文章目錄
- 1. Spring Boot
- 1.1 說說你對Spring Boot的理解
- 1.2 Spring Boot Starter有什么用?
- 1.3 介紹Spring Boot的啟動流程
- 1.4 Spring Boot項目是如何導入包的?
- 1.5 請描述Spring Boot自動裝配的過程
- 1.6 說說你對Spring Boot注解的了解
- 2. Spring
- 2.1 請你說說Spring的核心是什么
- 2.2 說一說你對Spring容器的了解
- 2.3 說一說你對BeanFactory的了解
- 2.4 說一說你對Spring IOC的理解
- 2.5 Spring是如何管理Bean的?
- 2.6 介紹Bean的作用域
- 2.7 說一說Bean的生命周期
- 2.8 Spring是怎么解決循環依賴的?
- 2.9 @Autowired和@Resource注解有什么區別?
- 2.10 Spring中默認提供的單例是線程安全的嗎?
- 2.11 說一說你對Spring AOP的理解
- 2.12 請你說說AOP的應用場景
- 2.13 Spring AOP不能對哪些類進行增強?
- 2.14 JDK動態代理和CGLIB有什么區別?
- 2.15 既然有沒有接口都可以用CGLIB,為什么Spring還要使用JDK動態代理?
- 2.16 Spring如何管理事務?
- 2.17 Spring的事務傳播方式有哪些?
- 2.18 Spring的事務如何配置,常用注解有哪些?
- 2.19 說一說你對聲明式事務的理解
- 3. Spring MVC
- 3.1 什么是MVC?
- 3.2 DAO層是做什么的?
- 3.3 介紹一下Spring MVC的執行流程
- 3.4 說一說你知道的Spring MVC注解
- 3.5 介紹一下Spring MVC的攔截器
- 3.6 怎么去做請求攔截?
- 4. MyBatis
- 4.1 談談MyBatis和JPA的區別
- 4.2 MyBatis輸入輸出支持的類型有哪些?
- 4.3 MyBatis里如何實現一對多關聯查詢?
- 4.4 MyBatis中的$和#有什么區別?
- 4.5 既然不安全,為什么還需要?什么時候會用到它?
- 4.6 MyBatis的xml文件和Mapper接口是怎么綁定的?
- 4.7 MyBatis分頁和自己寫的分頁哪個效率高?
- 4.8 了解MyBatis緩存機制嗎?
- 5. 其他
- 5.1 cookie和session的區別是什么?
- 5.2 cookie和session各自適合的場景是什么?
- 5.3 請介紹session的工作原理
- 5.4 get請求與post請求有什么區別?
- 5.5 get請求的參數能放到body里面嗎?
- 5.6 post不冪等是為什么?
- 5.7 頁面報400錯誤是什么意思?
- 5.8 請求數據出現亂碼該怎么處理?
- 5.9 如何在SpringBoot框架下實現一個定時任務?
- 5.10 調用接口時要記錄日志,該怎么設計?
- 5.11 了解Spring Boot JPA嗎?
- 5.7 頁面報400錯誤是什么意思?
- 5.8 請求數據出現亂碼該怎么處理?
- 5.9 如何在SpringBoot框架下實現一個定時任務?
- 5.10 調用接口時要記錄日志,該怎么設計?
- 5.11 了解Spring Boot JPA嗎?
1. Spring Boot
1.1 說說你對Spring Boot的理解
參考答案
從本質上來說,Spring Boot就是Spring,它做了那些沒有它你自己也會去做的Spring Bean配置。Spring Boot使用“習慣優于配置”的理念讓你的項目快速地運行起來,使用Spring Boot很容易創建一個能獨立運行、準生產級別、基于Spring框架的項目,使用Spring Boot你可以不用或者只需要很少的Spring配置。
簡而言之,Spring Boot本身并不提供Spring的核心功能,而是作為Spring的腳手架框架,以達到快速構建項目、預置三方配置、開箱即用的目的。Spring Boot有如下的優點:
- 可以快速構建項目;
- 可以對主流開發框架的無配置集成;
- 項目可獨立運行,無需外部依賴Servlet容器;
- 提供運行時的應用監控;
- 可以極大地提高開發、部署效率;
- 可以與云計算天然集成。
1.2 Spring Boot Starter有什么用?
參考答案
Spring Boot通過提供眾多起步依賴(Starter)降低項目依賴的復雜度。起步依賴本質上是一個Maven項目對象模型(Project Object Model, POM),定義了對其他庫的傳遞依賴,這些東西加在一起即支持某項功能。很多起步依賴的命名都暗示了它們提供的某種或某類功能。
舉例來說,你打算把這個閱讀列表應用程序做成一個Web應用程序。與其向項目的構建文件里添加一堆單獨的庫依賴,還不如聲明這是一個Web應用程序來得簡單。你只要添加Spring Boot的Web起步依賴就好了。
1.3 介紹Spring Boot的啟動流程
參考答案
首先,Spring Boot項目創建完成會默認生成一個名為 *Application 的入口類,我們是通過該類的main方法啟動Spring Boot項目的。在main方法中,通過SpringApplication的靜態方法,即run方法進行SpringApplication類的實例化操作,然后再針對實例化對象調用另外一個run方法來完成整個項目的初始化和啟動。
SpringApplication調用的run方法的大致流程,如下圖:
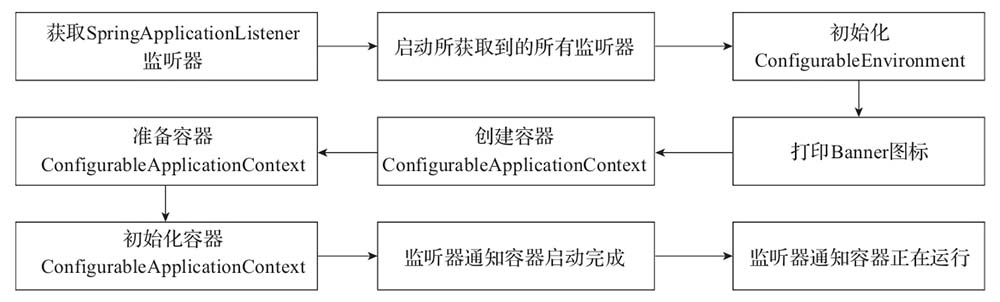
其中,SpringApplication在run方法中重點做了以下操作:
- 獲取監聽器和參數配置;
- 打印Banner信息;
- 創建并初始化容器;
- 監聽器發送通知。
當然,除了上述核心操作,run方法運行過程中還涉及啟動時長統計、異常報告、啟動日志、異常處理等輔助操作。比較完整的流程,可以參考如下源代碼:
public ConfigurableApplicationContext run(String... args) {// 創建StopWatch對象,用于統計run方法啟動時長。StopWatch stopWatch = new StopWatch();// 啟動統計stopWatch.start();ConfigurableApplicationContext context = null;Collection<SpringBootExceptionReporter> exceptionReporters = new ArrayList<>();// 配置Headless屬性configureHeadlessProperty();// 獲得SpringApplicationRunListener數組,// 該數組封裝于SpringApplicationRunListeners對象的listeners中。SpringApplicationRunListeners listeners = getRunListeners(args);// 啟動監聽,遍歷SpringApplicationRunListener數組每個元素,并執行。listeners.starting();try {// 創建ApplicationArguments對象ApplicationArguments applicationArguments = new DefaultApplicationArguments(args);// 加載屬性配置,包括所有的配置屬性。ConfigurableEnvironment environment = prepareEnvironment(listeners, applicationArguments);configureIgnoreBeanInfo(environment);// 打印BannerBanner printedBanner = printBanner(environment);// 創建容器context = createApplicationContext();// 異常報告器exceptionReporters = getSpringFactoriesInstances(SpringBootExceptionReporter.class,new Class[] { ConfigurableApplicationContext.class }, context);// 準備容器,組件對象之間進行關聯。prepareContext(context, environment, listeners, applicationArguments, printedBanner);// 初始化容器refreshContext(context);// 初始化操作之后執行,默認實現為空。afterRefresh(context, applicationArguments);// 停止時長統計stopWatch.stop();// 打印啟動日志if (this.logStartupInfo) {new StartupInfoLogger(this.mainApplicationClass).logStarted(getApplicationLog(), stopWatch);}// 通知監聽器:容器完成啟動。listeners.started(context);// 調用ApplicationRunner和CommandLineRunner的運行方法。callRunners(context, applicationArguments);} catch (Throwable ex) {// 異常處理handleRunFailure(context, ex, exceptionReporters, listeners);throw new IllegalStateException(ex);}try {// 通知監聽器:容器正在運行。listeners.running(context);} catch (Throwable ex) {// 異常處理handleRunFailure(context, ex, exceptionReporters, null);throw new IllegalStateException(ex);}return context;
