前言:在利用機器學習方法進行數據分析時經常要了解變量的相關性,有時還需要對變量進行回歸分析。本文首先對人工智能/機器學習/深度學習、相關分析/因果分析/回歸分析等易混淆的概念進行區分,最后結合案例介紹如何利用Python進行簡單線性回歸分析。
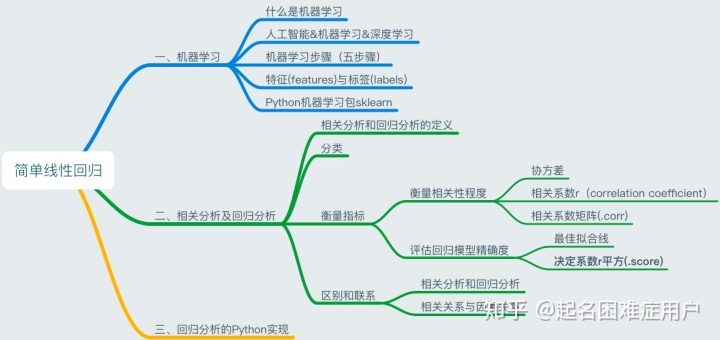
一、機器學習
1.1什么是機器學習
談到機器學習,人們會很容易聯想到人工智能和深度學習,我們通過這三個概念的對比來說明三者的區別和聯系。
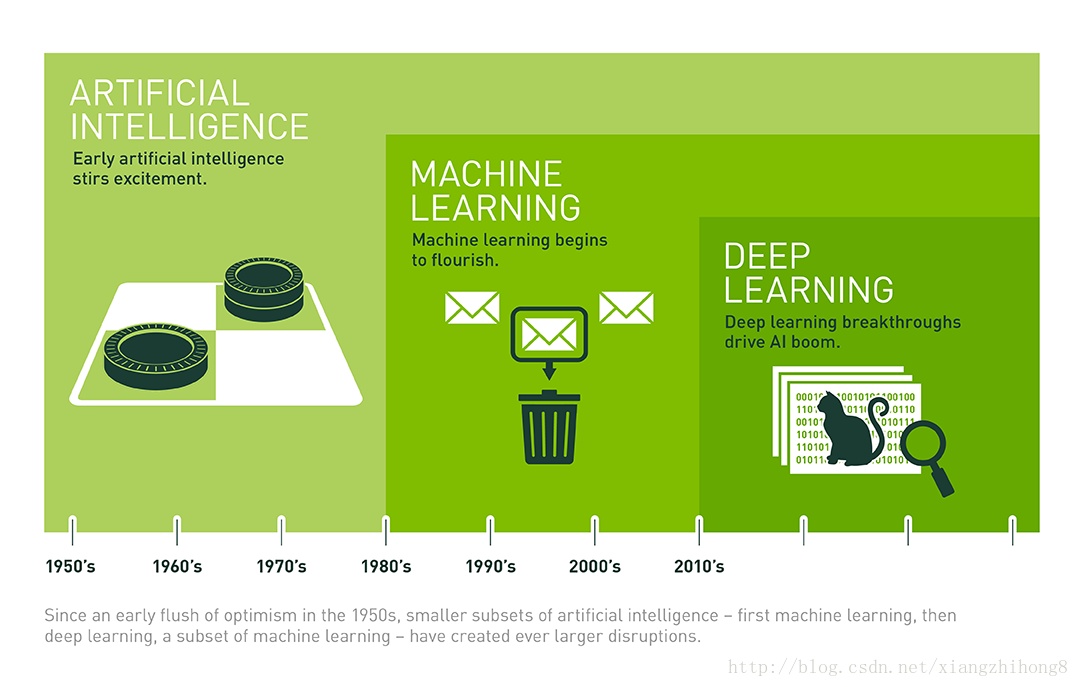
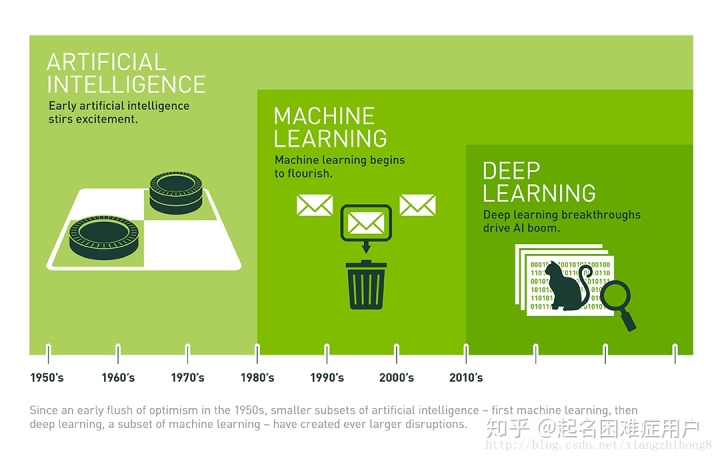
人工智能Artificial Inteligence:這個概念早在1956年就被提出,當時科學家夢想著用當時剛剛出現的計算機來構造復雜的、擁有像人類智慧特性的機器。目前,AI的分支很多,諸如專家系統、機器學習、自然語言處理以及推薦系統等。
機器學習Mechine Learning:機器學習是實現人工智能的一種方法,是使用算法解析數據、并從中學習,然后對真實世界中事件作出決策或預測。機器學習是通過大量數據來“訓練”算法模型,利用算法從數據中學習如何完成任務。學習方法可以分為:監督學習(如分類)、無監督學習(如聚類)等。(下面介紹一些基礎概念)
- 學習(learning):是指找到特征(feature)和標簽(label)的映射(mapping)關系。
- 有監督學習(supervised learning):不僅將訓練數據(特征)丟給計算機,還把分類的結果(數據具有的標簽)也一并丟給計算機分析,如分類和回歸;
- 無監督學習(unsupervised learning):只提供訓練數據(特征),不給結果(標簽),計算機只能利用其計算能力分析數據的特征,然后得到一些數據集合,集合內的數據在某些特征上相同或相似,如聚類分析;
- 半監督學習(semi-supervised learning):給計算機大量訓練數據與少量分類結果(具有同一標簽的集合)。
- 聚類(clustering):無監督學習的結果,聚類的結果將產生若干組集合,同集合中對象彼此相似,與其他集合中對象相異。
- 分類(classification)與回歸(regression):有監督學習的兩大應用,其區別在于分別產生離散或連續的結果(分類及回歸方法的區別在下文中有較詳細分析)。
