一、前言
自從大模型被炒的越來越火之后,似乎國內涌現出很多希望基于大模型構建本地知識庫的需求,大概在5月底的時候,當時Quivr發布了第一個0.0.1版本,第一個版本僅僅只是使用LangChain技術結合OpenAI的GPT模型實現了一個最基本的架子,功能并不夠完善,但可以研究研究思路,當時 Quivr 通過借助于GPT的模型能力,選擇Supabase構建向量數據庫來實現個人知識庫還算是一個不錯的選擇,自此一直有在關注 Quivr 的進展,基本上Quivr的更新頻率還是比較高的,5月底寫了一篇關于如何在本地基于Quivr構建知識庫的文章之后,陸陸續續基本上都有一些朋友私聊詢問有關Quivr構建的一些問題,也有一些對于Quivr未來功能規劃方向的建議和期望,如果Quivr發展的比較成熟,對于個人或者中小企業或許也是一個低成本的選擇。
隨著這兩個多月的更新,Quivr已經陸續發布了五十多個版本,不管是對原來功能的改進,代碼的重構,還是擴展了很多新功能,都讓Quivr看起來沒有原來那么弱小了,基礎的功能基本上也覆蓋到了。感興趣的可以嘗試一下。
對于原來發布的文章和視頻,有感興趣的可以從下面的鏈接進去,因為Quivr一直在更新,在部署方面可能有些許變化,如果想部署最新版本的Quivr,可以直接看這篇最新的升級篇即可。
[文章]Quivr 基于Supabase構建本地知識庫
[視頻]Quivr 基于Supabase構建本地知識庫
二、功能特性
2.1、大腦擴展能力
從單個賬號只支持一個大腦,到現在可以支持多個大腦(具體數量可以配置,默認為5個),這樣部署一套Quivr系統就可以創建多個大腦來對知識庫進行分開維護,減少數據的檢索范圍和數據權限隔離。
用戶可以根據偏好來自定義知識庫,比如針對產品的智能客服、針對交付的Q&A助理、產品經理助手等等。
2.2、大腦權限控制
支持對單個知識庫根據[瀏覽]、[編輯]、[所有者]三個角色來設置對應的訪問權限,同時也支持通過鏈接和郵件的方式分享個人大腦給其他用戶。
這樣就可以很方便的實現個人私有知識庫,或者是公司團隊共享的知識庫,而避免了以前每個用戶都需要重復上傳相同的知識,導致Key的浪費和知識的冗余。
2.3、LLM擴展能力
原來的版本只支持集成GPT和Claude模型,現在擴展了對本地開源模型的支持,如GPT4All,后續還將支持更多的開源模型。
2.4、開放API接口
Quivr采用前后端分離的獨立架構,Quivr 使用 FastAPI 為后端提供 RESTful API,后端服務可以獨立使用,不需要前端應用程序,我們的第三方應用也可以很方便的通過API接口集成Quivr大腦的我們自己的產品中
三、基礎環境準備
3.1、先決條件
為了減少部署過程中不必要的麻煩,建議操作系統選擇Ubuntu 22或更高版本,至于服務器只要能正常訪問OpenAI的接口都可以,我在GCP/AWS/阿里云上都安裝過,主要解決網絡問題,選對服務器所在區域即可。
系統內存:如果只是個人用來部署玩一下,建議不少于1GB,2GB比較合適,如果想用于正式環境,則需根據具體的業務訪問量配置。
系統硬盤:僅僅部署演示,建議不少于30GB。
接下來將演示在 Ubuntu 22 版本上快速部署Quivr來構建本地知識庫系統。
3.2、安裝Docker & Docker-Compose
首先安裝 Docker 和 Docker Compose ,可以按照以下步驟進行操作:
1、更新系統軟件包列表:
sudo apt update
2、安裝Docker依賴的軟件包:
sudo apt install apt-transport-https ca-certificates curl software-properties-common
3、添加Docker官方的GPG密鑰:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
4、添加Docker的軟件源:
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
5、更新軟件包列表:
sudo apt update
6、安裝Docker Engine:
sudo apt install docker-ce docker-ce-cli containerd.io
7、驗證Docker是否正確安裝:
sudo docker run hello-world
8、安裝Docker Compose:
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
9、添加執行權限:
sudo chmod +x /usr/local/bin/docker-compose
10、驗證Docker Compose是否正確安裝:
docker-compose --version
現在,您已經成功在Ubuntu上安裝了Docker和Docker Compose。您可以使用這些命令來管理和運行容器化的應用程序。
錯誤:failed to update store for object type *libnetwork.endpointCnt: Key not found in store
Restart docker deamon would fix it.For ubuntu:sudo service docker restart
四、創建Supabase項目
Supabase是一個開源的Firebase替代品。使用 Postgres 數據庫、身份驗證、即時 API、邊緣函數、實時訂閱、存儲和向量嵌入。一個免費賬戶可以創建2個項目。
1、注冊賬戶
前往https://supabase.com/可以注冊免費賬戶。
2、創建項目
 ?
??
?
?
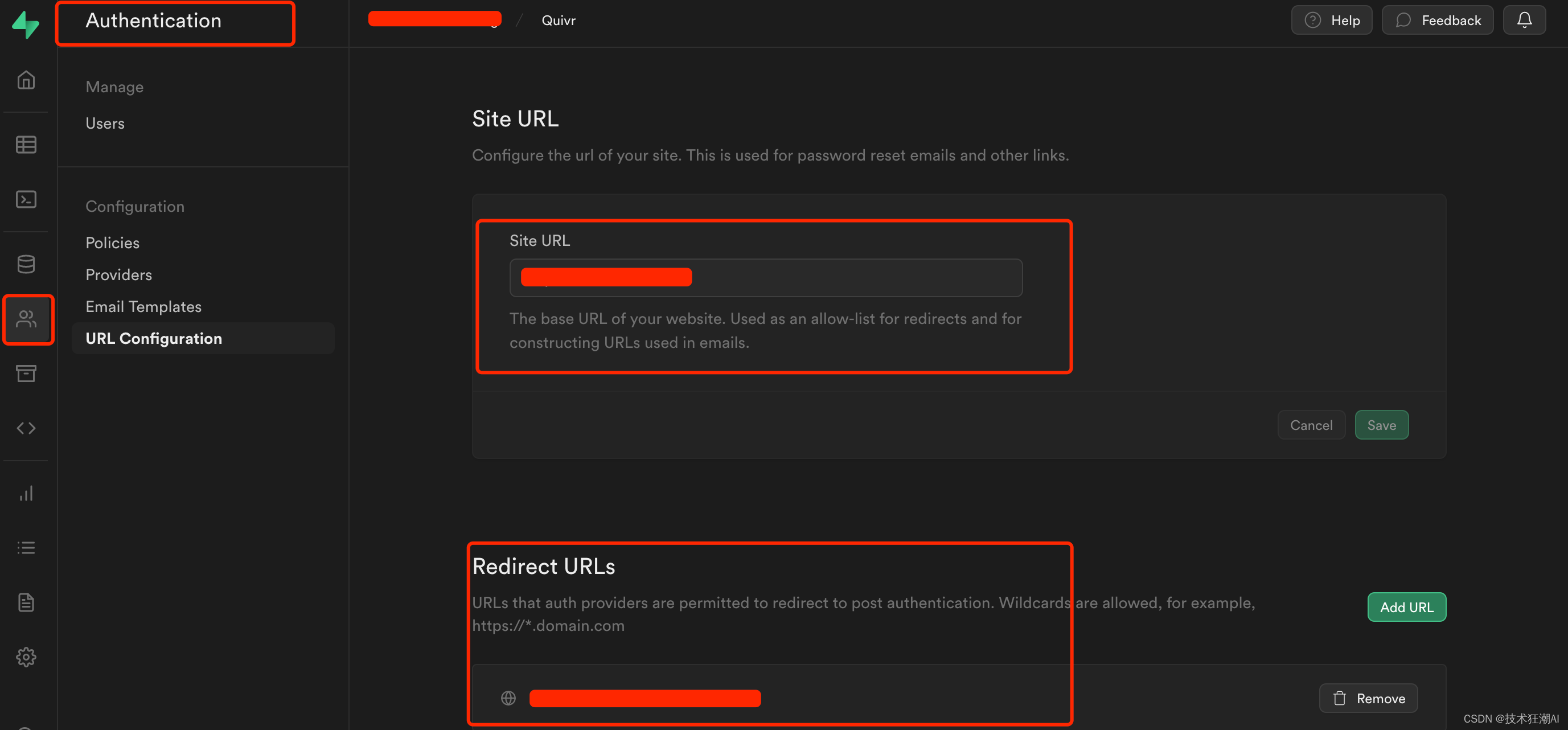
3、配置網站URL和重定向地址
主要用于密碼重置和電子郵件重定向跳轉鏈接。地址為系統前端訪問地址:http://ip:3000
?