}
1.4 Spring Boot項目是如何導入包的?
參考答案
通過Spring Boot Starter導入包。
Spring Boot通過提供眾多起步依賴(Starter)降低項目依賴的復雜度。起步依賴本質上是一個Maven項目對象模型(Project Object Model, POM),定義了對其他庫的傳遞依賴,這些東西加在一起即支持某項功能。很多起步依賴的命名都暗示了它們提供的某種或某類功能。
舉例來說,你打算把這個閱讀列表應用程序做成一個Web應用程序。與其向項目的構建文件里添加一堆單獨的庫依賴,還不如聲明這是一個Web應用程序來得簡單。你只要添加Spring Boot的Web起步依賴就好了。
1.5 請描述Spring Boot自動裝配的過程
參考答案
使用Spring Boot時,我們只需引入對應的Starters,Spring Boot啟動時便會自動加載相關依賴,配置相應的初始化參數,以最快捷、簡單的形式對第三方軟件進行集成,這便是Spring Boot的自動配置功能。Spring Boot實現該運作機制鎖涉及的核心部分如下圖所示:
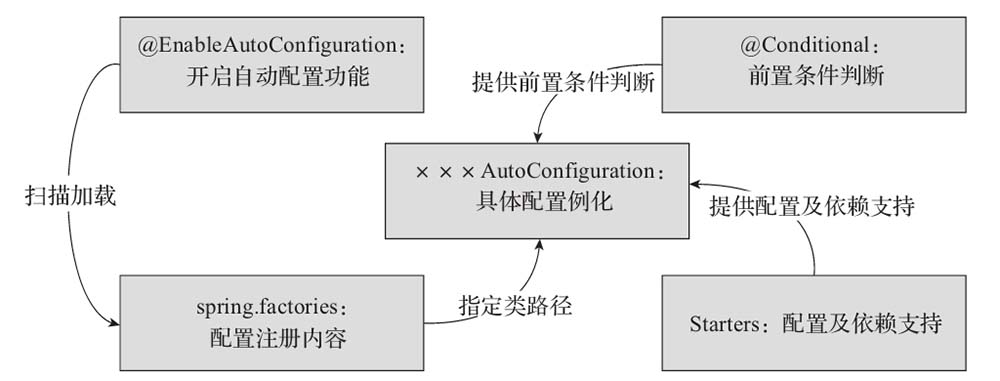
整個自動裝配的過程是:Spring Boot通過@EnableAutoConfiguration注解開啟自動配置,加載spring.factories中注冊的各種AutoConfiguration類,當某個AutoConfiguration類滿足其注解@Conditional指定的生效條件(Starters提供的依賴、配置或Spring容器中是否存在某個Bean等)時,實例化該AutoConfiguration類中定義的Bean(組件等),并注入Spring容器,就可以完成依賴框架的自動配置。
1.6 說說你對Spring Boot注解的了解
參考答案
@SpringBootApplication注解:
在Spring Boot入口類中,唯一的一個注解就是@SpringBootApplication。它是Spring Boot項目的核心注解,用于開啟自動配置,準確說是通過該注解內組合的@EnableAutoConfiguration開啟了自動配置。
@EnableAutoConfiguration注解:
@EnableAutoConfiguration的主要功能是啟動Spring應用程序上下文時進行自動配置,它會嘗試猜測并配置項目可能需要的Bean。自動配置通常是基于項目classpath中引入的類和已定義的Bean來實現的。在此過程中,被自動配置的組件來自項目自身和項目依賴的jar包中。
@Import注解:
@EnableAutoConfiguration的關鍵功能是通過@Import注解導入的ImportSelector來完成的。從源代碼得知@Import(AutoConfigurationImportSelector.class)是@EnableAutoConfiguration注解的組成部分,也是自動配置功能的核心實現者。
@Conditional注解:
@Conditional注解是由Spring 4.0版本引入的新特性,可根據是否滿足指定的條件來決定是否進行Bean的實例化及裝配,比如,設定當類路徑下包含某個jar包的時候才會對注解的類進行實例化操作。總之,就是根據一些特定條件來控制Bean實例化的行為。
@Conditional衍生注解:
在Spring Boot的autoconfigure項目中提供了各類基于@Conditional注解的衍生注解,它們適用不同的場景并提供了不同的功能。通過閱讀這些注解的源碼,你會發現它們其實都組合了@Conditional注解,不同之處是它們在注解中指定的條件(Condition)不同。
- @ConditionalOnBean:在容器中有指定Bean的條件下。
- @ConditionalOnClass:在classpath類路徑下有指定類的條件下。
- @ConditionalOnCloudPlatform:當指定的云平臺處于active狀態時。
- @ConditionalOnExpression:基于SpEL表達式的條件判斷。
- @ConditionalOnJava:基于JVM版本作為判斷條件。
- @ConditionalOnJndi:在JNDI存在的條件下查找指定的位置。
- @ConditionalOnMissingBean:當容器里沒有指定Bean的條件時。
- @ConditionalOnMissingClass:當類路徑下沒有指定類的條件時。
- @ConditionalOnNotWebApplication:在項目不是一個Web項目的條件下。
- @ConditionalOnProperty:在指定的屬性有指定值的條件下。
- @ConditionalOnResource:類路徑是否有指定的值。
- @ConditionalOnSingleCandidate:當指定的Bean在容器中只有一個或者有多個但是指定了首選的Bean時。
- @ConditionalOnWebApplication:在項目是一個Web項目的條件下。
2. Spring
2.1 請你說說Spring的核心是什么
參考答案
Spring框架包含眾多模塊,如Core、Testing、Data Access、Web Servlet等,其中Core是整個Spring框架的核心模塊。Core模塊提供了IoC容器、AOP功能、數據綁定、類型轉換等一系列的基礎功能,而這些功能以及其他模塊的功能都是建立在IoC和AOP之上的,所以IoC和AOP是Spring框架的核心。
IoC(Inversion of Control)是控制反轉的意思,這是一種面向對象編程的設計思想。在不采用這種思想的情況下,我們需要自己維護對象與對象之間的依賴關系,很容易造成對象之間的耦合度過高,在一個大型的項目中這十分的不利于代碼的維護。IoC則可以解決這種問題,它可以幫我們維護對象與對象之間的依賴關系,降低對象之間的耦合度。
說到IoC就不得不說DI(Dependency Injection),DI是依賴注入的意思,它是IoC實現的實現方式,就是說IoC是通過DI來實現的。由于IoC這個詞匯比較抽象而DI卻更直觀,所以很多時候我們就用DI來代替它,在很多時候我們簡單地將IoC和DI劃等號,這是一種習慣。而實現依賴注入的關鍵是IoC容器,它的本質就是一個工廠。
AOP(Aspect Oriented Programing)是面向切面編程思想,這種思想是對OOP的補充,它可以在OOP的基礎上進一步提高編程的效率。簡單來說,它可以統一解決一批組件的共性需求(如權限檢查、記錄日志、事務管理等)。在AOP思想下,我們可以將解決共性需求的代碼獨立出來,然后通過配置的方式,聲明這些代碼在什么地方、什么時機調用。當滿足調用條件時,AOP會將該業務代碼織入到我們指定的位置,從而統一解決了問題,又不需要修改這一批組件的代碼。
