廢話不多說,上干貨是兔老大的傳統了,收藏就完事了。
![]()
目錄
數據庫系統概論
四個基本概念
數據模型
數據庫系統結構
數據庫系統模式的概念
數據庫系統的三級模式結構
數據庫的二級映像功能與數據的獨立性
數據庫系統的組成
關系
關系模式
關系數據庫
基本的關系操作
關系的完整性
實體完整性(即主屬性非空)
參照完整性
用戶定義完整性
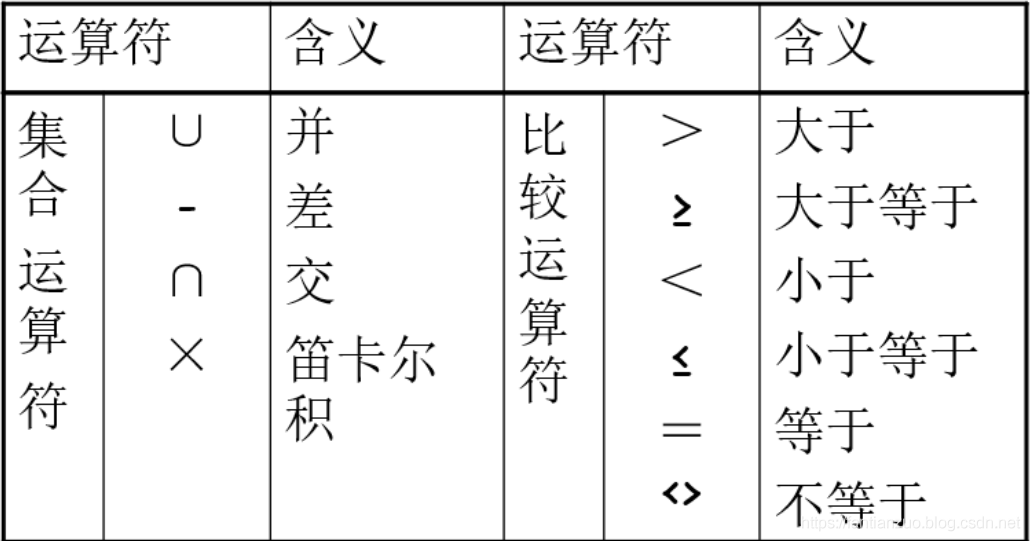
關系代數
傳統的集合運算
專門的關系運算
選擇:
投影:
連接
除
數據類型大總結
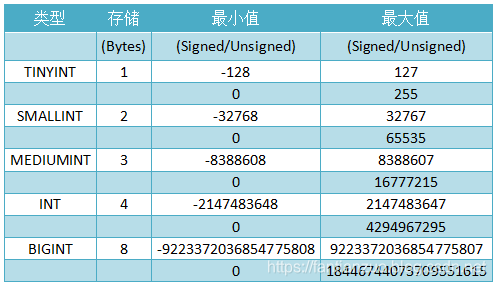
整數類型:
實數類型:
浮點數類型
BIT數據類型
字符串類型
CHAR & VARCHAR
BINARY & VARBINARY
BLOB & TEXT
ENUM 使用枚舉代替字符串類型
時間和日期類型
關系數據庫標準語言SQL
基本概念
數據庫的創建與基本概念
模式的創建與刪除
表的定義、刪除與修改
索引的建立與刪除
sql查詢
?
單表查詢
連接查詢
嵌套查詢
集合查詢
sql增刪改
數據的插入
3.5.2 數據的修改
3.5.3 數據的刪除
?mysql常用函數總結
文本處理函數
日期和時間處理函數
數值處理函數
視圖/存儲過程/觸發器
視圖
為什么使用視圖
視圖的規則和限制
視圖的創建
視圖的更新
存儲過程
為什么使用儲存過程?
執行存儲過程
使用參數的存儲過程
帶有控制語句的存儲過程
觸發器
創建觸發器
觸發器類別
總結
數據庫恢復
實現技術
數據轉儲
日志文件
1、什么是日志文件
2、日志文件的格式
3、日志文件的作用
4、登記日志文件:
恢復策略
事務故障的恢復
系統故障的恢復
介質故障的恢復
檢查點
鏡像
小結:
常用恢復技術
提高恢復效率的技術
并發控制
概述
封鎖
封鎖協議
饑餓
死鎖
解決死鎖的方法:預防、診斷和解除
串行調度
可串行化調度
沖突可串行化調度
兩段鎖協議
封鎖的粒度
意向鎖
其他并發控制
數據庫系統概論
四個基本概念
數據:數據庫中存儲的基本對象,描述一個事物的符號記錄,數據和其語義不可分開說
數據庫(DB):是長期儲存在計算機內、有組織的、可共享的大量數據的集合。
數據庫管理系統:一個管理數據的軟件
主要功能:
數據定義功能:
(1)提供數據定義語言(DDL):創建表(CREATE),修改表(ALTER),刪除表(DROP);
(2)定義數據庫中的數據對象
操縱功能:
提供數據操縱語言(DML,即增刪改查的操作),實現對數據庫的基本操作 (查詢、插入、刪除和修改)
事務管理和運行管理:
數據庫由DBMS統一管理和控制保證數據的安全,完整性、多用戶對數據的并發使用、發生故障后的系統恢復
建立和維護功能:(1)數據庫初始數據裝載轉換;(2)數據庫轉儲;(3)介質故障恢復;(4)數據庫的重組織;(5)性能監視分析等
數據庫系統:由數據庫、數據庫管理系統應用程序和數據庫管理員(DBA)等組成的存儲、管理、處理和維護數據的系統。
數據模型
兩類數據模型
-
概念模型:第一次抽象,用于數據庫設計
-
邏輯模型和物理模型:第二次抽象
1)邏輯模型主要包括網狀模型、層次模型、關系模型、面向對象模型等,按計算機系統的觀點對數據建模,用于DBMS實現
2)物理模型是對數據最底層的抽象,描述數據在系統內部的表示方式和存取方法,在磁盤或磁帶上的存儲方式和存取方法
數據模型的組成要素
-
數據結構
1)描述數據庫的組成對象,以及對象之間的聯系
2)描述與數據之間聯系有關的對象
3)是對系統靜態特性的描述
4)分類:(1)非關系型:網狀,層次;(2)關系型;(3)面向對象型
-
數據操作
1)對數據庫中各種對象(型)的實例(值)允許執行的操作及有關的操作規則
2)增刪改查
3)是對系統動態特性的描述
-
數據的完整性約束條件
1)一組完整性規則的集合
2)完整性規則:給定的數據模型中數據及其聯系所具有的制約和儲存規則
3)用以限定符合數據模型的數據庫狀態以及狀態的變化,以保證數據的正確、有效、相容
-
實體完整性:具體的數據的屬性信息是否完整
參照完整性:該屬性對應的值存在
用戶定義完整性:看心情
關系模型
-
基本概念:
1)關系(Relation):一個關系對應通常說的一張表
2)元組(Tuple):表中的一行即為一個元組
3)屬性(Attribute):表中的一列即為一個屬性,給每一個屬性起一個名稱即屬性名
4)碼(Key) :唯一確定一個元組的屬性或屬性組
5)域(Domain) :是一組具有相同數據類型的值的集合
6)分量:元組中的一個屬性值
7)關系模式:對關系的描述,一般表示為
? 關系名(屬性1,屬性2,……,屬性n)
學生(學號,姓名,年齡,性別,系,年級)
8)注意規范:不能出現大表套小表。
-
數據操作:增刪改查,對若干元組操作的集合
-
數據的完整性約束條件:
1)實體完整性
2)參照完整性
3)用戶定義完整性
數據庫系統結構
數據庫系統模式的概念
- 型:對某一類數據的結構和屬性的說明,(學號,姓名,性別,系別,年齡,籍貫)
- 值:是型的一個具體賦值,(201315130,李明,男,計算機,19,江蘇)
- 模式:數據庫邏輯結構和特征的描述,是型的描述,反映的是數據的結構及其聯系,模式是相對穩定的,即屬性名的集合
- 實例:模式的一個具體值,反映數據庫某一時刻的狀態,同一個模式可以有很多實例,實例隨數據庫中的數據的更新而變動
- 如果是一個成績單:那么科目那一行表示的是模式(不僅僅只是這些,還包括其他的信息),每一個人的成績一行表示的是一個實例
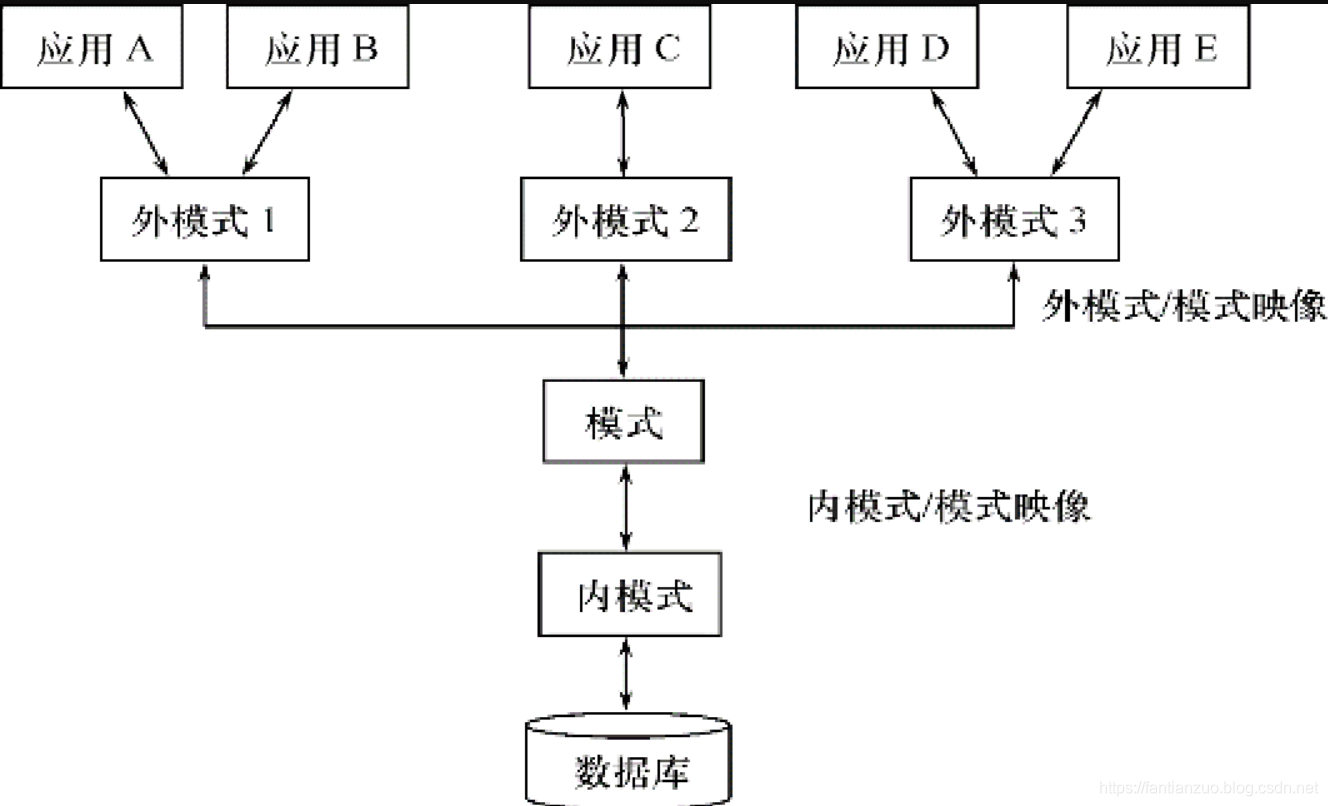
數據庫系統的三級模式結構
-
模式:數據庫中全體數據的邏輯結構和特征的描述,所有用戶的公共數據視圖,綜合了所有用戶的需求,一個數據庫只有一個模式,模式是相對穩定的,但是實體是相對變動的
地位:1)是數據庫系統模式結構的中間層;2)與數據的物理存儲細節和硬件環境無關;3)與具體的應用程序、開發工具及高級程序設計語言無關
定義:1)數據的邏輯結構(數據項的名字、類型、取值范圍等);2)數據之間的聯系;3)數據有關的安全性、完整性要求
-
外模式:模式的子集,一個數據庫可以有多個,是數據庫中局部數據的邏輯結構和特征的描述
-
內模式:1)是數據物理結構和存儲方式的描述;2)是數據在數據庫內部的表示方式
一個數據庫只有一個內模式。
數據庫的二級映像功能與數據的獨立性
-
外模式/模式映像:保證了數據的邏輯獨立性。不唯一
1)當模式改變時,數據庫管理員修改有關的外模式/模式映象,使外模式保持不變
2)應用程序是依據數據的外模式編寫的,從而應用程序不必修改,保證了數據與程序的邏輯獨立性,簡稱數據的邏輯獨立性。
-
模式/內模式映像:保證了數據的物理獨立性。唯一
1)當數據庫的存儲結構改變了(例如選用了另一種存儲結構),數據庫管理員修改模式/內模式映象,使模式保持不變,進而外模式也不發生改變
2)應用程序不受影響。保證了數據與程序的物理獨立性,簡稱數據的物理獨立性
-
數據的存取由DBMS管理的好處:
1)用戶不必考慮存取路徑等細節
2)簡化了應用程序的編制
3)大大減少了應用程序的維護和修改
?
數據庫系統的組成
硬件,操作系統,數據庫設計人員,數據庫管理人員,數據庫管理系統,用戶等等。
?
關系
-
域:一組具有相同數據類型的值的集合(即取值范圍)
-
笛卡爾積:域上的一種集合運算。結果為一個集合,集合的每一個元素是一個元組,元組的每一個分量來自不同的域。
-
基數:一個域允許的不同取值個數。
-
笛卡爾積的基數:每個域不同取值的個數的乘積,或者說元組的個數
-
關系:域的笛卡爾積的子集叫做在域上的關系,域的個數叫做關系的目或度。(即列數,屬性的數目),注意廣義上的笛卡爾積一般不能稱為關系,因為存在無效的數據。
-
關系:表
列:屬性
行:元組
-
候選碼:某一屬性組的值能唯一地標示一個元組,而其子集不能,則稱該屬性組為候選碼
-
主屬性:候選碼中的屬性都稱為主屬性,注意:主屬性非空。
-
非主屬性:候選碼之外的屬性稱為非主屬性
-
全碼:關系模式的所有屬性是這個關系模式的候選碼
-
主碼:從候選碼中選取一組能唯一確定一個元組的屬性組作為主碼。
-
三類關系:
1)基本關系:實際存在的表,是實際存儲數據的邏輯表示
2)查詢表:查詢結果對應的表
3)視圖表:由基本表或其他視圖表導出的表,是虛表,不對應實際存儲的數據。
注意:關系數據模型中的關系必須是有限集合。
關系的每一個列必須附加一個屬性名,屬性名不能重名,這種方法取消了關系屬性的有序性。
-
① 列是同質的(Homogeneous):每一列中的分量來自同一個域,是同一類型的數據
② 不同的列可出自同一個域
-
其中的每一列稱為一個屬性
-
不同的屬性要給予不同的屬性名
③ 列的順序無所謂, 列的次序可以任意交換
④ 任意兩個元組的候選碼不能相同:相同就不是候選碼了
⑤ 行的順序無所謂,行的次序可以任意交換
⑥ 分量必須取原子值(不允許表中套表)
-
關系模式