深度學習Deep Learning:深度學習是機器學習的一種方法,其本身會用到有監督和無監督的學習方法來訓練深度神經網絡。
1.2機器學習的步驟
利用機器學習方法分析、解決問題的過程可分為五個步驟:

1.提出問題
明確要分析的問題,為后續的機器學習過程提供目標。
2.理解數據(采集并查看數據)
采集數據(根據研究問題采集數據);導入數據(從不同數據源讀取數據);查看數據信息(描述統計信息、數據缺失值、異常值情況等,可以結合具體圖表來直觀查看數據)。
3.數據清洗(數據預處理)
數據預處理是數據分析過程中關鍵的一環,數據質量決定了機器學習分析的上限,而具體采用的算法和模型只是逼近這個上限。(包括缺失數據處理、異常值處理、數據類型轉換、列名重命名、數據排序、選擇子集、特征工程等步驟)
4.構建模型
根據研究的問題以及數據的特點選擇合適的算法,將訓練數據放入所選擇的機器學習算法中構建相應的模型,有時需要對多種算法模型進行比較,甚至進行模型整合。
5.模型評估
利用測試數據對得到的模型效果進行評估,具體評估指標依據研究的問題及采用的模型進行選擇,常用到的指標需根據模型的類型而定,如分類模型常用準確率、ROC-AUC等,而回歸模型可以用決定系數等。
各類學習器評價指標 - MsSpark的博客 - CSDN博客?blog.csdn.net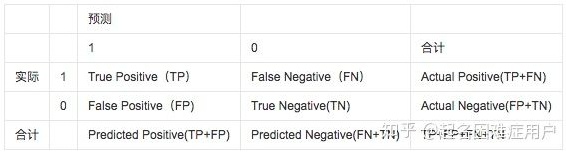
1.3特征(feature)和標簽(label)
機器學習中經常遇到特征及標簽兩個概念:
特征:數據的特征,描述數據的屬性。
標簽:數據的標簽,對數據的預測結果。
1.4Python機器學習包sklearn
Python提供了強大的sklearn包,可以調用不同機器學習方法解決問題。我們并不需要一開始就掌握sklearn中每種機器學習方法,只需在用到某個機器學習方法時,再去sklearn中找對應算法的用法即可。本文第三部分會以調用sklearn包中LinearRegression方法進行簡單線性回歸分析為例,說明如何使用Python進行數據分析。
二、相關分析及回歸分析
機器學習常用來解決相關分析和回歸分析的問題,本文接下來主要介紹兩者的相關概念及評估指標,以及它們的區別與聯系。
2.1相關分析及回歸分析
