文章目錄
- 1. Java基礎
- 1.1 為什么Java代碼可以實現一次編寫、到處運行?
- 1.2 一個Java文件里可以有多個類嗎(不含內部類)?
- 1.3 說一說你對Java訪問權限的了解
- 1.4 介紹一下Java的數據類型
- 1.5 int類型的數據范圍是多少?
- 1.6 請介紹全局變量和局部變量的區別
- 1.7 請介紹一下實例變量的默認值
- 1.8 為啥要有包裝類?
- 1.9 說一說自動裝箱、自動拆箱的應用場景
- 1.10 如何對Integer和Double類型判斷相等?
- 1.11 int和Integer有什么區別,二者在做==運算時會得到什么結果?
- 1.12 說一說你對面向對象的理解
- 面向對象
- 1.13 面向對象的三大特征是什么?
- 1.14 封裝的目的是什么,為什么要有封裝?
- 1.15 說一說你對多態的理解
- 1.16 Java中的多態是怎么實現的?
- 1.17 Java為什么是單繼承,為什么不能多繼承?
- 1.18 說一說重寫與重載的區別
- 1.19 構造方法能不能重寫?
- 1.20 介紹一下Object類中的方法
- 1.21 說一說hashCode()和equals()的關系
- 1.22 為什么要重寫hashCode()和equals()?
- 1.23 ==和equals()有什么區別?
- String
- 1.24 String類有哪些方法?
- 1.25 String可以被繼承嗎?
- 1.26 說一說String和StringBuffer有什么區別
- 1.27 說一說StringBuffer和StringBuilder有什么區別
- 1.28 使用字符串時,new和""推薦使用哪種方式?
- 1.29 說一說你對字符串拼接的理解
- 1.30 兩個字符串相加的底層是如何實現的?
- 1.31 String a = "abc"; ,說一下這個過程會創建什么,放在哪里?
- 1.32 new String("abc") 是去了哪里,僅僅是在堆里面嗎?
- 1.33 接口和抽象類有什么區別?
- 1.34 接口中可以有構造函數嗎?
- 1.35 談談你對面向接口編程的理解
- 異常
- 1.36 遇到過異常嗎,如何處理?
- 1.37 說一說Java的異常機制
- 1.38 請介紹Java的異常接口
- 1.39 finally是無條件執行的嗎?
- 1.40 在finally中return會發生什么?
- static
- 1.41 說一說你對static關鍵字的理解
- 1.42 static修飾的類能不能被繼承?
- 1.43 static和final有什么區別?
- 泛型
- 1.44 說一說你對泛型的理解
- 1.45 介紹一下泛型擦除
- 1.46 List<? super T>和List<? extends T>有什么區別?
- 反射
- 1.47 說一說你對Java反射機制的理解
- 1.48 Java反射在實際項目中有哪些應用場景?
- 1.49 說一說Java的四種引用方式
- 2. 集合類
- 2.1 Java中有哪些容器(集合類)?
- 2.2 Java中的容器,線程安全和線程不安全的分別有哪些?
- 2.3 Map接口有哪些實現類?
- 2.4 描述一下Map put的過程
- 2.5 如何得到一個線程安全的Map?
- 2.6 HashMap有什么特點?
- 2.7 JDK7和JDK8中的HashMap有什么區別?
- 2.8 介紹一下HashMap底層的實現原理
- 2.9 介紹一下HashMap的擴容機制
- 2.10 HashMap中的循環鏈表是如何產生的?
- 2.11 HashMap為什么用紅黑樹而不用B樹?
- 2.12 HashMap為什么線程不安全?
- 2.13 HashMap如何實現線程安全?
- 2.14 HashMap是如何解決哈希沖突的?
- 2.15 說一說HashMap和HashTable的區別
- 2.16 HashMap與ConcurrentHashMap有什么區別?
- 2.17 介紹一下ConcurrentHashMap是怎么實現的?
- 2.18 ConcurrentHashMap是怎么分段分組的?
- 2.19 說一說你對LinkedHashMap的理解
- 2.20 請介紹LinkedHashMap的底層原理
- 2.21 請介紹TreeMap的底層原理
- 2.22 Map和Set有什么區別?
- 2.23 List和Set有什么區別?
- 2.24 ArrayList和LinkedList有什么區別?
- 2.25 有哪些線程安全的List?
- 2.26 介紹一下ArrayList的數據結構?
- 2.27 談談CopyOnWriteArrayList的原理
- 2.28 說一說TreeSet和HashSet的區別
- 2.29 說一說HashSet的底層結構
- 2.30 BlockingQueue中有哪些方法,為什么這樣設計?
- 2.31 BlockingQueue是怎么實現的?
- 2.32 Stream(不是IOStream)有哪些方法?
- 3. IO
- 3.1 介紹一下Java中的IO流
- 3.2 怎么用流打開一個大文件?
- 3.4 說說NIO的實現原理
- 3.5 介紹一下Java的序列化與反序列化
- 3.6 Serializable接口為什么需要定義serialVersionUID變量?
- 3.7 除了Java自帶的序列化之外,你還了解哪些序列化工具?
- 3.8 如果不用JSON工具,該如何實現對實體類的序列化?
- 3.7 除了Java自帶的序列化之外,你還了解哪些序列化工具?
- 3.8 如果不用JSON工具,該如何實現對實體類的序列化?
1. Java基礎
1.1 為什么Java代碼可以實現一次編寫、到處運行?
參考答案
JVM(Java虛擬機)是Java跨平臺的關鍵。
在程序運行前,Java源代碼(.java)需要經過編譯器編譯成字節碼(.class)。在程序運行時,JVM負責將字節碼翻譯成特定平臺下的機器碼并運行,也就是說,只要在不同的平臺上安裝對應的JVM,就可以運行字節碼文件。
同一份Java源代碼在不同的平臺上運行,它不需要做任何的改變,并且只需要編譯一次。而編譯好的字節碼,是通過JVM這個中間的“橋梁”實現跨平臺的,JVM是與平臺相關的軟件,它能將統一的字節碼翻譯成該平臺的機器碼。
注意事項
- 編譯的結果是生成字節碼、不是機器碼,字節碼不能直接運行,必須通過JVM翻譯成機器碼才能運行;
- 跨平臺的是Java程序、而不是JVM,JVM是用C/C++開發的軟件,不同平臺下需要安裝不同版本的JVM。
1.2 一個Java文件里可以有多個類嗎(不含內部類)?
參考答案
- 一個java文件里可以有多個類,但最多只能有一個被public修飾的類;
- 如果這個java文件中包含public修飾的類,則這個類的名稱必須和java文件名一致。
1.3 說一說你對Java訪問權限的了解
參考答案
Java語言為我們提供了三種訪問修飾符,即private、protected、public,在使用這些修飾符修飾目標時,一共可以形成四種訪問權限,即private、defalut、protected、public,注意在不加任何修飾符時為default訪問權限。
在修飾成員變量/成員方法時,該成員的四種訪問權限的含義如下:
- private:該成員可以被該類內部成員訪問;
- defalut:該成員可以被該類內部成員訪問,也可以被同一包下其他的類訪問;
- protected:該成員可以被該類內部成員訪問,也可以被同一包下其他的類訪問,還可以被它的子類訪問;
- public:該成員可以被任意包下,任意類的成員進行訪問。
在修飾類時,該類只有兩種訪問權限,對應的訪問權限的含義如下:
- defalut:該類可以被同一包下其他的類訪問;
- public:該類可以被任意包下,任意的類所訪問。
1.4 介紹一下Java的數據類型
參考答案
Java數據類型包括基本數據類型和引用數據類型兩大類。
基本數據類型有8個,可以分為4個小類,分別是整數類型(byte/short/int/long)、浮點類型(float/double)、字符類型(char)、布爾類型(boolean)。其中,4個整數類型中,int類型最為常用。2個浮點類型中,double最為常用。另外,在這8個基本類型當中,除了布爾類型之外的其他7個類型,都可以看做是數字類型,它們相互之間可以進行類型轉換。
引用類型就是對一個對象的引用,根據引用對象類型的不同,可以將引用類型分為3類,即數組、類、接口類型。引用類型本質上就是通過指針,指向堆中對象所持有的內存空間,只是Java語言不再沿用指針這個說法而已。
擴展閱讀
對于基本數據類型,你需要了解每種類型所占據的內存空間,面試官可能會追問這類問題:
- byte:1字節(8位),數據范圍是
-2^7 ~ 2^7-1。 - short:2字節(16位),數據范圍是
-2^15 ~ 2^15-1。 - int:4字節(32位),數據范圍是
-2^31 ~ 2^31-1。 - long:8字節(64位),數據范圍是
-2^63 ~ 2^63-1。 - float:4字節(32位),數據范圍大約是
-3.4*10^38 ~ 3.4*10^38。 - double:8字節(64位),數據范圍大約是
-1.8*10^308 ~ 1.8*10^308。 - char:2字節(16位),數據范圍是
\u0000 ~ \uffff。 - boolean:Java規范沒有明確的規定,不同的JVM有不同的實現機制。
對于引用數據類型,你需要了解JVM的內存分布情況,知道引用以及引用對象存放的位置,詳見JVM部分的題目。
1.5 int類型的數據范圍是多少?
參考答案
int類型占4字節(32位),數據范圍是 -2^31 ~ 2^31-1。
1.6 請介紹全局變量和局部變量的區別
參考答案
Java中的變量分為成員變量和局部變量,它們的區別如下:
成員變量:
- 成員變量是在類的范圍里定義的變量;
- 成員變量有默認初始值;
- 未被static修飾的成員變量也叫實例變量,它存儲于對象所在的堆內存中,生命周期與對象相同;
- 被static修飾的成員變量也叫類變量,它存儲于方法區中,生命周期與當前類相同。
局部變量:
- 局部變量是在方法里定義的變量;
- 局部變量沒有默認初始值;
- 局部變量存儲于棧內存中,作用的范圍結束,變量空間會自動的釋放。
注意事項
Java中沒有真正的全局變量,面試官應該是出于其他語言的習慣說全局變量的,他的本意應該是指成員變量。
1.7 請介紹一下實例變量的默認值
參考答案
實例變量若為引用數據類型,其默認值一律為null。若為基本數據類型,其默認值如下:
- byte:0
- short:0
- int:0
- long:0L
- float:0.0F
- double:0.0
- char:’\u0000’
- boolean:false
注意事項
上述默認值規則適用于所有的成員變量,所以對于類變量也是適用的。
1.8 為啥要有包裝類?
參考答案
Java語言是面向對象的語言,其設計理念是“一切皆對象”。但8種基本數據類型卻出現了例外,它們不具備對象的特性。正是為了解決這個問題,Java為每個基本數據類型都定義了一個對應的引用類型,這就是包裝類。
擴展閱讀
Java之所以提供8種基本數據類型,主要是為了照顧程序員的傳統習慣。這8種基本數據類型的確帶來了一定的方便性,但在某些時候也會受到一些制約。比如,所有的引用類型的變量都繼承于Object類,都可以當做Object類型的變量使用,但基本數據類型卻不可以。如果某個方法需要Object類型的參數,但實際傳入的值卻是數字的話,就需要做特殊的處理了。有了包裝類,這種問題就可以得以簡化。
1.9 說一說自動裝箱、自動拆箱的應用場景
參考答案
自動裝箱、自動拆箱是JDK1.5提供的功能。
自動裝箱:可以把一個基本類型的數據直接賦值給對應的包裝類型;
自動拆箱:可以把一個包裝類型的對象直接賦值給對應的基本類型;
通過自動裝箱、自動拆箱功能,可以大大簡化基本類型變量和包裝類對象之間的轉換過程。比如,某個方法的參數類型為包裝類型,調用時我們所持有的數據卻是基本類型的值,則可以不做任何特殊的處理,直接將這個基本類型的值傳入給方法即可。
1.10 如何對Integer和Double類型判斷相等?
參考答案
Integer、Double不能直接進行比較,這包括:
- 不能用==進行直接比較,因為它們是不同的數據類型;
- 不能轉為字符串進行比較,因為轉為字符串后,浮點值帶小數點,整數值不帶,這樣它們永遠都不相等;
- 不能使用compareTo方法進行比較,雖然它們都有compareTo方法,但該方法只能對相同類型進行比較。
整數、浮點類型的包裝類,都繼承于Number類型,而Number類型分別定義了將數字轉換為byte、short、int、long、float、double的方法。所以,可以將Integer、Double先轉為轉換為相同的基本數據類型(如double),然后使用==進行比較。
示例代碼
Integer i = 100;
Double d = 100.00;
System.out.println(i.doubleValue() == d.doubleValue());
1.11 int和Integer有什么區別,二者在做==運算時會得到什么結果?
參考答案
int是基本數據類型,Integer是int的包裝類。二者在做==運算時,Integer會自動拆箱為int類型,然后再進行比較。屆時,如果兩個int值相等則返回true,否則就返回false。
1.12 說一說你對面向對象的理解
參考答案
面向對象是一種更優秀的程序設計方法,它的基本思想是使用類、對象、繼承、封裝、消息等基本概念進行程序設計。它從現實世界中客觀存在的事物出發來構造軟件系統,并在系統構造中盡可能運用人類的自然思維方式,強調直接以現實世界中的事物為中心來思考,認識問題,并根據這些事物的本質特點,把它們抽象地表示為系統中的類,作為系統的基本構成單元,這使得軟件系統的組件可以直接映像到客觀世界,并保持客觀世界中事物及其相互關系的本來面貌。
擴展閱讀
結構化程序設計方法主張按功能來分析系統需求,其主要原則可概括為自頂向下、逐步求精、模塊化等。結構化程序設計首先采用結構化分析方法對系統進行需求分析,然后使用結構化設計方法對系統進行概要設計、詳細設計,最后采用結構化編程方法來實現系統。
因為結構化程序設計方法主張按功能把軟件系統逐步細分,因此這種方法也被稱為面向功能的程序設計方法;結構化程序設計的每個功能都負責對數據進行一次處理,每個功能都接受一些數據,處理完后輸出一些數據,這種處理方式也被稱為面向數據流的處理方式。
結構化程序設計里最小的程序單元是函數,每個函數都負責完成一個功能,用以接收一些輸入數據,函數對這些輸入數據進行處理,處理結束后輸出一些數據。整個軟件系統由一個個函數組成,其中作為程序入口的函數被稱為主函數,主函數依次調用其他普通函數,普通函數之間依次調用,從而完成整個軟件系統的功能。
每個函數都是具有輸入、輸出的子系統,函數的輸入數據包括函數形參、全局變量和常量等,函數的輸出數據包括函數返回值以及傳出參數等。結構化程序設計方式有如下兩個局限性:
- 設計不夠直觀,與人類習慣思維不一致。采用結構化程序分析、設計時,開發者需要將客觀世界模型分解成一個個功能,每個功能用以完成一定的數據處理。
- 適應性差,可擴展性不強。由于結構化設計采用自頂向下的設計方式,所以當用戶的需求發生改變,或需要修改現有的實現方式時,都需要自頂向下地修改模塊結構,這種方式的維護成本相當高。
面向對象
1.13 面向對象的三大特征是什么?
