分布式緩存
- a.Redis持久化
- 1) RDB持久化
- 1.a) RDB持久化-原理
- 2) AOF持久化
- 3) 兩者對比
- b.Redis主從
- 1) 搭建主從架構
- 2) 數據同步原理(全量同步)
- 3) 數據同步原理(增量同步)
- c.Redis哨兵
- 1) 哨兵的作用
- 2) 搭建Redis哨兵集群
- 3) RedisTemplate的哨兵模式
- d.Redis分片集群
- 1) 搭建分片集群
- 2) 散列插槽
- 3) 集群伸縮
- 4) 故障轉移
- 5) RedisTemplate訪問分片集群
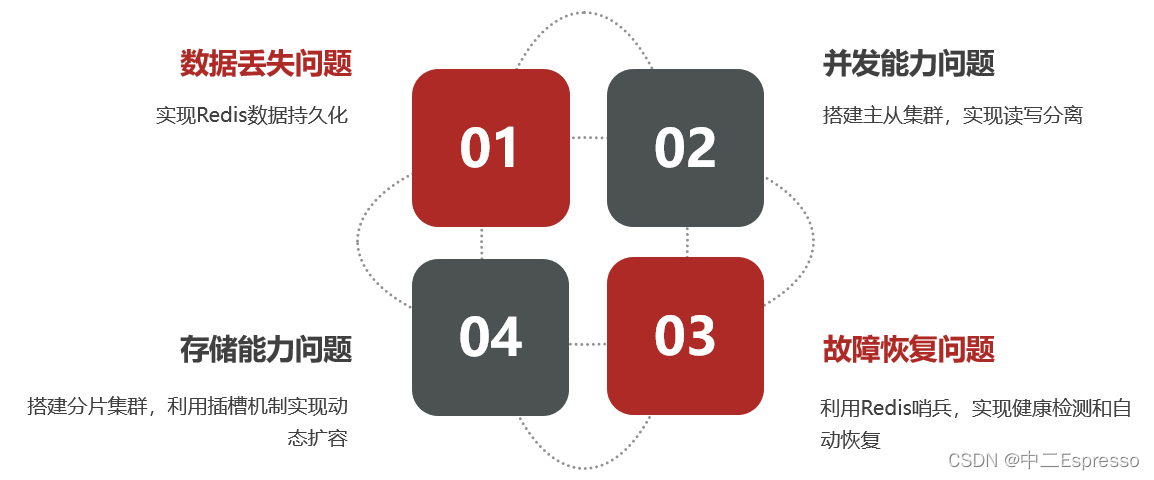
– 基于Redis集群解決單機Redis存在的問題
單機的Redis存在四大問題:
- 1.數據丟失問題: Redis是內存存儲,服務重啟可能會丟失數據
- 2.并發能力問題: 單節點Redis并發能力雖然不錯,但也無法滿足如618這樣的高并發場景
- 3.故障恢復問題: 如果Redis宕機,則服務不可用,需要一種自動的故障恢復手段
- 4.存儲能力問題: Redis基于內存,單節點能存儲的數據量難以滿足海量數據需求
a.Redis持久化
1) RDB持久化
RDB全稱Redis Database Backup file(Redis數據備份文件),也被叫做Redis數據快照。簡單來說就是把內存中的所有數據都記錄到磁盤中。當Redis實例故障重啟后,從磁盤讀取快照文件,恢復數據。
快照文件稱為RDB文件,默認是保存在當前運行目錄。
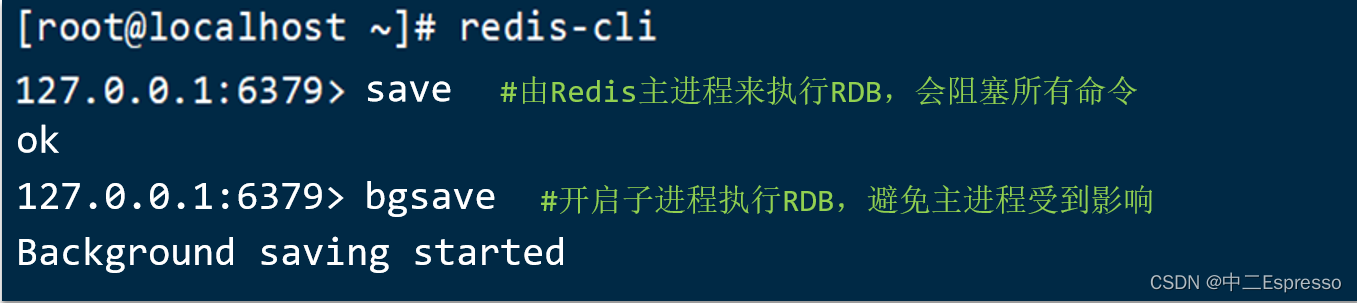
Redis停機時會執行一次RDB。
Redis內部有觸發RDB的機制,可以在redis.conf文件中找到,格式如下:

RDB的其它配置也可以在redis.conf文件中設置:

1.a) RDB持久化-原理
bgsave開始時會fork主進程得到子進程,子進程共享主進程的內存數據。完成fork后讀取內存數據并寫入 RDB 文件
fork采用的是copy-on-write技術:
- 當主進程執行讀操作時,訪問共享內存;
- 當主進程執行寫操作時,則會拷貝一份數據,執行寫操作。
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-9auWz7oi-1692354289144)(C:\Users\captaindeng\AppData\Roaming\Typora\typora-user-images\image-20230817140743459.png)]
RDB方式bgsave的基本流程?
- fork主進程得到一個子進程,共享內存空間
- 子進程讀取內存數據并寫入新的RDB文件
- 用新RDB文件替換舊的RDB文件。
RDB會在什么時候執行?
- 默認是服務停止時。
- 也可以設置在60秒內至少執行1000次修改則觸發RDB (自修改)
RDB的缺點?