 ?
??
?
五、部署Quivr應用
5.1、克隆存儲庫
git clone https://github.com/StanGirard/Quivr.git && cd Quivr
- 可以使用 ls -alh 命令查看所有文件(包含隱藏文件)
一般Quivr每周都會在主分支更新新的內容,會存在一定未知的bug,建議選擇一個最新的release穩定版本進行部署
 ?
??
5.2、復制.XXXXX_env文件
新版本后端代碼重構了,新的配置文件注意在backend/core/目錄下面。
cp .backend_env.example backend/core/.env
cp .frontend_env.example frontend/.env
5.3、更新frontend/.env文件
NEXT_PUBLIC_ENV=local
NEXT_PUBLIC_BACKEND_URL=http://你的IP:5050/
NEXT_PUBLIC_SUPABASE_URL=your supabase project url
NEXT_PUBLIC_SUPABASE_ANON_KEY=your supabase api key
NEXT_PUBLIC_JUNE_API_KEY=your june api key請注意,如果Quivr部署在本機電腦,backend_url直接使用localhost,如果Quivr部署在本地服務器或者云服務器則需要將后端URL修改為你服務器的實際的IP地址。(很多人會忽略這個配置!)
關于NEXT_PUBLIC_JUNE_API_KEY屬性的配置說明:
Quivr 集成了 June Analytics 提供的API接口,在集成了June Analytics 之后,你只需要在系統中配置正確的June API密鑰(即June key),然后June網站會自動開始收集和跟蹤系統的數據。
一旦數據開始被收集,你可以登錄到June Analytics的儀表板,并在其中查看和分析收集到的數據。June儀表板提供了一個用戶友好的界面,用于瀏覽各種報告、圖表和指標,以便你了解用戶行為、事件觸發和其他關鍵指標。
通過June儀表板,你可以探索不同的分析視圖,如用戶活動、事件追蹤、轉化率等。你可以根據時間范圍、特定用戶或自定義事件來過濾和細化數據,以獲取更具體的見解和洞察。
如果是正式上線的站點,可以按需選擇接入,默認可以不用考慮設置此參數,如果需要收集和分析網站的數據,可以去注冊June賬號,申請一個June Key:
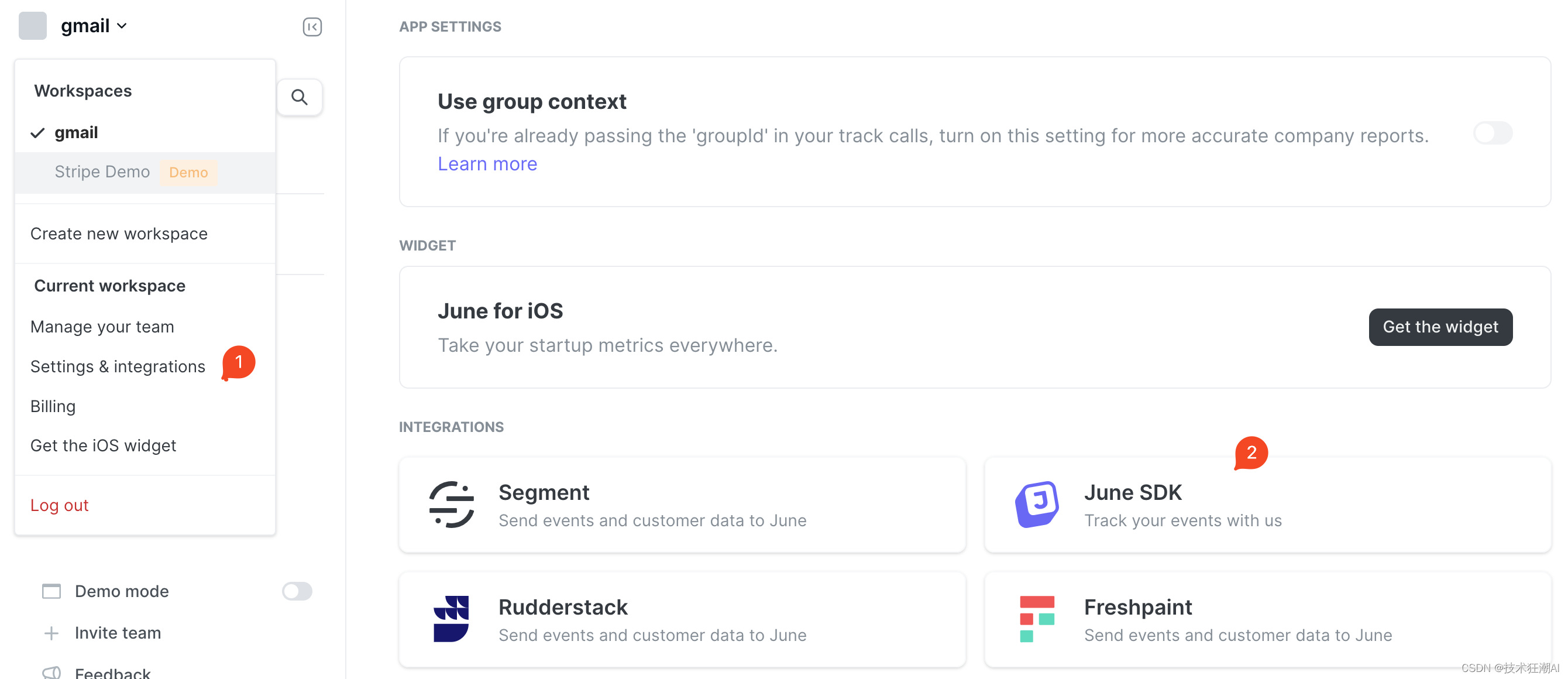
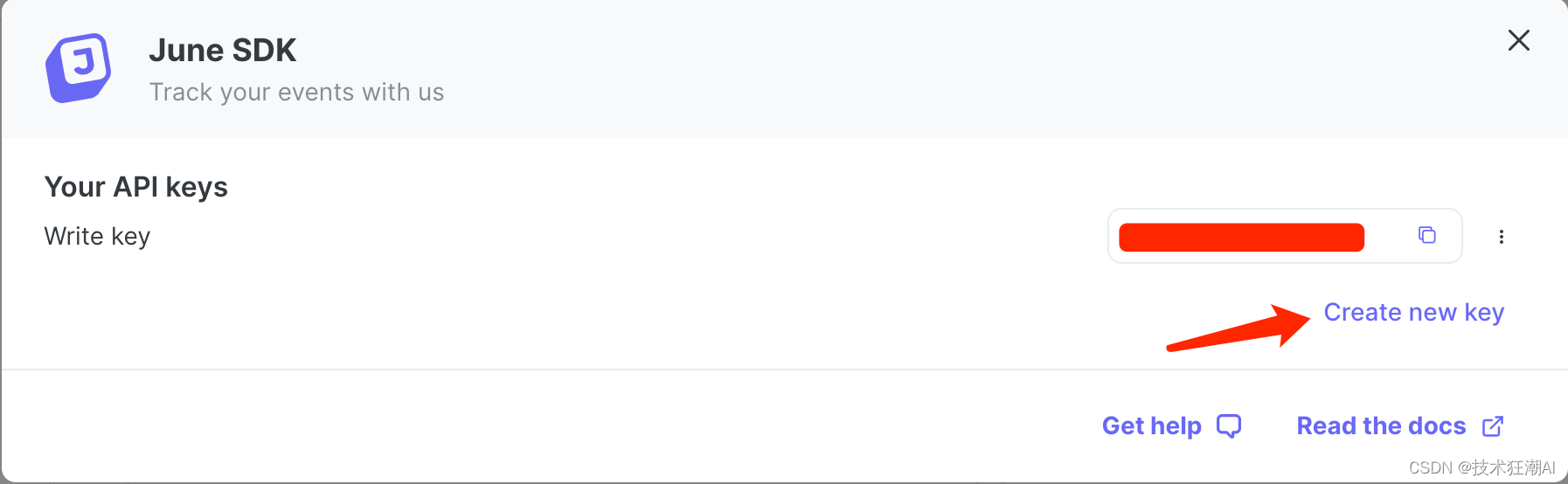 ?5.4、更新backend/core/.env文件?
