本文主要介紹一下CNN的幾種經典模型比較。之前自己也用過AlexNet和GoogleNet,網絡上關于各種模型的介紹更是形形色色,自己就想著整理一下,以備自己以后查閱方便
LeNet5

先放一張圖,我感覺凡是對深度學習有涉獵的人,對這張圖一定不會陌生,這就是最早的LeNet5的平面結構圖。
Lenet5誕生于1994年,是最早的卷積神經網絡之一,并且推動了深度學習的發展。Caffe中LeNet的配置文件,從中我們可以看出Lenet5由兩個卷積層,兩個池化層,以及兩個全連接層組成。卷積都是5*5的filter,步長為1,。池化都是max-pooling
Lenet5特征能夠總結為如下幾點:
(1)卷積神經網絡使用三個層作為一個系列:卷積、池化、非線性
(2)使用卷積提取空間特征
(3)使用映射到空間均值下采樣
(4)雙曲線(tanh)或s型(sigmoid)形式的非線性
(5)多層神經網絡(MLP)作為最后的分類器
(6)層與層之間的稀疏鏈接矩陣避免大的計算成本
AlexNet
2012年,ImageNet比賽冠軍的model–Alexnet,可以說是LeNet的一種更深更寬的版本。AlexNet包含了6億3000萬個連接,6000萬個參數和65萬個神經元,擁有5個卷積層,其中3個卷積層后面連接了最大池化層,最后還有3個全連接層。AlextNet以顯著的優勢贏得了ILSVRC比賽的冠軍,top-5的錯誤率從之前的25.8%降低至16.4。 AlexNet的Caffe的model文件
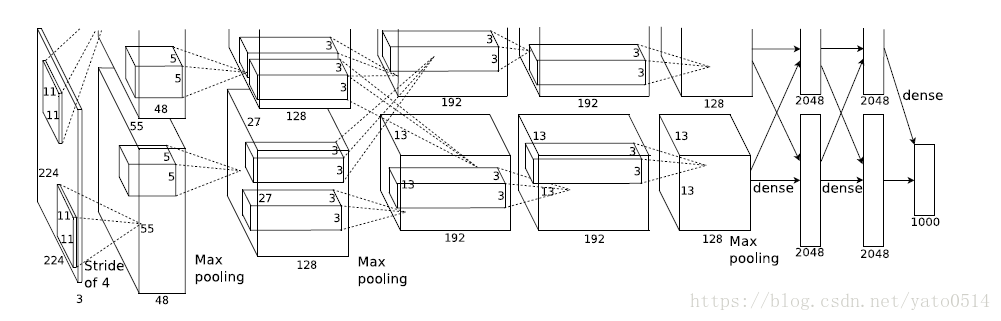
上圖之所以分為兩層,是因為AlexNet訓練時用了兩塊GPU。
ALexNet的主要技術點在于:
(1)使用RELU作為CNN的激活函數,解決了sigmoid在網絡較深時的梯度彌散問題。
(2)訓練時使用了Dropout隨機忽略一部分神經元,以避免模型過擬合。
(3)在CNN中使用重疊的最大池化,步長小于池化核,這樣輸出之間會有重疊和覆蓋,提升了特征的豐富性。此前CNN普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊性效果。
(4)提出了LRN層,對局部神經元的活動創建競爭機制,使得其中響應比較大的值變得相對更大,并抑制其他反饋比較小的神經元,增強了模型的泛化能力。
(5)使用CUDA加速深度卷積網絡的訓練,利用GPU強大的并行計算能力,處理神經網絡訓練時大量的矩陣計算。AlexNet使用了兩塊GTX?580?GPU進行訓練,單個GTX?580只有3GB顯存,這限制了可訓練的網絡的最大規模。因此作者將AlexNet分布在兩個GPU上,在每個GPU的顯存中儲存一半的神經元的參數。因為GPU之間通信方便,可以互相訪問顯存,而不需要通過主機內存,所以同時使用多塊GPU也是非常高效的。同時,AlexNet的設計讓GPU之間的通信只在網絡的某些層進行,控制了通信的性能損耗。?
(6)使用數據增強,減輕過擬合,提高泛化能力
具體打開AlextNet的每一階段來看:

