Prompt Tuning 和 P-Tuning 都屬于 參數高效微調方法(PEFT, Parameter-Efficient Fine-Tuning),主要是為了避免對大模型全部參數進行訓練,而是通過小規模參數(prompt embedding)來適配下游任務。但兩者的實現方式和應用場景有一些區別:
提示微調 僅在輸入嵌入層中加入可訓練的提示向量。在離散提示方法的基礎上,提示微調首先在輸入端插入一組連續嵌入數值的提示詞元,這些提示詞元可以以自由形式 或前
綴形式 來增強輸入文本,用于解決特定的下游任務。在具體實現中,只需要
將可學習的特定任務提示向量與輸入文本向量結合起來一起輸入到語言模型中。
P-tuning 提出了使用自由形式來組合輸入文本和提示向量,通過雙向 LSTM
來學習軟提示詞元的表示,它可以同時適用于自然語言理解和生成任務。另一種
代表性方法稱為 Prompt Tuning ,它以前綴形式添加提示,直接在輸入前拼
接連續型向量。在提示微調的訓練過程中,只有提示的嵌入向量會根據特定任務
進行監督學習,然而由于只在輸入層中包含了極少量的可訓練參數,有研究工作
表明該方法的性能高度依賴底層語言模型的能力 。下圖 展示了提示微調算
法的示意圖。
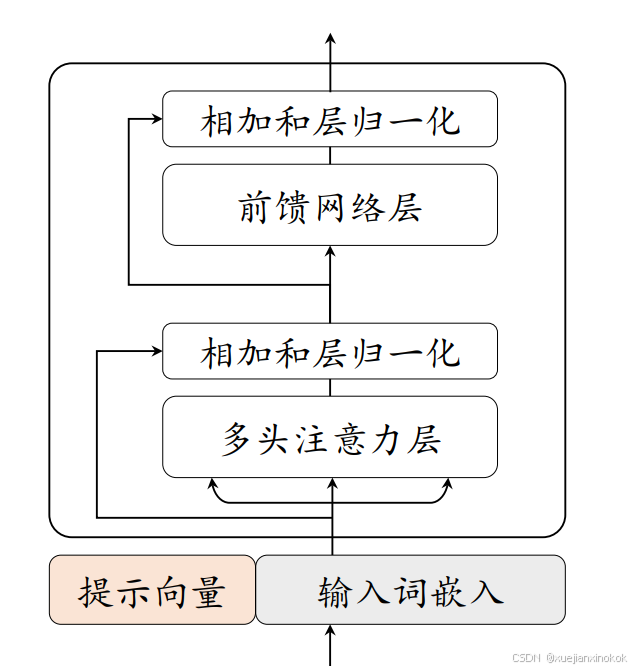
1. Prompt Tuning
-
提出者:Lester et al., 2021(Google)
-
核心思想:
- 在輸入序列前面加上 可學習的“虛擬token embedding”(prompt embedding),而不是直接調模型的原始參數。
- 這些 prompt embeddings 在訓練時會被更新,而模型的其他參數保持凍結。
-
應用方式:
- 常用于 encoder-decoder模型(如T5) 或 decoder-only(如GPT)任務。
- 輸入
[Prompt Embeddings] + [下游任務輸入]→ 模型輸出。
-
特點:
- 訓練參數量極小(只訓練 prompt embedding)。
- Prompt 是直接加在 embedding 層,和 token embedding 維度相同。
- 更偏向 NLP生成/分類任務。
2. P-Tuning
-
提出者:Liu et al., 2021(清華)
-
核心思想:
- 最初的 P-Tuning v1:用 連續可學習 embedding 代替離散 prompt。
- P-Tuning v2(改進版,ACL 2022):通過 深層插入虛擬 prompt embedding 到 Transformer 的多層中(不是只在輸入層)。
-
應用方式:
- 適用于 分類、生成、信息抽取 等多種任務。
- v2 更適合 小數據集場景,因為它的表示能力比單層 prompt tuning 更強。
-
特點:
- P-Tuning v1 和 Prompt Tuning 類似,都是加連續 embedding。
- P-Tuning v2 比 Prompt Tuning 更強,因為不僅在輸入層,而且在 Transformer 各層都插入可學習參數。
- 表現更接近全參數微調,但仍保持參數高效。
3. 區別總結
| 對比點 | Prompt Tuning | P-Tuning (v1) | P-Tuning v2 |
|---|---|---|---|
| 參數位置 | 輸入層前加虛擬 embedding | 輸入層前加連續 embedding | 各層 Transformer 插入虛擬 prompt |
| 訓練參數量 | 極少 | 極少 | 較少(但比 Prompt Tuning 多) |
| 表達能力 | 相對較弱 | 類似 Prompt Tuning | 更強,接近全量微調 |
| 適用任務 | NLP下游任務(分類、生成) | NLP任務 | 小數據/復雜任務,泛化更好 |
| 提出方 | Google (Lester et al., 2021) | 清華 (Liu et al., 2021) | 清華 (v2, ACL 2022) |
一句話總結:
- Prompt Tuning:只在輸入 embedding 層加可學習 prompt → 輕量但表達能力有限。
- P-Tuning:不僅能在輸入層加 embedding,還能在 Transformer 深層插入虛擬 prompt(尤其 v2) → 表達能力更強,效果接近全參數微調。
舉例說明。
1. 普通 Embedding(離散 token embedding)
在 NLP 里,輸入通常是離散的 token(如 “apple”、“我”、“中國”)。
這些 token 會先通過 詞表查找 變成向量:
例如詞表大小 = 10000,embedding 維度 = 768:
"apple" → [0.12, -0.34, 0.98, ... , 0.45] (768維向量)
"中國" → [0.87, 0.22, -0.54, ... , -0.11]
這些 embedding 是模型在預訓練時學好的。
2. 虛擬 embedding(virtual tokens / prompt embedding)
- 意思:人為加一些 不存在于詞表中的“假token”,但是它們有 embedding 向量。
- 這些向量是 隨機初始化 的,然后通過訓練學習,而不是固定的詞表 lookup。
- 它們本身沒有對應的文字,只是模型前面附加的“提示信號”。
舉例:
假設我們要做 情感分類(句子 → 積極/消極),輸入是:
"這部電影很精彩"
用 Prompt Tuning 時,可以加 5 個虛擬 token:
[v1][v2][v3][v4][v5] 這部電影很精彩
其中 [v1]...[v5] 就是 虛擬 embedding:
[v1] → [0.01, 0.77, -0.32, ...]