?5.4、更新backend/core/.env文件?
SUPABASE_URL=your supabase project url
SUPABASE_SERVICE_KEY=your supabase api key
PG_DATABASE_URL=notimplementedyet
OPENAI_API_KEY=your openai api key
ANTHROPIC_API_KEY=null
JWT_SECRET_KEY=your supabase jwt secret keyAUTHENTICATE=true
GOOGLE_APPLICATION_CREDENTIALS=<change-me>
GOOGLE_CLOUD_PROJECT=<change-me># 默認50M
MAX_BRAIN_SIZE=52428800.
MAX_REQUESTS_NUMBER=2000
MAX_BRAIN_PER_USER=100# Private LLM Variables
PRIVATE=False
MODEL_PATH=./local_models/ggml-gpt4all-j-v1.3-groovy.bin# RESEND
RESEND_API_KEY=your resend api key
RESEND_EMAIL_ADDRESS=your resend email address請注意,supabase_url在您的Supabase儀表板下的項目設置-> API中對應的Project URL,supabase_service_key在您的Supabase儀表板下的項目設置-> API中找到。使用“Project API keys”部分中找到的anon public鍵。您 JWT_SECRET_KEY可以在 Project Settings -> JWT Settings -> JWT Secret 下的 supabase 設置中找到。(注意ANTHROPIC_API_KEY可以不配置值,但key不能刪除,否則構建會失敗)

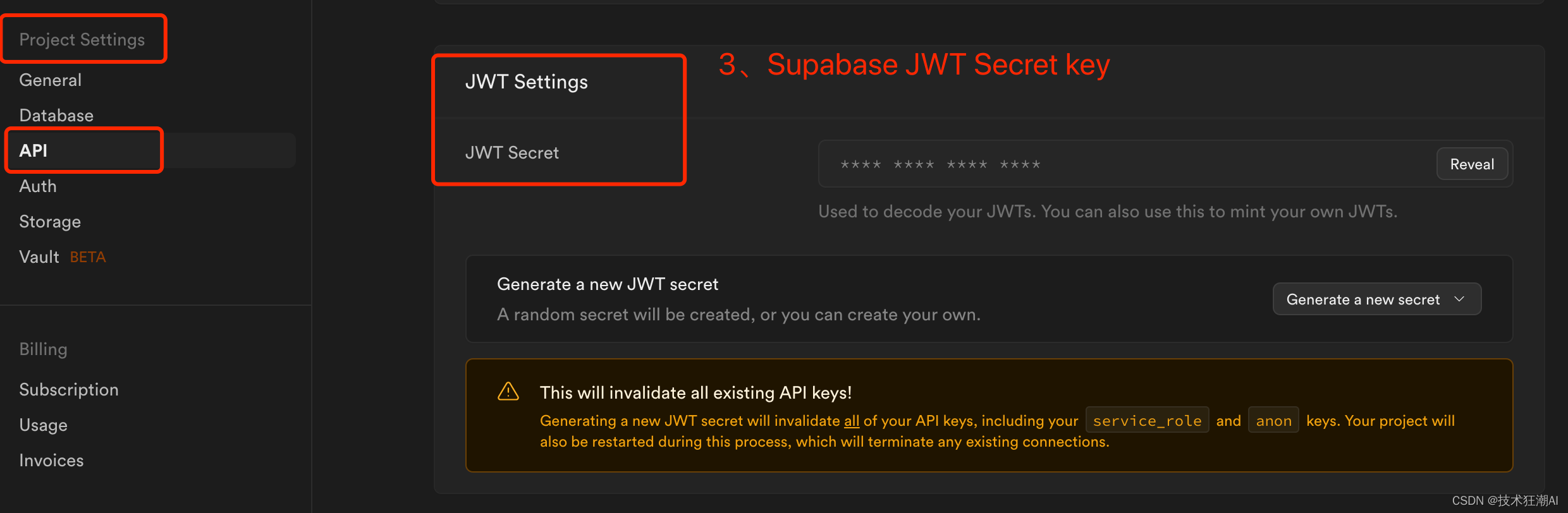
5.5、創建Supabase數據庫和表
通過Web界面(SQL編輯器->“New Query”)在Supabase數據庫上運行以下遷移腳本。
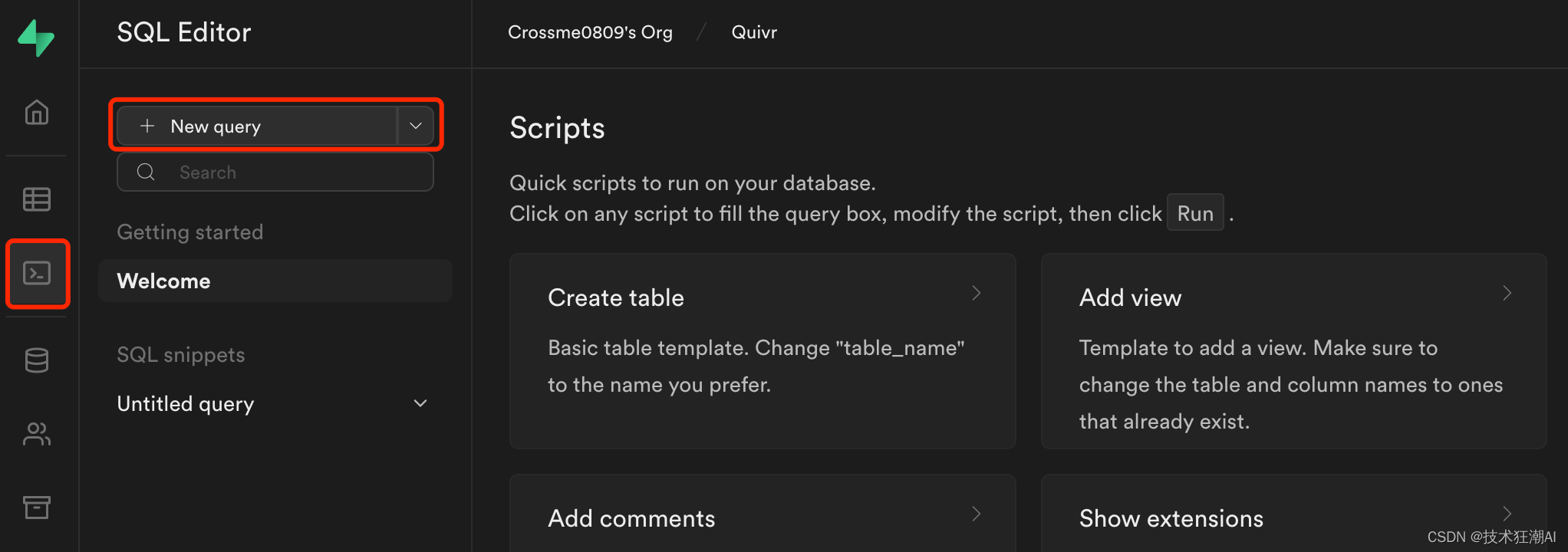
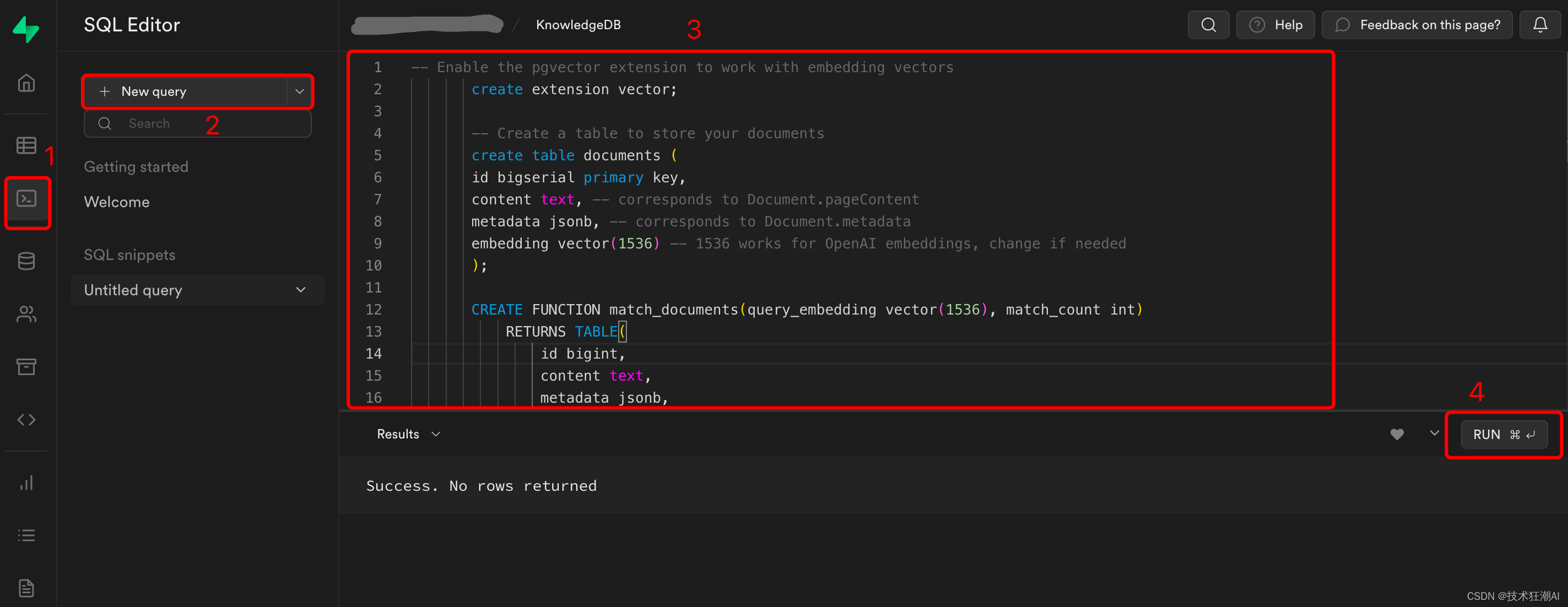
數據庫腳本地址:
https://github.com/StanGirard/quivr/blob/main/scripts/tables.sql
-- Create users table
CREATE TABLE IF NOT EXISTS users(user_id UUID REFERENCES auth.users (id),email TEXT,date TEXT,requests_count INT,PRIMARY KEY (user_id, date)
);-- Create chats table
CREATE TABLE IF NOT EXISTS chats(chat_id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,user_id UUID REFERENCES auth.users (id),creation_time TIMESTAMP DEFAULT current_timestamp,history JSONB,chat_name TEXT
);-- Create vector extension
CREATE EXTENSION IF NOT EXISTS vector;-- Create vectors table