參考答案
面向對象的程序設計方法具有三個基本特征:封裝、繼承、多態。其中,封裝指的是將對象的實現細節隱藏起來,然后通過一些公用方法來暴露該對象的功能;繼承是面向對象實現軟件復用的重要手段,當子類繼承父類后,子類作為一種特殊的父類,將直接獲得父類的屬性和方法;多態指的是子類對象可以直接賦給父類變量,但運行時依然表現出子類的行為特征,這意味著同一個類型的對象在執行同一個方法時,可能表現出多種行為特征。
擴展閱讀
抽象也是面向對象的重要部分,抽象就是忽略一個主題中與當前目標無關的那些方面,以便更充分地注意與當前目標有關的方面。抽象并不打算了解全部問題,而只是考慮部分問題。例如,需要考察Person對象時,不可能在程序中把Person的所有細節都定義出來,通常只能定義Person的部分數據、部分行為特征,而這些數據、行為特征是軟件系統所關心的部分。
1.14 封裝的目的是什么,為什么要有封裝?
參考答案
封裝是面向對象編程語言對客觀世界的模擬,在客觀世界里,對象的狀態信息都被隱藏在對象內部,外界無法直接操作和修改。對一個類或對象實現良好的封裝,可以實現以下目的:
- 隱藏類的實現細節;
- 讓使用者只能通過事先預定的方法來訪問數據,從而可以在該方法里加入控制邏輯,限制對成員變量的不合理訪問;
- 可進行數據檢查,從而有利于保證對象信息的完整性;
- 便于修改,提高代碼的可維護性。
擴展閱讀
為了實現良好的封裝,需要從兩個方面考慮:
- 將對象的成員變量和實現細節隱藏起來,不允許外部直接訪問;
- 把方法暴露出來,讓方法來控制對這些成員變量進行安全的訪問和操作。
封裝實際上有兩個方面的含義:把該隱藏的隱藏起來,把該暴露的暴露出來。這兩個方面都需要通過使用Java提供的訪問控制符來實現。
1.15 說一說你對多態的理解
參考答案
因為子類其實是一種特殊的父類,因此Java允許把一個子類對象直接賦給一個父類引用變量,無須任何類型轉換,或者被稱為向上轉型,向上轉型由系統自動完成。
當把一個子類對象直接賦給父類引用變量時,例如 BaseClass obj = new SubClass();,這個obj引用變量的編譯時類型是BaseClass,而運行時類型是SubClass,當運行時調用該引用變量的方法時,其方法行為總是表現出子類方法的行為特征,而不是父類方法的行為特征,這就可能出現:相同類型的變量、調用同一個方法時呈現出多種不同的行為特征,這就是多態。
擴展閱讀
多態可以提高程序的可擴展性,在設計程序時讓代碼更加簡潔而優雅。
例如我要設計一個司機類,他可以開轎車、巴士、卡車等等,示例代碼如下:
class Driver {void drive(Car car) { ... }void drive(Bus bus) { ... }void drive(Truck truck) { ... }
}
在設計上述代碼時,我已采用了重載機制,將方法名進行了統一。這樣在進行調用時,無論要開什么交通工具,都是通過 driver.drive(obj) 這樣的方式來調用,對調用者足夠的友好。
但對于程序的開發者來說,這顯得繁瑣,因為實際上這個司機可以駕駛更多的交通工具。當系統需要為這個司機增加車型時,開發者就需要相應的增加driver方法,類似的代碼會堆積的越來越多,顯得臃腫。
采用多態的方式來設計上述程序,就會變得簡潔很多。我們可以為所有的交通工具定義一個父類Vehicle,然后按照如下的方式設計drive方法。調用時,我們可以傳入Vehicle類型的實例,也可以傳入任意的Vechile子類型的實例,對于調用者來說一樣的方便,但對于開發者來說,代碼卻變得十分的簡潔了。
class Driver {void drive(Vehicle vehicle) { ... }
}
1.16 Java中的多態是怎么實現的?
參考答案
多態的實現離不開繼承,在設計程序時,我們可以將參數的類型定義為父類型。在調用程序時,則可以根據實際情況,傳入該父類型的某個子類型的實例,這樣就實現了多態。對于父類型,可以有三種形式,即普通的類、抽象類、接口。對于子類型,則要根據它自身的特征,重寫父類的某些方法,或實現抽象類/接口的某些抽象方法。
1.17 Java為什么是單繼承,為什么不能多繼承?
參考答案
首先,Java是單繼承的,指的是Java中一個類只能有一個直接的父類。Java不能多繼承,則是說Java中一個類不能直接繼承多個父類。
其次,Java在設計時借鑒了C++的語法,而C++是支持多繼承的。Java語言之所以摒棄了多繼承的這項特征,是因為多繼承容易產生混淆。比如,兩個父類中包含相同的方法時,子類在調用該方法或重寫該方法時就會迷惑。
準確來說,Java是可以實現"多繼承"的。因為盡管一個類只能有一個直接父類,但是卻可以有任意多個間接的父類。這樣的設計方式,避免了多繼承時所產生的混淆。
1.18 說一說重寫與重載的區別
參考答案
重載發生在同一個類中,若多個方法之間方法名相同、參數列表不同,則它們構成重載的關系。重載與方法的返回值以及訪問修飾符無關,即重載的方法不能根據返回類型進行區分。
重寫發生在父類子類中,若子類方法想要和父類方法構成重寫關系,則它的方法名、參數列表必須與父類方法相同。另外,返回值要小于等于父類方法,拋出的異常要小于等于父類方法,訪問修飾符則要大于等于父類方法。還有,若父類方法的訪問修飾符為private,則子類不能對其重寫。
1.19 構造方法能不能重寫?
參考答案
構造方法不能重寫。因為構造方法需要和類保持同名,而重寫的要求是子類方法要和父類方法保持同名。如果允許重寫構造方法的話,那么子類中將會存在與類名不同的構造方法,這與構造方法的要求是矛盾的。
1.20 介紹一下Object類中的方法
參考答案
Object類提供了如下幾個常用方法:
- Class<?> getClass():返回該對象的運行時類。
- boolean equals(Object obj):判斷指定對象與該對象是否相等。
- int hashCode():返回該對象的hashCode值。在默認情況下,Object類的hashCode()方法根據該對象的地址來計算。但很多類都重寫了Object類的hashCode()方法,不再根據地址來計算其hashCode()方法值。
- String toString():返回該對象的字符串表示,當程序使用System.out.println()方法輸出一個對象,或者把某個對象和字符串進行連接運算時,系統會自動調用該對象的toString()方法返回該對象的字符串表示。Object類的toString()方法返回
運行時類名@十六進制hashCode值格式的字符串,但很多類都重寫了Object類的toString()方法,用于返回可以表述該對象信息的字符串。
另外,Object類還提供了wait()、notify()、notifyAll()這幾個方法,通過這幾個方法可以控制線程的暫停和運行。Object類還提供了一個clone()方法,該方法用于幫助其他對象來實現“自我克隆”,所謂“自我克隆”就是得到一個當前對象的副本,而且二者之間完全隔離。由于該方法使用了protected修飾,因此它只能被子類重寫或調用。
擴展閱讀
Object類還提供了一個finalize()方法,當系統中沒有引用變量引用到該對象時,垃圾回收器調用此方法來清理該對象的資源。并且,針對某一個對象,垃圾回收器最多只會調用它的finalize()方法一次。
注意,finalize()方法何時調用、是否調用都是不確定的,我們也不要主動調用finalize()方法。從JDK9開始,這個方法被標記為不推薦使用的方法。
1.21 說一說hashCode()和equals()的關系
參考答案
hashCode()用于獲取哈希碼(散列碼),eauqls()用于比較兩個對象是否相等,它們應遵守如下規定:
- 如果兩個對象相等,則它們必須有相同的哈希碼。
- 如果兩個對象有相同的哈希碼,則它們未必相等。
擴展閱讀
在Java中,Set接口代表無序的、元素不可重復的集合,HashSet則是Set接口的典型實現。
當向HashSet中加入一個元素時,它需要判斷集合中是否已經包含了這個元素,從而避免重復存儲。由于這個判斷十分的頻繁,所以要講求效率,絕不能采用遍歷集合逐個元素進行比較的方式。實際上,HashSet是通過獲取對象的哈希碼,以及調用對象的equals()方法來解決這個判斷問題的。
HashSet首先會調用對象的hashCode()方法獲取其哈希碼,并通過哈希碼確定該對象在集合中存放的位置。假設這個位置之前已經存了一個對象,則HashSet會調用equals()對兩個對象進行比較。若相等則說明對象重復,此時不會保存新加的對象。若不等說明對象不重復,但是它們存儲的位置發生了碰撞,此時HashSet會采用鏈式結構在同一位置保存多個對象,即將新加對象鏈接到原來對象的之后。之后,再有新添加對象也映射到這個位置時,就需要與這個位置中所有的對象進行equals()比較,若均不相等則將其鏈到最后一個對象之后。
1.22 為什么要重寫hashCode()和equals()?
參考答案
Object類提供的equals()方法默認是用==來進行比較的,也就是說只有兩個對象是同一個對象時,才能返回相等的結果。而實際的業務中,我們通常的需求是,若兩個不同的對象它們的內容是相同的,就認為它們相等。鑒于這種情況,Object類中equals()方法的默認實現是沒有實用價值的,所以通常都要重寫。
由于hashCode()與equals()具有聯動關系(參考“說一說hashCode()和equals()的關系”一題),所以equals()方法重寫時,通常也要將hashCode()進行重寫,使得這兩個方法始終滿足相關的約定。
1.23 ==和equals()有什么區別?
參考答案
==運算符:
- 作用于基本數據類型時,是比較兩個數值是否相等;
- 作用于引用數據類型時,是比較兩個對象的內存地址是否相同,即判斷它們是否為同一個對象;
equals()方法:
- 沒有重寫時,Object默認以
==來實現,即比較兩個對象的內存地址是否相同; - 進行重寫后,一般會按照對象的內容來進行比較,若兩個對象內容相同則認為對象相等,否則認為對象不等。
String
1.24 String類有哪些方法?
參考答案
String類是Java最常用的API,它包含了大量處理字符串的方法,比較常用的有:
- char charAt(int index):返回指定索引處的字符;
- String substring(int beginIndex, int endIndex):從此字符串中截取出一部分子字符串;
- String[] split(String regex):以指定的規則將此字符串分割成數組;
- String trim():刪除字符串前導和后置的空格;
- int indexOf(String str):返回子串在此字符串首次出現的索引;
- int lastIndexOf(String str):返回子串在此字符串最后出現的索引;
- boolean startsWith(String prefix):判斷此字符串是否以指定的前綴開頭;
- boolean endsWith(String suffix):判斷此字符串是否以指定的后綴結尾;
- String toUpperCase():將此字符串中所有的字符大寫;
- String toLowerCase():將此字符串中所有的字符小寫;
- String replaceFirst(String regex, String replacement):用指定字符串替換第一個匹配的子串;
- String replaceAll(String regex, String replacement):用指定字符串替換所有的匹配的子串。
注意事項
String類的方法太多了,你沒必要都記下來,更不需要一一列舉。面試時能說出一些常用的方法,表現出對這個類足夠的熟悉就可以了。另外,建議你挑幾個方法仔細看看源碼實現,面試時可以重點說這幾個方法。
1.25 String可以被繼承嗎?
參考答案
String類由final修飾,所以不能被繼承。
擴展閱讀
在Java中,String類被設計為不可變類,主要表現在它保存字符串的成員變量是final的。
- Java 9之前字符串采用char[]數組來保存字符,即
private final char[] value; - Java 9做了改進,采用byte[]數組來保存字符,即
private final byte[] value;
之所以要把String類設計為不可變類,主要是出于安全和性能的考慮,可歸納為如下4點。
- 由于字符串無論在任何 Java 系統中都廣泛使用,會用來存儲敏感信息,如賬號,密碼,網絡路徑,文件處理等場景里,保證字符串 String 類的安全性就尤為重要了,如果字符串是可變的,容易被篡改,那我們就無法保證使用字符串進行操作時,它是安全的,很有可能出現 SQL 注入,訪問危險文件等操作。
- 在多線程中,只有不變的對象和值是線程安全的,可以在多個線程中共享數據。由于 String 天然的不可變,當一個線程”修改“了字符串的值,只會產生一個新的字符串對象,不會對其他線程的訪問產生副作用,訪問的都是同樣的字符串數據,不需要任何同步操作。
- 字符串作為基礎的數據結構,大量地應用在一些集合容器之中,尤其是一些散列集合,在散列集合中,存放元素都要根據對象的
hashCode()方法來確定元素的位置。由于字符串hashcode屬性不會變更,保證了唯一性,使得類似 HashMap,HashSet 等容器才能實現相應的緩存功能。由于 String 的不可變,避免重復計算hashcode,只要使用緩存的hashcode即可,這樣一來大大提高了在散列集合中使用 String 對象的性能。 - 當字符串不可變時,字符串常量池才有意義。字符串常量池的出現,可以減少創建相同字面量的字符串,讓不同的引用指向池中同一個字符串,為運行時節約很多的堆內存。若字符串可變,字符串常量池失去意義,基于常量池的
String.intern()方法也失效,每次創建新的字符串將在堆內開辟出新的空間,占據更多的內存。
因為要保證String類的不可變,那么將這個類定義為final的就很容易理解了。如果沒有final修飾,那么就會存在String的子類,這些子類可以重寫String類的方法,強行改變字符串的值,這便違背了String類設計的初衷。
1.26 說一說String和StringBuffer有什么區別
參考答案
String類是不可變類,即一旦一個String對象被創建以后,包含在這個對象中的字符序列是不可改變的,直至這個對象被銷毀。
StringBuffer對象則代表一個字符序列可變的字符串,當一個StringBuffer被創建以后,通過StringBuffer提供的append()、insert()、reverse()、setCharAt()、setLength()等方法可以改變這個字符串對象的字符序列。一旦通過StringBuffer生成了最終想要的字符串,就可以調用它的toString()方法將其轉換為一個String對象。
1.27 說一說StringBuffer和StringBuilder有什么區別
參考答案
StringBuffer、StringBuilder都代表可變的字符串對象,它們有共同的父類 AbstractStringBuilder,并且兩個類的構造方法和成員方法也基本相同。不同的是,StringBuffer是線程安全的,而StringBuilder是非線程安全的,所以StringBuilder性能略高。一般情況下,要創建一個內容可變的字符串,建議優先考慮StringBuilder類。
1.28 使用字符串時,new和""推薦使用哪種方式?
