持續更新。。。。。。
2.1斐波那契系列問題
2.2矩陣系列問題
2.3跳躍系列問題
3.1 01背包
3.2 完全背包
3.3多重背包
3.4 一些變形選講
?
?
?
2.1斐波那契系列問題
在數學上,斐波納契數列以如下被以遞歸的方法定義:F(0)=0,F(1)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)根據定義,前十項為1, 1, 2, 3, 5, 8, 13, 21, 34, 55
?
例1:給定一個正整數n,求出斐波那契數列第n項(這時n較小)
解法一:完全抄定義
def f(n):if n==1 or n==2:return 1return f(n-1)+f(n-2)?
分析一下,為什么說遞歸效率很低呢?咱們來試著運行一下就知道了:
?
比如想求f(10),計算機里怎么運行的?
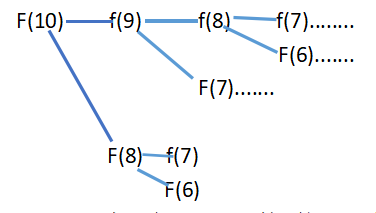
想算出f(10),就要先算出F(9),
想算出f(9),就要先算出F(8),
想算出f(8),就要先算出F(7),
想算出f(7),就要先算出F(6)……
兜了一圈,我們發現,有相當多的計算都重復了,比如紅框部分:
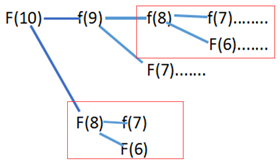
那如何解決這個問題呢?問題的原因就在于,我們算出來某個結果,并沒有記錄下來,導致了重復計算。那很容易想到如果我們把計算的結果全都保存下來,按照一定的順序推出n項,就可以提升效率
?
解法2:
def f1(n):if n==1 or n==2:return 1l=[0]*n??????????????? #保存結果l[0],l[1]=1,1??????????? #賦初值for i in range(2,n):l[i]=l[i-1]+l[i-2]???? #直接利用之前結果return l[-1]可以看出,時間o(n),空間o(n)。
繼續思考,既然只求第n項,而斐波那契又嚴格依賴前兩項,那我們何必記錄那么多值浪費空間呢?只記錄前兩項就可以了。
?
解法3:
def f2(n):a,b=1,1for i in range(n-1):a,b=b,a+breturn a補充:
- pat、藍橋杯等比賽原題:求的n很大,F(N)模一個數。應每個結果都對這個數取模,否則:第一,計算量巨大,浪費時間;第二,數據太大,爆內存,
- 對于有多組輸入并且所求結果類似的題,可以先求出所有結果存起來,然后直接接受每一個元素,在表中查找相應答案
- 此題有快速冪算法,但是礙于篇幅和同學們水平有限,不再敘述,可以自行學習。
?
例2:一只青蛙一次可以跳上1級臺階,也可以跳上2級。求該青蛙跳上一個n級的臺階總共有多少種跳法。
?
依舊是找遞推關系:
1)跳一階,就一種方法
2)跳兩階,它可以一次跳兩個,也可以一個一個跳,所以有兩種
3)三個及三個以上,假設為n階,青蛙可以是跳一階來到這里,或者跳兩階來到這里,只有這兩種方法。
它跳一階來到這里,說明它上一次跳到n-1階,
同理,它也可以從n-2跳過來
f(n)為跳到n的方法數,所以,f(n)=f(n-1)+f(n-2)
?
優化思路與例1類似,請自行思考。
?
例3:我們可以用2*1的小矩形橫著或者豎著去覆蓋更大的矩形。請問用n個2*1的小矩形無重疊地覆蓋一個2*n的大矩形,總共有多少種方法?
?
N=1: 只有一種
N=2,兩種:
N=3:
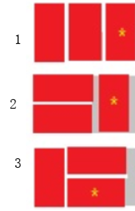
讀到這里,你們應該能很快想到,依舊是斐波那契式遞歸啊。
?
對于n>=3:怎么能覆蓋到三?
只有兩種辦法,從n-1的地方豎著放了一塊,或者從n-2的位置橫著放了兩塊
?
例4:給定一個由0-9組成的字符串,1可以轉化成A,2可以轉化成B。依此類推。。25可以轉化成Y,26可以轉化成z,給一個字符串,返回能轉化的字母串的有幾種?
?
比如:123,可以轉化成
1 、2 、3變成ABC,
12 、3變成LC,
?
1 、23變成AW
三種,返回三,
?
比如99999,就一種:iiiii,返回一。
?
分析:求i位置及之前字符能轉化多少種。
?
兩種轉化方法
1)字符i自己轉換成自己對應的字母
2)和前面那個數組成兩位數,然后轉換成對應的字母
?
假設遍歷到i位置,判斷i-1位置和i位置組成的兩位數是否大于26,大于就沒有第二種方法,f(i)=f(i-1),如果小于26, f(i)=f(i-1)+f(i-2)
?
2.2矩陣系列問題
例5:給一個由數字組成的矩陣,初始在左上角,要求每次只能向下或向右移動,路徑和就是經過的數字全部加起來,求可能的最小路徑和。
?
1? 3? 5? 9
?
8? 1? 3? 4
?
5? 0? 6? 1
?
8? 8? 4? 0
?
路徑:1 3 1 0 6 1 0路徑和最小,返回12
?
分析:我們可以像之前一樣,暴力的把每一種情況都試一次,但是依舊會造成過多的重復計算,以本題為例子最后解釋一下暴力慢在哪里,以后不再敘述了。
比如本題來講,我們嘗試如下路徑:
?
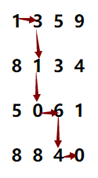

