1 特征工程是什么?
2 數據預處理
2.1 無量綱化
2.1.1 標準化
2.1.2 區間縮放法
2.1.3 標準化與歸一化的區別
2.2 對定量特征二值化
2.3 對定性特征啞編碼
2.4 缺失值計算
2.5 數據變換
3 特征選擇
3.1 Filter
3.1.1 方差選擇法
3.1.2 相關系數法
3.1.3 卡方檢驗
3.1.4 互信息法
3.2 Wrapper
3.2.1 遞歸特征消除法
3.3 Embedded
3.3.1 基于懲罰項的特征選擇法
3.3.2 基于樹模型的特征選擇法
4 降維
4.1 主成分分析法(PCA)
4.2 線性判別分析法(LDA)
5 總結
6 參考資料
1 特征工程是什么?
有這么一句話在業界廣泛流傳:數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限而已。那特征工程到底是什么呢?顧名思義,其本質是一項工程活動,目的是最大限度地從原始數據中提取特征以供算法和模型使用。通過總結和歸納,人們認為特征工程包括以下方面:
<img src="https://pic3.zhimg.com/20e4522e6104ad71fc543cc21f402b36_b.png" data-rawwidth="875" data-rawheight="967" class="origin_image zh-lightbox-thumb" width="875" data-original="https://pic3.zhimg.com/20e4522e6104ad71fc543cc21f402b36_r.png">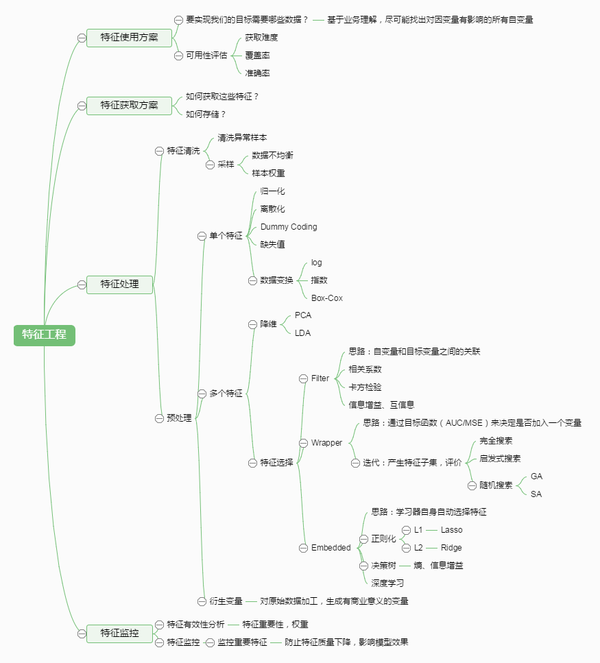
特征處理是特征工程的核心部分,sklearn提供了較為完整的特征處理方法,包括數據預處理,特征選擇,降維等。首次接觸到sklearn,通常會被其豐富且方便的算法模型庫吸引,但是這里介紹的特征處理庫也十分強大!
