純手擼一個RAG
- RAG基本流程
- 第一階段:數據預處理(索引) - 構建知識庫
- 第二階段:查詢與生成(推理) - 回答問題
- 總結
- Chunk介紹
- Chunk框架的介紹
- Chunk核心概念
- 選擇分塊策略和框架
- 如何選擇分塊框架
- Python代碼實現
- 第一步:文檔準備
- 第二步:chunk代碼
- 第二步:Embedding--我這里選擇的千問Embedding模型
- 第三步:將Embedding之后的數據存入向量數據庫中--這里選擇的向量數據庫為 chromadb
- 第四步:執行一次搜索【孫悟空的金箍棒是從哪里得來的?】--這里的LLM模型選擇的也是千問模型
- embed.py文件的完整代碼
- 第五步:可視化查看向量數據庫
- 結束語
RAG基本流程
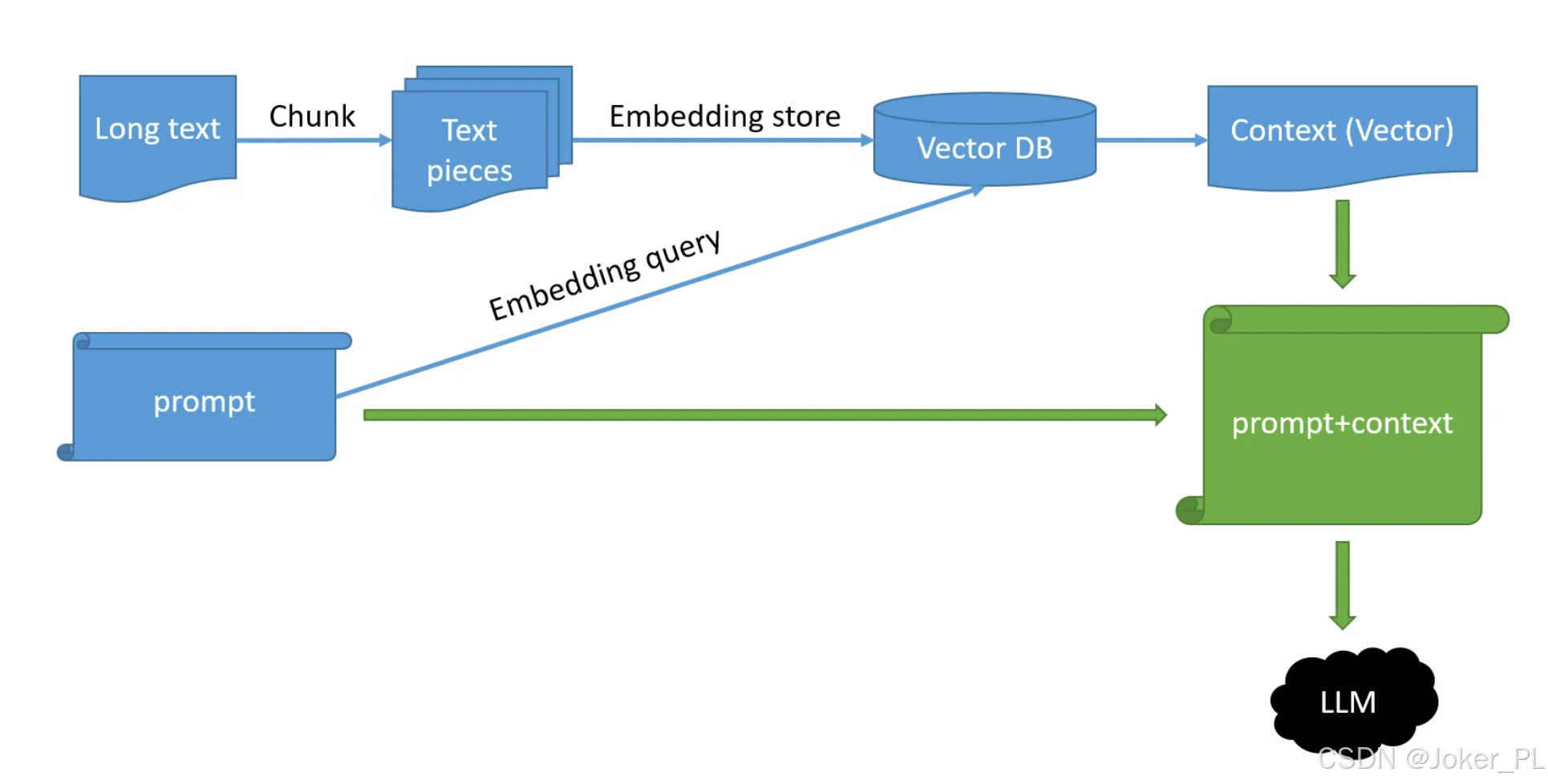
整個流程可以解讀為:先用知識庫訓練一個“超級大腦”,當用戶提問時,這個大腦會先從自己的知識庫里精準地找到相關答案片段,然后再組織語言給出最終回答。
下面我將為您詳細解釋圖中每個步驟的含義。
第一階段:數據預處理(索引) - 構建知識庫
這個階段是“備課”的過程,通常離線進行,目的是將您的知識文檔(如公司內部文檔、產品手冊等)處理成系統可以快速查詢的格式。
- Long Text (長文本)
- 含義:這就是您的原始知識庫來源,可以是PDF、Word、TXT、網頁等任何格式的長篇文檔。
- 類比:就像一本完整的教科書。
- Chunk (分塊)