[v2] → [0.55, -0.88, 0.14, ...]
...
這些 embedding 不屬于詞表,但會在訓練過程中學會 如何引導模型輸出“積極/消極”。
3. 連續 embedding(continuous prompt)
- 意思:Prompt 不再用自然語言(“Please classify the sentiment…”),而是直接用 連續向量。
- 這個概念最早是 P-Tuning v1 提的,本質和虛擬 embedding 很像,但強調它是 連續空間里的可學習向量,而不是離散 token(不可再映射回“文字”)。
舉例:
離散 prompt(人寫的文字)可能是:
"這部電影很精彩 [MASK]"
連續 prompt(P-Tuning)則是:
[0.12, -0.33, 0.98, ...] (embedding1)
[0.54, 0.11, -0.66, ...] (embedding2)
[0.22, -0.77, 0.44, ...] (embedding3)
這部電影很精彩
區別在于:
- 離散 prompt = 用真實 token(如 “Please”, “answer”)拼出來。
- 連續/虛擬 prompt = 直接用可訓練的向量,不需要映射回文字。
4. 總結
-
虛擬 embedding = 給模型輸入前面加“假 token”,它們的 embedding 隨訓練調整。
-
連續 embedding = 直接訓練連續的 embedding 向量,不一定對應詞表里的任何 token。
-
本質上兩者差別不大,很多時候是不同論文里對類似概念的叫法,區別主要在:
- Prompt Tuning 強調 虛擬 token embedding
- P-Tuning 強調 連續可學習 embedding(不依賴離散 token)
下邊是一個 PyTorch 示例,演示如何在輸入序列前面加上 虛擬/連續 embedding。
假設我們有一個簡化的模型(類似 BERT),輸入是 token embedding,我們想在輸入前面加幾個可學習的 prompt embedding。
🔹 PyTorch 示例代碼
import torch
import torch.nn as nnclass SimpleModel(nn.Module):def __init__(self, vocab_size=10000, embed_dim=16, prompt_len=5):super().__init__()# 普通 embedding (詞表)self.embedding = nn.Embedding(vocab_size, embed_dim)# prompt embedding (虛擬/連續向量,不屬于詞表)self.prompt_embedding = nn.Parameter(torch.randn(prompt_len, embed_dim))# 一個簡單的分類頭self.fc = nn.Linear(embed_dim, 2) # 假設2分類任務def forward(self, input_ids):"""input_ids: [batch_size, seq_len] (普通輸入token的id)"""batch_size = input_ids.size(0)# 1. 把 token id 轉換成 embeddingtoken_embeds = self.embedding(input_ids) # [batch, seq_len, embed_dim]# 2. prompt embedding (復制到 batch 維度)prompt_embeds = self.prompt_embedding.unsqueeze(0).expand(batch_size, -1, -1) # [batch, prompt_len, embed_dim]# 3. 拼接 prompt 和原始輸入full_embeds = torch.cat([prompt_embeds, token_embeds], dim=1) # [batch, prompt_len+seq_len, embed_dim]# 假設我們只取最后一個 token 位置做分類last_hidden = full_embeds[:, -1, :] # [batch, embed_dim]# 分類logits = self.fc(last_hidden)return logits# ======================
# 🔹 測試
# ======================
batch_size = 2
seq_len = 4
vocab_size = 10000
embed_dim = 16
prompt_len = 5model = SimpleModel(vocab_size, embed_dim, prompt_len)# 模擬兩個樣本,每個長度為4
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len))print("輸入 token ids:\n", input_ids)logits = model(input_ids)
print("輸出 logits:\n", logits)
🔹 運行邏輯說明
-
普通 embedding:把輸入 token id 轉成向量。
- 例如
[12, 87, 325, 99] → 4個 embedding
- 例如
-
prompt embedding:訓練時額外引入的向量,例如
5 個虛擬 token。- 例如
[p1, p2, p3, p4, p5] → 5個 embedding
- 例如
-
拼接輸入:
[p1, p2, p3, p4, p5, token1, token2, token3, token4] -
模型只更新 prompt embedding,而原始模型參數可以凍結(只讓
self.prompt_embedding學習)。
)
)
















 MyBatis-plus)
