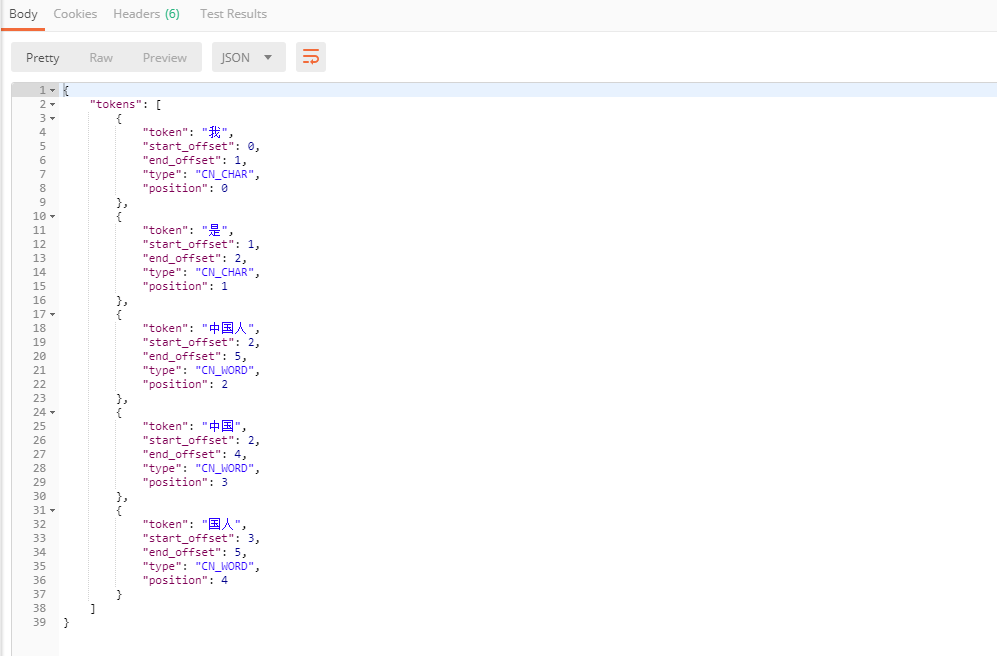
POST /_analyze
{"analyzer": "ik_max_word","text": "我是中國人"
}
我們發現ik分詞器已經成功分詞完成
全文搜索
全文搜索兩個最重要的方面是:
- 相關性(Relevance) 它是評價查詢與其結果間的相關程度,并根據這種相關程度對結果排名的一種能力,這 種計算方式可以是 TF/IDF 方法、地理位置鄰近、模糊相似,或其他的某些算法。
- 分詞(Analysis) 它是將文本塊轉換為有區別的、規范化的 token 的一個過程,目的是為了創建倒排索引以及查詢倒排索引。
構造數據
ES 7.4 默認不在支持指定索引類型,默認索引類型是_doc
http://202.193.56.222:9200/itcast?include_type_name=true
{"settings":{"index":{"number_of_shards":"1","number_of_replicas":"0"}},"mappings":{"person":{"properties":{"name":{"type":"text"},"age":{"type":"integer"},"mail":{"type":"keyword"},"hobby":{"type":"text","analyzer":"ik_max_word"}}}}
}
然后插入數據
POST http://202.193.56.222:9200/itcast/_bulk
{"index":{"_index":"itcast","_type":"person"}}
{"name":"張三","age": 20,"mail": "111@qq.com","hobby":"羽毛球、乒乓球、足球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"李四","age": 21,"mail": "222@qq.com","hobby":"羽毛球、乒乓球、足球、籃球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"王五","age": 22,"mail": "333@qq.com","hobby":"羽毛球、籃球、游泳、聽音樂"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"趙六","age": 23,"mail": "444@qq.com","hobby":"跑步、游泳、籃球"}
{"index":{"_index":"itcast","_type":"person"}}
{"name":"孫七","age": 24,"mail": "555@qq.com","hobby":"聽音樂、看電影、羽毛球"}
單詞搜索
POST /itcast/person/_search
{"query":{"match":{"hobby":"音樂"}},"highlight":{"fields":{"hobby":{}}}
}
查詢出來的結果如下,并且還帶有高亮
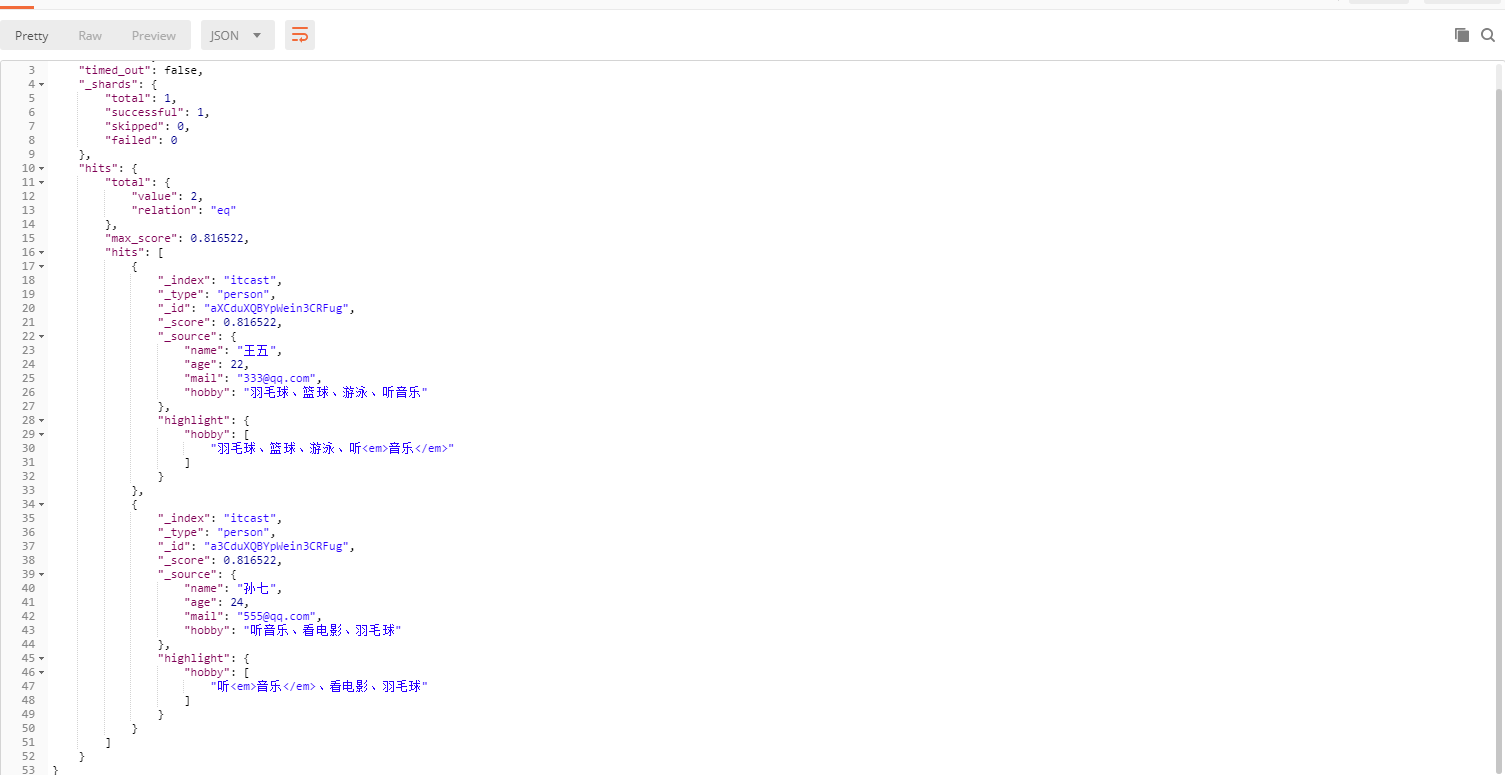
過程說明:
- 檢查字段類型
- 愛好 hobby 字段是一個 text 類型( 指定了IK分詞器),這意味著查詢字符串本身也應該被分詞。
- 分析查詢字符串 。
- 將查詢的字符串 “音樂” 傳入IK分詞器中,輸出的結果是單個項 音樂。因為只有一個單詞項,所以 match 查詢執行的是單個底層 term 查詢。
- 查找匹配文檔 。
- 用 term 查詢在倒排索引中查找 “音樂” 然后獲取一組包含該項的文檔,本例的結果是文檔:3 、5 。
- 為每個文檔評分 。
- 用 term 查詢計算每個文檔相關度評分 _score ,這是種將 詞頻(term frequency,即詞 “音樂” 在相關文檔的hobby 字段中出現的頻率)和 反向文檔頻率(inverse document frequency,即詞 “音樂” 在所有文檔的hobby 字段中出現的頻率),以及字段的長度(即字段越短相關度越高)相結合的計算方式。
多詞搜索
POST /itcast/person/_search
{"query":{"match":{"hobby":"音樂 籃球"}},"highlight":{"fields":{"hobby":{}}}
}
可以看到,包含了“音樂”、“籃球”的數據都已經被搜索到了。可是,搜索的結果并不符合我們的預期,因為我們想搜索的是既包含“音樂”又包含“籃球”的用戶,顯然結果返回的“或”的關系。在Elasticsearch中,可以指定詞之間的邏輯關系,如下:
POST /itcast/person/_search
{"query":{"match":{"hobby":"音樂 籃球""operator":"and"}},"highlight":{"fields":{"hobby":{}}}
}
通過這樣的話,就會讓兩個關鍵字之間存在and關系了
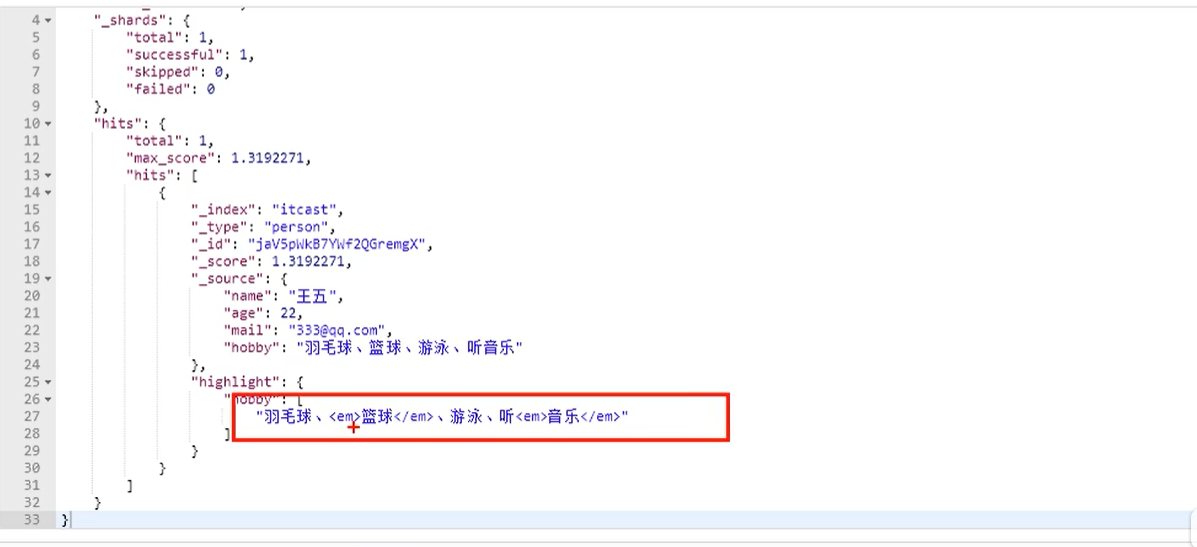
可以看到結果符合預期。
前面我們測試了“OR” 和 “AND”搜索,這是兩個極端,其實在實際場景中,并不會選取這2個極端,更有可能是選取這種,或者說,只需要符合一定的相似度就可以查詢到數據,在Elasticsearch中也支持這樣的查詢,通過 minimum_should_match來指定匹配度,如:70%;
示例:
{"query":{"match":{"hobby":{"query":"游泳 羽毛球","minimum_should_match":"80%"}}},"highlight": {"fields": {"hobby": {}}}
}
#結果:省略顯示
"hits": {
"total": 4, #相似度為80%的情況下,查詢到4條數據
"max_score": 1.621458,
"hits": [}
#設置40%進行測試:
{"query":{"match":{"hobby":{"query":"游泳 羽毛球","minimum_should_match":"40%"}}},"highlight": {"fields": {"hobby": {}}}
}#結果:
"hits": {
"total": 5, #相似度為40%的情況下,查詢到5條數據
"max_score": 1.621458,
"hits": [}
相似度應該多少合適,需要在實際的需求中進行反復測試,才可得到合理的值。
組合搜索
在搜索時,也可以使用過濾器中講過的bool組合查詢,示例:
POST /itcast/person/_search
{"query":{"bool":{"must":{"match":{"hobby":"籃球"}},"must_not":{"match":{"hobby":"音樂"}},"should":[{"match":{"hobby":"游泳"}}]}},"highlight":{"fields":{"hobby":{}}}
}
上面搜索的意思是: 搜索結果中必須包含籃球,不能包含音樂,如果包含了游泳,那么它的相似度更高。
結果:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-sBVqSAwi-1614908740790)(http://victorfengming.gitee.io/elk/1_ElasticSearch%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%89%E8%A3%85/images/image-20200923145310698.png)]
評分的計算規則
bool 查詢會為每個文檔計算相關度評分 _score , 再將所有匹配的 must 和 should 語句的分數 _score 求和,最后除以 must 和 should 語句的總數。
must_not 語句不會影響評分; 它的作用只是將不相關的文檔排除。
默認情況下,should中的內容不是必須匹配的,如果查詢語句中沒有must,那么就會至少匹配其中一個。當然了,也可以通過minimum_should_match參數進行控制,該值可以是數字也可以的百分比。
示例:
POST /itcast/person/_search
{"query":{"bool":{"should":[{"match":{"hobby":"游泳"}},{"match":{"hobby":"籃球"}},{"match":{"hobby":"音樂"}}],"minimum_should_match":2}},"highlight":{"fields":{"hobby":{}}}
}
minimum_should_match為2,意思是should中的三個詞,至少要滿足2個。
權重
有些時候,我們可能需要對某些詞增加權重來影響該條數據的得分。如下:
搜索關鍵字為“游泳籃球”,如果結果中包含了“音樂”權重為10,包含了“跑步”權重為2。
POST /itcast/person/_search