2.2 說一說你對Spring容器的了解
參考答案
Spring主要提供了兩種類型的容器:BeanFactory和ApplicationContext。
- BeanFactory:是基礎類型的IoC容器,提供完整的IoC服務支持。如果沒有特殊指定,默認采用延
遲初始化策略。只有當客戶端對象需要訪問容器中的某個受管對象的時候,才對該受管對象進行初始化以及依賴注入操作。所以,相對來說,容器啟動初期速度較快,所需要的資源有限。對于資源有限,并且功能要求不是很嚴格的場景,BeanFactory是比較合適的IoC容器選擇。 - ApplicationContext:它是在BeanFactory的基礎上構建的,是相對比較高級的容器實現,除了擁有BeanFactory的所有支持,ApplicationContext還提供了其他高級特性,比如事件發布、國際化信息支持等。ApplicationContext所管理的對象,在該類型容器啟動之后,默認全部初始化并綁定完成。所以,相對于BeanFactory來說,ApplicationContext要求更多的系統資源,同時,因為在啟動時就完成所有初始化,容
器啟動時間較之BeanFactory也會長一些。在那些系統資源充足,并且要求更多功能的場景中,ApplicationContext類型的容器是比較合適的選擇。
2.3 說一說你對BeanFactory的了解
參考答案
BeanFactory是一個類工廠,與傳統類工廠不同的是,BeanFactory是類的通用工廠,它可以創建并管理各種類的對象。這些可被創建和管理的對象本身沒有什么特別之處,僅是一個POJO,Spring稱這些被創建和管理的Java對象為Bean。并且,Spring中所說的Bean比JavaBean更為寬泛一些,所有可以被Spring容器實例化并管理的Java類都可以成為Bean。
BeanFactory是Spring容器的頂層接口,Spring為BeanFactory提供了多種實現,最常用的是XmlBeanFactory。但它在Spring 3.2中已被廢棄,建議使用XmlBeanDefinitionReader、DefaultListableBeanFactory替代。BeanFactory最主要的方法就是 getBean(String beanName),該方法從容器中返回特定名稱的Bean。
2.4 說一說你對Spring IOC的理解
參考答案
IoC(Inversion of Control)是控制反轉的意思,這是一種面向對象編程的設計思想。在不采用這種思想的情況下,我們需要自己維護對象與對象之間的依賴關系,很容易造成對象之間的耦合度過高,在一個大型的項目中這十分的不利于代碼的維護。IoC則可以解決這種問題,它可以幫我們維護對象與對象之間的依賴關系,降低對象之間的耦合度。
說到IoC就不得不說DI(Dependency Injection),DI是依賴注入的意思,它是IoC實現的實現方式,就是說IoC是通過DI來實現的。由于IoC這個詞匯比較抽象而DI卻更直觀,所以很多時候我們就用DI來代替它,在很多時候我們簡單地將IoC和DI劃等號,這是一種習慣。而實現依賴注入的關鍵是IoC容器,它的本質就是一個工廠。
在具體的實現中,主要由三種注入方式:
-
構造方法注入
就是被注入對象可以在它的構造方法中聲明依賴對象的參數列表,讓外部知道它需要哪些依賴對象。然后,IoC Service Provider會檢查被注入的對象的構造方法,取得它所需要的依賴對象列表,進而為其注入相應的對象。構造方法注入方式比較直觀,對象被構造完成后,即進入就緒狀態,可以馬上使用。
-
setter方法注入
通過setter方法,可以更改相應的對象屬性。所以,當前對象只要為其依賴對象所對應的屬性添加setter方法,就可以通過setter方法將相應的依賴對象設置到被注入對象中。setter方法注入雖不像構造方法注入那樣,讓對象構造完成后即可使用,但相對來說更寬松一些,
可以在對象構造完成后再注入。 -
接口注入
相對于前兩種注入方式來說,接口注入沒有那么簡單明了。被注入對象如果想要IoC Service Provider為其注入依賴對象,就必須實現某個接口。這個接口提供一個方法,用來為其注入依賴對象。IoC Service Provider最終通過這些接口來了解應該為被注入對象注入什么依賴對象。相對于前兩種依賴注入方式,接口注入比較死板和煩瑣。
總體來說,構造方法注入和setter方法注入因為其侵入性較弱,且易于理解和使用,所以是現在使用最多的注入方式。而接口注入因為侵入性較強,近年來已經不流行了。
2.5 Spring是如何管理Bean的?
參考答案
Spring通過IoC容器來管理Bean,我們可以通過XML配置或者注解配置,來指導IoC容器對Bean的管理。因為注解配置比XML配置方便很多,所以現在大多時候會使用注解配置的方式。
以下是管理Bean時常用的一些注解:
- @ComponentScan用于聲明掃描策略,通過它的聲明,容器就知道要掃描哪些包下帶有聲明的類,也可以知道哪些特定的類是被排除在外的。
- @Component、@Repository、@Service、@Controller用于聲明Bean,它們的作用一樣,但是語義不同。@Component用于聲明通用的Bean,@Repository用于聲明DAO層的Bean,@Service用于聲明業務層的Bean,@Controller用于聲明視圖層的控制器Bean,被這些注解聲明的類就可以被容器掃描并創建。
- @Autowired、@Qualifier用于注入Bean,即告訴容器應該為當前屬性注入哪個Bean。其中,@Autowired是按照Bean的類型進行匹配的,如果這個屬性的類型具有多個Bean,就可以通過@Qualifier指定Bean的名稱,以消除歧義。
- @Scope用于聲明Bean的作用域,默認情況下Bean是單例的,即在整個容器中這個類型只有一個實例。可以通過@Scope注解指定prototype值將其聲明為多例的,也可以將Bean聲明為session級作用域、request級作用域等等,但最常用的還是默認的單例模式。
- @PostConstruct、@PreDestroy用于聲明Bean的生命周期。其中,被@PostConstruct修飾的方法將在Bean實例化后被調用,@PreDestroy修飾的方法將在容器銷毀前被調用。
2.6 介紹Bean的作用域
參考答案
默認情況下,Bean在Spring容器中是單例的,我們可以通過@Scope注解修改Bean的作用域。該注解有如下5個取值,它們代表了Bean的5種不同類型的作用域:

2.7 說一說Bean的生命周期
參考答案
Spring容器管理Bean,涉及對Bean的創建、初始化、調用、銷毀等一系列的流程,這個流程就是Bean的生命周期。整個流程參考下圖:
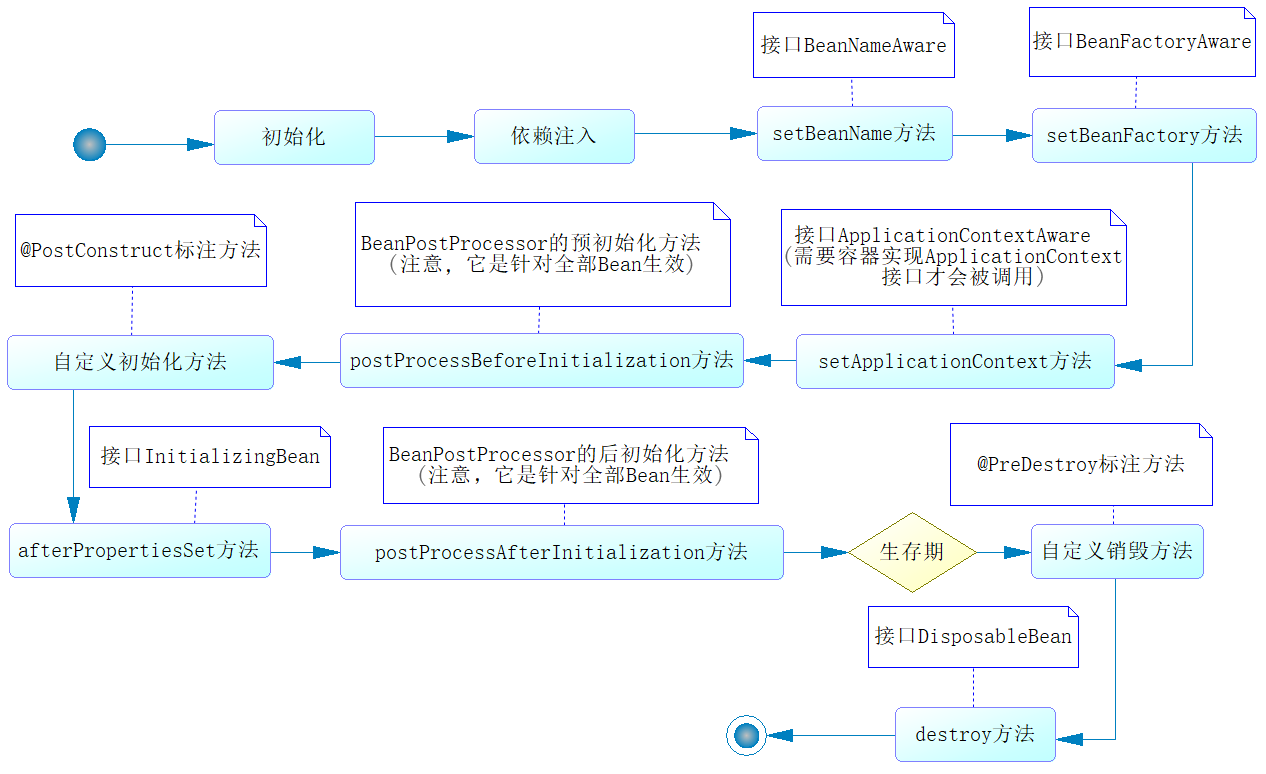
這個過程是由Spring容器自動管理的,其中有兩個環節我們可以進行干預。
- 我們可以自定義初始化方法,并在該方法前增加@PostConstruct注解,屆時Spring容器將在調用SetBeanFactory方法之后調用該方法。
- 我們可以自定義銷毀方法,并在該方法前增加@PreDestroy注解,屆時Spring容器將在自身銷毀前,調用這個方法。
2.8 Spring是怎么解決循環依賴的?
參考答案
首先,需要明確的是spring對循環依賴的處理有三種情況:
- 構造器的循環依賴:這種依賴spring是處理不了的,直接拋出BeanCurrentlylnCreationException異常。
- 單例模式下的setter循環依賴:通過“三級緩存”處理循環依賴。
- 非單例循環依賴:無法處理。
接下來,我們具體看看spring是如何處理第二種循環依賴的。
Spring單例對象的初始化大略分為三步:
- createBeanInstance:實例化,其實也就是調用對象的構造方法實例化對象;
- populateBean:填充屬性,這一步主要是多bean的依賴屬性進行填充;
- initializeBean:調用spring xml中的init 方法。
從上面講述的單例bean初始化步驟我們可以知道,循環依賴主要發生在第一步、第二步。也就是構造器循環依賴和field循環依賴。 Spring為了解決單例的循環依賴問題,使用了三級緩存。
/** Cache of singleton objects: bean name –> bean instance */
private final Map singletonObjects = new ConcurrentHashMap(256);
/** Cache of singleton factories: bean name –> ObjectFactory */
private final Map> singletonFactories = new HashMap>(16);
/** Cache of early singleton objects: bean name –> bean instance */
private final Map earlySingletonObjects = new HashMap(16);
這三級緩存的作用分別是:
- singletonFactories : 進入實例化階段的單例對象工廠的cache (三級緩存);
- earlySingletonObjects :完成實例化但是尚未初始化的,提前暴光的單例對象的Cache (二級緩存);
- singletonObjects:完成初始化的單例對象的cache(一級緩存)。
我們在創建bean的時候,會首先從cache中獲取這個bean,這個緩存就是sigletonObjects。主要的調用方法是:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {Object singletonObject = this.singletonObjects.get(beanName);//isSingletonCurrentlyInCreation()判斷當前單例bean是否正在創建中if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {synchronized (this.singletonObjects) {singletonObject = this.earlySingletonObjects.get(beanName);//allowEarlyReference 是否允許從singletonFactories中通過getObject拿到對象if (singletonObject == null && allowEarlyReference) {ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);if (singletonFactory != null) {singletonObject = singletonFactory.getObject();//從singletonFactories中移除,并放入earlySingletonObjects中。//其實也就是從三級緩存移動到了二級緩存this.earlySingletonObjects.put(beanName, singletonObject);this.singletonFactories.remove(beanName);}}}}return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
從上面三級緩存的分析,我們可以知道,Spring解決循環依賴的訣竅就在于singletonFactories這個三級cache。這個cache的類型是ObjectFactory,定義如下:
public interface ObjectFactory<T> {T getObject() throws BeansException;
}
這個接口在AbstractBeanFactory里實現,并在核心方法doCreateBean()引用下面的方法:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {Assert.notNull(singletonFactory, "Singleton factory must not be null");synchronized (this.singletonObjects) {if (!this.singletonObjects.containsKey(beanName)) {this.singletonFactories.put(beanName, singletonFactory);this.earlySingletonObjects.remove(beanName);this.registeredSingletons.add(beanName);}}
}
這段代碼發生在createBeanInstance之后,populateBean()之前,也就是說單例對象此時已經被創建出來(調用了構造器)。這個對象已經被生產出來了,此時將這個對象提前曝光出來,讓大家使用。
這樣做有什么好處呢?讓我們來分析一下“A的某個field或者setter依賴了B的實例對象,同時B的某個field或者setter依賴了A的實例對象”這種循環依賴的情況。A首先完成了初始化的第一步,并且將自己提前曝光到singletonFactories中,此時進行初始化的第二步,發現自己依賴對象B,此時就嘗試去get(B),發現B還沒有被create,所以走create流程,B在初始化第一步的時候發現自己依賴了對象A,于是嘗試get(A),嘗試一級緩存singletonObjects(肯定沒有,因為A還沒初始化完全),嘗試二級緩存earlySingletonObjects(也沒有),嘗試三級緩存singletonFactories,由于A通過ObjectFactory將自己提前曝光了,所以B能夠通過ObjectFactory.getObject拿到A對象(雖然A還沒有初始化完全,但是總比沒有好呀),B拿到A對象后順利完成了初始化階段1、2、3,完全初始化之后將自己放入到一級緩存singletonObjects中。此時返回A中,A此時能拿到B的對象順利完成自己的初始化階段2、3,最終A也完成了初始化,進去了一級緩存singletonObjects中,而且更加幸運的是,由于B拿到了A的對象引用,所以B現在hold住的A對象完成了初始化。
2.9 @Autowired和@Resource注解有什么區別?
參考答案
- @Autowired是Spring提供的注解,@Resource是JDK提供的注解。
- @Autowired是只能按類型注入,@Resource默認按名稱注入,也支持按類型注入。
- @Autowired按類型裝配依賴對象,默認情況下它要求依賴對象必須存在,如果允許null值,可以設置它required屬性為false,如果我們想使用按名稱裝配,可以結合@Qualifier注解一起使用。@Resource有兩個中重要的屬性:name和type。name屬性指定byName,如果沒有指定name屬性,當注解標注在字段上,即默認取字段的名稱作為bean名稱尋找依賴對象,當注解標注在屬性的setter方法上,即默認取屬性名作為bean名稱尋找依賴對象。需要注意的是,@Resource如果沒有指定name屬性,并且按照默認的名稱仍然找不到依賴對象時, @Resource注解會回退到按類型裝配。但一旦指定了name屬性,就只能按名稱裝配了。
