文章目錄
- 目錄
- 1. 機器學習的定義
- 2. 機器學習的分類
- 2.1根據是否在人類監督下進行訓練
- 監督學習
- 非監督學習
- 半監督學習
- 強化學習
- 2.2根據是否可以動態漸進的學習
- 在線學習
- 批量學習
- 2.3根據是否在訓練數據過程中進行模式識別
- 實例學習
- 基于模型的學習
- 3. 機器學習中的一些常見名詞
- 4. 機器學習的挑戰
- 4.1 訓練的數據量不足
- 4.2 沒有代表性的數據
- 4.3 低質量的數據
- 4.4 不相關的特征
- 4.5 過擬合和欠擬合
- 5. 其他
- 5.1偏差與方差
- 概念
- 導致偏差和方差的原因
- 深度學習中的偏差與方差
- 偏差與方差的計算公式
- 偏差與方差的權衡(過擬合與模型復雜度的權衡)
- 5.2 生成模型與判別模型
- 概念
- 優缺點
- 常見模型
- 5.3 先驗概率與后驗概率
目錄
1. 機器學習的定義
機器學習是通過編程讓計算機能夠從數據中進行學習的科學(藝術)
從經驗E學習一些分類任務T和性能測量P,它在任務T中的性能(由P測量)隨著經驗E提升–湯姆.米切爾.1997
2. 機器學習的分類
2.1根據是否在人類監督下進行訓練
監督學習
在監督學習中用于訓練算法的數據中包含了答案,即標簽信息。
監督學習主要包括分類和回歸2個重要的任務。
重要的監督學習算法:
- KNN
- 線性回歸
- 邏輯回歸
- SVM
- 決策樹和隨機森林
- 神經網絡
非監督學習
在非監督學習中用于訓練算法的數據中沒有標簽信息。
非監督學習主要包括:聚類,可視化與降維,關聯性規則分析和異常檢測4個重要的任務
重要的聚類算法:
- K means
- 層次聚類
- 期望最大
可視化和降維 - PCA
- 核主成分分析
- LLE(局部線性嵌入)
- t-SNE(t分布領域嵌入算法)
關聯性規則學習
- Apriori算法
- Eclat算法
半監督學習
