
一、說明
????????我已經做了將近十年的數據分析。有時,我使用機器學習技術從數據中獲取見解,并且我習慣于使用經典 ML。
????????雖然我已經通過了神經網絡和深度學習的一些MOOC,但我從未在我的工作中使用過它們,這個領域對我來說似乎很有挑戰性。我有所有這些偏見:
- 你需要學習很多東西才能開始使用深度學習:數學,不同的框架(我至少聽說過其中的三個:和)和網絡的架構。
PyTorchTensorFlowKeras - 需要龐大的數據集來擬合模型。
- 如果沒有強大的計算機(它們還必須具有Nvidia GPU),就不可能獲得像樣的結果,因此很難進行設置。
- 啟動并運行 ML 驅動的服務有很多樣板文件:您需要處理前端和后端端。
????????我相信分析的主要目標是幫助產品團隊根據數據做出正確的決策。如今,神經網絡絕對可以改善我們的分析,即NLP有助于從文本中獲得更多見解。因此,我決定再次嘗試利用深度學習的力量對我有幫助。
????????這就是我開始?Fast.AI 課程的方式(它在 2022 年初更新,所以我想自之前對 TDS 的評論以來,內容已經發生了變化)。我已經意識到使用深度學習解決你的任務并不是那么困難。
????????本課程遵循自上而下的方法。因此,您從構建一個工作系統開始,然后才能更深入地了解所有必需的基礎知識和細微差別。
????????我在第二周制作了我的第一個 ML 驅動的應用程序(你可以在這里嘗試)。?這是一個圖像分類模型,可以識別我最喜歡的狗品種。令人驚訝的是,即使我的數據集中只有幾千張圖像,它也能很好地工作。這讓我感到鼓舞,我們現在可以輕松構建一項十年前完全神奇的服務。

????????因此,在本文中,您將找到有關構建和部署由機器學習提供支持的第一個服務的初學者級教程。
二、什么是深度學習?
????????當我們使用多層神經網絡作為模型時,深度學習是機器學習的一個特定用例。
????????神經網絡非常強大。根據通用近似定理,神經網絡可以近似任何函數,這意味著它們能夠解決任何任務。
????????現在,您可以將此模型視為一個黑盒,它接受輸入(在我們的例子中 - 一個狗圖像)并返回輸出(在我們的例子中 - 一個標簽)。

作者攝
三、構建模型
您可以在Kaggle上找到此階段的完整代碼。
????????我們將使用Kaggle筆記本來構建我們的深度學習模型。如果您還沒有在 Kaggle 上擁有帳戶,那么值得通過注冊過程。Kaggle是數據科學家的流行平臺,您可以在其中查找數據集,參加競賽以及運行和共享代碼。
????????您可以在 Kaggle 上創建一個筆記本,并在此處執行代碼,就像在本地 Jupyter 筆記本中一樣。Kaggle甚至提供了GPU,因此我們將能夠非常快速地訓練NN模型。

圖片來源:作者
讓我們從導入所有包開始,因為我們將使用許多 Fast.AI 工具。
from fastcore.all import *
from fastai.vision.all import *
from fastai.vision.widgets import *
from fastdownload import download_url四、加載數據
????????不言而喻,我們需要一個數據集來訓練我們的模型。獲取一組圖像的最簡單方法是使用搜索引擎。
DuckDuckGo搜索引擎有一個易于使用的API和方便的Python包(更多信息),所以我們將使用它。duckduckgo_search
????????讓我們嘗試搜索狗的圖像。我們已指定僅使用具有知識共享許可的圖像。license_image = any
from duckduckgo_search import DDGS
import itertools
with DDGS() as ddgs:res = list(itertools.islice(ddgs.images('photo samoyed happy', license_image = 'any'), 1))????????在輸出中,我們獲得了有關圖像的所有信息:名稱,URL和大小。
{"title": "Happy Samoyed dog photo and wallpaper. Beautiful Happy Samoyed dog picture", "image": "http://www.dogwallpapers.net/wallpapers/happy-samoyed-dog-wallpaper.jpg", "thumbnail": "https://tse2.mm.bing.net/th?id=OIP.BqTE8dYqO-W9qcCXdGcF6QHaFL&pid=Api", "url": "http://www.dogwallpapers.net/samoyed-dog/happy-samoyed-dog-wallpaper.html", "height": 834, "width": 1193, "source": "Bing"
}????????現在我們可以使用 Fast.AI 工具下載圖像并顯示縮略圖。

