1.前言
RDD
JAVA中的IO
1.小知識點穿插
1. 裝飾者設計模式
裝飾者設計模式:本身功能不變,擴展功能.
舉例: 數據流的讀取
一層一層的包裝,進而將功能進行進一步的擴展

2.sleep和wait的區別
本質區別是字體不一樣,sleep斜體,wait正常
斜體是靜態方法
sleep:靜態方法,和對象無關
t1.sleep 當前休眠的不是t1線程,而是調用方法的線程,如果在主線程運行,調用的就是主線程,
與對象無關,得不到對象鎖
wait :成員方法 ,與對象相關
t2.wait 當前等待的線程是t2線程
能得到對象鎖,能釋放.
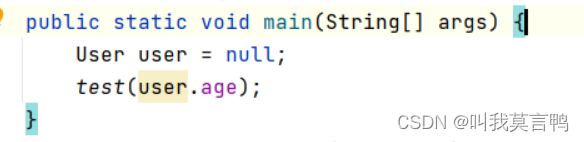
空指針異常:調用一個為null的對象的成員屬性或成員方法,會發生空指針異常,
注意 是成員的 ,如果是靜態的,與動態就無關了.
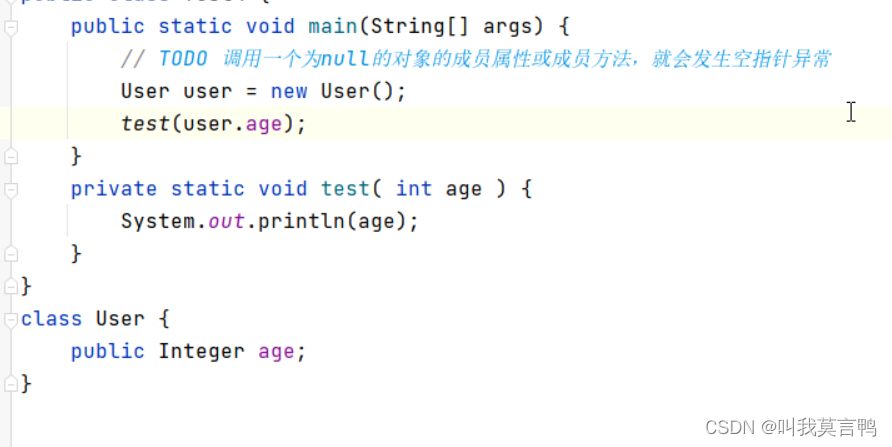
為什么會出現空指針?
報錯的時候,給的是.class的位置,不一定完全對應java的問題,
去看字節碼Terminal 輸入javap -c +名稱 -v的話,更詳細