- RDB執行間隔時間長,兩次RDB之間寫入數據有丟失的風險
- fork子進程、壓縮、寫出RDB文件都比較耗時
2) AOF持久化
AOF全稱為Append Only File(追加文件)。Redis處理的每一個寫命令都會記錄在AOF文件,可以看做是命令日志文件
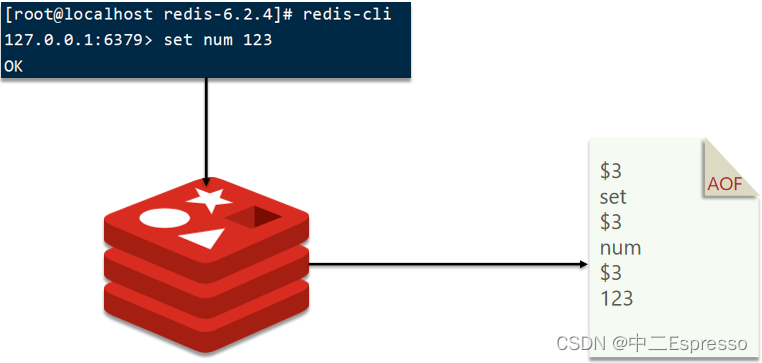
AOF默認是關閉的,需要修改redis.conf配置文件來開啟AOF:

AOF的命令記錄的頻率也可以通過redis.conf文件來配:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-pkPcdXYV-1692354289145)(C:\Users\captaindeng\AppData\Roaming\Typora\typora-user-images\image-20230817144856449.png)]
| 配置項 | 刷盤時機 | 優點 | 缺點 |
|---|---|---|---|
| Always | 同步刷盤 | 可靠性高,幾乎不丟數據 | 性能影響大 |
| everysec | 每秒刷盤 | 性能適中 | 最多丟失1秒數據 |
| no | 操作系統控制 | 性能最好 | 可靠性較差,可能丟失大量數據 |
因為是記錄命令,AOF文件會比RDB文件大的多。而且AOF會記錄對同一個key的多次寫操作,但只有最后一次寫操作才有意義。通過執行bgrewriteaof命令,可以讓AOF文件執行重寫功能,用最少的命令達到相同效果。

Redis也會在觸發閾值時自動去重寫AOF文件。閾值也可以在redis.conf中配置:

3) 兩者對比
RDB和AOF各有自己的優缺點,如果對數據安全性要求較高,在實際開發中往往會結合兩者來使用。
| RDB | AOF | |
|---|---|---|
| 持久化方式 | 定時對整個內存做快照 | 記錄每一次執行的命令 |
| 數據完整性 | 不完整,兩次備份之間會丟失 | 相對完整,取決于刷盤策略 |
| 文件大小 | 會有壓縮,文件體積小 | 記錄命令,文件體積很大 |
| 宕機恢復速度 | 很快 | 慢 |
| 數據恢復優先級 | 低,因為數據完整性不如AOF | 高,因為數據完整性更高 |
| 系統資源占用 | 高,大量CPU和內存消耗 | 低,主要是磁盤IO資源但AOF重寫時會占用大量CPU和內存資源 |
| 使用場景 | 可以容忍數分鐘的數據丟失,追求更快的啟動速度 | 對數據安全性要求較高常見 |
b.Redis主從
1) 搭建主從架構
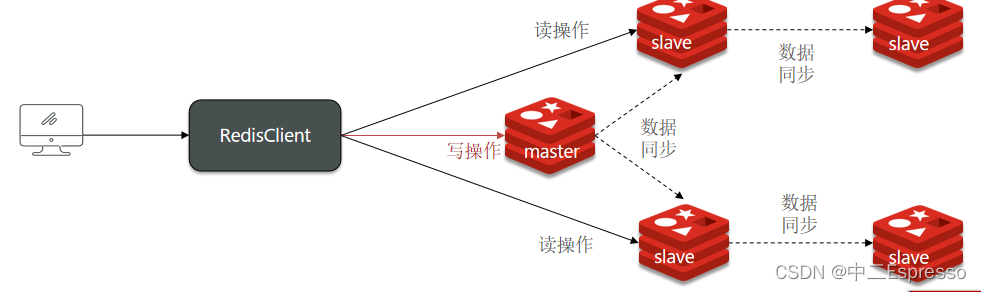
單節點Redis的并發能力是有上限的,要進一步提高Redis的并發能力,就需要搭建主從集群,實現讀寫分離。
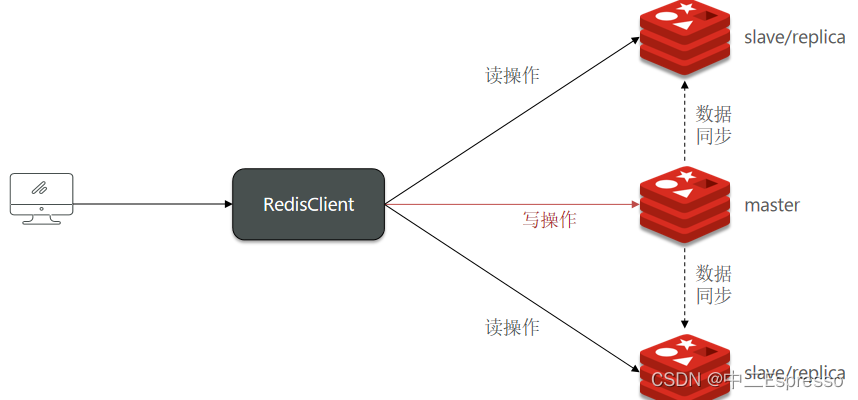
共包含三個節點,一個主節點,兩個從節點。
這里我們會在同一臺虛擬機中開啟3個redis實例,模擬主從集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | slave |
| 192.168.150.101 | 7003 | slave |
準備實例和配置
要在同一臺虛擬機開啟3個實例,必須準備三份不同的配置文件和目錄,配置文件所在目錄也就是工作目錄。
1)創建目錄
我們創建三個文件夾,名字分別叫7001、7002、7003:
# 進入/tmp目錄
cd /tmp
# 創建目錄
mkdir 7001 7002 7003
如圖:
2)恢復原始配置
修改redis-6.2.4/redis.conf文件,將其中的持久化模式改為默認的RDB模式,AOF保持關閉狀態。
# 開啟RDB
# save ""
save 3600 1
save 300 100
save 60 10000# 關閉AOF
appendonly no
3)拷貝配置文件到每個實例目錄
然后將redis-6.2.4/redis.conf文件拷貝到三個目錄中(在/tmp目錄執行下列命令):
# 方式一:逐個拷貝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
# 方式二:管道組合命令,一鍵拷貝
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf
4)修改每個實例的端口、工作目錄