參考答案
先看看 "hello" 和 new String("hello") 的區別:
- 當Java程序直接使用
"hello"的字符串直接量時,JVM將會使用常量池來管理這個字符串; - 當使用
new String("hello")時,JVM會先使用常量池來管理"hello"直接量,再調用String類的構造器來創建一個新的String對象,新創建的String對象被保存在堆內存中。
顯然,采用new的方式會多創建一個對象出來,會占用更多的內存,所以一般建議使用直接量的方式創建字符串。
1.29 說一說你對字符串拼接的理解
參考答案
拼接字符串有很多種方式,其中最常用的有4種,下面列舉了這4種方式各自適合的場景。
+運算符:如果拼接的都是字符串直接量,則適合使用+運算符實現拼接;- StringBuilder:如果拼接的字符串中包含變量,并不要求線程安全,則適合使用StringBuilder;
- StringBuffer:如果拼接的字符串中包含變量,并且要求線程安全,則適合使用StringBuffer;
- String類的concat方法:如果只是對兩個字符串進行拼接,并且包含變量,則適合使用concat方法;
擴展閱讀
采用 + 運算符拼接字符串時:
- 如果拼接的都是字符串直接量,則在編譯時編譯器會將其直接優化為一個完整的字符串,和你直接寫一個完整的字符串是一樣的,所以效率非常的高。
- 如果拼接的字符串中包含變量,則在編譯時編譯器采用StringBuilder對其進行優化,即自動創建StringBuilder實例并調用其append()方法,將這些字符串拼接在一起,效率也很高。但如果這個拼接操作是在循環中進行的,那么每次循環編譯器都會創建一個StringBuilder實例,再去拼接字符串,相當于執行了
new StringBuilder().append(str),所以此時效率很低。
采用StringBuilder/StringBuffer拼接字符串時:
- StringBuilder/StringBuffer都有字符串緩沖區,緩沖區的容量在創建對象時確定,并且默認為16。當拼接的字符串超過緩沖區的容量時,會觸發緩沖區的擴容機制,即緩沖區加倍。
- 緩沖區頻繁的擴容會降低拼接的性能,所以如果能提前預估最終字符串的長度,則建議在創建可變字符串對象時,放棄使用默認的容量,可以指定緩沖區的容量為預估的字符串的長度。
采用String類的concat方法拼接字符串時:
- concat方法的拼接邏輯是,先創建一個足以容納待拼接的兩個字符串的字節數組,然后先后將兩個字符串拼到這個數組里,最后將此數組轉換為字符串。
- 在拼接大量字符串的時候,concat方法的效率低于StringBuilder。但是只拼接2個字符串時,concat方法的效率要優于StringBuilder。并且這種拼接方式代碼簡潔,所以只拼2個字符串時建議優先選擇concat方法。
1.30 兩個字符串相加的底層是如何實現的?
參考答案
如果拼接的都是字符串直接量,則在編譯時編譯器會將其直接優化為一個完整的字符串,和你直接寫一個完整的字符串是一樣的。
如果拼接的字符串中包含變量,則在編譯時編譯器采用StringBuilder對其進行優化,即自動創建StringBuilder實例并調用其append()方法,將這些字符串拼接在一起。
1.31 String a = “abc”; ,說一下這個過程會創建什么,放在哪里?
參考答案
JVM會使用常量池來管理字符串直接量。在執行這句話時,JVM會先檢查常量池中是否已經存有"abc",若沒有則將"abc"存入常量池,否則就復用常量池中已有的"abc",將其引用賦值給變量a。
1.32 new String(“abc”) 是去了哪里,僅僅是在堆里面嗎?
參考答案
在執行這句話時,JVM會先使用常量池來管理字符串直接量,即將"abc"存入常量池。然后再創建一個新的String對象,這個對象會被保存在堆內存中。并且,堆中對象的數據會指向常量池中的直接量。
1.33 接口和抽象類有什么區別?
參考答案
從設計目的上來說,二者有如下的區別:
接口體現的是一種規范。對于接口的實現者而言,接口規定了實現者必須向外提供哪些服務;對于接口的調用者而言,接口規定了調用者可以調用哪些服務,以及如何調用這些服務。當在一個程序中使用接口時,接口是多個模塊間的耦合標準;當在多個應用程序之間使用接口時,接口是多個程序之間的通信標準。
抽象類體現的是一種模板式設計。抽象類作為多個子類的抽象父類,可以被當成系統實現過程中的中間產品,這個中間產品已經實現了系統的部分功能,但這個產品依然不能當成最終產品,必須有更進一步的完善,這種完善可能有幾種不同方式。
從使用方式上來說,二者有如下的區別:
- 接口里只能包含抽象方法、靜態方法、默認方法和私有方法,不能為普通方法提供方法實現;抽象類則完全可以包含普通方法。
- 接口里只能定義靜態常量,不能定義普通成員變量;抽象類里則既可以定義普通成員變量,也可以定義靜態常量。
- 接口里不包含構造器;抽象類里可以包含構造器,抽象類里的構造器并不是用于創建對象,而是讓其子類調用這些構造器來完成屬于抽象類的初始化操作。
- 接口里不能包含初始化塊;但抽象類則完全可以包含初始化塊。
- 一個類最多只能有一個直接父類,包括抽象類;但一個類可以直接實現多個接口,通過實現多個接口可以彌補Java單繼承的不足。
擴展閱讀
接口和抽象類很像,它們都具有如下共同的特征:
- 接口和抽象類都不能被實例化,它們都位于繼承樹的頂端,用于被其他類實現和繼承。
- 接口和抽象類都可以包含抽象方法,實現接口或繼承抽象類的普通子類都必須實現這些抽象方法。
1.34 接口中可以有構造函數嗎?
參考答案
由于接口定義的是一種規范,因此接口里不能包含構造器和初始化塊定義。接口里可以包含成員變量(只能是靜態常量)、方法(只能是抽象實例方法、類方法、默認方法或私有方法)、內部類(包括內部接口、枚舉)定義。
1.35 談談你對面向接口編程的理解
參考答案
接口體現的是一種規范和實現分離的設計哲學,充分利用接口可以極好地降低程序各模塊之間的耦合,從而提高系統的可擴展性和可維護性。基于這種原則,很多軟件架構設計理論都倡導“面向接口”編程,而不是面向實現類編程,希望通過面向接口編程來降低程序的耦合。
異常
1.36 遇到過異常嗎,如何處理?
參考答案
在Java中,可以按照如下三個步驟處理異常:
-
捕獲異常
將業務代碼包裹在try塊內部,當業務代碼中發生任何異常時,系統都會為此異常創建一個異常對象。創建異常對象之后,JVM會在try塊之后尋找可以處理它的catch塊,并將異常對象交給這個catch塊處理。
-
處理異常
在catch塊中處理異常時,應該先記錄日志,便于以后追溯這個異常。然后根據異常的類型、結合當前的業務情況,進行相應的處理。比如,給變量賦予一個默認值、直接返回空值、向外拋出一個新的業務異常交給調用者處理,等等。
-
回收資源
如果業務代碼打開了某個資源,比如數據庫連接、網絡連接、磁盤文件等,則需要在這段業務代碼執行完畢后關閉這項資源。并且,無論是否發生異常,都要嘗試關閉這項資源。將關閉資源的代碼寫在finally塊內,可以滿足這種需求,即無論是否發生異常,finally塊內的代碼總會被執行。
1.37 說一說Java的異常機制
參考答案
關于異常處理:
在Java中,處理異常的語句由try、catch、finally三部分組成。其中,try塊用于包裹業務代碼,catch塊用于捕獲并處理某個類型的異常,finally塊則用于回收資源。當業務代碼發生異常時,系統會創建一個異常對象,然后由JVM尋找可以處理這個異常的catch塊,并將異常對象交給這個catch塊處理。若業務代碼打開了某項資源,則可以在finally塊中關閉這項資源,因為無論是否發生異常,finally塊一定會執行。
關于拋出異常:
當程序出現錯誤時,系統會自動拋出異常。除此以外,Java也允許程序主動拋出異常。當業務代碼中,判斷某項錯誤的條件成立時,可以使用throw關鍵字向外拋出異常。在這種情況下,如果當前方法不知道該如何處理這個異常,可以在方法簽名上通過throws關鍵字聲明拋出異常,則該異常將交給JVM處理。
關于異常跟蹤棧:
程序運行時,經常會發生一系列方法調用,從而形成方法調用棧。異常機制會導致異常在這些方法之間傳播,而異常傳播的順序與方法的調用相反。異常從發生異常的方法向外傳播,首先傳給該方法的調用者,再傳給上層調用者,以此類推。最終會傳到main方法,若依然沒有得到處理,則JVM會終止程序,并打印異常跟蹤棧的信息
1.38 請介紹Java的異常接口
參考答案
Throwable是異常的頂層父類,代表所有的非正常情況。它有兩個直接子類,分別是Error、Exception。
Error是錯誤,一般是指與虛擬機相關的問題,如系統崩潰、虛擬機錯誤、動態鏈接失敗等,這種錯誤無法恢復或不可能捕獲,將導致應用程序中斷。通常應用程序無法處理這些錯誤,因此應用程序不應該試圖使用catch塊來捕獲Error對象。在定義方法時,也無須在其throws子句中聲明該方法可能拋出Error及其任何子類。
Exception是異常,它被分為兩大類,分別是Checked異常和Runtime異常。所有的RuntimeException類及其子類的實例被稱為Runtime異常;不是RuntimeException類及其子類的異常實例則被稱為Checked異常。Java認為Checked異常都是可以被處理(修復)的異常,所以Java程序必須顯式處理Checked異常。如果程序沒有處理Checked異常,該程序在編譯時就會發生錯誤,無法通過編譯。Runtime異常則更加靈活,Runtime異常無須顯式聲明拋出,如果程序需要捕獲Runtime異常,也可以使用try…catch塊來實現。
1.39 finally是無條件執行的嗎?
參考答案
不管try塊中的代碼是否出現異常,也不管哪一個catch塊被執行,甚至在try塊或catch塊中執行了return語句,finally塊總會被執行。
注意事項
如果在try塊或catch塊中使用 System.exit(1); 來退出虛擬機,則finally塊將失去執行的機會。但是我們在實際的開發中,重來都不會這樣做,所以盡管存在這種導致finally塊無法執行的可能,也只是一種可能而已。
1.40 在finally中return會發生什么?
參考答案
在通常情況下,不要在finally塊中使用return、throw等導致方法終止的語句,一旦在finally塊中使用了return、throw語句,將會導致try塊、catch塊中的return、throw語句失效。
詳細解析
當Java程序執行try塊、catch塊時遇到了return或throw語句,這兩個語句都會導致該方法立即結束,但是系統執行這兩個語句并不會結束該方法,而是去尋找該異常處理流程中是否包含finally塊,如果沒有finally塊,程序立即執行return或throw語句,方法終止;如果有finally塊,系統立即開始執行finally塊。只有當finally塊執行完成后,系統才會再次跳回來執行try塊、catch塊里的return或throw語句;如果finally塊里也使用了return或throw等導致方法終止的語句,finally塊已經終止了方法,系統將不會跳回去執行try塊、catch塊里的任何代碼。
static
1.41 說一說你對static關鍵字的理解
參考答案
在Java類里只能包含成員變量、方法、構造器、初始化塊、內部類(包括接口、枚舉)5種成員,而static可以修飾成員變量、方法、初始化塊、內部類(包括接口、枚舉),以static修飾的成員就是類成員。類成員屬于整個類,而不屬于單個對象。
對static關鍵字而言,有一條非常重要的規則:類成員(包括成員變量、方法、初始化塊、內部類和內部枚舉)不能訪問實例成員(包括成員變量、方法、初始化塊、內部類和內部枚舉)。因為類成員是屬于類的,類成員的作用域比實例成員的作用域更大,完全可能出現類成員已經初始化完成,但實例成員還不曾初始化的情況,如果允許類成員訪問實例成員將會引起大量錯誤。
1.42 static修飾的類能不能被繼承?
參考答案
static修飾的類可以被繼承。
擴展閱讀
如果使用static來修飾一個內部類,則這個內部類就屬于外部類本身,而不屬于外部類的某個對象。因此使用static修飾的內部類被稱為類內部類,有的地方也稱為靜態內部類。
static關鍵字的作用是把類的成員變成類相關,而不是實例相關,即static修飾的成員屬于整個類,而不屬于單個對象。外部類的上一級程序單元是包,所以不可使用static修飾;而內部類的上一級程序單元是外部類,使用static修飾可以將內部類變成外部類相關,而不是外部類實例相關。因此static關鍵字不可修飾外部類,但可修飾內部類。
靜態內部類需滿足如下規則:
-
靜態內部類可以包含靜態成員,也可以包含非靜態成員;
-
靜態內部類不能訪問外部類的實例成員,只能訪問它的靜態成員;
-
外部類的所有方法、初始化塊都能訪問其內部定義的靜態內部類;
-
在外部類的外部,也可以實例化靜態內部類,語法如下:
外部類.內部類 變量名 = ``new外部類.內部類構造方法();
1.43 static和final有什么區別?