本文中使用sklearn中的IRIS(鳶尾花)數據集來對特征處理功能進行說明。IRIS數據集由Fisher在1936年整理,包含4個特征(Sepal.Length(花萼長度)、Sepal.Width(花萼寬度)、Petal.Length(花瓣長度)、Petal.Width(花瓣寬度)),特征值都為正浮點數,單位為厘米。目標值為鳶尾花的分類(Iris Setosa(山鳶尾)、Iris Versicolour(雜色鳶尾),Iris Virginica(維吉尼亞鳶尾))。導入IRIS數據集的代碼如下:
- from sklearn.datasets import load_iris
-
- #導入IRIS數據集
- iris = load_iris()
-
- #特征矩陣
- iris.data
-
- #目標向量
- iris.target
2 數據預處理
通過特征提取,我們能得到未經處理的特征,這時的特征可能有以下問題:
- 不屬于同一量綱:即特征的規格不一樣,不能夠放在一起比較。無量綱化可以解決這一問題。
- 信息冗余:對于某些定量特征,其包含的有效信息為區間劃分,例如學習成績,假若只關心“及格”或不“及格”,那么需要將定量的考分,轉換成“1”和“0”表示及格和未及格。二值化可以解決這一問題。
- 定性特征不能直接使用:某些機器學習算法和模型只能接受定量特征的輸入,那么需要將定性特征轉換為定量特征。最簡單的方式是為每一種定性值指定一個定量值,但是這種方式過于靈活,增加了調參的工作。通常使用啞編碼的方式將定性特征轉換為定量特征:假設有N種定性值,則將這一個特征擴展為N種特征,當原始特征值為第i種定性值時,第i個擴展特征賦值為1,其他擴展特征賦值為0。啞編碼的方式相比直接指定的方式,不用增加調參的工作,對于線性模型來說,使用啞編碼后的特征可達到非線性的效果。
- 存在缺失值:缺失值需要補充。
- 信息利用率低:不同的機器學習算法和模型對數據中信息的利用是不同的,之前提到在線性模型中,使用對定性特征啞編碼可以達到非線性的效果。類似地,對定量變量多項式化,或者進行其他的轉換,都能達到非線性的效果。
我們使用sklearn中的preproccessing庫來進行數據預處理,可以覆蓋以上問題的解決方案。
2.1 無量綱化無量綱化使不同規格的數據轉換到同一規格。常見的無量綱化方法有標準化和區間縮放法。標準化的前提是特征值服從正態分布,標準化后,其轉換成標準正態分布。區間縮放法利用了邊界值信息,將特征的取值區間縮放到某個特點的范圍,例如[0, 1]等。
2.1.1 標準化標準化需要計算特征的均值和標準差,公式表達為:
使用preproccessing庫的StandardScaler類對數據進行標準化的代碼如下:
<img src="https://pic2.zhimg.com/c7e852db6bd05b7bb1017b5425ffeec1_b.png" data-rawwidth="81" data-rawheight="48" class="content_image" width="81">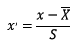
- from sklearn.preprocessing import StandardScaler
-
- #標準化,返回值為標準化后的數據
- StandardScaler().fit_transform(iris.data)
區間縮放法的思路有多種,常見的一種為利用兩個最值進行縮放,公式表達為:
使用preproccessing庫的MinMaxScaler類對數據進行區間縮放的代碼如下:
<img src="https://pic2.zhimg.com/0f119a8e8f69509c5b95ef6a8a01a809_b.png" data-rawwidth="119" data-rawheight="52" class="content_image" width="119">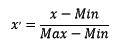
from sklearn.preprocessing import MinMaxScaler
#區間縮放,返回值為縮放到[0, 1]區間的數據
MinMaxScaler().fit_transform(iris.data)
簡單來說,標準化是依照特征矩陣的列處理數據,其通過求z-score的方法,將樣本的特征值轉換到同一量綱下。歸一化是依照特征矩陣的行處理數據,其目的在于樣本向量在點乘運算或其他核函數計算相似性時,擁有統一的標準,也就是說都轉化為“單位向量”。規則為l2的歸一化公式如下:
<img src="https://pic1.zhimg.com/fbb2fd0a163f2fa211829b735194baac_b.png" data-rawwidth="113" data-rawheight="57" class="content_image" width="113">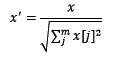
使用preproccessing庫的Normalizer類對數據進行歸一化的代碼如下:
- from sklearn.preprocessing import Normalizer
-
- #歸一化,返回值為歸一化后的數據
- Normalizer().fit_transform(iris.data)
定量特征二值化的核心在于設定一個閾值,大于閾值的賦值為1,小于等于閾值的賦值為0,公式表達如下:
<img src="https://pic2.zhimg.com/11111244c5b69c1af6c034496a2591ad_b.png" data-rawwidth="159" data-rawheight="41" class="content_image" width="159">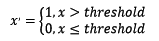
使用preproccessing庫的Binarizer類對數據進行二值化的代碼如下:
- from sklearn.preprocessing import Binarizer
-
- #二值化,閾值設置為3,返回值為二值化后的數據
- Binarizer(threshold=3).fit_transform(iris.data)
由于IRIS數據集的特征皆為定量特征,故使用其目標值進行啞編碼(實際上是不需要的)。使用preproccessing庫的OneHotEncoder類對數據進行啞編碼的代碼如下:
- from sklearn.preprocessing import OneHotEncoder
-
- #啞編碼,對IRIS數據集的目標值,返回值為啞編碼后的數據
- OneHotEncoder().fit_transform(iris.target.reshape((-1,1)))
由于IRIS數據集沒有缺失值,故對數據集新增一個樣本,4個特征均賦值為NaN,表示數據缺失。使用preproccessing庫的Imputer類對數據進行缺失值計算的代碼如下:
- from numpy import vstack, array, nan
- from sklearn.preprocessing import Imputer
-
- #缺失值計算,返回值為計算缺失值后的數據
- #參數missing_value為缺失值的表示形式,默認為NaN
- #參數strategy為缺失值填充方式,默認為mean(均值)
- Imputer().fit_transform(vstack((array([nan, nan, nan, nan]), iris.data)))
常見的數據變換有基于多項式的、基于指數函數的、基于對數函數的。4個特征,度為2的多項式轉換公式如下:
<img src="https://pic4.zhimg.com/d1c57a66fad39df90b87cea330efb3f3_b.png" data-rawwidth="571" data-rawheight="57" class="origin_image zh-lightbox-thumb" width="571" data-original="https://pic4.zhimg.com/d1c57a66fad39df90b87cea330efb3f3_r.png">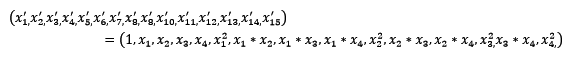
使用preproccessing庫的PolynomialFeatures類對數據進行多項式轉換的代碼如下:
- from sklearn.preprocessing import PolynomialFeatures
-
- #多項式轉換
- #參數degree為度,默認值為2
- PolynomialFeatures().fit_transform(iris.data)
基于單變元函數的數據變換可以使用一個統一的方式完成,使用preproccessing庫的FunctionTransformer對數據進行對數函數轉換的代碼如下:
- from numpy import log1p
- from sklearn.preprocessing import FunctionTransformer
-
- #自定義轉換函數為對數函數的數據變換
- #第一個參數是單變元函數
- FunctionTransformer(log1p).fit_transform(iris.data)
3 特征選擇
當數據預處理完成后,我們需要選擇有意義的特征輸入機器學習的算法和模型進行訓練。通常來說,從兩個方面考慮來選擇特征:
- 特征是否發散:如果一個特征不發散,例如方差接近于0,也就是說樣本在這個特征上基本上沒有差異,這個特征對于樣本的區分并沒有什么用。
- 特征與目標的相關性:這點比較顯見,與目標相關性高的特征,應當優選選擇。除方差法外,本文介紹的其他方法均從相關性考慮。
根據特征選擇的形式又可以將特征選擇方法分為3種:
- Filter:過濾法,按照發散性或者相關性對各個特征進行評分,設定閾值或者待選擇閾值的個數,選擇特征。
- Wrapper:包裝法,根據目標函數(通常是預測效果評分),每次選擇若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些機器學習的算法和模型進行訓練,得到各個特征的權值系數,根據系數從大到小選擇特征。類似于Filter方法,但是是通過訓練來確定特征的優劣。
我們使用sklearn中的feature_selection庫來進行特征選擇。
3.1 Filter3.1.1 方差選擇法
使用方差選擇法,先要計算各個特征的方差,然后根據閾值,選擇方差大于閾值的特征。使用feature_selection庫的VarianceThreshold類來選擇特征的代碼如下:
- from sklearn.feature_selection import VarianceThreshold
-
- #方差選擇法,返回值為特征選擇后的數據
- #參數threshold為方差的閾值
- VarianceThreshold(threshold=3).fit_transform(iris.data)
使用相關系數法,先要計算各個特征對目標值的相關系數以及相關系數的P值。用feature_selection庫的SelectKBest類結合相關系數來選擇特征的代碼如下:
- from sklearn.feature_selection import SelectKBest
- from scipy.stats import pearsonr
-
- #選擇K個最好的特征,返回選擇特征后的數據
- #第一個參數為計算評估特征是否好的函數,該函數輸入特征矩陣和目標向量,輸出二元組(評分,P值)的數組,數組第i項為第i個特征的評分和P值。在此定義為計算相關系數
- #參數k為選擇的特征個數
- SelectKBest(lambda X, Y: array(map(lambda x:pearsonr(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
