tensor常用數學操作
- 1. 隨機數
- 1.1 torch.rand() - 均勻分布數字
- 1.2 torch.randn() - 正態分布數字
- 2. 求和
- 2.1 torch.sum(data, dim)
- 2.2 numpy.sum(data, axis)
- 3. 求積
- 3.1 點乘--對應位置相乘
- 3.2 矩陣乘法
- 4. 均值、方差
- 4.1 torch tensor.mean() .std()
- 4.2 numpy array.mean() .std()
- 4.3 numpy 與torch .std()計算公式差別
- 5 求冪運算--torch.pow()
- 6. tensor 取值
- 6.1 scaler.item()
- 6.2 tensor.tolist()
- 7. 降升維
- 7.1 torch.squeeze() 降維
- 7.2 torch.unsqueeze() 升維
- 8. 最大/最小/非零 值索引
- 8.1 tensor.argmax()
- 8.2 tensor.argmin()
- 8.3 tensor.nonzero()
- 9. 矩陣拼接
- 9.1 torch.cat((a, b, c), dim )
- 9.2 numpy.concatenate((a,b), axis)
- 10. 矩陣拉伸
- 10.1 torch.flatten()
- 10.2 numpy.matrix.flatten
import torch
1. 隨機數
1.1 torch.rand() - 均勻分布數字
產生大小指定的,[0,1)之間的均勻分布的樣本.
> torch.rand(2,3)
>>tensor([[0.0270, 0.9856, 0.6599],[0.2237, 0.3888, 0.4566]])
> torch.rand(3,1)
>>tensor([[0.1268],[0.3370],[0.5097]])
1.2 torch.randn() - 正態分布數字
產生大小為指定的,正態分布的采樣點,數據類型是tensor
> torch.randn(4)
>>tensor([-2.1436, 0.9966, 2.3426, -0.6366])>torch.randn(2, 3)
>>tensor([[ 1.5954, 2.8929, -1.0923],[ 1.1719, -0.4709, -0.1996]])
2. 求和
2.1 torch.sum(data, dim)
>>> a=torch.ones(2,3)
>>> a
tensor([[1., 1., 1.],[1., 1., 1.]])
# 按行求和
>>> b=torch.sum(a,1) # 每列疊加,按行求和
>>> b
tensor([3., 3.])
>>> b.size()
torch.Size([2])
# 按列求和
>>> d=torch.sum(a,0) # 每行疊加,按列求和
>>> d
tensor([2., 2., 2.])
>>> d.size()
torch.Size([3])
2.2 numpy.sum(data, axis)
>>> import numpy as np
>>> np.sum([[0, 1], [0, 5]], axis=0) #每行疊加,按列求和
array([0, 6])
>>> np.sum([[0, 1], [0, 5]], axis=1)
array([1, 5])
3. 求積
3.1 點乘–對應位置相乘
數組和矩陣對應位置相乘,輸出與相乘數組/矩陣的大小一致
np.multiply()
torch直接用* 就能實現
3.2 矩陣乘法
矩陣乘法:兩個矩陣需要滿足一定的行列關系
torch.matmul(tensor1, tensor2)
numpy.matmul(array1, array2)
4. 均值、方差
4.1 torch tensor.mean() .std()
>a.mean() # a為Tensor型變量
>a.std()>torch.mean(a) # a為Tensor型變量
>torch.std(a)>>> torch.Tensor([1,2,3,4,5])
tensor([1., 2., 3., 4., 5.])
>>> a=torch.Tensor([1,2,3,4,5])
>>> a.mean()
tensor(3.)
>>> torch.mean(a)
tensor(3.)
>>> a.std()
tensor(1.5811)
>>>> torch.std(a)
tensor(1.5811) # 注意和numpy求解的區別
torch.mean(input) 輸出input 各個元素的的均值,不指定任何參數就是所有元素的算術平均值,指定參數可以計算每一行或者 每一列的算術平均數
> a = torch.randn(4, 4)
