我不會記錄的特別詳細
大體框架
- 基本的Select語句
- 運算符
- 排序與分頁
- 多表查詢
- 單行函數
- 聚合函數
- 子查詢
第三章 基本的SELECT語句
SQL分類
這個分類有很多種,大致了解下即可
- DDL(Data Definition Languages、數據定義語言),定義了不同的數據庫、表、視圖、索引等數據庫對象,也可以用來創建、刪除、修改數據庫和數據表的結構。
常見的CREATE、DROP、ALTER - DML(Data Manipulation Language、數據操作語言),用于添加、刪除、更新和查詢數據庫記錄,并檢查數據完整性。
主要包括INSERT、DELETE、UPDATE、SELECT等。SELECT用的最多. - DCL(Data Control Language、數據控制語言),用于定義數據庫、表、字段、用戶的訪問權限和安全級別。
主要包括GRANT、REVOKE、COMMIT、ROLLBACK、SAVEPOINT等。
SQL的規則與規范
規則
這個必須遵守
- 每條命令以;或\g或\G結束
- 關鍵字不能被縮寫也不能分行,更不能在中間插入空格,如select寫成sel ect,錯誤
- 字符串和日期時間類型的數據可以使用單引號(‘’)表示
- 列的別名用雙引號(“”),建議加上as
規范
- windows下對大小寫不敏感
- Linux下大小寫敏感,比如數據庫名大寫和小寫不一樣,但是關鍵字、函數名、列名及其別名是忽略大小寫的
- 推薦的規范
- -SQL關鍵字、函數名、綁定變量都大寫,其余的都小寫
注釋
單行注釋 #和–,多行注釋 /**/
# 單行注釋
-- 單行注釋
/*多行注釋
*/
命名規則
這個了解即可
- 庫名,表名不得超過30個字符,變量名限制為29個字符
- 同一個MySQL軟件中,庫名必須唯一,同一個庫中,表名必須唯一,同一個表中,字段名唯一
- 若關鍵字與字段名沖突且堅持使用,用著重號(``)把字段引起來
例子
create database a;//正確
create database a;//錯誤,已經存在
use a;
create table order(id int);//錯誤,order是關鍵字
create table `order`(id int);//正確
數據導入指令
source sqlFile
基本的Select語句
select … from TableName;
為什么不推薦使用*
因為獲取所有的列會降低性能,讓效率變低
列的別名
就比如你要計算年工資,你總不能存一個年工資和月工資把,這樣浪費空間,還不是起一個別名
注意事項
別名使用雙引號,列名和別名之間加入AS,若別名有空格必須使用雙引號,別名要見名知義
例子:
SELECT name,salary,salary * 12 AS "annual salary" FROM employee;
DISTINCT
去重的,對所在列以及后面的列去重
例如:
SELECT DISTINCT departmentId From employee;//對departmentId進行去重
SELECT DISTINCT departmentId,salary FROM employee;//對部門id和工資這個組合進行去重
/*
若有兩條記錄
departmentId salary
1 8000
1 7800
那么這兩條記錄會保留
若兩條記錄是
departmentId salary