?
-
關系模式:對關系的描述,是靜態的、穩定的
-
關系:是關系模式在某一時刻的狀態或內容,是動態的、隨時間不斷變化的,指后邊的那個關系
-
關系模式的形式化表示:
//關系模式
R(U, D, DOM, F)
R 關系名
U 組成該關系的屬性名集合
D 屬性組U中屬性所來自的域
DOM 屬性向域的映象集合
F 屬性間的數據依賴關系集合//可以簡記為
R (U) 或 R (A1,A2,…,An)
R: 關系名
A1,A2,…,An : 屬性名
注:域名及屬性向域的映象常常直接說明為屬性的類型、長度關系數據庫
-
在一個給定的應用領域中,所有關系的集合構成一個關系數據庫
-
關系數據庫的型與值,不是關系的型與值
1)關系數據庫的型也稱關系數據庫模式,是對關系數據庫的描述
2)關系數據庫的值是關系模式在某一時刻對應的關系的集合,簡稱為關系數據庫
基本的關系操作
-
常用的基本操作:
**查詢:**選擇、投影、連接、除、并、交、差
**數據更新:**插入、刪除、修改
-
**5種基本操作:**選擇、投影、并、差、笛卡爾積?注意:不算交
-
關系操作的特點:
集合操作方式:操作的對象和結果都是集合,一次一集合的方式,操作對象是集合,操作結果亦為集合。
?
關系的完整性
實體完整性(即主屬性非空)
- 若屬性A是基本關系R的主屬性,則屬性A不能取空值
參照完整性
-
關系間的引用:關系與關系之間存在著聯系
-
外碼:設F是基本關系R的一個或一組屬性,但不是關系R的主碼,Ks是基本關系S的主碼。如果F與Ks相對應,則稱F是基本關系R的外碼,外碼所在的基本關系叫做參照關系,Ks所在的關系叫做被參照關系。
注:
1)R、S不一定是不同的關系。
2)目標關系S的主碼Ks 和參照關系的外碼F必須定義在同一個(或一組)域上
3)外碼并不一定要與相應的主碼同名,當外碼與相應的主碼屬于不同關系時,往往取相同的名字,以便于識別
4)外碼的取值:如果外碼是參照關系的主屬性,則不能為空(實體完整性),只能為被參照關系中主碼的取值。如果外碼不是參照關系的主屬性,則可以取空或者被參照關系主碼的取值
-
兩個不變性:指實體完整性和參照完整性
用戶定義完整性
-
針對某一具體關系數據庫的約束條件,反映某一具體應用所涉及的數據必須滿足的語義要求
-
關系模型應提供定義和檢驗這類完整性的機制,以便用統一的系統的方法處理它們,而不要由應用程序承擔這一功能
關系代數
傳統的集合運算
-
傳統的關系運算:
并、交、差、笛卡爾積
-
操作對象關系:
操作方式:同數學中的并、交、差、笛卡爾積。只不過操作對象的元素是元組。另外需要注意能進行運算所需要滿足的條件。
對于并、交、差需要滿足的關系:1)屬性的數目相同;2)相應的屬性取自同一個域
專門的關系運算
常見的關系運算有選擇、投影、連接、除
選擇:
在關系R中選擇滿足給定條件的諸元組。
表達式:$\sigma_F(R) = {t | t \in R \and F(t) = ''true''}$
F:為選擇條件,是一個邏輯表達式,基本形式為:$X_1 \theta Y_1$,其中$\theta$為大于、小于、等于、不等于等。
舉例:
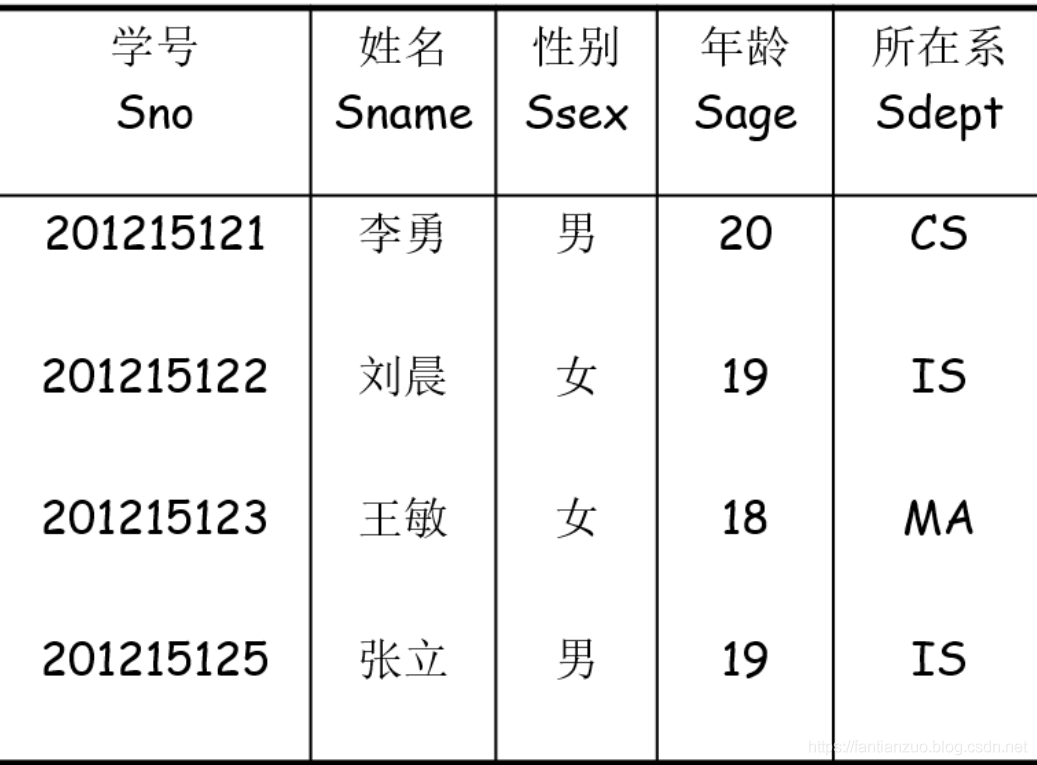
選擇:$\sigma_{Sdept = "IS"}(Student)$
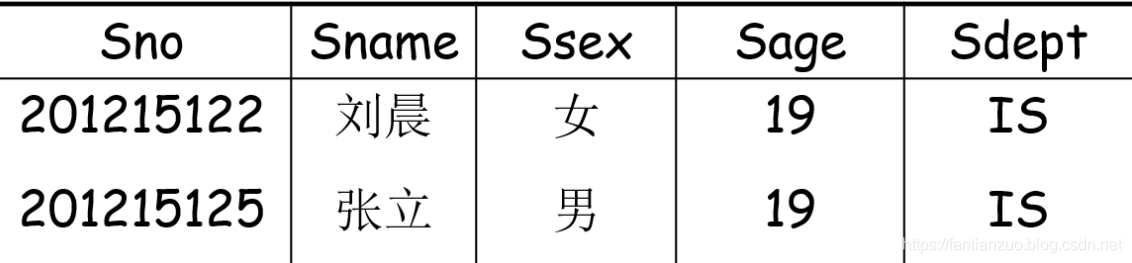
投影:
從R中選擇出若干屬性列組成新的關系
表達式:$\prod_{A} (R)= {t[A] | t\in R}$
A為屬性列,即從R中選擇A中屬性列的元組,當然選擇之后可能會刪掉一些元組,因為避免重復。
舉例:還是上方的關系,經過投影$\prod_{Sname, Sdept}(Student)$,結果如下:
?
連接
?
1)**一般連接:**從兩個關系的笛卡爾積中選取屬性間滿足一定條件的元組
(1)表達式:$R\bowtie_ {A \theta B} S = {t_r^ \frown t_s | t_r \in R \and t_s \in S \and t_r[A] \theta t_s[B] }$
(2)A和B:分別為R和S上度數相等且可比的屬性組
(3)$\theta$表示比較運算符,
(4)連接運算從R和S的廣義笛卡爾積R×S中選取(R關系)在A屬性組上的值與(S關系)在B屬性組上值滿足比較關系θ的元組
2)**等值連接:**當上述的運算符為等于號的時候
(1)含義:從關系R與S的廣義笛卡爾積中選取A、B屬性值相等的那些元組,即等值連接為:
(2)表達式:$R\bowtie_ {A = B} S = {t_r^ \frown t_s | t_r \in R \and t_s \in S \and t_r[A] = t_s[B] }$
(3)仍然是從行的角度進行運算,而不涉及列
(4)屬性組可以不同
3)**自然連接:**一種特殊的等值連接
(1)與等值連接的不同:兩個關系R和S必須具有相同的屬性組
(2)將結果中相同的屬性列去掉
(3)表達式:$R\bowtie S = {t_r^ \frown t_s | t_r \in R \and t_s \in S \and t_r[A] = t_s[B] }$
4)由自然連接所引發的一系列問題:
(1)懸浮元組:在做自然連接的時候被舍棄的元組
(2)外連接:如果把舍棄的元組也保存在結果關系中,而在其他屬性上填空值(Null),這種連接就叫做外連接,外連接 = 左外連接 + 右外連接
(3)左外連接:如果只把左邊關系R中要舍棄的元組保留就叫做左外連接
(4)右外連接:如果只把右邊關系S中要舍棄的元組保留就叫做右外連接
除
1)除運算的意義:
(1)假設關系R,S,RS,R關系擁有的屬性是姓名,S關系擁有的屬性是課程,RS關系擁有的屬性是姓名和課程的聯系,則RS/S表示選出所有至少選了表S中所列課程的學生的元組。
(2)如下圖:
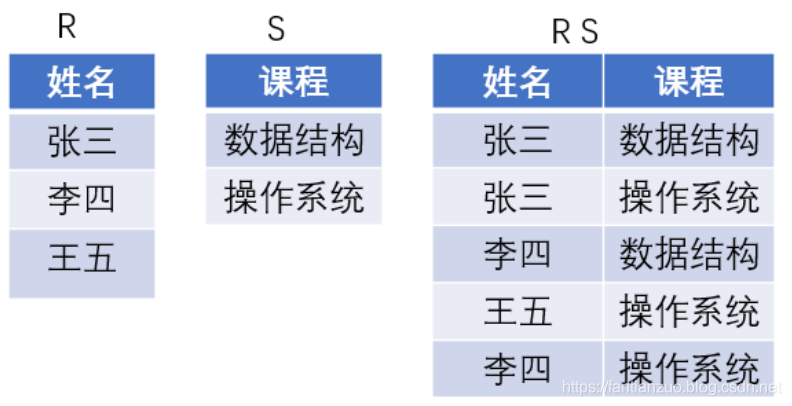
注:RS/S得到的關系:張三和李四構成的表,表示選修了全部課程的同學的集合。
舉例:
R:
| A | B | C |
|---|---|---|
| a1 | b1 | c2 |
| a2 | b3 | c7 |
| a3 | b4 | c6 |
| a1 | b2 | c3 |
| a4 | b6 | c6 |
| a2 | b2 | c3 |
| a1 | b2 | c1 |
S:
| B | C | D |
|---|---|---|
| b1 | c2 | d1 |
| b2 | c1 | d1 |
| b2 | c3 | d2 |
R÷S
| A |
|---|
| a1 |
(1) 找S與R的共同屬性,即公式中的Y屬性
(2)計算R中每個X屬性的象集,如果某個象集包含S在Y屬性上的投影,則該屬為R/S結果中的一個值。
解答如下:
在關系R中,A可以取四個值{a1,a2,a3,a4},其中:
a1的象集為:{(b1,c2),(b2,c3),(b2,c1)}
a2的象集為:{(b3,c7),(b2,c3)}
a3的象集為:{(b4,c6)}
a4的象集為:{(b6,c6)}
S在(B,C)上的投影為{(b1,c2),(b2,c3),(b2,c1)}。
顯然只有R的象集a1包含S在(B,C)屬性組上的投影,所以R÷S={a1}。
?
數據類型大總結
?
整數類型:
實數類型:
定點數:DECIMAL和NUMERIC類型在MySQL中視為相同的類型。它們用于保存必須為確切精度的值。
DECIMAL(M,D),其中M表示十進制數字總的個數,D表示小數點后面數字的位數。
- 如果存儲時,整數部分超出了范圍(如上面的例子中,添加數值為1000.01),MySql就會報錯,不允許存這樣的值。
- 如果存儲時,小數點部分若超出范圍,就分以下情況:
- 若四舍五入后,整數部分沒有超出范圍,則只警告,但能成功操作并四舍五入刪除多余的小數位后保存。如999.994實際被保存為999.99。
- 若四舍五入后,整數部分超出范圍,則MySql報錯,并拒絕處理。如999.995和-999.995都會報錯。
M的默認取值為10,D默認取值為0。如果創建表時,某字段定義為decimal類型不帶任何參數,等同于decimal(10,0)。帶一個參數時,D取默認值。
M的取值范圍為1~65,取0時會被設為默認值,超出范圍會報錯。
D的取值范圍為0~30,而且必須<=M,超出范圍會報錯。
所以,很顯然,當M=65,D=0時,可以取得最大和最小值。
?
浮點數類型
:float,double和real。他們定義方式為:FLOAT(M,D) 、 REAL(M,D) 、 DOUBLE PRECISION(M,D)。? “(M,D)”表示該值一共顯示M位整數,其中D位位于小數點后面
FLOAT和DOUBLE中的M和D的取值默認都為0,即除了最大最小值,不限制位數。
M取值范圍為0~255。FLOAT只保證6位有效數字的準確性,所以FLOAT(M,D)中,M<=6時,數字通常是準確的。如果M和D都有明確定義,其超出范圍后的處理同decimal。
D取值范圍為0~30,同時必須<=M。double只保證16位有效數字的準確性,所以DOUBLE(M,D)中,M<=16時,數字通常是準確的。如果M和D都有明確定義,其超出范圍后的處理同decimal。
內存中,FLOAT占4-byte(1位符號位 8位表示指數 23位表示尾數),DOUBLE占8-byte(1位符號位 11位表示指數 52位表示尾數)。
?
浮點數比定點數類型存儲空間少,計算速度快,但是不夠精確。
?
因為需要計算額外的空間和計算開銷,所以應該盡量只在對小數進行精確計算時 才使用DECIMAL。但在數據量比較大的情況下,可以考慮使用BIGINT代替DECIMAL,將需要存儲的貨幣單位根據小數的位數乘以相應的倍數即可。
?
BIT數據類型
可用來保存位字段值。BIT(M)類型允許存儲M位值。M范圍為1~64,默認為1。
BIT其實就是存入二進制的值,類似010110。
如果存入一個BIT類型的值,位數少于M值,則左補0.
如果存入一個BIT類型的值,位數多于M值,MySQL的操作取決于此時有效的SQL模式:
如果模式未設置,MySQL將值裁剪到范圍的相應端點,并保存裁減好的值。
如果模式設置為traditional(“嚴格模式”),超出范圍的值將被拒絕并提示錯誤,并且根據SQL標準插入會失敗。
MySQL把BIT當做字符串類型,而非數字類型。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
字符串類型
字符串類型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。
?
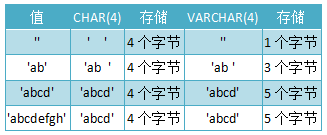
CHAR & VARCHAR
?
CHAR和VARCHAR類型聲明的長度表示你想要保存的最大字符數。例如,CHAR(30)可以占用30個字符。默認長度都為255。
CHAR列的長度固定為創建表時聲明的長度。長度可以為從0到255的任何值。當保存CHAR值時,在它們的右邊填充空格以達到指定的長度。當檢索到CHAR值時,尾部的空格被刪除掉,所以,我們在存儲時字符串右邊不能有空格,即使有,查詢出來后也會被刪除。在存儲或檢索過程中不進行大小寫轉換。
所以當char類型的字段為唯一值時,添加的值是否已經存在以不包含末尾空格(可能有多個空格)的值確定,比較時會在末尾補滿空格后與現已存在的值比較。
VARCHAR列中的值為可變長字符串。長度可以指定為0到65,535之間的值(實際可指定的最大長度與編碼和其他字段有關,比如,MySql使用utf-8編碼格式,大小為標準格式大小的2倍,僅有一個varchar字段時實測最大值僅21844,如果添加一個char(3),則最大取值減少3。整體最大長度是65,532字節)。
?
同CHAR對比,VARCHAR值保存時只保存需要的字符數,另加一個字節來記錄長度(如果列聲明的長度超過255,則使用兩個字節)。
?
VARCHAR值保存時不進行填充。當值保存和檢索時尾部的空格仍保留,符合標準SQL。
?
如果分配給CHAR或VARCHAR列的值超過列的最大長度,則對值進行裁剪以使其適合。如果被裁掉的字符不是空格,則會產生一條警告。如果裁剪非空格字符,則會造成錯誤(而不是警告)并通過使用嚴格SQL模式禁用值的插入。
?
BINARY & VARBINARY
?
BINARY和VARBINARY類型類似于CHAR和VARCHAR類型,但是不同的是,它們存儲的不是字符串,而是二進制串。所以它們沒有編碼格式,并且排序和比較基于列值字節的數值值。
當保存BINARY值時,在它們右邊填充0x00(零字節)值以達到指定長度。取值時不刪除尾部的字節。比較時所有字節很重要(因為空格和0x00是不同的,0x00<空格),包括ORDER BY和DISTINCT操作。比如插入'a '會變成'a \0'。
對于VARBINARY,插入時不填充字符,選擇時不裁剪字節。比較時所有字節很重要。
?
BLOB & TEXT
BLOB是一個二進制大對象,可以容納可變數量的數據。有4種BLOB類型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它們只是可容納值的最大長度不同。
有4種TEXT類型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。這些對應4種BLOB類型,有相同的最大長度和存儲需求。
BLOB列被視為二進制字符串。TEXT列被視為字符字符串,類似BINARY和CHAR。
在TEXT或BLOB列的存儲或檢索過程中,不存在大小寫轉換。
未運行在嚴格模式時,如果你為BLOB或TEXT列分配一個超過該列類型的最大長度的值,值被截取以保證適合。如果截掉的字符不是空格,將會產生一條警告。使用嚴格SQL模式,會產生錯誤,并且值將被拒絕而不是截取并給出警告。
?
在大多數方面,可以將BLOB列視為能夠足夠大的VARBINARY列。同樣,可以將TEXT列視為VARCHAR列。
?
BLOB和TEXT在以下幾個方面不同于VARBINARY和VARCHAR:
當保存或檢索BLOB和TEXT列的值時不刪除尾部空格。(這與VARBINARY和VARCHAR列相同)。
比較時將用空格對TEXT進行擴充以適合比較的對象,正如CHAR和VARCHAR。
對于BLOB和TEXT列的索引,必須指定索引前綴的長度。對于CHAR和VARCHAR,前綴長度是可選的。
BLOB和TEXT列不能有默認值。
BLOB或TEXT對象的最大大小由其類型確定,但在客戶端和服務器之間實際可以傳遞的最大值由可用內存數量和通信緩存區大小確定。你可以通過更改max_allowed_packet變量的值更改消息緩存區的大小,但必須同時修改服務器和客戶端程序。
?
每個BLOB或TEXT值分別由內部分配的對象表示。
它們(TEXT和BLOB同)的長度:
Tiny:最大長度255個字符(2^8-1)
BLOB或TEXT:最大長度65535個字符(2^16-1)
Medium:最大長度16777215個字符(2^24-1)
LongText 最大長度4294967295個字符(2^32-1)
實際長度與編碼有關,比如utf-8的會減半。
?
當BLOB和TEXT值太大時,InnoDB會使用專門的外部存儲區域來進行存儲,此時單個值在行內需要1~4個字節存儲一個指針,然后在外部存儲區域存儲實際的值。
MySQL會BLOB和TEXT進行排序與其他類型是不同的:它只對每個類的最前max_sort_length字節而不是整個字符串進行排序。
MySQL不能將BLOB和TEXT列全部長度的字符串進行索引,也不能使用這些索引消除排序。
?
ENUM 使用枚舉代替字符串類型
MySQL在存儲枚舉時非常緊湊,會根據列表值的數量壓縮到一個或兩個字節中。MySQL在內部將每個值在列表中的位置保存為整數,并且在表的.frm文件中保存“數組——字符串”映射關系的查找表。
枚舉字段是按照內部存儲的整數而不是定義的字符串進行排序的;
由于MySQL把每個枚舉值都保存為整數,并且必須通過查找才能轉換為字符串,所以枚舉列有一定開銷。在特定情況下,把CHAR/VARCHAR列與枚舉列進行JOIN可能會比直接關聯CHAR/VARCHAR更慢。

