文章目錄
- 目錄
- 1.Hadoop的發展與優化
- 1.1 Hadoop1.0 的不足與局限
- 1.2 Hadoop2.0 的改進與提升
- 2.HDFS2.0 的新特性
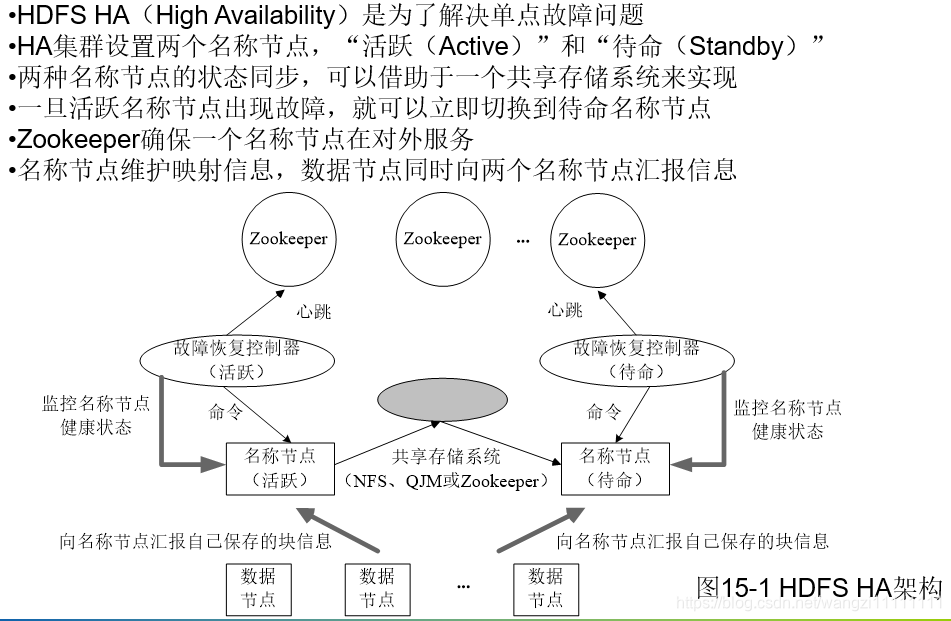
- 2.1 HDFS HA
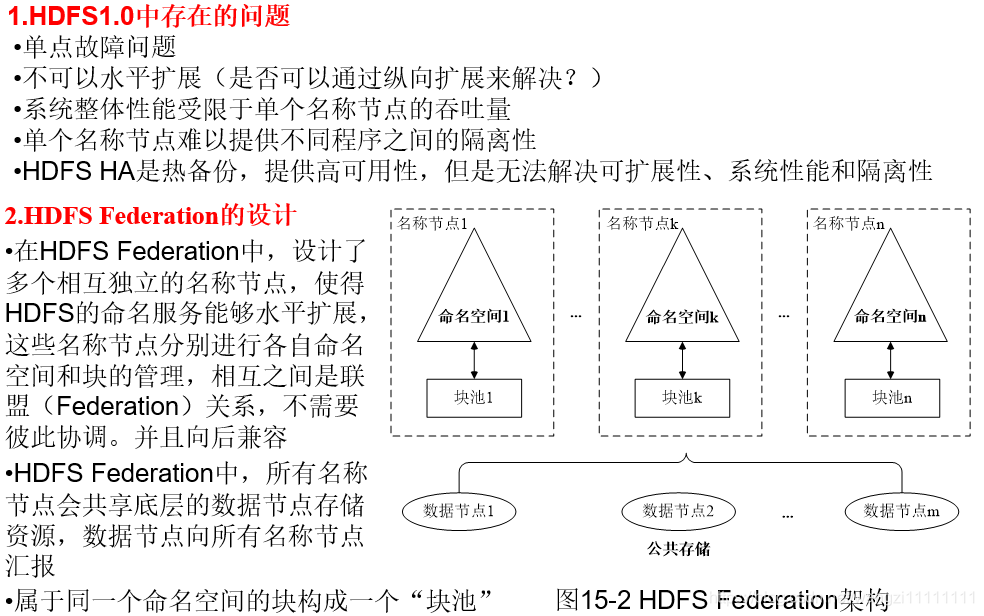
- 2.2 HDFS Federation
- 3. 新一代的資源管理器YARN
- 3.1 MapReduce1.0 缺陷
- 3.2 YARN的設計思路
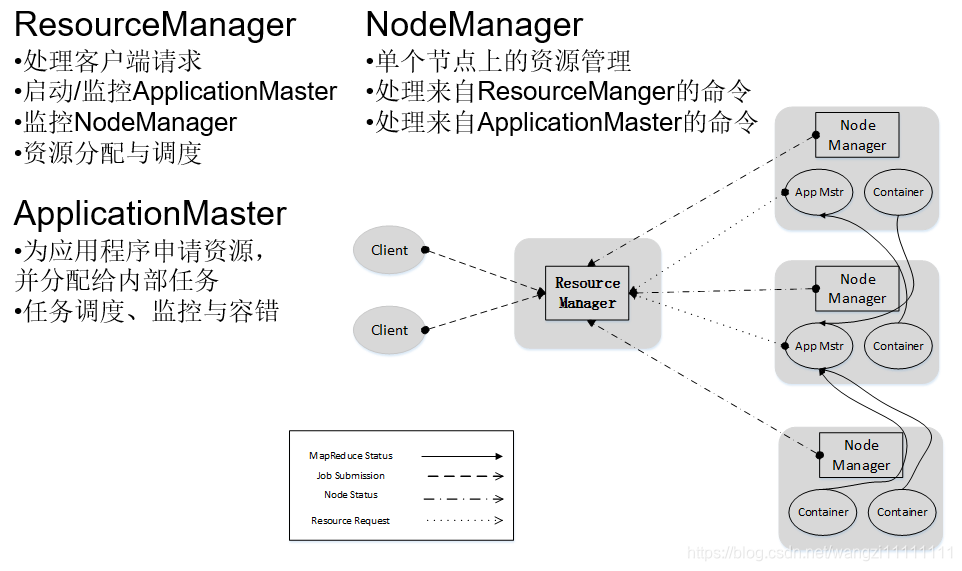
- 3.3 YARN 體系結構
- 3.4 YARN工作流程
- 3.5 YARN框架與MapReduce1.0框架進行對比
- 3.6 YARN的發展目標
- 4.Hadoop2.0 生態中具有代表性的功能組件
- 4.1 Pig
- 4.2 Tez
- 4.3 Spark
- 4.4 Kafka
目錄
1.Hadoop的發展與優化
1.1 Hadoop1.0 的不足與局限
主要針對于Hadoop1.0中兩大核心組件:MapReduce和HDFS有以下幾點不足:
- 抽象層次低,需要人工編碼(MapReduce需要人為的寫map和reduce函數)
- 表達能力有限(MapReduce)
- 開發者自己管理作業之間的依賴關系(MapReduce)
- 難以看清程序的整體邏輯(MapReduce)
- 執行迭代操作效率低(MapReduce每次迭代寫磁盤)
- 資源浪費(map-slot與reduce-slot不能共用)
- 實時性差(適用于批處理,不支持實時交互)
1.2 Hadoop2.0 的改進與提升