處理部分帶數據標簽的訓練數據,通常是大量數據不帶標簽,然后小部分數據帶標簽。
對數的半監督學習算法是監督學習算法和非監督算法的結合。
深度信念網絡是基于受限玻爾茲曼機的非監督組件。RBM是先用非監督的方法對數據進行訓練,在使用監督的方法歲整個系統進行微調。
強化學習
強化學習是智能體(Agent)以“試錯”的方式進行學習,通過與環境進行交互獲得的獎賞指導行為,目標是使智能體獲得最大的獎賞,強化學習不同于連接主義學習中的監督學習,主要表現在強化信號上,強化學習中由環境提供的強化信號是對產生動作的好壞作一種評價(通常為標量信號),而不是告訴強化學習系統RLS(reinforcement learning system)如何去產生正確的動作。由于外部環境提供的信息很少,RLS必須靠自身的經歷進行學習。通過這種方式,RLS在行動-評價的環境中獲得知識,改進行動方案以適應環境。
2.2根據是否可以動態漸進的學習
在線學習
與批量學習不同,在線學習假設訓練數據持續到來,通常利用一個訓練樣本更新當前的模型,大大降低了學習算法的空間復雜度和時間復雜度,實時性強。在大數據時代,大數據高速增長的特點為機器學習帶來了嚴峻的挑戰,在線學習可以有效地解決該問題,引起了學術界和工業界的廣泛關注。
批量學習
不能進行持續的學習,在線使用和離線學習完全分開,只是使用離線學習到的策略。
2.3根據是否在訓練數據過程中進行模式識別
實例學習
直接從實例當中進行學習,最簡單的方法就是查表,即所謂的記憶學習。其中KNN可以認為是一種基于實例的學習方法。
基于模型的學習
從樣本中進行歸納,然后建立樣本的模型,然后根據模型進行新樣本的預測,則為基于模型的學習。大部分的機器學習模型都是基于模型的學習方法。
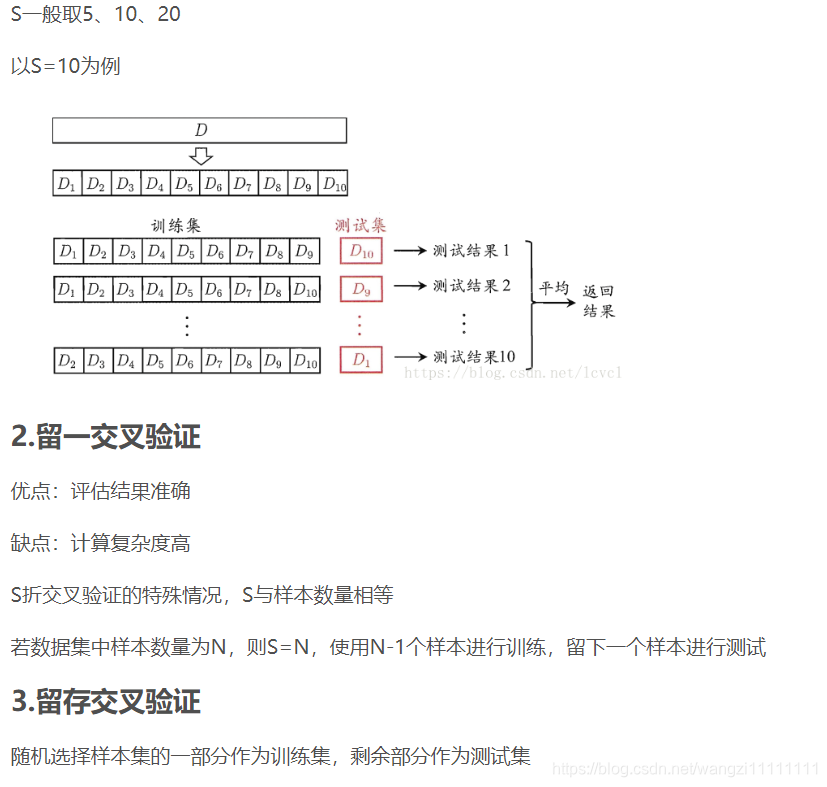
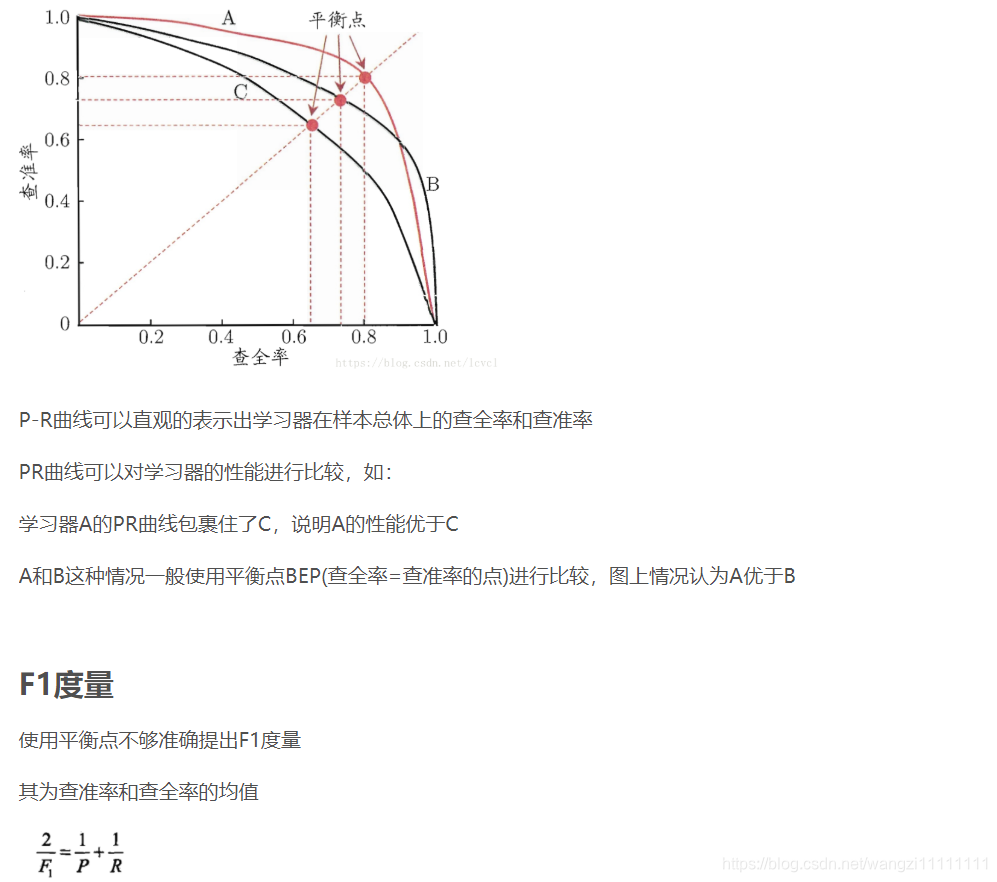
3. 機器學習中的一些常見名詞