{"query":{"bool":{"must":{"match":{"hobby":{"query":"游泳籃球","operator":"and"}}},"should":[{"match":{"hobby":{"query":"音樂","boost":10}}},{"match":{"hobby":{"query":"跑步","boost":2}}}]}},"highlight":{"fields":{"hobby":{}}}
}
ElasticSearch集群
集群節點
ELasticsearch的集群是由多個節點組成的,通過cluster.name設置集群名稱,并且用于區分其它的集群,每個節點通過node.name指定節點的名稱。
在Elasticsearch中,節點的類型主要有4種:
- master節點
- 配置文件中node.master屬性為true(默認為true),就有資格被選為master節點。master節點用于控制整個集群的操作。比如創建或刪除索引,管理其它非master節點等。
- data節點
- 配置文件中node.data屬性為true(默認為true),就有資格被設置成data節點。data節點主要用于執行數據相關的操作。比如文檔的CRUD。
- 客戶端節點
- 配置文件中node.master屬性和node.data屬性均為false。
- 該節點不能作為master節點,也不能作為data節點。
- 可以作為客戶端節點,用于響應用戶的請求,把請求轉發到其他節點
- 部落節點
- 當一個節點配置tribe.*的時候,它是一個特殊的客戶端,它可以連接多個集群,在所有連接的集群上執行 搜索和其他操作。
搭建集群
#啟動3個虛擬機,分別在3臺虛擬機上部署安裝Elasticsearch
mkdir /itcast/es-cluster#分發到其它機器
scp -r es-cluster elsearch@192.168.40.134:/itcast#node01的配置:
cluster.name: es-itcast-cluster
node.name: node01
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.40.133","192.168.40.134","192.168.40.135"]
# 最小節點數
discovery.zen.minimum_master_nodes: 2
# 跨域專用
http.cors.enabled: true
http.cors.allow-origin: "*"#node02的配置:
cluster.name: es-itcast-cluster
node.name: node02
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.40.133","192.168.40.134","192.168.40.135"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"#node03的配置:
cluster.name: es-itcast-cluster
node.name: node02
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.40.133","192.168.40.134","192.168.40.135"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"#分別啟動3個節點
./elasticsearch
查看集群
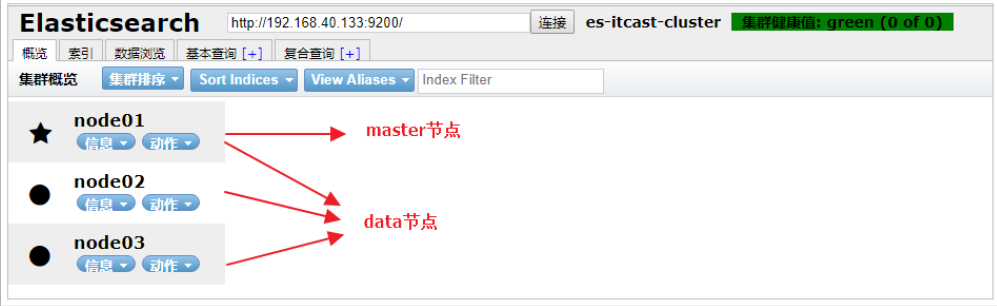
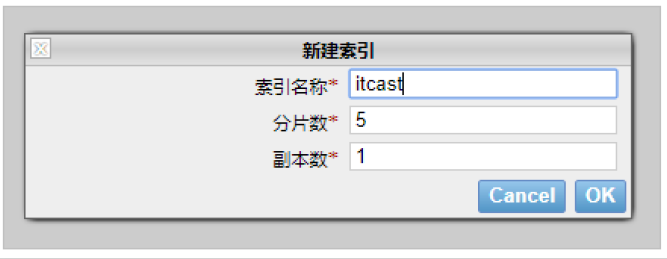
創建索引:
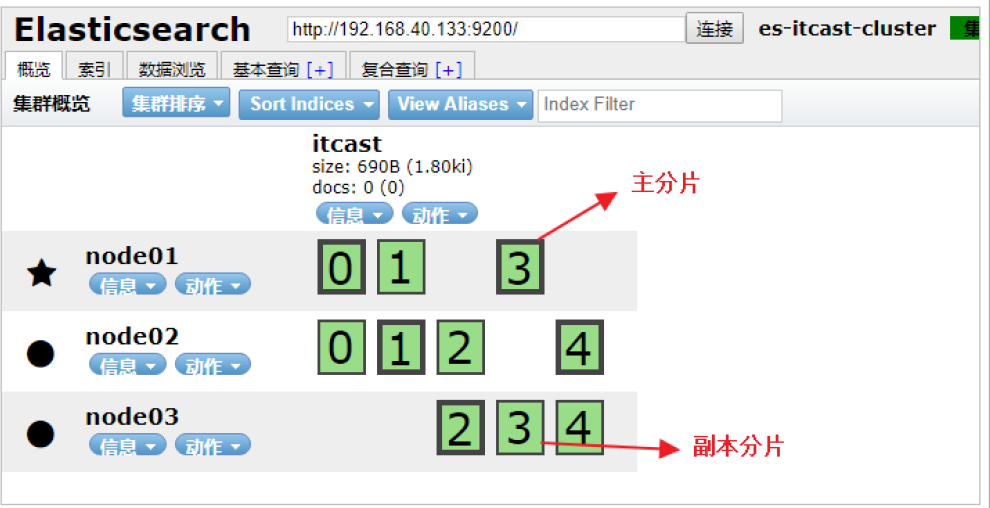
查詢集群狀態:/_cluster/health 響應:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-UE1MJuLz-1614908740798)(http://victorfengming.gitee.io/elk/1_ElasticSearch%E4%BB%8B%E7%BB%8D%E4%B8%8E%E5%AE%89%E8%A3%85/images/image-20200923151953227.png)]
集群中有三種顏色

分片和副本
為了將數據添加到Elasticsearch,我們需要索引(index)——一個存儲關聯數據的地方。實際上,索引只是一個用來指向一個或多個分片(shards)的“邏輯命名空間(logical namespace)”.
