小白和老手都應該看看的總結
輸入
java.util.Scanner 是 Java5 的新特征,我們可以通過 Scanner 類來獲取用戶的輸入。
下面是創建 Scanner 對象的基本語法:
Scanner s = new Scanner(System.in);使用方法如下:
//對應類型用對應的方法接收
String stringx=s.next();
String stringy=s.nextLine();int intx=s.nextInt();
long longx=s.nextLong();
short shortx=s.nextShort();float floatx=s.nextFloat();
double doublex=s.nextDouble();BigInteger bigInteger=s.nextBigInteger();
BigDecimal bigDecimal=s.nextBigDecimal();注意:
1、next和nextLine的區別:next讀取到空格停止,nextLine讀取到回車停止,讀取到空格不會停止。
2、nextInt不要和nextLine混用,如果nextLine在nextInt后面使用,會有吸收掉了本行的換行符而并沒有接收到下一行數據的問題
輸出
System是java.lang里面的一個類
out是System的靜態數據成員,而且這個成員是java.io.PrintStream類的引用
println()和print()就是java.io.PrintStream類里的方法.
被關鍵字static修飾的成員可以直接通過"類名.成員名"來引用,無需創建類的實例。所以System.out是調用了System類的靜態數據成員out。?
第一種:
System.out.println();?是最常用的輸出語句,它會把括號里的內容轉換成字符串輸出到控制臺,并且結尾換行。
1)輸出的是一個基本數據類型,會自動轉換成字符串,
2)輸出的是一個對象,會自動調用對象的toString()方法
第二種:
System.out.print();?和第一種一樣,只是結尾不換行。
第三種:
System.out.printf(); 這個方法延續了C語言的輸出方式,通過格式化文本和參數列表輸出比如:

?
八種基本類型


基本數據類型的變量是存儲在棧內存中,而引用類型變量存儲在棧內存中,保存的是實際對象在堆內存中的地址。
注意:有兩個大數類:BigInteger,BigDecimal分別是整數和小數
自動裝箱: java自動將原始類型轉化為引用類型的過程,編譯器調用valueOf方法將原始類型轉化為對象類型。
自動拆箱: java自動將引用類型轉化為原始類型的過程,編譯器調用intValue(),doubleValue()這類方法將對象轉換成原始類型值
例子:
Integer a = 3; //自動裝箱
int b = a; //自動拆箱條件分支
1)if語句中必須是一個布爾值,而不能是其他類型,這是java特殊的地方,比如判斷x是否為null不能寫if(!x)而要寫if(x==null)
2)switch 語句中的變量類型可以是: byte、short、int 、char。
從 Java SE 7 開始,switch 支持字符串 String 類型了
Switch語句和if else語句的區別
switch case會生成一個跳轉表來指示實際的case分支的地址,而if...else是需要遍歷條件分支直到命中條件
1)if-else語句更適合于對區間(范圍)的判斷,而switch語句更適合于對離散值的判斷
2)所有的switch都可以用if-else語句替換(if-else對每個離散值分別做判斷即可)
但是不是所有的if-else都可以用switch替換(因為區間里值的個數是無限的)
3)當分支較多時,用switch的效率是很高的。因為switch是確定了選擇值之后直接跳轉到那個特定的分支
switch...case占用較多的空間,因為它要生成跳表,特別是當case常量分布范圍很大但實際有效值又比較少,空間利用率很低。
?
