前面, 介紹了DNN及其參數求解的方法(深度學習之 BP 算法),我們知道DNN仍然存在很多的問題,其中最主要的就是BP求解可能造成的梯度消失和梯度爆炸.那么,人們又是怎么解決這個問題的呢?本節的卷積神經網絡(Convolutional Neural Networks, CNN)就是一種解決方法.
????我們知道神經網絡主要有三個部分組成, 分別為:?
- 網絡結構 ——?描述神經元的層次與連接神經元的結構.
- 激活函數(激勵函數) ——?用于加入非線性的因素,?解決線性模型所不能解決的問題.
- 參數學習方法的選擇(一般為權重值W和偏置項b) —— 如BP算法等.
我們將主要從這幾個方面進行講述.
1 CNN的應用領域
CNN在以下幾個領域均有不同程度的應用:
- 圖像處理領域(最主要運用領域) —— 圖像識別和物體識別,圖像標注,圖像主題生成,圖像內容生成,物體標注等。
- 視頻處理領域 ——?視頻分類,視頻標準,視頻預測等
- 自然語言處理(NLP)領域 ——?對話生成,文本生成,機器翻譯等
- 其它方面 ——?機器人控制,游戲,參數控制等
2 CNN的網絡結構??
2.1 傳統神經網絡

上圖為傳統的神經網絡的結構, 它是一種全連接的結構, 這也就造成了參數訓練的難度加深. 還有BP求解中的可能出現的梯度爆炸和梯度消失的現象等.此外,深度結構(涉及多個非線性處理單元層)非凸目標代價函數中普遍存在的局部最小是訓練困難的主要來源.?這些因素都造成了傳統的神經網絡的不適用性,所以沒有較為廣泛的運用.
2.2 卷積神經網絡(Convolutional Neural Networks,CNN)

上圖為CNN的網絡結構,CNN可以有效的降低反饋神經網絡(傳統神經網絡)的復雜性,常見的CNN結構有LeNet-5、AlexNet、ZFNet、VGGNet、GoogleNet、ResNet等等,其中在LVSVRC2015 冠軍ResNet的網絡層次是AlexNet的20多倍,是VGGNet的8倍;從這些結構來講CNN發展的一個方向就是層次的增加,通過這種方式可以利用增加的非線性得出目標函數的近似結構,同時得出更好的特征表達,但是這種方式導致了網絡整體復雜性的增加,使網絡更加難以優化,很容易過擬合。
CNN的網絡結構和傳統神經網絡結構異同點有:?
- CNN主要有數據輸入層, 卷積層, RELU激勵層, 池化層, 全連接層, Batch Normalization Layer(不一定存在). 傳統神經網絡主要有數據輸入層, 一個或多個隱層以及數據輸出層. 比較可以發現CNN仍然使用傳統神經網絡的層級結構.?
- CNN的每一層都具有不同的功能, 而傳統神經網絡每一層都是對上一層特征進行線性回歸, 再進行非線性變換的操作.
- CNN使用RELU作為激活函數(激勵函數) ,?傳統神經網絡使用sigmoid函數作為激活函數.
- CNN的池化層實現數據降維的作用,提取數據的高頻信息.傳統神經網絡沒有這個作用.
CNN主要是在圖像分類和物品識別等應用場景應用比較多
2.2.0 CNN的主要層次介紹
CNN保持了層級網絡結構,不同層次使用不同的形式(運算)與功能
- 數據輸入層:Input Layer
- 卷積計算層:CONV Layer
- ReLU激勵層:ReLU Incentive Layer
- 池化層:Pooling Layer
- 全連接層:FC Layer
- 備注:Batch Normalization Layer(可能有)
2.2.1 數據輸入層 (Input Layer)
和神經網絡/機器學習一樣,需要對輸入的數據需要進行預處理操作,需要進行預處理的主要原因是:
- 輸入數據單位不一樣,可能會導致神經網絡收斂速度慢,訓練時間長
- 數據范圍大的輸入在模式分類中的作用可能偏大,而數據范圍小的作用就有可能偏小
- 由于神經網絡中存在的激活函數是有值域限制的,因此需要將網絡訓練的目標數據映射到激活函數的值域
- S形激活函數在(0,1)區間以外區域很平緩,區分度太小。例如S形函數f(X),f(100)與f(5)只相差0.0067
常見的數據預處理的方式有以下幾種:
- 均值化處理 --- 即對于給定數據的每個特征減去該特征的均值(將數據集的數據中心化到0)
- 歸一化操作 --- 在均值化的基礎上再除以該特征的方差(將數據集各個維度的幅度歸一化到同樣的范圍內)
- PCA降維 --- 將高維數據集投影到低維的坐標軸上, 并要求投影后的數據集具有最大的方差.(去除了特征之間的相關性,用于獲取低頻信息)
- 白化 --- 在PCA的基礎上, 對轉換后的數據每個特征軸上的幅度進行歸一化.用于獲取高頻信息.
- ?http://ufldl.stanford.edu/wiki/index.php/白化