2.10 Spring中默認提供的單例是線程安全的嗎?
參考答案
不是。
Spring容器本身并沒有提供Bean的線程安全策略。如果單例的Bean是一個無狀態的Bean,即線程中的操作不會對Bean的成員執行查詢以外的操作,那么這個單例的Bean是線程安全的。比如,Controller、Service、DAO這樣的組件,通常都是單例且線程安全的。如果單例的Bean是一個有狀態的Bean,則可以采用ThreadLocal對狀態數據做線程隔離,來保證線程安全。
2.11 說一說你對Spring AOP的理解
參考答案
AOP(Aspect Oriented Programming)是面向切面編程,它是一種編程思想,是面向對象編程(OOP)的一種補充。面向對象編程將程序抽象成各個層次的對象,而面向切面編程是將程序抽象成各個切面。如下圖,可以很形象地看出,所謂切面,相當于應用對象間的橫切點,我們可以將其單獨抽象為單獨的模塊。
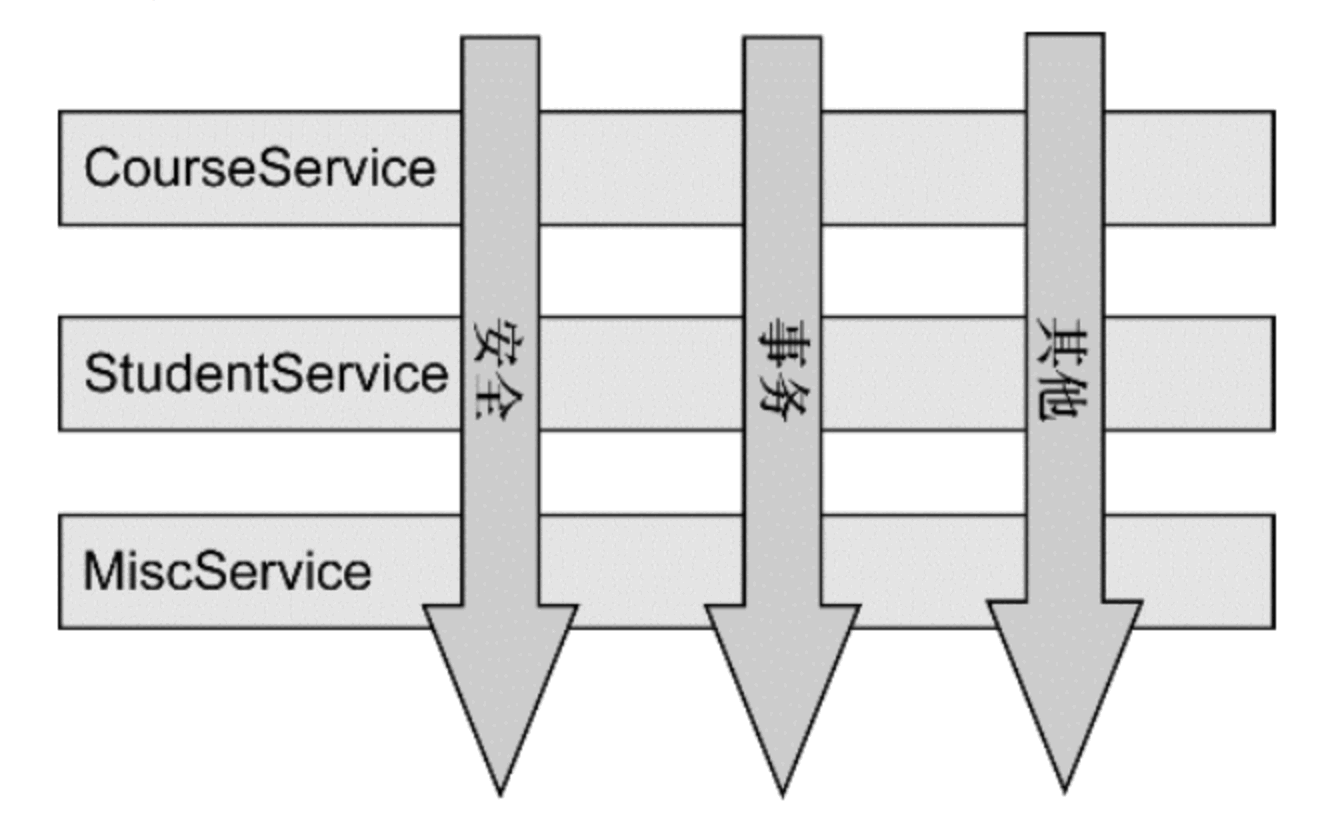
AOP的術語:
- 連接點(join point):對應的是具體被攔截的對象,因為Spring只能支持方法,所以被攔截的對象往往就是指特定的方法,AOP將通過動態代理技術把它織入對應的流程中。
- 切點(point cut):有時候,我們的切面不單單應用于單個方法,也可能是多個類的不同方法,這時,可以通過正則式和指示器的規則去定義,從而適配連接點。切點就是提供這樣一個功能的概念。
- 通知(advice):就是按照約定的流程下的方法,分為前置通知、后置通知、環繞通知、事后返回通知和異常通知,它會根據約定織入流程中。
- 目標對象(target):即被代理對象。
- 引入(introduction):是指引入新的類和其方法,增強現有Bean的功能。
- 織入(weaving):它是一個通過動態代理技術,為原有服務對象生成代理對象,然后將與切點定義匹配的連接點攔截,并按約定將各類通知織入約定流程的過程。
- 切面(aspect):是一個可以定義切點、各類通知和引入的內容,SpringAOP將通過它的信息來增強Bean的功能或者將對應的方法織入流程。
Spring AOP:
AOP可以有多種實現方式,而Spring AOP支持如下兩種實現方式。
- JDK動態代理:這是Java提供的動態代理技術,可以在運行時創建接口的代理實例。Spring AOP默認采用這種方式,在接口的代理實例中織入代碼。
- CGLib動態代理:采用底層的字節碼技術,在運行時創建子類代理的實例。當目標對象不存在接口時,Spring AOP就會采用這種方式,在子類實例中織入代碼。
2.12 請你說說AOP的應用場景
參考答案
Spring AOP為IoC的使用提供了更多的便利,一方面,應用可以直接使用AOP的功能,設計應用的橫切關注點,把跨越應用程序多個模塊的功能抽象出來,并通過簡單的AOP的使用,靈活地編制到模塊中,比如可以通過AOP實現應用程序中的日志功能。另一方面,在Spring內部,一些支持模塊也是通過Spring AOP來實現的,比如事務處理。從這兩個角度就已經可以看到Spring AOP的核心地位了。
2.13 Spring AOP不能對哪些類進行增強?
參考答案
- Spring AOP只能對IoC容器中的Bean進行增強,對于不受容器管理的對象不能增強。
- 由于CGLib采用動態創建子類的方式生成代理對象,所以不能對final修飾的類進行代理。
2.14 JDK動態代理和CGLIB有什么區別?
參考答案
JDK動態代理
這是Java提供的動態代理技術,可以在運行時創建接口的代理實例。Spring AOP默認采用這種方式,在接口的代理實例中織入代碼。
CGLib動態代理
采用底層的字節碼技術,在運行時創建子類代理的實例。當目標對象不存在接口時,Spring AOP就會采用這種方式,在子類實例中織入代碼。
2.15 既然有沒有接口都可以用CGLIB,為什么Spring還要使用JDK動態代理?
參考答案
在性能方面,CGLib創建的代理對象比JDK動態代理創建的代理對象高很多。但是,CGLib在創建代理對象時所花費的時間比JDK動態代理多很多。所以,對于單例的對象因為無需頻繁創建代理對象,采用CGLib動態代理比較合適。反之,對于多例的對象因為需要頻繁的創建代理對象,則JDK動態代理更合適。
2.16 Spring如何管理事務?
參考答案
Spring為事務管理提供了一致的編程模板,在高層次上建立了統一的事務抽象。也就是說,不管是選擇MyBatis、Hibernate、JPA還是Spring JDBC,Spring都可以讓用戶以統一的編程模型進行事務管理。
Spring支持兩種事務編程模型:
-
編程式事務
Spring提供了TransactionTemplate模板,利用該模板我們可以通過編程的方式實現事務管理,而無需關注資源獲取、復用、釋放、事務同步及異常處理等操作。相對于聲明式事務來說,這種方式相對麻煩一些,但是好在更為靈活,我們可以將事務管理的范圍控制的更為精確。
-
聲明式事務
Spring事務管理的亮點在于聲明式事務管理,它允許我們通過聲明的方式,在IoC配置中指定事務的邊界和事務屬性,Spring會自動在指定的事務邊界上應用事務屬性。相對于編程式事務來說,這種方式十分的方便,只需要在需要做事務管理的方法上,增加@Transactional注解,以聲明事務特征即可。