參考答案
static關鍵字可以修飾成員變量、成員方法、初始化塊、內部類,被static修飾的成員是類的成員,它屬于類、不屬于單個對象。以下是static修飾這4種成員時表現出的特征:
- 類變量:被static修飾的成員變量叫類變量(靜態變量)。類變量屬于類,它隨類的信息存儲在方法區,并不隨對象存儲在堆中,類變量可以通過類名來訪問,也可以通過對象名來訪問,但建議通過類名訪問它。
- 類方法:被static修飾的成員方法叫類方法(靜態方法)。類方法屬于類,可以通過類名訪問,也可以通過對象名訪問,建議通過類名訪問它。
- 靜態塊:被static修飾的初始化塊叫靜態初始化塊。靜態塊屬于類,它在類加載的時候被隱式調用一次,之后便不會被調用了。
- 靜態內部類:被static修飾的內部類叫靜態內部類。靜態內部類可以包含靜態成員,也可以包含非靜態成員。靜態內部類不能訪問外部類的實例成員,只能訪問外部類的靜態成員。外部類的所有方法、初始化塊都能訪問其內部定義的靜態內部類。
final關鍵字可以修飾類、方法、變量,以下是final修飾這3種目標時表現出的特征:
- final類:final關鍵字修飾的類不可以被繼承。
- final方法:final關鍵字修飾的方法不可以被重寫。
- final變量:final關鍵字修飾的變量,一旦獲得了初始值,就不可以被修改。
擴展閱讀
變量分為成員變量、局部變量。
final修飾成員變量:
- 類變量:可以在聲明變量時指定初始值,也可以在靜態初始化塊中指定初始值;
- 實例變量:可以在聲明變量時指定初始值,也可以在初始化塊或構造方法中指定初始值;
final修飾局部變量:
- 可以在聲明變量時指定初始值,也可以在后面的代碼中指定初始值。
注意:被 final 修飾的任何形式的變量,一旦獲得了初始值,就不可以被修改!
泛型
1.44 說一說你對泛型的理解
參考答案
Java集合有個缺點—把一個對象“丟進”集合里之后,集合就會“忘記”這個對象的數據類型,當再次取出該對象時,該對象的編譯類型就變成了Object類型(其運行時類型沒變)。
Java集合之所以被設計成這樣,是因為集合的設計者不知道我們會用集合來保存什么類型的對象,所以他們把集合設計成能保存任何類型的對象,只要求具有很好的通用性。但這樣做帶來如下兩個問題:
- 集合對元素類型沒有任何限制,這樣可能引發一些問題。例如,想創建一個只能保存Dog對象的集合,但程序也可以輕易地將Cat對象“丟”進去,所以可能引發異常。
- 由于把對象“丟進”集合時,集合丟失了對象的狀態信息,只知道它盛裝的是Object,因此取出集合元素后通常還需要進行強制類型轉換。這種強制類型轉換既增加了編程的復雜度,也可能引發ClassCastException異常。
從Java 5開始,Java引入了“參數化類型”的概念,允許程序在創建集合時指定集合元素的類型,Java的參數化類型被稱為泛型(Generic)。例如 List<String>,表明該List只能保存字符串類型的對象。
有了泛型以后,程序再也不能“不小心”地把其他對象“丟進”集合中。而且程序更加簡潔,集合自動記住所有集合元素的數據類型,從而無須對集合元素進行強制類型轉換。
1.45 介紹一下泛型擦除
參考答案
在嚴格的泛型代碼里,帶泛型聲明的類總應該帶著類型參數。但為了與老的Java代碼保持一致,也允許在使用帶泛型聲明的類時不指定實際的類型。如果沒有為這個泛型類指定實際的類型,此時被稱作raw type(原始類型),默認是聲明該泛型形參時指定的第一個上限類型。
當把一個具有泛型信息的對象賦給另一個沒有泛型信息的變量時,所有在尖括號之間的類型信息都將被扔掉。比如一個 List<String> 類型被轉換為List,則該List對集合元素的類型檢查變成了泛型參數的上限(即Object)。
上述規則即為泛型擦除,可以通過下面代碼進一步理解泛型擦除:
List<String> list1 = ...;``List list2 = list1; ``// list2將元素當做Object處理
擴展閱讀
從邏輯上來看,List<String> 是List的子類,如果直接把一個List對象賦給一個List<String>對象應該引起編譯錯誤,但實際上不會。對泛型而言,可以直接把一個List對象賦給一個 List<String> 對象,編譯器僅僅提示“未經檢查的轉換”。
上述規則叫做泛型轉換,可以通過下面代碼進一步理解泛型轉換:
List list1 = ...;``List<String> list2 = list1; ``// 編譯時警告“未經檢查的轉換”
1.46 List<? super T>和List<? extends T>有什么區別?
參考答案
- ? 是類型通配符,
List<?>可以表示各種泛型List的父類,意思是元素類型未知的List; List<? super T>用于設定類型通配符的下限,此處 ? 代表一個未知的類型,但它必須是T的父類型;List<? extends T>用于設定類型通配符的上限,此處 ? 代表一個未知的類型,但它必須是T的子類型。
擴展閱讀
在Java的早期設計中,允許把Integer[]數組賦值給Number[]變量,此時如果試圖把一個Double對象保存到該Number[]數組中,編譯可以通過,但在運行時拋出ArrayStoreException異常。這顯然是一種不安全的設計,因此Java在泛型設計時進行了改進,它不再允許把 List<Integer> 對象賦值給 List<Number> 變量。
數組和泛型有所不同,假設Foo是Bar的一個子類型(子類或者子接口),那么Foo[]依然是Bar[]的子類型,但G<Foo> 不是 G<Bar> 的子類型。Foo[]自動向上轉型為Bar[]的方式被稱為型變,也就是說,Java的數組支持型變,但Java集合并不支持型變。Java泛型的設計原則是,只要代碼在編譯時沒有出現警告,就不會遇到運行時ClassCastException異常。
反射
1.47 說一說你對Java反射機制的理解
參考答案
Java程序中的對象在運行時可以表現為兩種類型,即編譯時類型和運行時類型。例如 Person p = new Student(); ,這行代碼將會生成一個p變量,該變量的編譯時類型為Person,運行時類型為Student。
有時,程序在運行時接收到外部傳入的一個對象,該對象的編譯時類型是Object,但程序又需要調用該對象的運行時類型的方法。這就要求程序需要在運行時發現對象和類的真實信息,而解決這個問題有以下兩種做法:
- 第一種做法是假設在編譯時和運行時都完全知道類型的具體信息,在這種情況下,可以先使用instanceof運算符進行判斷,再利用強制類型轉換將其轉換成其運行時類型的變量即可。
- 第二種做法是編譯時根本無法預知該對象和類可能屬于哪些類,程序只依靠運行時信息來發現該對象和類的真實信息,這就必須使用反射。
具體來說,通過反射機制,我們可以實現如下的操作:
- 程序運行時,可以通過反射獲得任意一個類的Class對象,并通過這個對象查看這個類的信息;
- 程序運行時,可以通過反射創建任意一個類的實例,并訪問該實例的成員;
- 程序運行時,可以通過反射機制生成一個類的動態代理類或動態代理對象。
1.48 Java反射在實際項目中有哪些應用場景?
參考答案
Java的反射機制在實際項目中應用廣泛,常見的應用場景有:
- 使用JDBC時,如果要創建數據庫的連接,則需要先通過反射機制加載數據庫的驅動程序;
- 多數框架都支持注解/XML配置,從配置中解析出來的類是字符串,需要利用反射機制實例化;
- 面向切面編程(AOP)的實現方案,是在程序運行時創建目標對象的代理類,這必須由反射機制來實現。
1.49 說一說Java的四種引用方式
參考答案
Java對象的四種引用方式分別是強引用、軟引用、弱引用、虛引用,具體含義如下:
- 強引用:這是Java程序中最常見的引用方式,即程序創建一個對象,并把這個對象賦給一個引用變量,程序通過該引用變量來操作實際的對象。當一個對象被一個或一個以上的引用變量所引用時,它處于可達狀態,不可能被系統垃圾回收機制回收。
- 軟引用:當一個對象只有軟引用時,它有可能被垃圾回收機制回收。對于只有軟引用的對象而言,當系統內存空間足夠時,它不會被系統回收,程序也可使用該對象。當系統內存空間不足時,系統可能會回收它。軟引用通常用于對內存敏感的程序中。
- 弱引用:弱引用和軟引用很像,但弱引用的引用級別更低。對于只有弱引用的對象而言,當系統垃圾回收機制運行時,不管系統內存是否足夠,總會回收該對象所占用的內存。當然,并不是說當一個對象只有弱引用時,它就會立即被回收,正如那些失去引用的對象一樣,必須等到系統垃圾回收機制運行時才會被回收。
- 虛引用:虛引用完全類似于沒有引用。虛引用對對象本身沒有太大影響,對象甚至感覺不到虛引用的存在。如果一個對象只有一個虛引用時,那么它和沒有引用的效果大致相同。虛引用主要用于跟蹤對象被垃圾回收的狀態,虛引用不能單獨使用,虛引用必須和引用隊列聯合使用。
2. 集合類
2.1 Java中有哪些容器(集合類)?
參考答案
Java中的集合類主要由Collection和Map這兩個接口派生而出,其中Collection接口又派生出三個子接口,分別是Set、List、Queue。所有的Java集合類,都是Set、List、Queue、Map這四個接口的實現類,這四個接口將集合分成了四大類,其中
- Set代表無序的,元素不可重復的集合;
- List代表有序的,元素可以重復的集合;
- Queue代表先進先出(FIFO)的隊列;
- Map代表具有映射關系(key-value)的集合。
這些接口擁有眾多的實現類,其中最常用的實現類有HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap等。
擴展閱讀
Collection體系的繼承樹:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-sGP2fKP3-1641469701679)(https://gitee.com/RedemptionXU/pic-md/raw/master/20220106193852.jpeg)]
Map體系的繼承樹:
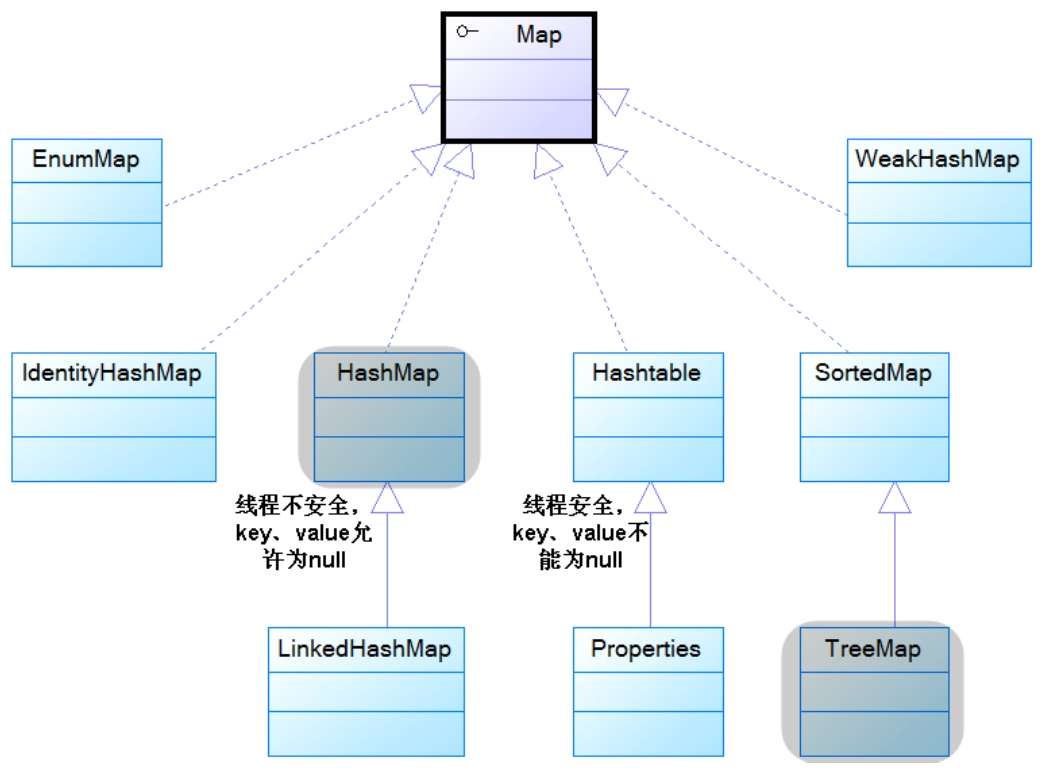
注:紫色框體代表接口,其中加粗的是代表四類集合的接口。藍色框體代表實現類,其中有陰影的是常用實現類。
2.2 Java中的容器,線程安全和線程不安全的分別有哪些?
參考答案
java.util包下的集合類大部分都是線程不安全的,例如我們常用的HashSet、TreeSet、ArrayList、LinkedList、ArrayDeque、HashMap、TreeMap,這些都是線程不安全的集合類,但是它們的優點是性能好。如果需要使用線程安全的集合類,則可以使用Collections工具類提供的synchronizedXxx()方法,將這些集合類包裝成線程安全的集合類。
java.util包下也有線程安全的集合類,例如Vector、Hashtable。這些集合類都是比較古老的API,雖然實現了線程安全,但是性能很差。所以即便是需要使用線程安全的集合類,也建議將線程不安全的集合類包裝成線程安全集合類的方式,而不是直接使用這些古老的API。
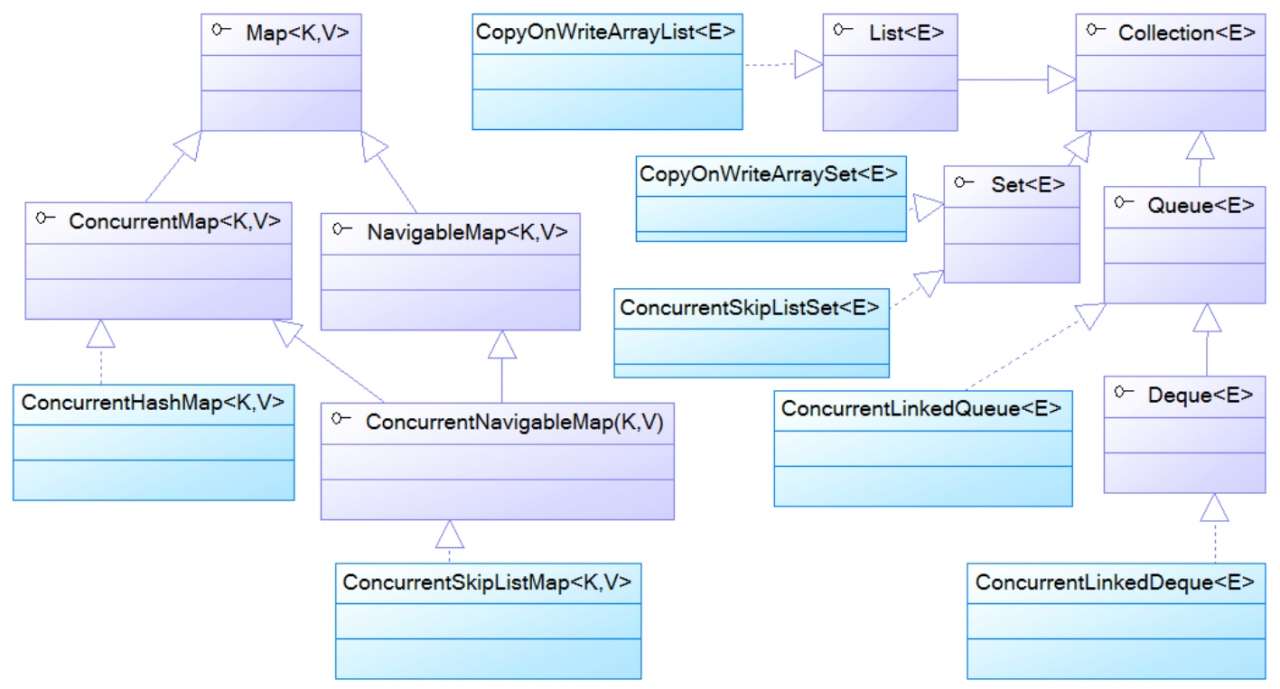
從Java5開始,Java在java.util.concurrent包下提供了大量支持高效并發訪問的集合類,它們既能包裝良好的訪問性能,有能包裝線程安全。這些集合類可以分為兩部分,它們的特征如下:
-
以Concurrent開頭的集合類:
以Concurrent開頭的集合類代表了支持并發訪問的集合,它們可以支持多個線程并發寫入訪問,這些寫入線程的所有操作都是線程安全的,但讀取操作不必鎖定。以Concurrent開頭的集合類采用了更復雜的算法來保證永遠不會鎖住整個集合,因此在并發寫入時有較好的性能。
-
以CopyOnWrite開頭的集合類:
以CopyOnWrite開頭的集合類采用復制底層數組的方式來實現寫操作。當線程對此類集合執行讀取操作時,線程將會直接讀取集合本身,無須加鎖與阻塞。當線程對此類集合執行寫入操作時,集合會在底層復制一份新的數組,接下來對新的數組執行寫入操作。由于對集合的寫入操作都是對數組的副本執行操作,因此它是線程安全的。
擴展閱讀
java.util.concurrent包下線程安全的集合類的體系結構:
2.3 Map接口有哪些實現類?
參考答案
Map接口有很多實現類,其中比較常用的有HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap。
對于不需要排序的場景,優先考慮使用HashMap,因為它是性能最好的Map實現。如果需要保證線程安全,則可以使用ConcurrentHashMap。它的性能好于Hashtable,因為它在put時采用分段鎖/CAS的加鎖機制,而不是像Hashtable那樣,無論是put還是get都做同步處理。
對于需要排序的場景,如果需要按插入順序排序則可以使用LinkedHashMap,如果需要將key按自然順序排列甚至是自定義順序排列,則可以選擇TreeMap。如果需要保證線程安全,則可以使用Collections工具類將上述實現類包裝成線程安全的Map。
2.4 描述一下Map put的過程
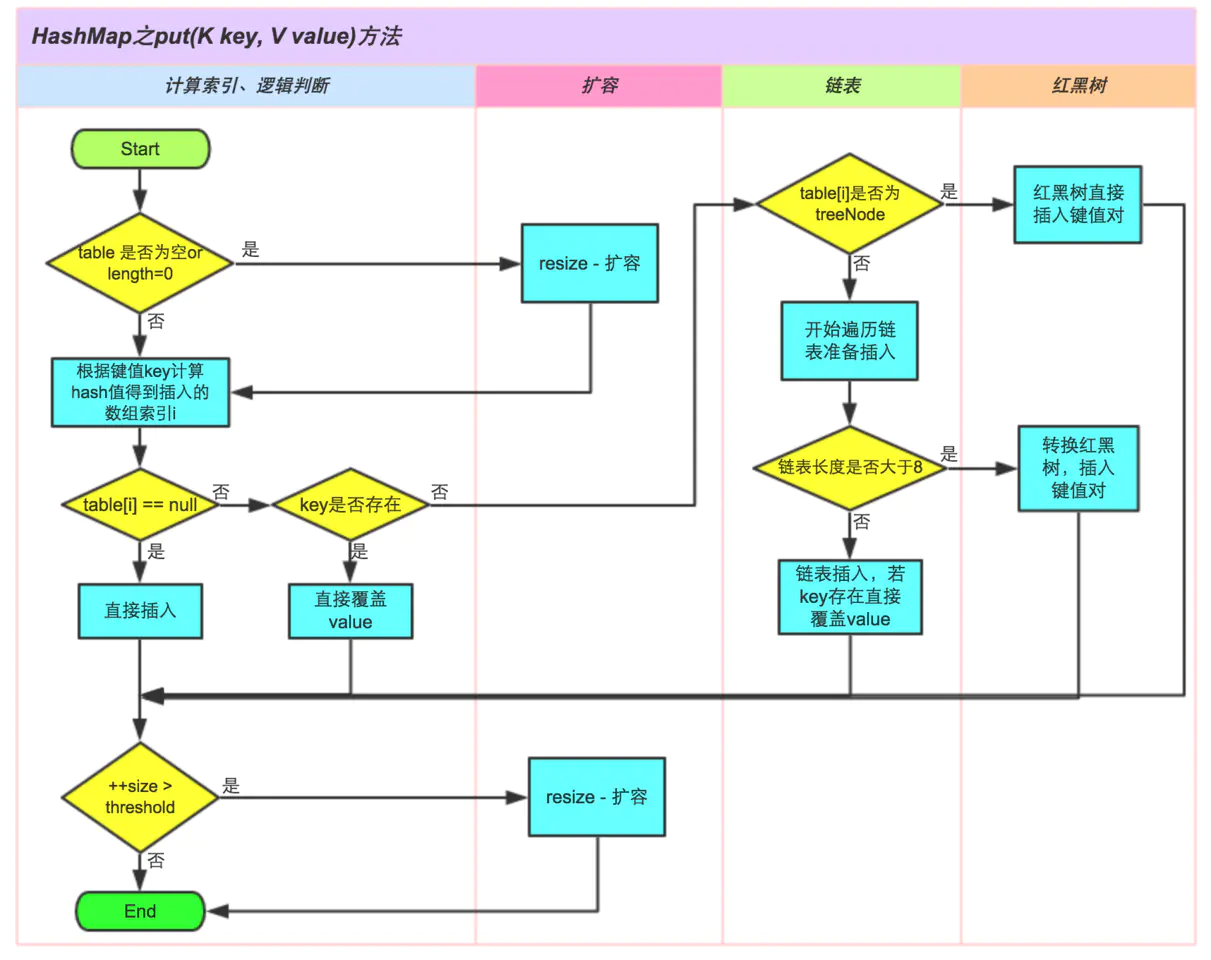
參考答案
HashMap是最經典的Map實現,下面以它的視角介紹put的過程:
-
首次擴容:
先判斷數組是否為空,若數組為空則進行第一次擴容(resize);
-
計算索引:
通過hash算法,計算鍵值對在數組中的索引;
-
插入數據:
- 如果當前位置元素為空,則直接插入數據;
- 如果當前位置元素非空,且key已存在,則直接覆蓋其value;
- 如果當前位置元素非空,且key不存在,則將數據鏈到鏈表末端;
- 若鏈表長度達到8,則將鏈表轉換成紅黑樹,并將數據插入樹中;
-
再次擴容
如果數組中元素個數(size)超過threshold,則再次進行擴容操作。
擴展閱讀
HashMap添加數據的詳細過程,如下圖:
2.5 如何得到一個線程安全的Map?
參考答案
- 使用Collections工具類,將線程不安全的Map包裝成線程安全的Map;
- 使用java.util.concurrent包下的Map,如ConcurrentHashMap;
- 不建議使用Hashtable,雖然Hashtable是線程安全的,但是性能較差。
2.6 HashMap有什么特點?
參考答案
- HashMap是線程不安全的實現;
- HashMap可以使用null作為key或value。
2.7 JDK7和JDK8中的HashMap有什么區別?
參考答案
JDK7中的HashMap,是基于數組+鏈表來實現的,它的底層維護一個Entry數組。它會根據計算的hashCode將對應的KV鍵值對存儲到該數組中,一旦發生hashCode沖突,那么就會將該KV鍵值對放到對應的已有元素的后面, 此時便形成了一個鏈表式的存儲結構。
JDK7中HashMap的實現方案有一個明顯的缺點,即當Hash沖突嚴重時,在桶上形成的鏈表會變得越來越長,這樣在查詢時的效率就會越來越低,其時間復雜度為O(N)。
JDK8中的HashMap,是基于數組+鏈表+紅黑樹來實現的,它的底層維護一個Node數組。當鏈表的存儲的數據個數大于等于8的時候,不再采用鏈表存儲,而采用了紅黑樹存儲結構。這么做主要是在查詢的時間復雜度上進行優化,鏈表為O(N),而紅黑樹一直是O(logN),可以大大的提高查找性能。
2.8 介紹一下HashMap底層的實現原理
參考答案
它基于hash算法,通過put方法和get方法存儲和獲取對象。
存儲對象時,我們將K/V傳給put方法時,它調用K的hashCode計算hash從而得到bucket位置,進一步存儲,HashMap會根據當前bucket的占用情況自動調整容量(超過Load Facotr則resize為原來的2倍)。獲取對象時,我們將K傳給get,它調用hashCode計算hash從而得到bucket位置,并進一步調用equals()方法確定鍵值對。
如果發生碰撞的時候,HashMap通過鏈表將產生碰撞沖突的元素組織起來。在Java 8中,如果一個bucket中碰撞沖突的元素超過某個限制(默認是8),則使用紅黑樹來替換鏈表,從而提高速度。
2.9 介紹一下HashMap的擴容機制
參考答案
- 數組的初始容量為16,而容量是以2的次方擴充的,一是為了提高性能使用足夠大的數組,二是為了能使用位運算代替取模預算(據說提升了5~8倍)。
- 數組是否需要擴充是通過負載因子判斷的,如果當前元素個數為數組容量的0.75時,就會擴充數組。這個0.75就是默認的負載因子,可由構造器傳入。我們也可以設置大于1的負載因子,這樣數組就不會擴充,犧牲性能,節省內存。
- 為了解決碰撞,數組中的元素是單向鏈表類型。當鏈表長度到達一個閾值時(7或8),會將鏈表轉換成紅黑樹提高性能。而當鏈表長度縮小到另一個閾值時(6),又會將紅黑樹轉換回單向鏈表提高性能。
- 對于第三點補充說明,檢查鏈表長度轉換成紅黑樹之前,還會先檢測當前數組數組是否到達一個閾值(64),如果沒有到達這個容量,會放棄轉換,先去擴充數組。所以上面也說了鏈表長度的閾值是7或8,因為會有一次放棄轉換的操作。
擴展閱讀
例如我們從16擴展為32時,具體的變化如下所示:
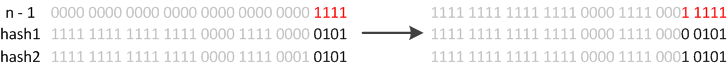
因此元素在重新計算hash之后,因為n變為2倍,那么n-1的mask范圍在高位多1bit(紅色),因此新的index就會發生這樣的變化:
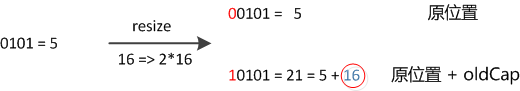
因此,我們在擴充HashMap的時候,不需要重新計算hash,只需要看看原來的hash值新增的那個bit是1還是0就好了,是0的話索引沒變,是1的話索引變成“原索引+oldCap”。可以看看下圖為16擴充為32的resize示意圖:
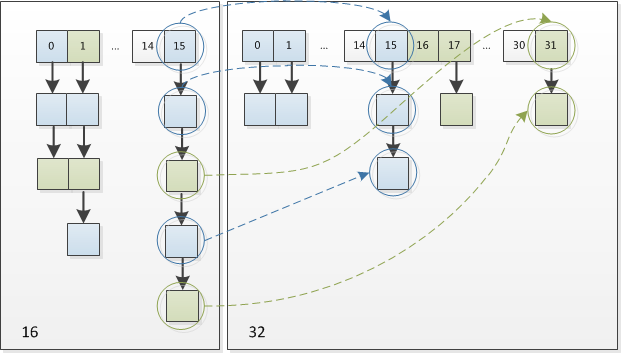
這個設計確實非常的巧妙,既省去了重新計算hash值的時間,而且同時,由于新增的1bit是0還是1可以認為是隨機的,因此resize的過程,均勻的把之前的沖突的節點分散到新的bucket了。
2.10 HashMap中的循環鏈表是如何產生的?
參考答案
在多線程的情況下,當重新調整HashMap大小的時候,就會存在條件競爭,因為如果兩個線程都發現HashMap需要重新調整大小了,它們會同時試著調整大小。在調整大小的過程中,存儲在鏈表中的元素的次序會反過來,因為移動到新的bucket位置的時候,HashMap并不會將元素放在鏈表的尾部,而是放在頭部,這是為了避免尾部遍歷。如果條件競爭發生了,那么就會產生死循環了。
2.11 HashMap為什么用紅黑樹而不用B樹?
參考答案
B/B+樹多用于外存上時,B/B+也被成為一個磁盤友好的數據結構。
HashMap本來是數組+鏈表的形式,鏈表由于其查找慢的特點,所以需要被查找效率更高的樹結構來替換。如果用B/B+樹的話,在數據量不是很多的情況下,數據都會“擠在”一個結點里面,這個時候遍歷效率就退化成了鏈表。