- 上面分別為:原圖、x = x - np.mean(x, 0)、x = (x - np.mean(x, 0)) / np.std(x, 0)

- 上圖分別為:原圖、PCA、白化
- x -= np.mean(x, axis=0) # ?去均值
- cov = np.dot(x.T, x) / x.shape[0] # ?計算協方差
- u, s, v = np.linalg.svd(cov) # ?進行 svd 分解
- xrot = np.dot(x, u)
- x = np.dot(x, u[:, :2]) # ?計算 pca???
- x = xrot / np.sqrt(s + 1e-5)?# ?白化

備注:雖然我們介紹了PCA去相關和白化的操作,但是實際上在卷積神經網絡中,一般并不會適用PCA和白化的操作,一般去均值和歸一化使用的會比較多.
建議:對數據特征進行預處理,去均值、歸一化
2.2.2 卷積計算層(CONV Layer)
這一層就是卷積神經網絡最重要的一層,也是“卷積神經網絡”的名字由來。??
人的大腦在識別圖片的過程中,會由不同的皮質層處理不同方面的數據,比如:顏色、形狀、光暗等,然后將不同皮質層的處理結果進行合并映射操作,得出最終的結果值,第一部分實質上是一個局部的觀察結果,第二部分才是一個整體的結果合并.
還有,對于給定的一張圖片, 人眼總是習慣性的先關注那些重要的點(局部), 再到全局. 局部感知是將整個圖片分為多個可以有局部重疊的小窗口, 通過滑窗的方法進行圖像的局部特征的識別.?也可以說每個神經元只與上一層的部分神經元相連, 只感知局部, 而不是整幅圖像.
基于人腦的圖片識別過程,我們可以認為圖像的空間聯系也是局部的像素聯系比較緊密,而較遠的像素相關性比較弱,所以每個神經元沒有必要對全局圖像進行感知,只要對局部進行感知,而在更高層次對局部的信息進行綜合操作得出全局信息;即局部感知。



- 局部關聯:每個神經元看做一個filter
- 窗口(receptive field)滑動,filter對局部數據進行計算
- 相關概念:深度:depth,步長:stride,填充值:zero-padding
CONV過程參考:http://cs231n.github.io/assets/conv-demo/index.html
一個數據輸入,假設為一個RGB的圖片
在神經網絡中,輸入是一個向量,但是在卷積神經網絡中,輸入是一個多通道圖像(比如這個例子中有3個通道)

1) 局部感知
在進行計算的時候,將圖片劃分為一個個的區域進行計算/考慮;
那么,為什么可以使用局部感知呢?
我們發現, 越是接近的像素點之間的關聯性越強, 反之則越弱. 所以我們選擇先進行局部感知, 然后在更高層(FC層)將這些局部信息綜合起來得到全局信息的方式.
2)?參數共享機制
所謂的參數共享就是就是同一個神經元使用一個固定的卷積核去卷積整個圖像,也可以認為一個神經元只關注一個特征.?而不同的神經元關注多個不同的特征.(每一個神經元都可以看作一個filter)
固定每個神經元的連接權重,可以將神經元看成一個模板;也就是每個神經元只關注一個特性
需要計算的權重個數會大大的減少
3)?滑動窗口的重疊
滑動窗口重疊就是在進行滑窗的過程中對于相鄰的窗口有局部重疊的部分,這主要是為了保證圖像處理后的各個窗口之間的邊緣的平滑度。降低窗口與窗口之間的邊緣不平滑的特性。
4)) 卷積計算
卷積的計算就是: 對于每一個神經元的固定的卷積核矩陣與窗口矩陣的乘積(對應位置相乘)再求和之后再加上偏置項b的值, 就得到了代表該神經元所關注的特征在當前圖像窗口的值.
如圖2.4所示, 可以看出卷積計算的過程.動態圖點擊這里查看.