CREATE TABLE IF NOT EXISTS vectors (id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,content TEXT,metadata JSONB,embedding VECTOR(1536)
);-- Create function to match vectors
CREATE OR REPLACE FUNCTION match_vectors(query_embedding VECTOR(1536), match_count INT, p_brain_id UUID)
RETURNS TABLE(id UUID,brain_id UUID,content TEXT,metadata JSONB,embedding VECTOR(1536),similarity FLOAT
) LANGUAGE plpgsql AS $$
#variable_conflict use_column
BEGINRETURN QUERYSELECTvectors.id,brains_vectors.brain_id,vectors.content,vectors.metadata,vectors.embedding,1 - (vectors.embedding <=> query_embedding) AS similarityFROMvectorsINNER JOINbrains_vectors ON vectors.id = brains_vectors.vector_idWHERE brains_vectors.brain_id = p_brain_idORDER BYvectors.embedding <=> query_embeddingLIMIT match_count;
END;
$$;-- Create stats table
CREATE TABLE IF NOT EXISTS stats (time TIMESTAMP,chat BOOLEAN,embedding BOOLEAN,details TEXT,metadata JSONB,id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY
);-- Create summaries table
CREATE TABLE IF NOT EXISTS summaries (id BIGSERIAL PRIMARY KEY,document_id UUID REFERENCES vectors(id),content TEXT,metadata JSONB,embedding VECTOR(1536)
);-- Create function to match summaries
CREATE OR REPLACE FUNCTION match_summaries(query_embedding VECTOR(1536), match_count INT, match_threshold FLOAT)
RETURNS TABLE(id BIGINT,document_id UUID,content TEXT,metadata JSONB,embedding VECTOR(1536),similarity FLOAT
) LANGUAGE plpgsql AS $$
#variable_conflict use_column
BEGINRETURN QUERYSELECTid,document_id,content,metadata,embedding,1 - (summaries.embedding <=> query_embedding) AS similarityFROMsummariesWHERE 1 - (summaries.embedding <=> query_embedding) > match_thresholdORDER BYsummaries.embedding <=> query_embeddingLIMIT match_count;