- 相關分析(Correlation analysis):研究兩個或兩個以上處于同等地位的隨機變量間的相關關系的統計分析方法。
- 回歸分析(Regression analysis):確定兩種或兩種以上變量間相互依賴定量關系的統計分析方法,將變量分為因變量和自變量。
兩者的區別:
- 相關分析中涉及的變量不區分自變量和因變量,變量之間關系是對等的;回歸分析中,需要根據研究對象的性質和研究分析的目的,區分變量為自變量和因變量。
- 相關分析主要通過“相關系數”反映變量間相關程度的大小,因為變量間關系是對等的,所有相關系數是唯一的;回歸分析中,自變量和因變量之間可能存在多個回歸方程。
兩者的聯系:
- 相關分析是回歸分析的基礎和前提,回歸分析是相關分析的深入和繼續。
- 相關分析表現變量間數量變化的相關程度,回歸分析表現變量間數量相關的具體形式。
- 只有變量間存在高度相關時,進行回歸分析需求具體形式才有意義。
2.2線性相關性類型及回歸分析類型
2.2.1線性相關性類型
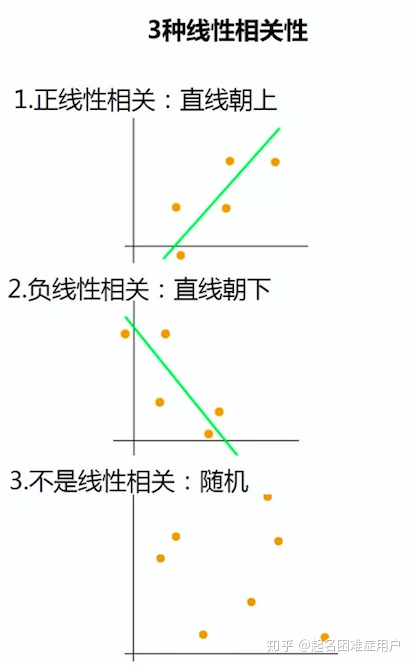
以兩個變量的簡單線性相關為例:
散點圖(直觀判斷變量間是否有相關性的最佳方法):結合散點圖來直觀顯示各個變量之間的相關性。
三種線性相關性:正線性相關(總體表現直線朝上);負線性相關;非線性相關。
2.2.2回歸分析類型
根據不同的維度對回歸分析進行分類:
- 一元回歸和多元multivariate回歸分析(因變量多少);
- 簡單回歸和多重multiple回歸分析(自變量多少);
- 線性回歸和非線性回歸(自變量及因變量間關系類型)。
2.3衡量指標
2.3.1衡量變量間相關度的指標
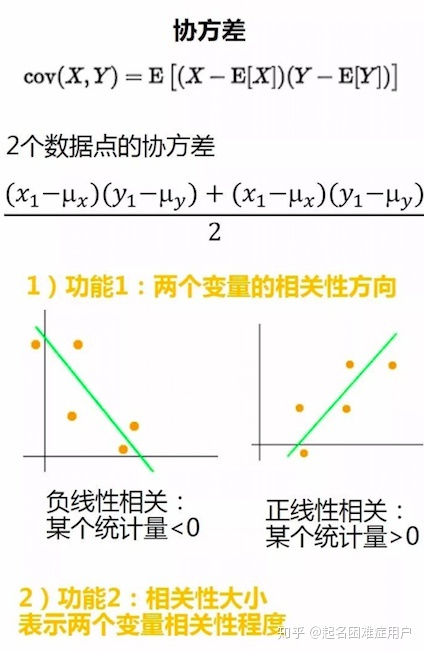
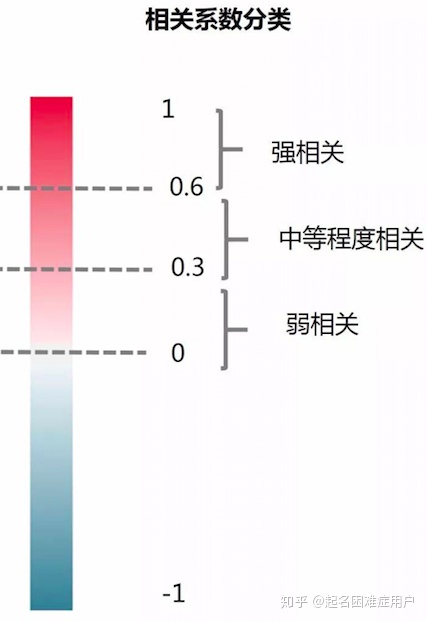
符號(反映兩個變量的相關性方向);大小(表示兩個變量相關性程度)
- 指標一:協方差
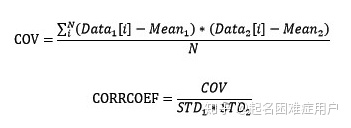
協方差(cov(data,bias=1)):描述變量間相互關系,兩隨機向量X,Y之間的協方差定義為cov(X,Y)=E[(X-E(X))(Y-E(Y))],E表示數學期望。可通俗的理解為,兩個變量在變化過程中是同方向變化還是反方向變化?以及同向或反向程度如何?
