K近鄰法(k-nearst neighbors,KNN)是一種很基本的機器學習方法了,在我們平常的生活中也會不自主的應用。比如,我們判斷一個人的人品,只需要觀察他來往最密切的幾個人的人品好壞就可以得出了。這里就運用了KNN的思想。KNN方法既可以做分類,也可以做回歸,這點和決策樹算法相同。
KNN做回歸和分類的主要區別在于最后做預測時候的決策方式不同。KNN做分類預測時,一般是選擇多數表決法,即訓練集里和預測的樣本特征最近的K個樣本,預測為里面有最多類別數的類別。而KNN做回歸時,一般是選擇平均法,即最近的K個樣本的樣本輸出的平均值作為回歸預測值。由于兩者區別不大,雖然本文主要是講解KNN的分類方法,但思想對KNN的回歸方法也適用。由于scikit-learn里只使用了蠻力實現(brute-force),KD樹實現(KDTree)和球樹(BallTree)實現,本文只討論這幾種算法的實現原理。其余的實現方法比如BBF樹,MVP樹等,在這里不做討論。
KNN算法原理
- 1.從訓練數據集合中獲取K個離待預測樣本距離最近的樣本數據;
- 2.根據獲取得到的K個樣本數據來預測當前待預測樣本的目標屬性值。
如下圖綠色圓是要被決定賦予哪個類,如果K=3,由于紅色三角形所占比例為2/3,綠色圓就被認為是紅色三角形類;如果K=5,由于藍色正方形所占比例為3/5,藍色圓就被認為是藍色正方形類。
在理想情況下,K值選擇為1,即值選擇最近鄰居。在現實生活中往往沒有這么理想,比如對于價格來說,有些孤噩消息閉塞,可以回為“最近鄰居”多付很多錢,所以應當貨幣三家,多選一些鄰居,取均值來減少噪聲。實際上,K值過大過小都會影響最終結果。
KNN算法三要素
KNN算法我們主要要考慮三個重要的要素,對于固定的訓練集,只要這三點確定了,算法的預測方式也就決定了。這三個最終的要素是k值的選取,距離度量的方式和分類決策規則。
分類決策規則,在分類模型中,主要使用多數表決法或者加權多數表決法;在回歸模型中,主要使用平均值法或者加權平均值法。
對于k值的選擇,沒有一個固定的經驗,一般根據樣本的分布,選擇一個較小的值,可以通過交叉驗證選擇一個合適的k值。選擇較小的k值,就相當于用較小的領域中的訓練實例進行預測,訓練誤差會減小,只有與輸入實例較近或相似的訓練實例才會對預測結果起作用,與此同時帶來的問題是泛化誤差會增大,換句話說,K值的減小就意味著整體模型變得復雜,容易發生過擬合;選擇較大的k值,就相當于用較大領域中的訓練實例進行預測,其優點是可以減少泛化誤差,但缺點是訓練誤差會增大。這時候,與輸入實例較遠(不相似的)訓練實例也會對預測器作用,使預測發生錯誤,且K值的增大就意味著整體的模型變得簡單。一個極端是k等于樣本數m,則完全沒有分類,此時無論輸入實例是什么,都只是簡單的預測它屬于在訓練實例中最多的類,模型過于簡單。
對于距離的度量,我們有很多的距離度量方式,但最常用的是歐式距離,即對于兩個n維向量x和y,兩者的歐式距離定義為:
大多數情況下,歐式距離可以滿足我們的需求,我們不需要再去操心距離的度量。當然我們也可以用他的距離度量方式。比如曼哈頓距離:
更加通用點,比如閔可夫斯基距離(Minkowski Distance),定義為:
可以看出,歐式距離是閔可夫斯基距離距離在p=2時的特例,而曼哈頓距離是p=1時的特例。
KNN分類預測規則
KNN在分類應用中,一般采用多數表決法或者加權多數表決法。
- 多數表決法:每個鄰近樣本的權重一樣的,也就是說最終預測的結果為出現類別最多的那個類,比如下圖中藍色最終類別為紅色;
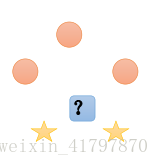