修改每個文件夾內的配置文件,將端口分別修改為7001、7002、7003,將rdb文件保存位置都修改為自己所在目錄(在/tmp目錄執行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf
5)修改每個實例的聲明IP
虛擬機本身有多個IP,為了避免將來混亂,我們需要在redis.conf文件中指定每一個實例的綁定ip信息,格式如下:
# redis實例的聲明 IP
replica-announce-ip 192.168.150.101
每個目錄都要改,我們一鍵完成修改(在/tmp目錄執行下列命令):
# 逐一執行
sed -i '1a replica-announce-ip 192.168.150.101' 7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7003/redis.conf# 或者一鍵修改
printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf
啟動
為了方便查看日志,我們打開3個ssh窗口,分別啟動3個redis實例,啟動命令:
# 第1個
redis-server 7001/redis.conf
# 第2個
redis-server 7002/redis.conf
# 第3個
redis-server 7003/redis.conf
啟動后:
如果要一鍵停止,可以運行下面命令:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown
開啟主從關系
現在三個實例還沒有任何關系,要配置主從可以使用replicaof 或者slaveof(5.0以前)命令。
有臨時和永久兩種模式:
-
修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
- 在redis.conf中添加一行配置:
-
使用redis-cli客戶端連接到redis服務,執行slaveof命令(重啟后失效):
slaveof <masterip> <masterport>
注意:在5.0以后新增命令replicaof,與salveof效果一致。
這里我們為了演示方便,使用方式二。
通過redis-cli命令連接7002,執行下面命令:
# 連接 7002
redis-cli -p 7002
# 執行slaveof
slaveof 192.168.150.101 7001
通過redis-cli命令連接7003,執行下面命令:
# 連接 7003
redis-cli -p 7003
# 執行slaveof
slaveof 192.168.150.101 7001
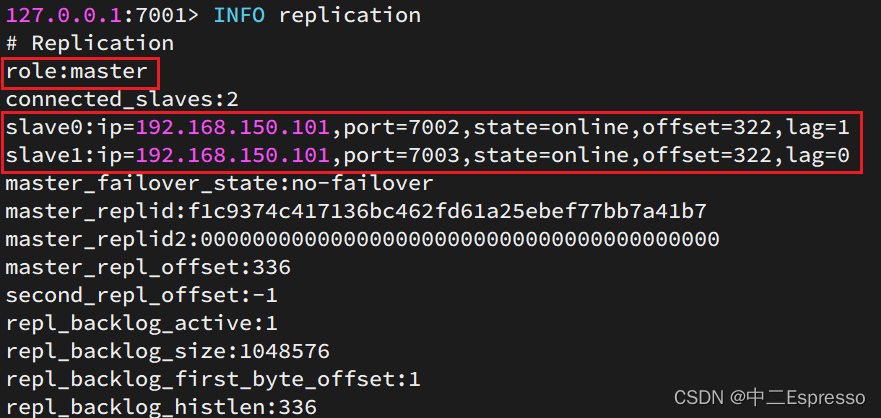
然后連接 7001節點,查看集群狀態:
# 連接 7001
redis-cli -p 7001
# 查看狀態
info replication
結果:
測試
執行下列操作以測試:
-
利用redis-cli連接7001,執行
set num 123 -
利用redis-cli連接7002,執行
get num,再執行set num 666 -
利用redis-cli連接7003,執行
get num,再執行set num 888
可以發現,只有在7001這個master節點上可以執行寫操作,7002和7003這兩個slave節點只能執行讀操作。
2) 數據同步原理(全量同步)
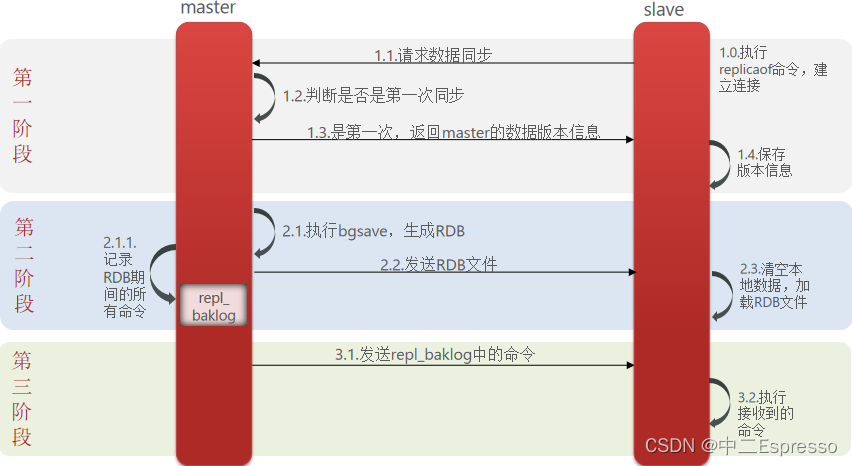
主從第一次同步是全量同步:
master如何判斷slave是不是第一次來同步數據?
- Replication Id:簡稱replid,是數據集的標記,id一致則說明是同一數據集。每一個master都有唯一的replid,slave則會繼承master節點的replid
- offset:偏移量,隨著記錄在repl_baklog中的數據增多而逐漸增大。slave完成同步時也會記錄當前同步的offset。如果slave的offset小于master的offset,說明slave數據落后于master,需要更新。
因此slave做數據同步,必須向master聲明自己的replication id 和offset,master才可以判斷到底需要同步哪些數據
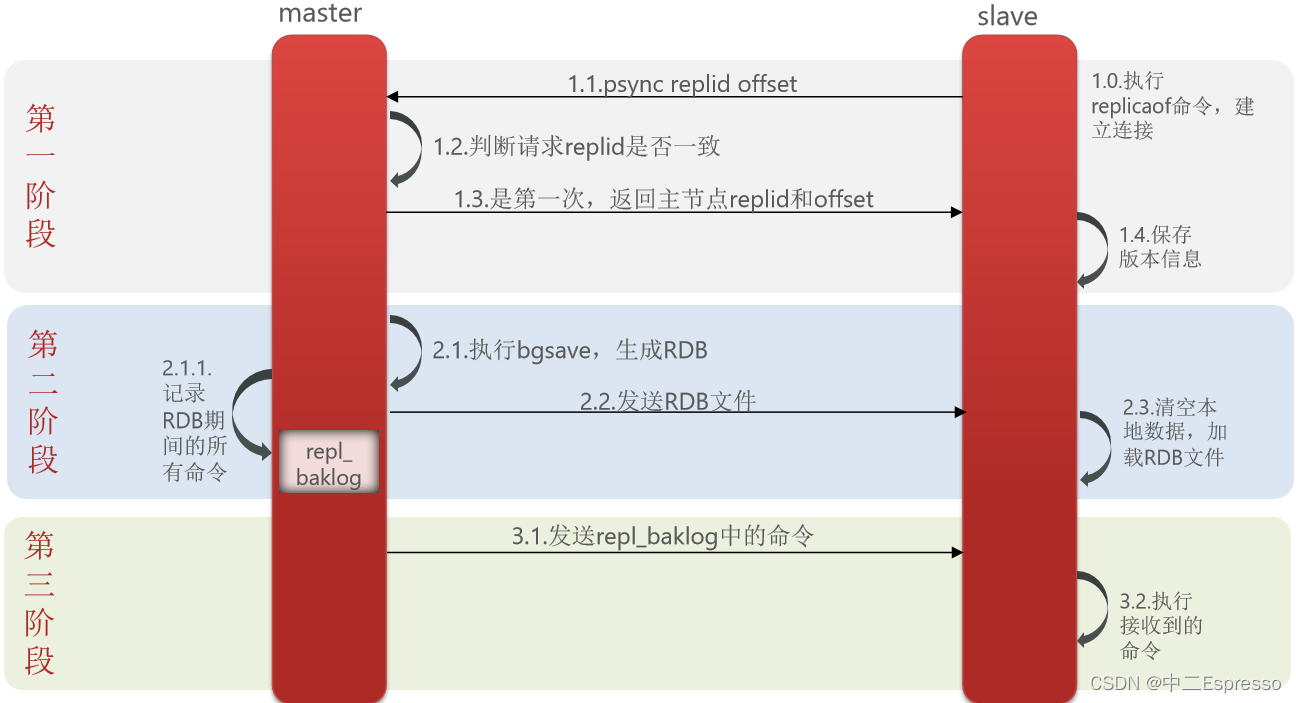
簡述全量同步的流程?
