LeNet5
LeNet5可以說是最早的卷積神經網絡了,它發表于1998年,論文原文Gradient-Based Learning Applied to Doucment Recognition作者是Yann Le Cun等。下面對LeNet5網絡架構進行簡單的說明,有興趣的同學可以去參考原文,論文原文地址 http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf。
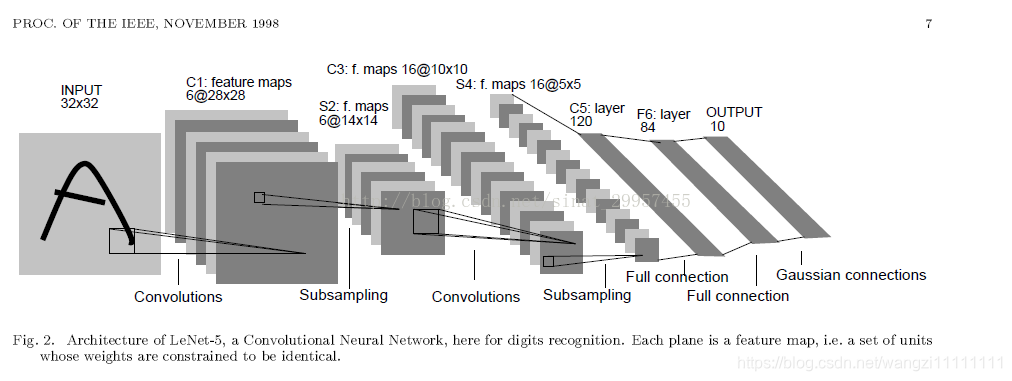
Conv1: f=[5,5], s=[1,1], padding=’valid’
Pool1: f=[2,2], s=[2,2]
Conv2: f=[5,5], s=[1,1], padding=’valid’
Pool2: f=[2,2], s=[1,1]
fc1: 1024 relu
fc2: 200 relu
fc3: 6 softMax
(m,64,64,3)-(m,60,60,8)-(m,30,30,8)-(m,26,26,16)-(m,13,13,16)
(m,1024)-(m,200)-(m,6)
def LeNet5(input_shape=(64,64,3), classes=6):X_input = Input(input_shape)X = Conv2D(filters=8, kernel_size=(5,5), strides=(1,1), padding='valid',name='conv1')(X_input)X = MaxPooling2D((2,2), strides=(2,2), name='maxpool1')(X)X = Conv2D(filters=16, kernel_size=(5,5), strides=(1,1), padding='valid',name='conv2')(X)X = MaxPooling2D((2,2), strides=(2,2), name='maxpool2')(X)X = Flatten()(X)X = Dense(1024, activation='relu', name='fc1')(X)X = Dense(200, activation='relu', name='fc2')(X)X = Dense(classes, activation='softmax', name='fc3')(X)model = Model(inputs=X_input, outputs=X, name='LeNet5')return model
卷積神經網絡在本質上是一種輸入到輸出的映射,它能夠學習大量的輸入與輸出之間的映射關系,而不需要任何輸入與輸出之間的精確的數學表達式,只要用已知的模式對卷積神經網絡加以訓練,網絡就具有輸入與輸出之間的映射能力。卷積網絡是有監督學習,所以它的樣本集都形如:(輸入向量,理想輸出向量)之類的向量對構成。
在訓練之前,所有權值都用一些不同的小隨機數進行初始化,小的隨機數可以保證網絡不會因權值太大而進入飽和狀態,從而導致訓練失敗。不同則保證網絡可以正常學習。
如果要是用相同的數去初始化矩陣,網絡會沒有學習的能力。
網絡的訓練過程為:
分為四步:
(1) 在一批數據中取樣(Sample a batch of data)
(2)前向過程計算得到損失(Forward prop it through the graph, get loss)
(3)反向傳播計算梯度(Backprop to calculate the gradient)
(4)利用梯度進行梯度的更新(Updata the parameters using the gradient)
這里,網絡的訓練主要分為2個大的階段:
第一階段,向前傳播階段:
1)從樣本集中取一個樣本(X,Yp),將X輸入網絡;
2)計算相應的實際輸出Op。
在此階段,信息從輸入層經過逐級的變換,傳送到輸出層。這個過程也是網絡在完成訓練后正常運行時執行的過程。在此過程中,網絡執行的是計算(實際上就是輸入與每層的權值矩陣相點乘,得到最后的輸出結果):
Op=Fn(…(F2(F1(XpW(1))W(2))…)W(n))
第二階段,向后傳播階段
1)算實際輸出Op與相應的理想輸出Yp的差;
2)按極小化誤差的方法反向傳播調整權矩陣。
AlexNet
1、AlexNet網絡結構
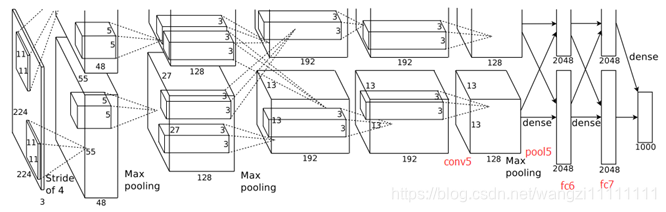
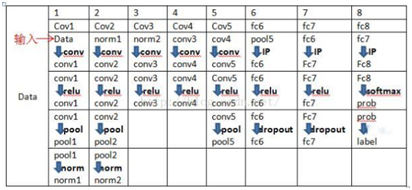