2.12 HashMap為什么線程不安全?
參考答案
HashMap在并發執行put操作時,可能會導致形成循環鏈表,從而引起死循環。
2.13 HashMap如何實現線程安全?
參考答案
- 直接使用Hashtable類;
- 直接使用ConcurrentHashMap;
- 使用Collections將HashMap包裝成線程安全的Map。
2.14 HashMap是如何解決哈希沖突的?
參考答案
為了解決碰撞,數組中的元素是單向鏈表類型。當鏈表長度到達一個閾值時,會將鏈表轉換成紅黑樹提高性能。而當鏈表長度縮小到另一個閾值時,又會將紅黑樹轉換回單向鏈表提高性能。
2.15 說一說HashMap和HashTable的區別
參考答案
- Hashtable是一個線程安全的Map實現,但HashMap是線程不安全的實現,所以HashMap比Hashtable的性能高一點。
- Hashtable不允許使用null作為key和value,如果試圖把null值放進Hashtable中,將會引發空指針異常,但HashMap可以使用null作為key或value。
擴展閱讀
從Hashtable的類名上就可以看出它是一個古老的類,它的命名甚至沒有遵守Java的命名規范:每個單詞的首字母都應該大寫。也許當初開發Hashtable的工程師也沒有注意到這一點,后來大量Java程序中使用了Hashtable類,所以這個類名也就不能改為HashTable了,否則將導致大量程序需要改寫。
與Vector類似的是,盡量少用Hashtable實現類,即使需要創建線程安全的Map實現類,也無須使用Hashtable實現類,可以通過Collections工具類把HashMap變成線程安全的Map。
2.16 HashMap與ConcurrentHashMap有什么區別?
參考答案
HashMap是非線程安全的,這意味著不應該在多線程中對這些Map進行修改操作,否則會產生數據不一致的問題,甚至還會因為并發插入元素而導致鏈表成環,這樣在查找時就會發生死循環,影響到整個應用程序。
Collections工具類可以將一個Map轉換成線程安全的實現,其實也就是通過一個包裝類,然后把所有功能都委托給傳入的Map,而包裝類是基于synchronized關鍵字來保證線程安全的(Hashtable也是基于synchronized關鍵字),底層使用的是互斥鎖,性能與吞吐量比較低。
ConcurrentHashMap的實現細節遠沒有這么簡單,因此性能也要高上許多。它沒有使用一個全局鎖來鎖住自己,而是采用了減少鎖粒度的方法,盡量減少因為競爭鎖而導致的阻塞與沖突,而且ConcurrentHashMap的檢索操作是不需要鎖的。
2.17 介紹一下ConcurrentHashMap是怎么實現的?
參考答案
JDK 1.7中的實現:
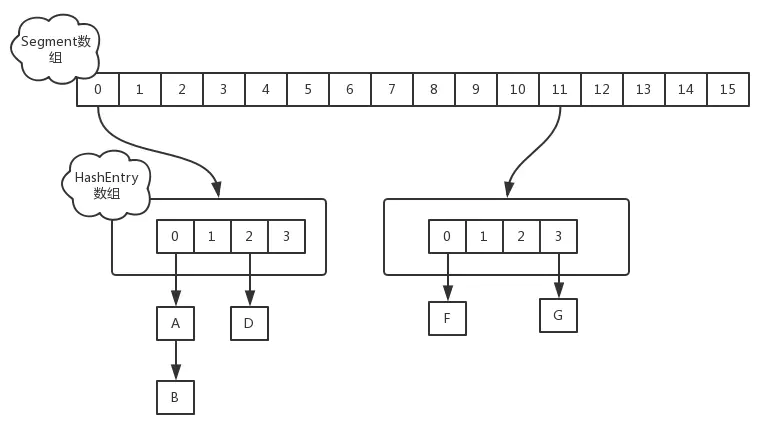
在 jdk 1.7 中,ConcurrentHashMap 是由 Segment 數據結構和 HashEntry 數組結構構成,采取分段鎖來保證安全性。Segment 是 ReentrantLock 重入鎖,在 ConcurrentHashMap 中扮演鎖的角色,HashEntry 則用于存儲鍵值對數據。一個 ConcurrentHashMap 里包含一個 Segment 數組,一個 Segment 里包含一個 HashEntry 數組,Segment 的結構和 HashMap 類似,是一個數組和鏈表結構。
JDK 1.8中的實現:
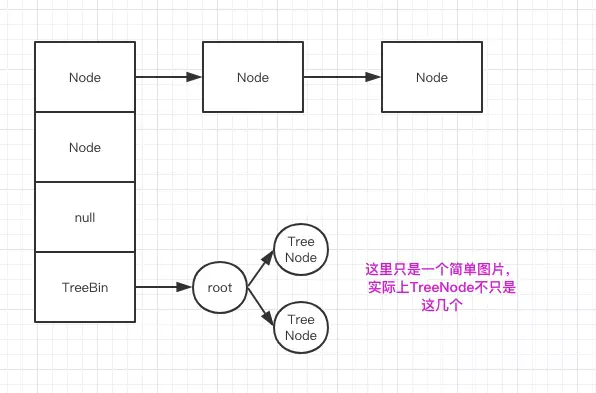
JDK1.8 的實現已經摒棄了 Segment 的概念,而是直接用 Node 數組+鏈表+紅黑樹的數據結構來實現,并發控制使用 Synchronized 和 CAS 來操作,整個看起來就像是優化過且線程安全的 HashMap,雖然在 JDK1.8 中還能看到 Segment 的數據結構,但是已經簡化了屬性,只是為了兼容舊版本。
2.18 ConcurrentHashMap是怎么分段分組的?
參考答案
get操作:
Segment的get操作實現非常簡單和高效,先經過一次再散列,然后使用這個散列值通過散列運算定位到 Segment,再通過散列算法定位到元素。get操作的高效之處在于整個get過程都不需要加鎖,除非讀到空的值才會加鎖重讀。原因就是將使用的共享變量定義成 volatile 類型。
put操作:
當執行put操作時,會經歷兩個步驟:
- 判斷是否需要擴容;
- 定位到添加元素的位置,將其放入 HashEntry 數組中。
插入過程會進行第一次 key 的 hash 來定位 Segment 的位置,如果該 Segment 還沒有初始化,即通過 CAS 操作進行賦值,然后進行第二次 hash 操作,找到相應的 HashEntry 的位置,這里會利用繼承過來的鎖的特性,在將數據插入指定的 HashEntry 位置時(尾插法),會通過繼承 ReentrantLock 的 tryLock() 方法嘗試去獲取鎖,如果獲取成功就直接插入相應的位置,如果已經有線程獲取該Segment的鎖,那當前線程會以自旋的方式去繼續的調用 tryLock() 方法去獲取鎖,超過指定次數就掛起,等待喚醒。
2.19 說一說你對LinkedHashMap的理解
參考答案
LinkedHashMap使用雙向鏈表來維護key-value對的順序(其實只需要考慮key的順序),該鏈表負責維護Map的迭代順序,迭代順序與key-value對的插入順序保持一致。
LinkedHashMap可以避免對HashMap、Hashtable里的key-value對進行排序(只要插入key-value對時保持順序即可),同時又可避免使用TreeMap所增加的成本。
LinkedHashMap需要維護元素的插入順序,因此性能略低于HashMap的性能。但因為它以鏈表來維護內部順序,所以在迭代訪問Map里的全部元素時將有較好的性能。
2.20 請介紹LinkedHashMap的底層原理
參考答案
LinkedHashMap繼承于HashMap,它在HashMap的基礎上,通過維護一條雙向鏈表,解決了HashMap不能隨時保持遍歷順序和插入順序一致的問題。在實現上,LinkedHashMap很多方法直接繼承自HashMap,僅為維護雙向鏈表重寫了部分方法。
如下圖,淡藍色的箭頭表示前驅引用,紅色箭頭表示后繼引用。每當有新的鍵值對節點插入時,新節點最終會接在tail引用指向的節點后面。而tail引用則會移動到新的節點上,這樣一個雙向鏈表就建立起來了。
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-tnTK8heo-1641469701690)(https://gitee.com/RedemptionXU/pic-md/raw/master/20220106194101.jpeg)]
2.21 請介紹TreeMap的底層原理
參考答案
TreeMap基于紅黑樹(Red-Black tree)實現。映射根據其鍵的自然順序進行排序,或者根據創建映射時提供的 Comparator 進行排序,具體取決于使用的構造方法。TreeMap的基本操作containsKey、get、put、remove方法,它的時間復雜度是log(N)。
TreeMap包含幾個重要的成員變量:root、size、comparator。其中root是紅黑樹的根節點。它是Entry類型,Entry是紅黑樹的節點,它包含了紅黑樹的6個基本組成:key、value、left、right、parent和color。Entry節點根據根據Key排序,包含的內容是value。Entry中key比較大小是根據比較器comparator來進行判斷的。size是紅黑樹的節點個數。
2.22 Map和Set有什么區別?
參考答案
Set代表無序的,元素不可重復的集合;
Map代表具有映射關系(key-value)的集合,其所有的key是一個Set集合,即key無序且不能重復。
2.23 List和Set有什么區別?
參考答案
Set代表無序的,元素不可重復的集合;
List代表有序的,元素可以重復的集合。
2.24 ArrayList和LinkedList有什么區別?
參考答案
- ArrayList的實現是基于數組,LinkedList的實現是基于雙向鏈表;
- 對于隨機訪問ArrayList要優于LinkedList,ArrayList可以根據下標以O(1)時間復雜度對元素進行隨機訪問,而LinkedList的每一個元素都依靠地址指針和它后一個元素連接在一起,查找某個元素的時間復雜度是O(N);
- 對于插入和刪除操作,LinkedList要優于ArrayList,因為當元素被添加到LinkedList任意位置的時候,不需要像ArrayList那樣重新計算大小或者是更新索引;
- LinkedList比ArrayList更占內存,因為LinkedList的節點除了存儲數據,還存儲了兩個引用,一個指向前一個元素,一個指向后一個元素。
2.25 有哪些線程安全的List?
參考答案
-
Vector
Vector是比較古老的API,雖然保證了線程安全,但是由于效率低一般不建議使用。
-
Collections.SynchronizedList
SynchronizedList是Collections的內部類,Collections提供了synchronizedList方法,可以將一個線程不安全的List包裝成線程安全的List,即SynchronizedList。它比Vector有更好的擴展性和兼容性,但是它所有的方法都帶有同步鎖,也不是性能最優的List。
-
CopyOnWriteArrayList
CopyOnWriteArrayList是Java 1.5在java.util.concurrent包下增加的類,它采用復制底層數組的方式來實現寫操作。當線程對此類集合執行讀取操作時,線程將會直接讀取集合本身,無須加鎖與阻塞。當線程對此類集合執行寫入操作時,集合會在底層復制一份新的數組,接下來對新的數組執行寫入操作。由于對集合的寫入操作都是對數組的副本執行操作,因此它是線程安全的。在所有線程安全的List中,它是性能最優的方案。
2.26 介紹一下ArrayList的數據結構?
參考答案
ArrayList的底層是用數組來實現的,默認第一次插入元素時創建大小為10的數組,超出限制時會增加50%的容量,并且數據以 System.arraycopy() 復制到新的數組,因此最好能給出數組大小的預估值。
按數組下標訪問元素的性能很高,這是數組的基本優勢。直接在數組末尾加入元素的性能也高,但如果按下標插入、刪除元素,則要用 System.arraycopy() 來移動部分受影響的元素,性能就變差了,這是基本劣勢。
2.27 談談CopyOnWriteArrayList的原理
參考答案
CopyOnWriteArrayList是Java并發包里提供的并發類,簡單來說它就是一個線程安全且讀操作無鎖的ArrayList。正如其名字一樣,在寫操作時會復制一份新的List,在新的List上完成寫操作,然后再將原引用指向新的List。這樣就保證了寫操作的線程安全。
CopyOnWriteArrayList允許線程并發訪問讀操作,這個時候是沒有加鎖限制的,性能較高。而寫操作的時候,則首先將容器復制一份,然后在新的副本上執行寫操作,這個時候寫操作是上鎖的。結束之后再將原容器的引用指向新容器。注意,在上鎖執行寫操作的過程中,如果有需要讀操作,會作用在原容器上。因此上鎖的寫操作不會影響到并發訪問的讀操作。
- 優點:讀操作性能很高,因為無需任何同步措施,比較適用于讀多寫少的并發場景。在遍歷傳統的List時,若中途有別的線程對其進行修改,則會拋出ConcurrentModificationException異常。而CopyOnWriteArrayList由于其"讀寫分離"的思想,遍歷和修改操作分別作用在不同的List容器,所以在使用迭代器進行遍歷時候,也就不會拋出ConcurrentModificationException異常了。
- 缺點:一是內存占用問題,畢竟每次執行寫操作都要將原容器拷貝一份,數據量大時,對內存壓力較大,可能會引起頻繁GC。二是無法保證實時性,Vector對于讀寫操作均加鎖同步,可以保證讀和寫的強一致性。而CopyOnWriteArrayList由于其實現策略的原因,寫和讀分別作用在新老不同容器上,在寫操作執行過程中,讀不會阻塞但讀取到的卻是老容器的數據。
2.28 說一說TreeSet和HashSet的區別
參考答案
HashSet、TreeSet中的元素都是不能重復的,并且它們都是線程不安全的,二者的區別是:
- HashSet中的元素可以是null,但TreeSet中的元素不能是null;
- HashSet不能保證元素的排列順序,而TreeSet支持自然排序、定制排序兩種排序的方式;
- HashSet底層是采用哈希表實現的,而TreeSet底層是采用紅黑樹實現的。
2.29 說一說HashSet的底層結構
參考答案
HashSet是基于HashMap實現的,默認構造函數是構建一個初始容量為16,負載因子為0.75 的HashMap。它封裝了一個 HashMap 對象來存儲所有的集合元素,所有放入 HashSet 中的集合元素實際上由 HashMap 的 key 來保存,而 HashMap 的 value 則存儲了一個 PRESENT,它是一個靜態的 Object 對象。