2.17 Spring的事務傳播方式有哪些?
參考答案
當我們調用一個業務方法時,它的內部可能會調用其他的業務方法,以完成一個完整的業務操作。這種業務方法嵌套調用的時候,如果這兩個方法都是要保證事務的,那么就要通過Spring的事務傳播機制控制當前事務如何傳播到被嵌套調用的業務方法中。
Spring在TransactionDefinition接口中規定了7種類型的事務傳播行為,它們規定了事務方法和事務方法發生嵌套調用時如何進行傳播,如下表:
| 事務傳播類型 | 說明 |
|---|---|
| PROPAGATION_REQUIRED | 如果當前沒有事務,則新建一個事務;如果已存在一個事務,則加入到這個事務中。這是最常見的選擇。 |
| PROPAGATION_SUPPORTS | 支持當前事務,如果當前沒有事務,則以非事務方式執行。 |
| PROPAGATION_MANDATORY | 使用當前的事務,如果當前沒有事務,則拋出異常。 |
| PROPAGATION_REQUIRES_NEW | 新建事務,如果當前存在事務,則把當前事務掛起。 |
| PROPAGATION_NOT_SUPPORTED | 以非事務方式執行操作,如果當前存在事務,則把當前事務掛起。 |
| PROPAGATION_NEVER | 以非事務方式執行操作,如果當前存在事務,則拋出異常。 |
| PROPAGATION_NESTED | 如果當前存在事務,則在嵌套事務內執行;如果當前沒有事務,則執行與PROPAGATION_REQUIRED類似的操作。 |
2.18 Spring的事務如何配置,常用注解有哪些?
參考答案
事務的打開、回滾和提交是由事務管理器來完成的,我們使用不同的數據庫訪問框架,就要使用與之對應的事務管理器。在Spring Boot中,當你添加了數據庫訪問框架的起步依賴時,它就會進行自動配置,即自動實例化正確的事務管理器。
對于聲明式事務,是使用@Transactional進行標注的。這個注解可以標注在類或者方法上。
- 當它標注在類上時,代表這個類所有公共(public)非靜態的方法都將啟用事務功能。
- 當它標注在方法上時,代表這個方法將啟用事務功能。
另外,在@Transactional注解上,我們可以使用isolation屬性聲明事務的隔離級別,使用propagation屬性聲明事務的傳播機制。
2.19 說一說你對聲明式事務的理解
參考答案
Spring事務管理的亮點在于聲明式事務管理,它允許我們通過聲明的方式,在IoC配置中指定事務的邊界和事務屬性,Spring會自動在指定的事務邊界上應用事務屬性。相對于編程式事務來說,這種方式十分的方便,只需要在需要做事務管理的方法上,增加@Transactional注解,以聲明事務特征即可。
3. Spring MVC
3.1 什么是MVC?
參考答案
MVC是一種設計模式,在這種模式下軟件被分為三層,即Model(模型)、View(視圖)、Controller(控制器)。Model代表的是數據,View代表的是用戶界面,Controller代表的是數據的處理邏輯,它是Model和View這兩層的橋梁。將軟件分層的好處是,可以將對象之間的耦合度降低,便于代碼的維護。
3.2 DAO層是做什么的?
參考答案
DAO是Data Access Obejct的縮寫,即數據訪問對象,在項目中它通常作為獨立的一層,專門用于訪問數據庫。這一層的具體實現技術有很多,常用的有Spring JDBC、Hibernate、JPA、MyBatis等,在Spring框架下無論采用哪一種技術訪問數據庫,它的編程模式都是統一的。
3.3 介紹一下Spring MVC的執行流程
參考答案
- 整個過程開始于客戶端發出的一個HTTP請求,Web應用服務器接收到這個請求。如果匹配DispatcherServlet的請求映射路徑,則Web容器將該請求轉交給DispatcherServlet處理。
- DispatcherServlet接收到這個請求后,將根據請求的信息(包括URL、HTTP方法、請求報文頭、請求參數、Cookie等)及HandlerMapping的配置找到處理請求的處理器(Handler)。可將HandlerMapping看做路由控制器,將Handler看做目標主機。值得注意的是,在Spring MVC中并沒有定義一個Handler接口,實際上任何一個Object都可以成為請求處理器。
- 當DispatcherServlet根據HandlerMapping得到對應當前請求的Handler后,通過HandlerAdapter對Handler進行封裝,再以統一的適配器接口調用Handler。HandlerAdapter是Spring MVC框架級接口,顧名思義,HandlerAdapter是一個適配器,它用統一的接口對各種Handler方法進行調用。
- 處理器完成業務邏 輯的處理后,將返回一個ModelAndView給DispatcherServlet,ModelAndView包含了視圖邏輯名和模型數據信息。
- ModelAndView中包含的是“邏輯視圖名”而非真正的視圖對象,DispatcherServlet借由ViewResolver完成邏輯視圖名到真實視圖對象的解析工作。
- 當得到真實的視圖對象View后,DispatcherServlet就使用這個View對象對ModelAndView中的模型數據進行視圖渲染。
- 最終客戶端得到的響應消息可能是一個普通的HTML頁面,也可能是一個XML或JSON串,甚至是一張圖片或一個PDF文檔等不同的媒體形式。
3.4 說一說你知道的Spring MVC注解
參考答案
@RequestMapping:
作用:該注解的作用就是用來處理請求地址映射的,也就是說將其中的處理器方法映射到url路徑上。
屬性:
- method:是讓你指定請求的method的類型,比如常用的有get和post。
- value:是指請求的實際地址,如果是多個地址就用{}來指定就可以啦。
- produces:指定返回的內容類型,當request請求頭中的Accept類型中包含指定的類型才可以返回的。
- consumes:指定處理請求的提交內容類型,比如一些json、html、text等的類型。
- headers:指定request中必須包含那些的headed值時,它才會用該方法處理請求的。
- params:指定request中一定要有的參數值,它才會使用該方法處理請求。
@RequestParam:
作用:是將請求參數綁定到你的控制器的方法參數上,是Spring MVC中的接收普通參數的注解。
屬性:
- value是請求參數中的名稱。
- required是請求參數是否必須提供參數,它的默認是true,意思是表示必須提供。
@RequestBody:
作用:如果作用在方法上,就表示該方法的返回結果是直接按寫入的Http responsebody中(一般在異步獲取數據時使用的注解)。
屬性:required,是否必須有請求體。它的默認值是true,在使用該注解時,值得注意的當為true時get的請求方式是報錯的,如果你取值為false的話,get的請求是null。
@PathVaribale:
作用:該注解是用于綁定url中的占位符,但是注意,spring3.0以后,url才開始支持占位符的,它是Spring MVC支持的rest風格url的一個重要的標志。
3.5 介紹一下Spring MVC的攔截器
參考答案
攔截器會對處理器進行攔截,這樣通過攔截器就可以增強處理器的功能。Spring MVC中,所有的攔截器都需要實現HandlerInterceptor接口,該接口包含如下三個方法:preHandle()、postHandle()、afterCompletion()。
這些方法的執行流程如下圖:
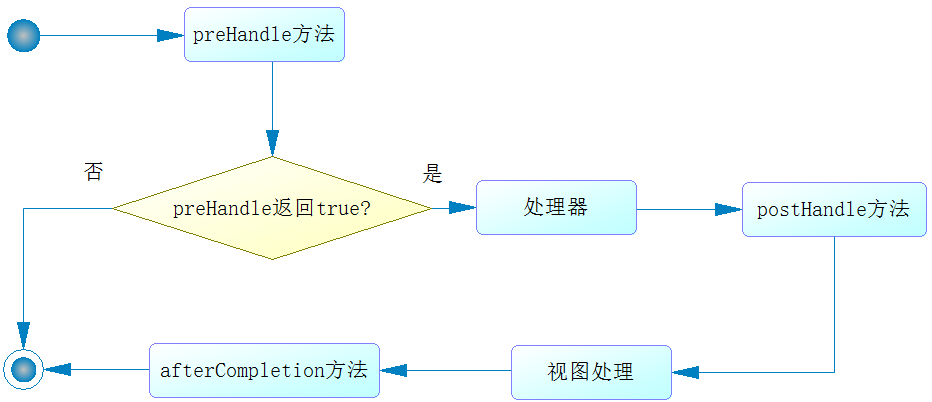
通過上圖可以看出,Spring MVC攔截器的執行流程如下:
- 執行preHandle方法,它會返回一個布爾值。如果為false,則結束所有流程,如果為true,則執行下一步。
- 執行處理器邏輯,它包含控制器的功能。
- 執行postHandle方法。
- 執行視圖解析和視圖渲染。
- 執行afterCompletion方法。
Spring MVC攔截器的開發步驟如下:
-
開發攔截器:
實現handlerInterceptor接口,從三個方法中選擇合適的方法,實現攔截時要執行的具體業務邏輯。
-
注冊攔截器:
定義配置類,并讓它實現WebMvcConfigurer接口,在接口的addInterceptors方法中,注冊攔截器,并定義該攔截器匹配哪些請求路徑。
3.6 怎么去做請求攔截?