攝影:Barcs Tamás on?Unsplash
????????我們看到一個快樂的薩摩耶德,這意味著它正在工作。因此,讓我們加載更多照片。
????????我的目標是確定五種不同的狗品種(我最喜歡的品種)。我將為每個品種加載圖片并將它們存儲在單獨的目錄中。
breeds = ['siberian husky', 'corgi', 'pomeranian', 'retriever', 'samoyed']
path = Path('dogs_breeds') # defining pathfor b in tqdm.tqdm(breeds):dest = (path/b)dest.mkdir(exist_ok=True, parents=True) download_images(dest, urls=search_images(f'photo {b}'))sleep(10) download_images(dest, urls=search_images(f'photo {b} puppy'))sleep(10) download_images(dest, urls=search_images(f'photo {b} sleep'))sleep(10) resize_images(path/b, max_size=400, dest=path/b)運行此代碼后,您將在Kaggle的右側面板上看到所有加載的照片。

圖片來源:作者
????????下一步是將數據轉換為適合 Fast.AI 模型的格式 — 。DataBlock
????????您需要為此對象指定一些參數,但我將只強調最重要的參數:
splitter=RandomSplitter(valid_pct=0.2, seed=18):Fast.AI 要求您選擇一個驗證集。驗證集是將用于估計模型質量的保留數據。訓練期間不會使用驗證數據來防止過度擬合。在我們的例子中,驗證集是數據集的隨機 20%。我們指定了參數,以便下次能夠重現完全相同的拆分。seeditem_tfms=[Resize(256, method=’squish’)]:神經網絡批量處理圖像。這就是為什么我們必須擁有相同大小的圖片。圖像大小調整有不同的方法,我們現在使用 squish,但我們稍后會更詳細地討論它。
????????我們已經定義了一個數據塊。該函數可以向我們顯示一組帶有標簽的隨機圖像。show_batch

攝影:Angel Luciano?on?Unsplash?|攝影:Brigitta Botrágyi?on?Unsplash?|攝影:Charlotte Freeman?on?Unsplash
數據看起來不錯,所以讓我們繼續訓練。
五、訓練模型
您可能會感到驚訝,但下面的兩行代碼將完成所有工作。

????????我們使用了預訓練模型(具有 18 個深層的卷積神經網絡 — )。這就是為什么我們稱該函數。Resnet18fine_tune
????????我們對模型進行了三個時期的訓練,這意味著模型看到了整個數據集 3 次。
????????我們還指定了指標 — (正確標記的圖片的份額)。您可以在每個紀元后的結果中看到此指標(僅使用驗證集計算,以免扭曲結果)。但是,它不會在優化過程中使用,僅供您參考。accuracy
????????整個過程大約需要 30 分鐘,現在我們的模型可以預測狗的品種,準確率為 94.45%。干得好!但是我們能改善這個結果嗎?
六、改進模型:數據清理和擴充
如果希望看到第一個模型盡快工作,請隨時將本部分留到以后,并轉到模型的部署。
????????首先,讓我們看看模型的錯誤:它是否無法區分柯基犬和哈士奇犬或博美犬和獵犬。我們可以使用它。請注意,混淆矩陣也僅使用驗證集進行計算。confusion_matrix

????????Fast.AI 課程中分享的另一個生活技巧是可以使用模型來清理我們的數據。對于它,我們可以看到損失最高的圖像:可能是模型錯誤但置信度高或正確但置信度低的情況。