2.30 BlockingQueue中有哪些方法,為什么這樣設計?
參考答案
為了應對不同的業務場景,BlockingQueue 提供了4 組不同的方法用于插入、移除以及對隊列中的元素進行檢查。如果請求的操作不能得到立即執行的話,每組方法的表現是不同的。這些方法如下:

四組不同的行為方式含義如下:
- 拋異常:如果操作無法立即執行,則拋一個異常;
- 特定值:如果操作無法立即執行,則返回一個特定的值(一般是 true / false)。
- 阻塞:如果操作無法立即執行,則該方法調用將會發生阻塞,直到能夠執行;
- 超時:如果操作無法立即執行,則該方法調用將會發生阻塞,直到能夠執行。但等待時間不會超過給定值,并返回一個特定值以告知該操作是否成功(典型的是true / false)。
2.31 BlockingQueue是怎么實現的?
參考答案
BlockingQueue是一個接口,它的實現類有ArrayBlockingQueue、DelayQueue、 LinkedBlockingQueue、PriorityBlockingQueue、SynchronousQueue等。它們的區別主要體現在存儲結構上或對元素操作上的不同,但是對于put與take操作的原理是類似的。下面以ArrayBlockingQueue為例,來說明BlockingQueue的實現原理。
首先看一下ArrayBlockingQueue的構造函數,它初始化了put和take函數中用到的關鍵成員變量,這兩個變量的類型分別是ReentrantLock和Condition。ReentrantLock是AbstractQueuedSynchronizer(AQS)的子類,它的newCondition函數返回的Condition實例,是定義在AQS類內部的ConditionObject類,該類可以直接調用AQS相關的函數。
public ArrayBlockingQueue(int capacity, boolean fair) {if (capacity <= 0)throw new IllegalArgumentException();this.items = new Object[capacity];lock = new ReentrantLock(fair);notEmpty = lock.newCondition();notFull = lock.newCondition();
}
put函數會在隊列末尾添加元素,如果隊列已經滿了,無法添加元素的話,就一直阻塞等待到可以加入為止。函數的源碼如下所示。我們會發現put函數使用了wait/notify的機制。與一般生產者-消費者的實現方式不同,同步隊列使用ReentrantLock和Condition相結合的機制,即先獲得鎖,再等待,而不是synchronized和wait的機制。
public void put(E e) throws InterruptedException {checkNotNull(e);final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == items.length) notFull.await();enqueue(e);} finally {lock.unlock();}
}
再來看一下消費者調用的take函數,take函數在隊列為空時會被阻塞,一直到阻塞隊列加入了新的元素。
public E take() throws InterruptedException {final ReentrantLock lock = this.lock;lock.lockInterruptibly();try {while (count == 0)notEmpty.await();return dequeue();} finally {lock.unlock();}
}
擴展閱讀
await操作:
我們發現ArrayBlockingQueue并沒有使用Object.wait,而是使用的Condition.await,這是為什么呢?Condition對象可以提供和Object的wait和notify一樣的行為,但是后者必須先獲取synchronized這個內置的monitor鎖才能調用,而Condition則必須先獲取ReentrantLock。這兩種方式在阻塞等待時都會將相應的鎖釋放掉,但是Condition的等待可以中斷,這是二者唯一的區別。
我們先來看一下Condition的await函數,await函數的流程大致如下圖所示。await函數主要有三個步驟,一是調用addConditionWaiter函數,在condition wait queue隊列中添加一個節點,代表當前線程在等待一個消息。然后調用fullyRelease函數,將持有的鎖釋放掉,調用的是AQS的函數。最后一直調用isOnSyncQueue函數判斷節點是否被轉移到sync queue隊列上,也就是AQS中等待獲取鎖的隊列。如果沒有,則進入阻塞狀態,如果已經在隊列上,則調用acquireQueued函數重新獲取鎖。
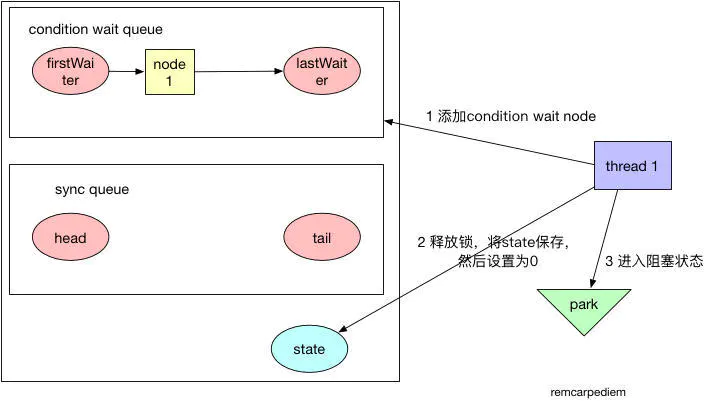
signal操作:
signal函數將condition wait queue隊列中隊首的線程節點轉移等待獲取鎖的sync queue隊列中。這樣的話,await函數中調用isOnSyncQueue函數就會返回true,導致await函數進入最后一步重新獲取鎖的狀態。
我們這里來詳細解析一下condition wait queue和sync queue兩個隊列的設計原理。condition wait queue是等待消息的隊列,因為阻塞隊列為空而進入阻塞狀態的take函數操作就是在等待阻塞隊列不為空的消息。而sync queue隊列則是等待獲取鎖的隊列,take函數獲得了消息,就可以運行了,但是它還必須等待獲取鎖之后才能真正進行運行狀態。
signal函數其實就做了一件事情,就是不斷嘗試調用transferForSignal函數,將condition wait queue隊首的一個節點轉移到sync queue隊列中,直到轉移成功。因為一次轉移成功,就代表這個消息被成功通知到了等待消息的節點。
signal函數的示意圖如下所示。
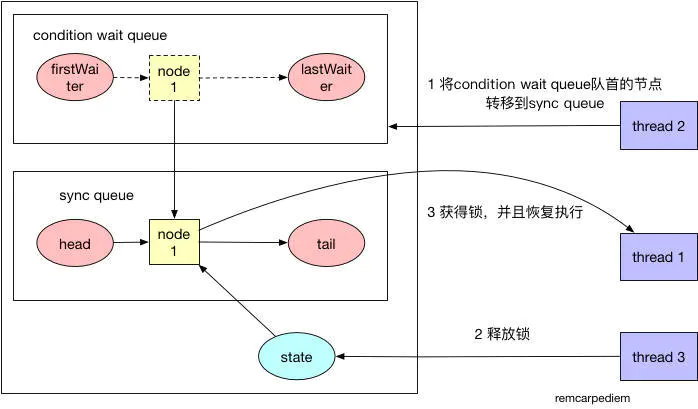
2.32 Stream(不是IOStream)有哪些方法?
參考答案
Stream提供了大量的方法進行聚集操作,這些方法既可以是“中間的”,也可以是“末端的”。
- 中間方法:中間操作允許流保持打開狀態,并允許直接調用后續方法。上面程序中的map()方法就是中間方法。中間方法的返回值是另外一個流。
- 末端方法:末端方法是對流的最終操作。當對某個Stream執行末端方法后,該流將會被“消耗”且不再可用。上面程序中的sum()、count()、average()等方法都是末端方法。
除此之外,關于流的方法還有如下兩個特征:
- 有狀態的方法:這種方法會給流增加一些新的屬性,比如元素的唯一性、元素的最大數量、保證元素以排序的方式被處理等。有狀態的方法往往需要更大的性能開銷。
- 短路方法:短路方法可以盡早結束對流的操作,不必檢查所有的元素。
下面簡單介紹一下Stream常用的中間方法:
- filter(Predicate predicate):過濾Stream中所有不符合predicate的元素。
- mapToXxx(ToXxxFunction mapper):使用ToXxxFunction對流中的元素執行一對一的轉換,該方法返回的新流中包含了ToXxxFunction轉換生成的所有元素。
- peek(Consumer action):依次對每個元素執行一些操作,該方法返回的流與原有流包含相同的元素。該方法主要用于調試。
- distinct():該方法用于排序流中所有重復的元素(判斷元素重復的標準是使用equals()比較返回true)。這是一個有狀態的方法。
- sorted():該方法用于保證流中的元素在后續的訪問中處于有序狀態。這是一個有狀態的方法。
- limit(long maxSize):該方法用于保證對該流的后續訪問中最大允許訪問的元素個數。這是一個有狀態的、短路方法。
下面簡單介紹一下Stream常用的末端方法:
- forEach(Consumer action):遍歷流中所有元素,對每個元素執行action。
- toArray():將流中所有元素轉換為一個數組。
- reduce():該方法有三個重載的版本,都用于通過某種操作來合并流中的元素。
- min():返回流中所有元素的最小值。
- max():返回流中所有元素的最大值。
- count():返回流中所有元素的數量。
- anyMatch(Predicate predicate):判斷流中是否至少包含一個元素符合Predicate條件。
- noneMatch(Predicate predicate):判斷流中是否所有元素都不符合Predicate條件。
- findFirst():返回流中的第一個元素。
- findAny():返回流中的任意一個元素。
除此之外,Java 8允許使用流式API來操作集合,Collection接口提供了一個stream()默認方法,該方法可返回該集合對應的流,接下來即可通過流式API來操作集合元素。由于Stream可以對集合元素進行整體的聚集操作,因此Stream極大地豐富了集合的功能。
擴展閱讀
Java 8新增了Stream、IntStream、LongStream、DoubleStream等流式API,這些API代表多個支持串行和并行聚集操作的元素。上面4個接口中,Stream是一個通用的流接口,而IntStream、LongStream、DoubleStream則代表元素類型為int、long、double的流。
Java 8還為上面每個流式API提供了對應的Builder,例如Stream.Builder、IntStream.Builder、LongStream.Builder、DoubleStream.Builder,開發者可以通過這些Builder來創建對應的流。
獨立使用Stream的步驟如下:
- 使用Stream或XxxStream的builder()類方法創建該Stream對應的Builder。
- 重復調用Builder的add()方法向該流中添加多個元素。
- 調用Builder的build()方法獲取對應的Stream。
- 調用Stream的聚集方法。
在上面4個步驟中,第4步可以根據具體需求來調用不同的方法,Stream提供了大量的聚集方法供用戶調用,具體可參考Stream或XxxStream的API文檔。對于大部分聚集方法而言,每個Stream只能執行一次。
3. IO
3.1 介紹一下Java中的IO流
參考答案
IO(Input Output)用于實現對數據的輸入與輸出操作,Java把不同的輸入/輸出源(鍵盤、文件、網絡等)抽象表述為流(Stream)。流是從起源到接收的有序數據,有了它程序就可以采用同一方式訪問不同的輸入/輸出源。
- 按照數據流向,可以將流分為輸入流和輸出流,其中輸入流只能讀取數據、不能寫入數據,而輸出流只能寫入數據、不能讀取數據。
- 按照數據類型,可以將流分為字節流和字符流,其中字節流操作的數據單元是8位的字節,而字符流操作的數據單元是16位的字符。
- 按照處理功能,可以將流分為節點流和處理流,其中節點流可以直接從/向一個特定的IO設備(磁盤、網絡等)讀/寫數據,也稱為低級流,而處理流是對節點流的連接或封裝,用于簡化數據讀/寫功能或提高效率,也稱為高級流。
Java提供了大量的類來支持IO操作,下表給大家整理了其中比較常用的一些類。其中,黑色字體的是抽象基類,其他所有的類都繼承自它們。紅色字體的是節點流,藍色字體的是處理流。
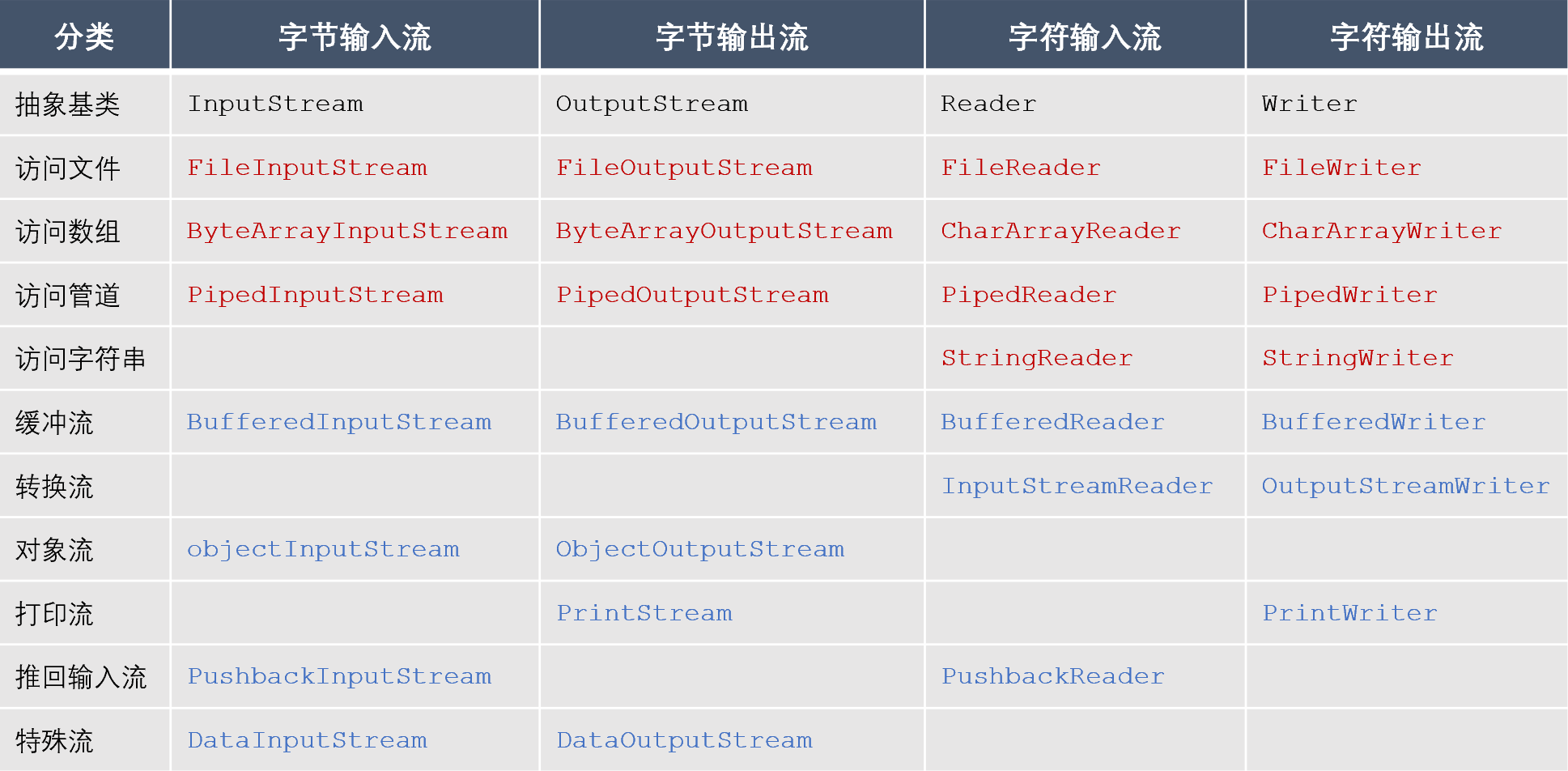
根據命名很容易理解各個流的作用:
- 以File開頭的文件流用于訪問文件;
- 以ByteArray/CharArray開頭的流用于訪問內存中的數組;
- 以Piped開頭的管道流用于訪問管道,實現進程之間的通信;
- 以String開頭的流用于訪問內存中的字符串;
- 以Buffered開頭的緩沖流,用于在讀寫數據時對數據進行緩存,以減少IO次數;
- InputStreamReader、InputStreamWriter是轉換流,用于將字節流轉換為字符流;
- 以Object開頭的流是對象流,用于實現對象的序列化;
- 以Print開頭的流是打印流,用于簡化打印操作;
- 以Pushback開頭的流是推回輸入流,用于將已讀入的數據推回到緩沖區,從而實現再次讀取;
- 以Data開頭的流是特殊流,用于讀寫Java基本類型的數據。
3.2 怎么用流打開一個大文件?