經典的卡方檢驗是檢驗定性自變量對定性因變量的相關性。假設自變量有N種取值,因變量有M種取值,考慮自變量等于i且因變量等于j的樣本頻數的觀察值與期望的差距,構建統計量:
<img src="https://pic1.zhimg.com/7bc586c806b9b8bf1e74433a2e1976bc_b.png" data-rawwidth="162" data-rawheight="48" class="content_image" width="162">
不難發現,這個統計量的含義簡而言之就是自變量對因變量的相關性。用feature_selection庫的SelectKBest類結合卡方檢驗來選擇特征的代碼如下:
- from sklearn.feature_selection import SelectKBest
- from sklearn.feature_selection import chi2
-
- #選擇K個最好的特征,返回選擇特征后的數據
- SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
經典的互信息也是評價定性自變量對定性因變量的相關性的,互信息計算公式如下:
<img src="https://pic3.zhimg.com/6af9a077b49f587a5d149f5dc51073ba_b.png" data-rawwidth="274" data-rawheight="50" class="content_image" width="274">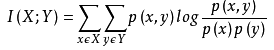
為了處理定量數據,最大信息系數法被提出,使用feature_selection庫的SelectKBest類結合最大信息系數法來選擇特征的代碼如下:
- from sklearn.feature_selection import SelectKBest
- from minepy import MINE
-
- #由于MINE的設計不是函數式的,定義mic方法將其為函數式的,返回一個二元組,二元組的第2項設置成固定的P值0.5
- def mic(x, y):
- m = MINE()
- m.compute_score(x, y)
- return (m.mic(), 0.5)
-
- #選擇K個最好的特征,返回特征選擇后的數據
- SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
3.2.1 遞歸特征消除法
遞歸消除特征法使用一個基模型來進行多輪訓練,每輪訓練后,消除若干權值系數的特征,再基于新的特征集進行下一輪訓練。使用feature_selection庫的RFE類來選擇特征的代碼如下:
- from sklearn.feature_selection import RFE
- from sklearn.linear_model import LogisticRegression
-
- #遞歸特征消除法,返回特征選擇后的數據
- #參數estimator為基模型
- #參數n_features_to_select為選擇的特征個數
- RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target)
3.3.1 基于懲罰項的特征選擇法
使用帶懲罰項的基模型,除了篩選出特征外,同時也進行了降維。使用feature_selection庫的SelectFromModel類結合帶L1懲罰項的邏輯回歸模型,來選擇特征的代碼如下:
- from sklearn.feature_selection import SelectFromModel
- from sklearn.linear_model import LogisticRegression
-
- #帶L1懲罰項的邏輯回歸作為基模型的特征選擇
- SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target)
實際上,L1懲罰項降維的原理在于保留多個對目標值具有同等相關性的特征中的一個,所以沒選到的特征不代表不重要。故,可結合L2懲罰項來優化。具體操作為:若一個特征在L1中的權值為1,選擇在L2中權值差別不大且在L1中權值為0的特征構成同類集合,將這一集合中的特征平分L1中的權值,故需要構建一個新的邏輯回歸模型:
- from sklearn.linear_model import LogisticRegression
-
- class LR(LogisticRegression):
- def __init__(self, threshold=0.01, dual=False, tol=1e-4, C=1.0,
- fit_intercept=True, intercept_scaling=1, class_weight=None,
- random_state=None, solver='liblinear', max_iter=100,
- multi_class='ovr', verbose=0, warm_start=False, n_jobs=1):
-
- #權值相近的閾值
- self.threshold = threshold
- LogisticRegression.__init__(self, penalty='l1', dual=dual, tol=tol, C=C,
- fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight=class_weight,
- random_state=random_state, solver=solver, max_iter=max_iter,
- multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