intValue是一個成員方法,但是此時age沒有賦值,是null, 空對象的成員方法調用
this與super

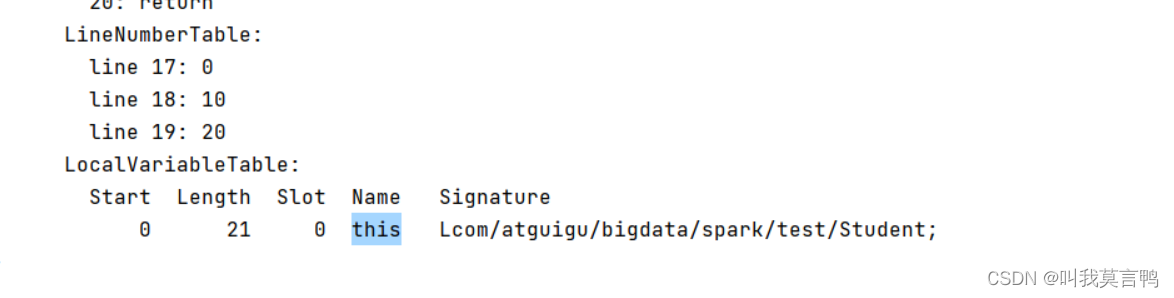
this是當前方法的局部變量,
super只在編譯時出現,this可以在運行時出現
3.關于import *
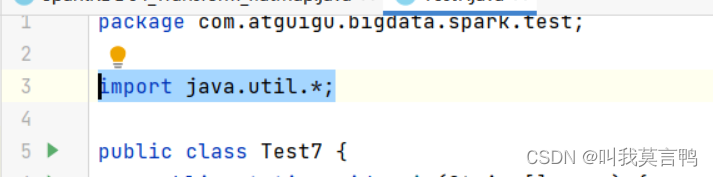
這個是給javac 用的,讓javac自動去找
編譯成.class 時,需要什么就導什么,而不是全部都導
2.正題
1.注意點 切片與讀取的不同
HADOOP切片邏輯是均分
但是讀取數據進行分區保存時,不能均分,
HADOOP是按行讀,而不是字節,
為啥HADOOP按行讀取,一行就是一個業務數據
但是切片是均分,指的是字節均分
2.hadoop讀取按照偏移量讀取,同一個數據的偏移量不能被重復讀取,也就是必須重來?
5+2+1+2+6 =16
4個分區,能均分
4個分區,讀按行讀,所以最后一個是空 數據傾斜
2.轉換算子
1.是什么?
Transformation轉換算子
轉換方法
算子是個啥?
認知心理學 解決問題的狀態: 初始狀態(提出問題) -> 解決 不強調過程
轉換:一個東西變成另外一個東西
所謂的轉換算子,就是調用RDD對象的功能(方法)轉變成一個新RDD





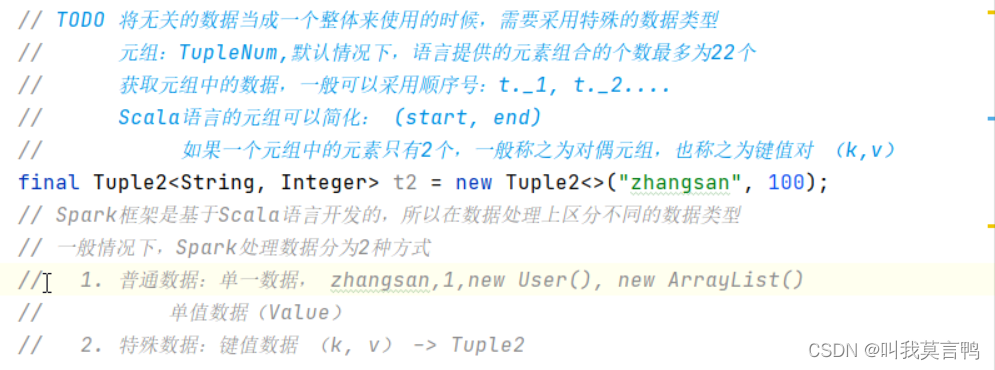
元組,需要先知道一共多少個數據, 默認元組最多為22個
元組是專門用來存放無關數據的,不同數據類型也能存
取的時候