參考答案
如果是對Controller記性攔截,則可以使用Spring MVC的攔截器。
如果是對所有的請求(如訪問靜態資源的請求)進行攔截,則可以使用Filter。
如果是對除了Controller之外的其他Bean的請求進行攔截,則可以使用Spring AOP。
4. MyBatis
4.1 談談MyBatis和JPA的區別
參考答案
ORM映射不同:
MyBatis是半自動的ORM框架,提供數據庫與結果集的映射;
JPA(默認采用Hibernate實現)是全自動的ORM框架,提供對象與數據庫的映射。
可移植性不同:
JPA通過它強大的映射結構和HQL語言,大大降低了對象與數據庫的耦合性;
MyBatis由于需要寫SQL,因此與數據庫的耦合性直接取決于SQL的寫法,如果SQL不具備通用性而用了很多數據庫的特性SQL的話,移植性就會降低很多,移植時成本很高。
日志系統的完整性不同:
JPA日志系統非常健全、涉及廣泛,包括:SQL記錄、關系異常、優化警告、緩存提示、臟數據警告等;
MyBatis除了基本的記錄功能外,日志功能薄弱很多。
SQL優化上的區別:
由于Mybatis的SQL都是寫在XML里,因此優化SQL比Hibernate方便很多。
而Hibernate的SQL很多都是自動生成的,無法直接維護SQL。雖有HQL,但功能還是不及SQL強大,見到報表等復雜需求時HQL就無能為力,也就是說HQL是有局限的Hhibernate雖然也支持原生SQL,但開發模式上卻與ORM不同,需要轉換思維,因此使用上不是非常方便。總之寫SQL的靈活度上Hibernate不及Mybatis。
4.2 MyBatis輸入輸出支持的類型有哪些?
參考答案
parameterType:
MyBatis支持多種輸入輸出類型,包括:
- 簡單的類型,如整數、小數、字符串等;
- 集合類型,如Map等;
- 自定義的JavaBean。
其中,簡單的類型,其數值直接映射到參數上。對于Map或JavaBean則將其屬性按照名稱映射到參數上。
4.3 MyBatis里如何實現一對多關聯查詢?
參考答案
一對多映射有兩種配置方式,都是使用collection標簽實現的。在此之前,為了能夠存儲一對多的數據,需要在主表對應的實體類中增加集合屬性,用于封裝子表對應的實體類。
嵌套查詢:
- 通過select標簽定義查詢主表的SQL,返回結果通過reusltMap進行映射。
- 在resultMap中,除了映射主表屬性,還要通過collection標簽映射子表屬性,該標簽需包含如下內容:
- 通過property屬性指定子表屬性名;
- 通過javaType屬性指定封裝子表屬性的集合類型;
- 通過ofType屬性指定子表的實體類型;
- 通過select屬性指定查詢子表所依賴的SQL,這個SQL需單獨定義,內部包含查詢子表的語句。
嵌套結果:
- 通過select標簽定義關聯查詢主表和子表的SQL,返回結果通過resultMap進行映射。
- 在resultMap中,除了映射主表屬性,還要通過collection標簽映射子表屬性,該標簽需包含如下內容:
- 通過property屬性指定子表屬性名;
- 通過ofType屬性指定子表的實體類型;
- 通過result子標簽定義子表字段和屬性的映射關系。
4.4 MyBatis中的$和#有什么區別?
參考答案
使用#設置參數時,MyBatis會創建預編譯的SQL語句,然后在執行SQL時MyBatis會為預編譯SQL中的占位符(?)賦值。預編譯的SQL語句執行效率高,并且可以防止注入攻擊。
使用$設置參數時,MyBatis只是創建普通的SQL語句,然后在執行SQL語句時MyBatis將參數直接拼入到SQL里。這種方式在效率、安全性上均不如前者,但是可以解決一些特殊情況下的問題。例如,在一些動態表格(根據不同的條件產生不同的動態列)中,我們要傳遞SQL的列名,根據某些列進行排序,或者傳遞列名給SQL都是比較常見的場景,這就無法使用預編譯的方式了。
4.5 既然不安全,為什么還需要?什么時候會用到它?
參考答案
它可以解決一些特殊情況下的問題。例如,在一些動態表格(根據不同的條件產生不同的動態列)中,我們要傳遞SQL的列名,根據某些列進行排序,或者傳遞列名給SQL都是比較常見的場景,這就無法使用預編譯的方式了。
4.6 MyBatis的xml文件和Mapper接口是怎么綁定的?
參考答案
是通過xml文件中,<mapper> 根標簽的namespace屬性進行綁定的,即namespace屬性的值需要配置成接口的全限定名稱,MyBatis內部就會通過這個值將這個接口與這個xml關聯起來。
4.7 MyBatis分頁和自己寫的分頁哪個效率高?
參考答案
自己寫的分頁效率高。
在MyBatis中,我們可以通過分頁插件實現分頁,也可以通過分頁SQL自己實現分頁。其中,分頁插件的原理是,攔截查詢SQL,在這個SQL基礎上自動為其添加limit分頁條件。它會大大的提高開發的效率,但是無法對分頁語句做出有針對性的優化,比如分頁偏移量很大的情況,而這些在自己寫的分頁SQL里卻是可以靈活實現的。
4.8 了解MyBatis緩存機制嗎?
參考答案
MyBatis的緩存分為一級緩存和二級緩存。
一級緩存:
一級緩存也叫本地緩存,它默認會啟用,并且不能關閉。一級緩存存在于SqlSession的生命周期中,即它是SqlSession級別的緩存。在同一個 SqlSession 中查詢時,MyBatis 會把執行的方法和參數通過算法生成緩存的鍵值,將鍵值和查詢結果存入一個Map對象中。如果同一個SqlSession 中執行的方法和參數完全一致,那么通過算法會生成相同的鍵值,當Map 緩存對象中己經存在該鍵值時,則會返回緩存中的對象。
二級緩存:
二級緩存存在于SqlSessionFactory 的生命周期中,即它是SqlSessionFactory級別的緩存。若想使用二級緩存,需要在如下兩處進行配置。
在MyBatis 的全局配置settings 中有一個參數cacheEnabled,這個參數是二級緩存的全局開關,默認值是true ,初始狀態為啟用狀態。
MyBatis 的二級緩存是和命名空間綁定的,即二級緩存需要配置在Mapper.xml 映射文件中。在保證二級緩存的全局配置開啟的情況下,給Mapper.xml 開啟二級緩存只需要在Mapper. xml 中添加如下代碼:
<cache />
二級緩存具有如下效果:
- 映射語句文件中的所有SELECT 語句將會被緩存。
- 映射語句文件中的所有時INSERT 、UPDATE 、DELETE 語句會刷新緩存。
- 緩存會使用Least Rece ntly U sed ( LRU ,最近最少使用的)算法來收回。
- 根據時間表(如no Flush Int erv al ,沒有刷新間隔),緩存不會以任何時間順序來刷新。
- 緩存會存儲集合或對象(無論查詢方法返回什么類型的值)的1024 個引用。
- 緩存會被視為read/write(可讀/可寫)的,意味著對象檢索不是共享的,而且可以安全地被調用者修改,而不干擾其他調用者或線程所做的潛在修改。
5. 其他
5.1 cookie和session的區別是什么?