END;
$$;-- Create api_keys table
CREATE TABLE IF NOT EXISTS api_keys(key_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,user_id UUID REFERENCES auth.users (id),api_key TEXT UNIQUE,creation_time TIMESTAMP DEFAULT current_timestamp,deleted_time TIMESTAMP,is_active BOOLEAN DEFAULT true
);--- Create prompts table
CREATE TABLE IF NOT EXISTS prompts (id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,title VARCHAR(255),content TEXT,status VARCHAR(255) DEFAULT 'private'
);--- Create brains table
CREATE TABLE IF NOT EXISTS brains (brain_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,name TEXT NOT NULL,status TEXT,description TEXT,model TEXT,max_tokens INT,temperature FLOAT,openai_api_key TEXT,prompt_id UUID REFERENCES prompts(id)
);-- Create chat_history table
CREATE TABLE IF NOT EXISTS chat_history (message_id UUID DEFAULT uuid_generate_v4(),chat_id UUID REFERENCES chats(chat_id),user_message TEXT,assistant TEXT,message_time TIMESTAMP DEFAULT current_timestamp,PRIMARY KEY (chat_id, message_id),prompt_id UUID REFERENCES prompts(id),brain_id UUID REFERENCES brains(brain_id)
);-- Create brains X users table
CREATE TABLE IF NOT EXISTS brains_users (brain_id UUID,user_id UUID,rights VARCHAR(255),default_brain BOOLEAN DEFAULT false,PRIMARY KEY (brain_id, user_id),FOREIGN KEY (user_id) REFERENCES auth.users (id),FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);-- Create brains X vectors table