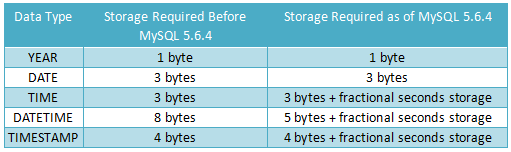
時間和日期類型
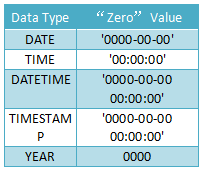
DATE, DATETIME, 和TIMESTAMP類型 這三者其實是關聯的,都用來表示日期或時間。
當你需要同時包含日期和時間信息的值時則使用DATETIME類型。MySQL以'YYYY-MM-DD HH:MM:SS'格式檢索和顯示DATETIME值。支持的范圍為'1000-01-01 00:00:00'到'9999-12-31 23:59:59'。
當你只需要日期值而不需要時間部分時應使用DATE類型。MySQL用'YYYY-MM-DD'格式檢索和顯示DATE值。支持的范圍是'1000-01-01'到 '9999-12-31'。
?
TIMESTAMP類型同樣包含日期和時間,范圍從'1970-01-01 00:00:01' UTC 到'2038-01-19 03:14:07' UTC。
TIME值的范圍可以從'-838:59:59'到'838:59:59'。小時部分會因此大的原因是TIME類型不僅可以用于表示一天的時間(必須小于24小時),還可能為某個事件過去的時間或兩個事件之間的時間間隔(可以大于24小時,或者甚至為負)
?
兩者的存儲方式不一樣
對于TIMESTAMP,它把客戶端插入的時間從當前時區轉化為UTC(世界標準時間)進行存儲。查詢時,將其又轉化為客戶端當前時區進行返回。
而對于DATETIME,不做任何改變,基本上是原樣輸入和輸出。
?
YEAR類型是一個單字節類型用于表示年。
MySQL以YYYY格式檢索和顯示YEAR值。范圍是1901到2155。
關系數據庫標準語言SQL
基本概念
-
SQL語言是一個功能極強的關系數據庫語言。同時也是一種介于關系代數與關系演算之間的結構化查詢語言(Structured Query Language),其功能包括數據定義、數據查詢、數據操縱和數據控制。
-
SQL的特點:
1)綜合統一:集數據定義、數據查詢、數據操縱和數據控制等多種功能于一體。
2)高度非過程化 :面對象的設計
3)面向集合的操作方式 :操作對象是集合,并且操作結果也是集合
4)兩種使用方式,統一的語法結構 :既是一種獨立的語言,又是一種嵌入式的語言,(嵌入式是指嵌入別的高級語言)。
5)簡潔易學
數據庫的創建與基本概念
一、創建數據庫:
代碼:
create database Student; --創建數據庫
use Student; --使用數據庫
drop database Student; --刪除數據庫注意:
1)兩種注釋方式:(1)兩個減號--,注釋單行 (2)/* */注釋多行
2)不能再當前數據庫刪除當前數據庫
數據類型:
注意:
1)一個屬性采用何種數據類型由兩部分決定:(1)該屬性的取值范圍;(2)該屬性做何種運算。
模式的創建與刪除
模式,一個獨立于數據庫用戶的非重復命名空間,在這個空間中可以定義該模式包含的數據庫對象,例如基本表、視圖、索引等。
代碼:
/** 創建模式zhang,下鍵表student*/
create schema zhangcreate table student(Sno char(9) primary key,Sname varchar(20) unique,Ssex char(4) not null,Sage smallint,Sdept varchar(5) );/** 刪除模式中的表*/
drop table zhang.student;/** 刪除模式*/
drop schema zhang; --注意前提該模式下無對象注意:
1)刪除模式的時候首先應當將模式下的所有對象刪除,才能刪除該模式
2)在刪除某個非dbo模式下的表時,需要加模式名
3)該模式不是三級模式兩級映像中的模式,而是相當于一個命名空間(主要可以解決重名的問題)
4)CASCADE(級聯):刪除模式的同時把該模式中所有的數據庫對象全部刪除(SQL Server不支持)
5)RESTRICT(限制):只有當該模式中沒有任何下屬的對象時才能執行
表的定義、刪除與修改
一、創建表(三張):(1)學生表(Student)(2)課程表(Course)(3)學生課程表(SC)
1)學生表(Student)
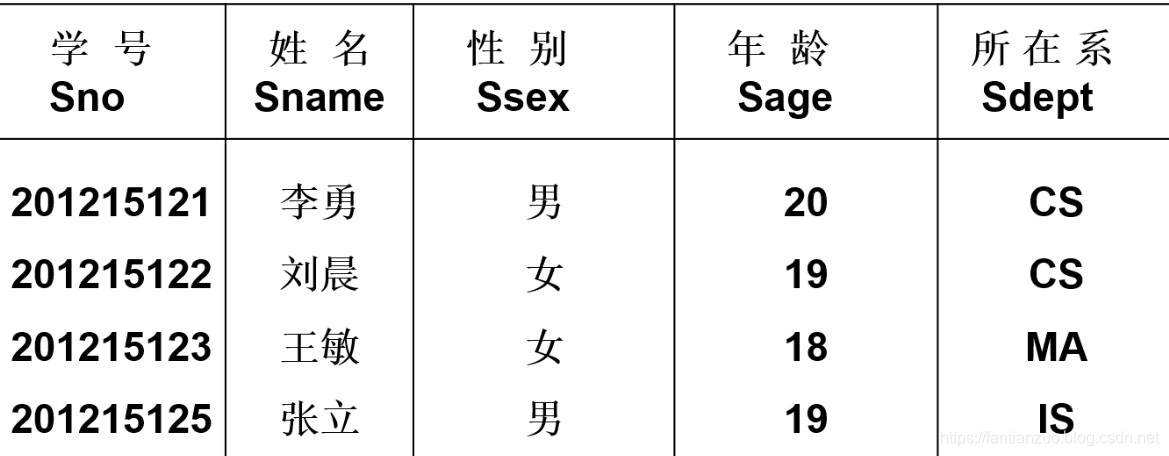
?代碼:
/** 未添加數據*/
create table student
(Sno char(9) primary key, --primary key 指示主碼Sname varchar(20) unique, --unique 指示值唯一,Ssex char(4) not null, --not null 該值非空Sage smallint,Sdept varchar(5)
);2)課程表(Course)
代碼:
/** 創建課程表*/
create table Course
(Cno char(2) primary key,Cname varchar(10) unique,Cpno char(2), --Cpno是外碼,參照的是自身的CnoCcredit smallint,foreign key (Cpno) references Course(Cno) --外碼
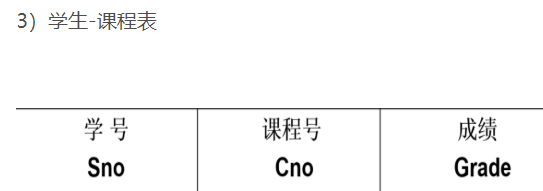
);3)學生-課程表
?
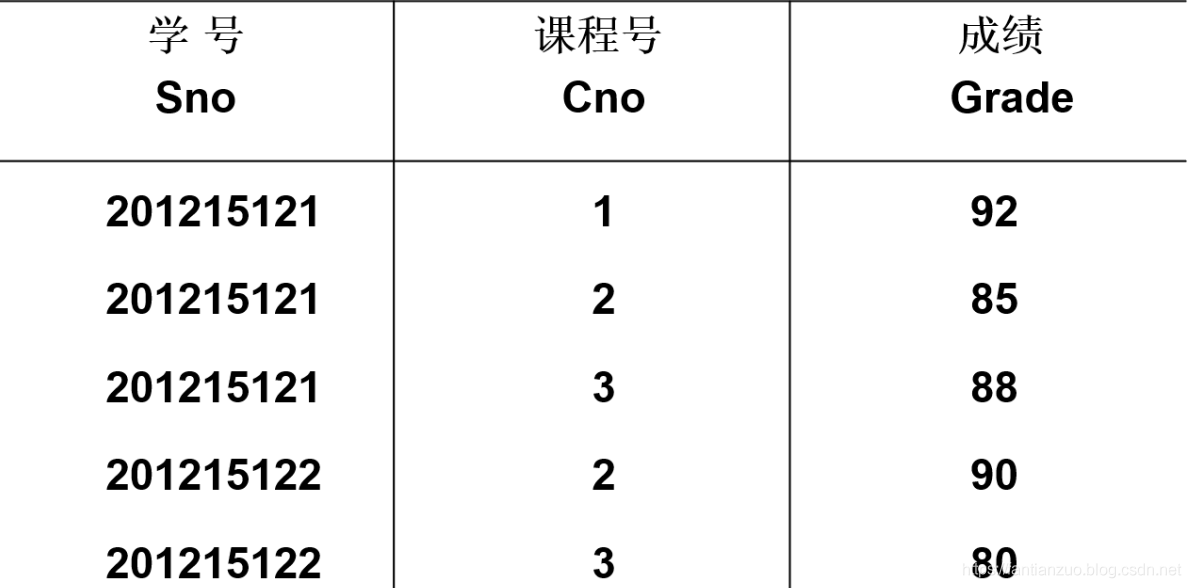
代碼:
/** 創建學生-課程表*/
create table SC
(Sno char(9),Cno char(2),Grade int,primary key(Sno, Cno), --多個屬性列構成主碼,寫在最后foreign key(Sno) references student(Sno), --外碼, 每個外碼寫一行foreign key(Cno) references Course(Cno)
);注意:
1)創建表的時候需要考慮三個完整性約束條件:實體完整性,參照完整性,用戶自定義完整性
2)兩種完整性約束條件的定義方式:
-
列級完整性約束條件:涉及相應屬性列的完整性約束條件,在屬性列的后邊定義。
-
表級完整性約束條件:涉及一個或多個屬性列的完整性約束條件 ,在將屬性列完之后定義。
3)外碼要和所參照的主碼類型相同。表級完整性約束的時候屬性列需要加括號。
二、修改表
增加列
alter table student add graduation date;
/*
1. 指定要修改的表
2. add關鍵字
3. 新增列的屬性名
4. 新增列的數據類型
*/刪除列
alter table student drop column graduation;修改列的數據類型
alter table student alter column graduation varchar(20); 增加約束
/*這種增加約束的方法不容易從左邊的框框(鍵)中看出來*/
alter table student add unique(graduation);/*給增加的約束自定義了一個別名,容易區分*/
alter table student add constraint S_un unique(graduation);/*注意*/
--1. 不可以使用增加not null約束,想要添加只可以在設計中將勾去掉
--雖然以下的方式看似添加了not null約束,但是不起任何作用
alter table student add constraint cc check(sname is not null);--2. 給某一屬性列添加主鍵,需要保證該屬性列不允許為空,剛建的新表在未加約束的情況下,默認屬性列允許為空值
alter table student add primary key(sno,cno);--3. 添加外鍵,需要保證外碼和被參照表的主屬性的數據類型保持一致
alter table student add foreign key (sno) references student(sno);刪除約束
/*通過指定的約束名字刪除指定的約束*/
alter table student drop constraint S_un;/*在左邊單機右鍵刪除*/三、刪除表
/*刪除表的時候必須先將參照表干掉,再刪除被參照表*/
drop table student;索引的建立與刪除
建立索引的目的是加快數據查詢的速度。DBA或者表的屬主可以根據需要建立表的索引;但是有些DBMS可以自動建立以下索引,1)PRIMARY KEY索引(聚簇索引)2)UNIQUE索引(唯一性索引)
一、創建索引
/*創建唯一性索引*/
/** stu為索引名字,創建索引必須要有一個索引名* 列名后面緊跟排序類型,ASC為升序,DESC為降序,默認為ASC,可以有多個列,用逗號隔開。* 對于已經包含重復值的屬性列不可以增加唯一性索引
*/
create unique index S_nn on student(graduation asc);/*創建聚簇索引(聚集)*/
Create clustered index stu on student(sage desc);
/** 聚簇索引的關鍵字為clustered,不是書上有誤,而是sqlserver是這樣* 同樣,列名后面緊跟排序類型,可以有多個列,用逗號隔開。* 聚簇索引嚴格按照物理存儲位置來排序。* 不可以在有主鍵的表中創建索引* 一個表只能創建一個聚簇索引
*/二、刪除索引
/*注意:刪除索引必須為表名+索引名*/
drop index student.stusql查詢