符號表示相關性方向;大小表示相關性程度。
該指標缺點:容易受到變量量綱影響。
- 指標二:相關系數
相關系數(corrcoef(data)):先對變量做標準化變換(除相應標準差),然后再計算協方差,把先標準化變換后做協方差運算定義為變量間的相關系數(皮爾遜相關系數)。可以理解為是剔除兩個變量量綱影響,標準化后的特殊協方差。
相關系數與協方差對比:
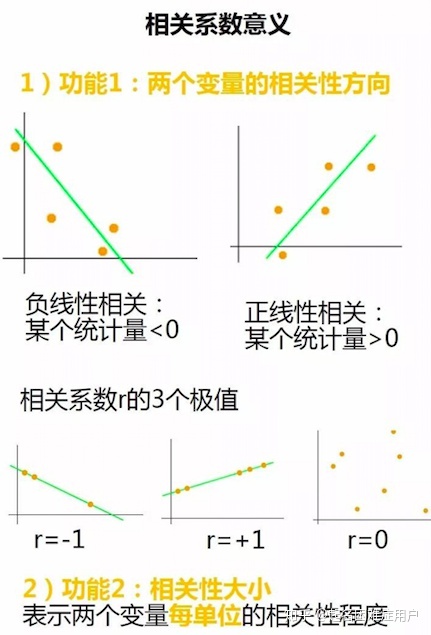
- 相關系數是一個無單位的量,絕對值不超過1,它描述了變量間的線性相關程度。
- 當變量間相關系數為0時,變量間不存在線性趨勢關系,但可能存在非線性趨勢關系。
- 當變量間相關系數的絕對值為1時,一個變量是另一變量的線性函數;當變量間相關系數越接近1時,變量間線性趨勢越明顯。
- 在用協方差描述變量間的相關程度時會受到變量的量綱和數量級的影響,即使對于同樣的一組變量,當變量的量綱和數量級發生變化時,協方差也會隨之改變。
2.3.2衡量回歸模型精確度的指標
>>>先介紹回歸分析中的最佳擬合線(回歸方程)
最佳擬合線即能最準確預測出所有點真實值的線。
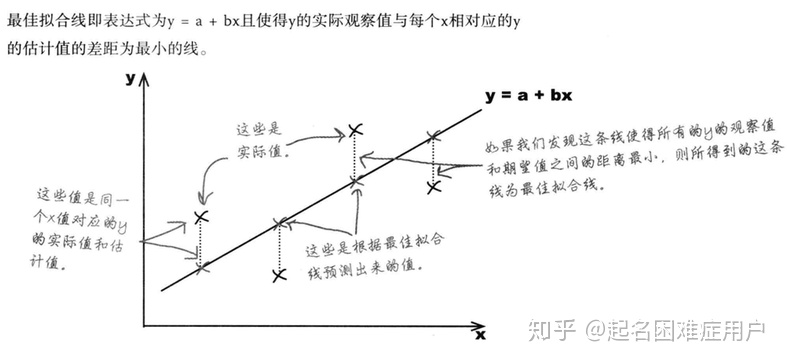
如何求出回歸方程中的截距和回歸系數(最小二乘法:使誤差平方和最小)
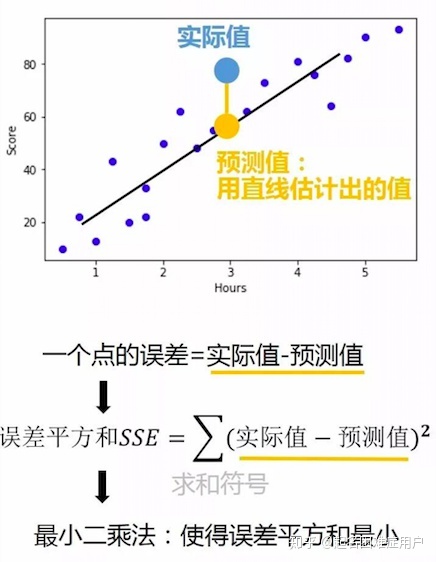
指標三:決定系數R平方(coefficient of determination)
決定系數(model.score()):評估得到的回歸方程是否較好擬合樣本數據的統計量。(以下是與決定系數相關的重要指標,以及決定系數的計算過程)

總的平方和:觀測值與平均值的離差平方和

誤差平方和:觀測值與預估值的離差平方和

回歸平方和:預估值與平均值的離差平方和

三個平方和之間的關系
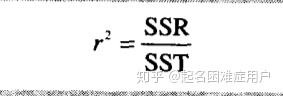
決定系數的計算(回歸平方和與總平方和的商)
決定系數與相關系數對比:
- 決定系數表示回歸線擬合程度,即有多少百分比的y波動可以被回歸線描述;相關系數表示變量間的相關關系。