- 含義:由于LLM的上下文窗口有限,并且為了提高檢索精度,需要將長文本切割成更小的、語義相對完整的片段。這個過程就是我們之前討論的 Text Chunking。
- 方法:可以使用固定大小、按句子/段落,或更高級的語義分塊等方法。
- 類比:把教科書中的每一章、每一節分解成一個個重點明確的段落或知識點卡片。
- Text Pieces (文本片段)
- 含義:分塊后產生的具體文本片段,也就是一個個“Chunk”。
- 類比:上一步制作好的知識點卡片。
- Embedding (嵌入)
- 含義:使用嵌入模型將這些文本片段轉換成向量。向量是一串數字,在高維空間中表示文本的語義信息。語義相近的文本,其向量在空間中的距離也更近。
- 目的:將文本轉換為計算機可以理解和計算的數學形式。
- 類比:為每一張知識點卡片生成一個獨一無二的“數字指紋”,這個指紋編碼了卡片上的所有知識。
- Vector DB (向量數據庫)
- 含義:將這些生成的向量(以及對應的原始文本片段)存儲到一個專門的數據庫中,這種數據庫擅長高效地存儲和檢索向量數據。
- 目的:為后續的相似性搜索做好準備。
- 類比:將一個裝滿所有“數字指紋”和對應“知識點卡片”的智能檔案柜歸檔完畢。
第二階段:查詢與生成(推理) - 回答問題
這個階段是“考試”或“答疑”的過程,在線實時進行。當用戶提出一個問題時,系統執行以下步驟來生成答案。
-
Query / Prompt (用戶查詢/問題)
- 含義:用戶輸入的問題或指令。例如:“我們公司的休假政策是怎樣的?”