- slave節點請求增量同步
- master節點判斷replid,發現不一致,拒絕增量同步,執行全量同步
- master將完整內存數據生成RDB,發送RDB到slave
- slave清空本地數據,加載master的RDB
- master將RDB期間的命令記錄在repl_baklog,并持續將log中的命令發送給slave
- slave執行接收到的命令,保持與master之間的同步
3) 數據同步原理(增量同步)
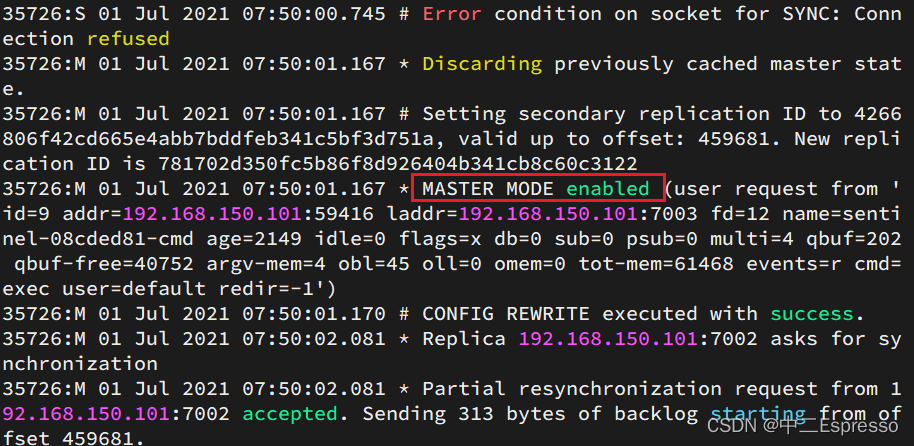
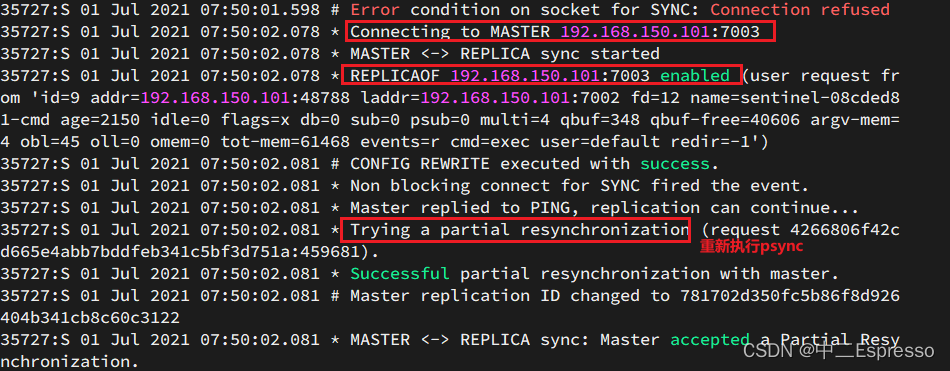
主從第一次同步是全量同步,但如果slave重啟后同步,則執行增量同步
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-Qv8gWjxp-1692354289145)(C:\Users\captaindeng\AppData\Roaming\Typora\typora-user-images\image-20230817161911269.png)]
repl_baklog大小有上限,寫滿后會覆蓋最早的數據。如果slave斷開時間過久,導致尚未備份的數據被覆蓋,則無法基于log做增量同步,只能再次全量同步。
可以從以下幾個方面來優化Redis主從集群:
- 在master中配置repl-diskless-sync yes啟用無磁盤復制(寫入網絡的IO中),避免全量同步時的磁盤IO
- Redis單節點上的內存占用不要太大,減少RDB導致的過多磁盤IO
- 適當提高repl_baklog的大小,發現slave宕機時盡快實現故障恢復,盡可能避免全量同步
- 限制一個master上的slave節點數量,如果實在是太多slave,則可以采用主-從-從鏈式結構,減少master壓力
c.Redis哨兵
1) 哨兵的作用
Redis提供了哨兵(Sentinel)機制來實現主從集群的自動故障恢復。哨兵的結構和作用如下:
- 監控:Sentinel 會不斷檢查您的master和slave是否按預期工作
- 自動故障恢復:如果master故障,Sentinel會將一個slave提升為master。當故障實例恢復后也以新的master為主
- 通知:Sentinel充當Redis客戶端的服務發現來源,當集群發生故障轉移時,會將最新信息推送給Redis的客戶端
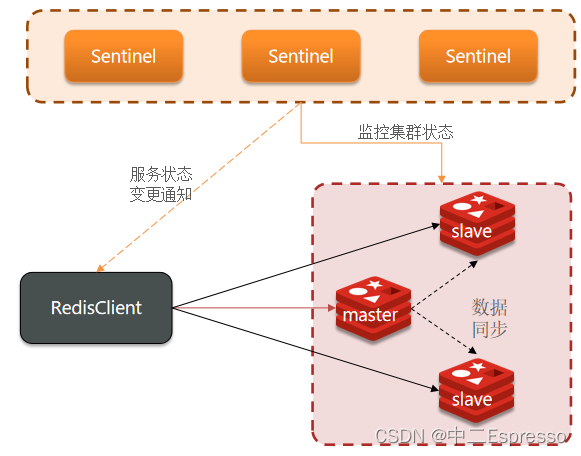
Sentinel基于心跳機制監測服務狀態,每隔1秒向集群的每個實例發送ping命令:
- **主觀下線:**如果某sentinel節點發現某實例未在規定時間響應,則認為該實例主觀下線。
- 客觀下線:若超過指定數量(quorum)的sentinel都認為該實例主觀下線,則該實例客觀下線。quorum值最好超過Sentinel實例數量的一半。
選舉新的master
一旦發現master故障,sentinel需要在salve中選擇一個作為新的master,選擇依據是這樣的:
- 首先會判斷slave節點與master節點斷開時間長短,如果超過指定值(down-after-milliseconds * 10)則會排除該slave節點
- 然后判斷slave節點的slave-priority值,越小優先級越高,如果是0則永不參與選舉
- 如果slave-prority一樣,則判斷slave節點的offset值,越大說明數據越新,優先級越高
- 最后是判斷slave節點的運行id大小,越小優先級越高
如何實現故障轉移
當選中了其中一個slave為新的master后(例如slave1),故障的轉移的步驟如下:
- sentinel給備選的slave1節點發送slaveof no one命令,讓該節點成為master