1 8000
1 8000
這個是保留一個
*/
NULL參與運算
只要有NULL結果必定為NULL
注意:NULL不是空,他占存儲空間,NULL的長度為空
查詢常數
這個我沒有試過,明天試試
就比方說我想要把公司A的所有部門都列出來,格式如下:
| 公司A | 部門名稱 |
|---|---|
| 公司A | 部門1 |
| 公司A | 部門2 |
| 公司A | 部門3 |
可以這么寫
SELECT "公司A",departmentName from deparments;
顯示表結構
DESC或者DESCRIBE
DESCRIBE departments;
desc departments;
結果中有兩列是Key和Extra,只記錄這兩個
- Key:表示該列是否已編制索引。PRI表示該列是表主鍵的一部分(主鍵可以有多個列組成);UNI表示該列是UNIQUE索引的一部分(復合索引);MUL表示在列中某個給定值允許出現多次。
- Extra:該列的附加信息,例如AUTO_INCREMENT等等
where
這個太簡單了,不記錄了
第四章 運算符
算數運算符
加->+
減->-
乘->*
除->/
取余->%,比如 17 % 5 = 2 (17 -3*5)
比較運算符
這個很簡單,簡要記錄
真為1,假為0,其他為null
- 不等于:<>,!=
- 大于(等于):>(>=)
- 小于(等于):<(<=)
等號運算符
- 若兩邊都是字符串,比較的是ASCII碼是否相等
若是整數就是比較數值大小 - 若一個是字符串,另一個是整數,MySQL會把字符串轉換為數字進行比較
- 若有一個為null,那么結果必定為null
安全等于運算符 <=>
他比等于多一個對null的判斷,只有他是針對null的,就是當兩邊都是null的時候返回1;一邊為null一邊不為null返回0
SELECT NULL <=> NULL, 1<=>1;
邏輯運算符
與或非,異或沒了,這里簡單記錄,
注意這里只要有一個參數是NULL那么結果必定為NULL,優先級:NOT > AND > OR(XOR)
| 運算符 | 規則 | 例子 |
|---|---|---|
| NOT 或! | 若為0結果為1,若為1,結果為0 | SELECT NOT |
| AND 或 && | 同一則一,有一個0就是0 | SELECT 1 && 1 |
| OR 或 || | 有一個一就是一,全為0結果就是0 | SELECT 1 OR 0 |
| XOR | 兩個不一樣就是1,一樣就是0 | SELECT 1 XOR 0 |
位運算符
我的理解就是把操作數轉換為補碼按照指定的運算符的規則進行運算,再把結果轉換為十進制數字
支持的運算符
| 運算符 | 含義 | 例子 |
|---|---|---|
| & | 按位與(AND) | SELECT A & B |
| | | 按位或(OR) | SELECT A | B |
| ^ | 按位異或(XOR) | SELECT A ^ B |
| ~ | 按位取反 | SELECT ~A |
| >> | 按位左移 | SELECT A <<1 |
| << | 按位右移 | SELECT B >>1 |
解釋: 以 8 和-2 為例
8轉換為補碼是 0 1000
-2的原碼是 1 0010
-2的反碼是 1 1101
-2的補碼是 1 1110
8 & -2
???0 1000
& 1 1110
——————
???0 1000