- 加權多數表決法:每個鄰近樣本的權重是不一樣的,一般情況下采用權重和距離成反比的方式來計算,也就是說最終預測結果是出現權重最大的那個類別。比如下圖中,假設三個紅色點到待預測樣本的距離為2,兩個黃色點到待預測樣本點距離為1,那么藍色圓最終的類別是黃色。
KNN回歸預測規則
在KNN回歸應用中,一般采用平均值法,或是加權平均值法。
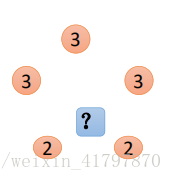
- 平均值法:每個鄰近樣本的權重是一樣的,也就是說最終預測的結果為所有鄰近樣本的目標值;比如下圖中,藍色圓圈的最終預測值為:2.6
- 加權平均值法:每個鄰近樣本的權重是不一樣的,一般情況下采用權重和距離懲罰比的方式計算也就是數在計算均值的時候進行加權操作;比如下圖假設上面三個點到待預測樣本點的距離均為2,下面兩個點到待預測樣本點距離為1,那么藍色圓圈的最終預測值為:2.43(權重分別為:1/7和2/7)
KNN算法實現方式
KNN算法的重點在于找出k個最鄰近的點,主要方式有以下幾種:
- 蠻力實現(brute):計算預測樣本到所有訓練集樣本的距離,然后選擇最小的K個距離即可得到k個最近鄰點。缺點在于當特征數比較多、樣本數比較多的時候,算法 的執行效率比較低。
- KD樹(kd_tree):KD樹算法中,首先是對訓練數據進行建模,構建KD樹,然后在根據建好的模型來獲取鄰近樣本的數據。
除此之外,還有一些從KD_Tree修改后的求解最鄰近點的算法,比如:Ball Tree、BBF Tree、MVP Tree等
KNN算法蠻力實現
既然我們要找到k個最近的鄰居來做預測,那么我們只需要計算預測樣本和所有訓練集中的樣本的距離,然后計算出最小的k個距離即可,接著多數表決,很容易做出預測。這個方法的確簡單直接,在樣本量少,樣本特征少的時候有效。但是在實際運用中很多時候用不上,為什么呢?因為我們經常碰到樣本的特征數有上千以上,樣本量有幾十萬以上,如果我們這要去預測少量的測試集樣本,算法的時間效率很成問題。因此,這個方法我們一般稱之為蠻力實現。比較適合于少量樣本的簡單模型的時候用。
KNN算法之KD樹實現原理
KD樹算法沒有一開始就嘗試對測試樣本分類,而是先對訓練集建模,建立的模型就是KD樹,建好了模型再對測試集做預測。所謂的KD樹就是K個特征維度的樹,注意這里的K和KNN中的K的意思不同。KNN中的K代表特征輸出類別,KD樹中的K代表樣本特征的維數。為了防止混淆,后面我們稱特征維數為n。
KD樹算法包括三步,第一步是建樹,第二部是搜索最近鄰,最后一步是預測。
KD樹的建立
我們首先來看建樹的方法。KD樹建樹采用的是從m個樣本的n維特征中,分別計算n個特征的取值的方差,用方差最大的第k維特征來作為根節點。對于這個特征,我們選擇特征的取值的中位數對應的樣本作為劃分點,對于所有第k維特征的取值小于的樣本,我們劃入左子樹,對于第k維特征的取值大于等于的樣本,我們劃入右子樹,對于左子樹和右子樹,我們采用和剛才同樣的辦法來找方差最大的特征來做更節點,遞歸的生成KD樹。
具體流程如下圖:
比如我們有二維樣本6個,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},構建kd樹的具體步驟為:
- 找到劃分的特征。6個數據點在x,y維度上的數據方差分別為6.97,5.37,所以在x軸上方差更大,用第1維特征建樹。
- 確定劃分點(7,2)。根據x維上的值將數據排序,6個數據的中值(所謂中值,即中間大小的值)為7,所以劃分點的數據是(7,2)。這樣,該節點的分割超平面就是通過(7,2)并垂直于:劃分點維度的直線x=7;