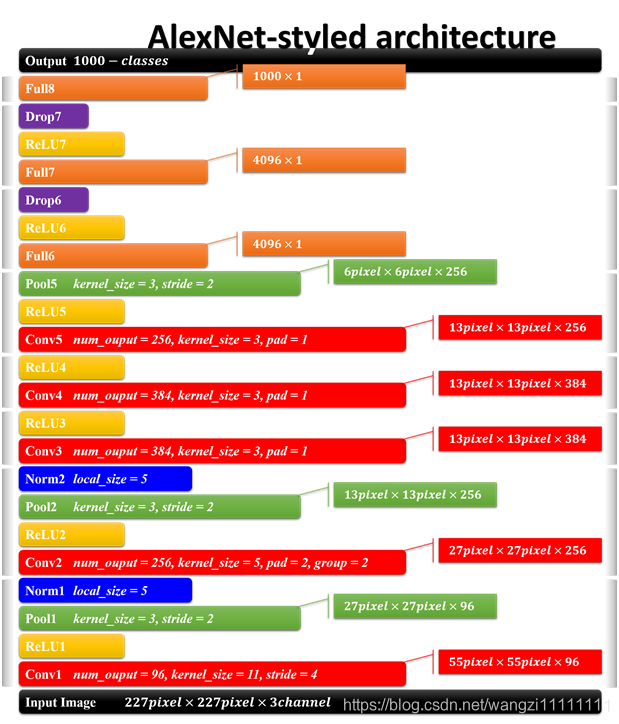

2、AlexNet應用在手勢RGB圖片
網絡結構
Input (64,64,3)Conv1 f=[5,5], s=[1,1], (60,60,8) Relu1
Maxpool1 f=[2,2], s=[2,2], (30,30,8) LRN1Conv2 f=[5,5] , s=[1,1] , (26,26,16) Relu2
Maxpool2 f=[2,2], s=[2,2], (13,13,16) LRN2Conv3 f=[3,3], s=[1,1], padding=’same’, (13,13,32) Relu3Conv4 f=[3,3], s=[1,1], padding=’same’, (13,13,32) Relu4Conv5 f=[3,3], s=[1,1], padding=’same’, (13,13,16) Relu5
Avepool1 f=[3,3], s=[2,2], (6,6,16)Flatten 6*6*16Fc1 1024 Relu6 Dropout1Fc2 1024 Relu7 Dropout2Fc3 6 Softmax代碼實現
def AlexNet(input_shape=(64,64,3), classes=6):X_input = Input(input_shape)"conv layer 1"X = Conv2D(filters=8, kernel_size=(5,5), strides=(1,1), padding='valid',name='conv1')(X_input)X = Activation('relu')(X)X = MaxPooling2D((2,2), strides=(2,2), name='maxpool1')(X)# X = LRN2D(alpha=0.0001, beta=0.75)(X)"conv layer 2"X = Conv2D(filters=16, kernel_size=(5,5), strides=(1,1), padding='valid',name='conv2')(X)X = Activation('relu')(X)X = MaxPooling2D((2,2), strides=(2,2), name='maxpool2')(X)# X = LRN2D(alpha=0.0001, beta=0.75)(X)"conv layer 3"X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same',name='conv3')(X)X = Activation('relu')(X)"conv layer 4"X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), padding='same',name='conv4')(X)X = Activation('relu')(X)"conv layer 5"X = Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), padding='same',name='conv5')(X)X = Activation('relu')(X)X = AveragePooling2D((3,3), strides=(2,2), name='maxpool3')(X)"flatten, fc1, fc2, fc3"X = Flatten()(X)X = Dense(1024, activation='relu', name='fc1')(X)X = Dense(1024, activation='relu', name='fc2')(X)X = Dense(classes, activation='softmax', name='fc3')(X)model = Model(inputs=X_input, outputs=X, name='AlexNet')return model

-while語句+賦值運算符號+轉義字符)

)
-Generative Adversarial Net-代碼實現資料)
--典型CNN結構(VGG13,16,19))

-內置/自己設計的損失函數使用)

-- Network in Network(NIN))
-tensor常用操作)
)
-- 經典CNN網絡結構(Inception (v1-v4)))
-函數,lambda語句)
-- Residual Network (ResNet))
-模塊)

-- DenseNet)

-window7配置iPython)