針對SRGAN提出的幾點改進,獲得了PIRM2018視覺質量的第一名。
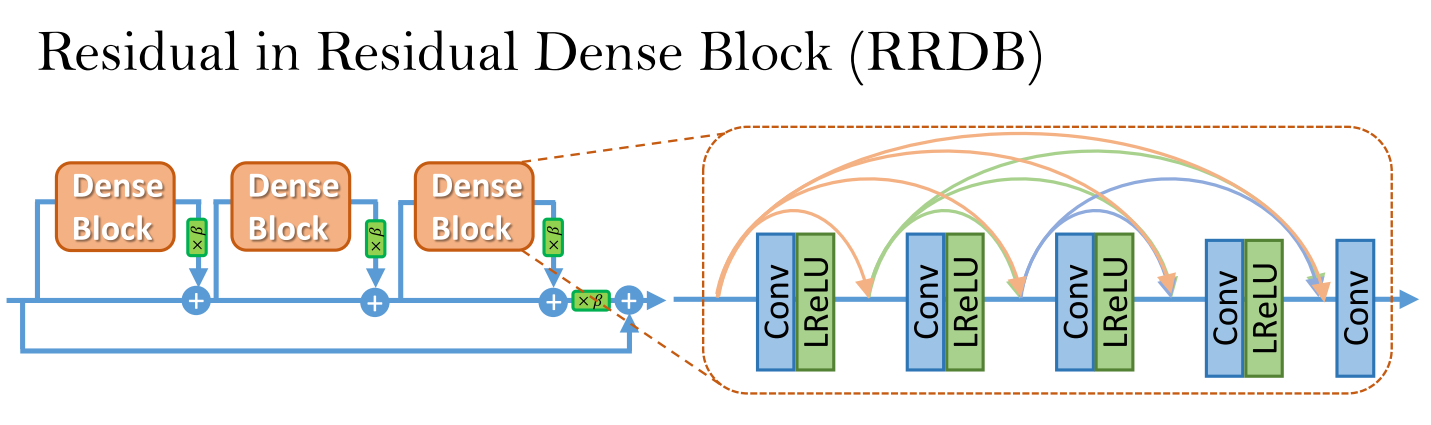
首先是使用去掉BN層的Residual in Residual Dense Block作為網絡的basic unit。并且使用residual scling 和 smaller initialization幫助訓練更深的網絡。
第二點改進是使用了Relativistic Discriminator來預測真實圖像$x_r$比生成圖像$x_f$更真實的可能性,而不是簡單判斷某個圖片是否是真實圖像。$D_{R_a}(x_r, x_f)=\sigma(C(x_r)-E_{x_f}[C(x_f)])$, $\sigma$為sigmoid函數,$E_{x_f}[\cdot]$是取mini-batch中所有fake data的平均, $C(x)$為non-transformed discriminator的輸出。那么GAN的loss就對應為:
$L_D^{Ra}=-E_{x_r}[log(D_{Ra}(x_r, x_f))]-E_{x_f}[log(1-D_{Ra}(x_f, x_r)], L_G^{Ra}=-E_{x_r}[log(1-D_{Ra}(x_r, x_f))]-E_{x_f}[log(D_{Ra}(x_f, x_r))]$這樣的loss使得generator可以同時從生成數據和真實數據的梯度中受益。
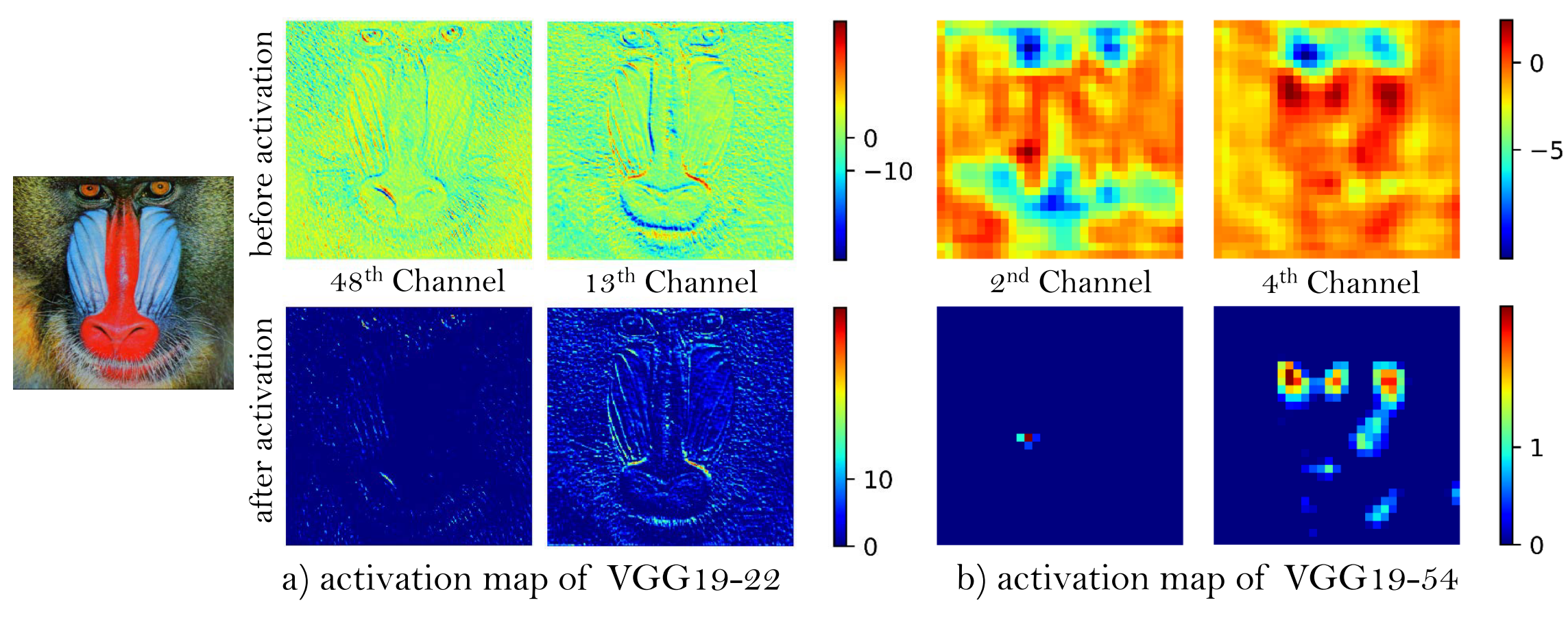
