1. LeNet
LeNet由兩個部分組成:
- 卷積編碼器:由兩個卷積層組成;
- 全連接層密集塊:由三個全連接層組成。

- 每個卷積塊中的基本單元是一個卷積層、一個sigmoid激活函數和平均匯聚層;
- 每個卷積層使用5×5卷積核和一個sigmoid激活函數;
- 這些層將輸入映射到多個二維特征輸出,通常同時增加通道的數量;
- 每個4×4池操作(步幅2)通過空間下采樣將維數減少4倍。
import torch
from torch import nn
from d2l import torch as d2l# 定義模型net
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))
該模型去掉了最后一層的高斯激活,下面將一個大小為28×28的單通道(黑白)圖像通過LeNet,打印每一層輸出的形狀。
# 觀察各層的輸入輸出通道數,寬度和高度
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)

- 第一個卷積層使用2個像素的填充,來補償5×5卷積核導致的特征減少;
- 第二個卷積層沒有填充,因此高度和寬度都減少了4個像素;
- 隨著層疊的上升,通道的數量從輸入時的1個,增加到第一個卷積層之后的6個,再到第二個卷積層之后的16個;
- 每個匯聚層的高度和寬度都減半;
- 每個全連接層減少維數,最終輸出一個維數與結果分類數相匹配的輸出。
2. 模型訓練
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
"""定義精度評估函數:1、將數據集復制到顯存中2、通過調用accuracy計算數據集的精度
"""
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save# 判斷net是否屬于torch.nn.Module類if isinstance(net, nn.Module):net.eval()# 如果不在參數選定的設備,將其傳輸到設備中if not device:device = next(iter(net.parameters())).device# Accumulator是累加器,定義兩個變量:正確預測的數量,總預測的數量。metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:# 將X, y復制到設備中if isinstance(X, list):# BERT微調所需的(之后將介紹)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)# 計算正確預測的數量,總預測的數量,并存儲到metric中metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]
"""定義GPU訓練函數:1、為了使用gpu,首先需要將每一小批量數據移動到指定的設備(例如GPU)上;2、使用Xavier隨機初始化模型參數;3、使用交叉熵損失函數和小批量隨機梯度下降。
"""
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU訓練模型(在第六章定義)"""# 定義初始化參數,對線性層和卷積層生效def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)# 在設備device上進行訓練print('training on', device)net.to(device)# 優化器:隨機梯度下降optimizer = torch.optim.SGD(net.parameters(), lr=lr)# 損失函數:交叉熵損失函數loss = nn.CrossEntropyLoss()# Animator為繪圖函數animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])# 調用Timer函數統計時間timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# Accumulator(3)定義3個變量:損失值,正確預測的數量,總預測的數量metric = d2l.Accumulator(3)net.train()# enumerate() 函數用于將一個可遍歷的數據對象for i, (X, y) in enumerate(train_iter):timer.start() # 進行計時optimizer.zero_grad() # 梯度清零X, y = X.to(device), y.to(device) # 將特征和標簽轉移到devicey_hat = net(X)l = loss(y_hat, y) # 交叉熵損失l.backward() # 進行梯度傳遞返回optimizer.step()with torch.no_grad():# 統計損失、預測正確數和樣本數metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop() # 計時結束train_l = metric[0] / metric[2] # 計算損失train_acc = metric[1] / metric[2] # 計算精度# 進行繪圖if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))# 測試精度test_acc = evaluate_accuracy_gpu(net, test_iter) animator.add(epoch + 1, (None, None, test_acc))# 輸出損失值、訓練精度、測試精度print(f'loss {train_l:.3f}, train acc {train_acc:.3f},'f'test acc {test_acc:.3f}')# 設備的計算能力print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec'f'on {str(device)}')

lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
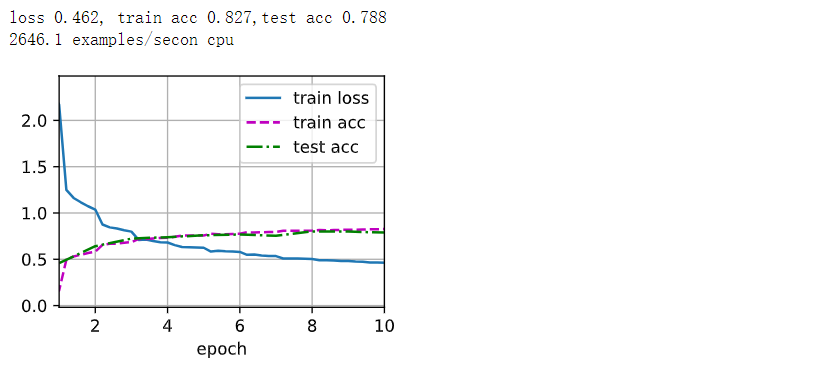
3. 小結
- 卷積神經網絡(CNN)是一類使用卷積層的網絡;
- 卷積神經網絡中,可以組合使用卷積層、非線性激活函數和匯聚層;
- 為了構造高性能的卷積神經網絡,通常對卷積層進行排列,逐漸降低其表示的空間分辨率,同時增加通道數;
- 在傳統的卷積神經網絡中,卷積塊編碼得到的表征在輸出之前需由一個或多個全連接層進行處理。
)



?為什么它在JavaScript中很有用?)





-JS句柄)



)