- 類比:學生提出的一個問題。
-
Embedding (嵌入查詢)
- 含義:使用同一個嵌入模型將用戶的問題也轉換為一個向量。
- 目的:讓計算機能夠理解用戶問題的“數字指紋”是什么樣的。
- 類比:為學生的這個問題也生成一個“數字指紋”。
-
Context (Vector) (檢索上下文)
- 含義:系統拿著用戶問題的“向量”,去向量數據庫中進行相似性搜索。它會尋找與問題向量最相近的那些向量(即語義最相關的文本片段)。
- 結果:系統檢索出最相關的幾個“文本片段”。
- 類比:拿著問題的“指紋”去智能檔案柜里查找,找出指紋最匹配的幾張“知識點卡片”。
-
Prompt + Context (組合提示詞)
-
含義:將用戶原始的問題和從向量數據庫中檢索到的相關上下文組合成一個新的、更豐富的提示詞。
-
模板示例:
請根據以下背景信息回答問題。
背景信息:[這里插入檢索到的相關文本片段]
問題:[這里插入用戶的原問題]
回答: -
類比:學生拿到了與問題最相關的幾張知識點卡片作為參考,然后開始組織答案。
-
-
LLM (大語言模型)
- 含義:將組合好的新提示詞發送給大語言模型(如GPT-4)。
- 過程:LLM的核心任務不再是依靠自己的內部知識,而是基于提供的“背景信息” 來生成一個精準、可靠的答案。
- 優點:避免了LLM的幻覺問題,答案更具事實性,并且可以引用最新的、私有的知識。
- 類比:學生參考著找到的知識點卡片,寫出一份準確、完整的答案。
-
Response / Answer (最終響應)
- 含義:LLM生成的最終答案返回給用戶。這個答案既結合了LLM強大的語言組織和推理能力,又扎根于您提供的真實數據。
- 類比:學生提交了最終答卷。
總結
這張圖清晰地展示了RAG如何將信息檢索 和文本生成 完美結合:
- 左邊(預處理):是知識灌輸的過程,把外部知識結構化地“教”給系統。
- 右邊(查詢):是知識應用的過程,系統利用學到的知識來精準地回答用戶問題。
Chunk介紹
RAG(Retrieval-Augmented Generation)系統中的 chunk(文本分塊/片段)是構建高效檢索的基礎。它將大型文檔分解為更小、更易管理的語義單元,以便后續的向量化、索引和檢索。合理的分塊策略能顯著影響知識檢索的準確性和生成答案的質量。
Chunk框架的介紹
| 框架名稱 | 主要特點 | 適用場景 | 支持的分塊策略 | 輕量/易用性 |
|---|---|---|---|---|
| LangChain | 生態成熟,功能全面,社區活躍 | 通用RAG應用,快速原型開發 | 固定大小、遞歸字符、語義1 | 中等 |
| Chonkie | 極速、輕量(核心僅9.7MB)2 | 高性能要求,輕量化部署 | Token、句子、語義、SDPM8 | ? |
| RAGFlow | 深度文檔理解,智能解析表格/公式4 | 企業級知識庫,復雜格式文檔 | 智能布局分析(含多模態)4 | 需Docker |
| LightRAG | 模塊化設計,支持自定義分塊策略10 | 研究、定制化場景 | 可按字符、語義或混合策略擴展10 | 高靈活性 |
Chunk核心概念
在RAG中,Chunk 是指將長文檔切割成的、帶有一定語義完整性且大小可控的文本片段。這個過程之所以關鍵,是因為它直接 bridge 了原始文檔和LLM的有效處理能力。
- 為什么需要分塊?
