(為了節約時間,后面關于機器學習和有關內容哦就是用中文進行書寫了,如果有需要的話,我在目前手頭項目交工以后,用英文重寫一遍)
(祝,本文同時用于比賽學習筆記和機器學習基礎課程)
俺前兩天參加了一個ai類的比賽,其中用到了一種名為baseline的模型來進行一些數據的識別。而這個識別的底層原理就是決策樹。正好原本的學習進度剛剛完成這部分,所以集成一個筆記了,本文中所有的截圖絕大多數來自吳恩達老師的公開課程,為了方便理解,把相關的圖片搬過來了)
決策樹是什么
決策樹是一種機器學習算法,在一個類似二叉樹的結構上實現的分支判斷算法。每個節點都視為一個“判斷語句”,將一批數據劃分成不同的部分。節點上(除了葉子)都要判斷“是”/“否”。

?一個具體化以后的模型差不多長這樣子:給出一堆寵物的數據,根據不同的特征(耳朵,臉型什么的),我們判斷輸入案例是狗還是貓貓。
如果還是不好理解,那么想象一下我們平時在寫代碼時候大量if else嵌套,展開以后也是一模一樣的結構。去別在于可能if構成的判斷樹的后代可能多于決策樹,決策樹只能是二叉樹,輸出“是”“不是”這種問題,當面對多個離散的特征值的時候,我們還有別的技術可以使用.
簡而言之,決策樹是一種區別于神經網絡的另一種判斷算法,在一些數據的處理上可能比神經網絡更快更有效,由于其結構類似二叉樹,所以稱之為決策樹(decision tree).決策樹的生成是要根據已經給出的數據案例創建的,數據有多少特征用于區分,就會有多少個節點進行分裂(split).
具體的訓練過程和訓練中遇到的問題會在下面解釋
在訓練之前要接觸的一些名詞
純凈(purity)/雜質(impurity):純度和不純是根據某個節點來說的,例如我們輸入一堆寵物的數據(包括耳朵形狀,毛發長度,臉型這些特征),在判斷某個屬性的節點上,我們會根據"符合"/"不符合"把已有的數據劃分為兩撥.比如這樣子
?原型的部分中,有四個是貓貓,三個是狗子.對于這個節點來說,我們可以認為這個節點的純度是(4/7)
同理,另一個節點的純度視為(1/3)
(純度是一個相對的概念,如果你判斷的是狗子,那么純度就要變了)
熵:這個熵不是化學中的概念,而是代表混亂程度,當純度和為0.5的時候,代表兩種東西對半開,也就是最混亂的情況.根據純度,我們有相關的公式可以計算出純度對應熵的大小(假設純度為p)
整個函數的圖像大概就是這樣子

信息增益:信息增益也是根據某一個點來說的,這個數值是訓練時候的重要依據,信息增益越大,代表整個節點進行的劃分越有效,信息增益的計算方式為
0.5對應的熵,減去左側的熵和右側的熵的加權平均和即可.比如上面的圖,我們可以計算為
決策樹如何進行訓練
決策樹底層的訓練原理其實很簡單,首先我們需要給定一個數據集合,這個數據集合中的每個事物都有一些共同的特征,類似這樣,通常我們可以把有效的特征組合起來形成一個表格.

?前面的特征為輸入,而cat一列作為輸出,決定這個寵物到底是不是貓,由此構成一系列符合監督學習要求的訓練數據集合.
然后會從這些信息中,選擇分裂時產生更小熵的特征,算法會基于某種標準(例如信息增益、基尼不純度等)來評估每個可能的劃分,并選擇最優的劃分特征。這些標準用于衡量數據的不純度和分割后的純度。這里我們使用上面講到的信息增益來判斷這個劃分成都