攝影:Benjamin Vang在Unsplash?|攝影:Xennie Moore?on?Unsplash?|攝影:Alvan Nee?on?Unsplash
????????顯然,第一張圖片的標簽不正確,而第二張圖片同時包含哈士奇和柯基。所以有一些改進的余地。
????????幸運的是,Fast.AI 提供了一個方便的小部件,可以幫助我們快速解決數據問題。可以在筆記本中對其進行初始化,然后可以更改數據集中的標簽。ImageClassifierCleaner
cleaner = ImageClassifierCleaner(learn)
cleaner ????????在每個類別之后,您可以運行以下代碼來解決問題:刪除圖像或將其移動到正確的文件夾。
for idx in cleaner.delete(): cleaner.fns[idx].unlink()
for idx,breed in cleaner.change(): shutil.move(str(cleaner.fns[idx]), path/breed)現在我們可以再次訓練我們的模型,并看到準確率有所提高:95.4% vs 94.5%。

正確識別的柯基犬的比例從88%增加到96%。明!

????????改進模型的另一種方法是更改調整大小的方法。我們使用了擠壓方法,但如您所見,它可以改變自然物體的比例。讓我們嘗試更具想象力并使用增強功能。
????????增強是對圖像的更改(例如,對比度改進、旋轉或裁剪)。它將為我們的模型提供更多可變數據,并有望提高其質量。
????????與 Fast.AI 一樣,您只需更改幾個參數即可添加增強功能。

照片由FLOUFFY在Unsplash上拍攝
????????此外,由于使用增強模型在每個時期都會看到略有不同的圖片,因此我們可以增加時期的數量。經過六個時期,我們達到了 95.65% 的準確率——結果要好一些。整個過程花了大約一個小時。
七、下載模型
????????最后一步是下載我們的模型。這很簡單。
learn.export('cuttest_dogs_model.pkl')????????然后,您將保存一個標準文件(用于存儲對象的常見Python格式)。只需選擇Kaggle筆記本右側面板中的文件旁邊,您就可以在計算機上獲得模型。pickleMore actions

現在我們有了經過訓練的模型,讓我們部署它,以便您可以與世界共享結果。
八、部署模型
我們將使用HuggingFace?Spaces和Gradio來構建我們的Web應用程序。
8.1 設置HuggingFace空間
????????HuggingFace是一家為機器學習提供便捷工具的公司,例如,流行的轉換器庫或共享模型和數據集的工具。今天,我們將使用他們的空間來托管我們的應用程序。
????????首先,如果您尚未注冊,則需要創建一個帳戶。只需幾分鐘。點擊此鏈接。
????????現在是時候創建一個新的空間了。前往“空間”選項卡,然后按“創建”按鈕。您可以在文檔中找到包含更多詳細信息的說明。
????????然后,您需要指定以下參數:
- 名稱(它將用于您的應用程序URL,因此請明智地選擇),
- 許可證(我選擇了開源 Apache 2.0 許可證)
- SDK(在本例中我將使用 Gradio)。