CREATE TABLE IF NOT EXISTS brains_vectors (brain_id UUID,vector_id UUID,file_sha1 TEXT,PRIMARY KEY (brain_id, vector_id),FOREIGN KEY (vector_id) REFERENCES vectors (id),FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);-- Create brains X vectors table
CREATE TABLE IF NOT EXISTS brain_subscription_invitations (brain_id UUID,email VARCHAR(255),rights VARCHAR(255),PRIMARY KEY (brain_id, email),FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
);--- Create user_identity table
CREATE TABLE IF NOT EXISTS user_identity (user_id UUID PRIMARY KEY,openai_api_key VARCHAR(255)
);CREATE OR REPLACE FUNCTION public.get_user_email_by_user_id(user_id uuid)
RETURNS TABLE (email text)
SECURITY definer
AS $$
BEGINRETURN QUERY SELECT au.email::text FROM auth.users au WHERE au.id = user_id;
END;
$$ LANGUAGE plpgsql;CREATE OR REPLACE FUNCTION public.get_user_id_by_user_email(user_email text)
RETURNS TABLE (user_id uuid)
SECURITY DEFINER
AS $$
BEGINRETURN QUERY SELECT au.id::uuid FROM auth.users au WHERE au.email = user_email;
END;
$$ LANGUAGE plpgsql;CREATE TABLE IF NOT EXISTS migrations (name VARCHAR(255) PRIMARY KEY,executed_at TIMESTAMPTZ DEFAULT current_timestamp
);INSERT INTO migrations (name)
SELECT '20230809154300_add_prompt_id_brain_id_to_chat_history_table'
WHERE NOT EXISTS (SELECT 1 FROM migrations WHERE name = '20230809154300_add_prompt_id_brain_id_to_chat_history_table'
);數據庫腳本執行完成后,在Table編輯器中可以看到已經創建完成的表。

5.6、設置yarn的超時時間
在前端容器構建依賴階段一般會比較慢,部分依賴可能由于網絡原因長時間無法完成會導致yarn連接超時,舊版本可以在/frontend/Dockerfile文件中修改yarn install部分的腳本,增加網絡超時參數,新版本已增加該參數可忽略此步驟。
RUN yarn install --network-timeout 1000000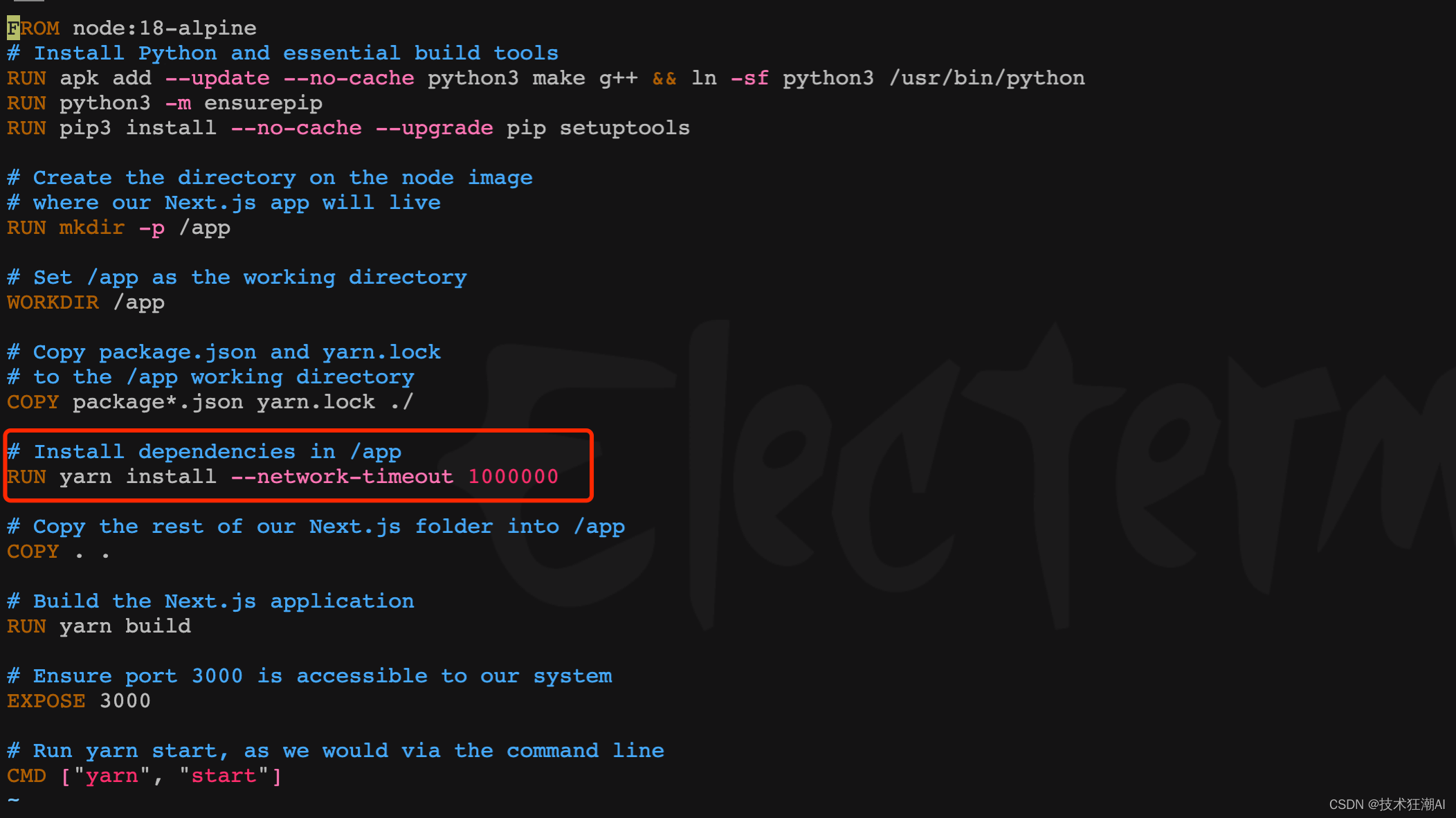
5.7、構建并啟動Quivr?