?由此可見,以耳朵形狀作為劃分所產生的分裂節點,信息增益更大,純度也更好.
接下來再根據其他的特征進行劃分即可,當遇到以下幾種情況的時候,我們可以認為這個節點不用再繼續分裂了
- 樹的高度達到某些限制
- 純度已經是100%
- 數據全部低于閾值
- ........
?兩個特殊情況
(1)分裂時候的數據不是二元的離散數值,而是一個連續的情況
這個很簡單,設置一個閾值,比如0.5,0,7,....反正到最后還是二元的
(2)分裂的時候,可能數據是多元的離散數值,比如毛發可能是長發,短發,卷發這三種.我們總不能搞出三叉樹來,所以這里我們把"是什么"轉變為"是不是"的問題.比如這樣一個特征,我們可以劃分為"是不是長發,是不是短發,是不是卷毛"三個二元的特征
隨機森林算法
給定一個數據集合,我們可以計算出一個決策樹來進行一些判斷,給定一個動物,決策樹最紅會給出我們這個是不是貓貓的答案.但是這有兩個問題,節點不一定是純凈的(雖然大多數情況下,只要不超過我們的限定高度,是可以把一個決策樹修煉到高度純凈的),造成判斷結果不一定準確.
另一個問題就是,一些數據發生擾動以后,可能會影響決策樹這個依托信息增益產生的精密系統.
最簡單粗暴的方法就是,訓練多個樹,形成一個森林.但是一個數據集合練出來的樹是一樣的,沒啥必要,所以我們產生了隨機森林算法.
sampling with replacement(放回抽樣)這東西我們在高中就學過,所以這里不加簡述了.我們要做的就是確定一個規模,比如10,每次從原始數據集中抽取10個案例,然后用來訓練一棵樹.
如此循環多次,我們就能得到多個決策樹,組成一個森林,這其中難免會有一些決策樹是一樣的,我們忽視掉它

這樣我們計算結果的時候,要考慮到整個森林所有樹木的輸出效果,然后綜合考慮我們怎樣確定輸出效果?
XGBoost算法和使用
在眾多隨機森林算法中,XGBoost是一種使用很廣泛的隨機森林算法,并且XGBoost也是一個開源庫(不是放在tf或者pytorch的庫中的).XGBoost非常像我們之前聊過的增強算法(啥,哦博客還沒寫出來,8好意思,盡快補上)
XGBoost算法和普通決策樹的區別在于放回抽樣的不瘋魔,傳統的決策樹是平等地抽取,xgb算法則是會根據上一次,估計錯了哪些數值,在本次抽取中優先提取上一次參與訓練并且估計失敗的數值案例.
比如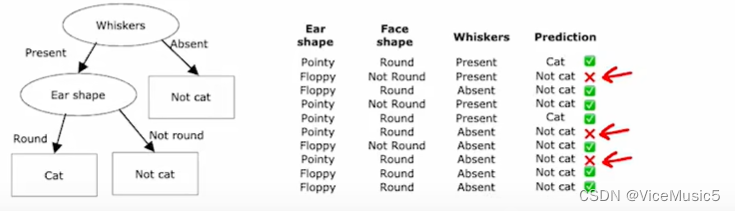
?構建某一次決策樹的時候,2,6,8號數據估計錯誤,則下一次會優先提取出這些作為訓練案例之一.
當然這些主要是底層實現了(注意對應的函數從xgboost包中導入,這個包需要提前下載)
下面來看一下具體的使用案例.
pip3 install xgboost#xgboost算法 這里沒有使用訓練集合什么de
# 定義特征矩陣和標簽
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])# 創建并訓練模型
model = XGBClassifier()
model.fit(X, y)# 預測一個數據
data_to_predict = np.array([[2, 3]])
prediction = model.predict(data_to_predict)print(f"預測結果: {prediction}")#xgboost算法 這里沒有使用訓練集合什么de
# 定義特征矩陣和標簽
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 1, 1])# 創建并訓練模型
model = XGBClassifier()
model.fit(X, y)# 預測一個數據
data_to_predict = np.array([[2, 3]])
prediction = model.predict(data_to_predict)print(f"預測結果: {prediction}")和神經網絡有什么區別捏?
相比于神經網絡來說,決策樹和隨機森林算法更適合一些有固定相似數據結構的數據集合.換句話說,更容易處理那種可以形成表格的數據.
而神經網絡則用來處理一些非相似結構的數據,這一點就是他們的主要區別
決策樹同樣是一種很重要的監督學習算法.
關于baseline(未完待續)
baseline是一種基于決策樹的大模型,適用于多重二元分析等操作,在競賽和論文中應用很廣泛.
(至少與我們之前用到tensorflow要廣泛.....tf都快開擺了)
不過這個模型我現在也不是很熟悉,僅僅是停留在"用過"這個層面上,后面有機會我會繼續在這里補充這個模型的使用和優缺點,


 創建UDR外部函數)
)
)



?為什么它在JavaScript中很有用?)





-JS句柄)



)