參考答案
- 存儲位置不同:cookie存放于客戶端;session存放于服務端。
- 存儲容量不同:單個cookie保存的數據<=4KB,一個站點最多保存20個cookie;而session并沒有上限。
- 存儲方式不同:cookie只能保存ASCII字符串,并需要通過編碼當時存儲為Unicode字符或者二進制數據;session中能夠存儲任何類型的數據,例如字符串、整數、集合等。
- 隱私策略不同:cookie對客戶端是可見的,別有用心的人可以分析存放在本地的cookie并進行cookie欺騙,所以它是不安全的;session存儲在服務器上,對客戶端是透明的,不存在敏感信息泄露的風險。
- 生命周期不同:可以通過設置cookie的屬性,達到cookie長期有效的效果;session依賴于名為JSESSIONID的cookie,而該cookie的默認過期時間為-1,只需關閉窗口該session就會失效,因此session不能長期有效。
- 服務器壓力不同:cookie保存在客戶端,不占用服務器資源;session保管在服務器上,每個用戶都會產生一個session,如果并發量大的話,則會消耗大量的服務器內存。
- 瀏覽器支持不同:cookie是需要瀏覽器支持的,如果客戶端禁用了cookie,則會話跟蹤就會失效;運用session就需要使用URL重寫的方式,所有用到session的URL都要進行重寫,否則session會話跟蹤也會失效。
- 跨域支持不同:cookie支持跨域訪問,session不支持跨域訪問。
5.2 cookie和session各自適合的場景是什么?
參考答案
對于敏感數據,應存放在session里,因為cookie不安全。
對于普通數據,優先考慮存放在cookie里,這樣會減少對服務器資源的占用。
5.3 請介紹session的工作原理
參考答案
session依賴于cookie。
當客戶端首次訪問服務器時,服務器會為其創建一個session對象,該對象具有一個唯一標識SESSIONID。并且在響應階段,服務器會創建一個cookie,并將SESSIONID存入其中。
客戶端通過響應的cookie而持有SESSIONID,所以當它再次訪問服務器時,會通過cookie攜帶這個SESSIONID。服務器獲取到SESSIONID后,就可以找到與之對應的session對象,進而從這個session中獲取該客戶端的狀態。
5.4 get請求與post請求有什么區別?
參考答案
- GET在瀏覽器回退時是無害的,而POST會再次提交請求。
- GET產生的URL地址可以被Bookmark,而POST不可以。
- GET請求會被瀏覽器主動cache,而POST不會,除非手動設置。
- GET請求只能進行url編碼,而POST支持多種編碼方式。
- GET請求參數會被完整保留在瀏覽器歷史記錄里,而POST中的參數不會被保留。
- GET請求在URL中傳送的參數是有長度限制的,而POST沒有。
- 對參數的數據類型,GET只接受ASCII字符,而POST沒有限制。
- GET比POST更不安全,因為參數直接暴露在URL上,所以不能用來傳遞敏感信息。
- GET參數通過URL傳遞,POST放在Request body中。
5.5 get請求的參數能放到body里面嗎?
參考答案
GET請求是可以將參數放到BODY里面的,官方并沒有明確禁止,但給出的建議是這樣不符合規范,無法保證所有的實現都支持。這就意味著,如果你試圖這樣做,可能出現各種未知的問題,所以應該當避免。
5.6 post不冪等是為什么?
參考答案
HTTP方法的冪等性是指一次和多次請求某一個資源應該具有同樣的副作用。冪等性屬于語義范疇,正如編譯器只能幫助檢查語法錯誤一樣,HTTP規范也沒有辦法通過消息格式等語法手段來定義它。
POST所對應的URI并非創建的資源本身,而是資源的接收者。比如:POST http://www.forum.com/articles的語義是在http://www.forum.com/articles下創建一篇帖子,HTTP響應中應包含帖子的創建狀態以及帖子的URI。兩次相同的POST請求會在服務器端創建兩份資源,它們具有不同的URI。所以,POST方法不具備冪等性。
5.7 頁面報400錯誤是什么意思?
參考答案
400狀態碼標識請求的語義有誤,當前請求無法被服務器理解。除非進行修改,否則客戶端不應該重復提交這個請求。通常情況下,是本次請求中包含有錯誤的參數,此時應該排查前端傳遞的參數。
5.8 請求數據出現亂碼該怎么處理?
參考答案
服務端出現請求亂碼的原因是,客戶端編碼與服務器解碼方案不一致,可以有如下幾種解決辦法:
- 將獲得的數據按照客戶端編碼轉成BYTE,再將BYTE按服務端編碼轉成字符串,這種方案對各種請求方式均有效,但是十分的麻煩。
- 在接受請求數據之前,顯示聲明實體內容的編碼與服務器一致,這種方式只對POST請求有效。
- 修改服務器的配置文件,顯示聲明請求路徑的編碼與服務器一致,這種方式只對GET請求有效。
5.9 如何在SpringBoot框架下實現一個定時任務?
參考答案
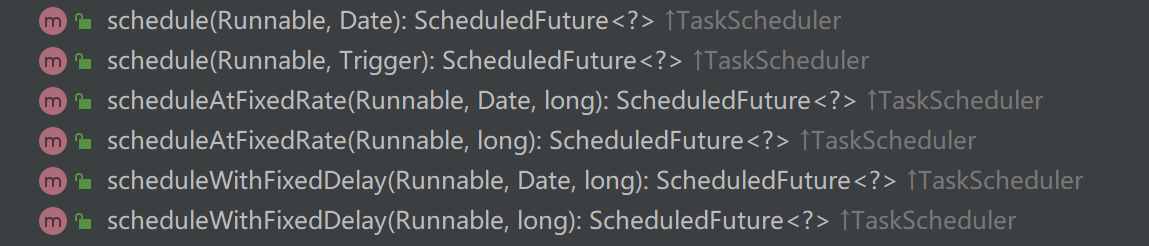
Spring給我們提供了可執行定時任務的線程池ThreadPoolTaskScheduler,該線程池提供了多個可以與執行定時任務的方法,如下圖。在Spring Boot中,只需要在配置類中啟用線程池注解,就可以直接使用這個線程池了。
5.10 調用接口時要記錄日志,該怎么設計?
參考答案
可以定義一個記錄日志的組件,并通過AOP將其織入到這個接口的調用中。這種方式對接口無需做任何改造,業務代碼中也無需增加任何調用的邏輯,完美地消除了記錄日志和業務代碼的耦合度。
5.11 了解Spring Boot JPA嗎?
參考答案
I。所以,POST方法不具備冪等性。
5.7 頁面報400錯誤是什么意思?
參考答案
400狀態碼標識請求的語義有誤,當前請求無法被服務器理解。除非進行修改,否則客戶端不應該重復提交這個請求。通常情況下,是本次請求中包含有錯誤的參數,此時應該排查前端傳遞的參數。
5.8 請求數據出現亂碼該怎么處理?
參考答案
服務端出現請求亂碼的原因是,客戶端編碼與服務器解碼方案不一致,可以有如下幾種解決辦法:
- 將獲得的數據按照客戶端編碼轉成BYTE,再將BYTE按服務端編碼轉成字符串,這種方案對各種請求方式均有效,但是十分的麻煩。
- 在接受請求數據之前,顯示聲明實體內容的編碼與服務器一致,這種方式只對POST請求有效。
- 修改服務器的配置文件,顯示聲明請求路徑的編碼與服務器一致,這種方式只對GET請求有效。
5.9 如何在SpringBoot框架下實現一個定時任務?
參考答案
Spring給我們提供了可執行定時任務的線程池ThreadPoolTaskScheduler,該線程池提供了多個可以與執行定時任務的方法,如下圖。在Spring Boot中,只需要在配置類中啟用線程池注解,就可以直接使用這個線程池了。
[外鏈圖片轉存中…(img-taMsqLji-1641471118189)]
5.10 調用接口時要記錄日志,該怎么設計?
參考答案
可以定義一個記錄日志的組件,并通過AOP將其織入到這個接口的調用中。這種方式對接口無需做任何改造,業務代碼中也無需增加任何調用的邏輯,完美地消除了記錄日志和業務代碼的耦合度。
5.11 了解Spring Boot JPA嗎?
參考答案
JPA即Java Persistence API,它是一個基于O/R映射的標準規范。也就是說它指定以了標準規則,不提供實現,軟件提供商可以按照標準規范來實現,而使用者只需按照規范中定義的方式來使用,不用和軟件提供商打交道。JPA主要實現有Hibernate、EclipseLink、OpenJPA等,我們使用JPA來開發,無論是采用哪一種實現方式都一樣。



















