本文來自公眾號“AI大道理”
DeepSORT在SORT的基礎上引入了深度學習的特征表示和更強大的目標關聯方式,有效地減少了身份切換的數量,緩解了重識別問題。
?
![]()
1、DeepSORT簡介
DeepSORT的主要思想是將目標檢測和目標跟蹤兩個任務相結合。
首先使用目標檢測算法(Faster R-CNN等)在每一幀中檢測出目標物體的位置和邊界框。然后,通過深度學習模型(如CNN)提取目標的特征表示,將每個目標與先前幀中已跟蹤的目標進行匹配。
匹配過程中會考慮目標的特征相似度、運動一致性等因素,以確定目標的身份和軌跡。
DeepSORT的關鍵貢獻之一是使用了一個強大的外觀特征描述符,可以準確地區分不同目標之間的相似度。
DeepSORT還通過處理目標的消失和重新出現等復雜情況,實現了對長期跟蹤的支持。
主要技術特點:
-
級聯匹配
-
ReID?網絡
-
馬氏距離
-
余弦距離
![]()
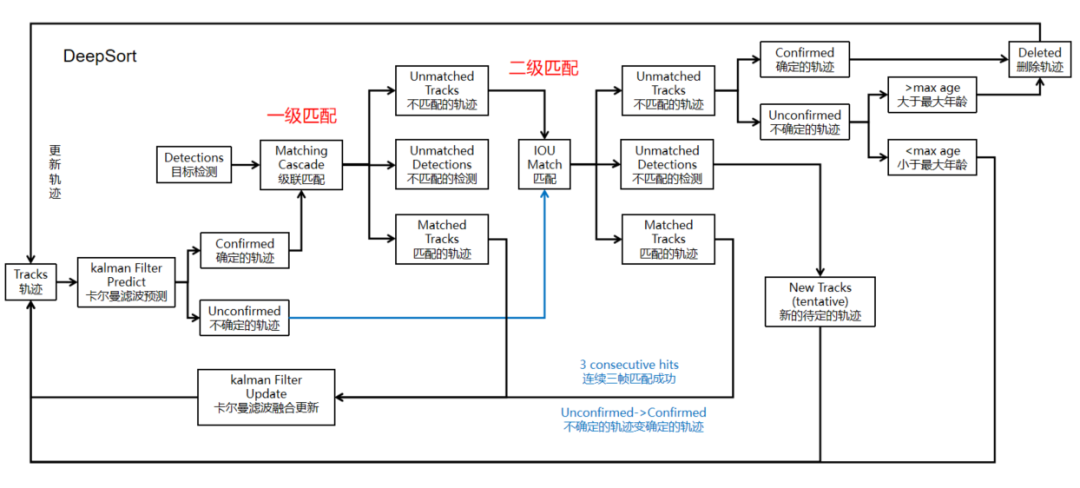
2、級聯匹配
原因:
當一個目標長時間被遮擋之后,kalman濾波預測的不確定性就會大大增加,狀態空間內的可觀察性就會大大降低。
假如此時兩個追蹤器競爭同一個檢測結果的匹配權,往往遮擋時間較長的那條軌跡的馬氏距離更小,使得檢測結果更可能和遮擋時間較長的那條軌跡相關聯,這種不理想的效果往往會破壞追蹤的持續性。
這么理解吧,假設本來協方差矩陣是一個正態分布,那么連續的預測不更新就會導致這個正態分布的方差越來越大,那么離均值歐氏距離遠的點可能和之前分布中離得較近的點獲得同樣的馬氏距離值。所以,作者使用了級聯匹配來對更加頻繁出現的目標賦予優先權。
匹配:
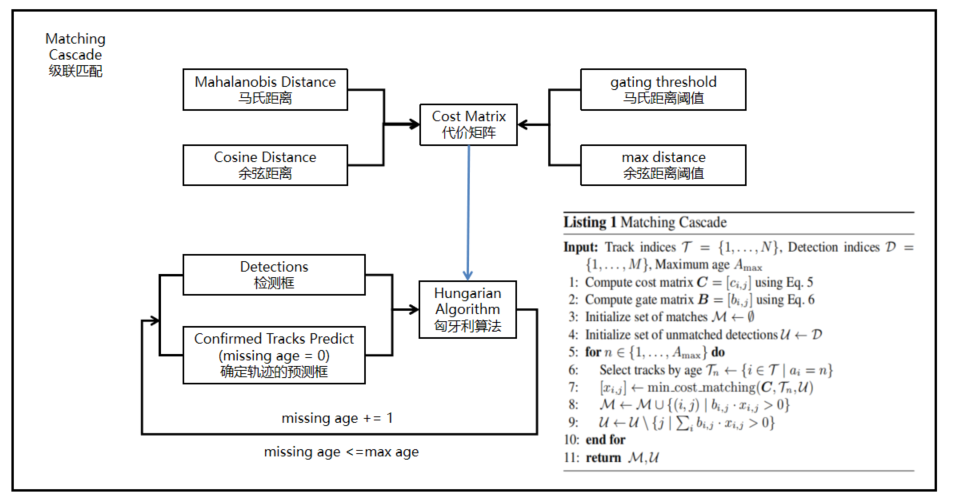
為什么叫級聯匹配,主要是它的匹配過程是一個循環。
即從missing age=0的軌跡,每一幀都匹配上,沒有丟失過的軌跡到missing age=30的軌跡,丟失軌跡的最大時間30幀的軌跡,挨個的和檢測結果進行匹配。
也就是說,對于沒有丟失過的軌跡賦予優先匹配的權利,而丟失的最久的軌跡最后匹配。
這里丟失30幀了還給機會匹配,就是對遮擋目標的再跟蹤。
級聯匹配的距離度量是馬氏距離和余弦距離的融合,設置了兩個距離的閾值,先過濾一遍。
然后利用這個融合的距離進行匈牙利算法的匹配,匹配是對檢測框和預測框的匹配。
而且匹配有優先級的,那些歷史上一直有匹配上的軌跡優先匹配,而歷史上已經已經很久沒有匹配上的軌跡則最后匹配。
也就是說遮擋的可能性比較小,大部分沒有匹配上的軌跡可能就是目標消失了。