hdfs fedration只是提供管理多個命名空間,每個節點還是存在單點故障的問題,所以需要集合HDFS HA一起使用,即對HDFS Fedration中的每個節點創建一個附屬的名稱節點,作為單個節點的熱備份。
Hadoop1.0 中的第二名稱節點不是一個熱備份的功能,濕冷備份,具體請查看之前的博客。

2.HDFS2.0 的新特性
2.1 HDFS HA


HDFS HA
2.2 HDFS Federation


3. 新一代的資源管理器YARN
3.1 MapReduce1.0 缺陷

3.2 YARN的設計思路
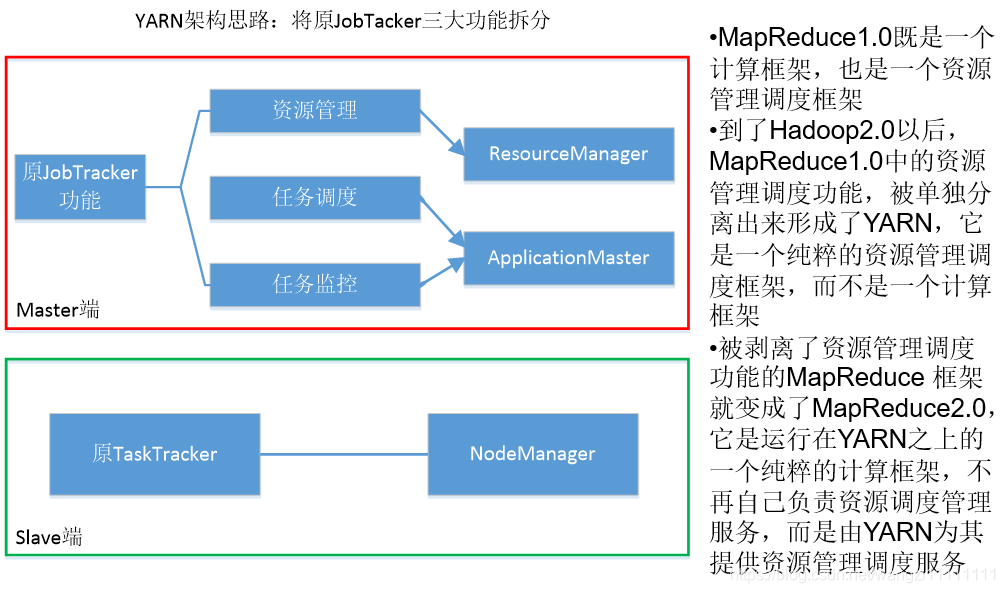
在Hadoop1.0 中,MapReduce既是一個大數據計算框架,又是一個資源和任務調度管理框架。
3.3 YARN 體系結構




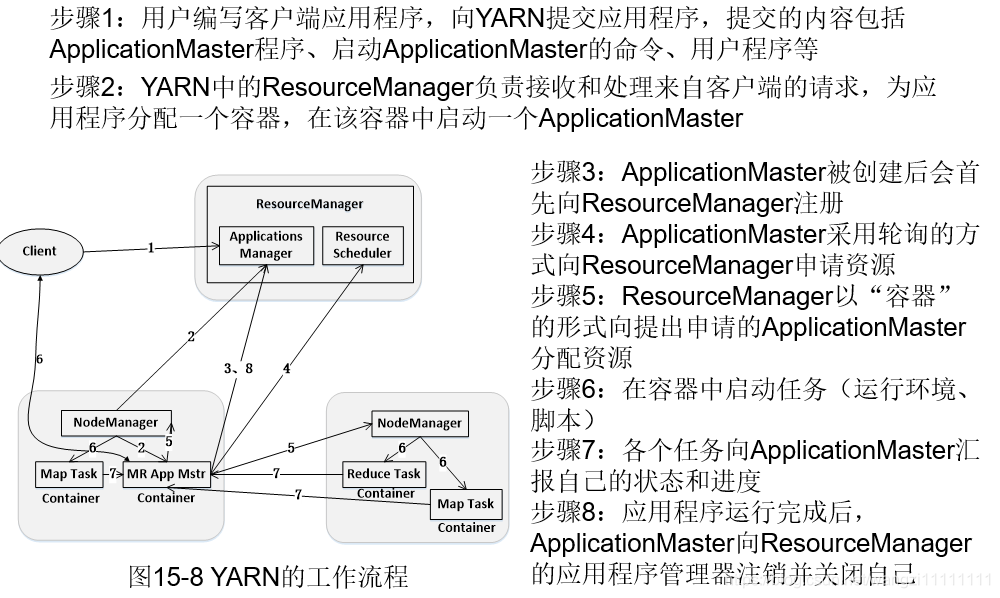
3.4 YARN工作流程
3.5 YARN框架與MapReduce1.0框架進行對比

3.6 YARN的發展目標


4.Hadoop2.0 生態中具有代表性的功能組件
4.1 Pig





4.2 Tez


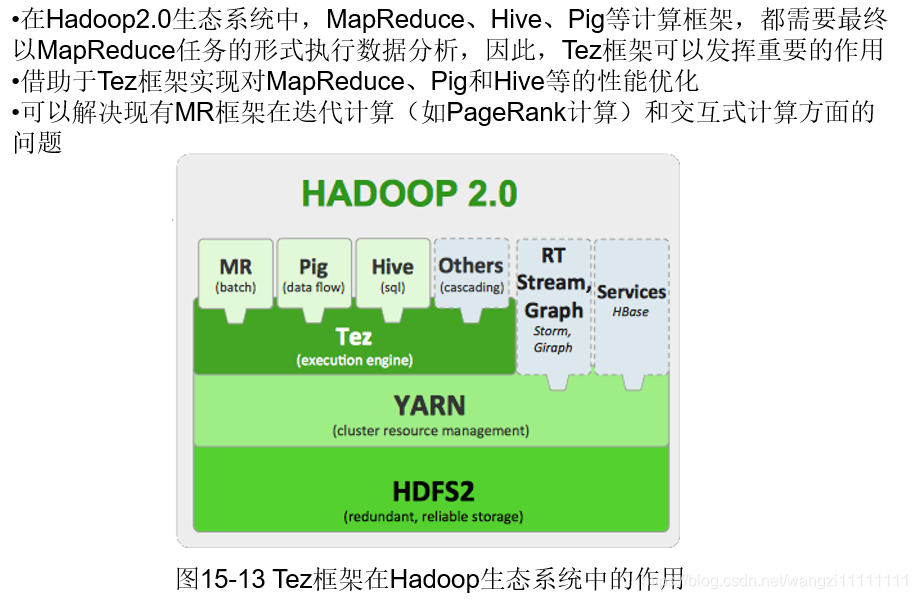
Tez是對MapReduce中的map和reduce過程進行優化,所以只要最終只要轉換為map和reduce操作的都可以使用Tez進行優化。

4.3 Spark

4.4 Kafka


-圖像分類常用數據集)

函數分析)


--spark學習)

![Python的Pexpect詳解 [圖片]](http://pic.xiahunao.cn/Python的Pexpect詳解 [圖片])


-隨機變量函數變換)

-Numpy 簡易使用教程)
)



--面向對象1-封裝)
)