循環流程
for( 初始化; 終止條件; 更新?) {
}
---------------------------------------------------------------
for(類型 變量名:數組或集合){
}//注意舉例:
for(int i:arr){
i=1;
}//arr數組內的值不會被改變
---------------------------------------------------------------
while(進入循環條件){
}
---------------------------------------------------------------
do{
}while(條件)
---------------------------------------------------------------
數組
靜態初始化
正確示例:
int ids[]或int[]?ids={ 1,2,3,4,5,6,7,8};
錯誤示例:
int num2[3] = {1,2,3};?// 編譯錯誤,不能在[ ]中指定數組長度
int[] num3;System.out.println(num3.length);?// 編譯錯誤,未初始化不能使用
動態初始化
正確示例:
int series[ ]= new int[4];
二維數組:
int arr[ ] [ ] = { {1,2},{3,4},{5,6}};
long[ ][ ] arr?= new long[5][5];
arrays類:
java.util.Arrays類能方便地操作數組,它提供的所有方法都是靜態的
常用方法:
–copyOf? ???????????實現數組的復制? ? ? ? ? ? ? ? ? ? ? ? ? ? ???copyOf(int[] a,int newlength);
–fill? ???????????????????實現數組元素的初始化? ? ? ? ? ? ? ? ? ???fill(int[] a,int val);
–sort? ?????????????????實現數組的排序? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ??sort(int[] a);
–binarySearch??? 實現排序后的數組元素查找? ? ? ? ? ???binarySearch(int[] a,int key);
面向對象的三大核心特性
封裝
保證了程序和數據不受外部干擾,不被誤用。封裝的目的在于保護信息,使用它的主要優點如下。
- 保護信息(阻止外部隨意訪問內部代碼和數據)
- 隱藏細節(一些不需要程序員修改和使用的信息,用戶只需要知道怎么用就可以,不需要知道內部如何運行)
- 有利于松耦合,提高系統的獨立性。(當一個系統的實現方式發生變化時,只要它的接口不變,就不會影響其他系統的使用)
- 提高軟件的復用率,降低成本
繼承
繼承可以使得子類具有父類的各種屬性和方法,而不需要再次編寫相同的代碼,缺點:提高了類之間的耦合性
繼承的語法:修飾符 class 子類名 extends 父類名
1)子類擁有父類非private的屬性,方法,子類可以擁有自己的屬性和方法,即子類可以對父類進行擴展。子類可以用自己的方式實現父類的方法(重寫)。
2)Java的繼承是一個子類只能繼承一個父類,但是可以多重繼承:例如A類繼承B類,B類繼承C類,這是java繼承區別于C++繼承的一個特性。
多態
?在面向對象理論中,多態性的定義是:同一操作作用于不同的類的對象,將產生不同的執行結果 。
比如動物類可以指向的貓或狗,他們的“叫”方法就是不一樣的,“喵喵”和“汪汪”
好處:多態除了代碼的復用性外,還可以降低耦合、可替換性、可擴充性
多態的轉型分為向上轉型和向下轉型兩種
向上轉型:多態本身就是向上轉型過的過程
父類類型 變量名=new 子類類型();? ? ? 比如:Set<Integer> set=new HashSet<Integer>();
向下轉型:一個子類對象可以使用強制類型轉換,將父類引用類型轉為子類引用各類型
子類類型 變量名=(子類類型)?父類類型的變量;
開發中實現多態?
接口實現、抽象類、繼承父類進行方法重寫、同一個類中進行方法重載。
關鍵字?
final 關鍵字:聲明類可以把類定義為不能繼承的,比如String
super關鍵字:用于引用父類中的屬性和方法,super.屬性、super.方法()
this關鍵字:用于引用本類中的屬性和方法,this.屬性、this.方法()
權限關鍵字
?
抽象類
在繼承關系中,有時基類本身生成對象是不合情理的。
例如,動物作為一個基類可以派生出貓、狗等子類,但動物類本身生成對象明顯不合常理。
abstract修飾的類稱為抽象類。抽象類的特點:
不能實例化對象、類中可以定義抽象方法、抽象類中可以沒有抽象方法。
?abstract修飾的方法稱為抽象方法,抽象方法只有聲明沒有實現,即沒有方法體。包含抽象方法的類本身必須被聲明為抽象的。
abstract class Animal {
private String color ;
public abstract void shout();
}
??派生類繼承抽象類必須實現抽象類中所有的抽象方法,否則派生類也必須定義為抽象類。
接口
Java中的接口是一系列方法的聲明,可以看做是特殊的抽象類,包含常量和方法的聲明,而沒有變量和方法的實現。
接口的意義:
?彌補Java中單繼承機制的不足。
?接口只有方法的定義沒有方法的實現,即都是抽象方法,這些方法可以在不同的地方被不同的類實現,而這些實現可以具有不同的行為(功能)。
接口的定義語法:
interface 接口名稱 {常量抽象方法}類可以通過實現接口的方式來具有接口中定義的功能,基本語法:
–class 類名 implements 接口名 {
–}
–一個類可以同時實現多個接口;
–一個接口可以被多個無關的類實現;
–一個類實現接口必須實現接口中所有的抽象方法,否則必須定義為抽象類。
接口繼承:
Java中接口可以繼承接口,與類的繼承概念一致,
會繼承父接口中定義的所有方法和屬性。
一個接口可以同時繼承多個接口。
接口和抽象類對比
?
| 參數 | 抽象類 | 接口 |
| 默認的方法實現 | 可以有默認的方法實現 | 接口完全是抽象的。不存在方法的實現 |
| 實現 | 子類使用extends關鍵字來繼承抽象類。如果子類不是抽象類的話,它需要提供抽象類中所有聲明的方法的實現。 | 子類使用關鍵字implements來實現接口。它需要提供接口中所有聲明的方法的實現 |
| 構造器 | 抽象類可以有構造器 | 接口不能有構造器 |
| main方法 | 抽象方法可以有main方法并且我們可以運行它 | 接口沒有main方法,因此我們不能運行它。 |
| 多繼承 | 抽象方法可以繼承一個類和實現多個接口 | 接口只可以繼承一個或多個其它接口 |
| 速度 | 它比接口速度要快 | 接口稍微慢,因為需要去尋找在類中實現的方法。 |
| 添加新方法 | 如果你往抽象類中添加新的方法,你可以給它提供默認的實現。因此你不需要改變你現在的代碼。 | 如果你往接口中添加方法,那么你必須改變實現該接口的類。 |
?