- 一個分片(shard)是一個最小級別“工作單元(worker unit)”,它只是保存了索引中所有數據的一部分。
- 我們需要知道是分片就是一個Lucene實例,并且它本身就是一個完整的搜索引擎。應用程序不會和它直接通 信。
- 分片可以是主分片(primary shard)或者是復制分片(replica shard)。
- 索引中的每個文檔屬于一個單獨的主分片,所以主分片的數量決定了索引最多能存儲多少數據。
- 復制分片只是主分片的一個副本,它可以防止硬件故障導致的數據丟失,同時可以提供讀請求,比如搜索或者從別的shard取回文檔。
- 當索引創建完成的時候,主分片的數量就固定了,但是復制分片的數量可以隨時調整。
故障轉移
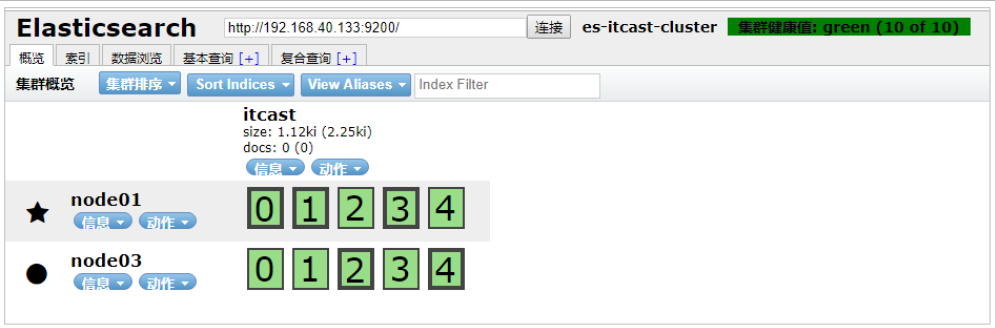
將data節點停止
這里選擇將node02停止:
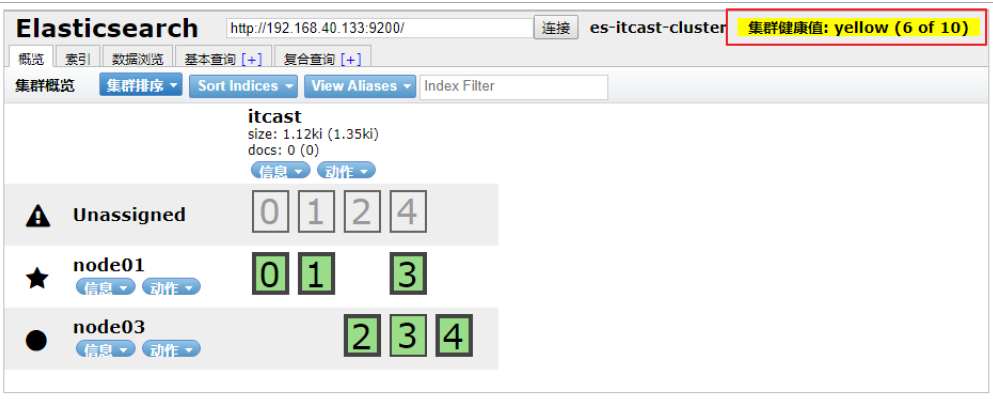
當前集群狀態為黃色,表示主節點可用,副本節點不完全可用,過一段時間觀察,發現節點列表中看不到node02,副本節點分配到了node01和node03,集群狀態恢復到綠色。
將node02恢復: ./node02/1 bin/elasticsearch
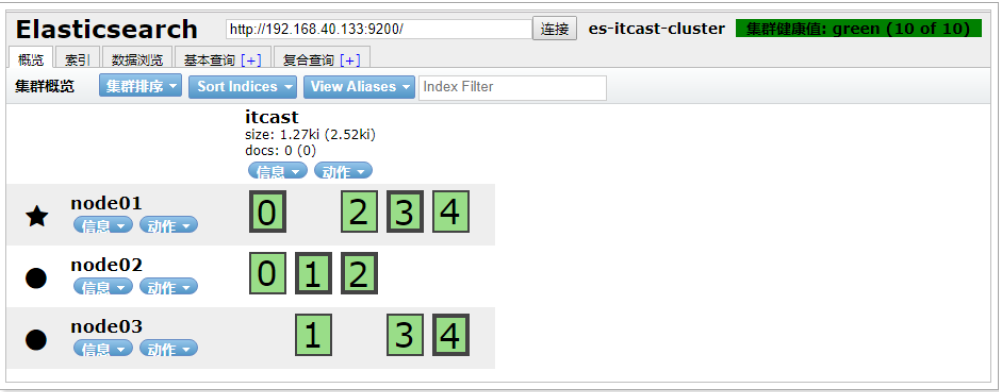
可以看到,node02恢復后,重新加入了集群,并且重新分配了節點信息。
將master節點停止
接下來,測試將node01停止,也就是將主節點停止。
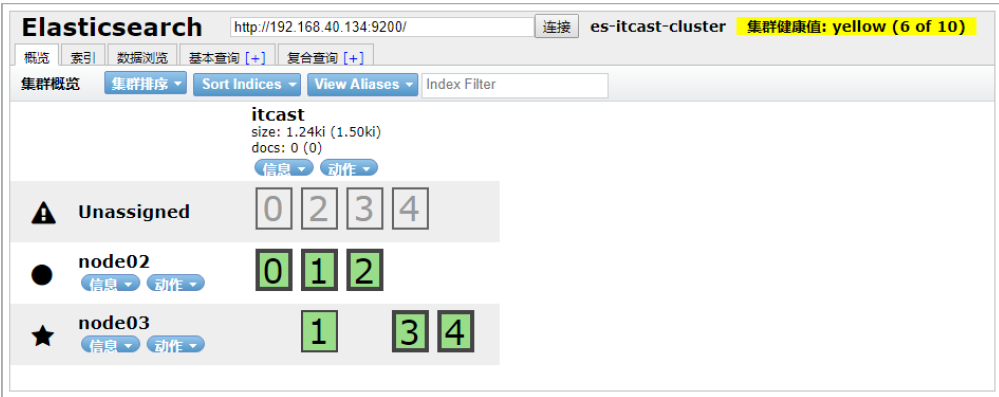