這里直接轉二進制即可,結果是8
8 | -2
???0 1000
|? 1 1110
——————
???1 1110
最高位是1,是負數,要求真值,對1 1110取補等于1 0010 轉換為二進制數為-2 ,但是顯示的結果是18446744073709551614,應該是默認情況下數字以bigint類型存儲的,bigint類型是8個字節,他的結果解釋方式應該是把二進制解釋成無符號數,要不然不會這么大的數字,如果是按照這么來的話,那1 1110需要進行符號位擴展,擴展如下
1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1110 ,就是在1 1110的最高位1前面加了79個1,把這一串數字轉換為十進制等于18446744073709551614
8 ^ -2
???0 1000
|? 1 1110
——————
???1 0110
符號位擴展,擴展成64位,擴展結果
1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 0110,把這東西轉換為十進制18446744073709551606
~ -2
-2的補碼(64位)等于1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1111 1110
# 1111 1111 -> 0000 0000
# 1111 1111 -> 0000 0000
# 1111 1111 -> 0000 0000
# 1111 1111 -> 0000 0000
# 1111 1111 -> 0000 0000
# 1111 1111 -> 0000 0000
# 1111 1110 -> 0000 0001
# 從上到下,把->后面的數字串起來為1前面63個0,當成無符號數,轉換為十進制為1,所以答案就是1
1 >> 2
tips:在一定的條件下,可以當作除以2的n次冪來用
右移的規則:右移指定的位數后,右邊低位的數值被移出并丟棄,左邊高位空出的位置用0補齊。
這里不做符號位擴展了,簡要的記錄一下
1的補碼是0 1,右移一位,01的最低位1就沒了,高位補零,那么直接移成了0
1 << 2
tips: 在一定的條件下,可以當成乘以2的n次冪來用
就是乘以了2n,n就是右移的位數,可能會溢出
優先級
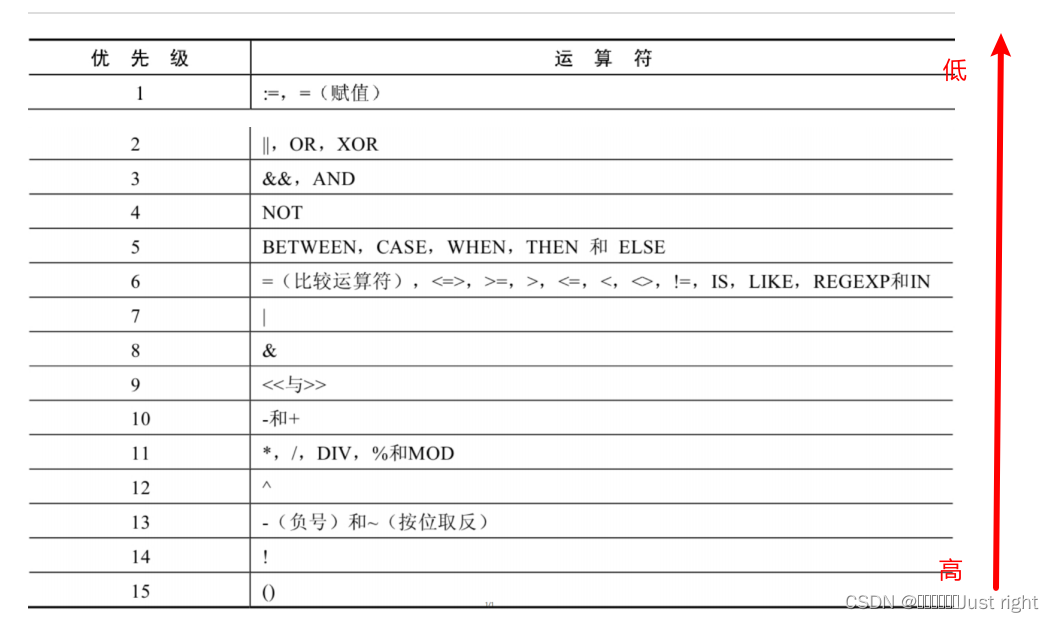
其他運算符
- IS NULL: 判空的
- IS NOT NULL:判非空的
- LEAST:返回多值中的最小值
SELECT LEAST(1,2,3,4) FROM DUAL;
- GREATEST:返回多值中的最大值
SELECT GREATEST(1,2,3,4) FROM DUAL;
- BETWEEN AND:判斷值是否在指定的區間內,區間是左閉右閉的
SELECT 2 between 1 and 2;
- ISNULL:判空
- IN: 判斷一個值是否為列表中的任意一個值
一般是在子查詢里面用的比較多
SELECT 2 NOT IN (1,2);
- NOT IN:判斷一個值是否不是一個列表中的任意一個值
SELECT 2 NOT IN (1,2);
- LIKE 運算符:匹配字符串的,模糊匹配
%是通配零個或多個字符的
_是只能匹配一個字符的
SELECT 'abcd' LIKE 'a__d';
- ESCAPE:回避特殊符號的,\也可以