- sentinel給所有其它slave發送slaveof 192.168.150.101 7002 命令,讓這些slave成為新master的從節點,開始從新的master上同步數據
- 最后,sentinel將故障節點標記為slave,當故障節點恢復后會自動成為新的master的slave節點
2) 搭建Redis哨兵集群
三個sentinel實例信息如下:
| 節點 | IP | PORT |
|---|---|---|
| s1 | 192.168.150.101 | 27001 |
| s2 | 192.168.150.101 | 27002 |
| s3 | 192.168.150.101 | 27003 |
準備實例和配置
要在同一臺虛擬機開啟3個實例,必須準備三份不同的配置文件和目錄,配置文件所在目錄也就是工作目錄。
我們創建三個文件夾,名字分別叫s1、s2、s3:
# 進入/tmp目錄
cd /tmp
# 創建目錄
mkdir s1 s2 s3
如圖:
然后我們在s1目錄創建一個sentinel.conf文件,添加下面的內容:
port 27001
sentinel announce-ip 192.168.150.101
sentinel monitor mymaster 192.168.150.101 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/s1"
解讀:
port 27001:是當前sentinel實例的端口sentinel monitor mymaster 192.168.150.101 7001 2:指定主節點信息mymaster:主節點名稱,自定義,任意寫192.168.150.101 7001:主節點的ip和端口2:選舉master時的quorum值
然后將s1/sentinel.conf文件拷貝到s2、s3兩個目錄中(在/tmp目錄執行下列命令):
# 方式一:逐個拷貝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
# 方式二:管道組合命令,一鍵拷貝
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf
修改s2、s3兩個文件夾內的配置文件,將端口分別修改為27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
啟動
為了方便查看日志,我們打開3個ssh窗口,分別啟動3個redis實例,啟動命令:
# 第1個
redis-sentinel s1/sentinel.conf
# 第2個
redis-sentinel s2/sentinel.conf
# 第3個
redis-sentinel s3/sentinel.conf
啟動后:
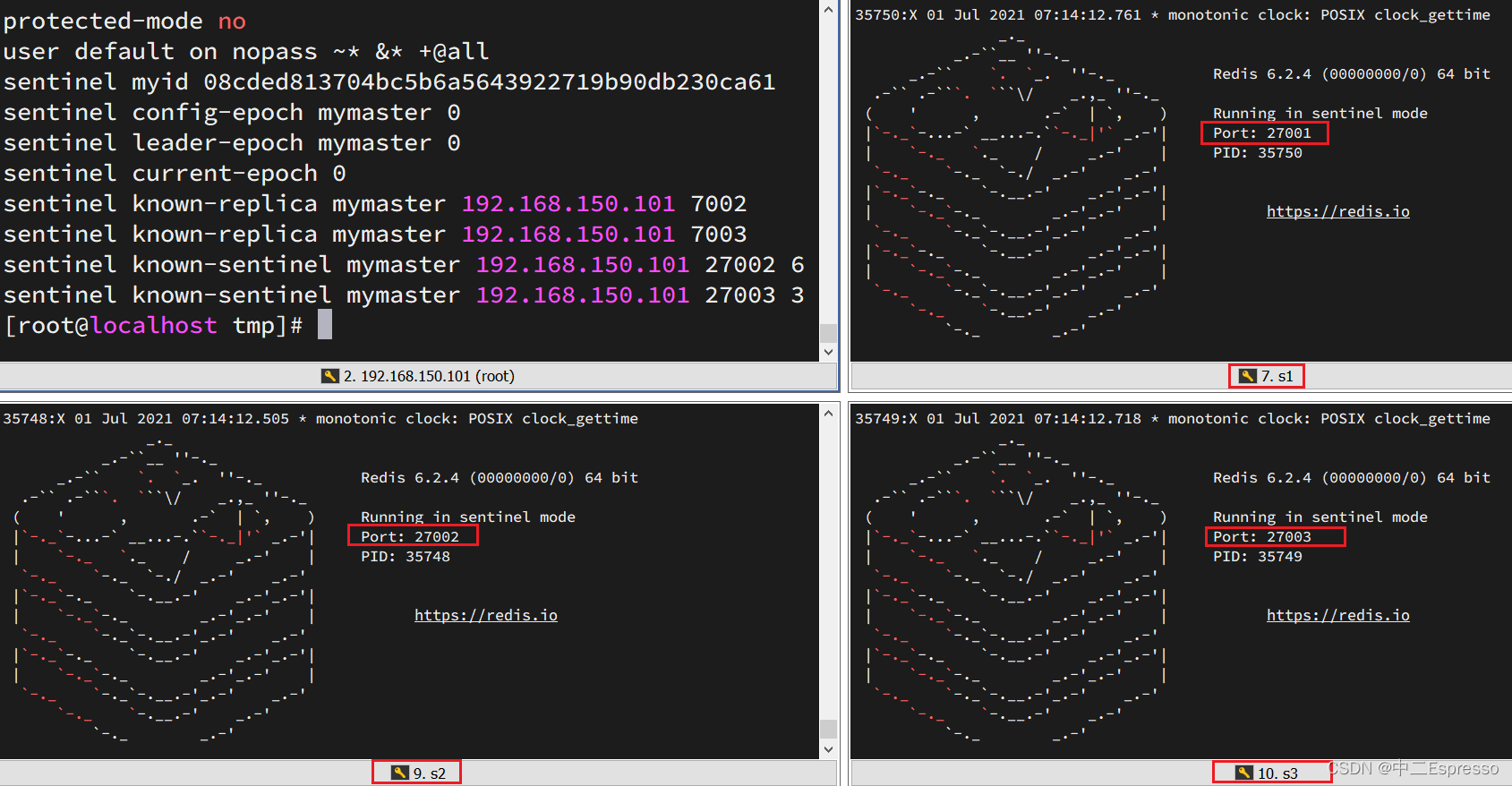
測試
嘗試讓master節點7001宕機,查看sentinel日志:
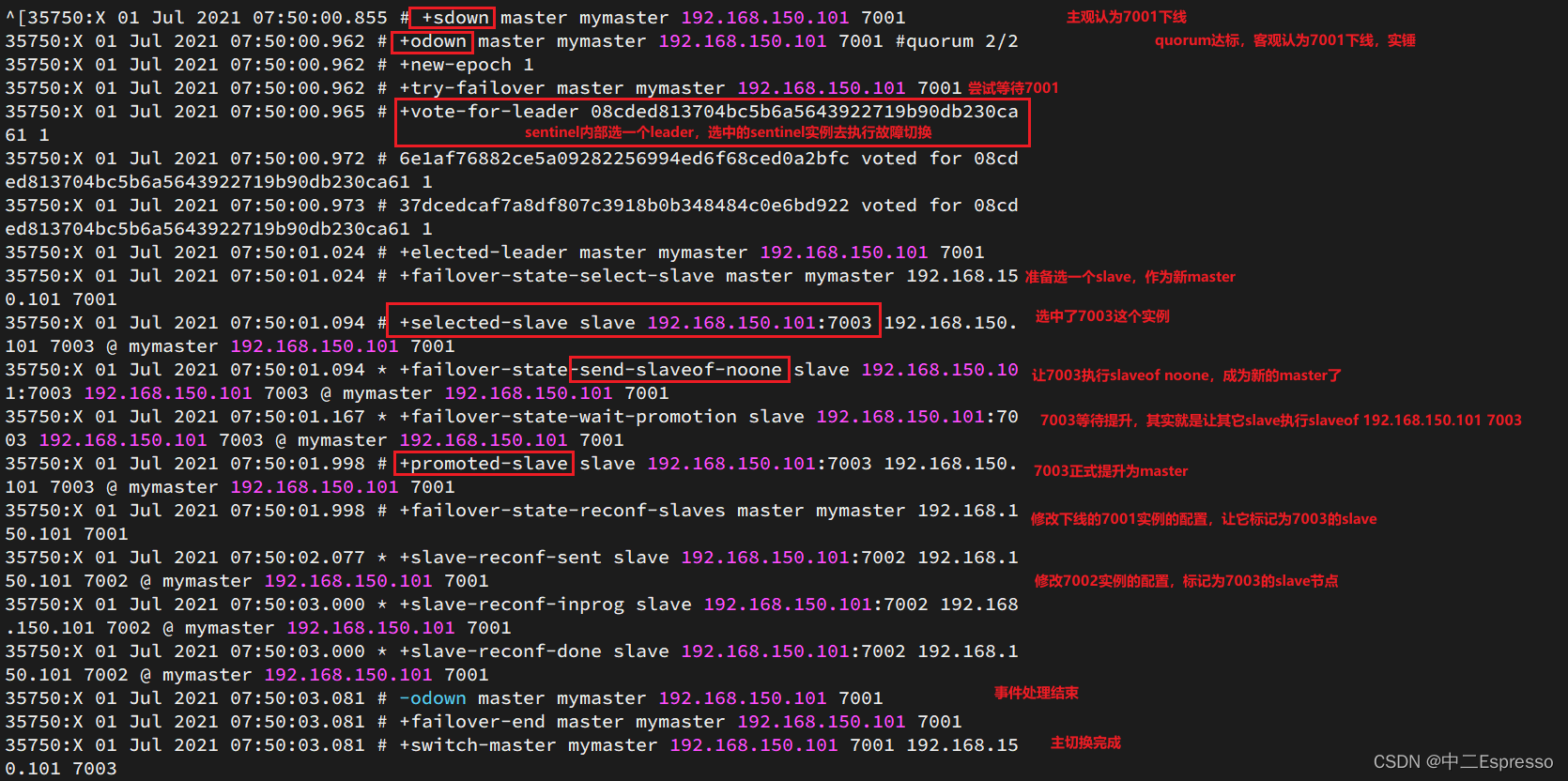
查看7003的日志:
查看7002的日志:
3) RedisTemplate的哨兵模式
在Sentinel集群監管下的Redis主從集群,其節點會因為自動故障轉移而發生變化,Redis的客戶端必須感知這種變化,及時更新連接信息。Spring的RedisTemplate底層利用lettuce實現了節點的感知和自動切換。
1.在pom文件中引入redis的starter依賴:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2.然后在配置文件application.yml中指定sentinel相關信息:
spring:redis:sentinel:master: mymasternodes:- 192.168.200.128:27001- 192.168.200.128:27002- 192.168.200.128:27003
3.配置主從讀寫分離