docker compose -f docker-compose.yml up --build -dQuivr構建完成啟動后如下圖所示:

六、訪問Quivr
部署完成后,直接訪問 http://ip:3000,第一次部署可以通過郵箱注冊賬號
6.1、添加新大腦
Quivr 有一個“大腦”的概念。它們是封閉的信息體,可用于為大型語言模型 (LLM) 提供上下文,以回答有關特定主題的問題。
LLM接受過各種各樣的數據培訓,但要回答有關特定主題的問題或用于圍繞特定主題進行推論,需要向他們提供該主題的上下文。Quivr 使用大腦作為提供上下文的直觀方式。
當在 Quivr 中選擇大腦時,LLM將僅獲得該大腦的上下文。這允許用戶為特定主題構建大腦,然后用它們來回答有關該主題的問題。未來 Quivr 將會有與其他用戶共享大腦的功能。
在Quivr新版本中,可以支持創新多個知識庫大腦,實現知識庫的內容檢索隔離,同時還支持對支持庫進行授權,只允許授權用戶才能訪問,也可以通過分享鏈接的方式共享知識庫。比幾個月前的版本功能更加完善。
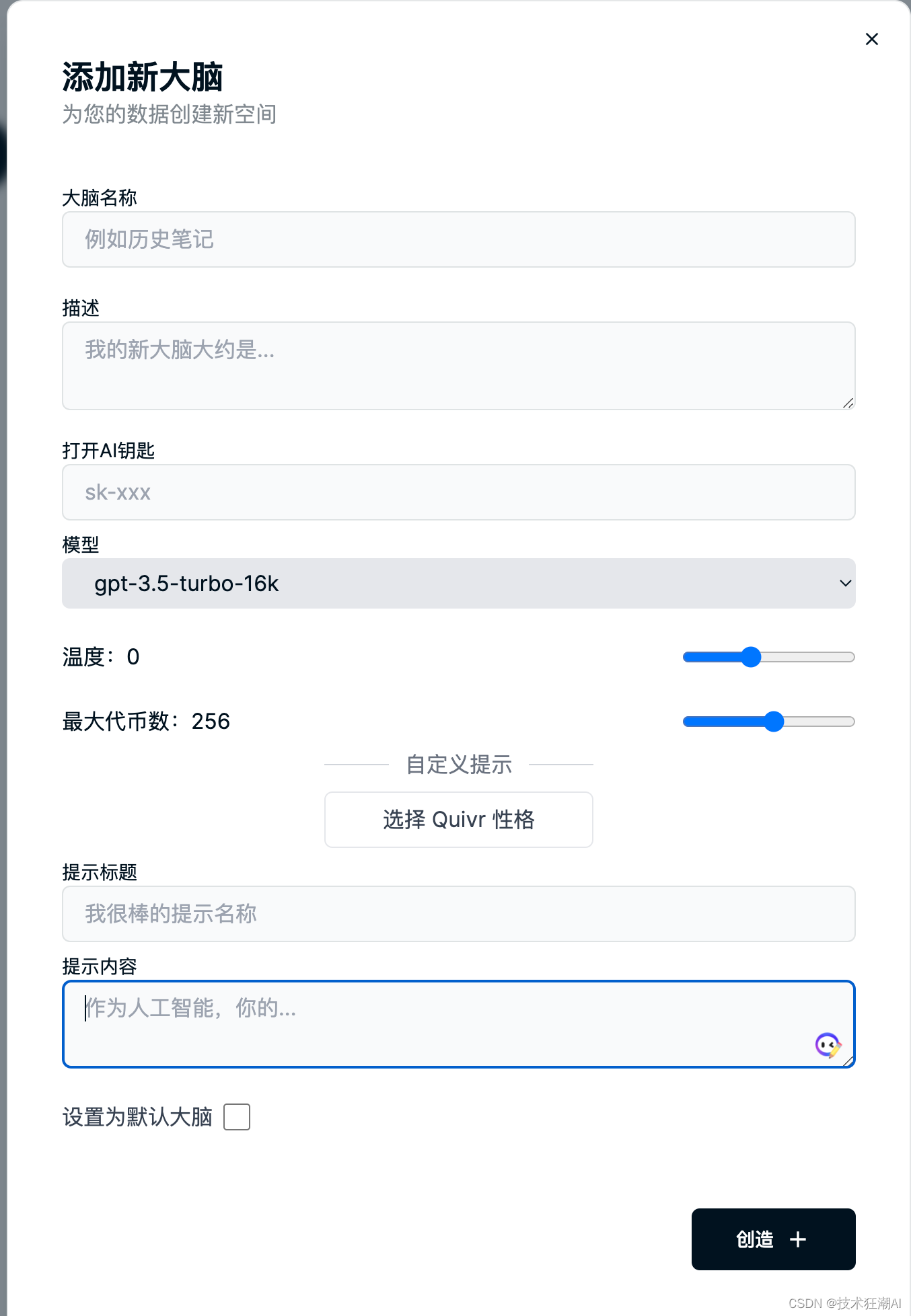
1)、要使用大腦,只需從 Quivr 界面右上角標題中的“使用大腦”圖標中選擇菜單即可。
2)、我們可以通過單擊“創建大腦”按鈕來創建一個新的大腦。系統將提示您輸入大腦的名稱。你也可以使用賬戶生成的默認大腦。
3)、要切換到不同的大腦,只需單擊菜單中的大腦名稱并選擇您想要使用的大腦即可。
4)、如果你沒有選擇大腦,則你上傳的任何文檔都將添加到默認大腦中。
5)、在新建大腦知識庫界面中,可以設置使用的模型和模型相關參數,同時也可以針對每個知識庫大腦設置獨有的Prompt以及所使用的OpenAI API Key,不設置則默認讀取配置文件中配置的Key。
注意:如果在使用聊天功能時,需要從菜單中先選擇一個大腦才能使用聊天功能。
6.2、共享知識庫
在選擇大腦界面,我們點擊大腦后面的分享按鈕,通過URL或者發郵件的方式分享或者邀請其它用戶加入大腦,共享知識庫。
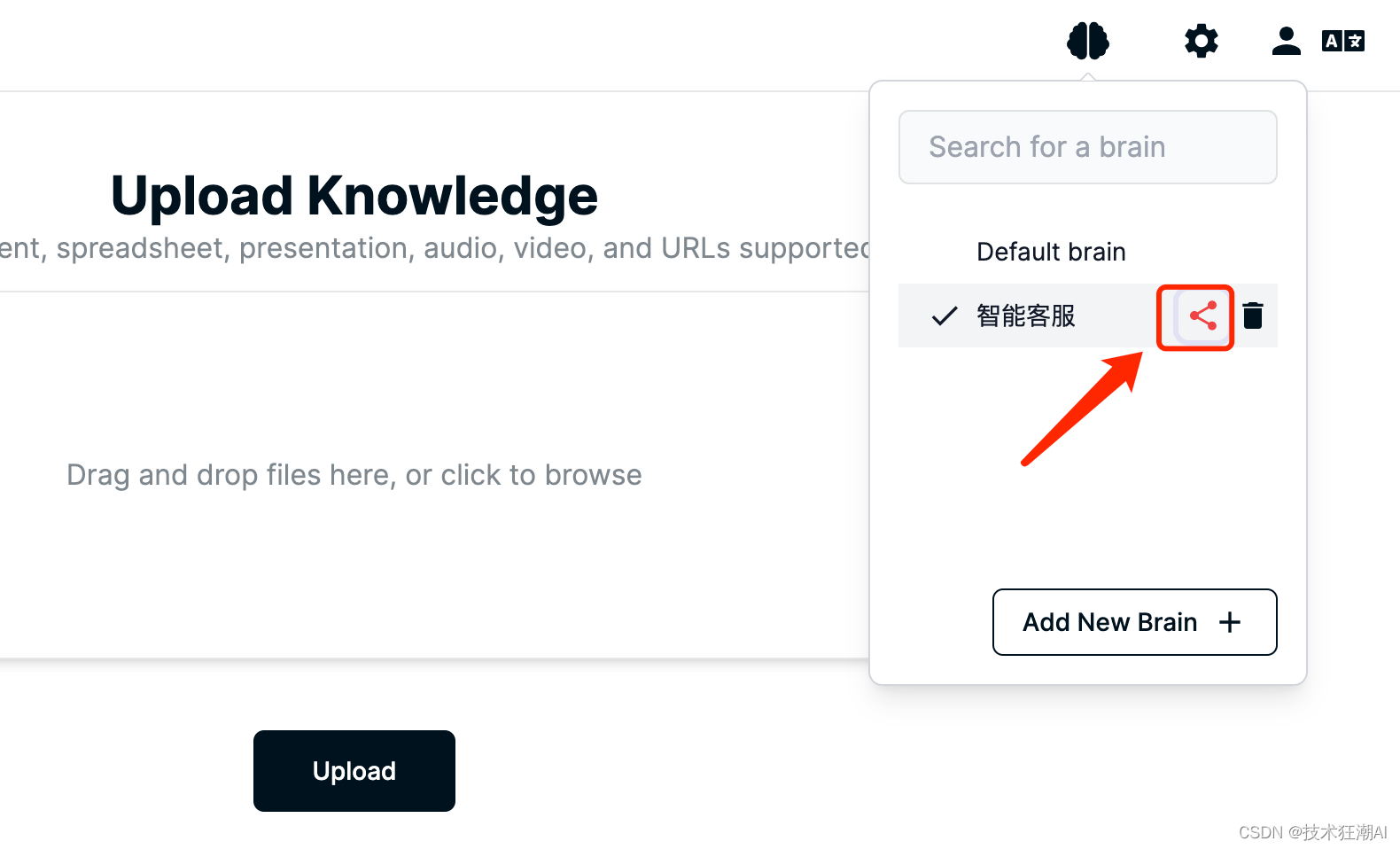 ?
?
Quivr 中通過集成 Resend API,用于通過電子郵件邀請來處理共享大腦。
在 /backend/core/.env 文件中引入了兩個環境變量來配置發送郵件的功能:
-
RESENDAPIKEY:這是 Resend 為我們的應用程序提供的唯一 API 密鑰。它使我們能夠以安全的方式與 Resend 平臺進行通信。
-
RESENDEMAILADDRESS:這是我們通過重新發送發送電子郵件時用作發件人地址的電子郵件地址。
從環境變量中獲取 Resend API 密鑰和電子郵件地址后,我們使用它通過 resend.Emails.send 方法發送電子郵件。
6.2、上傳知識庫
新建完知識庫大腦后,就可以選擇對應的知識庫,上傳文檔構建向量數據了,支持文檔、音頻、視頻和網頁鏈接,所有文件最終都會抽取文件中的文本內容通過調用大模型的API構建向量數據。
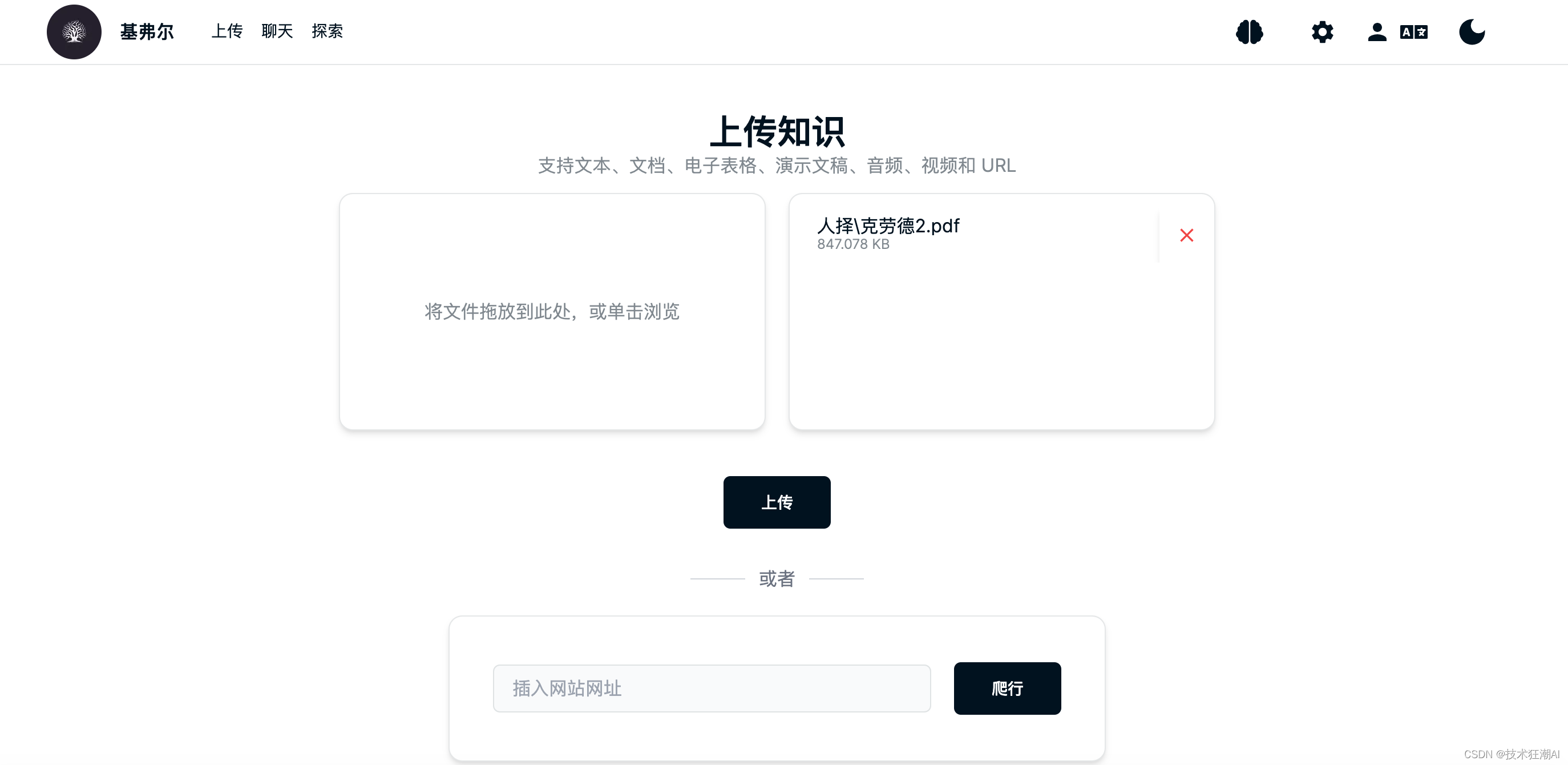
?文件上傳完成后,會有如下提示信息

6.3、查詢知識庫
知識庫文檔構建完成后,就可以對當前選擇的知識庫大腦進行內容檢索了,這里我們以魯迅先生在日本留學的老師藤野先生為例來測試一下Quivr是否正確識別了知識庫文檔的內容。?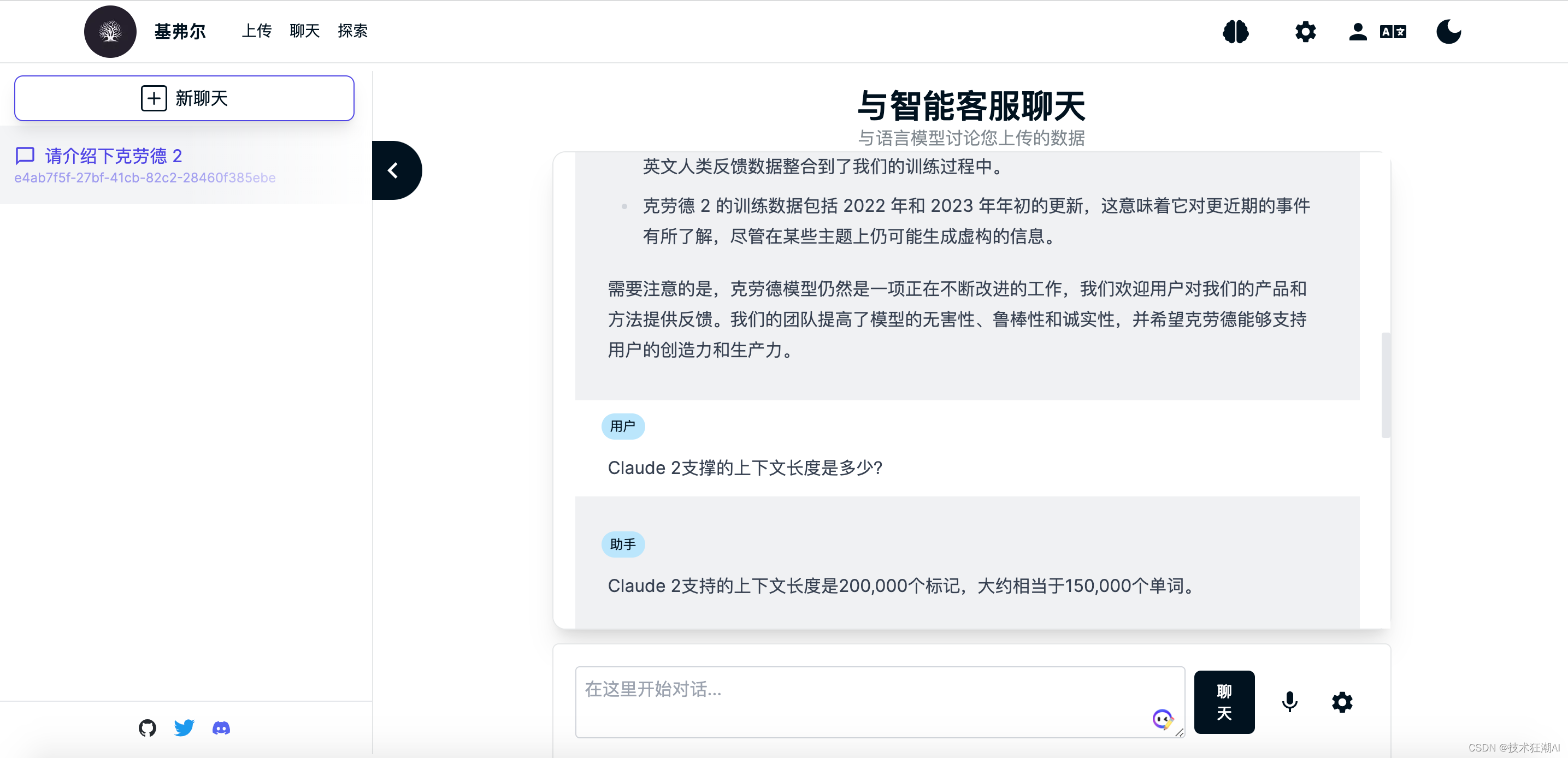
在沒學習專有知識之前,GPT模型不知道魯迅先生在日本學醫的老師是誰,一般會胡亂給出一個日本人的名字,而且多次詢問,人命還不一致。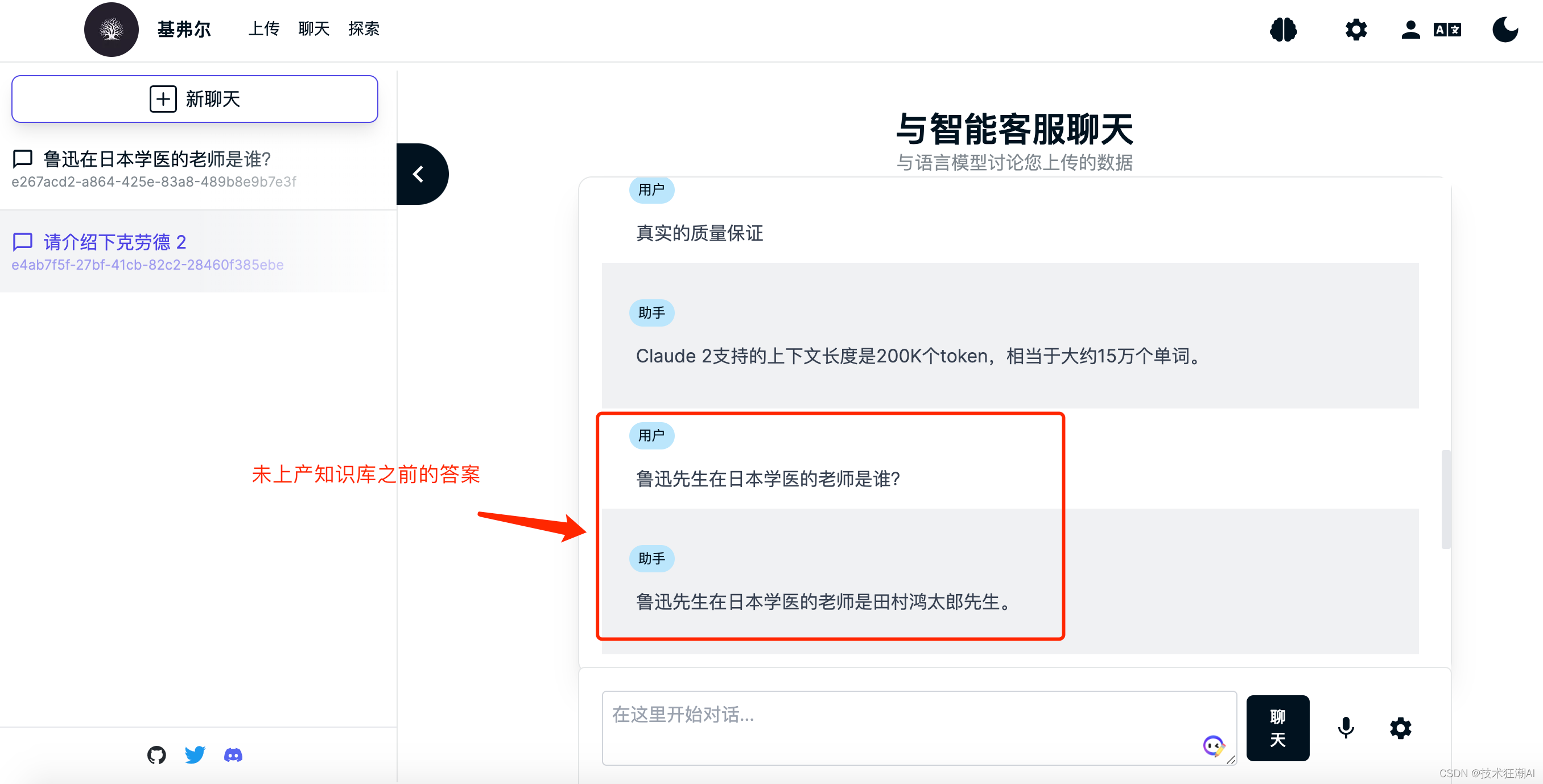 ?在上傳完關于魯迅先生寫的《藤野先生》部分文章內容之后,我們再次詢問發現可以成功檢索正確的答案了。?