- #使用同樣的參數創建L2邏輯回歸
- self.l2 = LogisticRegression(penalty='l2', dual=dual, tol=tol, C=C, fit_intercept=fit_intercept, intercept_scaling=intercept_scaling, class_weight = class_weight, random_state=random_state, solver=solver, max_iter=max_iter, multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
-
- def fit(self, X, y, sample_weight=None):
- #訓練L1邏輯回歸
- super(LR, self).fit(X, y, sample_weight=sample_weight)
- self.coef_old_ = self.coef_.copy()
- #訓練L2邏輯回歸
- self.l2.fit(X, y, sample_weight=sample_weight)
-
- cntOfRow, cntOfCol = self.coef_.shape
- #權值系數矩陣的行數對應目標值的種類數目
- for i in range(cntOfRow):
- for j in range(cntOfCol):
- coef = self.coef_[i][j]
- #L1邏輯回歸的權值系數不為0
- if coef != 0:
- idx = [j]
- #對應在L2邏輯回歸中的權值系數
- coef1 = self.l2.coef_[i][j]
- for k in range(cntOfCol):
- coef2 = self.l2.coef_[i][k]
- #在L2邏輯回歸中,權值系數之差小于設定的閾值,且在L1中對應的權值為0
- if abs(coef1-coef2) < self.threshold and j != k and self.coef_[i][k] == 0:
- idx.append(k)
- #計算這一類特征的權值系數均值
- mean = coef / len(idx)
- self.coef_[i][idx] = mean
- return self
使用feature_selection庫的SelectFromModel類結合帶L1以及L2懲罰項的邏輯回歸模型,來選擇特征的代碼如下:
- from sklearn.feature_selection import SelectFromModel
-
- #帶L1和L2懲罰項的邏輯回歸作為基模型的特征選擇
- #參數threshold為權值系數之差的閾值
- SelectFromModel(LR(threshold=0.5, C=0.1)).fit_transform(iris.data, iris.target)
樹模型中GBDT也可用來作為基模型進行特征選擇,使用feature_selection庫的SelectFromModel類結合GBDT模型,來選擇特征的代碼如下:
- from sklearn.feature_selection import SelectFromModel
- from sklearn.ensemble import GradientBoostingClassifier
-
- #GBDT作為基模型的特征選擇
- SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
4 降維
當特征選擇完成后,可以直接訓練模型了,但是可能由于特征矩陣過大,導致計算量大,訓練時間長的問題,因此降低特征矩陣維度也是必不可少的。常見的降維方法除了以上提到的基于L1懲罰項的模型以外,另外還有主成分分析法(PCA)和線性判別分析(LDA),線性判別分析本身也是一個分類模型。PCA和LDA有很多的相似點,其本質是要將原始的樣本映射到維度更低的樣本空間中,但是PCA和LDA的映射目標不一樣:PCA是為了讓映射后的樣本具有最大的發散性;而LDA是為了讓映射后的樣本有最好的分類性能。所以說PCA是一種無監督的降維方法,而LDA是一種有監督的降維方法。
4.1 主成分分析法(PCA)使用decomposition庫的PCA類選擇特征的代碼如下:
- from sklearn.decomposition import PCA
-
- #主成分分析法,返回降維后的數據
- #參數n_components為主成分數目
- PCA(n_components=2).fit_transform(iris.data)
使用lda庫的LDA類選擇特征的代碼如下:
- from sklearn.lda import LDA
-
- #線性判別分析法,返回降維后的數據
- #參數n_components為降維后的維數
- LDA(n_components=2).fit_transform(iris.data, iris.target)
5 總結
再讓我們回歸一下本文開始的特征工程的思維導圖,我們可以使用sklearn完成幾乎所有特征處理的工作,而且不管是數據預處理,還是特征選擇,抑或降維,它們都是通過某個類的方法fit_transform完成的,fit_transform要不只帶一個參數:特征矩陣,要不帶兩個參數:特征矩陣加目標向量。這些難道都是巧合嗎?還是故意設計成這樣?方法fit_transform中有fit這一單詞,它和訓練模型的fit方法有關聯嗎?接下來,我將在《使用sklearn優雅地進行數據挖掘》中闡述其中的奧妙!



--Hadoop2.0介紹)

-圖像分類常用數據集)

函數分析)


--spark學習)

![Python的Pexpect詳解 [圖片]](http://pic.xiahunao.cn/Python的Pexpect詳解 [圖片])


-隨機變量函數變換)

-Numpy 簡易使用教程)
)