單表查詢
簡單的查詢操作:
--投影,select后邊指明所選的列,from指明所訪問的表
select sno, sname, sdept
from student;--選擇指定的列,可以加算術表達式,并且為其添加新的屬性名
select sno, 2019-sage as birthday
from student;--投影后,修改屬性名
select sno num, 2019-sage birthday
from student;--*代表選中所有列
select *
from student;--除了int,smallint,其余的數據類型需要單引號''
select sname,'2017' year
from student;--字符串的拼接
--5)查詢全體學生的姓名、聯系電話,并在前面加上字符串‘聯系方式’
select sname, '聯系方式'+tel
from student;--select后加函數
--count函數空值不計,重復值重復計
--當count函數作用在全部列上時以元組計數
select COUNT(sno)
from student;--COUNT的含義是計數,*表示所有列,COUNT(*)表示元組數,某個或部分屬性列為空值不影響count統計結果
select COUNT(*)
from student;--去重,distinct作用域是整個元組,是所有指定列組成的元組的去重
select distinct sno, cno
from sc;--查詢性別為女的學生的學號,姓名
select sno, sname
from student
where ssex = '女';--查詢學分為4學分的課程的名字
select cname
from course
where ccredit = 4;--查詢成績在85分以上的學生的學號(學號不重)
select distinct sno
from sc
where grade > 85;--查詢年齡在20~23歲(包括20歲和23歲)之間的學生的姓名、系別和年齡。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;--不能寫成sdept='CS','IS','MA'
select sname,ssex
from student
where sdept='CS' or sdept='IS' or sdept = 'MA';--IS NULL, IS NOT NULL空值:只能用“is”,不能用“=”
--WHERE NOT Sage >= 20;not必須在 sage前邊,而不是>=前邊select sname,ssex
from student
where sdept in ('CS','IS','MA');--模糊查詢
--%任意長度,_單個字符,__表示兩個或兩個以內
--轉義字符\,需要加escape '\'標注
select *
from student
where sname like '劉__';select * --如果字符中本身帶有下劃線,用任意字符當轉義字符
from Course
where Cname like 'DB\_%i_ _' escape '\';order by子句:
--order by子句
--選擇sno列,從sc表中,cno為'3',按成績降序給出
--desc表示降序排列,asc表示升序排列,當缺省的時候表示asc
--在SqlServer中當排序的屬性列中存在空值的時候,升序排列默認空值在元組最先顯示,desc(降序)空值元組在最后顯示
select sno
from sc
where cno = '3'
order by grade desc;--多屬性列排序,首先按ccredit進行升序排列,當ccredit相等的時候,按cpno進行降序排列
select *
from course
order by ccredit, cpno desc;注意:
- 首先將符合where子句的元組篩選出來,然后根據order by子句進行排序。
聚集函數:
--count統計sc表中sno的數目,空值不計,重復值重復計
--distinct關鍵字,在計算式取消重復列中的重復值
select count (distinct sno)
from sc;--統計元組的數目
select count(*)
from sc;--求該列值的總和
select sum (grade)
from sc;--求平均值,結果向下取整
select AVG (grade)
from sc;--求最小
select min (grade)
from sc;--求最大
select max (grade)
from sc;注意:
- 聚集函數全部都忽略空值
- where子句中不能使用聚集函數作為條件表達式,聚集函數只能用在select子句或者group by中的having子句。
- 聚集函數作用的元組是滿足where子句中的條件的元組
group by子句:
--GROUP BY
--在有GROUP BY的語句中,select子句后邊只可以出現分組屬性列或者聚集函數,其他列名不可以,
--平均值計算略過空值
--首先按cno進行分組,分別統計每組中sno的數量和每組中的平均值,最后給每一新列起別名
select cno, count(sno) cnt,AVG (grade) av
from sc
group by cno;--可以使用HAVING短語篩選最終輸出結果,作用于組,從中選擇滿足條件的組
--同上首先通過cno分組,在通過having語句選出滿足指定條件的組
select cno, count(sno) cnt, AVG (grade) av
from sc
group by cno
having COUNT(sno)>=2;--查詢選修了3門以上課程的學生學號
--首先使用group by進行分組,然后使用having選擇滿足條件的組
select sno,COUNT(cno)
from sc
group by sno
having COUNT(cno)>=3注意:
- where子句作用于基表或視圖,從中選擇滿足條件的元組。
- having短語作用于組,從中選擇滿足條件的元組
- 使用group by子句后,select子句的列名列表中只能出現分組屬性和聚集函數
連接查詢
基本概念
-
連接謂詞中的列名稱為連接字段
-
連接條件中的各連接字段類型必須是可比的,但不必是相同的
-
SQL沒有自動去掉重復列的功能
基本操作
--from涉及兩個表,不加連接條件,得到的是廣義的笛卡爾積,select后跟的是最終顯示的列
select student.*,sc.*
from student,sc;--加上連接條件,得到的是從廣義笛卡爾積中選擇滿足指定條件的元組
--select后跟的是最終所顯示的列,對于兩個表公共的屬性列需要使用表名進行區分,不屬于公共列的不需要
--SqlServer沒有自動去掉重復列的功能
select student.*,cno,grade --去掉重復列
from student,sc
where student.sno=sc.sno; --連接條件:不然是廣義笛卡爾積--或者--
select sc.sno,sname,sage,ssex,sdept,cno,grade --去掉重復列
from student,sc
where student.sno=sc.sno;一種可能的執行過程:
1)首先在表1中找到第一個元組,然后從頭開始掃描表2,逐一查找滿足連接條件的元組,找到后就將表1中的第一個元組與該元組拼接起來,形成結果表中一個元組 。
2)表2全部查找完后,再找表1中第二個元組,然后再從頭開始掃描表2,逐一查找滿足連接條件的元組,找到后就將表1中的第二個元組與該元組拼接起來,形成結果表中一個元組。
3)重復上述操作,直到表1中的全部元組都處理完畢。
自身連接
select first.cno, second.cpno
from course first, course second
where first.cpno = second.cno;注意:
- 由于兩張表的所有屬性列的名字相同,所以需要起別名進行加以區分。
- 上述代碼表示將第一張自己表和第二張自己表做廣義笛卡爾積,然后選擇第一張自己表的cpno等于第二張自己的cno的元組對應的屬性列。
外連接
--外連接
select sc.sno,sname,sage,ssex,sdept,cno,grade
from student full outer join sc
on student.sno = sc.sno;--左外連接
select sc.sno,sname,sage,ssex,sdept,cno,grade
from student left outer join sc
on student.sno = sc.sno;--右外連接
select sc.sno,sname,sage,ssex,sdept,cno,grade
from student right outer join sc
on student.sno = sc.sno;注意:
- 原先的條件where變為on
- 表名后的外連接操作符指明了主體表。
嵌套查詢
基本概念
查詢塊:一個select-from-where語句
嵌套查詢:將一個查詢塊嵌套在另一個查詢塊的where子句或having短語的條件中的查詢
子查詢不能使用order by子句,因為嵌套查詢返回的是一個集合或者布爾值,排序沒有任何意義,所以規定不能使用order by語句(胡扯)
一些嵌套查詢可以使用連接查詢代替,但是一些不可以。
不相關子查詢:子查詢的查詢條件不依賴于父查詢
相關子查詢:子查詢的查詢條件依賴于父查詢
不相關子查詢的可能執行過程:由里向外逐層處理。即每個子查詢在上一級查詢處理之前求解,子查詢的結果用于建立其父查詢的查找條件。
相關子查詢可能的執行過程:1)首先取外層查詢中表的第一個元組,根據它與內層查詢相關的屬性值處理內層查詢,若where子句返回值為真,則取此元組放入結果表;2)然后再取外層表的下一個元組;3)重復這一過程,直至外層表全部檢查完為止。
帶有IN謂詞的子查詢
一個典型的例子:
該查詢為不相關子查詢,即查詢過稱為,1)在course表中查找出信息系統的課程號;2)根據查找出的課程號,在sc表中查詢出該學生的學號;3)根據查詢到的學號,在student表中查詢出相應學生的姓名。
帶有比較運算符的子查詢
適用條件:當能確切知道內層查詢返回單值時,可用比較運算符(>,<,=,>=,<=,!=或< >)
例如:
找出每個學生超過他選修課程平均成績的課程號。
SELECT Sno, CnoFROM SC xWHERE Grade >=(SELECT AVG(Grade) FROM SC yWHERE y.Sno = x.Sno);查詢過程:
該例為一個相關子查詢。
帶有any或者all謂詞的子查詢
聲明:
any:表示任意一個就行,> any表示大于任意一個就可以
all:表示所有,> all表示需要大于所有的值
常見的謂詞解釋:

?
?
帶有EXISTS謂詞的子查詢:
介紹:
存在量詞
exists
1)不返回任何數據,只返回true或者false。當內層的查詢非空時返回true,當內層的查詢為空時返回false。
2)由EXISTS引出的子查詢,其目標列表達式通常都用*,因為帶EXISTS的子查詢只返回真值或假值,給出列名無實際意義(還是胡扯)
not exists
1)若內層查詢結果非空,則外層的WHERE子句返回假值
2)若內層查詢結果為空,則外層的WHERE子句返回真值
例子:
exists的例子:

?
not exists的例子:
難點1:使用exists/not exists實現全稱量詞
1)查詢選修了全部課程的學生姓名
--說法轉換:即對于某個學生來說,沒有哪一門課程,使自己沒有選的
select sname
from student
where not exists(select *from coursewhere not exists(select s*from scwhere student.sno = sno and cno = course.cno));解釋:
(1)對于第一個not exists里邊查詢的是當前student是否有未選修的課程,如果當前學生有未選修的課程,經過not exists返回false,即該學生的信息不會被記錄。
(2)對于第二個not exists里邊查詢的是當前學生對象,對于當前的課程,如果選了該門課程,not exists里邊為真,經過not exists返回false,該門課程不會被記錄,反之,如果該學生未選該門課程,該門課程將會被記錄。
(3)有一點像雙重for循環,依次遍歷所有的student中的元組,在每一個student的情況下,在遍歷course,最后在一個not exists中的where子句中進行判斷。
難點2:使用exists/not exists實現邏輯蘊涵
2)查詢至少選修了學生201215122選修的全部課程的學生號碼。
SELECT DISTINCT Sno
FROM SC SCX
WHERE NOT EXISTS(SELECT *FROM SC SCYWHERE SCY.Sno = '201215122' ANDNOT EXISTS(SELECT *FROM SC SCZWHERE SCZ.Sno=SCX.Sno AND SCZ.Cno=SCY.Cno));解釋:
(1)基本同上
集合查詢
并操作:
查詢計算機科學系的學生及年齡不大于19歲的學生。
/*使用UNION取并集*/
SELECT *
FROM Student
WHERE Sdept= 'CS'
UNION
SELECT *
FROM Student
WHERE Sage<=19;交操作:
查詢計算機科學系的學生與年齡不大于19歲的學生的交集(INTERSECT)。
/*使用INTERSECT實現交操作*/
SELECT *
FROM Student
WHERE Sdept='CS'
INTERSECT
SELECT *
FROM Student
WHERE Sage<=19;差操作:
查詢計算機科學系的學生與年齡不大于19歲的學生的差集。
/*使用EXCEPT實現差操作*/
SELECT *
FROM Student
WHERE Sdept='CS'
EXCEPT
SELECT *
FROM Student
WHERE Sage <=19; sql增刪改
數據的插入
插入元祖
--1. 表名后沒有指定屬性列:表示要插入的是一條完整的元組,且屬性列屬性與表定義中的順序一致
insert into student
values ('201215128', '陳東', '18', '男', 'IS');--2. 在表明后指定要插入數據的表名及屬性列,屬性列的順序可與表定義中的順序不一致
insert into student(sno, sname, sage, ssex, sdept)
values ('201215138', '陳東棟', '18', '男', 'CS');--3. 插入部分列,未顯示給出的列按空值計算,當然前提條件是那些列可以為空值
insert into student(sno, sname)
values ('201215148', '陳棟');2. 插入一個子查詢的結果
--子查詢的結果必須包含和insert的字段列表一樣多的字段,并且數據類型兼容
insert into depavgselect sdept,AVG(sage) avgagefrom studentgroup by sdept;3.5.2 數據的修改
--1. 修改某些符合where子句中的條件的元組的值
update student
set sage = 92
where sno = '200215121';--2. where子句缺省,默認修改所有元組的該屬性的值
--注意:在修改數據的時候應當先寫where子句中的條件
update student
set sage = 92;--3. 帶子查詢的修改
update sc
set grade = 100
where 'CS' in (select sdeptfrom studentwhere sc.sno = student.sno
);--set子句中遇到null只能用等號,where子句中只能用is null
update student
set sage = null
where sno = '201811012';注意:
DBMS在執行修改語句時會檢查修改操作是否破壞表上已定義的完整性規則。
- 實體完整性:保證主碼不能被修改
- 用戶自定義完整性:not null約束,unique約束,值域約束等。
3.5.3 數據的刪除
--1. 刪除符合where子句中條件的某些行
delete
from student
where sno = '201215148';--2. 帶子查詢的刪除
delete
from sc
where 'CS' in (select sdeptfrom studentwhere sc.sno = student.sno
);--3. 刪除所有行
delete
from student;注意:
同數據更新,結果很危險,操作需謹慎。
?mysql常用函數總結
文本處理函數
Left(x,len) – 返回串左邊的字符(長度為len)
Right(x,len)
Length(x) – 返回串的長度
Locate(x,sub_x) – 找出串的一個子串
SubString(x, from, to) – 返回字串的字符
Lower(x)
Upper(x)
LTrim(x)
RTrim(x)
Soundex(x) – 讀音(用于發音匹配)
SELECT cust_name, cust_contact FROM customers WHERE Soundex(cust_contact) = Soundex(‘Y Lie’);
日期和時間處理函數
日期和時間采用相應的數據類型和特殊的格式存儲,以便可以快速和有效的排序或過濾,節省物理存儲空間.
一般,應用程序不使用用來存儲日期和時間的格式,因此日期和時間函數總是被用來讀取、統計和處理這些函數.
常用日期和時間處理函數:
AddDate() – 增加一個日期(天,周等)
AddTime() – 增加一個時間(時,分等)
CurDate() – 返回當前日期
CurTime() – 返回當前時間
Date() – 返回日期時間的日期部分
DateDiff() – 計算兩個日期之差
Date_Add() – 日期運算函數
Date_Format() – 返回一個格式化的日期或時間串
Day() – 返回一個日期的天數部分
DayOfWeek() – 返回日期對應的星期幾
Hour() – 返回一個時間的小時部分
Minute() – 返回一個時間的分鐘部分
Second() – 返回一個時間的秒部分
Month() – 返回一個日期的月部分
Now() – 返回當前日期和時間
Time() – 返回一個日期時間的時間部分
Year() – 返回一個日期的年份部分
日期首選格式: yyyy-mm-dd; 如2005-09-01
檢索某日期下的數據:
SELECT cust_id, order_num FROM orders WHERE Date(order_date) = ‘2005-09-01’;
檢索某月或日期范圍內的數據:
SELECT cust_id, order_num FROM orders WHERE Year(order_date) = 2005 AND Month(order_date) = 9;
– or
SELECT cust_id, order_num FROM orders WHERE date(order_date) BETWEEN ‘2005-09-01’ AND ‘2005-09-30’;
數值處理函數
代數、三角函數、幾何運算等
常用數值處理函數:
abs(); cos(); exp(); mod()(取余); Pi(); Rand(); Sin(); Sqrt(); Tan();
?
視圖/存儲過程/觸發器
視圖
視圖是虛擬的表,與包含數據的表不同,視圖只包含使用時動態檢索數據的查詢,主要是用于查詢。
為什么使用視圖
- 重用sql語句
- 簡化復雜的sql操作,在編寫查詢后,可以方便地重用它而不必知道他的基本查詢細節。
- 使用表的組成部分而不是整個表。
- 保護數據。可以給用戶授予表的特定部分的訪問權限而不是整個表的訪問權限。
- 更改數據格式和表示。視圖可返回與底層表的表示和格式不同的數據。
注意:
- 在視圖創建之后,可以用與表基本相同的方式利用它們。可以對視圖執行select操作,過濾和排序數據,將視圖聯結到其他視圖或表,甚至能添加和更新數據。
- 重要的是知道視圖僅僅是用來查看存儲在別處的數據的一種設施。視圖本身不包含數據,因此它們返回的數據時從其他表中檢索出來的。在添加和更改這些表中的數據時,視圖將返回改變過的數據。
- 因為視圖不包含數據,所以每次使用視圖時,都必須處理查詢執行時所需的任一檢索。如果你使用多個聯結和過濾創建了復雜的視圖或者嵌套了視圖,可能會發現性能下降得很厲害。因此,在部署使用了大量視圖的應用前,應該進行測試。
視圖的規則和限制
- 與表一樣,視圖必須唯一命名;
- 可以創建任意多的視圖;
- 為了創建視圖,必須具有足夠的訪問權限。這些限制通常由數據庫管理人員授予。
- 視圖可以嵌套,可以利用從其他視圖中檢索數據的查詢來構造一個視圖。
- Order by 可以在視圖中使用,但如果從該視圖檢索數據select中也是含有order by,那么該視圖的order by 將被覆蓋。
- 視圖不能索引,也不能有關聯的觸發器或默認值
- 視圖可以和表一起使用
視圖的創建
- 利用create view 語句來進行創建視圖
- 使用show create view viewname;來查看創建視圖的語句
- 用drop view viewname 來刪除視圖
- 更新視圖可以先drop在create,也可以使用create or replace view。
視圖的更新
視圖是否可以更新,要視情況而定。
通常情況下視圖是可以更新的,可以對他們進行insert,update和delete。更新視圖就是更新其基表(視圖本身沒有數據)。如果你對視圖進行增加或者刪除行,實際上就是對基表進行增加或者刪除行。
但是,如果MySQL不能正確的確定更新的基表數據,則不允許更新(包括插入和刪除),這就意味著視圖中如果存在以下操作則不能對視圖進行更新:(1)分組(使用group by 和 having );(2)聯結;(3)子查詢;(4)并;(5)聚集函數;(6)dictinct;(7)導出(計算)列。
?
存儲過程
存儲過程就是為了以后的使用而保存的一條或者多條MySQL語句的集合。可將視為批文件,雖然他們的作用不僅限于批處理。
為什么使用儲存過程?
1.通過把處理封裝在容易使用的單元中,簡化復雜的操作;
?
2.由于不要求反復建立一系列處理步驟,保證了數據的完整性。如果所有開發人員和應用程序都使用同一(實驗和測試)存儲過程,則所使用的代碼都是相同的。這一點的延伸就是防止錯誤。需要執行的步驟越多,出錯的可能性就越大,防止錯誤保證了數據的一致性。
?
3.簡化對變動的管理,如果表名。列名或者業務邏輯等有變化,只需要更改存儲過程的代碼。使用它的人員甚至不需要知道這些變化。這一點延伸就是安全性,通過存儲過程限制對基數據的訪問減少了數據訛誤的機會。
?
4.提高性能。因為使用存儲過程比使用單獨的sql語句更快。
?
5.存在一些只能用在單個請求的MySQL元素和特性,存儲過程可以使用他們來編寫功能更強更靈活的代碼
?
綜上:
三個主要的好處:簡單、安全、高性能。
兩個缺陷:
1、存儲過程的編寫更為復雜,需要更高的技能更豐富的經驗。
2、可能沒有創建存儲過程的安全訪問權限。許多數據庫管理員限制存儲過程的 創建權限,允許使用,不允許創建。
執行存儲過程
Call關鍵字:Call接受存儲過程的名字以及需要傳遞給他的任意參數。存儲過程可以顯示結果,也可以不顯示結果。
CREATE PROCEDURE productpricing()
??? BEGIN
??????? SELECT? AVG( prod_price)? as priceaverage FROM products;
??? END;
創建名為productpricing的儲存過程。如果存儲過程中需要傳遞參數,則將他們在括號中列舉出來即可。括號必須有。BEGIN和END關鍵字用來限制存儲過程體。上述存儲過程體本身是一個簡單的select語句。注意這里只是創建存儲過程并沒有進行調用。
