文章目錄
- 目錄
- 1.VGG結構
- 2.VGG結構解釋
- 3.3*3卷積核的優點
- 4.VGG的muti-scale方法
- 5.VGG的應用
目錄
1.VGG結構
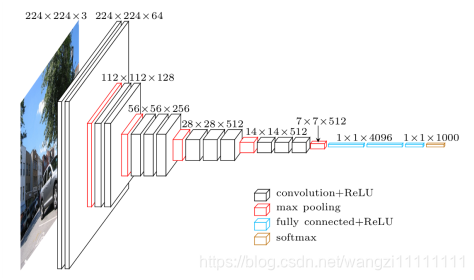
? LeNet5用大的卷積核來獲取圖像的相似特征
? AlexNet用99、1111的濾波器
? VGG 巨大的進展是通過依次采用多個 3×3 卷積,模仿出更大的感受野(receptive field)效果,例如 5×5 與 7×7。
? 這些思想也被用在更多的網絡架構中,如 Inception 與 ResNet。
VGG16的效果最好

- VGG16 的第 3、4、5 塊(block):256、512、512個 3×3 濾波器依次用來提取復雜的特征。
- 其效果就等于是一個帶有 3 個卷積層的大型的 512×512 大分類器。
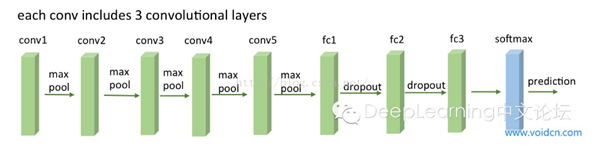
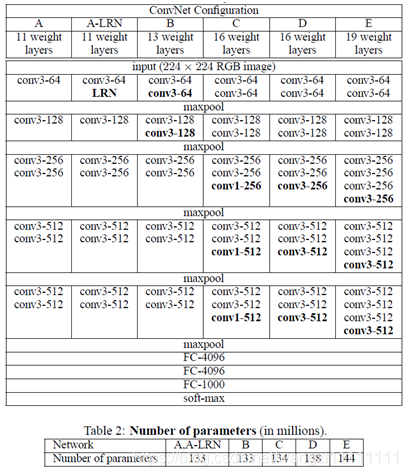
2.VGG結構解釋
(1)VGG全部使用33卷積核、22池化核,不斷加深網絡結構來提升性能。
(2)A到E網絡變深,參數量沒有增長很多,參數量主要在3個全連接層。
(3)訓練比較耗時的依然是卷積層,因計算量比較大。
(4)VGG有5段卷積,每段有2~3個卷積層,每段尾部用池化來縮小圖片尺寸。
(5)每段內卷積核數一樣,越靠后的段卷積核數越多:64–128–256–512–512。
3.3*3卷積核的優點

4.VGG的muti-scale方法

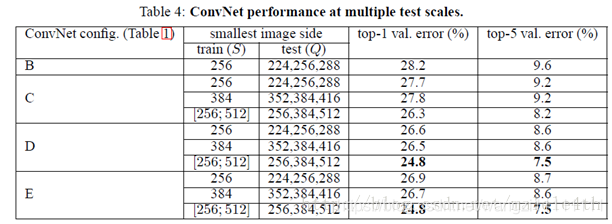
- LRN層作用不大。
- 越深的網絡效果越好。
- 11的卷積也是很有效的,但是沒有33的卷積好
- 大的卷積核可以學習更大的空間特征
1*1的卷積的作用
1.實現跨通道的交互和信息整合
- 1×1的卷積層(可能)引起人們的重視是在NIN的結構中,論文中林敏師兄的想法是利用MLP代替傳統的線性卷積核,從而提高網絡的表達能力。文中同時利用了跨通道pooling的角度解釋,認為文中提出的MLP其實等價于在傳統卷積核后面接cccp層,從而實現多個feature map的線性組合,實現跨通道的信息整合。
2.進行卷積核通道數的降維
- 降維( dimension reductionality )。比如,一張500 X500且厚度depth為100 的圖片在20個filter上做1X1的卷積,那么結果的大小為500X500X20。
- 加入非線性。卷積層之后經過激勵層,1X1的卷積在前一層的學習表示上添加了非線性激勵( non-linear activation ),提升網絡的表達能力;
5.VGG的應用
VGG9、VGG11、VGG13、VGG16、VGG19
出現了梯度消失的問題
只在第一個卷積(name=’block1_conv1’)后面加了BatchNormalization就解決了
def VGG16(input_shape=(64,64,3), classes=6):X_input = Input(input_shape)"block 1"X = Conv2D(filters=4, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block1_conv1')(X_input)X = BatchNormalization(axis=3)(X)X = Conv2D(filters=4, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block1_conv2')(X)X = MaxPooling2D((2,2), strides=(2,2), name='block1_pool')(X)"block 2"X = Conv2D(filters=8, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block2_conv1')(X)X = BatchNormalization(axis=3)(X)X = Conv2D(filters=8, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block2_conv2')(X)X = MaxPooling2D((2,2), strides=(2,2), name='block2_pool')(X)"block 3"X = Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block3_conv1')(X)X = Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block3_conv2')(X)X = Conv2D(filters=16, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block3_conv3')(X)X = MaxPooling2D((2,2), strides=(2,2), name='block3_pool')(X)"block 4"X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block4_conv1')(X)X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block4_conv2')(X)X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block4_conv3')(X)X = MaxPooling2D((2,2), strides=(2,2), name='block4_pool')(X)"block 5"X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block5_conv1')(X)X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block5_conv2')(X)X = Conv2D(filters=32, kernel_size=(3,3), strides=(1,1), activation='relu', padding='same', name='block5_conv3')(X)X = MaxPooling2D((2,2), strides=(2,2), name='block5_pool')(X)"flatten, fc1, fc2, fc3"X = Flatten(name='flatten')(X)X = Dense(256, activation='relu', name='fc1')(X)X = Dense(256, activation='relu', name='fc2')(X)X = Dense(classes, activation='softmax', name='fc3')(X)model = Model(inputs=X_input, outputs=X, name='VGG16')return model
-內置/自己設計的損失函數使用)

-- Network in Network(NIN))
-tensor常用操作)
)
-- 經典CNN網絡結構(Inception (v1-v4)))
-函數,lambda語句)
-- Residual Network (ResNet))
-模塊)

-- DenseNet)

-window7配置iPython)
-- Capsules Networks(CapsNet))

-列表list,for循環)
-- GAN)
--try-expect)