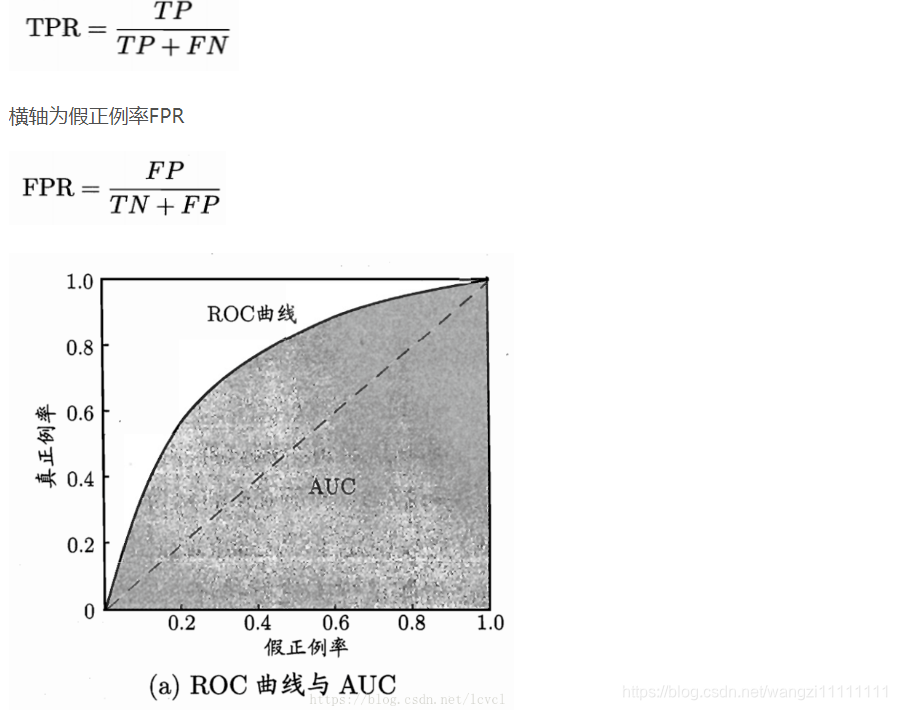
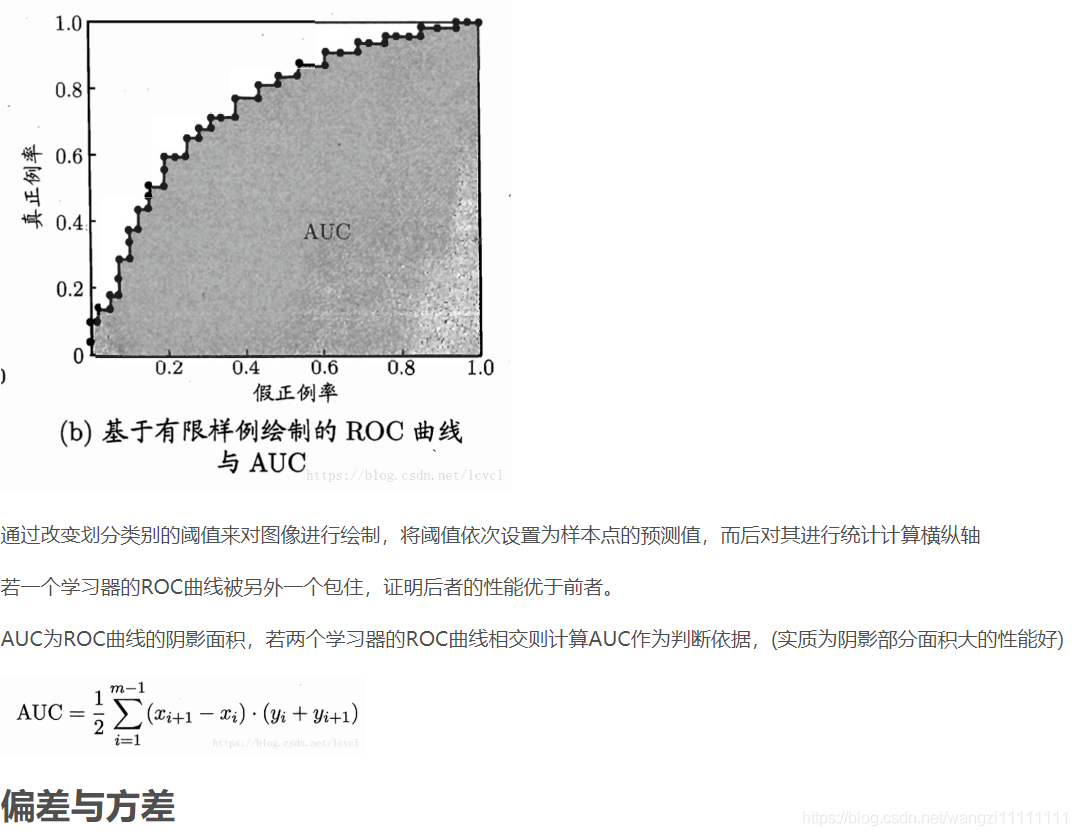