?
儲存過程的使用:
?
Call productpring();
?
使用參數的存儲過程
一般存儲過程并不顯示結果,而是把結果返回給你指定的變量上。
變量:內存中一個特定的位置,用來臨時存儲數據。
MySQL> CREATE PROCEDURE prod(out pl decimal(8,2),out ph decimal(8,2),out pa decimal(8,2))
beginselect Min(prod_price) into pl from products;select MAx(prod_price) into ph from products;select avg(prod_price) into pa from products;end;call PROCEDURE(@pricelow,@pricehigh,@priceaverage);select @pricelow;select @pricehigh;select @pricelow,@pricehigh,@priceaverage;?
解釋:
此存儲過程接受3個參數,pl存儲產品最低價,ph存儲產品最高價,pa存儲產品平均價。每個參數必須指定類型,使用的為十進制,關鍵字OUT 指出相應的參數用來從存儲過程傳出一個值(返回給調用者)。
?
MySQL支持in(傳遞給存儲過程)、out(從存儲過程傳出,這里所用)和inout(對存儲過程傳入和傳出)類型的參數。存儲過程的代碼位于begin和end語句內。他們是一系列select語句,用來檢索值。然后保存到相對應的變量(通過INTO關鍵字)。
存儲過程的參數允許的數據類型與表中使用的類型相同。注意記錄集是不被允許的類型,因此,不能通過一個參數返回多個行和列,這也是上面為什么要使用3個參數和3條select語句的原因。
?
調用:為調用此存儲過程,必須指定3個變量名。如上所示。3個參數是存儲過程保存結果的3個變量的名字。調用時,語句并不顯示任何數據,它返回以后可以顯示的變量(或在其他處理中使用)。
?
注意:所有的MySQL變量都是以@開頭。
CREATE PROCEDURE ordertotal(IN innumber int,OUT outtotal decimal(8,2))BEGINSELECT Sum(item_price * quantity) FROM orderitems WHERE order_num = innumber INTO outtotal;end??? //CALL ordertotal(20005,@total);select @total;? // 得到20005訂單的合計CALL ordertotal(20009,@total);select @total; //得到20009訂單的合計?
帶有控制語句的存儲過程
??
CREATE PROCEDURE ordertotal(IN onumber INT,IN taxable BOOLEAN,OUT ototal DECIMAL(8,2))COMMENT 'Obtain order total, optionally adding tax'BEGIN-- declear variable for totalDECLARE total DECIMAL(8,2);-- declear tax percentageDECLARE taxrate INT DEFAULT 6;-- get the order totalSELECT Sum(item_price * quantity) FROM orderitems WHERE order_num = onumber INTO total;-- IS this taxable?IF taxable THEN-- yes ,so add taxrate to the totalSELECT total+(total/100*taxrate)INTO total;END IF;-- finally ,save to out variableSELECT total INTO ototal;END;在存儲過程中我們使用了DECLARE語句,他們表示定義兩個局部變量,DECLARE要求指定變量名和數據類型。它也支持可選的默認值(taxrate默認6%),因為后期我們還要判斷要不要增加稅,所以,我們把SELECT查詢的結果存儲到局部變量total中,然后在IF 和THEN的配合下,檢查taxable是否為真,然后在真的情況下,我們利用另一條SELECT語句增加營業稅到局部變量total中,然后我們再利用SELECT語句將total(增加稅或者不增加稅的結果)保存到總的ototal中。
COMMENT關鍵字 上面的COMMENT是可以給出或者不給出,如果給出,將在SHOW PROCEDURE STATUS的結果中顯示。
?
觸發器
在某個表發生更改時自動處理某些語句,這就是觸發器。
?
觸發器是MySQL響應delete 、update 、insert 、位于begin 和end語句之間的一組語句而自動執行的一條MySQL語句。其他的語句不支持觸發器。
創建觸發器
在創建觸發器時,需要給出4條語句(規則):
1.? 唯一的觸發器名;
2.? 觸發器關聯的表;
3.? 觸發器應該響應的活動;
4.? 觸發器何時執行(處理之前或者之后)
?
Create trigger 語句創建 觸發器
CREATE TRIGGER newproduct AFTER INSERT ON products FOR EACH ROW SELECT 'Product added' INTO @info;
CREATE TRIGGER用來創建名為newproduct的新觸發器。觸發器可以在一個操作發生前或者發生后執行,這里AFTER INSERT 是指此觸發器在INSERT語句成功執行后執行。這個觸發器還指定FOR EACH ROW , 因此代碼對每個插入行都會執行。文本Product added 將對每個插入的行顯示一次。
?
注意:
1、觸發器只有表才支持,視圖,臨時表都不支持觸發器。
2、觸發器是按照每個表每個事件每次地定義,每個表每個事件每次只允許一個觸發器,因此,每個表最多支持六個觸發器(insert,update,delete的before 和after)。
3、單一觸發器不能與多個事件或多個表關聯,所以,你需要一個對insert和update 操作執行的觸發器,則應該定義兩個觸發器。
4、觸發器失敗:如果before 觸發器失敗,則MySQL將不執行請求的操作,此外,如果before觸發器或者語句本身失敗,MySQL則將不執行after觸發器。
觸發器類別
INSERT觸發器
是在insert語句執行之前或者執行之后被執行的觸發器。
1、在insert觸發器代碼中,可引入一個名為new的虛擬表,訪問被插入的行;
2、在before insert觸發器中,new中的值也可以被更新(允許更改被插入的值);
3、對于auto_increment列,new在insert執行之前包含0,在insert執行之后包含新的自動生成值
CREATE TRIGGER neworder AFTER INSERT ON orders FOR EACH ROW SELECT NEW.order_num;
創建一個名為neworder的觸發器,按照AFTER INSERT ON orders 執行。在插入一個新訂單到orders表時,MySQL生成一個新的訂單號并保存到order_num中。觸發器從NEW.order_num取得這個值并返回它。此觸發器必須按照AFTER INSERT執行,因為在BEFORE INSERT語句執行之前,新order_num還沒有生成。對于orders的每次插入使用這個觸發器總是返回新的訂單號。
DELETE觸發器
Delete觸發器在delete語句執行之前或者之后執行。
1、在delete觸發器的代碼內,可以引用一個名為OLD的虛擬表,用來訪問被刪除的行。
2、OLD中的值全為只讀,不能更新。
CREATE TRIGGER deleteorder BEFORE DELETE ON orders FOR EACH ROWBEGININSERT INTO archive_orders(order_num,order_date,cust_id) values (OLD.order_num,OLD.order_date,OLD.cust_id);END;----------------------------------------------------------------CREATE TABLE archive_orders(order_num int(11) NOT NULL AUTO_INCREMENT,order_date datetime NOT NULL,cust_id int(11) NOT NULL,PRIMARY KEY (order_num),KEY fk_orders1_customers1 (cust_id),CONSTRAINT fk_orders1_customers1 FOREIGN KEY (cust_id) REFERENCES customers(cust_id)) ENGINE=InnoDB AUTO_INCREMENT=20011 DEFAULT CHARSET=utf8在任意訂單被刪除前將執行此觸發器,它使用一條INSERT 語句將OLD中的值(要被刪除的訂單) 保存到一個名為archive_orders的存檔表中(為實際使用這個例子,我們需要用與orders相同的列創建一個名為archive_orders的表)
?
使用BEFORE DELETE觸發器的優點(相對于AFTER DELETE觸發器來說)為,如果由于某種原因,訂單不能存檔,delete本身將被放棄。
?
我們在這個觸發器使用了BEGIN和END語句標記觸發器體。這在此例子中并不是必須的,只是為了說明使用BEGIN END 塊的好處是觸發器能夠容納多條SQL 語句(在BEGIN END塊中一條挨著一條)。
UPDATE觸發器
在update語句執行之前或者之后執行
1、在update觸發器的代碼內,可以引用一個名為OLD的虛擬表,用來訪問以前(UPDATE語句之前)的值,引用一個名為NEW的虛擬表訪問新更新的值。
2、在BEFORE UPDATE觸發器中,NEW中的值可能也被用于更新(允許更改將要用于UPDATE語句中的值)
3、OLD中的值全為只讀,不能更新。
CREATE TRIGGER updatevendor BEFORE UPDATE ON vendors FOR EACH ROW SET NEW.vend_state = Upper(NEW.vemd_state);
保證州名縮寫總是大寫(不管UPFATE語句中是否給出了大寫),每次更新一行時,NEW.vend_state中的值(將用來更新表行的值)都用Upper(NEW.vend_state)替換。
總結
1、通常before用于數據的驗證和凈化(為了保證插入表中的數據確實是需要的數據) 也適用于update觸發器。
2、與其他DBMS相比,MySQL 5中支持的觸發器相當初級,未來的MySQL版本中估計會存在一些改進和增強觸發器的支持。
3、創建觸發器可能需要特殊的安全訪問權限,但是觸發器的執行時自動的,如果insert,update,或者delete語句能夠執行,則相關的觸發器也能執行。
4、用觸發器來保證數據的一致性(大小寫,格式等)。在觸發器中執行這種類型的處理的優點就是它總是進行這種處理,而且透明的進行,與客戶機應用無關。
5、觸發器的一種非常有意義的使用就是創建審計跟蹤。使用觸發器,把更改(如果需要,甚至還有之前和之后的狀態)記錄到另外一個表是非常容易的。
6、MySQL觸發器不支持call語句,無法從觸發器內調用存儲過程。
?
數據庫恢復
實現技術
?
- 恢復操作的基本原理:冗余?
- 恢復機制涉及的兩個關鍵問題
- 如何建立冗余數據
- 數據轉儲(backup)
- 登錄日志文件(logging)
- ?如何利用這些冗余數據實施數據庫恢復
?
數據轉儲
?
- 數據轉儲定義:
轉儲是指DBA將整個數據庫復制到其他存儲介質上保存起來的過程,備用的數據稱為后備副本或后援副本
- 如何使用
- 數據庫遭到破壞后可以將后備副本重新裝入
- 重裝后備副本只能將數據庫恢復到轉儲時的狀態
- 轉儲方法
- 靜態轉儲與動態轉儲
- 海量轉儲與增量轉儲
靜態轉儲:
1)定義:在系統中無事務運行時進行的轉儲操作。轉儲開始的時刻數據庫處于一? 致性狀態,而轉儲不允許對數據庫的任何存取、修改活動。靜態轉儲得到的一定是一個數據一致性的副本。
2)優點:實現簡單
3)缺點:降低了數據庫的可用性
轉儲必須等待正運行的用戶事務結束才能進行;新的事務必須等待轉儲結束才能執行
動態轉儲:
???????? ?? 1)定義:轉儲期間允許對數據庫進行存取或修改。轉儲和用戶事務可以并發執行。
???????? ?? 2)優點:不用等待正在運行的用戶事務結束;不會影響新事務的運行。
???????? ?? 3)實現:必須把轉儲期間各事務對數據庫的修改活動登記下來,建立日志文件后備副本加上日志文件就能把數據庫恢復到某一時刻的正確狀態。
海量轉儲:
???????? ?? 1)定義:每次轉儲全部數據庫
???????? ?? 2)特點:從恢復角度,使用海量轉儲得到的后備副本進行恢復更方便一些。
增量轉儲:
???????? ?? 1)定義:每次只轉儲上一次轉儲后更新過的數據
???????? ?? 2)特點:如果數據庫很大,事務處理又十分頻繁,則增量轉儲方式更實用更有效。