異常
Java5個異常
ArrayIndexOutOfBoundsExceptions:數組下標越界
NullPointerException:訪問null的對象的方法或屬性時
ClassCastException:類型轉換失敗時
ConcurrentModificationException:并發修改異常
ArithmeticException:除零異常
處理異常:
try catch :
try catch:自己處理異常
try {可能出現異常的代碼
} catch(異常類名A e){如果出現了異常類A類型的異常,那么執行該代碼
} ...(catch可以有多個)
finally {最終肯定必須要執行的代碼(例如釋放資源的代碼)
}
注意:finally不一定執行:前面代碼遇到如:System.exit(0);? ?return 0;,就不會執行接下來的語句,包括finally。
拋出:
一個方法不處理它產生的異常,而是沿著調用層次向上傳遞,由調用它的方法來處理這些異常,叫拋出異常。
throws:使用throws關鍵字,用來方法可能拋出異常的聲明。
例如:public void doA(int a) throws Exception1,Exception3{......}
throw:使用throws關鍵字,用來拋出異常
語法:throw (異常對象);
如:throw new ArithmeticException();
?
注意事項:
?避免過大的try塊,不要把不會出現異常的代碼放到try塊里面,盡量保持一個try塊對應一個或多個異常。
?細化異常的類型,不要不管什么類型的異常都寫成Excetpion。
?不要把自己能處理的異常拋給別人。
?
自定義異常
?如果JDK提供的異常類型不能滿足需求的時候,程序員可以自定義一些異常類來描述自身程序中的異常信息。
?程序員自定義異常必須是Throwable的直接或間接子類。
?在程序中獲得異常信息一般會調用異常對象的getMessage,printStackTrace,toString方法,所以自定義異常一般會重寫以上三個方法。
public class SpecialException extends Exception {@Overridepublic String getMessage() {return "message";}@Overridepublic void printStackTrace() {System.out.println(message);}@Overridepublic String toString() {return "message";}
}
?
字符串
String
String是字符串final常量類,值一經賦值,其值不可變(指的是所指向的內存值不可修改,但可以改變指向),而且無法被繼承。
初始化
?String name= new String(“小貓”);
和創建對象過程沒有區別,創建一個新的String對象,并用name指向它。
?String sex = “女”;
過程:
- 先在常量池中查找“女”,如果沒有則創建對象
- 在棧中創建引用sex,
- 將sex指向對象“女”
String s1 = "abc";
//"abc"是一個對象
String s2 = new String("abc");
//這里變成兩個對象,在內存中存在兩個,包括對象“abc” 和 new 出來的對象
String s3 = "abc"; //這里的‘abc’?和s1的‘abc’是同一個對象,二者的內存地址一樣。System.out.println(s1==s2);//false
System.out.println(s1==s3);//true部分api
字符串連接concat(String str)、“+”運算符
字符串查找indexOf (String str)、lastIndexOf(String str)、charAt(int indexOf)
字符串分割split(String regex)
字符串比較compareTo(String str):
忽略大小寫equalslgnoreCase(String str)
變成字符數組toCharArray()
StringBuild和 StringBuffer
因為String的值是不可變的,每次對String的操作都會生成新的String對象,這樣效率低下,大量浪費空間。
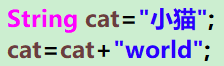
第一行:我們先棧里起名字叫cat,在堆里開辟空間,存入“小貓”,并用cat指向它
第二行:我們新開辟了一個空間,存入“小貓world”,并用cat指向它。
這個過程顯然又費時又費力。
為了應對字符串相關的操作,谷歌引入了兩個新的類:StringBuffer類和StringBuild類,它們能夠被多次的修改,并且不產生新的未使用對象。
StringBuild和 StringBuffer 之間的最大不同在于 StringBuilder 的方法不是線程安全的(不能同步訪問),StringBuffer是線程安全的。(StringBuffer 中的方法大都采用了 synchronized 關鍵字進行修飾)
由于?StringBuilder 相較于 StringBuffer 有速度優勢,所以多數情況下建議使用?StringBuilder 類。
在應用程序要求線程安全的情況下,則必須使用?StringBuffer 類。
集合
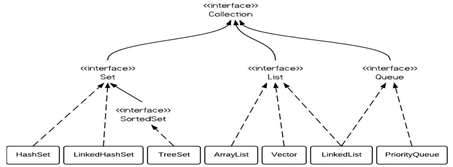
map/set
每一種set有對應類型的map