?在上傳完關于魯迅先生寫的《藤野先生》部分文章內容之后,我們再次詢問發現可以成功檢索正確的答案了。?
七、本地化LLM支持
Quivr 在0.0.46版本可以正式支持接入本地LLM大模型,目前只支持由 GPT4All 提供支持的私有 LLM 模型(其他開源模型即將推出),基本上與 PrivateGPT 項目提供的功能類似。意味著你的數據永遠存儲在本地。LLM 將下載到服務器并在本地對你的問題運行推理。
7.1、使用方法
-
在 /backend/core/.env 文件中將“private”屬性設置為 True。您還可以在 .env 文件中設置其他模型參數。
-
GPT4All 模型下載地址:https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin
將下載的 GPT4All 模型放在 /backend/local_models 文件夾中。
GPT4All 是一個開源軟件生態系統,允許任何人在日常硬件上訓練和部署強大且定制的大型語言模型 (LLM)。 Nomic AI 負責監督對開源生態系統的貢獻,確保質量、安全性和可維護性。
GPT4All 軟件生態系統與以下 Transformer 架構兼容:
-
Falcon -
LLaMA(includingOpenLLaMA) -
MPT(includingReplit) -
GPT-J -
Replit - 基于 Replit Inc. 的 Replit 架構
-
StarCoder - 基于 BigCode 的 StarCoder 架構
具體支持的模型型號列表可以從 GPT4All 的網站上查看詳盡列表,或下載任何支持的模型。使用這些架構之一訓練的任何模型都可以量化,并使用所有 GPT4All 綁定在本地運行,并在聊天客戶端。您可以通過為 gpt4all 后端做出貢獻來添加新變體。
7.2、未來計劃
Quivr 計劃在本地私有化 LLM 功能中添加更多模型。使用 Hugging Face 的本地嵌入模型來減少對 OpenAI API 的依賴。未來還將添加在前端和 API 中使用私有 LLM 模型的功能。目前的版本只有部署后端才能使用。
八、Quivr路線圖
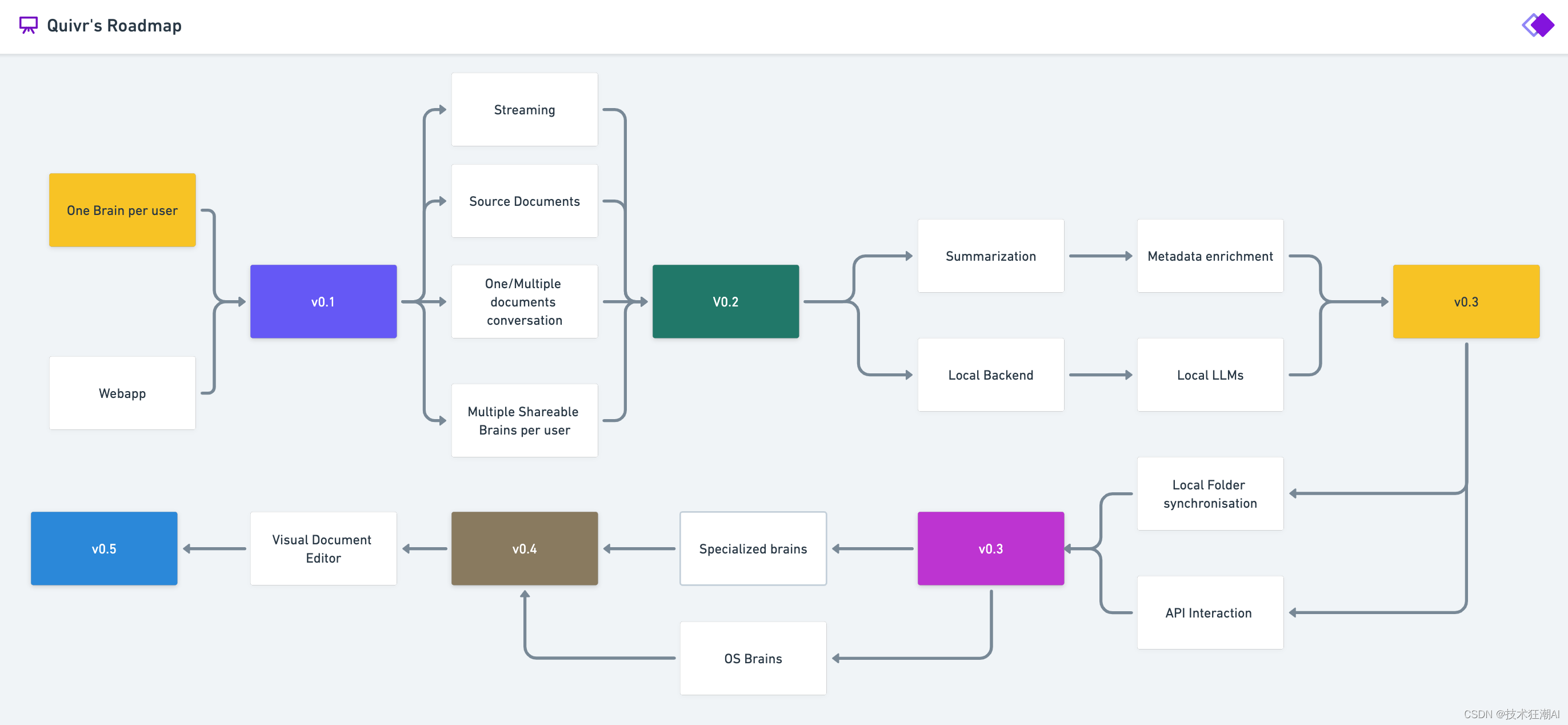
?
九、References
- Quivr GitHub
https://github.com/StanGirard/quivr
- Quivr FastAPI
https://api.quivr.app/docs
- Resend API
https://resend.com/overview
- June Analytics
https://analytics.june.so/
- GPT4All WebSite
https://gpt4all.io/index.html
- GPT4All Models
https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin
- GPT4All Supported Models
https://raw.githubusercontent.com/nomic-ai/gpt4all/main/gpt4all-chat/metadata/models.json

_socket編程)

















——圖像基本處理(二))