如果元組中元素就兩個,稱為對偶元組,也稱為鍵值對
RDD不保存(處理后的)數據,RDD是容器,但是容器是工具,存儲數據的,是數組,鏈表,而不是容器

加這個才能將類中的方法可以進行函數式
只需要考慮方法輸入輸出

因為必須有返回值,馬丁知道,所以return 可以省略
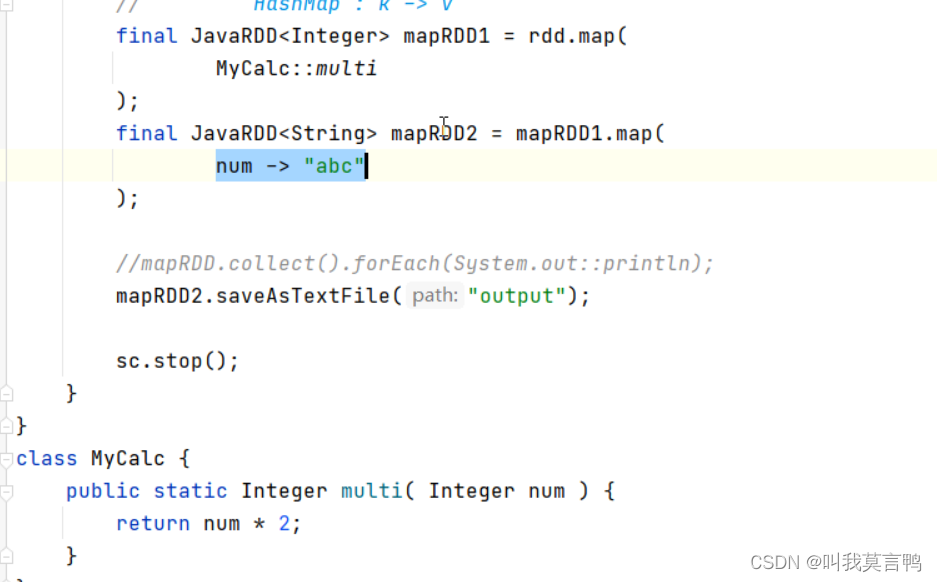
想省略參數,得有方法
如果一個整體需要拆分成多個個體,這種操作,叫做扁平化
Flat就是變
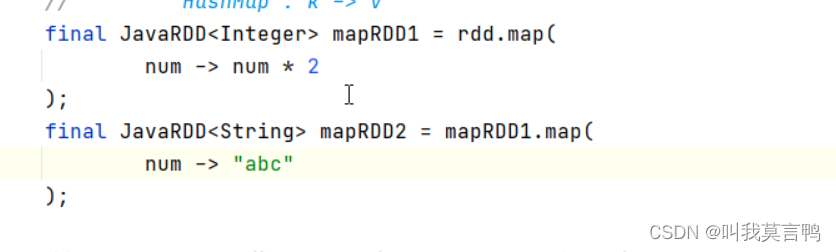
3.map
一個輸入 一個輸出 不能一個輸入多個輸出
package com.atguigu.core.rdd.transform;import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;public class SparkRDDmap {public static void main(String[] args) {JavaSparkContext sc = new JavaSparkContext("local[*]","SPARK_mapT");List<Integer> dataList = Arrays.asList(1,2,3,4);JavaRDD<Integer> rdd = sc.parallelize(dataList, 3);JavaRDD<Integer> rddMap = rdd.map(in -> in * 2);// 用流的形式進行操作rddMap.collect().forEach(System.out::println);sc.stop();}
}
4.flatMap
1.flatMap與Map的區別
map:一個輸入,一個輸出 做不到一個輸入多個輸出 也做不到多個輸入少個輸出
flatmap 扁平化 一個輸入 n個輸出 n(0和任意正整數)
整體拆成個體,但是每個個體都要使用
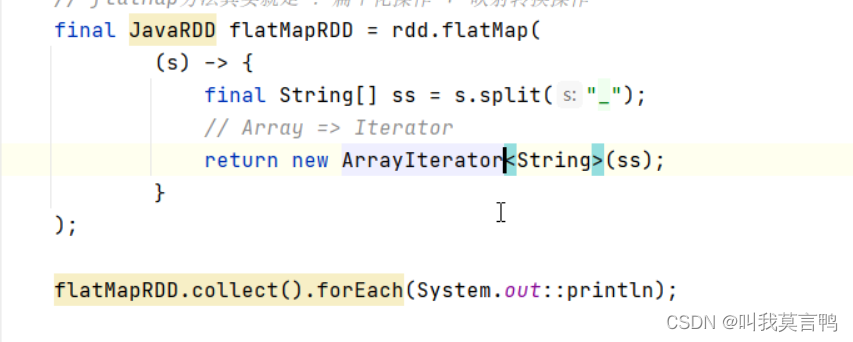
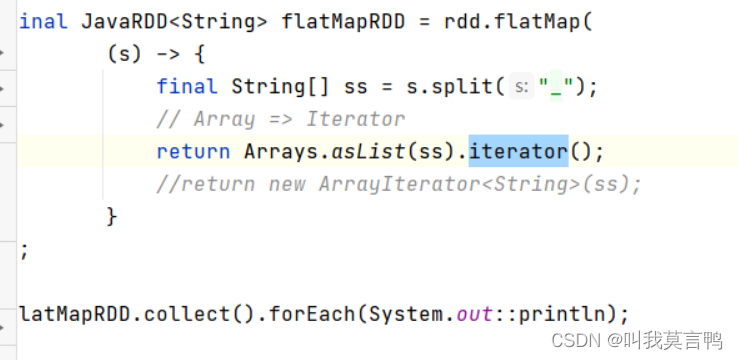
注意,這里的return 是泛型(不加也行) ,也可以是迭代器
5.分組
1.注意點 一個組的數據必定在一個分區
分組不是分區,分組是將數據按組劃分,是將所有數據重新進行劃分,按組成編制,
本來數據是單獨放入區中的,而現在的數據,是以組為單位放入區的,而不是說一個分區里面只能有一個組,分組與分區,無關
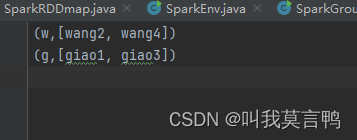
Spark的分組,一個組的數據放置在一個分區中(把之前的分區聚合了)