- 確定左子空間和右子空間。 分割超平面x=7將整個空間分為兩部分:x<=7的部分為左子空間,包含3個節點={(2,3),(5,4),(4,7)};另一部分為右子空間,包含2個節點={(9,6),(8,1)}。
- 用同樣的辦法劃分左子樹的節點{(2,3),(5,4),(4,7)}和右子樹的節點{(9,6),(8,1)}。最終得到KD樹。
最后得到的KD樹如下:
KD樹搜索最近鄰
當我們生成KD樹以后,就可以去預測測試集里面的樣本目標點了。對于一個目標點,我們首先在KD樹里面找到包含目標點的葉子節點。以目標點為圓心,以目標點到葉子節點樣本實例的距離為半徑,得到一個超球體,最近鄰的點一定在這個超球體內部。然后返回葉子節點的父節點,檢查另一個子節點包含的超矩形體是否和超球體相交,如果相交就到這個子節點尋找是否有更加近的近鄰,有的話就更新最近鄰。如果不相交那就簡單了,我們直接返回父節點的父節點,在另一個子樹繼續搜索最近鄰。當回溯到根節點時,算法結束,此時保存的最近鄰節點就是最終的最近鄰。
從上面的描述可以看出,KD樹劃分后可以大大減少無效的最近鄰搜索,很多樣本點由于所在的超矩形體和超球體不相交,根本不需要計算距離。大大節省了計算時間。
我們用建立的KD樹,來看對點(2,4.5)找最近鄰的過程。
先進行二叉查找,先從(7,2)查找到(5,4)節點,在進行查找時是由y = 4為分割超平面的,由于查找點為y值為4.5,因此進入右子空間查找到(4,7),形成搜索路徑<(7,2),(5,4),(4,7)>,但 (4,7)與目標查找點的距離為3.202,而(5,4)與查找點之間的距離為3.041,所以(5,4)為查詢點的最近點;?以(2,4.5)為圓心,以3.041為半徑作圓,如下圖所示。可見該圓和y = 4超平面交割,所以需要進入(5,4)左子空間進行查找,也就是將(2,3)節點加入搜索路徑中得<(7,2),(2,3)>;于是接著搜索至(2,3)葉子節點,(2,3)距離(2,4.5)比(5,4)要近,所以最近鄰點更新為(2,3),最近距離更新為1.5;回溯查找至(5,4),直到最后回溯到根結點(7,2)的時候,以(2,4.5)為圓心1.5為半徑作圓,并不和x = 7分割超平面交割,如下圖所示。至此,搜索路徑回溯完,返回最近鄰點(2,3),最近距離1.5。
對應的圖如下:
KD樹預測
有了KD樹搜索最近鄰的辦法,KD樹的預測就很簡單了,在KD樹搜索最近鄰的基礎上,我們選擇到了第一個最近鄰樣本,就把它置為已選。在第二輪中,我們忽略置為已選的樣本,重新選擇最近鄰,這樣跑k次,就得到了目標的K個最近鄰,然后根據多數表決法,如果是KNN分類,預測為K個最近鄰里面有最多類別數的類別。如果是KNN回歸,用K個最近鄰樣本輸出的平均值作為回歸預測值。
KNN算法之球樹實現原理
KD樹算法雖然提高了KNN搜索的效率,但是在某些時候效率并不高,比如當處理不均勻分布的數據集時,不管是近似方形,還是矩形,甚至正方形,都不是最好的使用形狀,因為他們都有角。一個例子如下圖:
如果黑色的實例點離目標點星點再遠一點,那么虛線圓會如紅線所示那樣擴大,導致與左上方矩形的右下角相交,既然相 交了,那么就要檢查這個左上方矩形,而實際上,最近的點離星點的距離很近,檢查左上方矩形區域已是多余。于此我們看見,KD樹把二維平面劃分成一個一個矩形,但矩形區域的角卻是個難以處理的問題。
為了優化超矩形體導致的搜索效率的問題,牛人們引入了球樹,這種結構可以優化上面的這種問題。
我們現在來看看球樹建樹和搜索最近鄰的算法。
球樹的建立