有很多路是重復走過的一遍。
再進一步說:

從1到6位置,有很多路可以走,直觀感受一下:
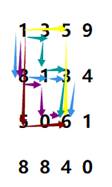
所有路中,一定會有和最小的,但是我們并不知道,每次嘗試一次1->6->終點的路線時,我們把所有的情況都算了一遍,這過程中我們浪費了相當多的有效信息。
?
這就是暴力的結果。
?
優化做法:生成和矩陣相同大小的二維表,用來記錄到起點每個位置的最小路徑和

接下來帶著大家真正進入動態規劃;
第一步:初始化(對于本題來說,第一列和第一行,我們別無選擇,就一條路,因此,我們可以直接確定答案)

第二步:確定其余位置如何推出(我們稱為狀態轉移方程)
直觀來說,每個位置只可能是從上面,或者左邊走來的:

對于普遍的位置i,j,只有i-1,j和i,j-1這兩個位置可以一步走到這里,所以
DP[i,j]=min(DP[i,j-1],DP[i-1,j])+L[i,j](之前的最優解加上本位置的數字)
?
繼續優化:和之前一樣,這個式子實際上也是嚴格依賴兩個值,一個是左邊的值,一個是上面的值,所以,我們按之前的思路,應該可以想到可以壓縮空間。
我們嘗試用一維的空間來解題:
想象這是我們的第一行答案:
![]()
我們如何利用僅有的一維空間來更新出下一行呢?
我們要想:
- 我們需要左面的數字,所以,本位置的左邊必須是更新過的數字(否則就是左上的位置了),所以應該從左往右更新。
- 我們需要上面的數字,這個不需要更新,本來就需要本位置的舊數字。
本題第二行為:8,1,3,4
第一行答案為

依次更新:
?
更新A:

(只能向下走)
更新B:
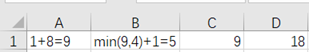
(比較從左邊來和從上面來哪里比較小)
更新C:
 ?
?
更新D:

最后我們可以發現,偽代碼是這樣的:
For i? 0 -> 高度:
??? For j? 0 -> 寬度
DP[j]=min(DP[j-1],DP[j])+L[i,j]
?
時間不變,空間優化到o(min(高,寬))
?
例6:給一個由數字組成的矩陣,初始在左上角,要求每次只能向下或向右移動,路徑和就是經過的數字全部加起來,求可能的最大路徑和。
?
和例5只差一個“大”字,請自己思考
?
例7:一個矩陣,初始在左上角,要求每次只能向下或向右移動,求到終點的方法數。
?
和例5,6類似,只是方法數應該等于,左邊的方法數加上上面的方法數
?
第二章末練習
1
一個只包含'A'、'B'和'C'的字符串,如果存在某一段長度為3的連續子串中恰好'A'、'B'和'C'各有一個,那么這個字符串就是純凈的,否則這個字符串就是暗黑的。例如:
BAACAACCBAAA 連續子串"CBA"中包含了'A','B','C'各一個,所以是純凈的字符串
AABBCCAABB 不存在一個長度為3的連續子串包含'A','B','C',所以是暗黑的字符串
你的任務就是計算出長度為n的字符串(只包含'A'、'B'和'C'),有多少個是暗黑的字符串。(網易17校招原題)
?
2、X國的一段古城墻的頂端可以看成 2*N個格子組成的矩形(如下圖所示),現需要把這些格子刷上保護漆。
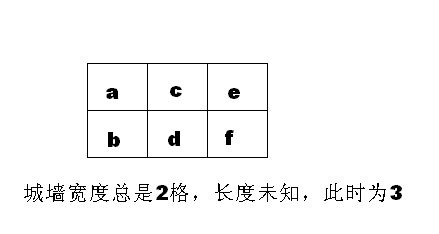
你可以從任意一個格子刷起,刷完一格,可以移動到和它相鄰的格子(對角相鄰也算數),但不能移動到較遠的格子(因為油漆未干不能踩!)
比如:a d b c e f 就是合格的刷漆順序。
c e f d a b 是另一種合適的方案。
當已知 N 時,求總的方案數。當N較大時,結果會迅速增大,請把結果對 1000000007 (十億零七) 取模。
3.1 01背包
入門了動態規劃之后,我們來看一個經典系列問題:背包問題
![]()
?
這是最基礎的背包問題,特點是:每種物品僅有一件,可以選擇放或不放。
用子問題定義狀態:
f[i][j]表示前i件物品恰放入一個容量為j的背包可以獲得的最大價值。則其狀態轉移方程為:
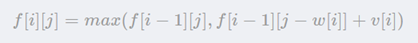
“將前i件物品放入容量為j的背包中”這個子問題,若只考慮第i件物品的策略(放或不放),那么就可以轉化為一個只牽扯前i?1件物品的問題。
如果不放第i件物品,那么問題就轉化為“前i?1件物品放入容量為j的背包中”,價值為f[i?1][j];
如果放第i件物品,那么問題就轉化為“前i?1件物品放入剩下的容量為j?c[i]的背包中”,此時能獲得的最大價值就是f[i?1][j?w[i]],再加上通過放入第i件物品獲得的價值v[i]。
因此得出上面的式子。
繼續優化空間(利用之前提到的知識):
如果我們壓縮到一維空間解題,這次我們需要的是上面的位置和左上的位置,也就是說,我們需要左邊的位置是沒被更新過的,得出更新順序應該從右往左:
?for i in range(1,n+1):
for j in range(v,-1,-1)
??????? f[j] = max(f[j], f[j - w[i]] + v[i]);
3.2 完全背包
?
![]()
這個問題非常類似于01背包問題,所不同的是每種物品有無限件。也就是從每種物品的角度考慮,與它相關的策略已并非取或不取兩種,而是有取0件、取1件、取2件……等很多種。如果仍然按照解01背包時的思路,很容易得出:
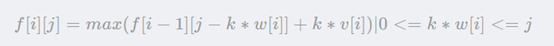
這跟01背包問題一樣有O(VN)個狀態需要求解,但求解每個狀態的時間已經不是常數了
而是![]() ,總的復雜度可以認為是
,總的復雜度可以認為是![]() ,將01背包問題的基本思路加以改進,得到了這樣一個清晰的方法。這說明01背包問題的方程的確是很重要,可以推及其它類型的背包問題。但我們還是試圖改進這個復雜度。
,將01背包問題的基本思路加以改進,得到了這樣一個清晰的方法。這說明01背包問題的方程的確是很重要,可以推及其它類型的背包問題。但我們還是試圖改進這個復雜度。
我們可以知道,對于一個普遍位置w,當前物品代價為2的話,下圖中紅色區域就是和位置w的取值相關的一些數值:

?
對當前物品的決策就依次是:不拿、拿一個、拿兩個、拿三個(對應上面式子中的k)
我們算法優化的思路就是不斷去除重復計算,顯然我們可以繼續優化這個式子。
請思考:我們的E3位置是如何得出的?其實是根據三個紅色區域得出的,但是我們算位置w時又算了一遍,顯然是重復了。而E3其實包含了不拿、拿一個、拿兩個這些情況中的最優解,我們算w時直接用就可以了。
?
給出模板代碼:
for (int i = 1; i <= n; i++)
??? for (int j = w[i]; j <= V; j++)
??????? f[j] = max(f[j], f[j - w[i]] + v[i]);
?
對比兩種背包:
這個代碼與01背包的代碼只有j的循環次序不同而已。為什么這樣一改就可行呢?
首先想想為什么01背包中要按照j=V...0 j=V...0j=V...0的逆序來循環。這是因為要保證第i次循環中的狀態f[i][j]是由狀態f[i?1][j?w[i]]遞推而來。換句話說,這正是為了保證每件物品只選一次,保證在考慮“選入第i件物品”這件策略時,依據的是一個絕無已經選入第i件物品的子結果f[i?1][j?w[i]]。
而現在完全背包的特點恰是每種物品可選無限件,所以在考慮“加選一件第i ii種物品”這種策略時,卻正需要一個可能已選入第i種物品的子結果f[i][j?w[i]],所以就可以并且必須采用j=0...V j=0...Vj=0...V的順序循環。這就是這個簡單的程序為何成立的道理。
最終給出狀態轉移方程給不明白的同學看:

(也可以通過數學導出此式)
?
3.3多重背包

和之前的背包不同,每種物品不是只有一件,也不是有無限件,這次的每種物品的數量都是有限制的,我們對于每種物品,可以選擇拿一件、兩件……p[i]件。
我們借用上一種問題的圖:

看起來是類似的,位置w依舊和紅色區域相關,但是我們可以直接根據E3來求出位置w嗎?是不能的,因為條件變了,每種物品不是無限的,可能在w位置,圖中橢圓圈出的位置代表著需要拿三個,但是如果規定最多拿兩個,我們這種算法就出問題了。
?
一種做題思路:把每個物品都按01背包做:比如第i種物品,我們就按有p[i]件相同的物品。每一種物品都是如此,按01背包做就可以了。(但是顯然很蠢)
?
改進:
我們平時買東西時,難道帶的全是一元的硬幣嗎?當然不是,只要手中的錢可以湊出商品的價格即可,比如9元的東西,我不一定用九個硬幣(背包問題的物品)來付錢,可以5元+4個1元。
背包問題也一樣,我們不一定要全部拆成1的物品,只要我們的物品可以代表0——>p[i]的所有情況,我們就認為這種策略是正確的。
那如何拆p[i]個物品可以保證我們的物品可以代表0——>p[i]的所有情況呢?這里要借助2進制思想。
一個n位的二進制數可以取0到2的n次方-1,第i位代表的是2的i-1次方。
對應到物品:
我們的p[i]=15,我們怎樣拆呢?
1+2+4+8即可,這四個數一定可以組合出0-15的任何一個數。
?
二進制拆分代碼如下:
?
for (int i = 1; i <= n; i++) {
??? int num = min(p[i], V / w[i]);
??? for (int k = 1; num > 0; k <<= 1) {
??????? if (k > num) k = num;
??????? num -= k;
??????? for (int j = V; j >= w[i] * k; j--)
??????????? f[j] = max(f[j], f[j - w[i] * k] + v[i] * k);
??? }
}
3.4 一些變形選講
1)最常見的一些變形,甚至不能說是變形,上面也提到過,但是怕同學們不知道:
我們常見的問題中,一般是問最優解,可能是最大,或者最小,但是,問題也可能是方法的數量,這個時候,一般把狀態轉移方程中的max(min)改為sum(求和)即可,當然,壓縮空間后的樣子還是需要自己寫。
2)初始化的細節問題
我們看到的求最優解的背包問題題目中,事實上有兩種不太相同的問法。有的題目要求"恰好裝滿背包"時的最優解,有的題目則并沒有要求必須把背包裝滿。這兩種問法的區別是在初始化的時候有所不同。
如果是第一種問法,要求恰好裝滿背包,那么在初始化時除了f[0]為0其它f[1...V]均設為?∞,這樣就可以保證最終得到的f[N]是一種恰好裝滿背包的最優解。
如果并沒有要求必須把背包裝滿,而是只希望價格盡量大,初始化時應該將f[0...V]全部設為0。
為什么呢?可以這樣理解:初始化的f數組事實上就是在沒有任何物品可以放入背包時的合法狀態。如果要求背包恰好裝滿,那么此時只有容量為0的背包可能被價值為0的nothing “恰好裝滿”,其它容量的背包均沒有合法的解,屬于未定義的狀態,它們的值就都應該是
?∞了。如果背包并非必須被裝滿,那么任何容量的背包都有一個合法解“什么都不裝”,這個解的價值為0,所以初始時狀態的值也就全部為0了。
3)常數優化
前面的代碼中有for(j=V...w[i]),還可以將這個循環的下限進行改進。
由于只需要最后f[j]的值,倒推前一個物品,其實只要知道f[j?w[n]]即可。以此類推,對以第j個背包,其實只需要知道到f[j?sumw[j...n]]即可,代碼自行修改。
4)其實拆解二進制物品并不是多重背包的最優解,但是最優的單調隊列思想寫起來有些繁瑣,可能以后會寫。
?
可以刷的題
鑒于有一些同學說簡單,我把去年寫的一些題解放在這里:
背包是否裝滿
單調棧
單調雙端隊列
雙端隊列優化的背包問題
字符串上的動態規劃
皇后問題(位運算)
旅行商問題(認識狀態壓縮)
藍橋杯 摔手機 費時巨多的題解
2018hbcpc dp總結
HDU1029 HDU1087 HDU1176?HDU1257 POJ1458
POJ2533 HDU1114 HDU1260 HDU1160
HDU1069 POJ3616 POJ1088
POJ1189 UVA12511 HDU2845 HBCPC2018 K
leetcode516 最長回文子序列
leetcode104 二叉樹的最大深度
leetcode403 青蛙過河
leetcode115 不同的子序列
leetcode32 最長有效括號
leetcode 152 乘積最大子序列
leetcode221 最大正方形
leetcode213 打家劫舍II
leetcode97 交錯字符串
leetcode542 01矩陣
leetcode303 區域和檢索
leetcode72 編輯距離
leetcode45 跳躍游戲II 秒殺所有答案
leetcode55 跳躍游戲 秒殺所有答案
leetcode63 不同路徑II
leecode5 最長回文子串
leetcode300 最長上升子序列
leetcode64 最小路徑和
leecode53 最大子序列和
leecode11 盛水最多的容器
leetcode538 把二叉搜索樹轉換成累加樹
leetcode322 零錢兌換
leetcode70 爬樓梯
leetcode121買賣股票的最佳時機
?
方法、按值排序sort_value()方法】)

、from_arrays()、from_product()、swaplevel()、sort_index()、sort_values()】)

函數、boxplot()方法】)

方法和to_numeric()函數)

函數、merge()函數、join()方法、combine_first()方法】)

)
方法和unstack()方法、pivot()方法】)

方法、cut()函數、get_dummies()函數】)

方法)

方法)

方法、apply()方法】)