匹配流程圖:
(藍字只對藍線有效)
情況1:確定的軌跡,一級匹配成功
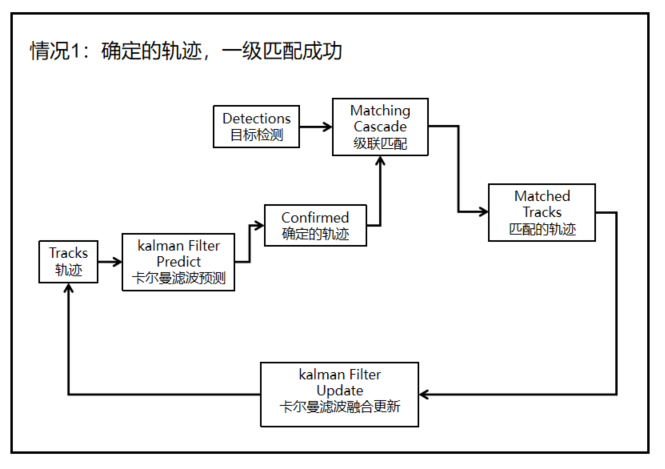
流程:
(1)軌跡(上一時刻的檢測框)經過kalman濾波預測后,會對當前幀預測出一組檢測框。
(2)目標檢測算法對當前幀進行目標檢測,產生檢測框。
(3)對于確定的軌跡來說與目標檢測的檢測框進行級聯匹配,也就是利用馬氏距離和圖像特征相似度余弦距離進行匈牙利算法的數據關聯。
(4)軌跡(上一時刻的檢測框)成功與檢測框匹配。
(5)進行卡爾曼濾波的融合,是檢測框與預測框的融合,融合完后更新到軌跡中。
情況2:確定的軌跡,一級匹配失敗,二級匹配成功