- 決定系數大小:R平方越高,回歸模型越精確,取值為[0,1];相關系數等于 (相關性方向符號+or-)決定系數開方,取值為[-1,1]。
- 決定系數越大則擬合優度越好,但具體問題要具體分析;相關系數絕對值越大說明變量相關性越強。
2.4相關關系與因果關系
注意不能混淆相關關系和因果關系,相關分析只能表明變量是如何或以怎樣的程度彼此聯系在一起的。
三、回歸分析的Python實現
利用Python中的sklearn包進行簡單線性回歸分析。
3.1提出問題
探究“學習時長”和“學習成績”之間是否存在相關性關系,如果有找出其回歸方程。
3.2理解數據
1、導入數據包
import 2、創建數據并查看數據
#創建數據并查看數據
3、提取特征值和標簽
#特征值:解釋變量(自變量),一般加X為后綴
4、利用散點圖查看數據間關系
import 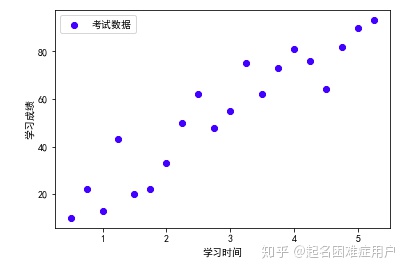
5、求出變量間相關系數
#變量間的相關系數
從散點圖中,我們可以看出學習時長和學習成績之間應該存在線性相關關系,且相關系數為0.9379呈現強線性相關關系(模型選擇時,我們會創建線性回歸模型進行擬合)。
3.3構建模型
1、從數據集中分離出訓練數據train和測試數據test
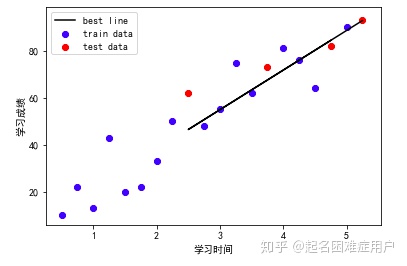
from 繪制散點圖,查看訓練集和測試集數據的分布情況
import 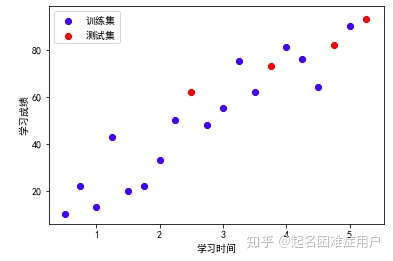
2、創建線性回歸模型
#導入線性回歸模型
3、訓練模型
#導入模型的數據應為一列數據
3.4模型評估
1、查看模型得分(即決定系數大小)
#查看模型得分
2、求出并繪制模型擬合線(模型的回歸方程)y=a+bx
#模型擬合線(模型的回歸方程)y=a+bx
四、總結
機器學習方法有很多,這些方法有些很容易混淆,比如相關分析/回歸分析/因果分析以及聚類分析/分類分析等,在使用時要注意區分其異同點。



















![拓展歐幾里得 [Noi2002]Savage](http://pic.xiahunao.cn/拓展歐幾里得 [Noi2002]Savage)