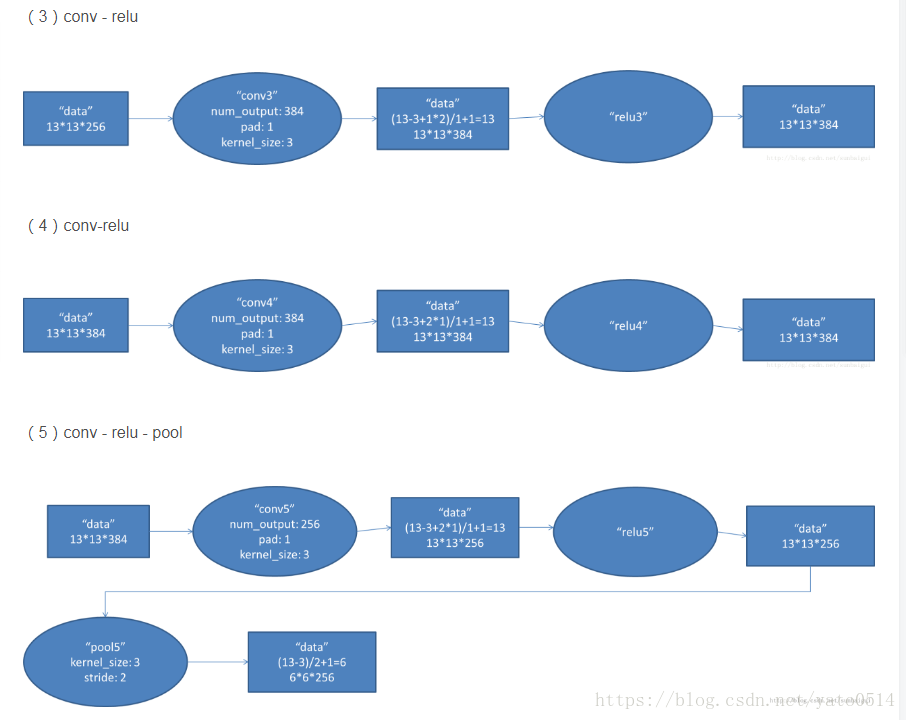
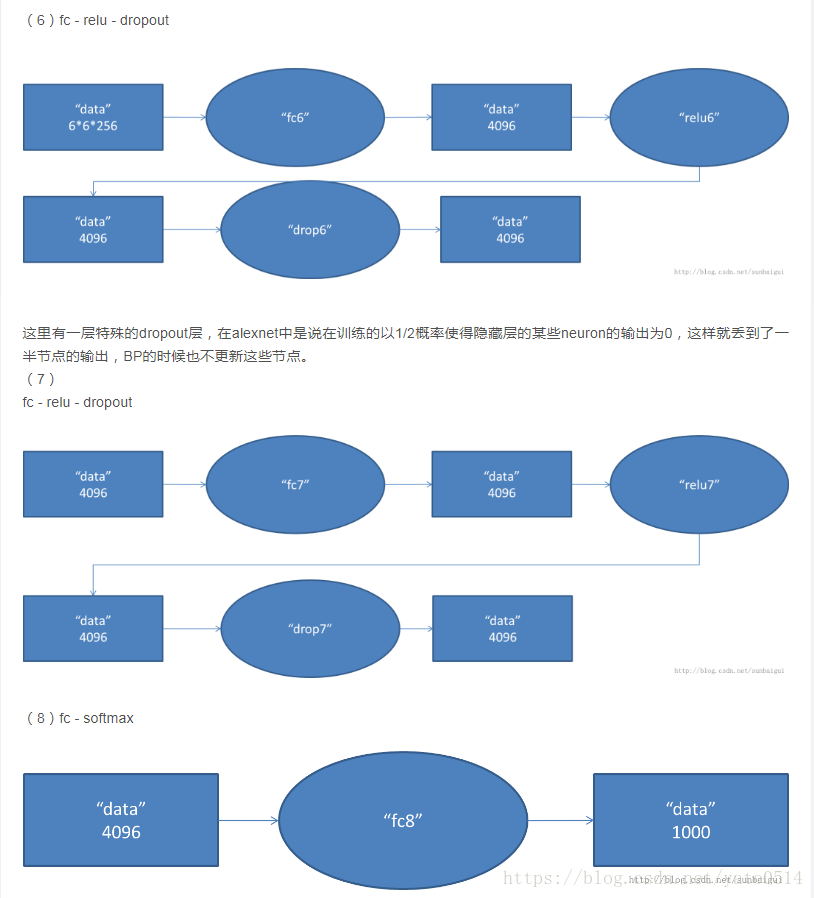
VGG
VGG是第一個在各個卷積層使用更小的3*3過濾器(filter),并把他們組合作為一個卷積序列進行 處理的網絡,它的特點就是連續conv多,計算量巨大。
VGG的巨大進展是通過依次采用多個3*3卷積,能夠模擬出更大的感受野(receptive field)的效果,兩個3*3卷積可以模擬出5*5的感受野,三個3*3的卷積可以模擬出7*7的感受野