- 適應模型上下文窗口:LLM有token處理上限,必須將長文本切塊。
- 提升檢索精度:過大的塊會包含無關信息(噪聲),降低檢索準確性;過小的塊可能上下文不足,影響LLM理解。合適的塊能讓檢索系統更精準地定位到與問題最相關的信息。
- 平衡效率與成本:小塊文本的向量化計算和索引更高效,存儲和檢索成本也更低。
- 分塊的核心原則
- 保持語義完整性:理想的分塊應盡可能保持一個完整的語義單元(如一個概念、一段論證),避免在句子中間或意群中斷開。常用的分隔符包括段落(
\n\n)、換行符(\n)、句號(。)等。 - 設置重疊區域:相鄰的塊之間保留一部分重疊文本(例如100-300字符),有助于保持上下文的連續性,防止關鍵信息因被切割在兩個塊的邊界而丟失。
- 選擇合適的大小:沒有 universally 的最佳大小,需根據文檔類型、模型能力和具體任務試驗。一個常見的起始參考范圍是 256~768個tokens。
- 保持語義完整性:理想的分塊應盡可能保持一個完整的語義單元(如一個概念、一段論證),避免在句子中間或意群中斷開。常用的分隔符包括段落(
選擇分塊策略和框架
你可以根據文檔特點和項目需求,參考以下策略進行選擇。
- 固定大小分塊 (Fixed-size Chunking):
最簡單直接的方法,按固定字符數或token數切割。優點是簡單快速;缺點是可能粗暴地破壞文本語義結構。
# 示例:LangChain 的固定大小分塊from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(chunk_size=1000,chunk_overlap=200,separator="\n")docs = text_splitter.split_text(your_text)
-
遞歸字符分塊 (Recursive Character Text Splitting):
LangChain 默認推薦的方法。它優先嘗試用一組分隔符(如["\n\n", "\n", "。", " ", ""])遞歸地分割文本,直到塊的大小符合要求。這種方法比固定分塊更能尊重文本的天然結構。 -
語義分塊 (Semantic Chunking):
利用嵌入模型計算句子或段落間的語義相似度,在語義變化邊界處進行切割。優點是能更好地保持語義連貫性;缺點是計算開銷稍大。
# 示例:使用 Chonkie 進行語義分塊from chonkie import SemanticChunkerchunker = SemanticChunker(embedding_model="all-minilm-l6-v2", max_chunk_size=512, similarity_threshold=0.7)chunks = chunker.chunk(your_text)
-
專用分塊 (Specialized Chunking):
對于代碼、論文、PPT等高度結構化的文檔,通用分塊策略往往效果不佳。- RAGFlow 這類框架的價值在此凸顯,它能深度解析文檔布局,對表格、公式、多欄排版進行結構化提取和智能分塊,最大限度保留原始信息的完整性。
如何選擇分塊框架
選擇時,可以重點考慮以下幾點:
- 文檔類型與復雜度:如果主要處理純文本文檔(TXT, MD),LangChain 或 Chonkie 足夠。如果需要處理PDF、PPT、Excel等復雜格式,并需要處理其中的表格、圖片,RAGFlow 的深度解析能力更為合適。
- 性能與資源要求:若對速度和資源占用非常敏感(如服務器less環境),Chonkie 以其輕量和高效著稱28。若需要高度定制化的分塊邏輯(例如為特定領域優化),LightRAG 的模塊化設計提供了更大靈活性10。
- 開發與部署成本:LangChain 生態系統龐大,社區支持好,適合快速開發和驗證想法。RAGFlow 提供開箱即用的體驗,包括可視化界面,更適合部署企業級應用4。
💡 實踐建議
- 沒有銀彈:最佳分塊策略高度依賴于你的具體數據、查詢類型和模型。強烈建議進行實驗和評估。
- 重疊是關鍵:不要忽視
chunk_overlap參數。適當的重疊(通常為塊大小的10%-20%)能有效防止邊界效應。 - 評估維度:可以從檢索精度(Recall@K, MRR)、生成答案質量(人工評估或LLM評估)以及系統延遲等維度綜合評估分塊效果。
Python代碼實現
廢話不多說,直接上代碼
第一步:文檔準備
西游記全文:此處省略N個字
📖保存為:data.md文件
第二步:chunk代碼
from langchain.text_splitter import RecursiveCharacterTextSplitter
def read_data() -> str:with open("data.md", "r", encoding="utf-8") as f:return f.read()