????????Then user-friendly HuggingFace shows you instructions.?TL;DR?now you have a Git repository, and you need to commit your code there.
????????Git 有一個細微差別。由于您的模型可能非常大,因此最好設置 Git LFS(大文件存儲),然后 Git 不會跟蹤此文件的所有更改。要進行安裝,請按照站點上的說明進行操作。
-- cloning repo
git clone https://huggingface.co/spaces/<your_login>/<your_app_name>
cd <your_app_name>-- setting up git-lfs
git lfs install
git lfs track "*.pkl"
git add .gitattributes
git commit -m "update gitattributes to use lfs for pkl files"8.2? Gradio?
? ????????Gradio是一個框架,允許你只使用Python構建愉快和友好的Web應用程序。這就是為什么它是原型設計的寶貴工具(特別是對于像我這樣沒有深厚JavaScript知識的人來說)。
????????在 Gradio 中,我們將定義我們的接口,指定以下參數:
- 輸入?— 圖像,
- 輸出?— 具有五個可能類的標簽,
- 標題、描述和一組示例圖像(我們還必須將它們提交到 repo),
enable_queue=True將幫助應用程序處理大量流量,如果它變得非常流行,- 要為輸入圖像執行的函數。
????????為了獲取輸入圖像的標簽,我們需要定義一個預測函數,該函數加載我們的模型并返回一個字典,其中包含每個類的概率。
????????最后,我們將有以下代碼app.py
import gradio as gr
from fastai.vision.all import *learn = load_learner('cuttest_dogs_model.pkl')labels = learn.dls.vocab # list of model classes
def predict(img):img = PILImage.create(img)pred,pred_idx,probs = learn.predict(img)return {labels[i]: float(probs[i]) for i in range(len(labels))}gr.Interface(fn=predict,inputs=gr.inputs.Image(shape=(512, 512)),outputs=gr.outputs.Label(num_top_classes=5),title="The Cuttest Dogs Classifier 🐶🐕🦮🐕?🦺",description="Classifier trainded on images of huskies, retrievers, pomeranians, corgis and samoyeds. Created as a demo for Deep Learning app using HuggingFace Spaces & Gradio.",examples=['husky.jpg', 'retriever.jpg', 'corgi.jpg', 'pomeranian.jpg', 'samoyed.jpg'],enable_queue=True).launch()????????如果您想了解有關 Gradio 的更多信息,請閱讀文檔。
????????讓我們也創建文件,然后這個庫將安裝在我們的服務器上。requirements.txtfastai
????????所以剩下的唯一一點就是將所有內容推送到 HuggingFace Git 存儲庫。
git add *
git commit -am 'First version of Cuttest Dogs app'
git push您可以在?GitHub?上找到完整的代碼。
????????推送文件后,返回 HuggingFace 空間,你會看到一張類似的圖片,展示了構建過程。如果一切正常,您的應用將在幾分鐘內運行。

如果有任何問題,您將看到堆棧跟蹤。然后,您將不得不返回到代碼,修復錯誤,推送新版本,然后再等待幾分鐘。
8.3 開始啟動
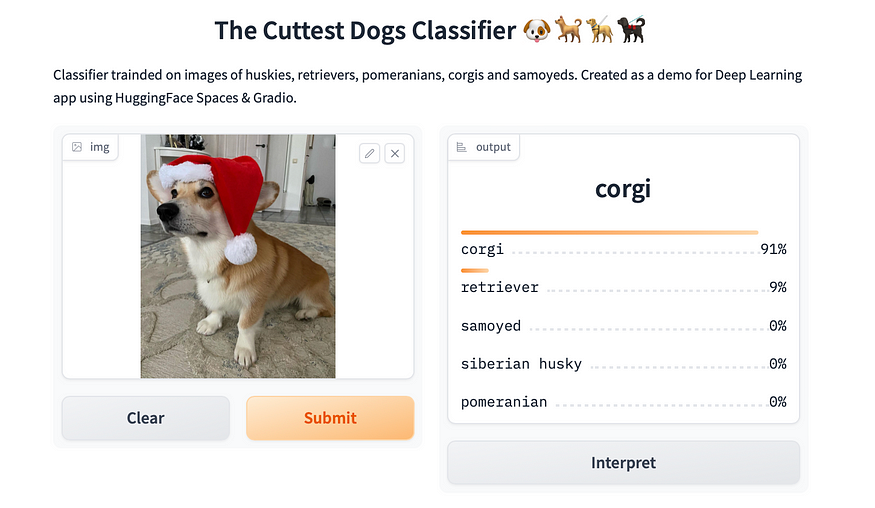
????????現在我們可以使用這個模型和真實照片來驗證我家的狗實際上是柯基犬。
九 后記
????????今天,我們已經完成了構建深度學習應用程序的整個過程:從獲取數據集和擬合模型到編寫和部署 Web 應用程序。希望您能夠完成本教程,現在您正在生產中測試您的出色模型。


)
:下載與安裝)

)





![[Go版]算法通關村第十一關青銅——理解位運算的規則](http://pic.xiahunao.cn/[Go版]算法通關村第十一關青銅——理解位運算的規則)