參考答案
打開大文件,應避免直接將文件中的數據全部讀取到內存中,可以采用分次讀取的方式。
- 使用緩沖流。緩沖流內部維護了一個緩沖區,通過與緩沖區的交互,減少與設備的交互次數。使用緩沖輸入流時,它每次會讀取一批數據將緩沖區填滿,每次調用讀取方法并不是直接從設備取值,而是從緩沖區取值,當緩沖區為空時,它會再一次讀取數據,將緩沖區填滿。使用緩沖輸出流時,每次調用寫入方法并不是直接寫入到設備,而是寫入緩沖區,當緩沖區填滿時它會自動刷入設備。
- 使用NIO。NIO采用內存映射文件的方式來處理輸入/輸出,NIO將文件或文件的一段區域映射到內存中,這樣就可以像訪問內存一樣來訪問文件了(這種方式模擬了操作系統上的虛擬內存的概念),通過這種方式來進行輸入/輸出比傳統的輸入/輸出要快得多。
3.4 說說NIO的實現原理
參考答案
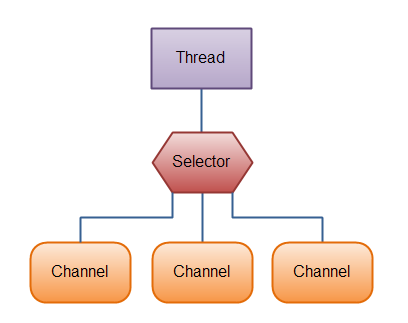
Java的NIO主要由三個核心部分組成:Channel、Buffer、Selector。
基本上,所有的IO在NIO中都從一個Channel開始,數據可以從Channel讀到Buffer中,也可以從Buffer寫到Channel中。Channel有好幾種類型,其中比較常用的有FileChannel、DatagramChannel、SocketChannel、ServerSocketChannel等,這些通道涵蓋了UDP和TCP網絡IO以及文件IO。
Buffer本質上是一塊可以寫入數據,然后可以從中讀取數據的內存。這塊內存被包裝成NIO Buffer對象,并提供了一組方法,用來方便的訪問該塊內存。Java NIO里關鍵的Buffer實現有CharBuffer、ByteBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer。這些Buffer覆蓋了你能通過IO發送的基本數據類型,即byte、short、int、long、float、double、char。
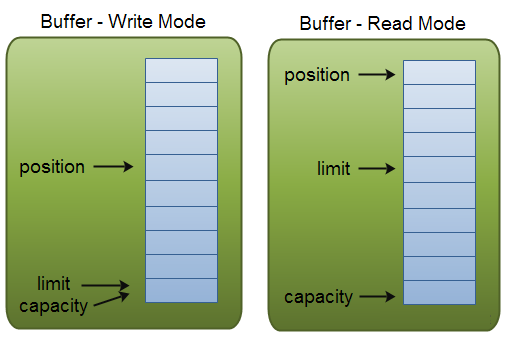
Buffer對象包含三個重要的屬性,分別是capacity、position、limit,其中position和limit的含義取決于Buffer處在讀模式還是寫模式。但不管Buffer處在什么模式,capacity的含義總是一樣的。
- capacity:作為一個內存塊,Buffer有個固定的最大值,就是capacity。Buffer只能寫capacity個數據,一旦Buffer滿了,需要將其清空才能繼續寫數據往里寫數據。
- position:當寫數據到Buffer中時,position表示當前的位置。初始的position值為0。當一個數據寫到Buffer后, position會向前移動到下一個可插入數據的Buffer單元。position最大可為capacity–1。當讀取數據時,也是從某個特定位置讀。當將Buffer從寫模式切換到讀模式,position會被重置為0。當從Buffer的position處讀取數據時,position向前移動到下一個可讀的位置。
- limit:在寫模式下,Buffer的limit表示最多能往Buffer里寫多少數據,此時limit等于capacity。當切換Buffer到讀模式時, limit表示你最多能讀到多少數據,此時limit會被設置成寫模式下的position值。
三個屬性之間的關系,如下圖所示:
Selector允許單線程處理多個 Channel,如果你的應用打開了多個連接(通道),但每個連接的流量都很低,使用Selector就會很方便。要使用Selector,得向Selector注冊Channel,然后調用它的select()方法。這個方法會一直阻塞到某個注冊的通道有事件就緒。一旦這個方法返回,線程就可以處理這些事件,事件例如有新連接進來,數據接收等。
這是在一個單線程中使用一個Selector處理3個Channel的圖示:
擴展閱讀
Java NIO根據操作系統不同, 針對NIO中的Selector有不同的實現:
- macosx:KQueueSelectorProvider
- solaris:DevPollSelectorProvider
- Linux:EPollSelectorProvider (Linux kernels >= 2.6)或PollSelectorProvider
- windows:WindowsSelectorProvider
所以不需要特別指定,Oracle JDK會自動選擇合適的Selector。如果想設置特定的Selector,可以設置屬性,例如: -Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.EPollSelectorProvider。
JDK在Linux已經默認使用epoll方式,但是JDK的epoll采用的是水平觸發,所以Netty自4.0.16起, Netty為Linux通過JNI的方式提供了native socket transport。Netty重新實現了epoll機制。
- 采用邊緣觸發方式;
- netty epoll transport暴露了更多的nio沒有的配置參數,如 TCP_CORK, SO_REUSEADDR等等;
- C代碼,更少GC,更少synchronized。
3.5 介紹一下Java的序列化與反序列化
參考答案
序列化機制可以將對象轉換成字節序列,這些字節序列可以保存在磁盤上,也可以在網絡中傳輸,并允許程序將這些字節序列再次恢復成原來的對象。其中,對象的序列化(Serialize),是指將一個Java對象寫入IO流中,對象的反序列化(Deserialize),則是指從IO流中恢復該Java對象。
若對象要支持序列化機制,則它的類需要實現Serializable接口,該接口是一個標記接口,它沒有提供任何方法,只是標明該類是可以序列化的,Java的很多類已經實現了Serializable接口,如包裝類、String、Date等。
若要實現序列化,則需要使用對象流ObjectInputStream和ObjectOutputStream。其中,在序列化時需要調用ObjectOutputStream對象的writeObject()方法,以輸出對象序列。在反序列化時需要調用ObjectInputStream對象的readObject()方法,將對象序列恢復為對象。
3.6 Serializable接口為什么需要定義serialVersionUID變量?
參考答案
serialVersionUID代表序列化的版本,通過定義類的序列化版本,在反序列化時,只要對象中所存的版本和當前類的版本一致,就允許做恢復數據的操作,否則將會拋出序列化版本不一致的錯誤。
如果不定義序列化版本,在反序列化時可能出現沖突的情況,例如:
- 創建該類的實例,并將這個實例序列化,保存在磁盤上;
- 升級這個類,例如增加、刪除、修改這個類的成員變量;
- 反序列化該類的實例,即從磁盤上恢復修改之前保存的數據。
在第3步恢復數據的時候,當前的類已經和序列化的數據的格式產生了沖突,可能會發生各種意想不到的問題。增加了序列化版本之后,在這種情況下則可以拋出異常,以提示這種矛盾的存在,提高數據的安全性。
3.7 除了Java自帶的序列化之外,你還了解哪些序列化工具?
參考答案
- JSON:目前使用比較頻繁的格式化數據工具,簡單直觀,可讀性好,有jackson,gson,fastjson等等,比較優秀的JSON解析工具的表現還是比較好的,有些json解析工具甚至速度超過了一些二進制的序列化方式。
- Protobuf:一個用來序列化結構化數據的技術,支持多種語言諸如C++、Java以及Python語言,可以使用該技術來持久化數據或者序列化成網絡傳輸的數據。相比較一些其他的XML技術而言,該技術的一個明顯特點就是更加節省空間(以二進制流存儲)、速度更快以及更加靈活。另外Protobuf支持的數據類型相對較少,不支持常量類型。由于其設計的理念是純粹的展現層協議(Presentation Layer),目前并沒有一個專門支持Protobuf的RPC框架。
- Thrift:是Facebook開源提供的一個高性能,輕量級RPC服務框架,其產生正是為了滿足當前大數據量、分布式、跨語言、跨平臺數據通訊的需求。 但是,Thrift并不僅僅是序列化協議,而是一個RPC框架。 相對于JSON和XML而言,Thrift在空間開銷和解析性能上有了比較大的提升,對于對性能要求比較高的分布式系統,它是一個優秀的RPC解決方案。但是由于Thrift的序列化被嵌入到Thrift框架里面, Thrift框架本身并沒有透出序列化和反序列化接口,這導致其很難和其他傳輸層協議共同使用(例如HTTP)。
- Avro:提供兩種序列化格式,即JSON格式或者Binary格式。Binary格式在空間開銷和解析性能方面可以和Protobuf媲美, JSON格式方便測試階段的調試。 Avro支持的數據類型非常豐富,包括C++語言里面的union類型。Avro支持JSON格式的IDL和類似于Thrift和Protobuf的IDL(實驗階段),這兩者之間可以互轉。Schema可以在傳輸數據的同時發送,加上JSON的自我描述屬性,這使得Avro非常適合動態類型語言。 Avro在做文件持久化的時候,一般會和Schema一起存儲,所以Avro序列化文件自身具有自我描述屬性,所以非常適合于做Hive、Pig和MapReduce的持久化數據格式。對于不同版本的Schema,在進行RPC調用的時候,服務端和客戶端可以在握手階段對Schema進行互相確認,大大提高了最終的數據解析速度。
3.8 如果不用JSON工具,該如何實現對實體類的序列化?
參考答案
可以使用Java原生的序列化機制,但是效率比較低一些,適合小項目;
- 創建該類的實例,并將這個實例序列化,保存在磁盤上;
- 升級這個類,例如增加、刪除、修改這個類的成員變量;
- 反序列化該類的實例,即從磁盤上恢復修改之前保存的數據。
在第3步恢復數據的時候,當前的類已經和序列化的數據的格式產生了沖突,可能會發生各種意想不到的問題。增加了序列化版本之后,在這種情況下則可以拋出異常,以提示這種矛盾的存在,提高數據的安全性。
3.7 除了Java自帶的序列化之外,你還了解哪些序列化工具?
參考答案
- JSON:目前使用比較頻繁的格式化數據工具,簡單直觀,可讀性好,有jackson,gson,fastjson等等,比較優秀的JSON解析工具的表現還是比較好的,有些json解析工具甚至速度超過了一些二進制的序列化方式。
- Protobuf:一個用來序列化結構化數據的技術,支持多種語言諸如C++、Java以及Python語言,可以使用該技術來持久化數據或者序列化成網絡傳輸的數據。相比較一些其他的XML技術而言,該技術的一個明顯特點就是更加節省空間(以二進制流存儲)、速度更快以及更加靈活。另外Protobuf支持的數據類型相對較少,不支持常量類型。由于其設計的理念是純粹的展現層協議(Presentation Layer),目前并沒有一個專門支持Protobuf的RPC框架。
- Thrift:是Facebook開源提供的一個高性能,輕量級RPC服務框架,其產生正是為了滿足當前大數據量、分布式、跨語言、跨平臺數據通訊的需求。 但是,Thrift并不僅僅是序列化協議,而是一個RPC框架。 相對于JSON和XML而言,Thrift在空間開銷和解析性能上有了比較大的提升,對于對性能要求比較高的分布式系統,它是一個優秀的RPC解決方案。但是由于Thrift的序列化被嵌入到Thrift框架里面, Thrift框架本身并沒有透出序列化和反序列化接口,這導致其很難和其他傳輸層協議共同使用(例如HTTP)。
- Avro:提供兩種序列化格式,即JSON格式或者Binary格式。Binary格式在空間開銷和解析性能方面可以和Protobuf媲美, JSON格式方便測試階段的調試。 Avro支持的數據類型非常豐富,包括C++語言里面的union類型。Avro支持JSON格式的IDL和類似于Thrift和Protobuf的IDL(實驗階段),這兩者之間可以互轉。Schema可以在傳輸數據的同時發送,加上JSON的自我描述屬性,這使得Avro非常適合動態類型語言。 Avro在做文件持久化的時候,一般會和Schema一起存儲,所以Avro序列化文件自身具有自我描述屬性,所以非常適合于做Hive、Pig和MapReduce的持久化數據格式。對于不同版本的Schema,在進行RPC調用的時候,服務端和客戶端可以在握手階段對Schema進行互相確認,大大提高了最終的數據解析速度。
3.8 如果不用JSON工具,該如何實現對實體類的序列化?
參考答案
可以使用Java原生的序列化機制,但是效率比較低一些,適合小項目;
可以使用其他的一些第三方類庫,比如Protobuf、Thrift、Avro等。








-- 開源機器人結構介紹)

)





)