def get_chunks() -> list[str]:# 1?? 定義示例文本(可替換為你自己的內容)# text = """# RAG(Retrieval-Augmented Generation)是將外部知識與大語言模型結合的一種技術方式,# 通過“先檢索、再生成”的流程,讓模型能結合知識庫回答問題。# 而文本切分,就是其中的關鍵第一步。# """text = read_data()# 2?? 初始化分塊器(推薦配置)text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "。"], # 語義感知分段,自定義分割符chunk_size=1000, ## 最大長度,每段最大長度(字符數)chunk_overlap=200 ## 重疊長度,相鄰 chunk 的重疊長度)# 3?? 執行分塊chunks = text_splitter.split_text(text)result = []# 4?? 輸出查看:前幾個 chunk 結果# print(f"總共分成 {len(chunks)} 塊:\n")for i, chunk in enumerate(chunks):result.append(f"{chunk}")# print(f"第 {i+1} 塊內容:\n{chunk}\n{'-'*30}")return resultif __name__ == '__main__':chunks = get_chunks()for c in chunks:print(c)print("--------------")
📖 保存為:chunkLangChain.py文件
第二步:Embedding–我這里選擇的千問Embedding模型
from openai import OpenAIdef embed(text: str) -> list[float]:client = OpenAI(api_key="API Key", # 如果您沒有配置環境變量,請在此處用您的API Key進行替換base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百煉服務的base_url)completion = client.embeddings.create(model="text-embedding-v4",input=text,dimensions=1024,# 指定向量維度(僅 text-embedding-v3及 text-embedding-v4支持該參數)encoding_format="float")assert completion.data[0]assert completion.data[0].embeddingreturn completion.data[0].embedding
📖 保存為embed.py文件
第三步:將Embedding之后的數據存入向量數據庫中–這里選擇的向量數據庫為 chromadb
## 代碼寫在embed.py文件中
import chunkLangChain
import chromadbchromadb_client = chromadb.PersistentClient("./chromaDb")
chromadb_collection = chromadb_client.get_or_create_collection("joker")
def create_db() -> None:for idx, c in enumerate(chunkLangChain.get_chunks()):print(f"Process: {c}")embedding = embed(c)chromadb_collection.upsert(ids=str(idx),documents=c,embeddings=embedding)
if __name__ == '__main__':create_db() # 只需要處理一次
第四步:執行一次搜索【孫悟空的金箍棒是從哪里得來的?】–這里的LLM模型選擇的也是千問模型
def query_db(question: str) -> list[str]:question_embedding = embed(question)result = chromadb_collection.query(query_embeddings=question_embedding,n_results=5)assert result["documents"]return result["documents"][0]def llm_query(content:str):client = OpenAI(api_key="API Key", # 如果您沒有配置環境變量,請在此處用您的API Key進行替換base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百煉服務的base_url)completion = client.chat.completions.create(model="qwen-plus",messages=[{"role": "system", "content": "你是一個全能的助手!"