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer() {return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
ReadFrom是配置Redis的讀取策略,是一個枚舉,包括下面選擇:
- MASTER:從主節點讀取
- MASTER_PREFERRED:優先從master節點讀取,master不可用才讀取replica
- REPLICA:從slave(replica)節點讀取
- REPLICA _PREFERRED:優先從slave(replica)節點讀取,所有的slave都不可用才讀取master
d.Redis分片集群
主從和哨兵可以解決高可用、高并發讀的問題。但是依然有兩個問題沒有解決:
- 海量數據存儲問題
- 高并發寫的問題
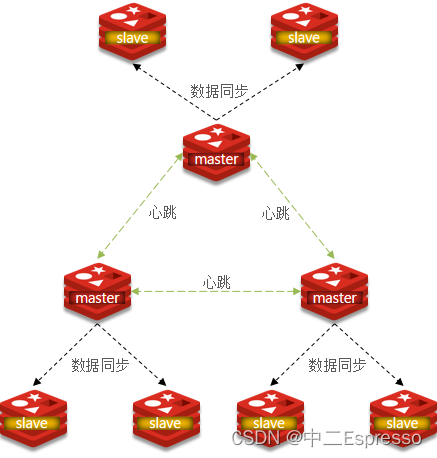
使用分片集群可以解決上述問題,分片集群特征:
- 集群中有多個master,每個master保存不同數據
- 每個master都可以有多個slave節點
- master之間通過ping監測彼此健康狀態
- 客戶端請求可以訪問集群任意節點,最終都會被轉發到正確節點
1) 搭建分片集群
分片集群需要的節點數量較多,這里我們搭建一個最小的分片集群,包含3個master節點,每個master包含一個slave節點
這里我們會在同一臺虛擬機中開啟6個redis實例,模擬分片集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 8001 | slave |
| 192.168.150.101 | 8002 | slave |
| 192.168.150.101 | 8003 | slave |
準備實例和配置
刪除之前的7001、7002、7003這幾個目錄,重新創建出7001、7002、7003、8001、8002、8003目錄:
# 進入/tmp目錄
cd /tmp
# 刪除舊的,避免配置干擾
rm -rf 7001 7002 7003
# 創建目錄
mkdir 7001 7002 7003 8001 8002 8003
在/tmp下準備一個新的redis.conf文件,內容如下:
port 6379
# 開啟集群功能
cluster-enabled yes
# 集群的配置文件名稱,不需要我們創建,由redis自己維護
cluster-config-file /tmp/6379/nodes.conf
# 節點心跳失敗的超時時間
cluster-node-timeout 5000
# 持久化文件存放目錄
dir /tmp/6379
# 綁定地址
bind 0.0.0.0
# 讓redis后臺運行
daemonize yes
# 注冊的實例ip
replica-announce-ip 192.168.150.101
# 保護模式
protected-mode no
# 數據庫數量
databases 1
# 日志
logfile /tmp/6379/run.log
將這個文件拷貝到每個目錄下:
# 進入/tmp目錄
cd /tmp
# 執行拷貝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
修改每個目錄下的redis.conf,將其中的6379修改為與所在目錄一致:
# 進入/tmp目錄
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
啟動
因為已經配置了后臺啟動模式,所以可以直接啟動服務:
# 進入/tmp目錄
cd /tmp
# 一鍵啟動所有服務
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
通過ps查看狀態:
ps -ef | grep redis
發現服務都已經正常啟動:

如果要關閉所有進程,可以執行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill
或者(推薦這種方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown
創建集群
雖然服務啟動了,但是目前每個服務之間都是獨立的,沒有任何關聯。
我們需要執行命令來創建集群,在Redis5.0之前創建集群比較麻煩,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安裝包下的src/redis-trib.rb來實現的。因為redis-trib.rb是有ruby語言編寫的所以需要安裝ruby環境。
# 安裝依賴
yum -y install zlib ruby rubygems
gem install redis
然后通過命令來管理集群:
# 進入redis的src目錄
cd /tmp/redis-6.2.4/src
# 創建集群
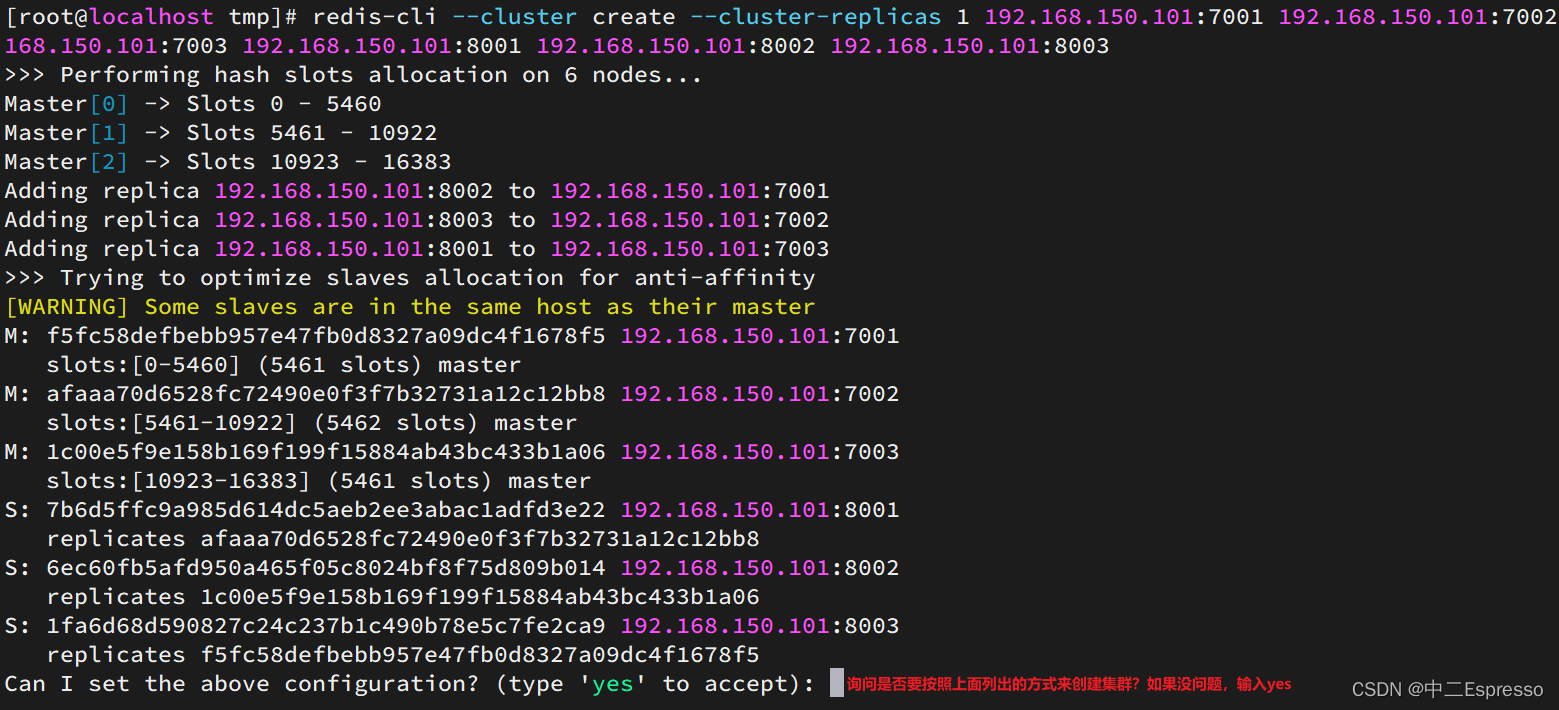
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003
2)Redis5.0以后
集群管理以及集成到了redis-cli中,格式如下:
redis-cli --cluster create --cluster-replicas 1 192.168.200.128:7001 192.168.200.128:7002 192.168.200.128:7003 192.168.200.128:8001 192.168.200.128:8002 192.168.200.128:8003
命令說明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是創建集群--replicas 1或者--cluster-replicas 1:指定集群中每個master的副本個數為1,此時節點總數 ÷ (replicas + 1)得到的就是master的數量。因此節點列表中的前n個就是master,其它節點都是slave節點,隨機分配到不同master
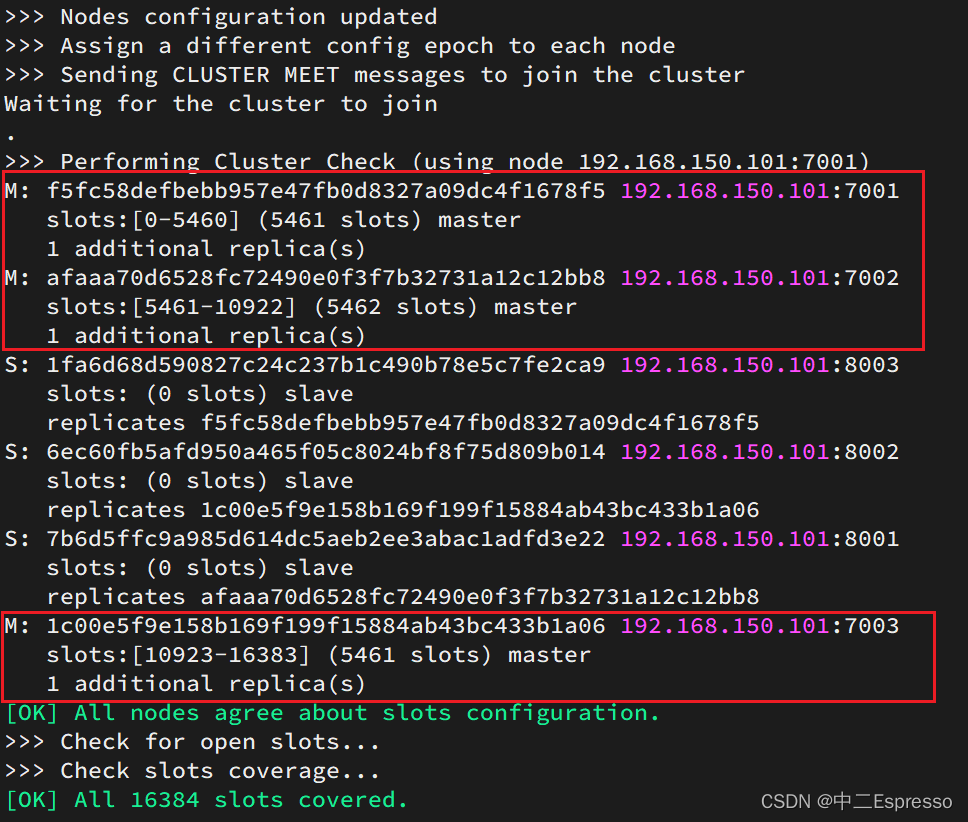
運行后的樣子:
這里輸入yes,則集群開始創建:
通過命令可以查看集群狀態:
redis-cli -p 7001 cluster nodes

測試
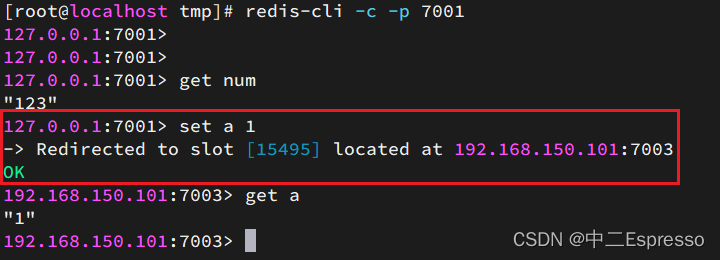
嘗試連接7001節點,存儲一個數據:
# 連接
redis-cli -p 7001
# 存儲數據
set num 123
# 讀取數據
get num
# 再次存儲
set a 1
結果悲劇了:
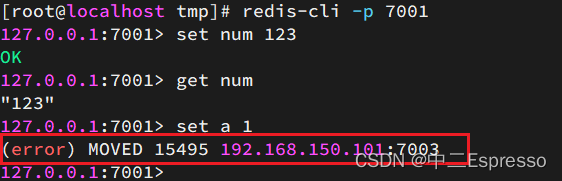
集群操作時,需要給redis-cli加上-c參數才可以:
redis-cli -c -p 7001
這次可以了:
2) 散列插槽
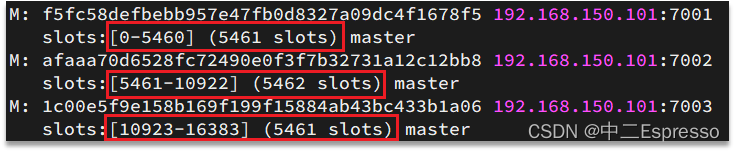
Redis會把每一個master節點映射到0~16383共16384個插槽(hash slot)上,查看集群信息時就能看到:
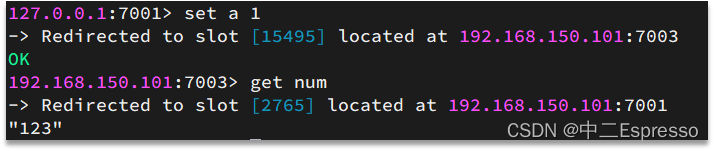
數據key不是與節點綁定,而是與插槽綁定。redis會根據key的有效部分計算插槽值,分兩種情況:
- key中包含"{}",且“{}”中至少包含1個字符,“{}”中的部分是有效部分
- key中不包含“{}”,整個key都是有效部分
例如:key是num,那么就根據num計算,如果是{itcast}num,則根據itcast計算。計算方式是利用CRC16算法得到一個hash值,然后對16384取余,得到的結果就是slot值。
Redis如何判斷某個key應該在哪個實例?