從結果中可以看出,集群對master進行了重新選舉,選擇node03為master。并且集群狀態變成黃色。 等待一段時間后,集群狀態從黃色變為了綠色:
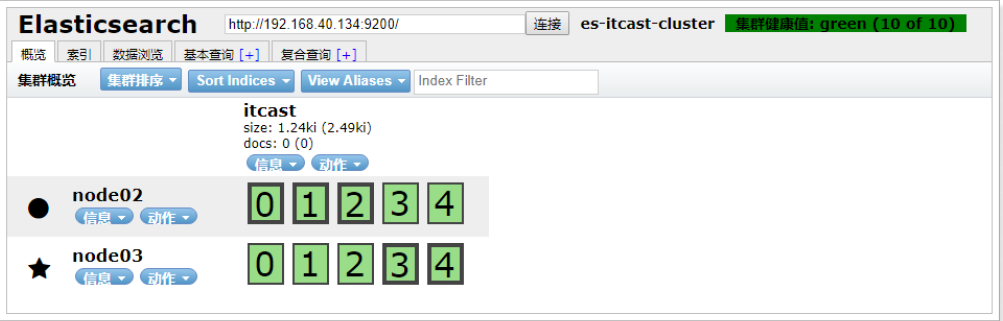
恢復node01節點:
./node01/1 bin/elasticsearch
重啟之后,發現node01可以正常加入到集群中,集群狀態依然為綠色:
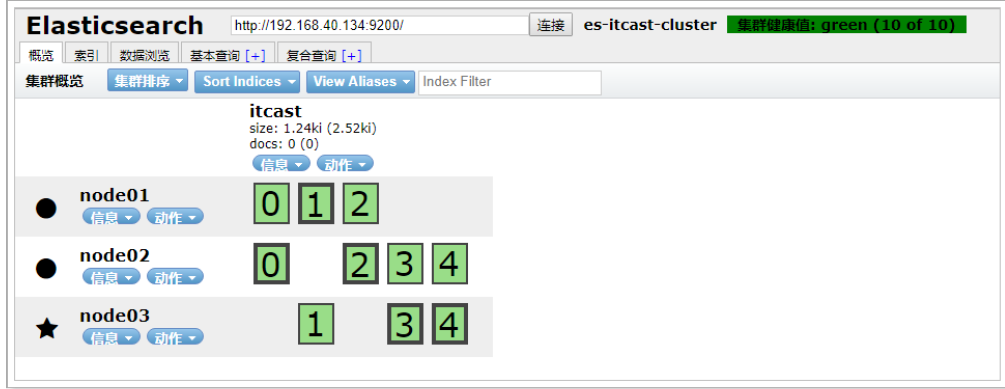
特別說明:
如果在配置文件中discovery.zen.minimum_master_nodes設置的不是N/2+1時,會出現腦裂問題,之前宕機 的主節點恢復后不會加入到集群。

分布式文檔
路由
首先,來看個問題:
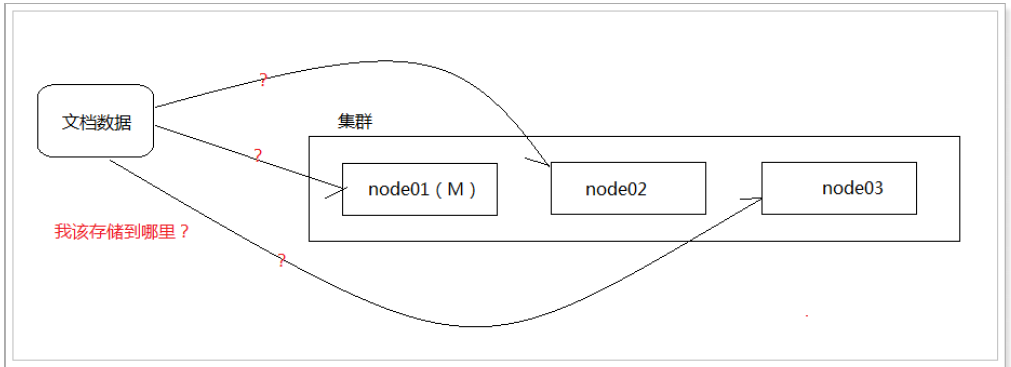
如圖所示:當我們想一個集群保存文檔時,文檔該存儲到哪個節點呢? 是隨機嗎? 是輪詢嗎?實際上,在ELasticsearch中,會采用計算的方式來確定存儲到哪個節點,計算公式如下:
shard = hash(routing) % number_1 of_primary_shards
其中:
- routing值是一個任意字符串,它默認是_id但也可以自定義。
- 這個routing字符串通過哈希函數生成一個數字,然后除以主切片的數量得到一個余數(remainder),余數 的范圍永遠是0到number_of_primary_shards - 1,這個數字就是特定文檔所在的分片
這就是為什么創建了主分片后,不能修改的原因。
文檔的寫操作
新建、索引和刪除請求都是寫(write)操作,它們必須在主分片上成功完成才能復制分片上