>>tensor([[-0.3841, 0.6320, 0.4254, -0.7384],[-0.9644, 1.0131, -0.6549, -1.4279],[-0.2951, -1.3350, -0.7694, 0.5600],[ 1.0842, -0.9580, 0.3623, 0.2343]])
# 每一行的平均值
> torch.mean(a, 1, True) #dim=true,計算每一行的平均數,輸出與輸入有相同的維度:兩維度(4,1)
>>tensor([[-0.0163],[-0.5085],[-0.4599],[ 0.1807]])> torch.mean(a, 1) # 不設置dim,默認計算每一行的平均數,內嵌了一個torch.squeeze(),將數值為1的維度壓縮(4,)
>>tensor([-0.0163, -0.5085, -0.4599, 0.1807])
4.2 numpy array.mean() .std()
>a.mean() # a為np array型變量
>a.std()>numpy.mean(a) # a為np array型變量
>numpy.std(a)
>>> import numpy
>>> c=numpy.array([1,2,3,4,5])
>>> c.mean()
3.0
>>> numpy.mean(c)
3.0
>>> c.std()
1.4142135623730951
>>> numpy.std(c)
1.4142135623730951>>> d=numpy.array([1,1,1,1])
>>> d.mean()
1.0
>>> d.std()
0.0
4.3 numpy 與torch .std()計算公式差別
numpy:
std=1N∑i=1N(xi?x ̄)2std=\sqrt{\frac{1}{N}\sum_{i=1}^N(x_i-\overline{x})^2}std=N1?i=1∑N?(xi??x)2?
torch:
std=1N?1∑i=1N(xi?x ̄)2std=\sqrt{\frac{1}{N-1}\sum_{i=1}^N(x_i-\overline{x})^2}std=N?11?i=1∑N?(xi??x)2?
5 求冪運算–torch.pow()
對輸入的每分量求冪次運算
>>> a = torch.randn(4)
>>> a
tensor([ 0.4331, 1.2475, 0.6834, -0.2791])
>>> torch.pow(a, 2)
tensor([ 0.1875, 1.5561, 0.4670, 0.0779])>>> exp = torch.arange(1., 5.)
>>> a = torch.arange(1., 5.)
>>> a
tensor([ 1., 2., 3., 4.])
>>> exp
tensor([ 1., 2., 3., 4.])
>>> torch.pow(a, exp)
tensor([ 1., 4., 27., 256.])
和numpy中的numpy.power()作用類似。
6. tensor 取值
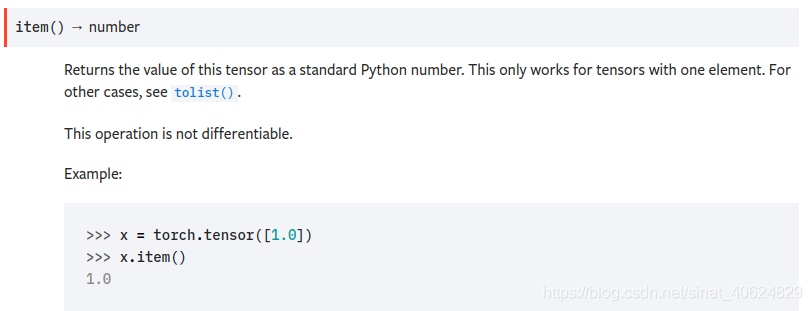
6.1 scaler.item()
一個Tensor調用.item()方法就可以返回這個Tensor 對應的標準python 類型的數據.注意事項,只針對一個元素的標量.若是向量,可以調用tolist()方法.
 在低版本的torch中tensor沒有.item()屬性,那么直接用[0]訪問其中的數據.
在低版本的torch中tensor沒有.item()屬性,那么直接用[0]訪問其中的數據.
>>> import torch
>>>c=torch.tensor([2.5555555])
>>> c2.5556
[torch.FloatTensor of size 1]
>>> c[0]
2.555555582046509
>>> round(c[0],3)
2.556
6.2 tensor.tolist()
(略)
7. 降升維
7.1 torch.squeeze() 降維
將輸入所有為1的維度去除(2,1)-> (2,)(以行向量的形式存在)
torch.squeeze(input, dim=None, out=None)
> x = torch.zeros(2, 1, 2, 1, 2)
> x.size()
>>torch.Size([2, 1, 2, 1, 2])
>
> y = torch.squeeze(x)
> y.size()
>>torch.Size([2, 2, 2])
7.2 torch.unsqueeze() 升維
Returns a new tensor with a dimension of size one inserted at the specified position)
給數據增加一維度,常看到數據的維度為.size([])懵逼了,在后續計算的時候會造成問題。所以需要給數據升維度。
> x = torch.tensor([1, 2, 3, 4])
>torch.unsqueeze(x, 0)
>>tensor([[ 1, 2, 3, 4]])
>
>torch.unsqueeze(x, 1)