比方說,查找前兩個字符是EM,第三個字符是%或者_的
:取消_,%的匹配作用
ESCAPE:指定一個字符充當\的作用,這個言簡意賅點,
指定字符后面緊挨著的第一個匹配符號(_,%)失效,這個不太常用
SELECT DepartmentId FROM DEPT WHERE DepartmentId like 'EM\%'or DepartmentId like 'EM\_';//這個用的比較少,了解
SELECT DepartmentId FROM DEPT WHERE DepartmentId like 'EMa%' ESCAPE 'a'or DepartmentId like 'EMb_' ESCAPE 'b';
- REGEXP運算符
這里要用到點正則表達式的東西,這個用到了去網上搜
正則表達式簡要了解下,這東西能寫出一本書出來
‘^’:匹配以該字符后面的字符開頭的字符串
‘$’:匹配以該字符前面的字符結尾的字符串
'. ': 匹配任何一個但字符
“[…]”:匹配出現在方括號里面的字符,如匹配所有字母:[a-zA-Z]
‘*’:匹配零個或多個在它前面的字符,
擴展 正則表達式
常應用于檢索字符串,提取數字,驗證等等
MySQL支持的
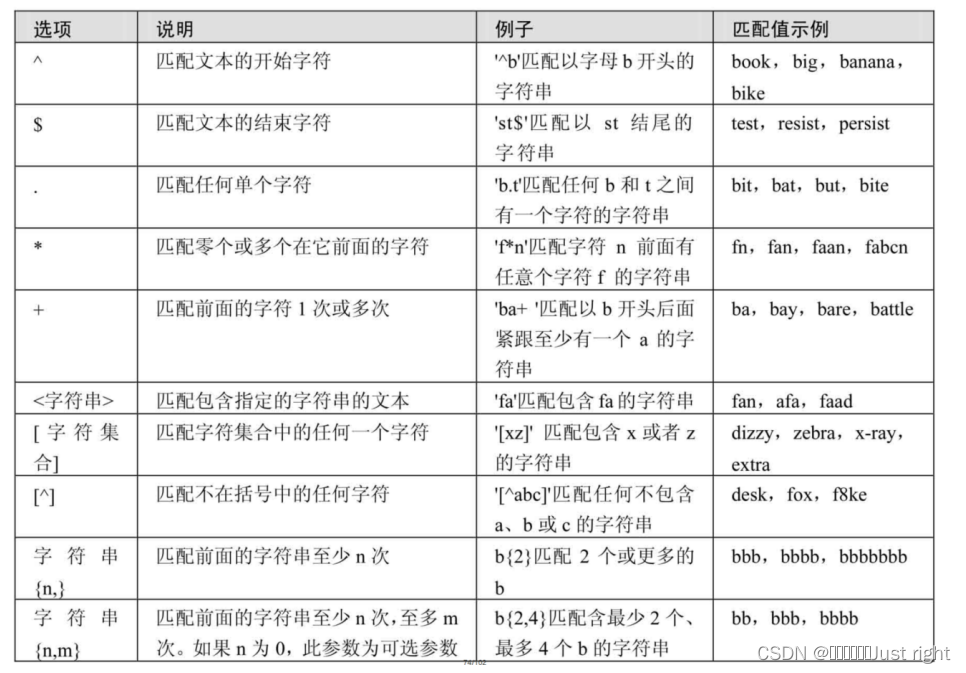
- 查詢以特定字符或字符串開頭的記錄:
在name列查詢以ea開頭的記錄
SELECT * FROM `user` where name REGEXP '^ea';
- 查詢以特定字符或字符串結尾的記錄:
在name列查詢以or結尾的記錄
SELECT * FROM `user` where name REGEXP 'or$';
- 用符號’.'通配一個字符,查詢name列字段值中包含ea且e和a之間只有一個字母的記錄
SELECT * FROM `user` where name REGEXP 'e.a';- 用’*‘和’+'匹配多個字符:在name列中查找以字母c開頭且c后面出現字母e至少一次的記錄
SELECT * FROM `user` where name REGEXP '^ce+';
- 匹配指定字符串,可以匹配多個
- 在name列中查找包含ea的記錄
SELECT * FROM `user` WHERE name REGEXP 'ea';
- 在name列中查找包含ea和or的記錄
SELECT * FROM `user` WHERE name REGEXP 'ea | or';
- 匹配指定字符中任意一個,就是方括號的用法
在name列中查找包含字母abced和 wxy的記錄
SELECT * FROM `user` WHERE name REGEXP '[a-dw-y]
- 匹配指定字符以外的字符 "[^字符集合]"匹配不在指定集合中的任何字符
在name列中查找id字符串包含a-h和數字1-8以外字符的記錄
SELECT * FROM `user` WHERE id REGEXP '[^a-h1-8]';
- 使用{n,}或者{n,m}來指定字符串連續出現的次數,“字符串
{n,}”表示至少匹配n次前面的字符;“字符串{n,m}”表示匹配前面的字符串不少于n次,不多于m次。例如,or{2,}表示or連續出現至少2次,也可以
大于2次;ea{2,4}表示ea連續出現最少2次,最多不能超過4次。
運算符一章完成,明天完成排序的一半








——圖像基本處理(二))





)