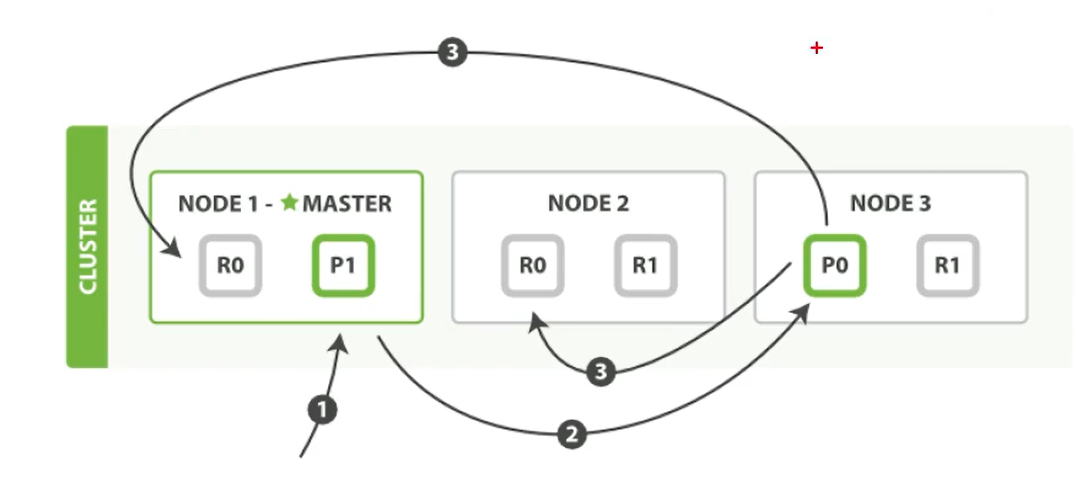
下面我們羅列在主分片和復制分片上成功新建、索引或刪除一個文檔必要的順序步驟:
- 客戶端給Node 1 發送新建、索引或刪除請求。
- 節點使用文檔的_id 確定文檔屬于分片0 。它轉發請求到Node 3 ,分片0 位于這個節點上。
- Node 3 在主分片上執行請求,如果成功,它轉發請求到相應的位于Node 1 和Node 2 的復制節點上。當所有 的復制節點報告成功, Node 3 報告成功到請求的節點,請求的節點再報告給客戶端。
客戶端接收到成功響應的時候,文檔的修改已經被應用于主分片和所有的復制分片。你的修改生效了。
搜索文檔
文檔能夠從主分片或任意一個復制分片被檢索。
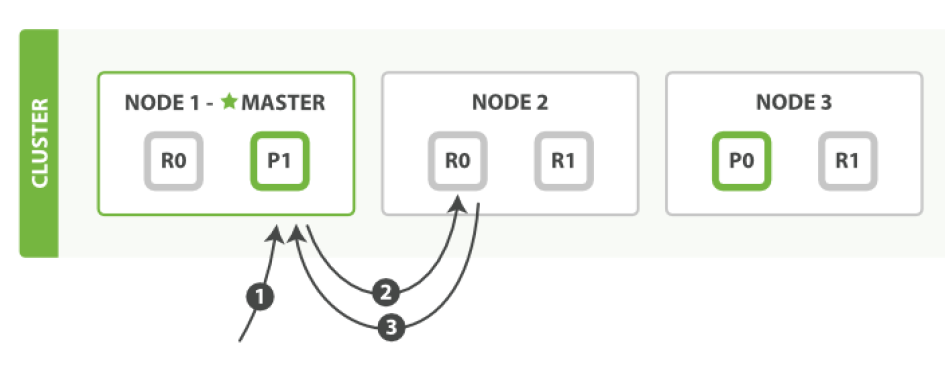
下面我們羅列在主分片或復制分片上檢索一個文檔必要的順序步驟:
- 客戶端給Node 1 發送get請求。
- 節點使用文檔的_id 確定文檔屬于分片0 。分片0 對應的復制分片在三個節點上都有。此時,它轉發請求到 Node 2 。
- Node 2 返回文檔(document)給Node 1 然后返回給客戶端。對于讀請求,為了平衡負載,請求節點會為每個請求選擇不同的分片——它會循環所有分片副本。可能的情況是,一個被索引的文檔已經存在于主分片上卻還沒來得及同步到復制分片上。這時復制分片會報告文檔未找到,主分片會成功返回文檔。一旦索引請求成功返回給用戶,文檔則在主分片和復制分片都是可用的。
全文搜索
對于全文搜索而言,文檔可能分散在各個節點上,那么在分布式的情況下,如何搜索文檔呢?