},{"role": "user", "content": content},],# Qwen3模型通過enable_thinking參數控制思考過程(開源版默認True,商業版默認False)# 使用Qwen3開源版模型時,若未啟用流式輸出,請將下行取消注釋,否則會報錯# extra_body={"enable_thinking": False},)assert completion.choicesassert completion.choices[0]assert completion.choices[0].messageassert completion.choices[0].message.contentreturn completion.choices[0].message.contentif __name__ == '__main__':# create_db() # 只需要處理一次question = "孫悟空的如意金箍棒是從哪里得來的?"chunks = query_db(question)prompt = "請根據上下文回答用戶的問題\n"prompt += f"Question: {question}\n"prompt += "Context:\n"for c in chunks:prompt += f"{c}\n"print(prompt)# 將向量數據庫中找到的片段統一丟給LLM;之后統一返回前端print(llm_query(prompt))
embed.py文件的完整代碼
from openai import OpenAI
import chunkLangChain
import chromadbchromadb_client = chromadb.PersistentClient("./chromaDb")
chromadb_collection = chromadb_client.get_or_create_collection("joker")def embed(text: str) -> list[float]:client = OpenAI(api_key="API Key", # 如果您沒有配置環境變量,請在此處用您的API Key進行替換base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百煉服務的base_url)completion = client.embeddings.create(model="text-embedding-v4",input=text,dimensions=1024,# 指定向量維度(僅 text-embedding-v3及 text-embedding-v4支持該參數)encoding_format="float")assert completion.data[0]assert completion.data[0].embeddingreturn completion.data[0].embeddingdef create_db() -> None:for idx, c in enumerate(chunkLangChain.get_chunks()):print(f"Process: {c}")embedding = embed(c)chromadb_collection.upsert(ids=str(idx),documents=c,embeddings=embedding)def query_db(question: str) -> list[str]:question_embedding = embed(question)result = chromadb_collection.query(query_embeddings=question_embedding,n_results=5)assert result["documents"]return result["documents"][0]def llm_query(content:str):client = OpenAI(api_key="API Key", # 如果您沒有配置環境變量,請在此處用您的API Key進行替換base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百煉服務的base_url)completion = client.chat.completions.create(model="qwen-plus",messages=[{"role": "system", "content": "你是一個全能的助手!"