匹配失敗分為軌跡匹配失敗和檢測框匹配失敗兩種。
軌跡匹配失敗:
有些軌跡沒有檢測框與之匹配,原因是檢測可能發生了漏檢,某時刻,預測的軌跡tracks還在,但是檢測器沒有檢測到與之對應的目標;也可能是這個目標消失不見了,或者被遮擋了,沒有檢測框了。
檢測框匹配失敗:
有些檢測框匹配不上軌跡,原因可能是某一時刻有一個物體是新進入的鏡頭,就會發生檢測框匹配不到tracks的情況,因為這個物體是新來的,在這之前并沒有它的軌跡;也可能是物體長時間被遮擋后的檢測,導致檢測到的物體沒有可以與之匹配的軌跡(長時間遮擋超過閾值軌跡被刪除)。
流程:
(1)對于確定的軌跡來說與目標檢測的檢測框進行級聯匹配,也就是利用馬氏距離和圖像特征相似度余弦距離進行匈牙利算法的數據關聯。
(2)軌跡沒有與檢測框匹配,則對這些軌跡進行與檢測框的IOU匹配,匹配成功。
(IOU匹配可以有效匹配靜態場景幾何體的部分遮擋的情況,提高匹配成功率。這里相當于進行多次匹配,第一次匹配成功那就成功,匹配不上再給一次機會,進行IOU匹配,這次匹配上也算匹配上。)
(3)檢測框沒有與軌跡匹配上,則對這些檢測框進行與軌跡的IOU匹配,匹配成功。
(4)進行卡爾曼濾波的融合,是檢測框與預測框的融合,融合完后更新到軌跡中。
情況3:確定的軌跡,一級匹配失敗,二級匹配也失敗。
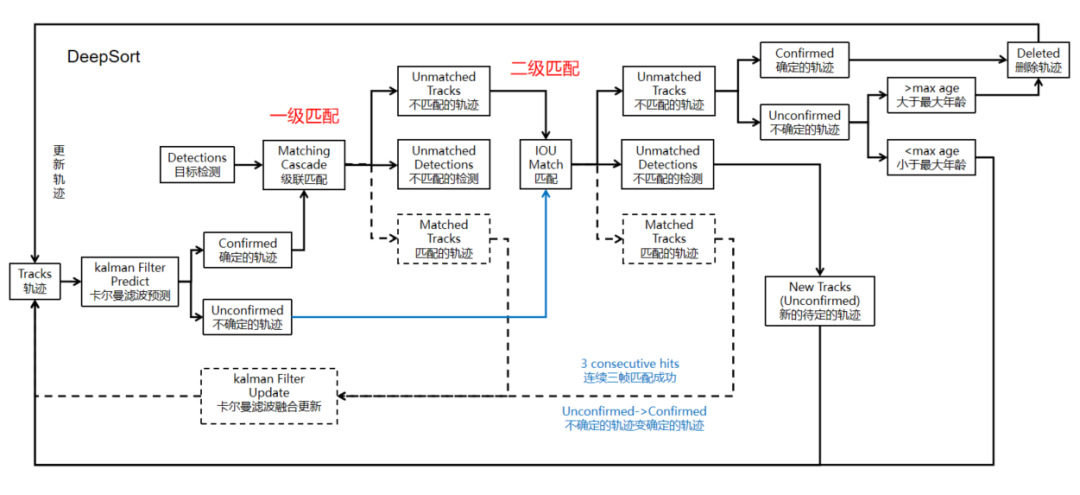
流程:
(1)對于二級匹配失敗的檢測框,建立一個新的不確定的軌跡。因為匹配失敗可能是視野中出現新目標了,也可能就是檢測器的誤檢測,對這個檢測框要不要建立真實軌跡是不一定的,也就是unconfirmed軌跡。
(2)這個新不確定的軌跡要經過一個考驗才能成為真實軌跡,那就是要連續三幀都要有檢測框對其進行成功匹配,那就確定是一個真實軌跡了。
(3)對于考核期的軌跡(3幀考核,unconfirmed軌跡),直接進行IOU匹配,匹配成功,計數加1,連續三次匹配成功,則變更為確定的軌跡。確認的軌跡接下來就會保存外觀特征100幀。考察期間的軌跡在3幀內匹配失敗,則直接刪除,判定為偶然的誤報。
(4)對于再次匹配失敗的軌跡來說,如果這個軌跡是待確定的軌跡,則刪除,如果是確定的軌跡,則判斷接下來幾幀(max age幀,30幀)是否還能匹配上,超過30幀了還不能匹配上,放棄了,這個軌跡終止了。可能是真的終止了,也可能是長時間遮擋,這個就是這個閾值max age的容忍程度了,遮擋太久就沒辦法了,只能認為是新目標了,也就是跟丟了。
如果在30幀內,那繼續給你機會進行IOU匹配,這時候即使匹配成功了,也要進行三幀考察。
![]()
3、ReID?網絡
DeepSORT中采用了一個簡單的CNN來提取被檢測物體的外觀特征,在每次檢測追蹤后,進行一次物體外觀特征的提取并保存,最多保存100幀。
后面每執行一步時,都要執行一次當前幀被檢測物體外觀特征與之前存儲的外觀特征的相似度計算,這個相似度將作為一個重要的判別依據。
Deep Sort 采用了經過大規模人員重新識別數據集訓練的 Cosine 深度特征網絡,該數據集包含 1,261 位行人的 1,100,000 多張圖像,使其非常適合在人員跟蹤環境中進行深度度量學習。
Cosine 深度特征網絡使用了寬殘差網絡,該網絡具有 2 個卷積層和 6 個殘差塊,L2 歸一化層能夠計算不同行人間的相似性,以與余弦外觀度量兼容。通過計算行人間的余弦距離,余弦距離越小,兩行人圖像越相似。Cosine 深度特征網絡結構如下圖所示。