- 將16384個插槽分配到不同的實例
- 根據key的有效部分計算哈希值,對16384取余
- 余數作為插槽,尋找插槽所在實例即可
如何將同一類數據固定的保存在同一個Redis實例?
- 這一類數據使用相同的有效部分,例如key都以{typeId}為前綴
3) 集群伸縮
添加一個節點到集群
redis-cli --cluster提供了很多操作集群的命令,可以通過下面方式查看:
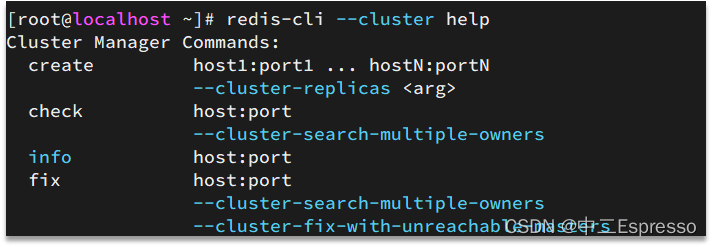
比如,添加節點的命令:
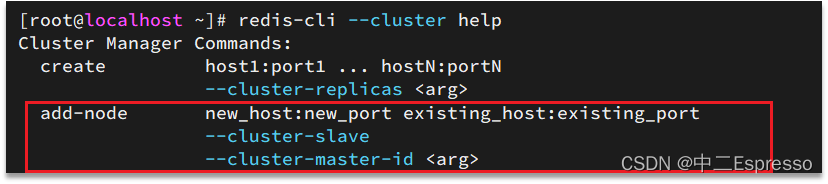
案例:向集群中添加一個新的master節點,并向其中存儲 num = 10
需求:
- 啟動一個新的redis實例,端口為7004
- 添加7004到之前的集群,并作為一個master節點
- 給7004節點分配插槽,使得num這個key可以存儲到7004實例
# 在tmp目錄下,創建新的7004目錄
mkdir 7004
# 拷貝redis.conf到7004目錄下
cp redis.conf 7004
# 將redis.conf的端口號全部替換成7004
sed -i s/6379/7004/g 7004/redis.conf
# 啟動7004的redis
redis-server 7004/redis.conf
# 添加7004到之前的集群中
redis-cli --cluster add-node 192.168.200.128:7004 192.168.200.128:7001
# 將7001的部分插槽移至7004
redis-cli --cluster reshard 192.168.200.128:7001# 提示輸入要移動多少個插槽:3000# 提示輸入接收插槽的id:輸入7004 redis的id# 提示輸入從那個插槽移動:輸入7001 redis的id# 輸入 done# 輸入 yes
# 查看插槽,是否移動成功
redis-cli -p 7001 cluster nodes
# 將num存入redis中
redis-cli -c -p 7004# set num 10
案例:刪除集群中的一個節點
需求:刪除7004這個實例
# 將7004的全部插槽移至7001
redis-cli --cluster reshard 192.168.200.128:7001# 提示輸入要移動多少個插槽:3000# 提示輸入接收插槽的id:輸入7001 redis的id# 提示輸入從那個插槽移動:輸入7004 redis的id# 輸入 done# 輸入 yes
# 查看插槽,是否移動成功。并獲取7004的id
redis-cli -p 7001 cluster nodes
# 刪除7004節點:redis-cli --cluster del-node nodeId
redis-cli --cluster del-node 192.168.200.128:7004 08af8f1fedc0d211bbb94225d3cef59efd75aa6a
4) 故障轉移
Redis集群擁有自動主從切換的功能,無需使用哨兵
當集群中有一個master宕機會發生什么呢?
1.首先是該實例與其它實例失去連接
2.然后是疑似宕機:

3.最后是確定下線,自動提升一個slave為新的master:

數據遷移
利用cluster failover命令可以手動讓集群中的某個master宕機,切換到執行cluster failover命令的這個slave節點,實現無感知的數據遷移。其流程如下:
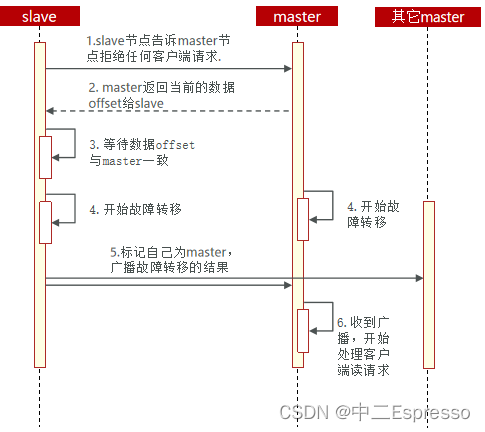
手動的Failover支持三種不同模式:
- 缺省:默認的流程,如圖1~6歩
- force:省略了對offset的一致性校驗
- takeover:直接執行第5歩,忽略數據一致性、忽略master狀態和其它master的意見
案例:在7002這個slave節點執行手動故障轉移,重新奪回master地位
步驟如下:
- 1.利用redis-cli連接7002這個節點
- 2.執行cluster failover命令
# 進入redis 7002的控制臺
redis-cli -p 7002# 在控制臺輸入 cluster failover# 7002將成為master
5) RedisTemplate訪問分片集群
RedisTemplate底層同樣基于lettuce實現了分片集群的支持,而使用的步驟與哨兵模式基本一致:
- 1.引入redis的starter依賴
- 2.配置分片集群地址
- 3.配置讀寫分離
與哨兵模式相比,其中只有分片集群的配置方式略有差異,如下:
spring:redis:cluster:nodes:- 192.168.200.128:7001- 192.168.200.128:7002- 192.168.200.128:7003- 192.168.200.128:8001- 192.168.200.128:8002- 192.168.200.128:8003


)














)