4. 機器學習的挑戰
4.1 訓練的數據量不足
- 在機器學習領域,往往是大數據+簡單模型的效果比小量數據+復雜模型的效果好。
- 對于復雜問題,數據比算法更重要
- 在實際的問題中,獲取大量的有標簽的數據往往是很困難的,所以優化算法也是比較重要的。
4.2 沒有代表性的數據
- 機器學習的本質是使用模型通過已有的數據去盡可能的擬合原始數據的分布情況,如果用于擬合的數據無法很好的代表全部數據的分布(即:采樣有偏的情況下),學習到的模型就是不準確的模型。
4.3 低質量的數據
- 訓練集中含有大量的噪聲,異常點,錯誤都會影響模型的訓練。
- 花費時間對數據進行清理是很有必要的。
4.4 不相關的特征
- 特征對于機器學習非常重要,所謂:進去的是垃圾,出來的也是垃圾。
- 特征工程是機器學習中很重要的一部分工作。
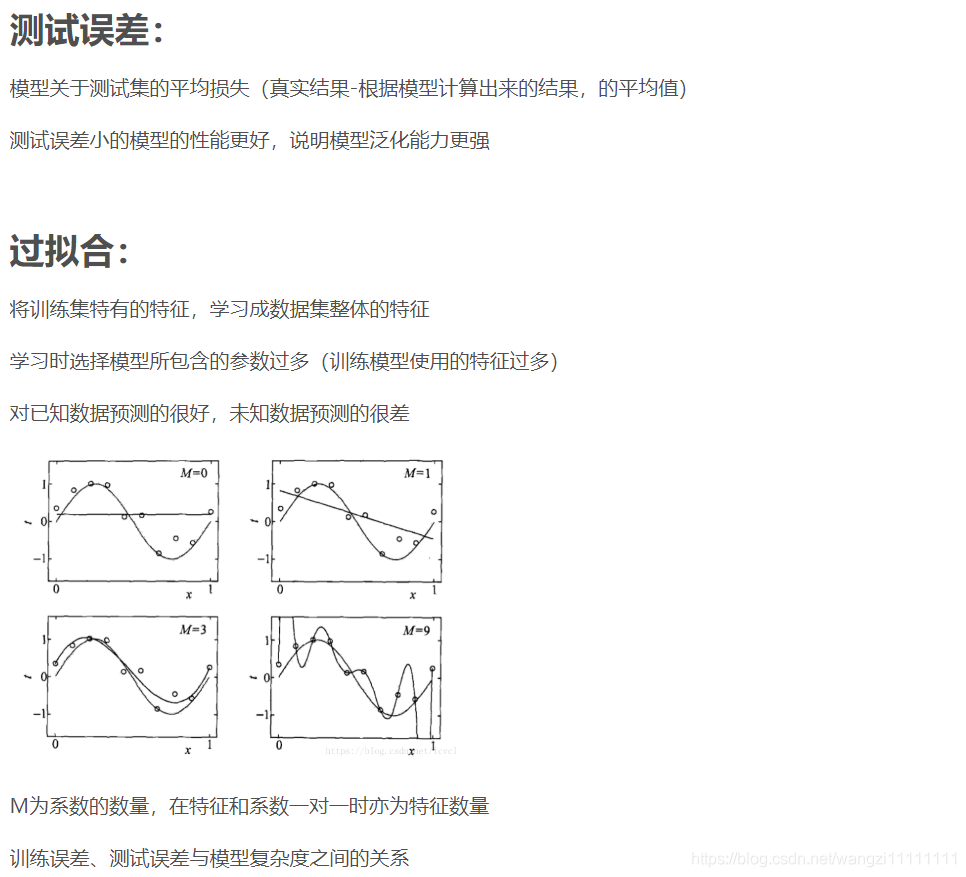
4.5 過擬合和欠擬合
5. 其他
5.1偏差與方差
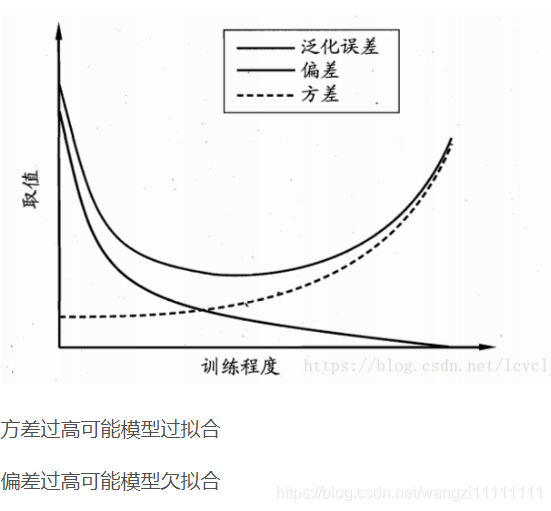
概念