使用 Cosine 深度特征網絡參數,將每個檢測框內圖片壓縮為最能表征圖片特異信息的128維向量,并歸一化后得到外觀描述向量。
![]()
4、馬氏距離
DeepSort使用馬氏距離表示檢測框到軌跡的距離,馬氏距離就是“加強版的歐氏距離”。
馬氏距離規避了歐氏距離中對于數據特征方差不同的風險,在計算中添加了協方差矩陣,其目的就是進行方差歸一化,從而使所謂的“距離”更加符合數據特征以及實際意義。
馬氏距離是旋轉變換縮放后的歐氏距離,它將樣本的協方差矩陣納入距離度量計算,相當于對歐式距離的修正。
馬氏距離完成正交,解決了特征間相關性的問題,內含標準化,解決了特征間尺度不一致的問題。
馬氏距離可用于判斷點到某個分布的距離。
馬氏距離是表示數據的協方差距離,計算兩個未知樣本集的相似度的方法。
公式:
馬氏距離是旋轉變換縮放后的歐氏距離,所以馬氏距離的計算公式可以由歐式距離推導而來。

如果協方差矩陣為單位矩陣,馬氏距離就簡化為歐式距離。
歐式距離兩個分量的權值都是1,而馬氏距離可以是其他值。
等距線:??
旋轉橢圓
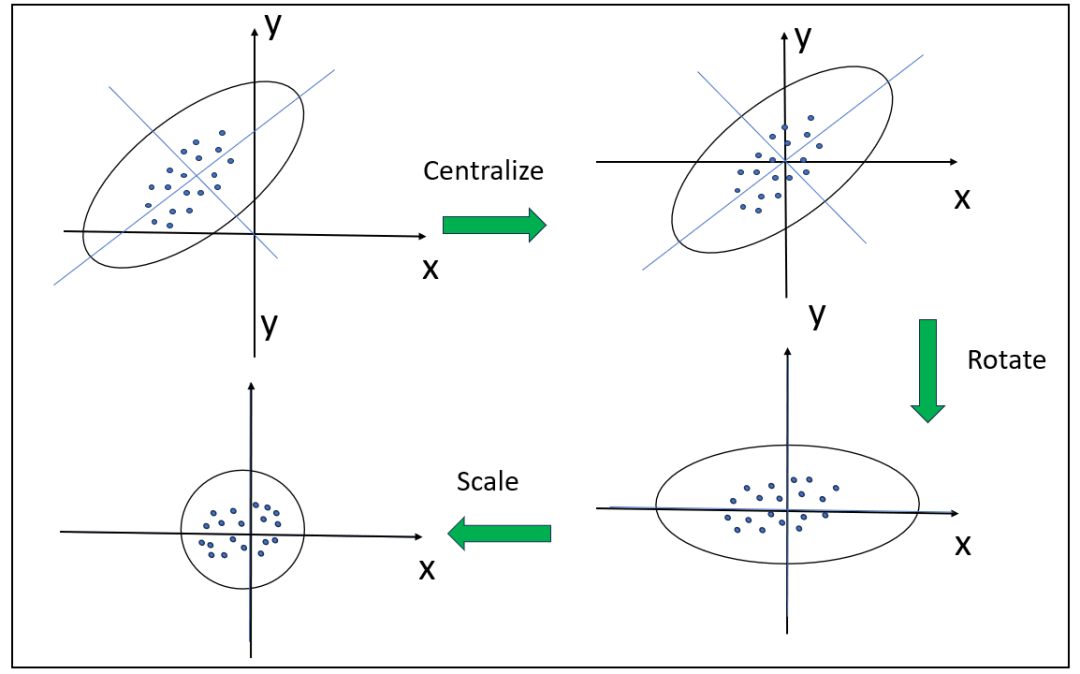
馬氏距離,將變量按照主成分進行旋轉,讓維度間相互獨立,然后進行標準化,讓維度同分布。
![]()
5、余弦距離
由于馬氏距離在遮擋后的度量有些問題,因此DeepSort加入了圖像特征相似度度來進行綜合判斷。
余弦距離則是一種相似度度量方式。
馬氏距離是針對于位置進行區分,而余弦距離則是針對于方向和特征。
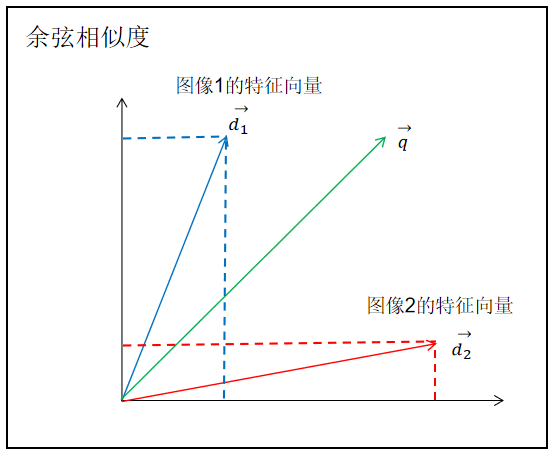
余弦相似度是一種常用的衡量向量之間相似度的方法,它可以用于計算兩個向量之間的夾角的余弦值。
在圖像相似度計算中,可以將圖像轉換為特征向量,在DeepSort中就是使用了ReID網絡,然后使用余弦相似度來比較這些特征向量的相似程度。
余弦相似度的計算公式如下:
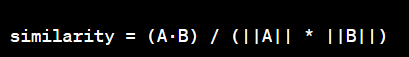
其中,A和B分別表示兩個向量,·表示向量的點積,||A||和||B||表示向量的范數(即向量的長度)。
余弦相似度的取值范圍在 -1 到 1 之間,值越接近 1 表示兩個向量越相似,越接近 -1 表示兩個向量越不相似,接近 0 表示兩個向量之間沒有明顯的相似性或差異。
在圖像相似度計算中,可以將圖像轉換為特征向量(如使用卷積神經網絡提取的特征向量),然后計算這些特征向量之間的余弦相似度來衡量圖像的相似性。
![]()
6、總結
DeepSort著重要解決的一個問題就是遮擋后的ID切換的問題,在遮擋一段時間后不管是IOU距離還是馬氏距離,其實效果都不是很理想。
因此要想建立這種遠程聯系就要進行特征比對。
這個很像孿生網絡的思想,建立一個歷史目標庫,檢測框與目標庫一一比對,相似度高的就是同一個目標,進行軌跡關聯。
因此這里的ReID網絡自然也可以用孿生網絡來做。
孿生網絡的應用有兩種思路,一種就是當做ReID網絡來用,下一幀使用檢測器檢測出來,然后對框內的目標進行相似度比對,這是判別式的思想。
另一種是當做生成式來用,對上一幀的檢測框里面的目標進行特征提取,然后下一幀就不用檢測器了,而是直接去所搜區域,逐一進行相似度比對找到目標。

?——————
淺談則止,細致入微AI大道理
掃描下方“AI大道理”,選擇“關注”公眾號
—————————————————————
?

—————————————————————
投稿吧?? |?留言吧

)







)
![[bug] 記錄version `GLIBCXX_3.4.29‘ not found 解決方法](http://pic.xiahunao.cn/[bug] 記錄version `GLIBCXX_3.4.29‘ not found 解決方法)
)


)