搜索,分為2個階段,
- 搜索(query)
- 取回(fetch)
搜索(query)
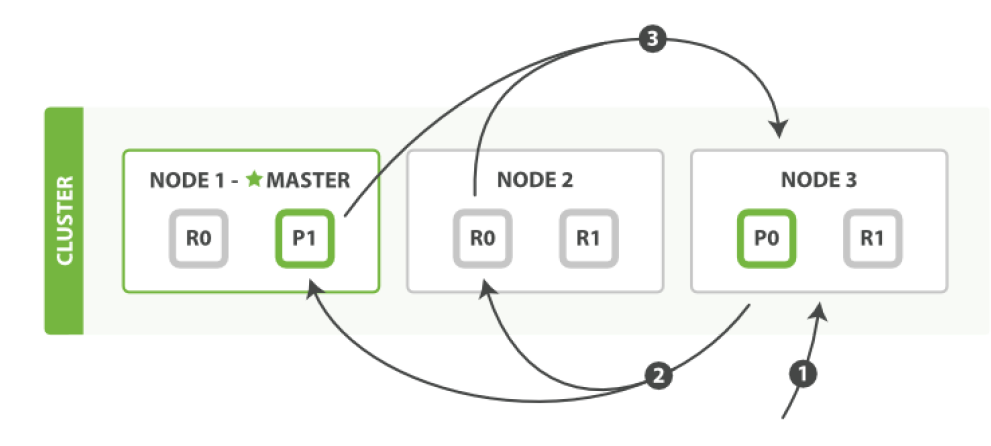
查詢階段包含以下三步:
- 客戶端發送一個search(搜索) 請求給Node 3 , Node 3 創建了一個長度為from+size 的空優先級隊
- Node 3 轉發這個搜索請求到索引中每個分片的原本或副本。每個分片在本地執行這個查詢并且結果將結果到 一個大小為from+size 的有序本地優先隊列里去。
- 每個分片返回document的ID和它優先隊列里的所有document的排序值給協調節點Node 3 。Node 3 把這些 值合并到自己的優先隊列里產生全局排序結果。
取回 fetch
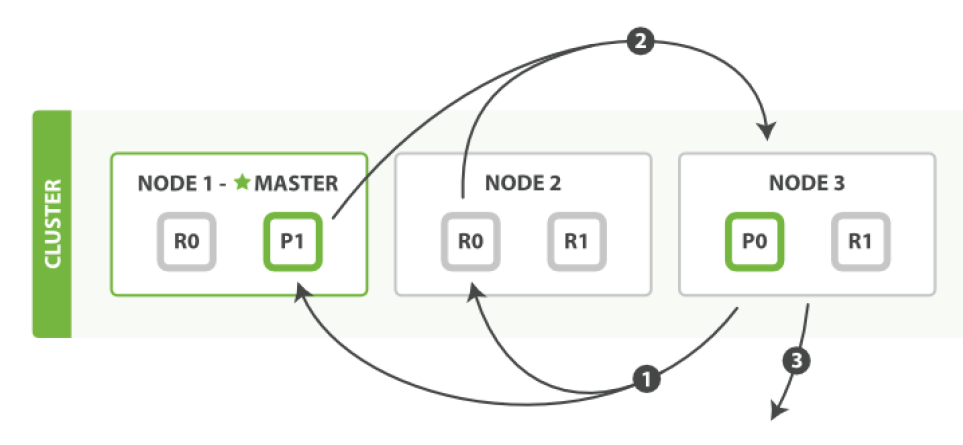
分發階段由以下步驟構成:
- 協調節點辨別出哪個document需要取回,并且向相關分片發出GET 請求。
- 每個分片加載document并且根據需要豐富(enrich)它們,然后再將document返回協調節點。
- 一旦所有的document都被取回,協調節點會將結果返回給客戶端。
Java客戶端
在Elasticsearch中,為java提供了2種客戶端,一種是REST風格的客戶端,另一種是Java API的客戶端
REST客戶端
Elasticsearch提供了2種REST客戶端,一種是低級客戶端,一種是高級客戶端。
- Java Low Level REST Client:官方提供的低級客戶端。該客戶端通過http來連接Elasticsearch集群。用戶在使 用該客戶端時需要將請求數據手動拼接成Elasticsearch所需JSON格式進行發送,收到響應時同樣也需要將返回的JSON數據手動封裝成對象。雖然麻煩,不過該客戶端兼容所有的Elasticsearch版本。
- Java High Level REST Client:官方提供的高級客戶端。該客戶端基于低級客戶端實現,它提供了很多便捷的 API來解決低級客戶端需要手動轉換數據格式的問題。
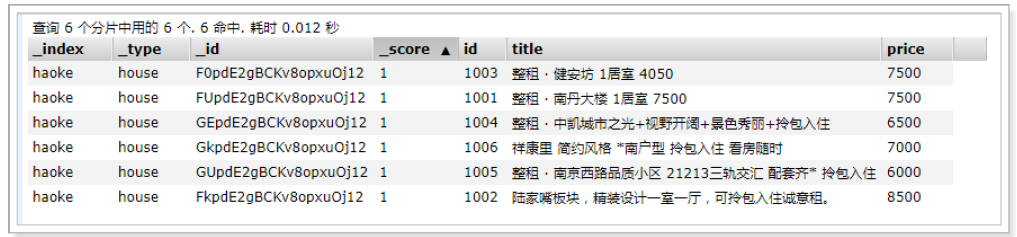
構造數據
POST /haoke/house/_bulk{"index":{"_index":"haoke","_type":"house"}}
{"id":"1001","title":"整租 · 南丹大樓 1居室 7500","price":"7500"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1002","title":"陸家嘴板塊,精裝設計一室一廳,可拎包入住誠意租。","price":"8500"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1003","title":"整租 · 健安坊 1居室 4050","price":"7500"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1004","title":"整租 · 中凱城市之光+視野開闊+景色秀麗+拎包入住","price":"6500"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1005","title":"整租 · 南京西路品質小區 21213三軌交匯 配套齊* 拎包入住","price":"6000"}
{"index":{"_index":"haoke","_type":"house"}}
{"id":"1006","title":"祥康里 簡約風格 *南戶型 拎包入住 看房隨時","price":"7000"}
REST低級客戶端
創建項目,加入依賴
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>Study_ElasticSearch_Code</artifactId><version>1.0-SNAPSHOT</version><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><configuration><source>7</source><target>7</target></configuration></plugin></plugins></build><dependencies><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>6.8.5</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version><scope>test</scope></dependency><dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.11.1</version></dependency></dependencies>
</project>
編寫測試類
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.HttpHost;
import org.apache.http.util.EntityUtils;
import org.elasticsearch.client.Request;
import org.elasticsearch.client.Response;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;import java.io.IOException;
import java.util.HashMap;
import java.util.Map;/*** 使用低級客戶端 訪問** @author: 陌溪* @create: 2020-09-23-16:33*/
public class ESApi {private RestClient restClient;private static final ObjectMapper MAPPER = new ObjectMapper();/*** 初始化*/public void init() {RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost("202.193.56.222", 9200, "http"));this.restClient = restClientBuilder.build();}/*** 查詢集群狀態*/public void testGetInfo() throws IOException {Request request = new Request("GET", "/_cluster/state");request.addParameter("pretty", "true");Response response = this.restClient.performRequest(request);System.out.println(response.getStatusLine());System.out.println(EntityUtils.toString(response.getEntity()));}/*** 根據ID查詢數據* @throws IOException*/public void testGetHouseInfo() throws IOException {Request request = new Request("GET", "/haoke/house/Z3CduXQBYpWein3CRFug");request.addParameter("pretty", "true");Response response = this.restClient.performRequest(request);System.out.println(response.getStatusLine());System.out.println(EntityUtils.toString(response.getEntity()));}public void testCreateData() throws IOException {Request request = new Request("POST", "/haoke/house");Map<String, Object> data = new HashMap<>();data.put("id", "2001");data.put("title", "張江高科");data.put("price", "3500");// 寫成JSONrequest.setJsonEntity(MAPPER.writeValueAsString(data));Response response = this.restClient.performRequest(request);System.out.println(response.getStatusLine());System.out.println(EntityUtils.toString(response.getEntity()));}// 搜索數據public void testSearchData() throws IOException {Request request = new Request("POST", "/haoke/house/_search");String searchJson = "{\"query\": {\"match\": {\"title\": \"拎包入住\"}}}";request.setJsonEntity(searchJson);request.addParameter("pretty","true");Response response = this.restClient.performRequest(request);System.out.println(response.getStatusLine());System.out.println(EntityUtils.toString(response.getEntity()));}public static void main(String[] args) throws IOException {ESApi esApi = new ESApi();esApi.init();
// esApi.testGetInfo();
// esApi.testGetHouseInfo();esApi.testCreateData();}
}
REST高級客戶端
創建項目,引入依賴
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>6.8.5</version>