HashSet(map)無序,底層哈希表+鏈表(1.8后,數量大于8后鏈表改為紅黑樹優化性能),增刪改查O(1)
TreeSet(map)有序(人規定排序的規則),底層是紅黑樹,但是增刪改查O(logN)
LinkerHashSet(map)添加一個雙向鏈表維護了插入的順序。
一般情況用HashSet(map)因為效率高
list
ArrayList,底層是數組,查詢快,增刪慢。
線程不安全,速度快
Vector, 底層是數組,查詢快,增刪慢。
線程安全,速度慢
LinkedList,底層數據結構是鏈表,查詢慢,增刪快。
線程不安全,速度快
PriorityQueue優先隊列,底層是堆。增刪改查O(logN)
API
ArrayList<Integer> list=new ArrayList<Integer>();增:add(E e):將指定的元素添加到此列表的尾部add(int index, E element):將指定的元素插入此列表中的指定位置
刪:remove(int index):移除此列表中指定位置上的元素
改:set(int index, E element):用element替換index上的數
查:get(int index):返回下標index上的元素size():返回此列表中的元素數
//map
Map<Integer, Integer> map=new HashMap<Integer, Integer>();int size()//K-V關系數量
boolean isEmpty()//是否為空
增:V put(K?key,V?value)//放入K-V鍵值對void putAll(Map<K,V> m)//放入m包含的所以鍵值對
刪:V remove(Object?key)//刪除key對應的鍵值對void clear()//刪除所有鍵值對
改:直接put,會覆蓋舊的記錄
查:boolean containsKey(Object?key)//是否包含keyboolean containsValue(Object?value)//是否包含valueV get(Object?key)//得到key對應的value
生成集合:Set<K> keySet()//返回包含所有key的setCollection<V> values()//返回包含所有value的CollectionTreeMap特有:
public K firstKey()//返回第一個key(最高)
public K lastKey()//返回最后一個key(最低)
//set,大部分和map類似
增:add
刪:remove
查:containsIterator
主要功能:用于對容器的遍歷
主要方法:
boolean hasNext():判斷是否有可以元素繼續迭代
Object next():返回迭代的下一個元素
void remove():從迭代器指向的集合中移除迭代器返回的最后一個元素
例子:
Set<String> name = new HashSet<String>();
name.add("LL");
name.add("VV");
name.add("WW");
......Iterator<String> it = name.iterator();
while(it.hasNext()){String n = it.next();...
}HashMap相關
HashMap
- ?哈希沖突:若干Key的哈希值如果落在同一個數組下標上,將組成一條鏈,對Key的查找需要遍歷鏈上的每個元素執行equals()比較,1.8后優化為紅黑樹
- 負載極限,“負載極限”是一個0~1的數值,“負載極限”決定了hash表的最大填滿程度。當hash表中的負載因子達到指定的“負載極限”時,hash表會自動成倍地增加容量(桶的數量),并將原有的對象重新分配,放入新的桶內,這稱為rehashing。默認當HashMap中的鍵值對達到數組大小的75%時,即會rehashing。
解釋0.75:
是時間和空間成本上的一種折中:
- 較高的“負載極限”(也就是數組小)可以降低占用的空間,但會增加查詢數據的時間開銷
- 較低的“負載極限”(也就是數組大)會提高查詢數據的性能,但會增加hash表所占用的內存開銷
可以根據實際情況來調整“負載極限”值。
多線程比較
HashMap
線程不安全
HashTable
線程安全,實現的方式是在修改數據時鎖住整個HashTable,效率低,ConcurrentHashMap做了相關優化
ConcurrentHashMap
線程安全,其關鍵在于使用了鎖分離技術。它使用了多個鎖來控制對hash表的不同部分進行的修改。
ConcurrentHashMap內部使用段(Segment)來表示這些不同的部分,每個段其實就是一個小的Hashtable,它們有自己的鎖。
只要多個修改操作發生在不同的段上,它們就可以并發進行。
默認將hash表分為16個桶,諸如get、put、remove等常用操作只鎖住當前需要用到的桶,讀操作大部分時候都不需要用到鎖。
(JDK1.8已經摒棄了Segment,并發控制使用Synchronized和CAS來操作,整個看起來就像是優化過且線程安全的HashMap,雖然在JDK1.8中還能看到Segment的數據結構,但是已經簡化了屬性,只是為了兼容舊版本。)
?
泛型
泛型用一個通用的數據類型T來代替類,在類實例化時指定T的類型,運行時自動編譯為本地代碼,運行效率和代碼質量都有很大提高,并且保證數據類型安全。
泛型的作用就是提高代碼的重用性,避免強制類型轉換,減少裝箱拆箱提高性能,減少錯誤。



)
)



)