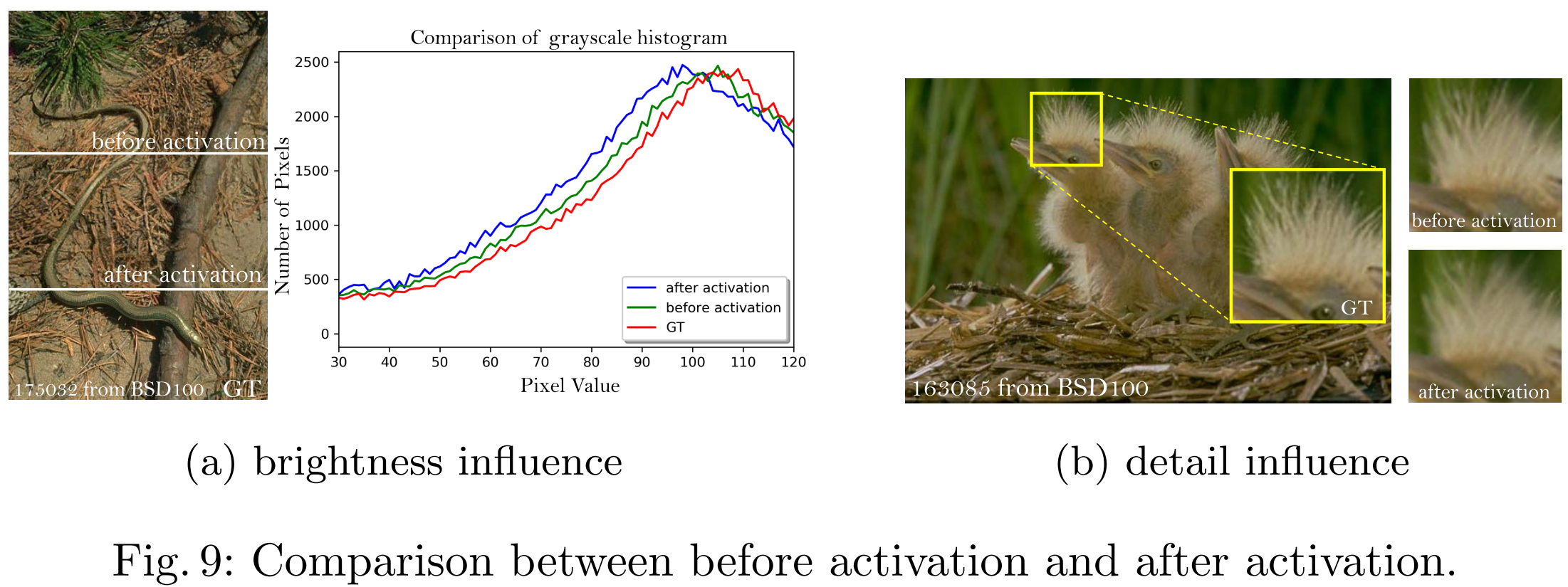
第三點改進是在loss中使用activation之前的特征,而不是使用activation后的特征。特征經過activation后非常的稀疏,特別是對于網絡深度深的情況。實驗發現使用activation后的特征會造成亮度上的不一致。
訓練時先訓練一個PSNR-oriented 網絡$G_{PSNR}$再用fine-tuning的方法獲得一個GAN-based 網絡$G_{GAN}$。這樣的方式可以避免generator落入local optima,使discriminator最開始就得到相對好的圖像幫助他更關注于區分紋理從何得到視覺上更好的效果。為了平衡$G_{PSNR}$和$G_{GAN}$的效果,使用了network interpolation。作者也嘗試使用其他兩種方法:直接interpolate輸出圖像,這種方法無法達到a good trade-off between noise and blur;調整content loss和adversarial loss之間的權重,這種方式需要對網絡進行微調,過于costly。
)





--數據類型(列表))



--數據類型(字典))
![js下載文件 java_[Java教程]使用js實現點擊按鈕下載文件](http://pic.xiahunao.cn/js下載文件 java_[Java教程]使用js實現點擊按鈕下載文件)
)





SQL題:1308. 不同性別每日分數總計)