球樹,顧名思義,就是每個分割塊都是超球體,而不是KD樹里面的超矩形體。
我們看看具體的建樹流程:
- 先構建一個超球體,這個超球體是可以包含所有樣本的最小球體。
- 從球中選擇一個離球的中心最遠的點,然后選擇第二個點離第一個點最遠,將球中所有的點分配到離這兩個聚類中心最近的一個上,然后計算每個聚類的中心,以及聚類能夠包含它所有數據點所需的最小半徑。這樣我們得到了兩個子超球體,和KD樹里面的左右子樹對應。
- 對于這兩個子超球體,遞歸執行步驟2). 最終得到了一個球樹。
可以看出KD樹和球樹類似,主要區別在于球樹得到的是節點樣本組成的最小超球體,而KD得到的是節點樣本組成的超矩形體,這個超球體要與對應的KD樹的超矩形體小,這樣在做最近鄰搜索的時候,可以避免一些無謂的搜索。
球樹搜索最近鄰
使用球樹找出給定目標點的最近鄰方法是首先自上而下貫穿整棵樹找出包含目標點所在的葉子,并在這個球里找出與目標點最鄰近的點,這將確定出目標點距離它的最近鄰點的一個上限值,然后跟KD樹查找一樣,檢查兄弟結點,如果目標點到兄弟結點中心的距離超過兄弟結點的半徑與當前的上限值之和,那么兄弟結點里不可能存在一個更近的點;否則的話,必須進一步檢查位于兄弟結點以下的子樹。
檢查完兄弟節點后,我們向父節點回溯,繼續搜索最小鄰近值。當回溯到根節點時,此時的最小鄰近值就是最終的搜索結果。
從上面的描述可以看出,KD樹在搜索路徑優化時使用的是兩點之間的距離來判斷,而球樹使用的是兩邊之和大于第三邊來判斷,相對來說球樹的判斷更加復雜,但是卻避免了更多的搜索,這是一個權衡。
KNN算法的擴展
這里我們再討論下KNN算法的擴展,限定半徑最近鄰算法。
有時候我們會遇到這樣的問題,即樣本中某系類別的樣本非常的少,甚至少于K,這導致稀有類別樣本在找K個最近鄰的時候,會把距離其實較遠的其他樣本考慮進來,而導致預測不準確。為了解決這個問題,我們限定最近鄰的一個最大距離,也就是說,我們只在一個距離范圍內搜索所有的最近鄰,這避免了上述問題。這個距離我們一般稱為限定半徑。
接著我們再討論下另一種擴展,最近質心算法。這個算法比KNN還簡單。它首先把樣本按輸出類別歸類。對于第 L類的個樣本。它會對這個樣本的n維特征中每一維特征求平均值,最終該類別所有維度的n個平均值形成所謂的質心點。對于樣本中的所有出現的類別,每個類別會最終得到一個質心點。當我們做預測時,僅僅需要比較預測樣本和這些質心的距離,最小的距離對于的質心類別即為預測的類別。這個算法通常用在文本分類處理上。
KNN算法小結
KNN算法是很基本的機器學習算法了,它非常容易學習,在維度很高的時候也有很好的分類效率,因此運用也很廣泛\
KNN的主要優點有:
- 理論成熟,思想簡單,既可以用來做分類也可以用來做回歸
- 可用于非線性分類
- 訓練時間復雜度比支持向量機之類的算法低,僅為O(n)
- 和樸素貝葉斯之類的算法比,對數據沒有假設,準確度高,對異常點不敏感
- 由于KNN方法主要靠周圍有限的鄰近的樣本,而不是靠判別類域的方法來確定所屬類別的,因此對于類域的交叉或重疊較多的待分樣本集來說,KNN方法較其他方法更為適合
- 該算法比較適用于樣本容量比較大的類域的自動分類,而那些樣本容量較小的類域采用這種算法比較容易產生誤分
KNN的主要缺點有:
- 計算量大,尤其是特征數非常多的時候
- 樣本不平衡的時候,對稀有類別的預測準確率低
- KD樹,球樹之類的模型建立需要大量的內存
- 使用懶散學習方法,基本上不學習,導致預測時速度比起邏輯回歸之類的算法慢
- 相比決策樹模型,KNN模型可解釋性不強






)





)






)