</dependency>
編寫測試用例
import com.fasterxml.jackson.databind.ObjectMapper;
import org.apache.http.HttpHost;
import org.apache.http.util.EntityUtils;
import org.elasticsearch.action.ActionListener;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.*;
import org.elasticsearch.common.Strings;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;/*** ES高級客戶端** @author: 陌溪* @create: 2020-09-23-16:56*/
public class ESHightApi {private RestHighLevelClient client;public void init() {RestClientBuilder restClientBuilder = RestClient.builder(new HttpHost("202.193.56.222", 9200, "http"));this.client = new RestHighLevelClient(restClientBuilder);}public void after() throws Exception {this.client.close();}/*** 新增文檔,同步操作** @throws Exception*/public void testCreate() throws Exception {Map<String, Object> data = new HashMap<>();data.put("id", "2002");data.put("title", "南京西路 拎包入住 一室一廳");data.put("price", "4500");IndexRequest indexRequest = new IndexRequest("haoke", "house").source(data);IndexResponse indexResponse = this.client.index(indexRequest,RequestOptions.DEFAULT);System.out.println("id->" + indexResponse.getId());System.out.println("index->" + indexResponse.getIndex());System.out.println("type->" + indexResponse.getType());System.out.println("version->" + indexResponse.getVersion());System.out.println("result->" + indexResponse.getResult());System.out.println("shardInfo->" + indexResponse.getShardInfo());}/*** 異步創建文檔* @throws Exception*/public void testCreateAsync() throws Exception {Map<String, Object> data = new HashMap<>();data.put("id", "2003");data.put("title", "南京東路 最新房源 二室一廳");data.put("price", "5500");IndexRequest indexRequest = new IndexRequest("haoke", "house").source(data);this.client.indexAsync(indexRequest, RequestOptions.DEFAULT, newActionListener<IndexResponse>() {@Overridepublic void onResponse(IndexResponse indexResponse) {System.out.println("id->" + indexResponse.getId());System.out.println("index->" + indexResponse.getIndex());System.out.println("type->" + indexResponse.getType());System.out.println("version->" + indexResponse.getVersion());System.out.println("result->" + indexResponse.getResult());System.out.println("shardInfo->" + indexResponse.getShardInfo());}@Overridepublic void onFailure(Exception e) {System.out.println(e);}});System.out.println("ok");Thread.sleep(20000);}/*** 查詢* @throws Exception*/public void testQuery() throws Exception {GetRequest getRequest = new GetRequest("haoke", "house","GkpdE2gBCKv8opxuOj12");// 指定返回的字段String[] includes = new String[]{"title", "id"};String[] excludes = Strings.EMPTY_ARRAY;FetchSourceContext fetchSourceContext =new FetchSourceContext(true, includes, excludes);getRequest.fetchSourceContext(fetchSourceContext);GetResponse response = this.client.get(getRequest, RequestOptions.DEFAULT);System.out.println("數據 -> " + response.getSource());}/*** 判斷是否存在** @throws Exception*/public void testExists() throws Exception {GetRequest getRequest = new GetRequest("haoke", "house","GkpdE2gBCKv8opxuOj12");
// 不返回的字段getRequest.fetchSourceContext(new FetchSourceContext(false));boolean exists = this.client.exists(getRequest, RequestOptions.DEFAULT);System.out.println("exists -> " + exists);}/*** 刪除數據** @throws Exception*/public void testDelete() throws Exception {DeleteRequest deleteRequest = new DeleteRequest("haoke", "house","GkpdE2gBCKv8opxuOj12");DeleteResponse response = this.client.delete(deleteRequest,RequestOptions.DEFAULT);System.out.println(response.status());// OK or NOT_FOUND}/*** 更新數據** @throws Exception*/public void testUpdate() throws Exception {UpdateRequest updateRequest = new UpdateRequest("haoke", "house","G0pfE2gBCKv8opxuRz1y");Map<String, Object> data = new HashMap<>();data.put("title", "張江高科2");data.put("price", "5000");updateRequest.doc(data);UpdateResponse response = this.client.update(updateRequest,RequestOptions.DEFAULT);System.out.println("version -> " + response.getVersion());}/*** 測試搜索** @throws Exception*/public void testSearch() throws Exception {SearchRequest searchRequest = new SearchRequest("haoke");searchRequest.types("house");SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.query(QueryBuilders.matchQuery("title", "拎包入住"));sourceBuilder.from(0);sourceBuilder.size(5);sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));searchRequest.source(sourceBuilder);SearchResponse search = this.client.search(searchRequest,RequestOptions.DEFAULT);System.out.println("搜索到 " + search.getHits().totalHits + " 條數據.");SearchHits hits = search.getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}}public static void main(String[] args) throws Exception {ESHightApi esHightApi = new ESHightApi();esHightApi.init();esHightApi.testCreate();}
}
)


