?
日志文件
?
1、什么是日志文件
日志文件(log)是用來記錄事務對數據庫的更新操作的文件
2、日志文件的格式
1)以記錄為單位:
日志文件中需要登記的內容包括:
-
- 各個事務的開始標記(BEGIN TRANSACTION)
- 各個事務的結束標記(COMMIT或ROLLBACK)
- 各個事務的所有更新操作
???? 以上均作為日志文件中的一個日志記錄???????????????????
每個日志記錄的內容:
- 事務標識(標明是哪個事務)
- 操作類型(插入、刪除或修改)
- 操作對象(記錄內部標識)
- 更新前數據的舊值(對插入操作而言,此項為空值)
- 更新后數據的新值(對刪除操作而言, 此項為空值)
?
2)以數據塊為單位
日志記錄內容包括:
事務標識(標明是哪個事務)
?被更新的數據塊
3、日志文件的作用
- 進行事務故障恢復
- 進行系統故障恢復
- 協助后備副本進行介質故障恢復
1)事務故障恢復和系統故障恢復必須用日志文件
2)在動態轉儲方式中必須建立日志文件,后備副本和日志文件結合起來才能有效地恢復數據庫
3)靜態轉儲方式中也可以建立日志文件(重新裝入后備副本,然后利用日志文件把已完成的事務進行重做,對未完成事務進行撤銷)

4、登記日志文件:
- 基本原則
- 登記的次序嚴格按并行事務執行的時間次序
- 必須先寫日志文件,后寫數據庫
為什么要先寫日志文件?
1)寫數據庫和寫日志文件是兩個不同的操作,在這兩個操作之間可能發生故障
2)如果先寫了數據庫修改,而在日志文件中沒有登記下這個修改,則以后就無法恢復這個修改了
3)如果先寫日志,但沒有修改數據庫,按日志文件恢復時只不過是多執行一次不必要的UNDO操作,并不會影響數據庫的正確性
?
恢復策略
?
事務故障的恢復
- 事務故障:事務在運行至正常終止點前被終止
- 恢復方法
- 由恢復子系統應利用日志文件撤消(UNDO)此事務已對數據庫進行的修改
- 事務故障的恢復由系統自動完成,對用戶是透明的,不需要用戶干預
- 事務故障的恢復步驟
1. 反向掃描文件日志,查找該事務的更新操作。
2. 對該事務的更新操作執行逆操作。即將日志記錄中“更新前的值” 寫入數據庫。
?
- ?插入操作, “更新前的值”為空,則相當于做刪除操作
- ?刪除操作,“更新后的值”為空,則相當于做插入操作
- ?若是修改操作,則相當于用修改前值代替修改后值
3. 繼續反向掃描日志文件,查找該事務的其他更新操作,并做同樣處理。
4. 如此處理下去,直至讀到此事務的開始標記,事務故障恢復就完成了。
系統故障的恢復
- 系統故障造成數據庫不一致狀態的原因
- 未完成事務對數據庫的更新已寫入數據庫
- 已提交事務對數據庫的更新還留在緩沖區沒來得及寫入數據庫
- 恢復方法
- Undo 故障發生時未完成的事務
- Redo 已完成的事務
- 系統故障的恢復由系統在重新啟動時自動完成,不需要用戶干預
- 系統故障的恢復步驟
1. 正向掃描日志文件
-
-
- 重做(REDO) 隊列: 在故障發生前已經提交的事務
- 這些事務既有BEGIN TRANSACTION記錄,也有COMMIT記錄
- 撤銷 (Undo)隊列: 故障發生時尚未完成的事務
- ?這些事務只有BEGIN TRANSACTION記錄,無相應的COMMIT記錄
- 重做(REDO) 隊列: 在故障發生前已經提交的事務
-
2. 對撤銷(Undo)隊列事務進行撤銷(UNDO)處理
-
-
- 反向掃描日志文件,對每個UNDO事務的更新操作執行逆操作
-
3. 對重做(Redo)隊列事務進行重做(REDO)處理
-
-
- 正向掃描日志文件,對每個REDO事務重新執行登記的操作
-
介質故障的恢復
恢復步驟
重裝數據庫
- 裝入最新的后備副本,使數據庫恢復到最近一次轉儲時的一致性狀態。
- 對于靜態轉儲的數據庫副本,裝入后數據庫即處于一致性狀態
- 對于動態轉儲的數據庫副本,還須同時裝入轉儲時刻的日志文件副本,利用恢復系統故障的方法(即REDO+UNDO),才能將數據庫恢復到一致性狀態。
?裝入有關的日志文件副本,重做已完成的事務。
- 首先掃描日志文件,找出故障發生時已提交的事務的標識,將其記入重做隊列。
- 然后正向掃描日志文件,對重做隊列中的所有事務進行重做處理。
- 介質故障的恢復需要DBA介入
- DBA的工作
- 重裝最近轉儲的數據庫副本和有關的各日志文件副本
- 執行系統提供的恢復命令,具體的恢復操作仍由DBMS完成
檢查點
- 利用日志技術進行數據庫恢復存在兩個問題
- 搜索整個日志將耗費大量的時間
- REDO處理:事務實際上已經執行,又重新執行,浪費了大量時間
- 具有檢查點(checkpoint)的恢復技術
- 在日志文件中增加檢查點記錄(checkpoint)
- 增加重新開始文件,并讓恢復子系統在登錄日志文件期間動態地維護日志
- 檢查點記錄的內容
- 建立檢查點時刻所有正在執行的事務清單
- 這些事務最近一個日志記錄的地址
- 重新開始文件的內容
- 記錄各個檢查點記錄在日志文件中的地址
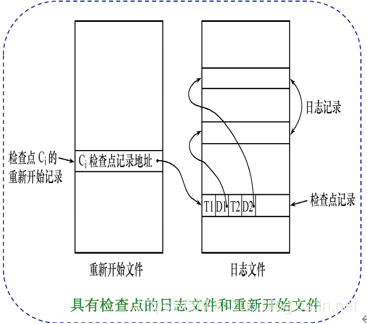
- 動態維護日志文件的方法
周期性地執行如下操作:建立檢查點,保存數據庫狀態。
具體步驟是:
1.將當前日志緩沖區中的所有日志記錄寫入磁盤的日志文件上
2.在日志文件中寫入一個檢查點記錄
3.將當前數據緩沖區的所有數據記錄寫入磁盤的數據庫中
4.把檢查點記錄在日志文件中的地址寫入一個重新開始文件
?
使用檢查點方法可以改善恢復效率
當事務T在一個檢查點之前提交:
- T對數據庫所做的修改一定都已寫入數據庫
- 寫入時間是在這個檢查點建立之前或在這個檢查點建立之時
- 在進行恢復處理時,沒有必要對事務T執行REDO操作
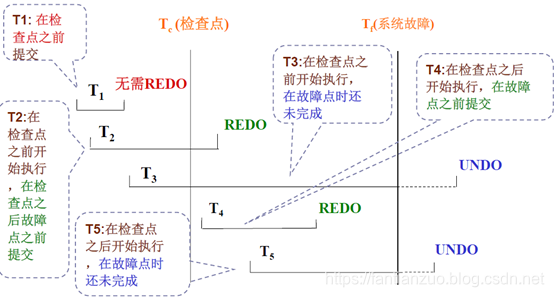
使用檢查點的恢復步驟
?1.從重新開始文件中找到最后一個檢查點記錄在日志文件中的地址,由該地址在日志文件中找到最后一個檢查點記錄
?2.由該檢查點記錄得到檢查點建立時刻所有正在執行的事務清單ACTIVE-LIST
- 建立兩個事務隊列
- UNDO-LIST
- REDO-LIST
- 把ACTIVE-LIST暫時放入UNDO-LIST隊列,REDO隊列暫為空
?3.從檢查點開始正向掃描日志文件,直到日志文件結束
- 如有新開始的事務Ti,把Ti暫時放入UNDO-LIST隊列
- 如有提交的事務Tj,把Tj從UNDO-LIST隊列移到REDO-LIST隊列
4.對UNDO-LIST中的每個事務執行UNDO操作
? ??????????????? 對REDO-LIST中的每個事務執行REDO操作
?
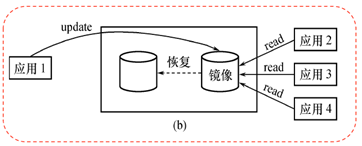
鏡像
?
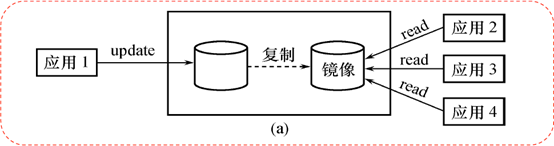
為避免硬盤介質出現故障影響數據庫的可用性,許多DBMS提供了數據庫映像(mirror)功能用于數據庫恢復。
將整個數據庫或其中的關鍵數據復制到另一個磁盤上,每當主數據庫更新時,DBMS自動把更新后的數據復制過去,由DBMS自動保證鏡像數據與主數據庫的一致性。一旦出現介質故障,可由鏡像磁盤繼續提供使用,同時DBMS自動利用磁盤數據進行數據庫的恢復,不需要關閉系統和重裝數據庫副本。
在沒有出現故障時,數據庫鏡像還可以用于并發操作,即當一個用戶對數據庫加排它鎖修改數據時,其他用戶可以讀鏡像數據庫上的數據,而不必等待該用戶釋放鎖。
由于數據庫鏡像是通過復制數據實現的,頻繁地賦值數據自然會降低系統運行效率。因此在實際應用中用戶往往只選擇對關鍵數據和日志文件進行鏡像。
?
?
?
小結:
?
- 如果數據庫只包含成功事務提交的結果,就說數據庫處于一致性狀態。保證數據一致性是對數據庫的最基本的要求。
- 事務是數據庫的邏輯工作單位
- DBMS保證系統中一切事務的原子性、一致性、隔離性和持續性
- DBMS必須對事務故障、系統故障和介質故障進行恢復
- 恢復中最經常使用的技術:數據庫轉儲和登記日志文件
- 恢復的基本原理:利用存儲在后備副本、日志文件和數據庫鏡像中的冗余數據來重建數據庫
常用恢復技術
?
事務故障的恢復
- UNDO
系統故障的恢復
- UNDO + REDO
介質故障的恢復
- 重裝備份并恢復到一致性狀態 + REDO
?
提高恢復效率的技術
檢查點技術
- 可以提高系統故障的恢復效率??
- 可以在一定程度上提高利用動態轉儲備份進行介質故障恢復的效率
鏡像技術
- 鏡像技術可以改善介質故障的恢復效率
并發控制
多用戶數據庫:允許多個用戶同時使用的數據庫(訂票系統)
不同的多事務執行方式:
???????? 1.串行執行:每個時刻只有一個事務運行,其他事務必須等到這個事務結束后方能運行。
???????? 2.交叉并發方式:
單處理機系統中,事務的并發執行實際上是這些并行事務的并行操作輪流交叉運行(不是真正的并發,但是提高了系統效率)
3.同時并發方式:
多處理機系統中,每個處理機可以運行一個事務,多個處理機可以同時運行多個事務,實現多個事務真正的并行運行
并發執行帶來的問題:
???????? 多個事務同時存取同一數據(共享資源)
???????? 存取不正確的數據,破壞事務一致性和數據庫一致性
概述
并發操作帶來的數據不一致性包括
???????? 1)丟失修改(lost update)
???????? 2)不可重復讀(non-repeatable read)
???????? 3)讀臟數據(dirty read)
記號:W(x)寫數據x?????????? R(x)讀數據x
?
并發控制機制的任務:
???????? 1)對并發操作進行正確的調度
???????? 2)保證事務的隔離性
???????? 3)保證數據庫的一致性
并發控制的主要技術
???????? 1)封鎖(locking)(主要使用的)
???????? 2)時間戳(timestamp)
???????? 3)樂觀控制法(optimistic scheduler)
???????? 4)多版本并發控制(multi-version concurrency control ,MVCC)
封鎖
封鎖:封鎖就是事務T在對某個數據對象(例如表、記錄等)操作之前,先向系統發出請求,對其加鎖。加鎖后事務T就對該數據對象有了一定的控制,在事務T釋放它的鎖之前,其它的事務不能更新此數據對象
?
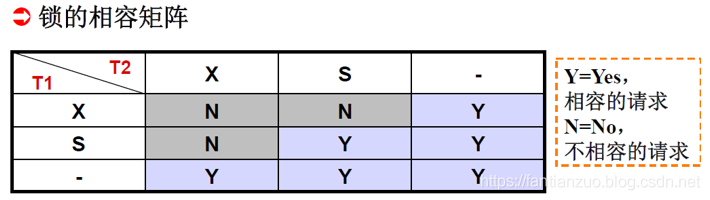
確切的控制由封鎖的類型決定
基本的封鎖類型有兩種:排它鎖(X鎖,exclusive locks)、共享鎖(S 鎖,share locks)
排它鎖又稱寫鎖,對A加了排它鎖之后,其他事務不能對A加 任何類型的鎖(排斥讀和寫)
共享鎖又稱讀鎖,對A加了共享鎖之后,其他事務只能對A加S鎖,不能加X鎖(只排斥寫)
(很重要)
封鎖協議
在運用X鎖和S鎖對數據對象加鎖時,需要約定一些規則:封鎖協議(Locking Protocol)
何時申請X鎖或S鎖、持鎖時間、何時釋放
對封鎖方式制定不同的規則,就形成了各種不同的封鎖協議。
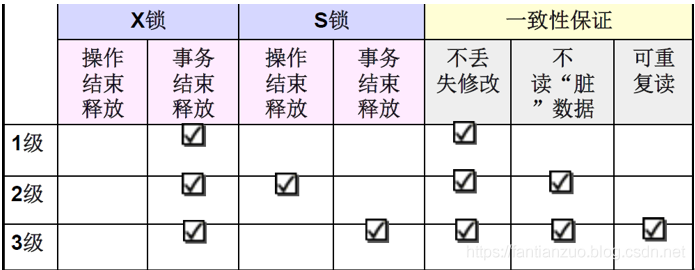
常用的封鎖協議:三級封鎖協議
三級封鎖協議在不同程度上解決了并發問題,為并發操作的正確調度提供一定的保證。
?
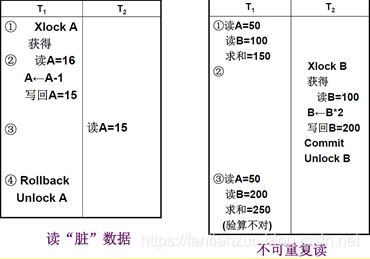
1、一級封鎖協議
事務T在修改數據R之前,必須先對其加X鎖,直到事務結束(commit/rollback)才釋放。
一級封鎖協議可以防止丟失修改
如果是讀數據,不需要加鎖的,所以它不能保證可重復讀和不讀“臟”數據。