2.2.3 RELU激勵層
這一層就是激活層, 在CNN中一般使用RELU函數作為激活函數.它的作用主要是將卷積層的輸出結果做非線性映射.

1) 常見的幾種激活函數
激活函數之 Sigmoid、tanh、ReLU、ReLU變形和Maxout
- sigmoid函數(S函數)
- Tanh函數(2S函數)
- RELU函數?---->?線性修正單元?---> max{ 0, x } ==>無邊界, 易出現'死神經元'
- Leaky ReLU?函數?---> 若x> 0 , 則輸出x ; 若x<0,則?alpha*x,?其中 0< alpha <1??==> 對RELU的改進
- ELU?函數 --->?若x> 0 , 則輸出x ; 若x<0,則?alpha*(e^x - 1),?其中 0< alpha <1??==> 也是一種對RELU的改進
- Maxout函數 ---> 相當于增加了一個激活層
2) 激活函數的一些建議
- 一般不要使用sigmoid函數作為CNN的激活函數.如果用可以在FC層使用.
- 優先選擇RELU作為激活函數,因為迭代速度快,但是有可能效果不佳
- 如果2失效,請用Leaky ReLU或者Maxout,此時一般情況都可以解決啦
- 在極少的情況下, tanh也是有不錯的效果的
2.2.4 池化層 (Poling Layer)
在連續的卷積層中間存在的就是池化層,主要功能是:通過逐步減小表征的空間尺寸來減小參數量和網絡中的計算;池化層在每個特征圖上獨立操作。使用池化層可以壓縮數據和參數的量,減小過擬合。簡而言之,如果輸入是圖像的話,那么池化層的最主要作用就是壓縮圖像。

池化層中的數據壓縮的策略主要有:
- Max Pooling(最大池化)---> 選擇每個小窗口中最大值作為需要的特征像素點(省略掉不重要的特征像素點)
- Average Pooling(平均池化) --->??選擇每個小窗口中平均值作為需要的特征像素點

????池化層選擇較為重要的特征點, 可以降低維度, 能夠在一定程度上防止過擬合的發生.
2.2.5 FC全連接層
類似傳統神經網絡中的結構,FC層中的神經元連接著之前層次的所有激活輸出;換一句話來講的話,就是兩層之間所有神經元都有權重連接;通常情況下,在CNN中,FC層只會在尾部出現
通過全連接結構,將前面輸出的特征重新組合成一張完整的圖像.
一般的CNN結構依次為:
- INPUT
- [[CONV -> RELU] * N -> POOL?]*M
- [FC -> RELU] * K
- FC
2.2.6 Batch Normalization Layer(一般用于卷積層后面,主要是使得期望結果服從高斯分布,好像使用之后可以更快的收斂)
Batch Normalization Layer(BN Layer)是期望我們的結果是服從高斯分布的,所以對神經元的輸出進行一下修正,一般放到卷積層后,池化層前。
- 論文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift;
- 論文鏈接:https://arxiv.org/pdf/1502.03167v3.pdf
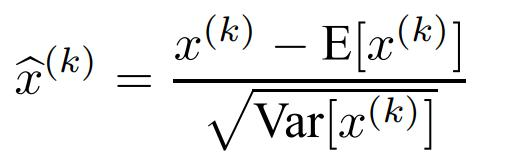
如果輸出的是N*D的結果,對D個維度每個維度求解均值和方差。
根據均值和方差做歸一化。(其實就是上面的去均值和除以方差)

強制的進行歸一化操作可能存在一些問題,eg: 方差為0等

Batch Normalization優點:
- 梯度傳遞(計算)更加順暢,不容易導致神經元飽和(防止梯度消失(梯度彌散)/梯度爆炸)
- 學習率可以設置的大一點
- 對于初始值的依賴減少
Batch Normalization缺點:
- 如果網絡層次比較深,加BN層的話,可能會導致模型訓練速度很慢。
備注:BN Layer慎用!!!
3 CNN的優缺點
優點
????① 使用局部感知和參數共享機制(共享卷積核), 對于較大的數據集處理能力較高.對高維數據的處理沒有壓力
????② 能夠提取圖像的深層次的信息,模型表達效果好.
????③ 不需要手動進行特征選擇, 只要訓練好卷積核W和偏置項b, 即可得到特征值.
缺點
????① 需要進行調參, 模型訓練時間較長, 需要的樣本較多, 一般建議使用GPU進行模型訓練.
????② 物理含義不明, 每層中的結果無法解釋, 這也是神經網絡的共有的缺點.?
?
)
![python序列是幾維_從一個1維的位數組獲得一個特定的2維的1序列數組[Python] - python...](http://pic.xiahunao.cn/python序列是幾維_從一個1維的位數組獲得一個特定的2維的1序列數組[Python] - python...)
(二))







)