},{"role": "user", "content": content},],# Qwen3模型通過enable_thinking參數控制思考過程(開源版默認True,商業版默認False)# 使用Qwen3開源版模型時,若未啟用流式輸出,請將下行取消注釋,否則會報錯# extra_body={"enable_thinking": False},)assert completion.choicesassert completion.choices[0]assert completion.choices[0].messageassert completion.choices[0].message.contentreturn completion.choices[0].message.contentif __name__ == '__main__':# create_db() # 只需要處理一次question = "孫悟空的如意金箍棒是從哪里得來的??"chunks = query_db(question)prompt = "請根據上下文回答用戶的問題\n"prompt += f"Question: {question}\n"prompt += "Context:\n"for c in chunks:prompt += f"{c}\n"print(prompt)# 將向量數據庫中找到的片段統一丟給LLM;之后統一返回前端print(llm_query(prompt))
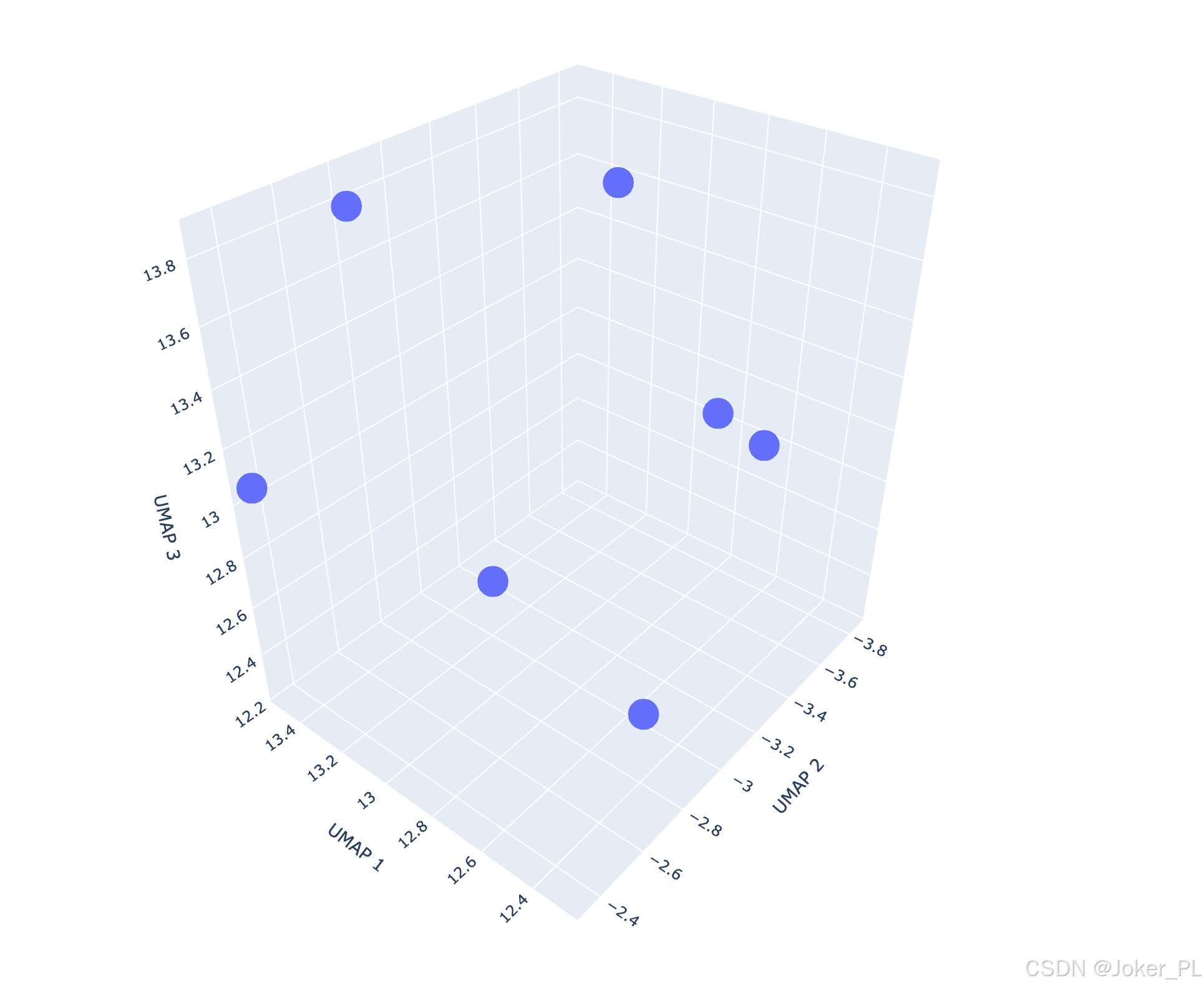
第五步:可視化查看向量數據庫
import chromadb
import umap
import plotly.express as px
import pandas as pd
import numpy as np# 連接到Chroma數據庫
client = chromadb.PersistentClient(path="./chromaDb") # 替換為您的數據庫路徑# 獲取集合列表
collections = client.list_collections()
print("可用集合:", [col.name for col in collections])# 選擇要可視化的集合
collection_name = "joker2" # 替換為您的集合名稱
collection = client.get_collection(collection_name)# 獲取所有向量和對應的元數據
results = collection.get(include=["embeddings", "metadatas", "documents"])
# 提取向量和元數據
embeddings = results["embeddings"]
metadatas = results["metadatas"]
documents = results["documents"]print(f"檢索到 {len(embeddings)} 個向量")# 使用UMAP進行降維
reducer = umap.UMAP(n_components=3, random_state=42)
embedding_3d = reducer.fit_transform(embeddings)# 準備可視化數據
df = pd.DataFrame({'x': embedding_3d[:, 0],'y': embedding_3d[:, 1],'z': embedding_3d[:, 2],
})
# print(metadatas)
# 添加元數據(如果有) 因為我們在存儲時,這部分信息沒有存儲,這部分可以注釋掉
# if metadatas and len(metadatas) > 0:
# print(metadatas[0])
# for key in metadatas[0].keys():
# df[key] = [meta.get(key, "") for meta in metadatas]# 添加文檔文本(如果有)
if documents and len(documents) > 0:df['document'] = documents# 創建3D散點圖
fig = px.scatter_3d(df,x='x',y='y',z='z',title=f"Chroma集合 '{collection_name}' 的向量可視化",hover_data=df.columns.tolist() # 懸停時顯示所有信息
)# 更新布局
fig.update_layout(scene=dict(xaxis_title='UMAP 1',yaxis_title='UMAP 2',zaxis_title='UMAP 3')
)# 顯示圖形
fig.show()
結束語
- 結合前端,可以將文件做成可視化上傳;
- 結合不同用戶,設置不同的數據庫,將不同用戶上傳的文件進行embedding向量化存儲;
- 根據不同的用戶或不同的數據庫,設置知識庫管理系統;
- 市面上可供使用的輪子:RAGFlow等。
)






?詳解)



)


)
8.21)



)