2、 二級封鎖協議
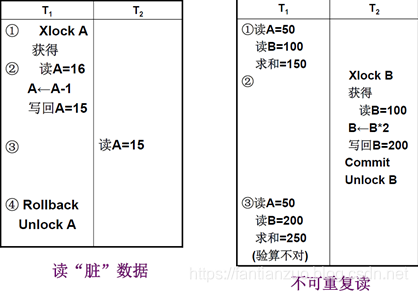
???????? 在一級封鎖協議的基礎(寫要加X鎖,事務結束釋放)上,增加事務T在讀入數據R之前必須先對其加S鎖,讀完后即可釋放S鎖。(讀要加S鎖,讀完即釋放)
二級封鎖協議除了可以防止丟失修改,還可以防止讀臟數據
由于讀完數據即釋放S鎖,不能保證不可重復讀

3、三級封鎖協議:
???????? 在一級封鎖協議基礎上增加事務T在讀取數據R之前必須先對其加S鎖,直到事務結束后釋放。
三級封鎖協議除了可以防止丟失修改和讀臟數據外,還防止了不可重復讀

三級封鎖協議的主要區別是什么操作需要申請鎖,何時釋放鎖。封鎖協議越高,一致性程度越高。
?
饑餓
?
饑餓:事務T1封鎖了數據R,事務T2又請求封鎖R,于是T2等待。T3也請求封鎖R,當T1釋放了R上的封鎖之后,系統首先批準了T3的請求,T2仍然等待。 T4又請求封鎖R,當T3釋放了R上的封鎖之后系統又批準了T4的請求……T2有可能永遠等待,這就是饑餓的情形
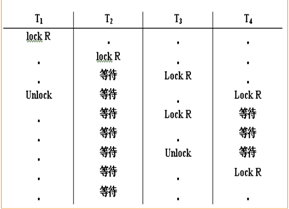
避免饑餓的方法:先來先服務
當多個事務請求封鎖同一數據對象時,按請求封鎖的先后次序對這些事務排隊
該數據對象上的鎖一旦釋放,首先批準申請隊列中第一個事務獲得鎖。
?
死鎖
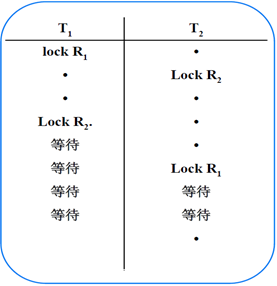
?
死鎖:事務T1封鎖了數據R1, T2封鎖了數據R2。 T1又請求封鎖R2,因T2已封鎖了R2,于是T1等待T2釋放R2上的鎖。 接著T2又申請封鎖R1,因T1已封鎖了R1,T2也只能
等待T1釋放R1上的鎖。 這樣T1在等待T2,而T2又在等待T1,T1和T2兩個事務永遠不能結束,形成死鎖。
解決死鎖的方法:預防、診斷和解除
1、死鎖的預防
產生死鎖的原因是兩個或多個事務都已經封鎖了一些數據對象,然后又都請求對已被其他事務封鎖的數據對象加鎖,從而出現死等待。
預防死鎖發生就是破壞產生死鎖的條件
方法
1)一次封鎖法:
???????? 要求每個事務必須一次將所有要使用的數據全部加鎖,否則就不能繼續執行。
???????? 存在的問題:降低系統的并發度;難以實現精確確定封鎖對象
2)順序封鎖法:
???????? 預先對數據對象規定一個封鎖順序,所有事務都按這個順序實施封鎖。
???????? 存在的問題:
維護成本:數據庫系統中的封鎖對象極多,并且在不斷地變化
難以實現:很難實現確定每一個事務要封鎖哪些對象
DBMS普通采用的診斷并解除死鎖的方法
2、死鎖的診斷和解除
???????? 方法:超時法和事務等待圖法
???????? 1)超時法:如果一個事務的等待時間超過了規定的時限,就認為發生了死鎖
????????????????? 優點:實現簡單
????????????????? 缺點:誤判死鎖;時限若設置太長,死鎖發生后不能及時發現。
???????? 2)事務等待圖法:用事務等待圖動態反映所有事務的等待情況事務
等待圖是一個有向圖G=(T,U),T為結點的集合,每個結點表示正運行的事務, U為邊的集合,每條邊表示事務等待的情況。若T1等待T2,則T1、T2之間劃一條有向邊,從T1指向T2。
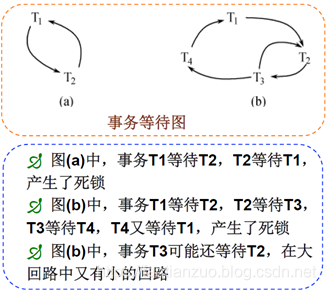
并發控制子系統周期性地(比如每隔數秒)生成事務等待圖,檢測事務。如果發現圖中存在回路,則表示系統中出現了死鎖。? ??
解除死鎖:并發控制子系統選擇一個處理死鎖代價最小的事務,將其撤銷。
釋放該事務持有的所有的鎖,使其他事務能夠繼續運行下去。
?
?
串行調度
什么樣的調度是正確的?串行調度是正確的。
(執行結果等價于串行調度的調度也是正確的,這樣的調度稱為可串行化調度。)
可串行化調度
定義:多個事務的并發執行是正確的,當且僅當其結果與按某一次序串行地執行這些事務時的結果相同,稱這種調度策略為可串行化調度(serializable)。
可串行性是并發事務正確調度的準則。按這個準則規定,一個給定的并發調度,當且僅當它是可串行化的,才認為是正確調度。


沖突可串行化調度
判斷可串行化調度的充分條件
沖突操作:不同的事務對同一個數據的讀寫和寫寫操作。

不同事務的沖突操作和同一事務的兩個操作是不能交換的。
Ri(x)和Wj(x)不可交換,Wi(x)和Wj(x)不可交換
沖突可串行化調度:
一個調度Sc在保證沖突操作的次序不變的情況下,通過交換兩個事務不沖突操作的次序得到另一個調度Sc’,如果Sc’是串行的,稱調度Sc為沖突可串行化的調度。
?
兩段鎖協議
DBMS的并發控制機制必須提供一定的手段來保證調度是可串行化的。目前DBMS普遍采用兩段鎖協議(TwoPhase Locking,簡稱2PL)的方法來顯示并發調度的可串行性。
?
兩段鎖協議是指所有事務必須分兩個階段對數據對象進行加鎖和解鎖。
???????? 1)在對任何數據進行讀寫操作以前,首先要申請并獲得對該數據的鎖。
???????? 2)在釋放一個鎖之后,事務不再申請和獲得其他任何的鎖。
“兩段”鎖的含義:事務分為兩個階段
第一階段是獲得封鎖,也稱為擴展階段
事務可以申請獲得任何數據對象上的任何類型的鎖,但是不能釋放任何鎖
第二階段是釋放封鎖,也稱為收縮階段
事務可以釋放任何數據對象上的任何類型的鎖,但是不能再申請任何鎖
?
事務遵守兩段鎖協議是可串行化調度的充分條件,而不是必要條件。
若并發事務都遵守兩段鎖協議,則對這些事務的任何并發調度策略都是可串行化的
若并發事務的一個調度是可串行化的,不一定所有事務都符合兩段鎖協議
?
兩段鎖協議與防止死鎖的一次封鎖法
一次封鎖法要求每個事務必須一次將所有要使用的數據全部加鎖,否則就不能繼續執行,因此一次封鎖法遵守兩段鎖協議
但是兩段鎖協議并不要求事務必須一次將所有要使用的數據全部加鎖,因此遵守兩段鎖協議的事務可能發生死鎖
?
封鎖的粒度
封鎖對象的大小稱為封鎖粒度(granularity)。
封鎖的對象可以是邏輯單元(屬性值、屬性值集合、元組、關系、索引項、數據庫),也可以是物理單元(頁、物理記錄)。
選擇封鎖粒度原則:
???????? 封鎖粒度和系統的并發度和并發控制的開銷密切相關
???????? 封鎖的粒度越大,數據庫所能夠封鎖的數據單元就越少,并發度就越低,系統開銷也
越小;
封鎖的粒度越小,并發度較高,但系統開銷也就越大
?
意向鎖
意向鎖:如果對一個節點加意向鎖,則可說明該節點的下層節點正在被加鎖;對任一節點加鎖時,必須先對它的上層節點加意向鎖。
例如,對任一元組加鎖時,必須先對它所在的數據庫和關系加意向鎖。
三種常用的意向鎖:意向共享鎖(Intent Share Lock,IS鎖);意向排它鎖(Intent Exclusive Lock,IX鎖);共享意向排它鎖(Share Intent Exclusive Lock,SIX鎖)。
?
1、IS鎖
如果對一個數據對象加IS鎖,表示它的子節點擬加S鎖。
例如:事務T1要對R1中某個元組加S鎖,則要首先對關系R1和數據庫加IS鎖
?
2、IX鎖
如果對一個數據對象加IX鎖,表示它的子節點擬加X鎖。
例如:事務T1要對R1中某個元組加X鎖,則要首先對關系R1和數據庫加IX鎖
?
3、SIX鎖
如果對一個數據對象加SIX鎖,表示對它加S鎖,再加IX鎖,即SIX = S + IX。
?
例如:對某個表加SIX鎖,則表示該事務要讀整個表(所以要對該表加S鎖),同
時會更新個別元組(所以要對該表加IX鎖)
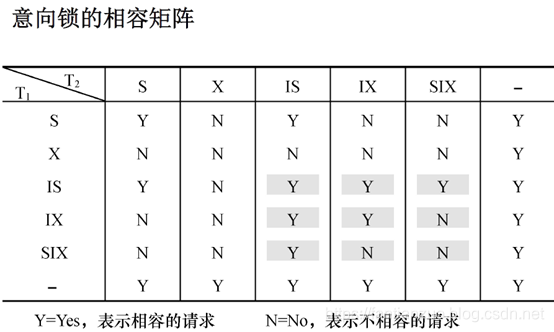
意向鎖的強度: 鎖的強度是指它對其他鎖的排斥程度。一個事務在申請封鎖時以強鎖代替弱鎖是安全的,反之則不然。
具有意向鎖的多粒度封鎖方法
申請封鎖時應該按自上而下的次序進行
釋放封鎖時則應該按自下而上的次序進行
優點:
???????? 1)提高了系統并發度
???????? 2)減少了加鎖和解鎖的開銷
在實際的DBMS產品中得到廣泛應用。
?
其他并發控制
并發控制的方法除了封鎖技術外,還有時間戳方法、樂觀控制法和多版本并發控制。
時間戳方法:給每一個事務蓋上一個時標,即事務開始的時間。每個事務具有唯一的時間戳,并按照這個時間戳來解決事務的沖突操作。如果發生沖突操作,就回滾到具有較早時間戳的事務,以保證其他事務的正常執行,被回滾的事務被賦予新的時間戳被從頭開始執行。
樂觀控制法認為事務執行時很少發生沖突,所以不對事務進行特殊的管制,而是讓它自由執行,事務提交前再進行正確性檢查。如果檢查后發現該事務執行中出現過沖突并影響了可串行性,則拒絕提交并回滾該事務。又稱為驗證方法
多版本控制是指在數據庫中通過維護數據對象的多個版本信息來實現高效并發的一種策略。








)


)

-(一千零一拾一元整)輸出。...)