導致偏差和方差的原因

深度學習中的偏差與方差
- 神經網絡的擬合能力非常強,因此它的訓練誤差(偏差)通常較小;
- 但是過強的擬合能力會導致較大的方差,使模型的測試誤差(泛化誤差)增大;
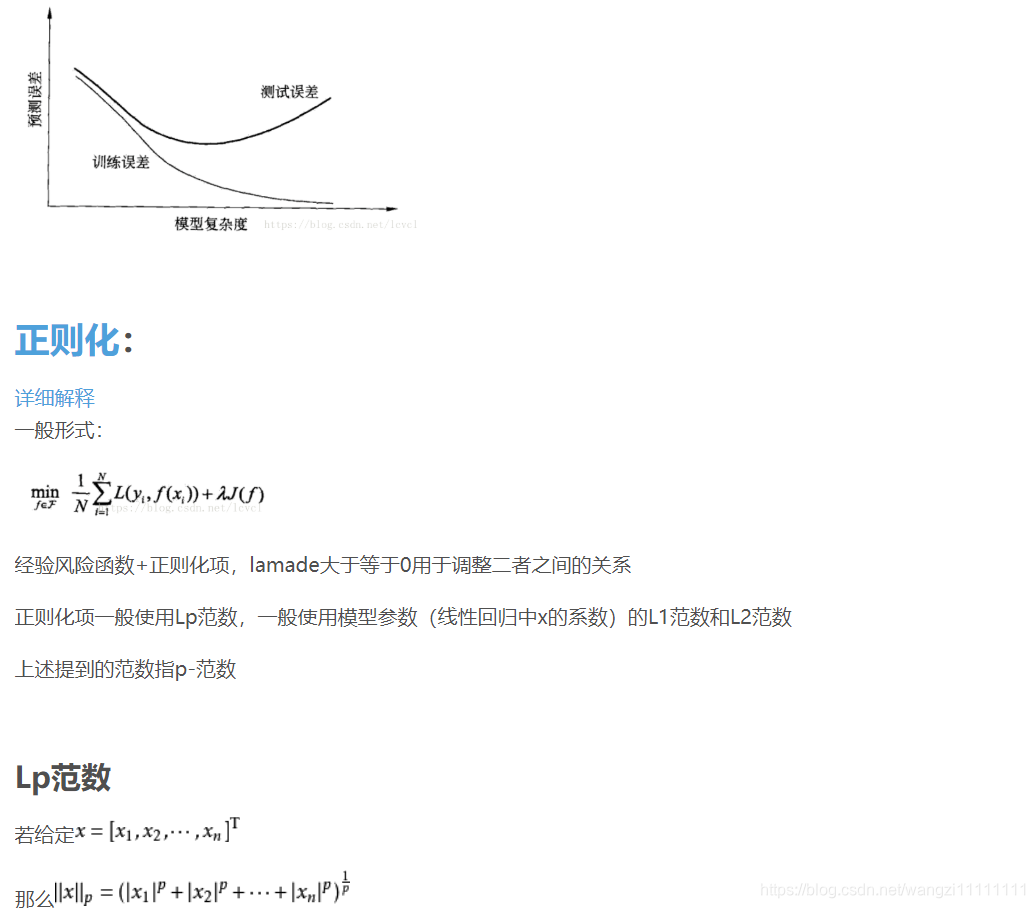
- 因此深度學習的核心工作之一就是研究如何降低模型的泛化誤差,這類方法統稱為正則化方法
偏差與方差的計算公式

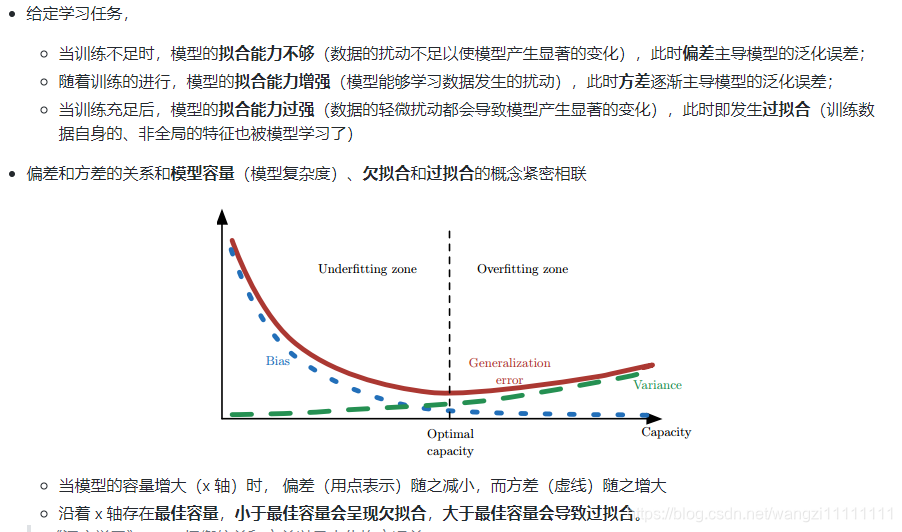
偏差與方差的權衡(過擬合與模型復雜度的權衡)
5.2 生成模型與判別模型
概念

優缺點

常見模型

5.3 先驗概率與后驗概率



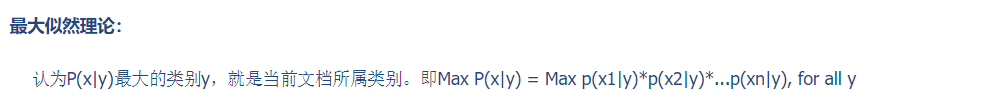
已將發生的概率就是最大的。

--c++,Python版本)

--c++,Python版本)

--c++,Python版本)


--c++,Python版本)

--c++,Python版本)

)
)

)
)

)
)
-touch,mkdir,rm,mv,cp,ls,cd,cat)