組是輸出 組內數據是輸入
輸出 就是分組規則
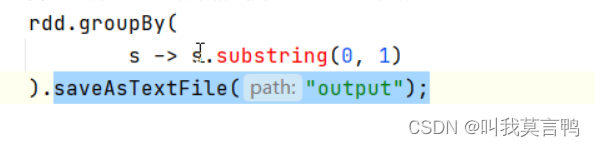
這種寫法,直接. 中間結果不會在內存中留下
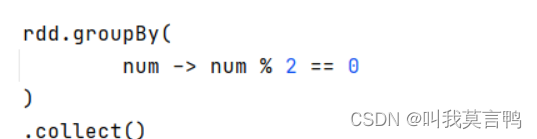
奇偶分組,這個的組名是true false
奇偶分組,去掉==0時,組名為0 1
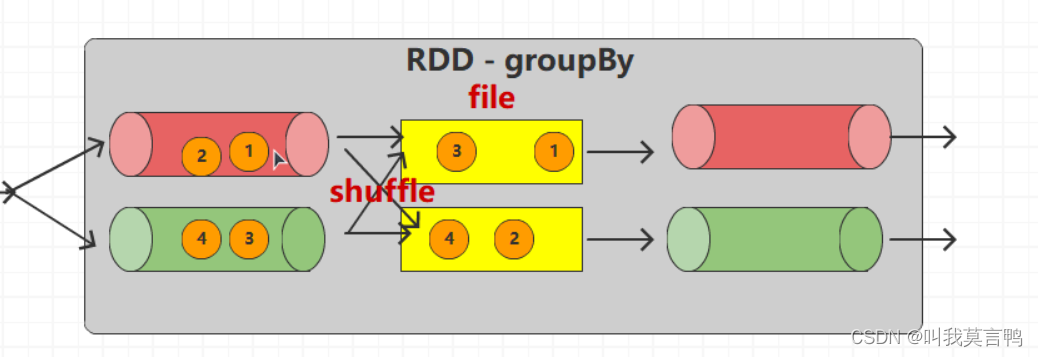
分組過程中,將已分組的數據先放入磁盤,分完組,重新按組分流,動態改變分區數量
默認分區數是不變的,這里主動修改分區數,才改變的


![[Go版]算法通關村第十一關青銅——理解位運算的規則](http://pic.xiahunao.cn/[Go版]算法通關村第十一關青銅——理解位運算的規則)












——手動實現ArrayList 源碼的初步理解分析 數組插入數據和刪除數據的問題)