VGG 網絡使用多個 3×3 卷積層去表征復雜特征。注意 VGG-E 的第 3、4、5 塊(block):256×256 和 512×512 個 3×3 過濾器被依次使用多次以提取更多復雜特征以及這些特征的組合。其效果就等于是一個帶有 3 個卷積層的大型的 512×512 大分類器。這顯然意味著有大量的參數與學習能力。但是這些網絡訓練很困難,必須劃分到較小的網絡,并逐層累加。這是因為缺少強大的方式對模型進行正則化,或者或多或少約束大量由于大量參數增長的搜索空間。
VGG-16和VGG-19的表現效果差不多,所以工業上還是用VGG-16的比較多
VGG用反復堆疊3*3的小型卷積核和2*2的最大池化層,通過不斷加深網絡結構來提升性能,VGGNet成功地構筑了16-19層的深度卷積網絡。
VGG拓展性很強,遷移到其他圖片數據上的泛化性非常好。
整個網絡都是用同樣大小的卷積核尺寸(3*3)和最大池化尺寸(2*2),可以用來提取特征。
用VGG的模型在domain specific的圖像分類任務上進行再訓練相當于提供了非常好的初始化權重
表一所示為VGGNet各級別的網絡結構圖,表2所示為每一級別的參數量,從11層的網絡一直到19層的網絡都有詳盡的性能測試。雖然從A到E每一級網絡逐漸變深,但是網絡的參數量并沒有增長很多,這是因為參數量主要都消耗在最后3個全連接層。前面的卷積部分雖然很深,但是消耗的參數量不大,不過訓練比較耗時的部分依然是卷積,因其計算量比較大。這其中的D、E也就是我們常說的VGGNet-16和VGGNet-19。C很有意思,相比B多了幾個1′1的卷積層,1′1卷積的意義主要在于線性變換,而輸入通道數和輸出通道數不變,沒有發生降維。
VGGNet擁有5段卷積,每一段內有2~3個卷積層,同時每段尾部會連接一個最大池化層用來縮小圖片尺寸。每段內的卷積核數量一樣,越靠后的段的卷積核數量越多:64?–?128?–?256?–?512?–?512。
VGGNet在訓練時有一個小技巧,先訓練級別A的簡單網絡,再復用A網絡的權重來初始化后面的幾個復雜模型,這樣訓練收斂的速度更快。在預測時,VGG采用Multi-Scale的方法,將圖像scale到一個尺寸Q,并將圖片輸入卷積網絡計算。然后在最后一個卷積層使用滑窗的方式進行分類預測,將不同窗口的分類結果平均,再將不同尺寸Q的結果平均得到最后結果,這樣可提高圖片數據的利用率并提升預測準確率。同時在訓練中,VGGNet還使用了Multi-Scale的方法做數據增強,將原始圖像縮放到不同尺寸S,然后再隨機裁切224′224的圖片,這樣能增加很多數據量,對于防止模型過擬合有很不錯的效果。
實踐中,作者令S在[256,512]這個區間內取值,使用Multi-Scale獲得多個版本的數據,并將多個版本的數據合在一起進行訓練。最終提交到ILSVRC?2014的版本是僅使用Single-Scale的6個不同等級的網絡與Multi-Scale的D網絡的融合,達到了7.3%的錯誤率。不過比賽結束后作者發現只融合Multi-Scale的D和E可以達到更好的效果,錯誤率達到7.0%,再使用其他優化策略最終錯誤率可達到6.8%左右,非常接近同年的冠軍Google?Inceptin?Net。同時,作者在對比各級網絡時總結出了以下幾個觀點。
(1)LRN層作用不大。
(2)越深的網絡效果越好。
(3)1′1的卷積也是很有效的,但是沒有3′3的卷積好,大一些的卷積核可以學習更大的空間特征。
接下來主要解析下VGG-16:

VGG模型主要關注的是網絡的深度,因此它固定了網絡的其他參數,通過增加卷積層來增加網絡的深度
網絡架構:
訓練輸入:固定尺寸224*224的RGB圖像。
預處理:每個像素值減去訓練集上的RGB均值。
卷積核:一系列3*3卷積核堆疊,步長為1,采用padding保持卷積后圖像空 間分辨率不變。
空間池化:緊隨卷積“堆”的最大池化,為2*2滑動窗口,步長為2。
全連接層:特征提取完成后,接三個全連接層,前兩個為4096通道,第三個為1000通道,最后是一個soft-max層,輸出概率。
所有隱藏層都用非線性修正ReLu.
使用3*3卷積的優點:
三個卷積堆疊具有三個非線性修正層,使模型更具判別性;
其次三個 3*3卷積參數量更少,相當于在7*7卷積核上加入了正則化,便于加快訓練.
下圖來看,在計算量這里,為了突出小卷積核的優勢,拿同conv3x3、conv5x5、conv7x7、conv9x9和conv11x11,在224x224x3的RGB圖上(設置pad=1,stride=4,output_channel=96)做卷積,卷積層的參數規模和得到的feature map的大小如下:

分類框架:
a):訓練
訓練方法基本與AlexNet一致,除了多尺度訓練圖像采樣方法不一致。 訓練采用mini-batch梯度下降法,batch size=256;
采用動量優化算法,momentum=0.9;
采用L2正則化方法,懲罰系數0.00005;
dropout比率設為0.5;
初始學習率為0.001,當驗證集準確率不再提高時,學習率衰減為原來的0.1 倍,總共下降三次;
總迭代次數為370K(74epochs);
數據增強采用隨機裁剪,水平翻轉,RGB顏色變化;
設置訓練圖片大小的兩種方法:
定義S代表經過各向同性縮放的訓練圖像的最小邊。
第一種方法針對單尺寸圖像訓練,S=256或384,輸入圖片從中隨機裁剪 224*224大小的圖片,原則上S可以取任意不小于224的值。
第二種方法是多尺度訓練,每張圖像單獨從[Smin ,Smax ]中隨機選取S來進行尺 寸縮放,由于圖像中目標物體尺寸不定,因此訓練中采用這種方法是有效的,可看作一種尺寸抖動的訓練集數據增強。
論文中提到,網絡權重的初始化非常重要,由于深度網絡梯度的不穩定性, 不合適的初始化會阻礙網絡的學習。因此我們先訓練淺層網絡,再用訓練好的淺層網絡去初始化深層網絡。
b):測試
測試階段,對于已訓練好的卷積網絡和一張輸入圖像,采用以下方法分類:
首先,圖像的最小邊被各向同性的縮放到預定尺寸Q;
然后,將原先的全連接層改換成卷積層,在未裁剪的全圖像上運用卷積網絡, 輸出是一個與輸入圖像尺寸相關的分類得分圖,輸出通道數與類別數相同;
最后,對分類得分圖進行空間平均化,得到固定尺寸的分類得分向量。
我們同樣對測試集做數據增強,采用水平翻轉,最終取原始圖像和翻轉圖像 的soft-max分類概率的平均值作為最終得分。 由于測試階段采用全卷積網絡,無需對輸入圖像進行裁剪,相對于多重裁剪效率會更高。但多重裁剪評估和運用全卷積的密集評估是互補的,有助于性能提升。
VGG的模型表明深度有利于分類準確率的提升,并且一個比較重要的思想是卷積可代替全連接。整體參數達1億4千萬,主要在于第一個全連接層,用卷積代替后,參數量下降且無精度損失
GoogleNet與Inception
來自谷歌的 Christian Szegedy 開始追求減少深度神經網絡的計算開銷,并設計出 GoogLeNet——第一個 Inception 架構(參見:Going Deeper with Convolutions)。
那是在 2014 年秋季,深度學習模型正在變得在圖像與視頻幀的分類中非常有用。大多數懷疑者已經不再懷疑深度學習與神經網絡這一次是真的回來了,而且將一直發展下去。鑒于這些技術的用處,谷歌這樣的互聯網巨頭非常有興趣在他們的服務器上高效且大規模龐大地部署這些架構。
Christian 考慮了很多關于在深度神經網絡達到最高水平的性能(例如在 ImageNet 上)的同時減少其計算開銷的方式。或者在能夠保證同樣的計算開銷的前提下對性能有所改進。
他和他的團隊提出了 Inception 模塊:

初看之下這不過基本上是 1×1、3×3、5×5 卷積過濾器的并行組合。但是 Inception 的偉大思路是用 1×1 的卷積塊(NiN)在昂貴的并行模塊之前減少特征的數量。這一般被稱為「瓶頸(bottleneck)」。
GoogLeNet 使用沒有 inception 模塊的主干作為初始層,之后是與 NiN 相似的一個平均池化層加 softmax 分類器。這個分類器比 AlexNet 與 VGG 的分類器的運算數量少得多。這也促成一項非常有效的網絡設計,參見論文:An Analysis of Deep Neural Network Models for Practical Applications。
Google?Inception?Net首次出現在ILSVRC?2014的比賽中(和VGGNet同年),就以較大優勢取得了第一名。那屆比賽中的Inception?Net通常被稱為Inception?V1,它最大的特點是控制了計算量和參數量的同時,獲得了非常好的分類性能——top-5錯誤率6.67%,只有AlexNet的一半不到。Inception?V1有22層深,比AlexNet的8層或者VGGNet的19層還要更深。但其計算量只有15億次浮點運算,同時只有500萬的參數量,僅為AlexNet參數量(6000萬)的1/12,卻可以達到遠勝于AlexNet的準確率,可以說是非常優秀并且非常實用的模型。
Inception?V1降低參數量的目的有兩點,第一,參數越多模型越龐大,需要供模型學習的數據量就越大,而目前高質量的數據非常昂貴;第二,參數越多,耗費的計算資源也會更大。Inception?V1參數少但效果好的原因除了模型層數更深、表達能力更強外,還有兩點:一是去除了最后的全連接層,用全局平均池化層(即將圖片尺寸變為1′1)來取代它。全連接層幾乎占據了AlexNet或VGGNet中90%的參數量,而且會引起過擬合,去除全連接層后模型訓練更快并且減輕了過擬合。用全局平均池化層取代全連接層的做法借鑒了Network?In?Network(以下簡稱NIN)論文。二是Inception?V1中精心設計的Inception?Module提高了參數的利用效率,這一部分也借鑒了NIN的思想,形象的解釋就是Inception?Module本身如同大網絡中的一個小網絡,其結構可以反復堆疊在一起形成大網絡。不過Inception?V1比NIN更進一步的是增加了分支網絡,NIN則主要是級聯的卷積層和MLPConv層。一般來說卷積層要提升表達能力,主要依靠增加輸出通道數,但副作用是計算量增大和過擬合。每一個輸出通道對應一個濾波器,同一個濾波器共享參數,只能提取一類特征,因此一個輸出通道只能做一種特征處理。而NIN中的MLPConv則擁有更強大的能力,允許在輸出通道之間組合信息,因此效果明顯。可以說,MLPConv基本等效于普通卷積層后再連接1′1的卷積和ReLU激活函數。
Inception V1
受到 NiN 的啟發,Inception 的瓶頸層(Bottleneck Layer)減少了每一層的特征的數量,并由此減少了運算的數量;所以可以保持較低的推理時間。在將數據通入昂貴的卷積模塊之前,特征的數量會減少 4 倍。在計算成本上這是很大的節約,也是該架構的成功之處。
Naive Inception:

Inception module 的提出主要考慮多個不同 size 的卷積核能夠增強網絡的適應力,paper 中分別使用1*1、3*3、5*5卷積核,同時加入3*3 max pooling。
隨后文章指出這種 naive 結構存在著問題:
每一層 Inception module 的 filters 參數量為所有分支上的總數和,多層 Inception 最終將導致 model 的參數數量龐大,對計算資源有更大的依賴。
在 NIN 模型中與1*1卷積層等效的 MLPConv 既能跨通道組織信息,提高網絡的表達能力,同時可以對輸出有效進行降維,因此文章提出了Inception module with dimension reduction,在不損失模型特征表示能力的前提下,盡量減少 filters 的數量,達到降低模型復雜度的目的:
如下圖所示,Inception Module:

Inception Module 的4個分支在最后通過一個聚合操作合并(在輸出通道數這個維度上聚合)。
完整的 GoogLeNet 結構在傳統的卷積層和池化層后面引入了 Inception 結構,對比 AlexNet 雖然網絡層數增加,但是參數數量減少的原因是絕大部分的參數集中在全連接層,最終取得了 ImageNet 上 6.67% 的成績。

Inception V2網絡
2015 年 2 月,Batch-normalized Inception 被引入作為 Inception V2(參見論文:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift)。
Inception V2 學習了 VGG 用兩個3′3的卷積代替5′5的大卷積,在降低參數的同時建立了更多的非線性變換,使得 CNN 對特征的學習能力更強:

另外提出了著名的 Batch Normalization(以下簡稱BN)方法。BN 是一個非常有效的正則化方法,可以讓大型卷積網絡的訓練速度加快很多倍,同時收斂后的分類準確率也可以得到大幅提高。BN 在用于神經網絡某層時,會對每一個 mini-batch 數據的內部進行標準化(normalization)處理,使輸出規范化到 N(0,1) 的正態分布,減少了 Internal Covariate Shift(內部神經元分布的改變)。
BN 的論文指出,傳統的深度神經網絡在訓練時,每一層的輸入的分布都在變化,導致訓練變得困難,我們只能使用一個很小的學習速率解決這個問題。而對每一層使用 BN 之后,我們就可以有效地解決這個問題,學習速率可以增大很多倍,達到之前的準確率所需要的迭代次數只有1/14,訓練時間大大縮短。而達到之前的準確率后,可以繼續訓練,并最終取得遠超于 Inception V1 模型的性能—— top-5 錯誤率 4.8%,已經優于人眼水平。因為 BN 某種意義上還起到了正則化的作用,所以可以減少或者取消 Dropout 和 LRN,簡化網絡結構。
Inception V3


一是引入了 Factorization into small convolutions 的思想,將一個較大的二維卷積拆成兩個較小的一維卷積,比如將7′7卷積拆成1′7卷積和7′1卷積,或者將3′3卷積拆成1′3卷積和3′1卷積,如上圖所示。一方面節約了大量參數,加速運算并減輕了過擬合(比將7′7卷積拆成1′7卷積和7′1卷積,比拆成3個3′3卷積更節約參數),同時增加了一層非線性擴展模型表達能力。論文中指出,這種非對稱的卷積結構拆分,其結果比對稱地拆為幾個相同的小卷積核效果更明顯,可以處理更多、更豐富的空間特征,增加特征多樣性。
另一方面,Inception V3 優化了 Inception Module 的結構,現在 Inception Module 有35′35、17′17和8′8三種不同結構。這些 Inception Module 只在網絡的后部出現,前部還是普通的卷積層。并且 Inception V3 除了在 Inception Module 中使用分支,還在分支中使用了分支(8′8的結構中),可以說是Network In Network In Network。最終取得 top-5 錯誤率 3.5%。
Inception V4
Inception V4 相比 V3 主要是結合了微軟的 ResNet,將錯誤率進一步減少到 3.08%。



總結:
Inception V1——構建了1x1、3x3、5x5的 conv 和3x3的 pooling 的分支網絡,同時使用 MLPConv 和全局平均池化,擴寬卷積層網絡寬度,增加了網絡對尺度的適應性;
Inception V2——提出了 Batch Normalization,代替 Dropout 和 LRN,其正則化的效果讓大型卷積網絡的訓練速度加快很多倍,同時收斂后的分類準確率也可以得到大幅提高,同時學習 VGG 使用兩個3′3的卷積核代替5′5的卷積核,在降低參數量同時提高網絡學習能力;
Inception V3——引入了 Factorization,將一個較大的二維卷積拆成兩個較小的一維卷積,比如將3′3卷積拆成1′3卷積和3′1卷積,一方面節約了大量參數,加速運算并減輕了過擬合,同時增加了一層非線性擴展模型表達能力,除了在 Inception Module 中使用分支,還在分支中使用了分支(Network In Network In Network);
Inception V4——研究了 Inception Module 結合 Residual Connection,結合 ResNet 可以極大地加速訓練,同時極大提升性能,在構建 Inception-ResNet 網絡同時,還設計了一個更深更優化的 Inception v4 模型,能達到相媲美的性能。
文章主要參考:
https://blog.csdn.net/xbinworld/article/details/45619685
https://blog.csdn.net/maxiao1204/article/details/65653781
https://zhuanlan.zhihu.com/p/37706726
http://lib.csdn.net/article/aimachinelearning/66253
)
-Generative Adversarial Net-代碼實現資料)
--典型CNN結構(VGG13,16,19))

-內置/自己設計的損失函數使用)

-- Network in Network(NIN))
-tensor常用操作)
)
-- 經典CNN網絡結構(Inception (v1-v4)))
-函數,lambda語句)
-- Residual Network (ResNet))
-模塊)

-- DenseNet)

-window7配置iPython)
-- Capsules Networks(CapsNet))

-列表list,for循環)