>>tensor([[ 1],[ 2],[ 3],[ 4]])
8. 最大/最小/非零 值索引
8.1 tensor.argmax()
tensor.argmax(dim)
返回tensor最大的值對應的index。dim 不設置-全部元素的最大值,dim = 0 每列的最大值,dim = 1每行的最大值。
>>> a = torch.randn(3,4)
>>> a
tensor([[ 1.1360, -0.5890, 1.8444, 0.6960],[ 0.3462, -1.1812, -1.5536, 0.4504],[-0.4464, -0.5600, -0.1655, 0.3914]])
>>> a.argmax()
tensor(2) # 按行拉成一維向量,對應的小次奧
>>> a.argmax(dim = 0)
tensor([0, 2, 0, 0]) # 每一列最大值的索引
>>> a.argmax(dim = 1)
tensor([2, 3, 3]) # 每一行最大值索引
8.2 tensor.argmin()
與tensor.argmax() 用法相同,在多分類問題求準確率時會用到。
output_labels = outputs.argmax(dim = 1)
train_acc = (output_labels == labels).float().mean()
8.3 tensor.nonzero()
返回非零元素對應的下標
>>> a = torch.tensor([[1,0],[0,3]])
>>> a.nonzero()
tensor([[0, 0],[1, 1]])
>>> a= torch.tensor([1,2,3,0,4,5,0])
>>> a.nonzero()
tensor([[0],[1],[2],[4],[5]])
9. 矩陣拼接
9.1 torch.cat((a, b, c), dim )
>>> x = torch.randn(2, 3)
>>> x
tensor([[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 0)
tensor([[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497],[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497],[ 0.6580, -1.0969, -0.4614],[-0.1034, -0.5790, 0.1497]])
>>> torch.cat((x, x, x), 1)
tensor([[ 0.6580, -1.0969, -0.4614, 0.6580, -1.0969, -0.4614, 0.6580,-1.0969, -0.4614],[-0.1034, -0.5790, 0.1497, -0.1034, -0.5790, 0.1497, -0.1034,-0.5790, 0.1497]])
9.2 numpy.concatenate((a,b), axis)
>>> a = np.array([[1, 2], [3, 4]])
>>> b = np.array([[5, 6]])
>>> np.concatenate((a, b), axis=0)
array([[1, 2],[3, 4],[5, 6]])
>>> np.concatenate((a, b.T), axis=1)
array([[1, 2, 5],[3, 4, 6]])
>>> np.concatenate((a, b), axis=None)
array([1, 2, 3, 4, 5, 6])
10. 矩陣拉伸
10.1 torch.flatten()
矩陣按行展開:
>>> t = torch.tensor([[[1, 2],[3, 4]],[[5, 6],[7, 8]]])
>>> torch.flatten(t)
tensor([1, 2, 3, 4, 5, 6, 7, 8])
>>> torch.flatten(t, start_dim=1)
tensor([[1, 2, 3, 4],[5, 6, 7, 8]])10.2 numpy.matrix.flatten
>>> m = np.matrix([[1,2], [3,4]])
>>> m.flatten()
matrix([[1, 2, 3, 4]])
>>> m.flatten('F')
matrix([[1, 3, 2, 4]])
)
-- 經典CNN網絡結構(Inception (v1-v4)))
-函數,lambda語句)
-- Residual Network (ResNet))
-模塊)

-- DenseNet)

-window7配置iPython)
-- Capsules Networks(CapsNet))

-列表list,for循環)
-- GAN)
--try-expect)

-Argparse 簡易使用教程)


-元組tuple)
 Keras)